شهدت نماذج اللغة الكبيرة مفتوحة المصدر محلياً في عام 2026 نقطة تحول مفصلية، حيث أطلقت شركة "مون شوت" (Moonshot AI) نموذجها الرائد Kimi K2.6 بشكل مفتوح المصدر. وقد حقق النموذج 58.6 نقطة في معيار SWE-Bench Pro، متفوقاً بذلك على GPT-5.4 (57.7 نقطة) وClaude Opus 4.6 (53.4 نقطة)، ليصبح النموذج الأكثر قدرة على حل مشكلات GitHub الحقيقية حالياً.
يتناول هذا المقال عملية دمج API لنموذج Kimi K2.6، مع تحليل معمق لهيكلية 1T MoE، ونافذة السياق التي تصل إلى 256K، وقدرات استدعاء الوظائف (Function Call) والتحكم في التكملة النصية. كما نوفر أمثلة برمجية كاملة لمساعدتك في إتمام عملية الدمج خلال 5 دقائق. ومن حيث التكلفة، توفر منصة APIYI (apiyi.com) عبر قنواتها الرسمية مع سحابة هواوي (Huawei Cloud) سعراً تنافسياً يبلغ 0.60 دولار للمدخلات و2.40 دولار للمخرجات لكل مليون رمز (tokens)، وهو ما يعادل تقريباً 60% من السعر الرسمي.
القيمة الجوهرية: ستتقن بنهاية هذا المقال طرق استدعاء Kimi K2.6 API، وتنظيم أدوات استدعاء الوظائف، وتقنيات تحسين ذاكرة التخزين المؤقت، وستعرف متى يكون K2.6 هو الخيار الأمثل من حيث التكلفة والأداء.

النقاط الجوهرية لـ Kimi K2.6 API
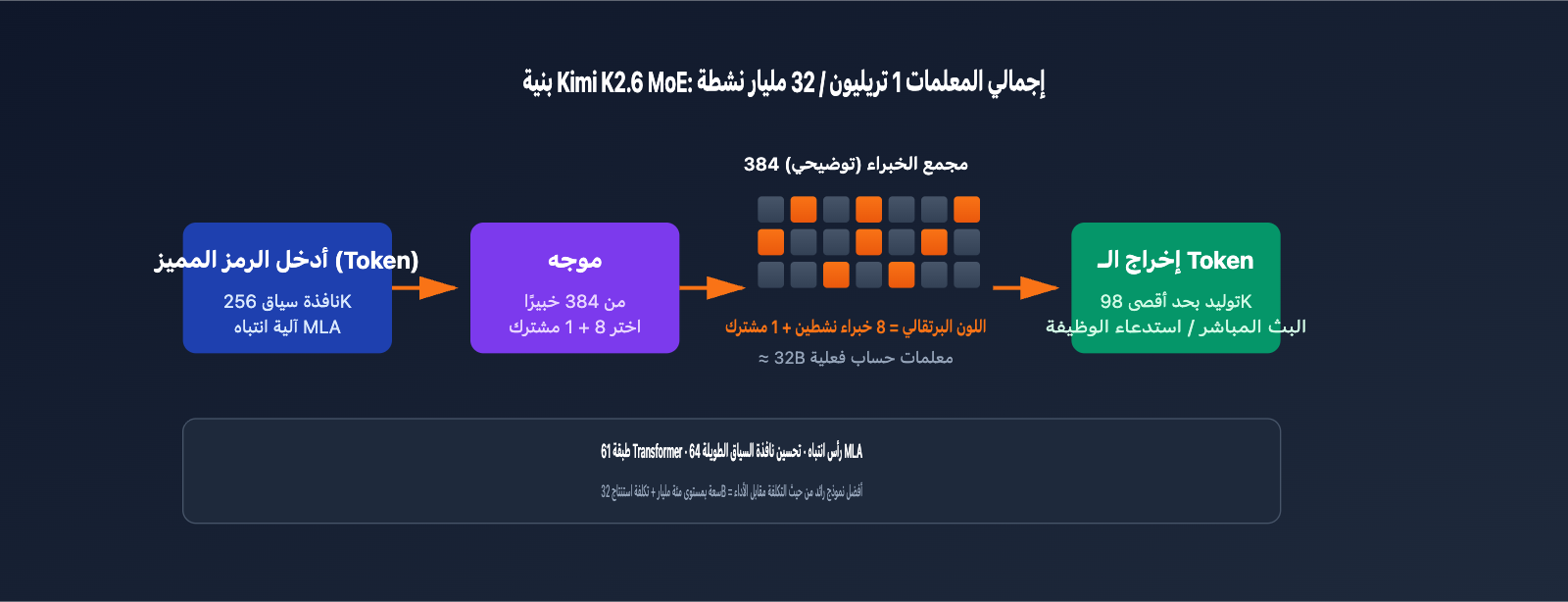
يُعد Kimi K2.6 الجيل الجديد من النماذج الرائدة مفتوحة المصدر التي أطلقتها شركة Moonshot في أبريل 2026. وهو يواصل استخدام معمارية MoE التي ميزت سلسلة Kimi K2، مع ترقيات جوهرية في البرمجة، وسياق الذاكرة الطويل، واستدعاء الأدوات. يوضح الجدول التالي المواصفات التي تهم المطورين:
| وجه المقارنة | المواصفات التفصيلية | القيمة العملية |
|---|---|---|
| معمارية MoE | 1T إجمالي البارامترات / 32B نشطة / 384 خبيراً (8 اختيار + 1 مشارك) | قدرات فائقة تقارن بنماذج التريليون، مع تكلفة استنتاج تعادل نموذج 32B |
| نافذة السياق | 256K tokens (بدقة 262,144) | معالجة مستودعات برمجية ضخمة أو وثائق قانونية دفعة واحدة |
| الحد الأقصى للتوليد | 98,304 tokens في المخرجة الواحدة | مثالي لإعادة هيكلة الأكواد الطويلة وتوليد الوثائق |
| متعدد الوسائط | مشفر بصري 400M MoonViT مدمج | دعم أصلي للمدخلات المرئية والصور ومقاطع الفيديو |
| تنظيم الوكلاء | دعم 300 وكيل فرعي / 4,000 خطوة تنسيق | قادر على معالجة عمليات البحث والتطوير المعقدة ومتعددة الخطوات |
| رخصة المصدر | Modified MIT License | صديقة للاستخدام التجاري، بدون قيود كبيرة |
شرح تفصيلي لقدرات Kimi K2.6 API
مقارنة بالجيل السابق K2.5، حقق K2.6 قفزة نوعية في ثلاثة أبعاد: أولاً، تجاوز 58.6 نقطة في معيار SWE-Bench Pro، متفوقاً لأول مرة على GPT-5.4 وClaude Opus 4.6 في مهام حل مشكلات البرمجيات مفتوحة المصدر. ثانياً، زيادة عدد الوكلاء الفرعيين من 100 إلى 300، ورفع خطوات التنسيق من 1500 إلى 4000، مما يتيح له تنفيذ مهام تطوير ذات سلاسل طويلة. ثالثاً، فتح نافذة سياق 256K بالكامل، مع تقليل تكاليف الذاكرة (VRAM) وزمن الاستجابة بشكل كبير بفضل تقنية الانتباه الكامن متعدد الرؤوس (MLA).
🎯 نصيحة تقنية: في التطوير الفعلي، ننصح باستدعاء Kimi K2.6 مباشرة عبر منصة APIYI (apiyi.com). توفر المنصة وصولاً عبر قنوات سحابة هواوي الرسمية، وتتوافق واجهاتها تماماً مع OpenAI SDK، مما يعني أنه يمكنك التبديل بين النماذج دون الحاجة إلى تعديل الكود البرمجي الخاص بك.
نظرة تفصيلية على البنية التقنية لـ Kimi K2.6 API
يساعدك فهم البنية الأساسية لنموذج Kimi K2.6 على اختيار النموذج الأنسب لمشاريعك المختلفة. يوازن تصميم البنية بين "سعة المعلمات التي تصل إلى ترليون" و"تكلفة الاستدلال الخاصة بنماذج العشرات من المليارات".
آلية التنشيط المتناثر (MoE)
يعتمد Kimi K2.6 على بنية خليط الخبراء (MoE) التي تضم ترليون معلمة، وتتكون من 384 شبكة خبراء. عند إجراء استدلال لكل "توكن"، يتم تنشيط 8 خبراء فقط (بالإضافة إلى خبير واحد مشترك)، مما يعني أن 32 مليار معلمة هي التي تشارك فعلياً في العمليات الحسابية. هذا التصميم يمنح النموذج اتساعاً معرفياً يضاهي النماذج ذات الـ 100 مليار معلمة، مع الحفاظ على سرعة استدلال النماذج ذات الـ 32 مليار معلمة، مما يجعله أحد أكثر النماذج كفاءة من حيث تكلفة استدعاء الـ API حالياً.
تحسين السياق الطويل
| المكون التقني | الوظيفة | إعدادات K2.6 |
|---|---|---|
| انتباه التنبيه متعدد الرؤوس (MLA) | تقليل حجم ذاكرة التخزين المؤقت KV للاستدلال بالسياق الطويل | 64 رأس انتباه |
| عدد طبقات الشبكة | تحديد عمق استدلال النموذج | 61 طبقة Transformer |
| نافذة السياق | أقصى عدد من الـ tokens في الإدخال الواحد | 262,144 توكن (256K) |
| ترميز الموضع | تقنية أساسية لدعم التسلسلات فائقة الطول | مدرب خصيصاً للسياق الطويل |
| ذاكرة التخزين المؤقت للبادئة | مطابقة الموجهات المتكررة لتقليل التكاليف | انخفاض سعر الإدخال بنحو 75% عند المطابقة |
💡 رؤية تقنية: يمكن لـ K2.6 تقليل تكاليف الإدخال بشكل ملحوظ في سيناريوهات الحوار متعدد الجولات أو عند استخدام موجه نظام (system prompt) ثابت عبر "ذاكرة التخزين المؤقت للبادئة". ننصح بالحفاظ على استقرار موجه النظام في بيئة الإنتاج لتعظيم معدل نجاح التخزين المؤقت.
مقارنة الأداء المعياري لـ Kimi K2.6 API
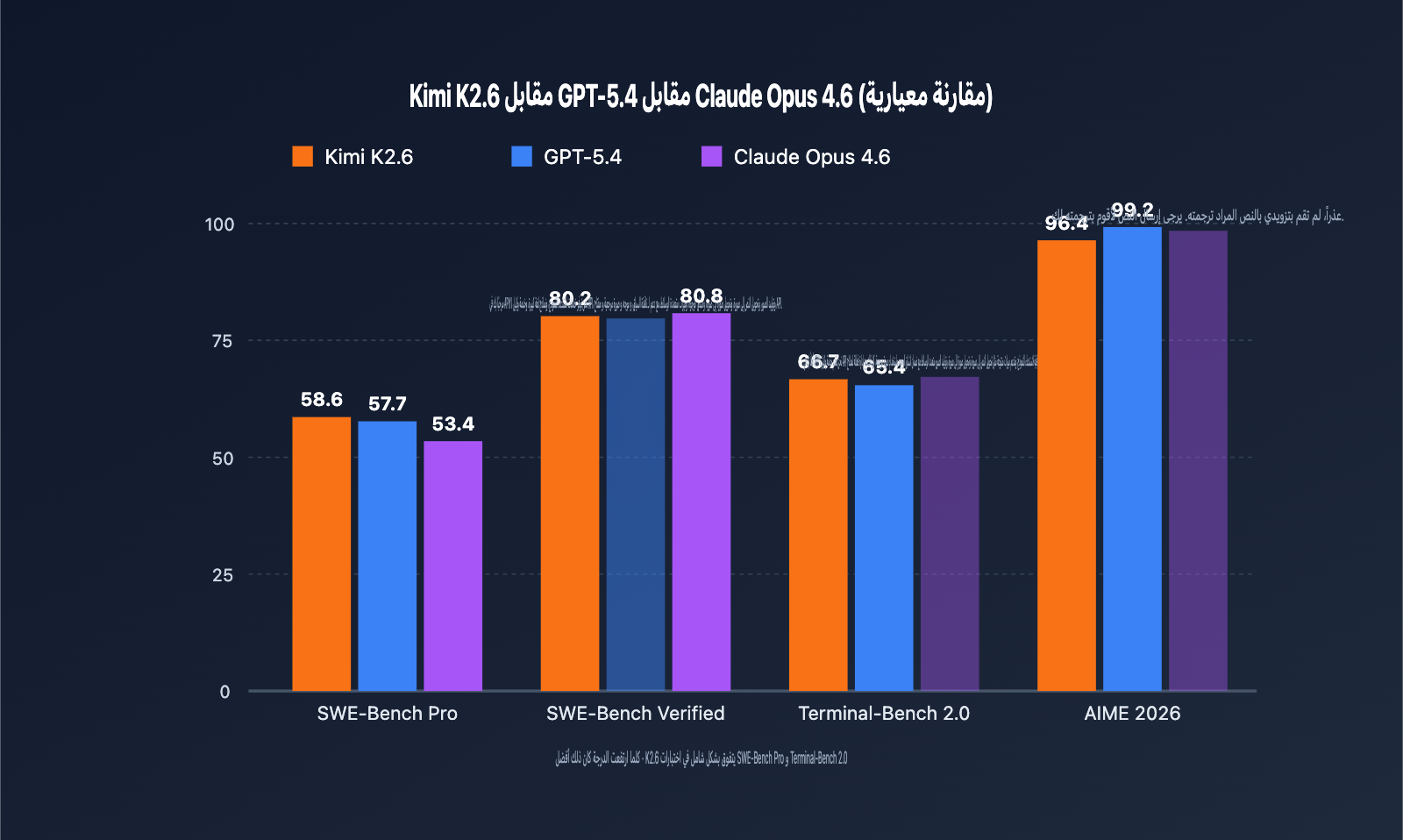
تُعد الاختبارات المعيارية الطريقة الأكثر مباشرة لتحديد ما إذا كان نموذج اللغة الكبير يستحق الاعتماد عليه أم لا. فيما يلي مقارنة لأداء نماذج Kimi K2.6 وGPT-5.4 وClaude Opus 4.6 عبر خمسة اختبارات معيارية موثوقة.
القدرات البرمجية وهندسة البرمجيات
| الاختبار المعياري | Kimi K2.6 | GPT-5.4 | Claude Opus 4.6 | النموذج الأفضل |
|---|---|---|---|---|
| SWE-Bench Pro | 58.6 | 57.7 | 53.4 | Kimi K2.6 |
| SWE-Bench Verified | 80.2 | – | 80.8 | Claude Opus 4.6 |
| Terminal-Bench 2.0 | 66.7 | 65.4 | – | Kimi K2.6 |
| HLE (with tools) | 54.0 | – | 53.0 | Kimi K2.6 |
| AIME 2026 | 96.4 | 99.2 | – | GPT-5.4 |
| GPQA-Diamond | 90.5 | – | – | – |
تحليل النقاط الرئيسية:
- SWE-Bench Pro: يقيس قدرة النموذج على حل مشاكل GitHub الحقيقية من البداية للنهاية. حقق K2.6 نتيجة 58.6، وهي المرة الأولى التي يتفوق فيها نموذج مفتوح المصدر على النماذج الرائدة مغلقة المصدر في هذا الاختبار، مما يعني أن K2.6 خيار مثالي لمهام صيانة الكود وإصلاح الأخطاء.
- SWE-Bench Verified: هو نسخة مبسطة نسبياً، حيث تفوق Claude Opus 4.6 بفارق بسيط (80.8 مقابل 80.2)، مما يشير إلى أن Claude لا يزال يحتفظ بميزة في مهام البرمجة القياسية.
- Terminal-Bench 2.0: يقيس قدرة النموذج على إدارة أوامر الطرفية (Terminal)، وقد تفوق K2.6 بنتيجة 66.7، مما يجعله مناسباً لسيناريوهات DevOps والعمليات المؤتمتة.
- AIME / HMMT: لا تزال الاستنتاجات الرياضية البحتة نقطة قوة لـ GPT-5.4، لذا نوصي بالاحتفاظ بـ GPT-5.4 للمهام ذات الطابع الرياضي الصرف.
🎯 توصيات السيناريو: ننصح بإجراء اختبارات A/B بين النماذج لمهام مختلفة؛ فمثلاً، أعطِ الأولوية لـ K2.6 في مهام صيانة الكود، وGPT-5.4 في الاستنتاج الرياضي، واحتفظ بخيار Claude للكتابة الإبداعية الطويلة.
دليل البدء السريع لـ Kimi K2.6 API
سنقوم في هذا القسم باستعراض كيفية استدعاء نموذج Kimi K2.6 عبر كود برمجي متكامل. سلسلة Kimi API متوافقة تماماً مع بروتوكول OpenAI SDK، لذا إذا كان لديك كود استدعاء لـ OpenAI، فكل ما عليك فعله هو استبدال base_url و model.
مثال مبسط (Python)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "system", "content": "أنت مهندس بايثون خبير."},
{"role": "user", "content": "استخدم asyncio لتنفيذ مجمع طلبات متزامن، مع حد أقصى للتزامن قدره 10."}
],
temperature=0.3,
max_tokens=2048
)
print(response.choices[0].message.content)
عرض مثال كامل للاستدعاء التدفقي غير المتزامن (مع معالجة الأخطاء)
import asyncio
from openai import AsyncOpenAI
from openai import APIError, RateLimitError
client = AsyncOpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
max_retries=3,
timeout=120.0
)
async def call_kimi_k26_stream(prompt: str, system: str = "") -> str:
"""استدعاء تدفقي لنموذج Kimi K2.6 مع طباعة الرموز (tokens) فورياً"""
messages = []
if system:
messages.append({"role": "system", "content": system})
messages.append({"role": "user", "content": prompt})
full_response = ""
try:
stream = await client.chat.completions.create(
model="kimi-k2.6",
messages=messages,
stream=True,
temperature=0.3,
max_tokens=8192
)
async for chunk in stream:
if chunk.choices[0].delta.content:
token = chunk.choices[0].delta.content
print(token, end="", flush=True)
full_response += token
except RateLimitError:
print("\n[تم الوصول للحد المسموح به، يُنصح بضبط إعادة المحاولة أو ترقية الباقة]")
raise
except APIError as e:
print(f"\n[خطأ في الـ API: {e}]")
raise
return full_response
async def main():
result = await call_kimi_k26_stream(
prompt="اشرح كيف تقلل بنية MoE من تكاليف الاستنتاج",
system="أنت خبير في بنية الذكاء الاصطناعي، إجابتك موجزة واحترافية"
)
print(f"\n\n[إجمالي عدد الرموز: {len(result)}]")
if __name__ == "__main__":
asyncio.run(main())
🚀 ابدأ بسرعة: بعد الحصول على مفتاح API من منصة APIYI apiyi.com، ما عليك سوى ضبط
base_urlعلىhttps://api.apiyi.com/v1. يمكن استخدام كافة حزم SDK الخاصة ببيئة OpenAI (Python/Node.js/Go) مباشرة، ويمكنك إكمال التكامل في غضون 5 دقائق.
الاستدعاء عبر Node.js / TypeScript
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.APIYI_KEY,
baseURL: "https://api.apiyi.com/v1",
});
const completion = await client.chat.completions.create({
model: "kimi-k2.6",
messages: [
{ role: "user", content: "اكتب دالة منع الارتداد (debounce) باستخدام TypeScript، مع دعم الأنواع العامة (Generics)" }
],
temperature: 0.2,
});
console.log(completion.choices[0].message.content);
الاستدعاء المباشر عبر cURL
curl https://api.apiyi.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_APIYI_KEY" \
-d '{
"model": "kimi-k2.6",
"messages": [
{"role": "user", "content": "مرحباً، Kimi K2.6"}
],
"max_tokens": 1024
}'
تطبيق استدعاء الأدوات (Function Call)
تعد قدرة استدعاء الأدوات في K2.6 ترقية ملحوظة مقارنة بسلسلة K2، حيث أظهرت أداءً متميزاً في قائمة المتصدرين لـ Berkeley Function-Calling. فيما يلي مثال كامل حول "الاستعلام عن الطقس" يوضح عملية تنسيق الأدوات.
تعريف واستدعاء الأدوات
from openai import OpenAI
import json
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "الاستعلام عن الطقس الفعلي لمدينة معينة",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "اسم المدينة"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["city"]
}
}
}
]
def get_weather(city: str, unit: str = "celsius") -> dict:
"""محاكاة واجهة الاستعلام عن الطقس"""
return {"city": city, "temperature": 22, "unit": unit, "condition": "مشمس"}
messages = [{"role": "user", "content": "ساعدني في معرفة الطقس في بكين وشانغهاي"}]
response = client.chat.completions.create(
model="kimi-k2.6",
messages=messages,
tools=tools,
tool_choice="auto"
)
assistant_msg = response.choices[0].message
messages.append(assistant_msg)
if assistant_msg.tool_calls:
for tool_call in assistant_msg.tool_calls:
args = json.loads(tool_call.function.arguments)
result = get_weather(**args)
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": json.dumps(result, ensure_ascii=False)
})
final_response = client.chat.completions.create(
model="kimi-k2.6",
messages=messages
)
print(final_response.choices[0].message.content)
التكملة المسبقة (Partial Mode)
يدعم K2.6 نمط "التكملة المسبقة" بأسلوب OpenAI، أي إدخال بداية الرسالة مسبقاً في رسالة المساعد، حيث يبدأ النموذج في التوليد من ذلك الموضع. يُستخدم هذا غالباً لفرض مخرجات JSON أو قيود تنسيق معينة:
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "user", "content": "أرجع بيانات الناتج المحلي الإجمالي لبكين بتنسيق JSON (عام 2023)"},
{"role": "assistant", "content": '{"city": "بكين", "year": 2023, "gdp":'}
],
max_tokens=200
)
print(response.choices[0].message.content)
💰 تحسين التكاليف: في سيناريوهات الموجهات النظامية (system prompt) الطويلة (مثل RAG و Agent)، تنخفض تكلفة المدخلات بنسبة 25% تقريباً بعد تطابق التخزين المؤقت للبادئة، وهو مثالي للحوارات متعددة الجولات والأعمال ذات القوالب الثابتة عالية التكرار. يُنصح بتفعيل مراقبة التخزين المؤقت على مستوى الحساب في منصة apiyi.com لمراقبة معدل التطابق في الوقت الفعلي.
قدرات Kimi K2.6 المتقدمة
إلى جانب استدعاء الأدوات، يقدم K2.6 ثلاث قدرات متقدمة: تنسيق الوكلاء المتعددين (Agent Swarm)، نافذة سياق طويلة تصل إلى 256 ألف، والوسائط المتعددة (Multi-modal)، والتي تشكل معاً قدرته التنافسية في البرمجة، أتمتة البحث والتطوير، وتحليل المستندات.
تنسيق الوكلاء المتعددين (Agent Swarm)
تعد Agent Swarm واحدة من أكثر قدرات K2.6 تميزاً، حيث يمكن للمهمة الواحدة تنسيق ما يصل إلى 300 وكيل فرعي متوازٍ لتنفيذ 4000 خطوة تنسيقية. تجعل هذه الميزة من K2.6 نموذجاً بارزاً في إعادة هيكلة قواعد الأكواد الضخمة، تحليل المراجع المتقاطعة للمستندات المتعددة، وخطوط أنابيب البحث والتطوير المعقدة.
أنماط تنسيق الوكلاء الفرعيين
يدعم Agent Swarm ثلاثة أنماط تنسيق نموذجية:
| نمط التنسيق | سيناريو الاستخدام | عدد الوكلاء الفرعيين | خطوات التنسيق |
|---|---|---|---|
| توازي أحادي المستوى | ملخص المستندات المجمعة، مراجعة الكود | 10-50 | < 200 |
| تنسيق هرمي | إعادة هيكلة كود متعدد الوحدات | 50-150 | 500-1500 |
| تعاون عميق | خط أنابيب الوكلاء عبر المستودعات | 150-300 | 1500-4000 |
مثال على تنسيق وكيل بسيط
يوضح الكود التالي كيفية استخدام K2.6 لتنسيق 5 وكلاء فرعيين متوازيين لإكمال مهمة مراجعة الكود:
from openai import OpenAI
import asyncio
import json
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
async def review_module(module_name: str, code: str) -> dict:
"""وكيل فرعي لمراجعة وحدة واحدة"""
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "system", "content": "أنت خبير في مراجعة الكود، تهتم بالأمان والأداء."},
{"role": "user", "content": f"راجع الوحدة {module_name}:\n{code}"}
],
temperature=0.2
)
return {
"module": module_name,
"review": response.choices[0].message.content
}
async def parallel_review(modules: dict) -> list:
"""تنسيق متوازٍ لوكلاء فرعيين متعددين"""
tasks = [review_module(name, code) for name, code in modules.items()]
return await asyncio.gather(*tasks)
# المسار الرئيسي: تنسيق 5 وكلاء فرعيين لمراجعة 5 وحدات
modules = {
"auth.py": "...",
"database.py": "...",
"api_routes.py": "...",
"cache.py": "...",
"logger.py": "..."
}
results = asyncio.run(parallel_review(modules))
for r in results:
print(f"[{r['module']}] {r['review'][:100]}...")
أفضل الممارسات لـ Agent Swarm
- التحكم في دقة المهام: يعالج الوكيل الفرعي الواحد 5 آلاف إلى 20 ألف رمز؛ الحجم الأكبر يسبب تكاليف تنسيق إضافية.
- عزل الأخطاء: استخدم
try/exceptلكل وكيل فرعي بشكل مستقل لتجنب انهيار النظام بالكامل. - تجميع النتائج: تعيين "وكيل رئيسي" لجمع نتائج الوكلاء الفرعيين والتحقق منها.
- إدارة المهلة الزمنية: مهلة الوكيل الفرعي الواحد 60-120 ثانية، والوكيل الرئيسي 10-30 دقيقة.
- التحكم في المعدل: تقييد أقصى تزامن عبر الإشارات (Semaphores) لتجنب تجاوز حد الـ API.
تطبيق نافذة السياق الطويلة (256K)
نافذة السياق 256 ألف (262,144 رمز) هي الميزة الأساسية لـ K2.6. ما يعادل حوالي 400-500 ألف حرف صيني، مما يسمح باستيعاب قاعدة أكواد ضخمة أو كتاب تقني كامل دفعة واحدة.
الاستخدام النموذجي للسياق الطويل
import os
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
def load_repo_files(repo_path: str, extensions=(".py", ".ts", ".md")) -> str:
"""تحميل كافة الملفات ذات اللواحق المحددة داخل المستودع"""
contents = []
for root, _, files in os.walk(repo_path):
for f in files:
if f.endswith(extensions):
full_path = os.path.join(root, f)
with open(full_path, "r", encoding="utf-8") as fp:
contents.append(f"## {full_path}\n```\n{fp.read()}\n```")
return "\n\n".join(contents)
repo_text = load_repo_files("./my_project")
print(f"تقدير الرموز الكلي للمستودع: {len(repo_text) // 2}")
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "system", "content": "أنت مهندس معماري خبير، تجيد تحليل قواعد الأكواد الضخمة."},
{"role": "user", "content": f"حلل بنية المشروع التالي، وقدم اقتراحات لإعادة الهيكلة:\n{repo_text}"}
],
temperature=0.3,
max_tokens=8192
)
print(response.choices[0].message.content)
المفاضلة بين التكلفة والأداء للسياق الطويل
| حجم المدخلات | التكلفة التقديرية/المرة | تأخير الرمز الأول | سيناريو الاستخدام |
|---|---|---|---|
| 8K | $0.005 | 1-2 ثانية | تحليل ملف واحد |
| 32K | $0.019 | 3-5 ثانية | مراجعة مستوى الوحدة |
| 100K | $0.06 | 8-15 ثانية | تحليل مستودع متوسط |
| 200K | $0.12 | 18-30 ثانية | مستودع ضخم / كتاب كامل |
| 256K (كامل) | $0.154 | 25-40 ثانية | سيناريو المستندات الطويلة جداً |
🎯 نصائح تحسين المستندات الطويلة: يُنصح في سيناريوهات السياق الطويل بتقسيم الموجه النظامي (system prompt) إلى "تعليمات ثابتة + مستندات ديناميكية". بعد تطابق الجزء الثابت في التخزين المؤقت للبادئة، يتم حساب تكلفة الاستدعاءات اللاحقة بناءً على الأجزاء المتغيرة فقط، مما يقلل التكلفة الإجمالية بمقدار 40%-60% في سيناريوهات RAG.
استدعاء الوسائط المتعددة (البصري)
يحتوي K2.6 على مشفر بصري MoonViT بقدرة 400 مليون معامل، ويدعم أصلياً إدخال الصور ومقاطع الفيديو. واجهة الوسائط المتعددة متوافقة أيضاً مع بروتوكول OpenAI:
from openai import OpenAI
import base64
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
def encode_image(image_path: str) -> str:
with open(image_path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
image_b64 = encode_image("./architecture_diagram.png")
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "حلل مخطط البنية هذا، وحدد نقاط الفشل المحتملة"},
{
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{image_b64}"}
}
]
}
],
max_tokens=2048
)
print(response.choices[0].message.content)
سيناريوهات استخدام الوسائط المتعددة:
- تحليل مخططات البنية/سير العمل واقتراح تعديلات عليها
- مراجعة تصميمات واجهة المستخدم (UI) وتوليد الكود
- فهم لقطات الشاشة للمستندات التقنية
- استخراج محتوى الرسوم البيانية للبيانات
- التعرف البصري لمراقبة الجودة الصناعية
ترحيل Kimi K2.6 API وتحسين الأداء
إذا كان مشروعك يستخدم حالياً OpenAI، أو K2.5، أو نماذج من شركات أخرى، فإن الانتقال إلى K2.6 يتطلب عادةً تعديل 3-5 أسطر من الكود فقط. بالإضافة إلى ذلك، يمكن لاستراتيجيات التزامن والتخزين المؤقت المعقولة أن تضاعف من المزايا التكلفية لـ K2.6.
الترحيل من سلسلة OpenAI GPT
# الكود الأصلي (OpenAI)
client = OpenAI(api_key="OPENAI_KEY")
response = client.chat.completions.create(
model="gpt-5.4",
messages=[...]
)
# الترحيل إلى K2.6 (تعديل base_url و model فقط)
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[...]
)
الترحيل من Kimi K2 / K2.5
تختلف معرفات النماذج في سلسلة K2، لكن بروتوكول API متطابق تماماً:
| معرف النموذج القديم | معرف النموذج الجديد | تاريخ الإيقاف المخطط له |
|---|---|---|
kimi-k2 |
kimi-k2.6 |
2026-05-25 |
kimi-k2.5 |
kimi-k2.6 |
مدعوم حالياً ولكن يُنصح بالترقية |
moonshot-v1-128k |
kimi-k2.6 |
خلال عام 2026 |
فحص التوافق قبل الترحيل
يُنصح بالتحقق من النقاط التالية قبل الترحيل:
- الحد الأقصى لـ max_tokens: يمكن لـ K2.6 إنتاج ما يصل إلى 98 ألف رمز في المرة الواحدة؛ إذا كان كودك يحتوي على حد ثابت عند 8K، يمكنك رفعه.
- نطاق temperature: يوصى بضبطه بين 0.1 و 0.7 لـ K2.6، حيث أن القيم العالية جداً قد تؤثر على جودة الكود.
- stop sequences: يدعم K2.6 رموز إيقاف مخصصة، تماماً مثل OpenAI.
- سلوك tool_choice: يميل وضع
autoفي K2.6 إلى استدعاء الأدوات بشكل أكبر، إذا كنت تفضل نهجاً متحفظاً، يمكنك تغييره إلىnoneأو تحديده بوضوح. - بروتوكول البث (Streaming): تنسيق SSE متطابق تماماً، ولا يتطلب كود الواجهة الأمامية أي تغييرات.
أفضل الممارسات لتحسين الأداء
تحسين سرعة الاستدعاء
| عنصر التحسين | طريقة التنفيذ | التحسن المتوقع |
|---|---|---|
| الطلبات المتزامنة | استخدام AsyncOpenAI + asyncio.gather | زيادة الإنتاجية 3-10 أضعاف |
| المخرجات المتدفقة | تفعيل stream=True | تقليل زمن الاستجابة الأولي بنسبة 70% |
| التخزين المؤقت للبادئة | تثبيت system prompt | خفض تكاليف الإدخال بنسبة 75% |
| ضبط max_tokens | تحديد سقف بناءً على المهمة | تقليل زمن الاستجابة للمهمة بـ 30% |
| التحكم في الحرارة | تعيين temp=0.2 لمهام الكود | مخرجات أكثر استقراراً |
توصيات معالجة الأخطاء
from openai import OpenAI, APIError, RateLimitError, APITimeoutError
import time
def call_with_retry(prompt: str, max_retries: int = 3):
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
timeout=120.0
)
for attempt in range(max_retries):
try:
return client.chat.completions.create(
model="kimi-k2.6",
messages=[{"role": "user", "content": prompt}]
)
except RateLimitError:
wait = 2 ** attempt
print(f"تم تجاوز حد المعدل، انتظار {wait} ثانية لإعادة المحاولة")
time.sleep(wait)
except APITimeoutError:
print(f"انتهت المهلة، إعادة المحاولة للمرة {attempt+1}")
except APIError as e:
print(f"خطأ API: {e}")
if attempt == max_retries - 1:
raise
raise Exception("تم الوصول إلى الحد الأقصى من المحاولات")
ميزات سعر Kimi K2.6 واختيار السيناريوهات
السعر هو عامل لا يمكن تجاهله عند اختيار النموذج. يوضح الجدول التالي مقارنة لأسعار Kimi K2.6 المعلنة عبر قنوات مختلفة (الوحدة: لكل 1 مليون رمز):
| قناة الاستدعاء | سعر الإدخال | سعر الإخراج | ملاحظات |
|---|---|---|---|
| منصة Kimi الرسمية | ¥6.5 (~$0.95) | ¥27 (~$4.00) | الفوترة الرسمية المحلية |
| APIYI (وكيل Huawei Cloud) | $0.60 | $2.40 | حوالي 60% من السعر الرسمي |
| OpenRouter (Parasail) | $0.60 | $2.40+ | قناة غير رسمية |
| GPT-5.4 (مرجع) | $2.50 | $15.00 | أغلى من K2.6 بـ 4-6 أضعاف |
| Claude Opus 4.6 (مرجع) | $15.00 | $75.00 | أغلى من K2.6 بأكثر من 25 ضعف |
تقدير التكلفة الفعلية
بأخذ سيناريو مساعد البرمجة اليومي كمثال (بافتراض جلسة واحدة: 5 آلاف رمز إدخال / 2 ألف رمز إخراج)، وبمعدل 100 ألف استدعاء شهرياً:
| النموذج | تكلفة الإدخال الشهرية | تكلفة الإخراج الشهرية | التكلفة الإجمالية |
|---|---|---|---|
| Kimi K2.6 (APIYI) | $300 | $480 | $780 |
| GPT-5.4 | $1,250 | $3,000 | $4,250 |
| Claude Opus 4.6 | $7,500 | $15,000 | $22,500 |
الخلاصة: في سيناريوهات البرمجة، والوكلاء (Agents)، والسياق الطويل، يمتلك K2.6 أداءً يضاهي GPT-5.4 و Claude Opus 4.6، لكن بتكلفة تتراوح بين 1/5 و 1/30 من تكلفتهما. هذا الخيار مناسب جداً للفرق الصغيرة والمطورين الأفراد.
🎯 نصيحة اختيار النموذج: يعتمد اختيار النموذج على سيناريوهات تطبيقك ومتطلبات الجودة. نوصي بإجراء اختبارات فعلية عبر منصة APIYI (apiyi.com) لاتخاذ القرار الأنسب. تدعم المنصة واجهة موحدة لاستدعاء عدة نماذج مثل Kimi K2.6، وGPT-5.4، وClaude Opus 4.6، مما يسهل المقارنة والتبديل السريع بينها.
توصيات سيناريوهات التطبيق
تختلف كفاءة K2.6 باختلاف سيناريوهات العمل. يقدم الجدول التالي توصيات واضحة للاختيار:
| سيناريو التطبيق | درجة التوصية | السبب |
|---|---|---|
| صيانة الكود وإعادة الهيكلة | ⭐⭐⭐⭐⭐ | الأول في SWE-Bench Pro، وسعة 256K تتسع للمستودعات الكبيرة |
| تنسيق الوكلاء (Agent) | ⭐⭐⭐⭐⭐ | 300 وكيل فرعي / 4000 خطوة، يدعم مسارات التطوير المعقدة |
| تحليل المستندات الطويلة | ⭐⭐⭐⭐⭐ | سياق 256K مع تحسين MLA، تكلفة متحكم بها للمستندات الطويلة |
| الفهم متعدد الوسائط | ⭐⭐⭐⭐ | محرك MoonViT أصلي، يدعم إدخال الصور والفيديو جاهزاً |
| خدمة العملاء والحوار | ⭐⭐⭐⭐ | استدعاء دالة (Function Call) ممتاز، التخزين المؤقت يقلل التكلفة |
| الاستدلال الرياضي البحت | ⭐⭐⭐ | حقق 96.4 نقطة في AIME، لكن GPT-5.4 أقوى |
| الكتابة الإبداعية | ⭐⭐⭐ | تعبيرات طبيعية باللغة الصينية، لكنه أقل قليلاً من Claude في المهام الأسلوبية |

الأسئلة الشائعة
س1: ما هي الاختلافات الرئيسية بين Kimi K2.6 API ونسختي K2.5 / K2؟
شهد نموذج K2.6 ترقيات جوهرية في ثلاثة جوانب: 1) قفز أداؤه في اختبار SWE-Bench Pro من 53 نقطة في K2.5 إلى 58.6، متفوقاً لأول مرة على GPT-5.4 وClaude Opus 4.6؛ 2) زيادة عدد الوكلاء الفرعيين (Agent Swarm) من 100 إلى 300، وخطوات التنسيق من 1500 إلى 4000؛ 3) إتاحة نافذة سياق بحجم 256K لجميع إصدارات السلسلة (بينما كانت بعض متغيرات K2 السابقة تدعم 128K فقط). تشير إعلانات Kimi الرسمية إلى إيقاف دعم إصدارات K2 القديمة في 25 مايو 2026، لذا ينبغي للمشاريع الجديدة البدء مباشرة بـ K2.6، والذي يحمل معرف النموذج kimi-k2.6 وهو متوافق تماماً مع حزمة تطوير برمجيات (SDK) الخاصة بـ OpenAI.
س2: هل Kimi K2.6 API متوافق تماماً مع OpenAI SDK؟
نعم. عند استدعاء K2.6 عبر قنوات مثل APIYI، يكون بروتوكول API متوافقاً تماماً مع واجهة chat completions الخاصة بـ OpenAI، بما في ذلك البث (streaming)، الأدوات (Function Call)، وبارامترات مثل tool_choice وtemperature وtop_p وmax_tokens. يمكن للمطورين باستخدام SDK للغات مثل Python أو Node.js أو Go التبديل ببساطة عن طريق تعديل معاملي base_url و model. لاحظ أن الحد الأقصى للمخرجات في K2.6 يصل إلى 98,304 رمز (token)، وهو أعلى بكثير من سعة 16K الخاصة بـ GPT-5.
س3: كيف هي مستويات التأخير (latency) والتكلفة عند استخدام نافذة السياق 256K في K2.6؟
قام K2.6 بتحسين حجم ذاكرة التخزين المؤقت (KV cache) للسياقات الطويلة بشكل ملحوظ باستخدام تقنية Multi-head Latent Attention (MLA). تظهر الاختبارات العملية عند مدخلات بحجم 100K أن تأخير الرمز الأول يبلغ حوالي 8-15 ثانية (اعتماداً على حمل الخادم)، تليها استجابة تدفقية للرموز التالية. من حيث التكلفة، فإن مدخلات 256K تكلف حوالي 0.15 دولار لكل عملية (بسعر 0.60 دولار لكل مليون رمز). وفي حال المحادثات المتعددة التي تستخدم نفس موجه النظام (system prompt)، تنخفض تكلفة المدخلات بنحو 25% بعد تحقيق التخزين المؤقت للبادئة (prefix cache hit). نوصي بإجراء اختبارات عملية على موجهاتك النموذجية قبل الإنتاج لمراقبة استهلاك الرموز وتحسين التكاليف.
س4: ما الفرق بين استدعاء الأدوات (Function Call) في K2.6 مقارنة بـ GPT-5 / Claude؟
الواجهة البرمجية متطابقة تماماً (بروتوكول الأدوات بأسلوب OpenAI)، لكن القدرات الداخلية تختلف: 1) يدعم K2.6 300 وكيل فرعي متزامن، مما يمنحه ميزة أصيلة في تنسيق الأدوات المتعددة بالتوازي؛ 2) يصنف K2.6 ضمن الفئة الأولى في لوحة صدارة Berkeley Function-Calling، وهو يقترب من مستوى أداء GPT-5؛ 3) يدعم K2.6 تكملة البادئة (Partial Mode)، والتي يمكنها فرض تنسيق مخرجات JSON، مما يقلل من معدلات فشل استدعاء الأدوات. بالنسبة لخطوط أنابيب الوكيل (Agent) المعقدة، يعتبر K2.6 الخيار الأفضل من حيث التكلفة مقابل الأداء.
س5: هل الاستدعاء عبر APIYI معتمد رسمياً؟ وهل أمن البيانات مضمون؟
يتم الوصول إلى نموذج Kimi الرسمي عبر قناة التحويل الرسمية من Huawei Cloud، مما يجعله قناة معتمدة ومتوافقة، حيث تكون أوزان النموذج ونتائج الاستدلال مطابقة للنسخة الرسمية. يتم تشفير نقل البيانات باستخدام HTTPS، ولا تحتفظ المنصة بمحتوى الطلبات. بالنسبة للمستخدمين من الشركات، نوفر ميزات أمان تشمل حسابات فرعية مستقلة، وتحديد صلاحيات مفتاح API، وحدود الاستهلاك. إذا كانت لديك متطلبات صارمة لامتثال البيانات، يمكنك مراجعة سياساتنا بالتفصيل على صفحة الامتثال في apiyi.com.
س6: ما هي أنواع المشاريع المناسبة لـ K2.6؟ ومتى يجب اختيار GPT-5.4 أو Claude؟
سيناريوهات الأولوية لـ K2.6: مساعدي البرمجة، مهام SWE، الاسترجاع المعزز بالتوليد (RAG) طويل السياق، تنسيق سير عمل الوكيل، والمشاريع الصغيرة والمتوسطة الحساسة للتكلفة. سيناريوهات الأولوية لـ GPT-5.4: مسابقات الرياضيات عالية الصعوبة (AIME/HMMT)، والمهام البحثية التي تتطلب عمقاً استدلالياً فائقاً. سيناريوهات الأولوية لـ Claude Opus 4.6: الكتابة الإبداعية الطويلة، وتوليد العقود/الوثائق القانونية التي تتطلب التزاماً صارماً بالتنسيق. ننصح بالاحتفاظ بتصميم واجهة برمجة تطبيقات يتيح التبديل بين النماذج، وإجراء اختبارات مقارنة للمهام المحددة قبل تحديد النموذج الإنتاجي.
ملخص
يعد Kimi K2.6 علامة فارقة في عالم نموذج اللغة الكبير مفتوح المصدر لعام 2026، حيث أثبت أن معمارية MoE ذات المائة مليار بارامتر يمكنها المنافسة بجدية مع النماذج الرائدة مغلقة المصدر في مجالات البرمجة، والوكلاء (Agents)، والسياق الطويل. بفضل نتيجته البالغة 58.6 في اختبار SWE-Bench Pro، وقدراته الهندسية التي تدعم 256K من السياق و300 وكيل فرعي، أصبح النموذج المفضل لمساعدي البرمجة ومشاريع أتمتة البحث والتطوير.
مراجعة النقاط الأساسية:
- ميزة المعمارية: 1T MoE / 32B للتفعيل، قدرات تعادل المائة مليار بارامتر مع تكلفة استدلال 32B.
- الريادة في المعايير: المركز الأول في ثلاثة اختبارات: SWE-Bench Pro / Terminal-Bench 2.0 / HLE.
- ميزة السعر: عبر قناة APIYI بتكلفة 0.60 دولار / 2.40 دولار، أي حوالي 60% من السعر الرسمي.
- دعم بيئي متميز: متوافق تماماً مع OpenAI SDK، مما يتيح الترحيل في غضون 5 دقائق.
- القدرات الهندسية: سياق 256K + 300 وكيل فرعي + ذاكرة تخزين مؤقت للبادئة.
بالنسبة للفرق التي تتطلع إلى بناء منتجات الذكاء الاصطناعي في عام 2026، يعد Kimi K2.6 API خياراً تنافسياً للغاية من حيث الأداء والتكلفة والبيئة. نوصي بالتحقق السريع من النتائج عبر منصة APIYI apiyi.com، ومقارنة أداء النماذج المختلفة في سيناريوهات عملك لاتخاذ القرار الأمثل.
المؤلف: فريق تقنية APIYI | نتابع باستمرار ديناميكيات نموذج اللغة الكبير، ونرحب بالتواصل التقني واستشارات الحلول عبر APIYI apiyi.com.