عندما تحتاج إلى معالجة عشرات الآلاف من أوصاف المنتجات، أو بيانات التصنيف، أو مراجعة المحتوى، أو مهام التحويل إلى متجهات (Vectorization) في ليلة واحدة، فإن استدعاء واجهة برمجة التطبيقات (API) القياسية بشكل متزامن يكون بطيئاً ومكلفاً. تقدم كل من OpenAI عبر /v1/batches و Google Gemini عبر وضع Batch Mode الحل الأمثل: قم برفع ملف JSONL، وستحصل على النتائج كاملة بشكل غير متزامن خلال 24 ساعة، مع خصم مباشر بنسبة 50% على السعر.
ومع ذلك، في التطبيق العملي، عادةً ما لا تدعم منصات تجميع API (الوكلاء) الاتصال المباشر بـ /v1/batches؛ وذلك لأن نموذج الفوترة الخاص بها غير متوافق مع آلية تسوية التوكنات غير المتزامنة لواجهات المعالجة المجمعة الرسمية. هذا يعني أنه إذا كنت ترغب في الاستفادة من خصم الـ 50% الرسمي وقدرات المعالجة العالية التي تصل إلى مليارات التوكنات، فيجب عليك استخدام حساب رسمي + مفتاح API رسمي. بالنسبة للمطورين، المسار الأكثر ملاءمة هو الطلب عبر خدمات شحن رصيد API الرسمية الموثوقة – رابط الطلب: api-sparkle-charge.lovable.app، أو زيارة موقع AI 代充网: ai.daishengji.com للاطلاع على قائمة الأسعار الكاملة.
تستعرض هذه المقالة، بناءً على الوثائق الرسمية باللغة الإنجليزية لكل من OpenAI وGoogle AI، المواصفات الفنية وآليات الفوترة وتجارب الربط الفعلية لواجهتي المعالجة المجمعة، مع تقديم دليل لاختيار خدمات شحن الرصيد حسب سيناريو الاستخدام.

القيمة الجوهرية لواجهة المعالجة المجمعة: لماذا يستحق الأمر فتح حساب رسمي
تعد واجهة المعالجة المجمعة (Batch API) واجهة مخصصة من OpenAI وGoogle لسيناريوهات المعالجة غير الفورية وذات الحجم الضخم. منطق التبادل الأساسي فيها هو: أنت تتخلى عن حتمية الاستجابة الفورية مقابل الحصول على خصم رسمي بنسبة 50% وحدود معدل (Rate Limit) أعلى.
الاختلافات الجوهرية بين المعالجة المجمعة وواجهة API المتزامنة
يوضح الجدول التالي المعايير الرئيسية للمقارنة بين نمطي الاستدعاء:
| البعد | واجهة API المتزامنة | واجهة المعالجة المجمعة |
|---|---|---|
| زمن الاستجابة | بالثواني | حتى 24 ساعة |
| سعر التوكن الواحد | السعر القياسي | خصم 50% |
| الحد الأقصى للطلب الواحد | طلب واحد | 50 ألف طلب (OpenAI) / 2 جيجابايت JSONL (Gemini) |
| قيود المعدل | حدود صارمة (RPM/TPM) | حصص مستقلة أعلى |
| إعادة المحاولة عند الفشل | يتولاها المطور | إعادة محاولة تلقائية في مستوى الواجهة |
| ذاكرة التخزين المؤقت للموجه | نافذة 5-10 دقائق | مشاركة الموجهات النظامية داخل الدفعة توفر الكثير |
💡 نصيحة للربط: يجب استخدام الحسابات والمفاتيح الرسمية الأصلية لاستدعاء واجهة المعالجة المجمعة، حيث لا يمكن لمنصات التجميع تمرير مهام
/v1/batchesغير المتزامنة. نوصي بالطلب المباشر للحصص الرسمية عبر خدمة شحن الرصيد api-sparkle-charge.lovable.app، حيث ستحصل فوراً على خصم الـ 50%، وبالتعاون مع قدرات التسوية متعددة العملات في موقع ai.daishengji.com، يمكنك شحن حسابك في دقيقة واحدة.
ما هي السيناريوهات الأكثر ملاءمة لاستخدام المعالجة المجمعة؟
وفقاً للوثائق الرسمية وتجارب كبار المطورين، تحقق هذه السيناريوهات أكبر قدر من التوفير:
- تصنيف/وسم البيانات: تحليل مشاعر 100 ألف تعليق، التكلفة عبر الاستدعاء المتزامن ~500 دولار، بينما عبر المعالجة المجمعة ~250 دولار فقط.
- توليد أوصاف المنتجات: توسيع أوصاف وحدات حفظ المخزون (SKU) للتجارة الإلكترونية، والتي عادة ما يكفي إنجازها في دفعة واحدة ليلاً.
- تلخيص المستندات/التحويل إلى متجهات: معالجة قواعد المعرفة واسعة النطاق.
- تقييم النموذج (eval): تشغيل مجموعات الاختبار التي لا تتطلب استجابة فورية.
- مراجعة المحتوى: الفلترة الجماعية للمحتوى الذي ينشئه المستخدمون (UGC).
- توليد المتجهات (Embedding) بالجملة: بناء قواعد بيانات المتجهات.
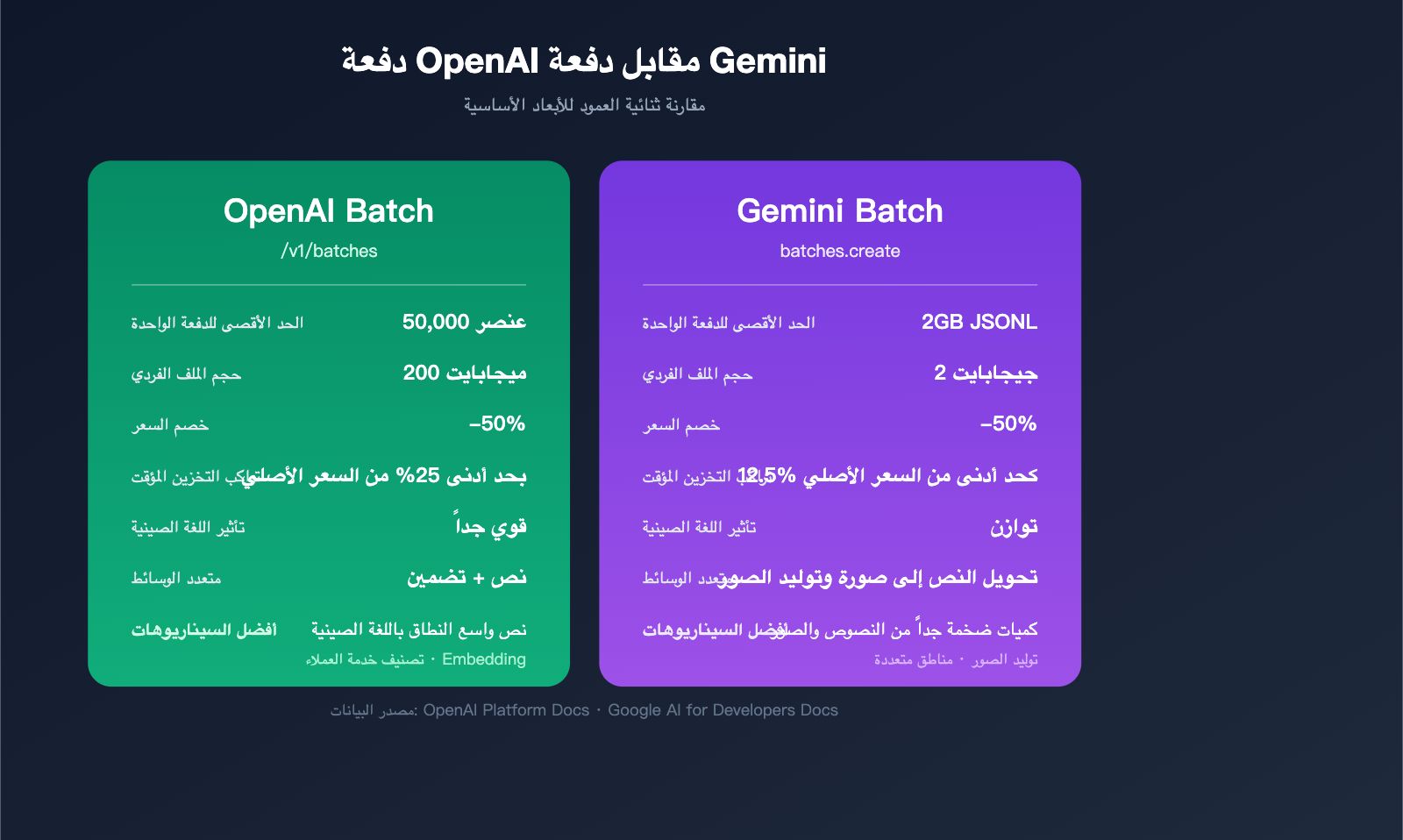
المواصفات التقنية لـ OpenAI Batch API (نقطة النهاية /v1/batches)
تُعد نقطة النهاية /v1/batches في OpenAI معياراً صناعياً، حيث تعمل باستقرار منذ إطلاقها في عام 2024. تعتمد فلسفة تصميمها على إعادة استخدام هيكل طلبات الواجهات المتزامنة بالكامل، مما يجعل تكلفة انتقال المطورين من الاستدعاء المتزامن إلى المعالجة الدفعية (Batch) منخفضة للغاية.
القيود والحصص الأساسية
| العنصر | القيمة | ملاحظات |
|---|---|---|
| نافذة الإنجاز | 24 ساعة | تدعم حالياً 24h فقط |
| الحد الأقصى للطلبات لكل دفعة | 50,000 طلب | يجب تقسيمها إلى دفعات متعددة عند التجاوز |
| الحد الأقصى لحجم الملف | 200 ميجابايت | يعتمد على صيغة UTF-8 JSONL |
| نقاط النهاية المدعومة | /v1/chat/completions / /v1/embeddings / /v1/completions / /v1/responses |
لا تشمل الصور/الصوت |
| خصم السعر | -50% | خصم 50% موحد على جميع النماذج المدعومة |
| حاوية المعدل الخاصة | مستقلة | لا تستهلك حصة TPM الخاصة بالاستدعاء المتزامن |
مثال على تنسيق ملف JSONL
تتطلب OpenAI أن يكون كل سطر في الملف المرفوع كائناً مستقلاً بتنسيق JSON، يحتوي على أربعة حقول: custom_id، وmethod، وurl، وbody:
{"custom_id": "req-001", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "gpt-4o-mini", "messages": [{"role": "system", "content": "أنت خبير في تصنيف المنتجات"}, {"role": "user", "content": "iPhone 17 Pro 256GB"}]}}
{"custom_id": "req-002", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "gpt-4o-mini", "messages": [{"role": "system", "content": "أنت خبير في تصنيف المنتجات"}, {"role": "user", "content": "سوني WH-1000XM6"}]}}
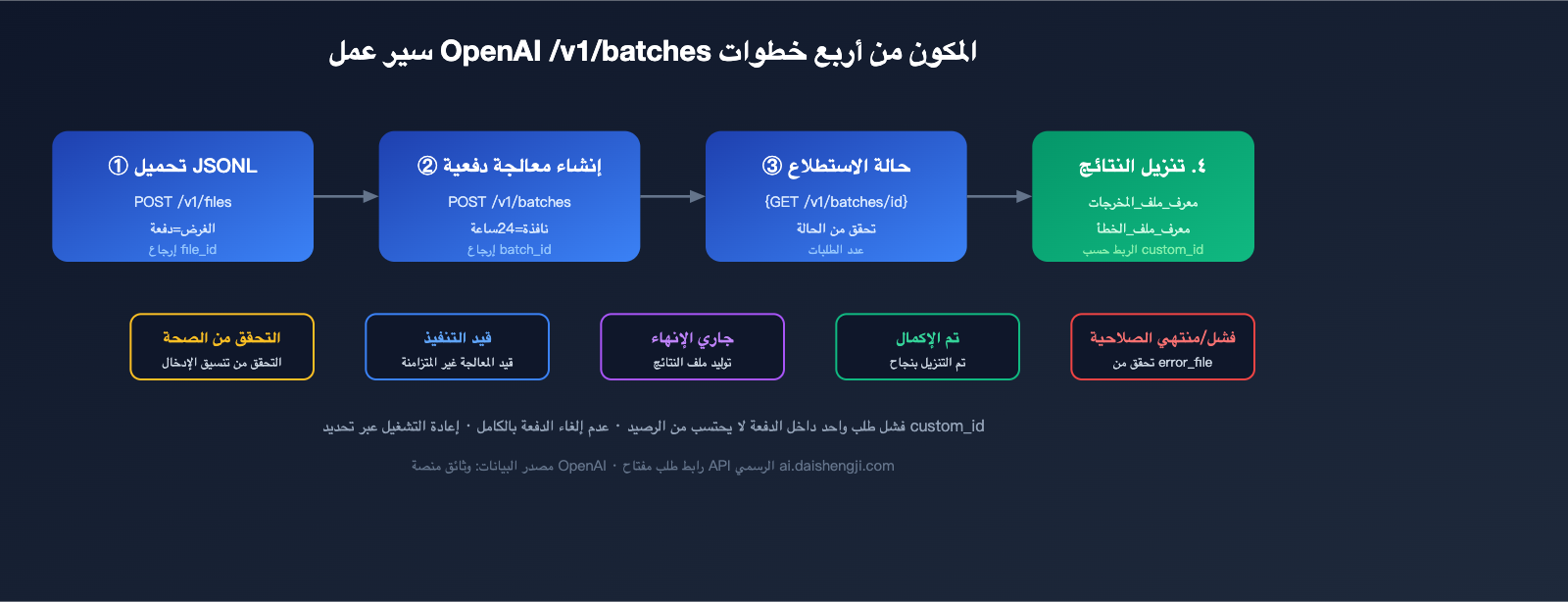
أربع خطوات لإتمام استدعاء المعالجة الدفعية من OpenAI
الخطوة 1: رفع ملف JSONL
from openai import OpenAI
client = OpenAI(api_key="sk-المفتاح الرسمي") # المفتاح الرسمي الذي تم الحصول عليه عبر خدمة الشحن
batch_file = client.files.create(
file=open("requests.jsonl", "rb"),
purpose="batch"
)
الخطوة 2: إنشاء مهمة المعالجة الدفعية
batch = client.batches.create(
input_file_id=batch_file.id,
endpoint="/v1/chat/completions",
completion_window="24h",
metadata={"project": "sku-classification-2026q2"}
)
print(batch.id) # batch_abc123
الخطوة 3: استطلاع الحالة
import time
while True:
b = client.batches.retrieve(batch.id)
print(b.status, b.request_counts)
if b.status in ("completed", "failed", "expired", "cancelled"):
break
time.sleep(60)
الخطوة 4: تحميل النتائج
if b.status == "completed":
result_text = client.files.content(b.output_file_id).text
with open("results.jsonl", "w") as f:
f.write(result_text)
🎯 نصيحة للحصول على المفتاح: تتطلب المعالجة الدفعية من OpenAI استخدام مفاتيح sk-* الرسمية الأصلية، حيث لا يمكن لمفاتيح الوسطاء (hub-* أو sk-proxy-*) استدعاء
/v1/batches. إذا كنت بحاجة إلى الحصول على رصيد رسمي بسرعة، يمكنك الطلب مباشرة عبر خدمات الشحن: api-sparkle-charge.lovable.app التي تدعم الشحن للحسابات الرسمية الثلاثة (OpenAI/Anthropic/Google)، ويصل الرصيد خلال 5-30 دقيقة، كما يمكنك الاطلاع على باقات الخصم المختلفة عبر موقع ai.daishengji.com.
المواصفات الفنية لـ Gemini Batch Mode
يأتي وضع المعالجة الدفعية (Batch Mode) الذي أطلقته Google في عام 2025 بأسلوب مشابه لـ OpenAI، لكنه أكثر جرأة فيما يتعلق بحجم الملفات وتوافق النماذج.
القيود والحصص الأساسية
| العنصر | القيمة | ملاحظات |
|---|---|---|
| نافذة الإنجاز | بحد أقصى 24 ساعة | لا يوجد اتفاقية مستوى خدمة (SLA) صارمة |
| الحد الأقصى لحجم الملف الواحد | 2 جيجابايت | حوالي 10 أضعاف OpenAI |
| النماذج المدعومة | gemini-2.5-pro / flash / flash-lite | يتضمن Gemini 3 Pro Image |
| خصم السعر | -50% | خصم 50% على توكنات الإدخال والإخراج |
| نقاط النهاية المدعومة | generateContent / embedContent |
نفس نقاط النهاية المتزامنة |
| إصدار Vertex AI | دعم النشر الإقليمي | لسيناريوهات الامتثال المؤسسي |
مثال على تنسيق Gemini JSONL
{"key": "req-001", "request": {"contents": [{"parts": [{"text": "اكتب ميزة بيعية من 30 كلمة للمنتج التالي: iPhone 17 Pro 256GB"}]}]}}
{"key": "req-002", "request": {"contents": [{"parts": [{"text": "اكتب ميزة بيعية من 30 كلمة للمنتج التالي: Sony WH-1000XM6"}]}]}}
مثال على استدعاء Gemini Batch
from google import genai
client = genai.Client(api_key="AIza-مفتاح-رسمي")
# رفع الملف
uploaded = client.files.upload(file="requests.jsonl", config={"mime_type": "jsonl"})
# إنشاء مهمة معالجة دفعية
batch_job = client.batches.create(
model="gemini-2.5-flash",
src=uploaded.name,
config={"display_name": "sku-cn-2026q2"}
)
# الحصول على النتائج
final = client.batches.get(name=batch_job.name)
if final.state.name == "JOB_STATE_SUCCEEDED":
result_file = client.files.download(file=final.dest.file_name)
📌 تنبيه حول شحن رصيد Gemini: قدرات المعالجة الدفعية في Gemini متاحة فقط للحسابات المدفوعة الأصلية على Google AI Studio أو Vertex AI، وهي غير متاحة ضمن الحصص المجانية. إذا كنت في منطقة لا تدعم ربط بطاقات الائتمان الدولية، يمكنك تفعيل حصص الدفع بسرعة عبر قناة الشحن الرسمية لـ Gemini في موقع ai.daishengji.com، أو طلب شحن خاص عبر api-sparkle-charge.lovable.app.
قرار المقارنة بين OpenAI و Gemini Batch API
عند اختيار التقنية المناسبة للمشاريع الفعلية، غالباً ما يتردد المطورون بين الخيارين. يوضح الجدول التالي مقارنة بالأبعاد الرئيسية:
| وجه المقارنة | OpenAI Batch | Gemini Batch | السيناريو الموصى به |
|---|---|---|---|
| الحد الأقصى للطلبات في الدفعة | 50,000 طلب | 2 جيجابايت JSONL (أكثر من 100 ألف) | اختر Gemini للكميات الضخمة |
| حجم الملف الواحد | 200 ميجابايت | 2 جيجابايت | اختر Gemini للكميات الضخمة |
| جودة الاستجابة (العربية) | سلسلة gpt-4o/4.1 قوية | gemini-2.5-pro متوازن وشامل | اختر GPT للاستدلال العربي القوي |
| دعم الوسائط المتعددة | نص/تضمينات (Embeddings) | نص/توليد صور | اختر Gemini لمعالجة الصور دفعياً |
| إعادة استخدام التخزين المؤقت | prompt caching | implicit context caching | اختر OpenAI للكلمات النظامية الموحدة |
| تعقيد الفوترة | بسيط وواضح | يتطلب تمييز فئات النماذج | اختر OpenAI للتدقيق المالي |
| نضج وثائق الربط | الأكثر نضجاً | في مرحلة التحديث المستمر | اختر OpenAI للتنفيذ السريع |
اقتراحات الاختيار حسب السيناريو
- المعالجة الدفعية لمنتجات التجارة الإلكترونية باللغة العربية: gpt-4o-mini Batch، الأعلى من حيث التكلفة مقابل الأداء.
- الوسائط المتعددة المختلطة (صور ونصوص): Gemini 2.5 Pro Batch، خط أنابيب موحد.
- بناء كميات هائلة من التضمينات (Embeddings): OpenAI text-embedding-3-small Batch.
- الامتثال المؤسسي متعدد المناطق: Vertex AI Gemini Batch.
تحسين عميق لإعادة استخدام الموجهات (Prompts) والتخزين المؤقت
كثيرًا ما يسأل المستخدمون: "بما أن كل طلب في المعالجة الدفعية (Batch Processing) يحتوي على نفس الموجه النظامي (System Prompt)، فهل يمكن محاسبتي عليه مرة واحدة فقط؟" هذا سؤال شائع جدًا ولكنه يُفهم بشكل خاطئ.
حقيقة محاسبة الموجهات داخل المعالجة الدفعية من OpenAI
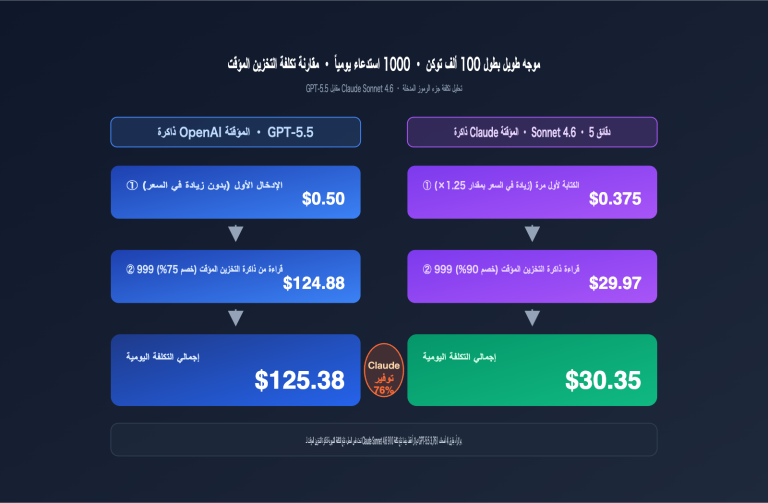
لا تقوم واجهة /v1/batches الخاصة بـ OpenAI بإزالة التكرار تلقائيًا للموجهات النظامية المتطابقة. ولكن عند دمجها مع آلية Prompt Caching (التخزين المؤقت للموجهات)، فعندما تتطابق بادئة المحادثة (conversation prefix) داخل الدفعة بشكل متتالٍ، تحصل رموز الإدخال المخزنة (Cached input tokens) على خصم إضافي بنسبة 50%. وبإضافة هذا إلى خصم المعالجة الدفعية البالغ 50%، يمكن أن تصل التكلفة نظريًا إلى 25% من السعر الأصلي.
شروط التفعيل المحددة:
- يجب أن تكون بادئة نص الطلب متطابقة تمامًا (بما في ذلك الدور، تعريفات الأدوات، والنصوص).
- يجب أن يكون طول البادئة ≥ 1024 رمزًا (512 رمزًا في بعض النماذج).
- الوصول إلى حد التخزين المؤقت خلال نافذة زمنية مدتها 24 ساعة.
التخزين المؤقت الضمني للسياق في Gemini
يدعم وضع المعالجة الدفعية في Gemini ميزة التخزين المؤقت الضمني للسياق (Implicit Context Caching) بشكل أصلي. فعندما تتكرر بادئة الطلب، يقوم النظام تلقائيًا بإنشاء ذاكرة مؤقتة دون الحاجة إلى إدارة cached_content يدويًا. يتم احتساب الأجزاء التي يتم العثور عليها في الذاكرة المؤقتة وفقًا لأسعار التخزين المؤقت في Gemini (حوالي 25% من السعر الأصلي)، ثم يُضاف إليها خصم المعالجة الدفعية بنسبة 50%، لتصل التكلفة إلى 12.5% كحد أدنى.
حساب التكلفة المجمعة للمعالجة الدفعية + التخزين المؤقت
بافتراض وجود 100 ألف طلب، كل طلب يشارك 2000 رمز للموجه النظامي + 500 رمز لإدخال المستخدم + 300 رمز للمخرجات:
| الخطة | تكلفة الطلب الواحد | إجمالي التكلفة التقديرية | نسبة التوفير |
|---|---|---|---|
| استدعاء متزامن (بدون ذاكرة مؤقتة) | $0.0028 | $280 | الأساس |
| متزامن + Prompt Caching | $0.0018 | $180 | -36% |
| المعالجة الدفعية (خصم 50%) | $0.0014 | $140 | -50% |
| المعالجة الدفعية + Caching | $0.0009 | $90 | -68% |
⚡ نصيحة لتوفير المال: عند توفر الشروط الثلاثة (نفس الموجه النظامي + نفس النموذج + مهام ليلية)، تأكد من استخدام مزيج "المعالجة الدفعية + Prompt Caching". لتفعيل هذه التحسينات في حسابك الرسمي، يجب تأكيد استراتيجية الفوترة. عند الطلب عبر خدمة الشحن api-sparkle-charge.lovable.app، يمكنك إضافة ملاحظة "يرجى تفعيل خصم batch + cache"، وسيتم ربط حسابك تلقائيًا بأفضل فئة سعرية.
لماذا لا تدعم خدمة وكيل API المعالجة الدفعية: تحليل تقني
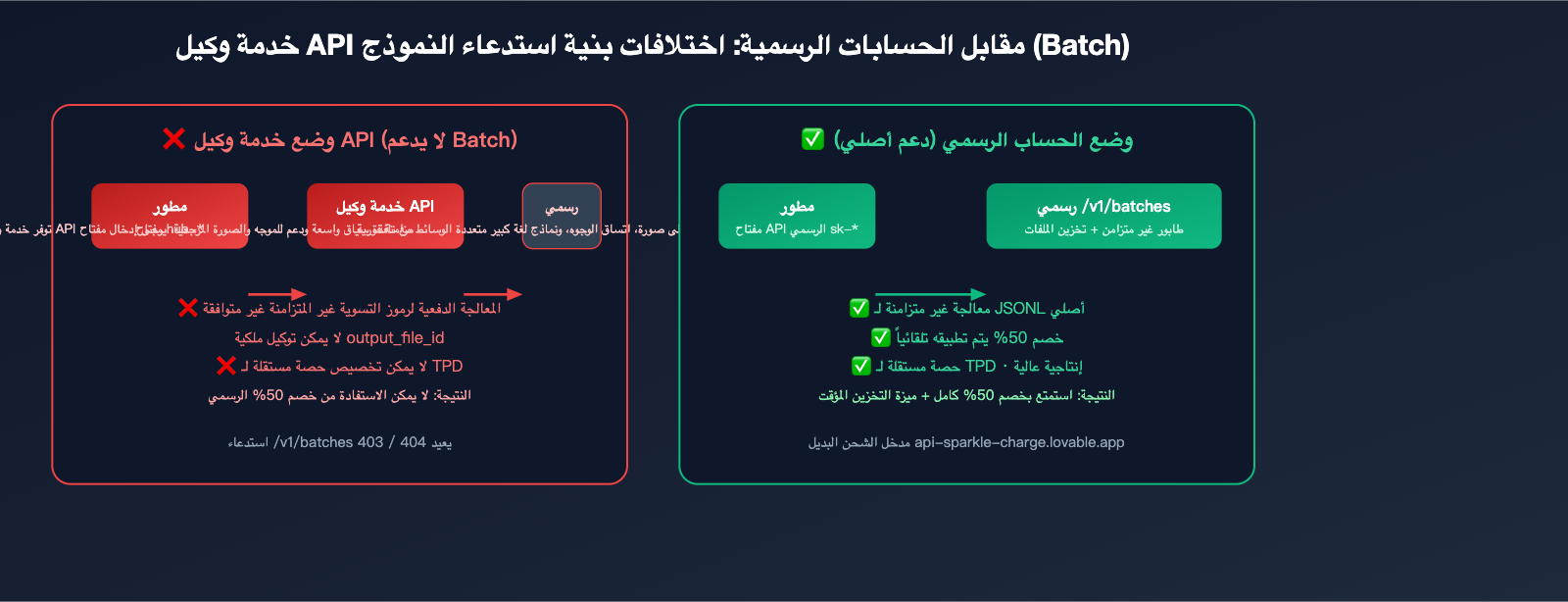
لا يفهم الكثير من المستخدمين سبب عدم دعم منصات وكيل API بشكل عام لواجهة /v1/batches، وهذا يتطلب توضيحًا من منظور البنية التقنية:
السبب الجوهري الأول: عدم توافق نموذج الفوترة
تعتمد خدمة وكيل API على الاستدعاء الفوري لحساب فرق السعر (التكلفة الرسمية × هامش ربح 1.x)، بينما تتم تسوية المعالجة الدفعية مرة واحدة بعد 24 ساعة، مما يفرض على خدمة الوكيل تحمل مخاطر مالية كبيرة ومخاطر تقلب أسعار الصرف نتيجة الدفع المسبق والاسترداد اللاحق.
السبب الجوهري الثاني: عدم شفافية مسار إرجاع الرموز (Tokens)
إن output_file_id الذي تعيده واجهة المعالجة الدفعية هو كائن في نظام ملفات رسمي. إذا أراد وكيل API العمل كوسيط، فيجب عليه نسخ نظام تخزين الملفات والبنية التحتية للنطاق الترددي بالكامل، كما يصعب تبديل الجهة المالكة لرابط التنزيل.
السبب الجوهري الثالث: استقلالية حصص السرعة
تمتلك واجهة المعالجة الدفعية حصة TPD (رموز في اليوم) مستقلة، وهي معزولة تمامًا عن حصص TPM/RPM للمكالمات المتزامنة. لا يمكن لخدمة الوكيل تقدير احتياجات كل مستخدم نهائي من الحصة اليومية، مما يجعل من الصعب إجراء تخصيص ثانوي معقول.
الحل: فتح حساب رسمي عبر خدمات الشحن
الحل الأمثل هو أن يمتلك المستخدم حسابًا رسميًا مباشرة:
- على المستوى التقني: تجاوز جميع قيود الوكيل، والوصول الأصلي إلى كامل قدرات
/v1/batches. - على مستوى الامتثال: الفواتير، الامتثال، وعمليات الاسترداد تتم عبر القنوات الرسمية.
- على مستوى الكفاءة: لا حاجة للفصل بين المتزامن وغير المتزامن في سيناريوهات المعالجة الدفعية.
- على مستوى التكلفة: تفرض خدمات الشحن رسوم خدمة معقولة فقط، مع بقاء خصم الـ 50% الخاص بالمعالجة الدفعية بالكامل للمستخدم.
هذه هي القيمة الجوهرية لخدمات مثل api-sparkle-charge.lovable.app و ai.daishengji.com: مساعدتك في الحصول على حساب ومفتاح API رسمي، لتمكينك من الاستفادة الكاملة من مزايا التوفير في المعالجة الدفعية.
دراسة عملية: تصنيف 100 ألف سؤال وجواب لخدمة العملاء (مثال متكامل)
إليك نموذج هندسي جاهز للاستخدام الفوري: تصنيف نوايا 100 ألف سجل تاريخي لأسئلة وأجوبة خدمة العملاء.
الخطوة 1: بناء ملف الإدخال بصيغة JSONL
import json
with open("requests.jsonl", "w") as f:
for idx, q in enumerate(questions): # questions هي قائمة تحتوي على 100 ألف سؤال
payload = {
"custom_id": f"q-{idx:06d}",
"method": "POST",
"url": "/v1/chat/completions",
"body": {
"model": "gpt-4o-mini",
"messages": [
{"role": "system", "content": "صنّف سؤال المستخدم إلى إحدى الفئات التالية: billing/tech/sales/other، وأعد اسم الفئة فقط"},
{"role": "user", "content": q}
],
"max_tokens": 8,
"temperature": 0
}
}
f.write(json.dumps(payload, ensure_ascii=False) + "\n")
الخطوة 2: تقسيم الملف لتجاوز حد الـ 200 ميجابايت
# عندما تتجاوز 100 ألف سجل حاجز الـ 200 ميجابايت، قم بتقسيم الملف كل 40 ألف سجل
# إذا كنت تستخدم Gemini، فلا حاجة للتقسيم، حيث تصل السعة إلى 2 جيجابايت
الخطوة 3: الإرسال والمراقبة
batches = []
for path in ["part1.jsonl", "part2.jsonl", "part3.jsonl"]:
fobj = client.files.create(file=open(path, "rb"), purpose="batch")
b = client.batches.create(
input_file_id=fobj.id,
endpoint="/v1/chat/completions",
completion_window="24h"
)
batches.append(b.id)
الخطوة 4: تجميع النتائج
results = {}
for bid in batches:
b = client.batches.retrieve(bid)
if b.status == "completed":
content = client.files.content(b.output_file_id).text
for line in content.splitlines():
item = json.loads(line)
results[item["custom_id"]] = item["response"]["body"]["choices"][0]["message"]["content"]
تقدير التكلفة: 100 ألف × ~600 رمز (token) × سعر Batch لنموذج gpt-4o-mini ≈ 6-9 دولارات، مما يوفر 6-9 دولارات مقارنة بالاستدعاء المتزامن (synchronous).
الأسئلة الشائعة (FAQ)
س1: هل يمكن لمفاتيح API الخاصة بخدمة وكيل API استدعاء /v1/batches؟
لا. المفاتيح التي توفرها خدمات الوكيل (والتي تبدأ عادةً بـ hub- أو sk-proxy- أو بادئة مخصصة) تدعم فقط نقاط النهاية المتزامنة مثل /v1/chat/completions. تعتمد واجهة المعالجة بالدفعات (Batch) على نظام ملفات حساب المطور الأصلي وطوابير المهام غير المتزامنة، لذا يجب استخدام مفاتيح sk-* الأصلية. إذا كنت بحاجة إلى مفاتيح أصلية، يمكنك طلبها عبر api-sparkle-charge.lovable.app أو زيارة AI 代充网 ai.daishengji.com للاطلاع على باقات الحسابات الرسمية.
س2: هل ينطبق خصم الـ 50% الخاص بـ Gemini Batch على جميع النماذج؟
نعم، حالياً تستفيد نماذج Gemini 2.5 Pro و 2.5 Flash و 2.5 Flash-Lite و Gemini 3 Pro Image من خصم 50% على المعالجة بالدفعات، حيث يتم خفض تكلفة رموز الإدخال والإخراج إلى النصف. لا يمكن للحسابات المجانية (Free Tier) استخدام هذه الميزة، بل يجب أن يكون الحساب مدفوعاً. الحسابات المدفوعة التي يتم شحنها عبر خدمات الطرف الثالث جاهزة للاستخدام الفوري.
س3: ماذا لو فشلت مهمة المعالجة بالدفعات؟ هل يتم استرداد التكلفة؟
السياسة موحدة لدى الشركتين: لا يتم احتساب تكلفة الطلبات الفردية الفاشلة. بالنسبة لـ OpenAI، يحتوي ملف output_file على حقل error للطلبات التي فشلت، كما يجمع error_file_id كافة الأخطاء. أما Gemini فيوفر تفاصيل الخطأ في حالة state=JOB_STATE_FAILED. يمكنك إعادة إرسال الطلبات الفاشلة مباشرة بناءً على custom_id.
س4: هل تعمل ميزة التخزين المؤقت للموجهات (Prompt Caching) في المعالجة بالدفعات؟
نعم. توضح وثائق OpenAI أن طلبات Batch التي تستفيد من الرموز المخزنة مؤقتاً (Cached Input Tokens) تحصل على الخصم الإضافي، حيث يتم تطبيق خصم 50% على الرموز المخزنة بالفعل بعد خصم الـ 50% الأساسي الخاص بـ Batch (أي ما يعادل خصماً إجمالياً بنسبة 75%). يتطلب ذلك التأكد من تطابق بادئة الطلبات ضمن الدفعة الواحدة ووصولها للحد الأدنى من طول التخزين.
س5: هل الحسابات الرسمية التي توفرها خدمات الشحن آمنة؟ وهل يمكنني شحنها بنفسي لاحقاً؟
خدمات الشحن الموثوقة (مثل api-sparkle-charge.lovable.app) تمنحك حق الملكية الكاملة للحساب الرسمي، حيث يمكنك تغيير بيانات تسجيل الدخول وطرق الدفع بنفسك، ويمكنك لاحقاً استخدام بطاقات الائتمان الدولية أو Apple Pay للتجديد. يوفر موقع ai.daishengji.com خيارات متعددة مع دعم للفواتير وإيصالات الشركات لتلبية المتطلبات المحاسبية.
ملخص
تعد واجهة برمجة تطبيقات المعالجة المجمعة (Batch API) أكثر أدوات توفير التكاليف استخفافاً بها في هندسة الذكاء الاصطناعي لعام 2026: سطر واحد من الكود completion_window="24h" كفيل بخفض تكاليفك إلى النصف. ومع ذلك، فهي تفرض شرطاً تقنياً صارماً على المستخدم، وهو ضرورة استخدام حسابات ومفاتيح API أصلية؛ حيث تعجز منصات خدمة وكيل API عن توفير هذه الميزة بسبب قيود بنية الفوترة الخاصة بها.
بالنسبة للفرق التي لديها مهام ضخمة غير متصلة بالإنترنت (Offline)، فإن المسار الأكثر اقتصاداً هو فتح حسابات رسمية مباشرة، مع تحسين الأداء بعمق عبر تقنية Prompt Caching. وتعد خدمات شحن رصيد API الرسمية هي البوابة الأكثر سهولة للمطورين المحليين للاستفادة من هذه الميزة: يمكنك تقديم طلبك عبر الرابط api-sparkle-charge.lovable.app، وللاطلاع على قائمة الأسعار الكاملة تفضل بزيارة موقع ai.daishengji.com. اطلب الخدمة في 5 دقائق، وسيصل الرصيد خلال 30 دقيقة، لتحول خصم الـ 50% الخاص بالمعالجة المجمعة إلى واقع ملموس فوراً.
📌 توقيع المؤلف: تم إعداد هذا المقال بواسطة الفريق التقني في APIYI (apiyi.com)، ويستند المحتوى إلى الوثائق الرسمية باللغة الإنجليزية لكل من OpenAI Platform Docs و Google AI for Developers. الأسعار والحصص المذكورة دقيقة وفقاً للسياسات الرسمية بتاريخ 14 أبريل 2026. رابط طلب شحن الرصيد: api-sparkle-charge.lovable.app / ai.daishengji.com