في أوائل أبريل 2026، ظهر نموذج فيديو غامض يعمل بالذكاء الاصطناعي يُدعى HappyHorse فجأة وبدون سابق إنذار على قائمة الاختبار الأعمى في منصة Artificial Analysis Video Arena. وبشكل متزامن تقريبًا، نجح الإصداران V1 وV2 في تحطيم أرقام Elo القياسية في فئتي "تحويل النص إلى فيديو" و"تحويل الصورة إلى فيديو"، متفوقين بذلك على عمالقة المجال مثل Seedance 2.0 وKling 3.0 وPixVerse V6. ومع ذلك، وبعد بضعة أيام فقط، اختفى HappyHorse 1.0 من القائمة تمامًا، ولم يترك خلفه سوى بضع لقطات شاشة وصفحة رسمية غامضة.
أثارت التكهنات حول نموذج HappyHorse ضجة واسعة في مجتمع الذكاء الاصطناعي الناطق بالإنجليزية: هل هو مجرد قناع لنموذج Wan 2.7؟ أم أنه الجيل القادم من تجارب فريق ByteDance Seedance؟ أم أنه ابتكار مفاجئ من مختبر آسيوي غير معروف؟ يستعرض هذا المقال، بناءً على المعلومات المتاحة والقابلة للتحقق، بنية HappyHorse 1.0، وأدائه، وحالة المصدر المفتوح الخاصة به، وأصوله المحتملة، لمساعدتك في تقييم ما إذا كان هذا "الحصان الأسود" يستحق الإضافة إلى حزمة أدوات توليد الفيديو الخاصة بك.
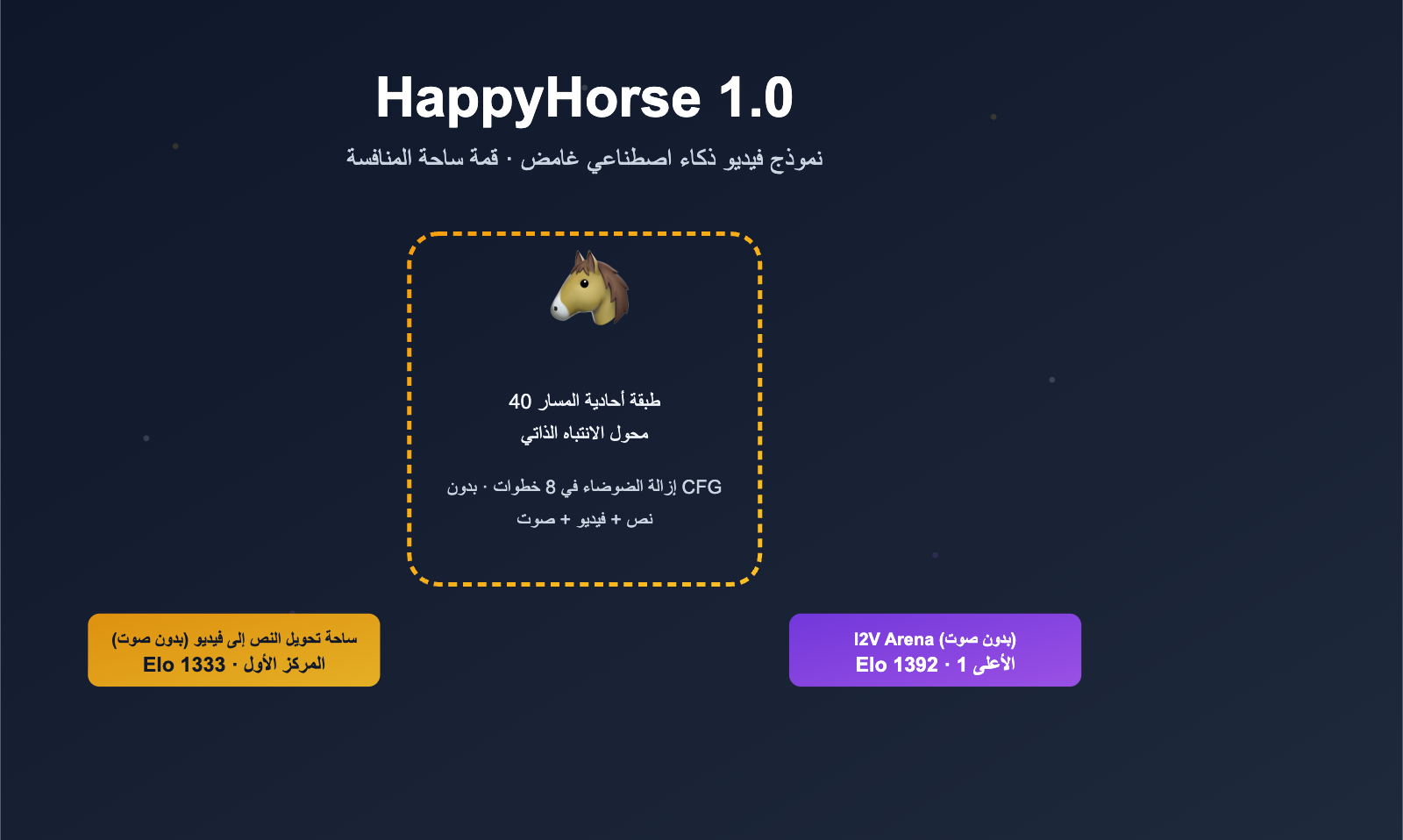
نظرة سريعة على المعلومات الأساسية لنموذج HappyHorse
قبل تفكيك التفاصيل التقنية، دعنا نلخص المعلومات المعروفة في جدول واحد ليسهل عليك استيعابها بسرعة.
| البعد | المعلومات المعروفة عن HappyHorse 1.0 |
|---|---|
| نوع النموذج | نموذج توليد فيديو من نص وصورة (توليد مشترك للصورة والصوت) |
| البنية | محول (Transformer) بـ 40 طبقة ذاتية الانتباه (Self-Attention) أحادية المسار، بدون انتباه متقاطع (Cross-Attention) |
| خطوات الاستدلال | يحتاج إلى 8 خطوات فقط لإزالة الضجيج، ولا يتطلب توجيهًا خاليًا من المصنف (CFG) |
| دعم اللغات | الصينية، الإنجليزية، اليابانية، الكورية، الألمانية، الفرنسية |
| الإصدارات | النموذج الأساسي / النموذج المقطر / نموذج الدقة الفائقة / كود الاستدلال (تزعم الشركة أنه مفتوح المصدر بالكامل) |
| مكان الظهور | Artificial Analysis Video Arena (تشير بعض المصادر أيضًا إلى مسار الفيديو في LMArena) |
| الحالة الحالية | اختفى الإصداران V1/V2 من القائمة العامة، الموقع الرسمي لا يزال متاحًا، لكن GitHub/Model Hub يشير إلى "قريبًا" |
| الأصل المشتبه به | من فريق آسيوي، وتتكهن المجتمعات بوجود صلة بنظام Wan 2.7 / Seedance، لكن لم يتم تأكيد ذلك رسميًا |
🎯 نصيحة للاختبار السريع: نظرًا لأن الأوزان الرسمية لـ نموذج HappyHorse لم تُفتح بعد على منصات الاستدلال الرئيسية، إذا كنت ترغب في مقارنة نماذج الفيديو من نفس الفئة (مثل Seedance 2.0 وKling 3.0 وVeo 3.1) في بيئة الإنتاج فورًا، نوصي باستخدام منصة وسيطة موحدة مثل APIYI (apiyi.com) لاستدعاء نماذج فيديو متعددة بالتوازي، مما يتيح لك التبديل بسلاسة فور إطلاق HappyHorse رسميًا وتجنب إعادة هندسة العمليات.
الجدول الزمني لظهور نموذج HappyHorse
لفهم سبب إحداث "الحصان السعيد" (HappyHorse) هذه الضجة الكبيرة في أوساط الذكاء الاصطناعي العالمية، نحتاج إلى إلقاء نظرة فاحصة على الجدول الزمني لأحداثه.
عام الحصان والمصادفة في التسمية
يصادف عام 2026 عام الحصان في التقويم الصيني، ومنذ بداية عيد الربيع في فبراير، تكرر ذكر وسائل الإعلام الأجنبية ومنصات مثل UX Tigers أن مجتمع الذكاء الاصطناعي الصيني يركز على سلسلة من الإصدارات المتعلقة بـ "الحصان". إن تسمية "HappyHorse" لا تتماشى فقط مع الأبراج الصينية، بل تشكل أيضًا ارتباطًا بسلسلة مع نموذج آخر ظهر في نفس الفترة يُختصر بـ "The Horse"، وهو أحد الأدلة الرئيسية التي جعلت المجتمع يستنتج على الفور أن هذا النموذج يأتي من فريق آسيوي.
الصعود والاختفاء على منصة Arena
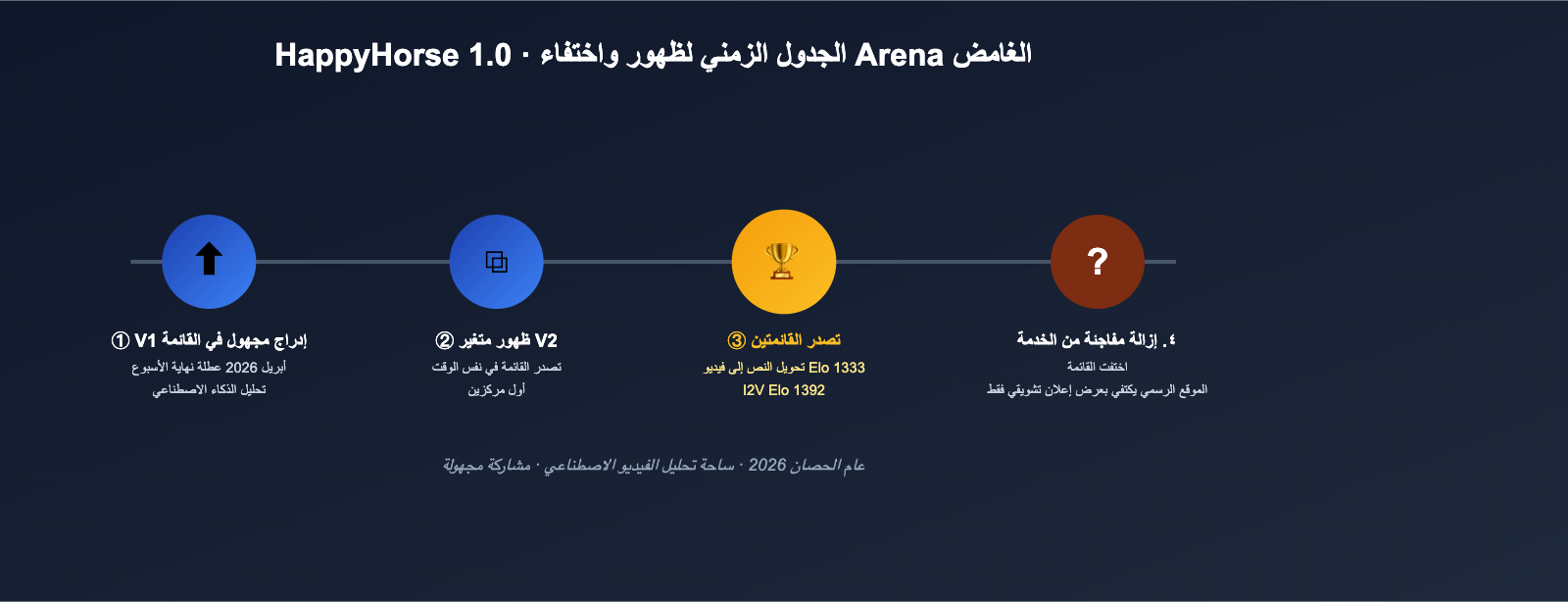
وفقًا للقطات الشاشة والتقارير اللاحقة التي نشرها مقيمو فيديوهات الذكاء الاصطناعي مثل Brent Lynch على منصة X (تويتر سابقًا) في أوائل أبريل، كان إيقاع ظهور HappyHorse 1.0 كالتالي:
- الظهور الأول: ظهر إصدار V1 كإدخال مجهول الهوية على منصة Artificial Analysis Video Arena، ووصل إلى المراكز الثلاثة الأولى في اختبارات تحويل النص إلى فيديو العمياء في غضون ساعات قليلة؛
- إطلاق الإصدار V2: ظهر متغير V2 في نفس الوقت تقريبًا، واحتل الإصداران لفترة وجيزة المركزين الأول والثاني في قائمة تحويل الصورة إلى فيديو؛
- تصدر القائمة: في المسارات التي لا تتضمن صوتًا، تفوق HappyHorse 1.0 على نماذج رائدة مثل Seedance 2.0 720p وKling 3.0 وPixVerse V6؛
- الاختفاء: في غضون أيام قليلة، تمت إزالة V1 وV2 من القائمة العامة، ولم يتبق سوى لقطات الشاشة والسجلات من أطراف ثالثة، بينما ظهرت لاحقًا ملاحظة على الصفحة الرسمية تفيد بأن "النموذج الأساسي سيصبح مفتوح المصدر قريبًا".
هذا النمط من "الظهور المفاجئ ← تصدر القائمة ← الإزالة الهادئة" يعني عادةً أحد أمرين: إما أن مختبرًا ما يجري اختبارات A/B مجهولة الهوية، أو أن الشركة المطورة للنموذج لا تزال تستعد للإطلاق الرسمي وقامت بسحبه طواعية بعد أن حظي باهتمام كبير قبل الأوان. كلا التفسيرين زادا من غموض نموذج HappyHorse.
تحليل بنية نموذج HappyHorse: كيف حقق Transformer أحادي المسار بـ 40 طبقة هذا النجاح؟
على الرغم من أن الورقة البحثية لم تُنشر رسميًا بعد، إلا أنه من خلال الأوصاف الموجودة على happyhorse-ai.com ومواقع النسخ المتطابقة happy-horse.net، يمكننا تجميع بعض خيارات التصميم الرئيسية لنموذج HappyHorse 1.0 على مستوى البنية.
الاعتماد على Self-Attention أحادي المسار بدلاً من الهياكل المعقدة متعددة المسارات
تستخدم نماذج توليد الفيديو التقليدية (خاصة النماذج متعددة الوسائط التي تعالج الصوت والنص والصورة في وقت واحد) عادةً بنية متعددة المسارات (multi-stream)، حيث يكون لكل من النص والفيديو والصوت مشفر (Encoder) خاص به، ثم تتفاعل فيما بينها عبر Cross-Attention. هذا الهيكل مرن ولكنه يهدر الكثير من المعلمات، ويتطلب نقل البيانات (Tensors) ذهابًا وإيابًا بين الفروع المتعددة أثناء الاستدلال.
قام HappyHorse 1.0 بتبسيط كل هذا في خط معالجة واحد: محول (Transformer) بـ 40 طبقة من نوع Self-Attention يعالج الرموز (Tokens) للنص والفيديو والصوت في وقت واحد، دون أي Cross-Attention بينها، ودون شبكات فرعية مصممة خصيصًا لنمط معين. يتم ترميز جميع الأنماط في تسلسل موحد من الرموز، وتتم نمذجتها مباشرة في نفس مساحة الانتباه. هذا التصميم له عدة مزايا من الناحية النظرية:
- كفاءة عالية في استخدام المعلمات: لا حاجة لمعلمات زائدة مخصصة لعزل الأنماط؛
- مسار استدلال قصير: لا يوجد نقل إضافي بين الأنماط، مما يجعل النواة (Kernel) أكثر استمرارية؛
- هدف تدريب موحد: تشترك النصوص والصور والأصوات في نفس مجموعة الخسائر (Loss)، مما يسهل عملية التحسين الشامل (End-to-End)؛
- دعم طبيعي للتزامن بين الصوت والفيديو: الصوت والصورة هما رموز في نفس التسلسل، مما يضمن التزامن تلقائيًا.
استدلال فائق بـ 8 خطوات إزالة ضجيج وبدون CFG
بالنسبة للمطورين الذين استخدموا نماذج مثل Stable Video Diffusion أو Sora أو Kling، أصبحت "عشرات الخطوات لإزالة الضجيج + التوجيه الخالي من المصنف (Classifier-Free Guidance)" بمثابة ذاكرة عضلية. لكن الوصف الرسمي لنموذج HappyHorse 1.0 جريء للغاية: يحتاج فقط إلى 8 خطوات لإزالة الضجيج، وبدون استخدام CFG، لإنتاج جودة صورة تتصدر حاليًا منصة Arena.
هذا يعني عادةً أن النموذج قد خضع لعمليات مثل تقطير الاتساق (Consistency Distillation) أو التدفق المصحح (Rectified Flow) أو التقطير التدريجي (Progressive Distillation) أثناء مرحلة التدريب، مما أدى إلى ضغط أخذ العينات متعدد الخطوات في بضع خطوات تنبؤ مباشرة. وبالاقتران مع "نموذج التقطير" و"نموذج رفع الدقة" اللذين أصدرتهما الشركة رسميًا، فإن حزمة الاستدلال بأكملها قريبة جدًا من هدف "سهولة التشغيل على الأجهزة الطرفية + الإنتاجية العالية على الخادم".
حجم المعلمات المحتمل ومتطلبات ذاكرة الفيديو (VRAM)
نظرًا لأن الأوزان لم تُنشر بعد، لا يمكن التحقق مباشرة من حجم معلمات نموذج HappyHorse. ولكن بالنظر إلى وصفه بأنه يحتوي على 40 طبقة، وبنية أحادية المسار، ودعم لـ 6 لغات، وأدائه على منصة Arena، فمن المعقول افتراض أن حجمه يقع في نفس فئة النماذج المفتوحة مثل Wan 2.x وSeedance 1.x وHunyuan Video، أي في نطاق 10B إلى 30B من المعلمات. وهذا يعني أن النشر المحلي الحقيقي يتطلب بطاقة احترافية ذات ذاكرة فيديو عالية، بينما لا يزال يتعين على مستخدمي بطاقات الرسوميات الاستهلاكية العادية انتظار إصدارات الكمية (Quantization) بنظام INT8/FP8.
🎯 نصيحة حول اختيار البنية: إذا كنت تقيم "البنية التحتية لتوليد الفيديو من الجيل التالي" لفريقك، فإننا نوصي بجعل نموذج HappyHorse 1.0 بنمطه "Transformer أحادي المسار + استدلال بعدد خطوات قليل جدًا" كهدف رئيسي للمراقبة؛ وقبل أن يصبح مفتوح المصدر بالكامل، يمكنك استخدام نماذج مثل Seedance وKling وVeo عبر خدمة وكيل API الخاص بـ APIYI على apiyi.com لإجراء الاختبارات الهندسية، وصقل الموجهات (Prompts) وسيناريوهات اللقطات وخطوات المعالجة اللاحقة، ثم الانتقال إلى HappyHorse بمجرد جاهزية أوزانه.
بيانات الأداء الفعلي لنموذج HappyHorse: كيف تصدر صدارة تصنيفات Arena؟
بعد الانتهاء من شرح البنية التقنية، تظل الأرقام هي الوسيلة الأقوى لإقناع فرق العمل الميدانية. يلخص الجدول التالي سجلات الطرف الثالث العامة لنتائج Elo الخاصة بنموذج HappyHorse 1.0 في اختبارات العمى (Blind Test) على منصة Artificial Analysis Video Arena، بالإضافة إلى مواقع المنافسين الرئيسيين.
مقارنة نقاط Elo في تحويل النص إلى فيديو / الصورة إلى فيديو
| فئة المنافسة | الترتيب | النموذج | نقاط Elo |
|---|---|---|---|
| تحويل النص إلى فيديو (بدون صوت) | 1 | HappyHorse-1.0 | 1333 |
| تحويل النص إلى فيديو (بدون صوت) | 2 | Dreamina Seedance 2.0 720p | 1273 |
| تحويل النص إلى فيديو (بدون صوت) | 3 | SkyReels V4 | 1244 |
| تحويل النص إلى فيديو (بدون صوت) | 4 | Kling 3.0 1080p (Pro) | 1241 |
| تحويل النص إلى فيديو (بدون صوت) | 5 | PixVerse V6 | 1239 |
| تحويل النص إلى فيديو (مع صوت) | 1 | Dreamina Seedance 2.0 720p | 1219 |
| تحويل النص إلى فيديو (مع صوت) | 2 | HappyHorse-1.0 | 1205 |
| تحويل الصورة إلى فيديو (بدون صوت) | 1 | HappyHorse-1.0 | 1392 |
| تحويل الصورة إلى فيديو (بدون صوت) | 2 | Dreamina Seedance 2.0 720p | 1355 |
| تحويل الصورة إلى فيديو (بدون صوت) | 3 | PixVerse V6 | 1338 |
| تحويل الصورة إلى فيديو (بدون صوت) | 4 | grok-imagine-video | 1333 |
| تحويل الصورة إلى فيديو (بدون صوت) | 5 | Kling 3.0 Omni 1080p (Pro) | 1297 |
ملاحظات رئيسية:
- أكبر ميزة تنافسية في فئة تحويل الصورة إلى فيديو: 1392 مقابل 1355، بفارق Elo يقترب من 40 نقطة، وهو مستوى يعتبر في نظام اختبارات العمى "فرقاً يمكن للمستخدمين ملاحظته بثبات"؛
- المركز الأول أيضاً في تحويل النص إلى فيديو: 1333 مقابل 1273، بفارق 60 نقطة، مما يعني أنه حتى بدون استخدام صورة مرجعية، يتفوق نموذج HappyHorse على Seedance 2.0 في القدرات الأساسية مثل تكوين اللقطات وحركة الشخصيات؛
- المركز الثاني مؤقتاً في فئة الصوت: لا يزال Seedance 2.0 يتفوق في مزامنة الصوت والصورة، وهو أمر يعود إلى التحسينات الهندسية التي أجريت عليه لخدمة "المخرجين بالذكاء الاصطناعي" في السرد القصصي الطويل؛
- متغير V2: ظهر الإصدار V2 لفترة وجيزة في بعض لقطات الشاشة، لكن المسؤولين لم يصدروا سوى وصف للإصدار 1.0، ولم يتم التأكد بعد مما إذا كان V2 هو النسخة التي "اختفت" لاحقاً.
دعم اللغات المتعددة والسيناريوهات المتمحورة حول الإنسان
أوضحت الجهة المطورة أن HappyHorse 1.0 يدعم أصلياً 6 لغات: الصينية، الإنجليزية، اليابانية، الكورية، الألمانية، والفرنسية، مع التأكيد على أن النموذج يتفوق بشكل خاص في السيناريوهات "المتمحورة حول الإنسان (human-centric)"، بما في ذلك:
- الأداء الوجهي الدقيق (facial performance)؛
- التنسيق الكلامي الطبيعي (speech coordination)؛
- حركات الجسم الواقعية (body motion)؛
- مزامنة الشفاه الدقيقة (lip sync).
هذا الوصف يضع نموذج HappyHorse بوضوح في مسار "الشخصيات الافتراضية / المحتوى الرقمي / المسلسلات القصيرة"، وليس مجرد "مقاطع ترويجية للمناظر الطبيعية". وهذا يفسر سبب تفوقه الكبير في فئة تحويل الصورة إلى فيديو (تحريك صورة شخصية) – وهو المطلب الأساسي للشخصيات الرقمية.

تخمينات حول أصل نموذج HappyHorse: هل هو WAN 2.7؟ أم Seedance؟ أم حصان أسود جديد؟
عندما بدأت لقطات شاشة HappyHorse 1.0 في الانتشار في أوساط الذكاء الاصطناعي الناطقة بالإنجليزية، كان النقاش الأكثر حيوية هو "من أين أتى هذا النموذج؟". وبالنظر إلى خيوط الأدلة في المجتمع التقني، يمكننا تلخيص التخمينات في الجدول التالي.
مقارنة بين ثلاثة تخمينات رئيسية
| مصدر التخمين | الحجة الجوهرية | الحجة المعارضة |
|---|---|---|
| نسخة معدلة من Alibaba Wan 2.7 | تم إصداره في نفس فترة Wan 2.7، ومختبرات Alibaba Tongyi معروفة بجرأتها في مجال الفيديو؛ التسمية "Horse" قد تشير إلى عام الحصان | الوصف الرسمي لـ Wan 2.7 يميل أكثر نحو الصور / أنماط التفكير، ولا يتطابق مع بنية الـ 40 طبقة أحادية التدفق التي يؤكد عليها HappyHorse |
| نسخة تجريبية من فريق ByteDance Seedance | Seedance 2.0 هو المنافس الصيني الحالي في صدارة Arena، ولدى ByteDance دافع كافٍ للاختبار المجهول | فريق Seedance 2.0 الرسمي لا يزال متفوقاً في فئة الصوت، ولا يوجد سبب لدى ByteDance لاستبدال "نسخة أقوى" باسم مختلف |
| مختبر غير معلن / تحالف أكاديمي | إصدار "نموذج مفتوح المصدر بالكامل + نموذج تقطير + نموذج فائق الدقة" يشبه الأسلوب البحثي؛ التسمية الغريبة والموقع الإلكتروني البسيط | جودة النموذج وصلت إلى مستوى تجاري من الدرجة الأولى، ومن الصعب على فريق أكاديمي بحت تدريب نموذج بهذا الحجم بشكل مستقل |
نحن نميل شخصياً إلى أن احتمال الفرضية الثالثة في تزايد: من المرجح أن HappyHorse 1.0 يأتي من فريق جديد يأمل في تحقيق شهرة واسعة من خلال استراتيجية المصدر المفتوح، واختيار المشاركة المجهولة في Arena كان بهدف بناء المصداقية باستخدام بيانات اختبارات العمى قبل الإطلاق الرسمي. هذا الأسلوب المتمثل في "التصنيف أولاً، ثم المصدر المفتوح، ثم إطلاق المنتج" قد أثبت فعاليته لدى العديد من المختبرات الآسيوية خلال الـ 18 شهراً الماضية.
ومع ذلك، هذه مجرد تخمينات. قبل الإطلاق الرسمي لمستودع GitHub و Model Hub، لا ينبغي اعتبار أي ادعاء بأنه "النموذج X" حقيقة. الموقف الأكثر عملية للمطورين هو: التركيز على منحنى قدرات النموذج، وليس على هويته.
🎯 نصيحة حذرة: طالما أن أوزان نموذج HappyHorse لم تُفتح للجمهور ولم يتم تأكيد مصدره رسمياً، لا ننصح بالمراهنة على مشاريع الإنتاج الحقيقية باستخدامه. يمكنك أولاً استدعاء نماذج الفيديو التجارية مثل Seedance 2.0 أو Kling 3.0 أو Veo 3.1 عبر منصات موثوقة مثل APIYI (apiyi.com) لإنجاز مشاريعك، مع تقييم تقدم HappyHorse في المصدر المفتوح داخلياً بالتوازي.
التأثيرات الثلاثية لنموذج HappyHorse على القطاع
حتى لو ثبت في النهاية أن HappyHorse 1.0 لم يكن سوى حملة ترويجية مدروسة، فقد ترك بالفعل ثلاثة تأثيرات تستحق التوثيق في مجال توليد الفيديو بالذكاء الاصطناعي.
المستوى الأول: إشارات حول نمط البنية الهيكلية
على مدار العامين الماضيين، استمرت نماذج الفيديو السائدة في التركيز على تحسين مسار "Diffusion متعدد المسارات + Cross-Attention". لكن نموذج HappyHorse أثبت من خلال تصدره للمركز الأول في منصة Arena أن مسار "Single-stream Self-Attention + استنتاج بخطوات قليلة" يمكن أن يصل إلى مستوى SOTA (أحدث ما توصلت إليه التقنية)، كما أنه أكثر كفاءة من الناحية الهندسية. هذا سيدفع المزيد من الفرق لإعادة التفكير: هل حان الوقت للتخلي عن تعقيدات طبقة Cross-Attention؟
المستوى الثاني: تطور استراتيجيات المصادر المفتوحة
اختار HappyHorse نهج "الظهور المجهول ← الإعلان عن نية المصدر المفتوح ← إطلاق الأوزان"، بدلاً من النهج التقليدي المتمثل في "نشر ورقة بحثية أولاً ← ثم إطلاق الأوزان". هذا الأسلوب أقرب إلى إطلاق المنتجات الاستهلاكية، حيث يتم وضع "بيانات تجربة المستخدم" قبل الأوراق البحثية. إذا تم الوفاء بوعد المصدر المفتوح، فقد يصبح HappyHorse 1.0 نموذجاً أساسياً آخر للفيديو يخضع لتطوير واسع النطاق، تماماً مثل Wan وHunyuan Video وOpen-Sora.
المستوى الثالث: مصداقية منصات التقييم الأعمى
من زاوية أخرى، شكل "صعود واختفاء" HappyHorse المفاجئ جرس إنذار لمنصات التقييم الأعمى مثل Artificial Analysis وLMArena. مع تزايد الإدخالات المجهولة، أصبح التمييز بين "نموذج جديد حقاً" و"نقطة تحقق (Checkpoint) لنموذج موجود مسبقاً" تحدياً لا مفر منه للقائمين على هذه المنصات. بالنسبة للمطورين، يعني هذا أن قراءة تصنيفات Elo تتطلب الآن دمج "بطاقة النموذج + أمثلة الاستنتاج + بيانات الأعمال الواقعية"، بدلاً من الاكتفاء بالنظر إلى مجرد رقم.

كيف يتعامل المطورون مع أحداث "المفاجآت" مثل نموذج HappyHorse
بالنسبة لفرق الهندسة وصناع المحتوى، بدلاً من الانشغال بالتخمينات حول "من هم ومتى سيصدرون الكود المصدري"، من الأفضل بناء مجموعة من الإجراءات القياسية للتعامل مع مثل هذه المفاجآت.
سير العمل الموصى به من أربع خطوات
| الخطوة | الإجراء | الهدف |
|---|---|---|
| 1 | توحيد واجهة الربط (API) لتشغيل عمليات توليد الفيديو الحالية | ضمان الانتقال السلس عند ظهور أي نموذج جديد |
| 2 | جمع الموجهات (Prompts) النموذجية والمواد المرجعية | إنشاء "مجموعة اختبار مرجعية" داخلية مستقلة عن Arena |
| 3 | تشغيل الاختبارات المرجعية الداخلية فور توفر النموذج الجديد | التحقق من بياناتك الخاصة لمعرفة ما إذا كانت نتائج Arena قابلة للتكرار |
| 4 | تقييم التكلفة الإجمالية (سعر API / تأخير الاستنتاج / الامتثال) | اتخاذ قرار بشأن استبدال النموذج الأساسي |
جوهر هذا المسار هو: ألا ترهن عملك بنمط إطلاق أي نموذج منفرد، بل اجعل "القدرة على دمج النماذج الجديدة بسرعة" مهارة أساسية لديك. لم تكن تجربة HappyHorse 1.0 سوى البداية، ومن المتوقع أن نرى المزيد من النماذج المجهولة المماثلة على منصات Arena المختلفة في النصف الثاني من عام 2026.
🎯 نصيحة هندسية: للفرق التي ترغب في متابعة نموذج HappyHorse والمنافسين مثل Seedance وKling وVeo على المدى الطويل، نوصي بربط عمليات توليد الفيديو عبر خدمة وكيل API مثل APIYI (apiyi.com) التي تدعم استدعاء نماذج متعددة بالتوازي؛ بهذه الطريقة، بغض النظر عمن يتصدر القائمة لاحقاً، لن تحتاج سوى لتغيير معامل
modelفي جانب الأعمال لإتمام المقارنة والإطلاق التدريجي.
الأسئلة الشائعة حول نموذج HappyHorse
س1: هل يمكن تنزيل واستخدام HappyHorse 1.0 الآن؟
حتى الآن (أوائل أبريل 2026)، لا تزال الصفحة الرسمية لنموذج HappyHorse 1.0 تشير إلى أن مستودع GitHub ومركز النماذج (Model Hub) "قريبان" (Coming Soon). وهذا يعني أن الأوزان ورموز الاستدلال لم تُنشر للعامة بعد، لذا يجب توخي الحذر الشديد تجاه أي جهة تدعي إمكانية تنزيله أو نشره حالياً. ننصح بمتابعة الموقع الرسمي، وقبل إصدار الأوزان رسمياً، يمكنك تجربة نماذج تجارية جاهزة مثل Seedance 2.0 أو Kling 3.0 عبر منصات مثل APIYI (apiyi.com).
س2: لماذا اختفى نموذج HappyHorse من قائمة تصنيف Arena؟
لا توجد معلومات رسمية تفسر سبب الاختفاء. وبالنظر إلى نقاشات المجتمع، هناك تفسيران رئيسيان: الأول، أن مؤلف النموذج سحبه طواعية لإعادة تنظيم النتائج قبل الإطلاق الرسمي؛ والثاني، أن المنصة قامت بإزالته مؤقتاً لعدم وضوح هوية النموذج (كونه مدرجاً كنموذج مجهول). وفي كلتا الحالتين، لا ينبغي تفسير ذلك على أنه "فشل للنموذج"، فنتائج اختبار Elo التي حققها قبل اختفائه كانت بيانات حقيقية ناتجة عن اختبارات عمياء.
س3: هل نموذج HappyHorse 1.0 هو نفسه نموذج Wan 2.7؟
لا توجد أي معلومات رسمية تؤكد ذلك. Wan 2.7 هو نموذج صور/فيديو أصدرته مختبرات "علي بابا تونغ يي" (Alibaba Tongyi) رسمياً في أبريل 2026، ويركز على "نمط التفكير" ومعالجة النصوص الطويلة؛ بينما يعتمد نموذج HappyHorse على بنية Transformer أحادية المسار (Single-stream) مكونة من 40 طبقة واستدلال بإزالة ضوضاء من 8 خطوات، وهي مواصفات تقنية مختلفة. قد يظن البعض أنهما من نفس المصدر، لكن يبدو أنهما "منتجان متنافسان في نفس المسار" وليس مجرد إعادة تسمية لنفس النموذج.
س4: هل يمكن لنموذج HappyHorse القيام بتوليد صوت وفيديو مشترك؟
نعم. أشارت الوثائق الرسمية بوضوح إلى أن HappyHorse 1.0 يعالج رموز النص والفيديو والصوت معاً داخل نفس الـ Transformer المكون من 40 طبقة، لذا فهو يدعم طبيعياً "إدخال نص ← إخراج مقطع فيديو مسموع". وفي مسار Arena الذي يتضمن الصوت، يحتل النموذج حالياً المرتبة الثانية بعد Seedance 2.0، مما يضعه ضمن الفئة الأولى.
س5: بصفتي مطوراً، كيف يجب أن أستعد الآن؟
أفضل استراتيجية هي الحياد في أدوات العمل: قم بربط عمليات توليد الفيديو الخاصة بك بمنصة موحدة تدعم استدعاء نماذج متعددة بالتوازي، مثل APIYI (apiyi.com)، وقم بإعداد الموجهات (Prompts)، وسيناريوهات اللقطات، وعمليات المراجعة مسبقاً. بمجرد إطلاق نموذج HappyHorse رسمياً أو توفره عبر API، ستحتاج فقط إلى تغيير معامل النموذج (model parameter) للبدء في استخدامه دون الحاجة لإعادة كتابة الكود.
س6: ما هي سيناريوهات الأعمال المناسبة لنموذج HappyHorse؟
من خلال تركيز الوثائق الرسمية على "المشاهد البشرية، أداء الوجه، مزامنة الشفاه، وتعدد اللغات"، فإن نموذج HappyHorse هو الأنسب لـ: المذيعين الافتراضيين / مقاطع الفيديو القصيرة للأشخاص الرقميين، المسلسلات القصيرة المعتمدة على الذكاء الاصطناعي، الأفلام الترويجية متعددة اللغات، ومشاهد الشخصيات في الإعلانات. أما إذا كان عملك يركز على المناظر الطبيعية أو لقطات المنتجات، فإن نماذج مثل Seedance 2.0 أو Veo 3.1 أو Kling 3.0 تظل خيارات أكثر استقراراً.
الخلاصة: ما الذي نتعلمه من نموذج HappyHorse؟
بجمع كل الخيوط، نجد أن HappyHorse 1.0 يستحق هذه الدراسة ليس فقط بسبب نقاط Elo المتميزة التي حققها في Artificial Analysis Video Arena، بل لأنه يمثل تجسيداً لنمط إطلاق نماذج توليد الفيديو في عام 2026: استبدال الهياكل المعقدة متعددة المسارات بـ Transformer أحادي المسار، استبدال عشرات خطوات إزالة الضوضاء بخطوات قليلة جداً، استبدال الأوراق البحثية المسبقة بالإدراج المجهول في القوائم، واستبدال الـ API المغلق بوعود المصادر المفتوحة. هذه التغيرات الأربعة، وإن لم تكن ثورية بشكل منفرد، إلا أنها مجتمعة تشير إلى وتيرة جديدة لتطور نماذج الفيديو.
النصيحة المباشرة لفرق العمل هي: لا تغرقوا في التخمين حول "هوية النموذج"، بل تعاملوا معه كاختبار ضغط هندسي؛ هل يمكن لخط إنتاج الفيديو الخاص بك أن يتكامل مع نموذج جديد في يوم إطلاقه؟ إذا كانت الإجابة نعم، فستستفيد من هذا النموذج سواء كان مفتوح المصدر حقاً، أو مجرد واجهة لشركة كبرى، أو حتى لو تلاشى تماماً.
🎯 نصيحة أخيرة: إذا كنت ترغب في تجربة جميع نماذج فيديو الذكاء الاصطناعي الرائدة (مثل Seedance 2.0 / Kling 3.0 / Veo 3.1 / PixVerse V6) فور صدورها، مع الحفاظ على القدرة على التبديل إلى HappyHorse بضغطة زر، ننصحك باستخدام منصة وسيطة موحدة مثل APIYI (apiyi.com). هذا يجنبك عناء الربط المتكرر مع SDK لكل شركة، ويقلل تكاليف الانتقال إلى أدنى مستوياتها عند ظهور نماذج جديدة.
بقلم: فريق APIYI | نركز على تطبيق نماذج اللغة الكبيرة والجانب الهندسي للذكاء الاصطناعي. للمزيد من تقييمات الفيديو والنماذج متعددة الوسائط، تفضل بزيارة APIYI (apiyi.com).