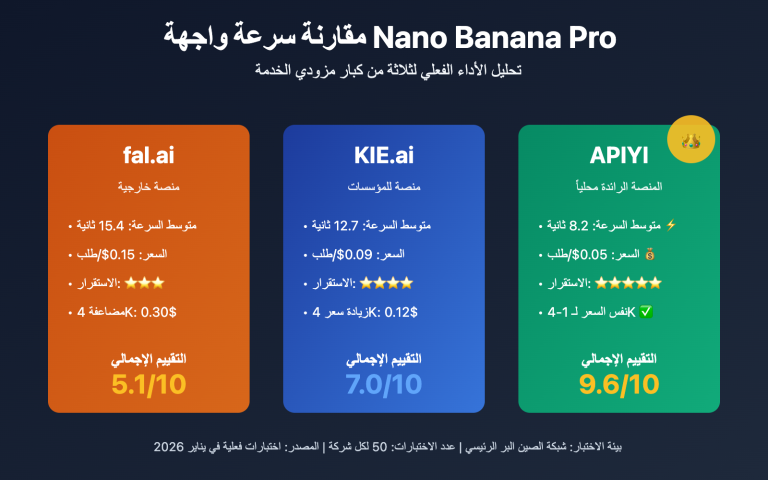
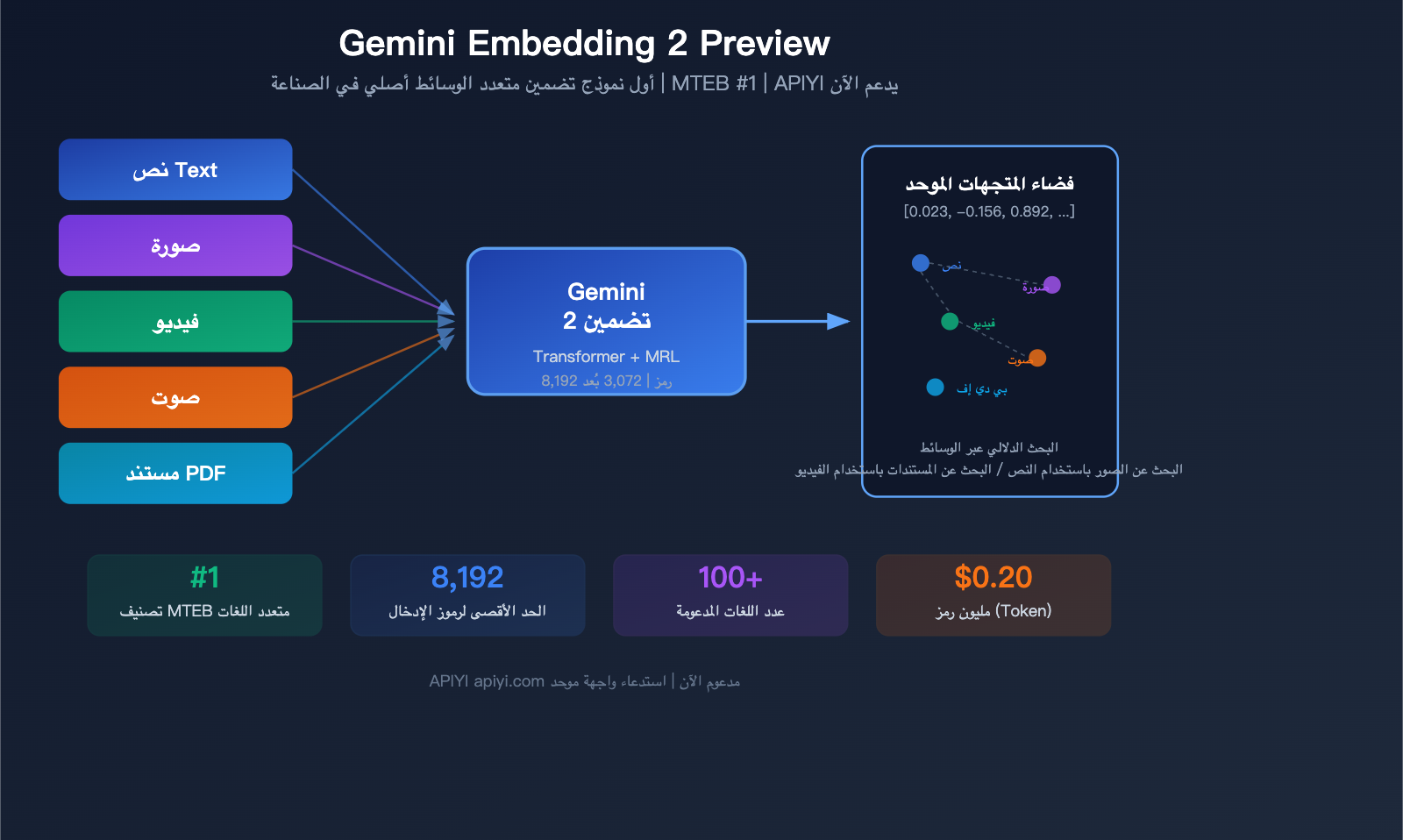
أطلقت جوجل في مارس 2026 نموذجاً محورياً يُدعى Gemini Embedding 2 Preview، وهو أول نموذج تضمين (Embedding) متعدد الوسائط أصلي في القطاع. يتميز هذا النموذج بقدرته على تعيين النصوص، الصور، مقاطع الفيديو، الملفات الصوتية، ومستندات PDF في مساحة متجهية موحدة، وقد حقق المرتبة الأولى في اختبار MTEB متعدد اللغات، متفوقاً على المركز الثاني بأكثر من 5 نقاط مئوية.
القيمة الجوهرية: بعد قراءة هذا المقال، ستتعرف على 5 اختراقات تقنية في Gemini Embedding 2 Preview، ومقارنة الأداء والتسعير مع المنافسين، وكيفية دمجه بسرعة عبر واجهة برمجة التطبيقات (API).
ما هو Gemini Embedding 2 Preview؟
يُعد Gemini Embedding 2 Preview أحدث نموذج تضمين (Embedding) أطلقته Google في 10 مارس 2026. تم بناؤه استناداً إلى بنية Gemini، ويستخدم هيكلية "المحول" (Transformer) ذات الانتباه ثنائي الاتجاه، وهو أول نموذج تضمين من Google يدعم المدخلات متعددة الوسائط بشكل أصلي.
| المواصفات | التفاصيل |
|---|---|
| معرف النموذج | gemini-embedding-2-preview |
| تاريخ الإصدار | 10 مارس 2026 |
| الحالة | معاينة (Preview، الإصدار النهائي لم يحدد بعد) |
| أبعاد المخرجات الافتراضية | 3,072 |
| نطاق الأبعاد المتاح | 128 — 3,072 |
| الحد الأقصى لرموز الإدخال | 8,192 (أربعة أضعاف الجيل السابق) |
| دعم الوسائط المتعددة | النصوص، الصور، الفيديو، الصوت، ملفات PDF |
| دعم اللغات | أكثر من 100 لغة |
| تدريب Matryoshka | مدعوم (يمكن تقليص الأبعاد مع الحفاظ على جودة الدلالات) |
| المنصات المتاحة | Gemini API، Vertex AI، APIYI apiyi.com |
الفروقات الجوهرية عن الجيل السابق
| الميزة | text-embedding-004 | gemini-embedding-001 | gemini-embedding-2-preview |
|---|---|---|---|
| الحد الأقصى لرموز الإدخال | 2,048 | 2,048 | 8,192 |
| أبعاد المخرجات | حتى 768 | 128-3,072 | 128-3,072 |
| الوسائط المتعددة | نصوص فقط | نصوص فقط | نصوص + صور + فيديو + صوت + PDF |
| تحديد نوع المهمة | حقل task_type |
حقل task_type |
تعليمات مضمنة في الموجه |
| دعم MRL | غير مدعوم | مدعوم | مدعوم |
| السعر/مليون رمز | متوقف | $0.15 | $0.20 |
🎯 نصيحة للربط: تدعم منصة APIYI apiyi.com بالفعل استدعاء نموذج gemini-embedding-2-preview،
حيث يمكنك الربط عبر واجهة متوافقة مع OpenAI دون الحاجة لإعداد مفتاح API خاص بـ Google.
شرح مفصل لـ 5 طفرات تقنية
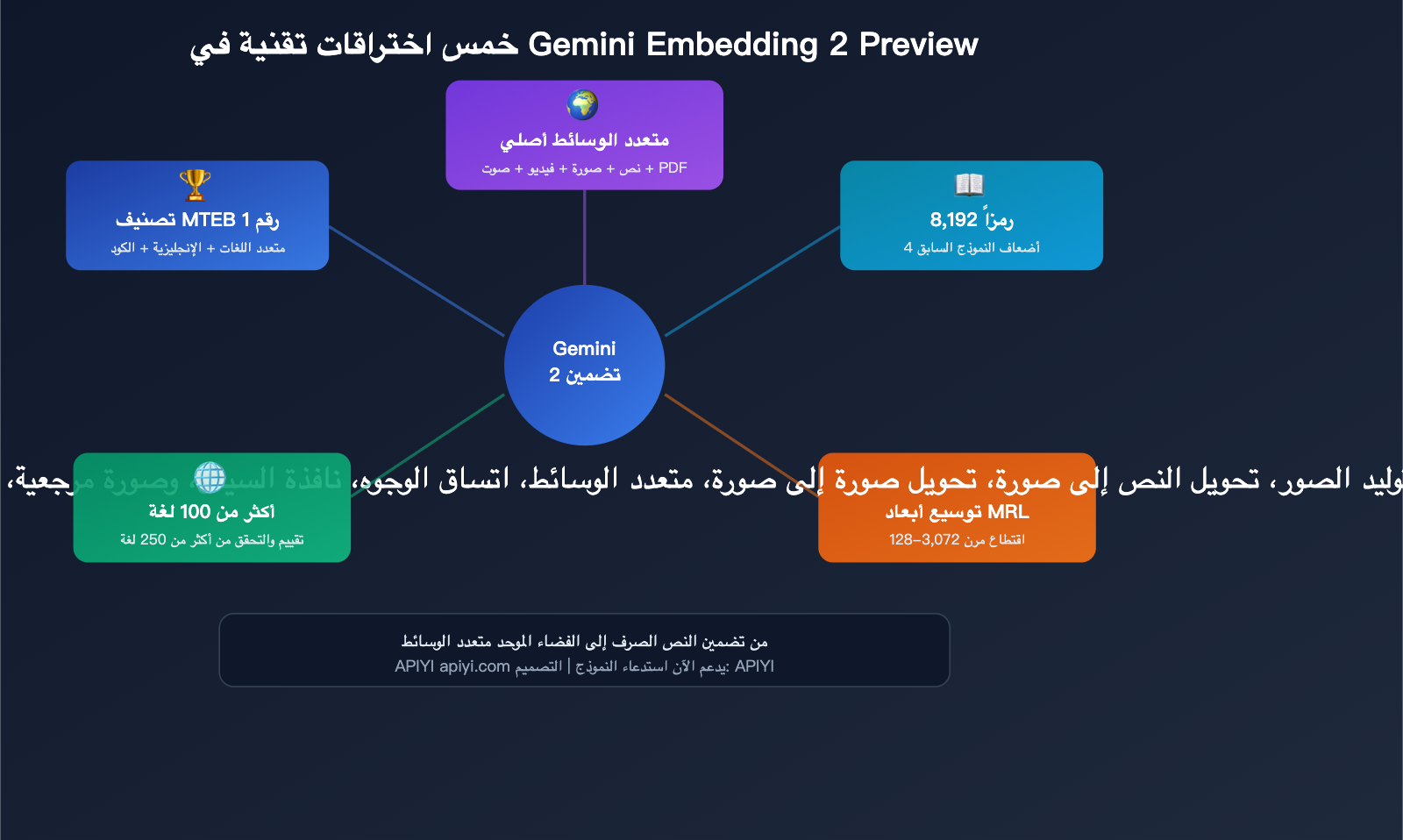
الطفرة الأولى: مساحة تضمين موحدة للوسائط المتعددة
هذه هي الميزة التنافسية الأكبر لنموذج Gemini Embedding 2، حيث يتم تعيين محتوى 5 وسائط مختلفة إلى نفس الفضاء المتجهي.
| الوسيط | متطلبات التنسيق | الحد الأقصى لكل طلب | ملاحظات |
|---|---|---|---|
| النصوص | نص عادي | 8,192 رمز | يدعم 100+ لغة |
| الصور | PNG, JPEG | حتى 6 صور لكل طلب | معالجة مباشرة للبكسلات |
| الفيديو | MP4, MOV | حتى 120 ثانية | أخذ عينات تلقائي لما يصل إلى 32 إطاراً |
| الصوت | MP3, WAV | حتى 80 ثانية | معالجة أصلية دون الحاجة لتحويل النص |
| مستندات PDF | حتى 6 صفحات لكل طلب | يتضمن قدرات OCR |
سيناريوهات الاستخدام العملي:
- البحث عن صور باستخدام نصوص ("سيارة سباق حمراء على المضمار" ← إرجاع الصور المطابقة).
- البحث عن مقاطع فيديو مشابهة باستخدام صور.
- البحث عن مستندات ذات صلة باستخدام وصف صوتي.
- بناء قاعدة معرفية موحدة عبر الوسائط.
هذا لم يكن ممكناً في نماذج التضمين السابقة؛ فسلسلة OpenAI text-embedding-3 تدعم النصوص فقط، وإذا كنت بحاجة للبحث عن صور، كان يجب عليك استخدام نموذج رؤية لاستخراج الوصف أولاً، مما يضيف خطوة إضافية ويؤدي لفقدان المعلومات.
الطفرة الثانية: نافذة سياق بـ 8,192 رمز
ارتفعت نافذة الإدخال من 2,048 إلى 8,192 رمزاً، مما يعني إمكانية تضمين مقاطع مستندات أطول في المرة الواحدة.
بالنسبة لأنظمة RAG (التوليد المعزز بالاسترجاع)، يعد هذا التحسين مفيداً جداً:
- سابقاً كان يجب تقطيع المستندات إلى أجزاء صغيرة من 500-1000 رمز.
- الآن يمكنك استخدام أجزاء كبيرة من 2000-4000 رمز، مما يحافظ على سياق أكبر.
- أجزاء مستند أكبر = تقطيع أقل = نتائج استرجاع أكثر اكتمالاً.
الطفرة الثالثة: مرونة الأبعاد عبر Matryoshka
يستخدم Gemini Embedding 2 تدريب Matryoshka Representation Learning (MRL)، حيث يركز النموذج أهم المعلومات الدلالية في الأبعاد الأولى للمتجه.
وهذا يعني أنه يمكنك اختيار الأبعاد بمرونة حسب السيناريو:
| الأبعاد | حجم المتجه | سيناريو الاستخدام | فقدان الجودة |
|---|---|---|---|
| 3,072 (افتراضي) | 12.3 كيلوبايت | استرجاع بأعلى دقة | لا يوجد |
| 1,536 | 6.1 كيلوبايت | توازن بين الدقة والتخزين | ضئيل جداً |
| 768 | 3.1 كيلوبايت | الخيار المفضل للنشر واسع النطاق | طفيف |
| 256 | 1.0 كيلوبايت | أنظمة التوصية اللحظية | متوسط |
| 128 | 0.5 كيلوبايت | سيناريوهات الضغط القصوى | كبير |
ملاحظة: عند استخدام أبعاد أقل من 3,072، يجب إجراء تسوية (Normalization) يدوية للمتجهات قبل حساب التشابه.
الطفرة الرابعة: دعم أكثر من 100 لغة
في اختبارات MTEB المعيارية متعددة اللغات، تم تقييم Gemini Embedding 2 على أكثر من 250 لغة، متجاوزاً نطاق المنافسين بكثير.
مؤشرات الأداء للغات الرئيسية:
- تعدين النصوص المزدوجة (Bitext Mining): 79.32 نقطة.
- الاسترجاع عبر اللغات (XOR-Retrieve): Recall@5kt 90.42 نقطة.
- الفهم متعدد اللغات (XTREME-UP): MRR@10 64.33 نقطة.
الطفرة الخامسة: المركز الأول في تصنيفات MTEB المتعددة
| الاختبار المعياري | النتيجة | الترتيب | هامش التفوق |
|---|---|---|---|
| MTEB متعدد اللغات (Mean Task) | 68.32 | الأول | +5.09 |
| MTEB متعدد اللغات (Mean Type) | 59.64 | الأول | — |
| MTEB الإنجليزية v2 (Mean Task) | 73.30 | الأول | — |
| MTEB الإنجليزية v2 (Mean Type) | 67.67 | الأول | — |
| MTEB البرمجة (Mean All) | 74.66 | الأول | — |
للمقارنة، حصل النموذج صاحب المركز الثاني gte-Qwen2-7B-instruct على 62.51 نقطة في اختبار MTEB متعدد اللغات، مما يعني أن Gemini Embedding 2 يتفوق بفارق 6 نقاط تقريباً، وهو فارق كبير جداً في مجال نماذج التضمين.
💡 نصيحة للمطورين: إذا كنت تبني نظام RAG أو تطبيق بحث دلالي،
فإن Gemini Embedding 2 هو الخيار الأقوى حالياً في سيناريوهات اللغات المتعددة والبرمجة.
يمكنك الربط مع هذا النموذج بضغطة زر عبر APIYI apiyi.com، مع دعم نماذج OpenAI embedding أيضاً،
مما يسهل عليك مقارنة النتائج بسرعة.
مقارنة الأسعار والأداء مع المنافسين
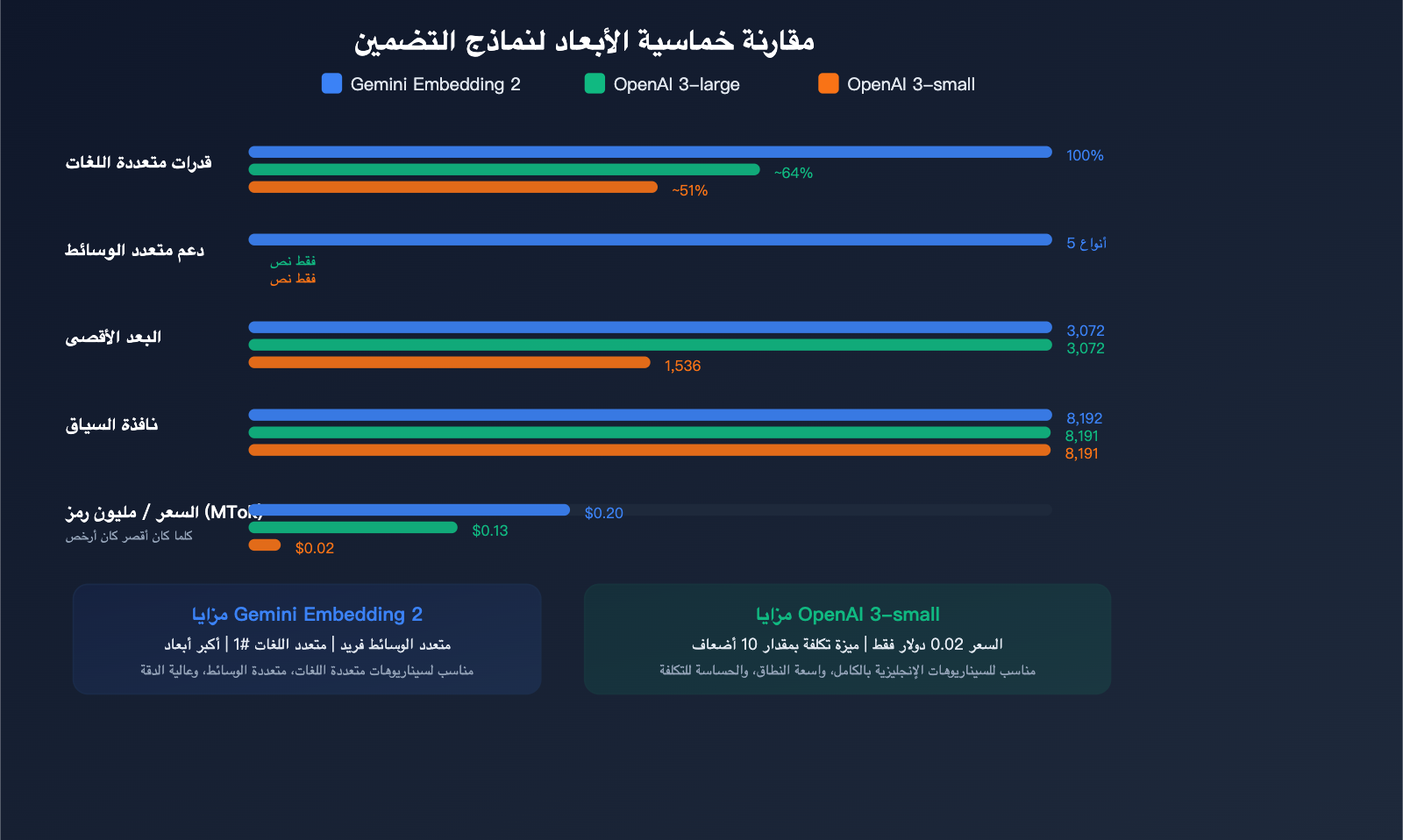
مقارنة أسعار تضمين النصوص (Embedding)
| النموذج | السعر/مليون رمز (Token) | الأبعاد القصوى | المدخلات القصوى | متعدد الوسائط | ترتيب تعدد اللغات |
|---|---|---|---|---|---|
| Gemini Embedding 2 | $0.20 | 3,072 | 8,192 | ✅ خماسي الوسائط | #1 |
| gemini-embedding-001 | $0.15 | 3,072 | 2,048 | ❌ | — |
| OpenAI text-embedding-3-large | $0.13 | 3,072 | 8,191 | ❌ | — |
| OpenAI text-embedding-3-small | $0.02 | 1,536 | 8,191 | ❌ | — |
تسعير المحتوى متعدد الوسائط (حصري لـ Gemini Embedding 2):
| نوع المدخلات | السعر العادي/مليون رمز | السعر بالجملة/مليون رمز |
|---|---|---|
| نص | $0.20 | $0.10 |
| صورة | $0.45 (~$0.00012/صورة) | $0.225 |
| صوت | $6.50 (~$0.00016/ثانية) | $3.25 |
| فيديو | $12.00 (~$0.00079/إطار) | $6.00 |
توصيات اختيار النموذج
| سيناريو الاستخدام | النموذج الموصى به | السبب |
|---|---|---|
| نص فقط، حساس للتكلفة | OpenAI text-embedding-3-small | الأرخص ($0.02) |
| نص فقط، دقة عالية | Gemini Embedding 2 أو OpenAI 3-large | دقة متقاربة، Gemini يتفوق في تعدد اللغات |
| البحث متعدد الوسائط | Gemini Embedding 2 | الحل الوحيد متعدد الوسائط أصلاً |
| استرجاع متعدد اللغات | Gemini Embedding 2 | الأول عالمياً في MTEB لتعدد اللغات |
| البحث في الأكواد | Gemini Embedding 2 | الأول عالمياً في MTEB للأكواد |
| تكلفة منخفضة على نطاق واسع | OpenAI 3-small + API بالجملة | ميزة سعرية بمقدار 10 أضعاف |
🎯 نصيحة للاختيار: يعتمد اختيار نموذج التضمين (Embedding) على سيناريو عملك الخاص.
ننصحك بالوصول إلى نماذج Gemini وOpenAI عبر منصة APIYI (apiyi.com)،
ومقارنة نتائج الاسترجاع ببياناتك الحقيقية قبل اتخاذ القرار. تدعم المنصة واجهة موحدة، مما يتيح لك تبديل النماذج دون الحاجة لتعديل الكود.
شرح تفصيلي لطريقة استدعاء API
طريقة تحديد نوع المهمة (تغيير مهم)
على عكس gemini-embedding-001، فإن نموذج Gemini Embedding 2 لم يعد يستخدم معامل task_type، بل يتم تحديد نوع المهمة من خلال تضمين تعليمات المهمة داخل محتوى الإدخال.
8 أنواع من المهام المدعومة:
| نوع المهمة | تنسيق جانب الاستعلام | تنسيق جانب المستند |
|---|---|---|
| البحث/الاسترجاع | task: search result | query: {المحتوى} |
title: {العنوان} | text: {المحتوى} |
| الإجابة على الأسئلة | task: question answering | query: {السؤال} |
title: {العنوان} | text: {المحتوى} |
| التحقق من الحقائق | task: fact checking | query: {الادعاء} |
title: {العنوان} | text: {المحتوى} |
| استرجاع الكود | task: code retrieval | query: {الوصف} |
title: {العنوان} | text: {الكود} |
| التصنيف | task: classification | query: {المحتوى} |
نفس التنسيق |
| التجميع (Clustering) | task: clustering | query: {المحتوى} |
نفس التنسيق |
| تشابه الجمل | task: sentence similarity | query: {الجملة} |
نفس التنسيق |
بالنسبة لجانب المستند، إذا لم يوجد عنوان، استخدم title: none.
مثال على الاستدعاء باستخدام Python
import openai
# الاستدعاء عبر الواجهة الموحدة لـ APIYI
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# تضمين النص - سيناريو البحث
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input="task: search result | query: ما هي قاعدة البيانات المتجهة",
dimensions=768 # الأبعاد المتاحة: 128-3072
)
embedding = response.data[0].embedding
print(f"أبعاد المتجه: {len(embedding)}")
print(f"أول 5 قيم: {embedding[:5]}")
عرض كود عملية استرجاع RAG الكاملة
import openai
import numpy as np
from typing import List
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
def get_embedding(text: str, task: str = "search result", dim: int = 768) -> List[float]:
"""الحصول على متجه تضمين النص"""
formatted = f"task: {task} | query: {text}"
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input=formatted,
dimensions=dim
)
vec = response.data[0].embedding
# أبعاد MRL المقتطعة تتطلب تطبيعاً (Normalization) يدوياً
if dim < 3072:
norm = np.linalg.norm(vec)
vec = (np.array(vec) / norm).tolist()
return vec
def get_doc_embedding(title: str, text: str, dim: int = 768) -> List[float]:
"""الحصول على متجه تضمين المستند"""
formatted = f"title: {title} | text: {text}"
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input=formatted,
dimensions=dim
)
vec = response.data[0].embedding
if dim < 3072:
norm = np.linalg.norm(vec)
vec = (np.array(vec) / norm).tolist()
return vec
def cosine_similarity(a: List[float], b: List[float]) -> float:
"""حساب تشابه جيب التمام"""
a, b = np.array(a), np.array(b)
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# مثال على الاستخدام
query_vec = get_embedding("كيفية تحسين نتائج استرجاع RAG")
doc_vec = get_doc_embedding(
"دليل تحسين RAG",
"يقدم هذا المقال 5 طرق لتحسين جودة استرجاع RAG..."
)
similarity = cosine_similarity(query_vec, doc_vec)
print(f"التشابه: {similarity:.4f}")
🚀 ابدأ بسرعة: نوصي باستخدام منصة APIYI (apiyi.com) للوصول السريع إلى Gemini Embedding 2.
توفر المنصة واجهة برمجة تطبيقات متوافقة مع OpenAI، مما يتيح لك إكمال التكامل في 5 دقائق،
مع دعم الاستدعاء الموحد لنماذج التضمين الرئيسية مثل OpenAI وGemini وCohere.
ملاحظات الاستخدام
قيود حالة المعاينة (Preview)
| عنصر القيد | الشرح | التأثير |
|---|---|---|
| تغير الإصدار | قد يتم تعديل المواصفات والأسعار في مرحلة المعاينة | يوصى بإعداد خطط تراجع في بيئة الإنتاج |
| عدم توافق مساحة المتجهات | لا يمكن خلطها مع متجهات النماذج القديمة | الترقية تتطلب إعادة فهرسة كاملة |
| تطبيع الأبعاد المنخفضة | يتطلب تطبيعاً يدوياً عند استخدام أبعاد أقل من 3,072 | يجب إضافة خطوة التطبيع في الكود |
| قيود السرعة | حصة نماذج المعاينة أقل من نماذج GA | يتطلب طلب زيادة الحصة للاستخدام واسع النطاق |
| استخدام بيانات الطبقة المجانية | تُستخدم بيانات الطبقة المجانية لتحسين المنتج | يوصى باستخدام الطبقة المدفوعة للبيانات الحساسة |
ملاحظات عند الترحيل من النماذج القديمة
- يجب إعادة بناء الفهرس: مساحات المتجهات للنماذج المختلفة غير متوافقة، ولا يمكن خلطها في نفس قاعدة البيانات.
- تغير تنسيق نوع المهمة: تم التغيير من معامل
task_typeإلى تعليمات مضمنة داخل الموجه (Prompt). - معالجة التطبيع: إذا كنت تستخدم أبعاداً غير افتراضية، يجب إضافة منطق التطبيع في الكود الخاص بك.
- اختبار النتائج قبل الترحيل: يوصى بمقارنة نتائج الاسترجاع بين النموذج القديم والجديد في بيئة اختبار قبل اتخاذ قرار الترحيل.
الأسئلة الشائعة
س1: ما هي نقاط تفوق Gemini Embedding 2 Preview على OpenAI text-embedding-3-large؟
تكمن المزايا الرئيسية في ثلاثة جوانب: دعم الوسائط المتعددة الأصلي (بينما تدعم OpenAI النصوص فقط)، تصدرها المركز الأول في تصنيف MTEB للغات المتعددة (بفارق كبير)، وجودة أعلى في تضمين الأكواد البرمجية. ومع ذلك، فإن OpenAI text-embedding-3-large أقل تكلفة (0.13 دولار مقابل 0.20 دولار)، وإذا كنت تحتاج فقط إلى تضمين نصوص باللغة الإنجليزية، فإن جودة النموذجين متقاربة جداً. يمكنك استخدام خدمة وكيل API من APIYI عبر apiyi.com لاستدعاء النموذجين ومقارنتهما ببيانات حقيقية.
س2: ما هي الاستخدامات العملية لتضمين الوسائط المتعددة (Multimodal Embedding)؟
التطبيق الأكثر مباشرة هو البحث عبر الوسائط: حيث يقوم المستخدم بإدخال نص، ليعيد النظام صوراً أو مقاطع فيديو أو مستندات ذات صلة. على سبيل المثال، في التجارة الإلكترونية، يمكنك البحث عن صور المنتجات باستخدام عبارة "فستان أحمر"، أو في قواعد المعرفة المؤسسية، يمكنك البحث عن مقاطع ذات صلة في فيديوهات التدريب باستخدام وصف نصي. الطريقة التقليدية تتطلب استخدام نموذج رؤية حاسوبية لاستخراج الوصف أولاً ثم تضمين النص، بينما يعالج Gemini Embedding 2 الصور/الفيديوهات الأصلية مباشرة، مما يقلل من فقدان المعلومات.
س3: ما هو عدد الأبعاد المناسب؟ وهل هناك فرق كبير بين 768 و 3072؟
بالنسبة لمعظم التطبيقات، تعتبر 768 بُعداً هي نقطة التوازن المثالية؛ حيث تبلغ تكلفة التخزين ربع تكلفة 3072 بُعداً، مع فقدان ضئيل جداً في جودة الاسترجاع (بفضل التدريب بتقنية Matryoshka). إذا كانت مجموعة بياناتك صغيرة (أقل من مليون سجل) وتتطلب دقة عالية جداً، استخدم 3072 بُعداً. أما إذا كان حجم البيانات كبيراً أو كنت بحاجة إلى استرجاع فوري، فإن 768 أو حتى 256 بُعداً تعتبر خيارات معقولة.
س4: كيف تدعم APIYI نموذج Gemini Embedding 2؟ وهل يتطلب إعدادات إضافية؟
تدعم منصة APIYI عبر apiyi.com بالفعل نموذج gemini-embedding-2-preview، ويمكن استدعاؤه عبر واجهة تضمين متوافقة مع OpenAI، دون الحاجة إلى إعداد مفتاح API خاص بـ Google. ما عليك سوى تحديد gemini-embedding-2-preview في معامل model، وستكون المعاملات الأخرى (مثل dimensions) متطابقة تماماً مع واجهة تضمين OpenAI.

ملخص: معيار جديد في تضمينات الوسائط المتعددة
يمثل نموذج Gemini Embedding 2 Preview علامة فارقة في عالم نماذج التضمين (Embedding models)؛ حيث ينتقل بنا من مجرد معالجة النصوص إلى فضاء موحد حقيقي للوسائط المتعددة. بفضل تصدره للمركز الأول في اختبارات MTEB في أبعاد اللغات المتعددة، واللغة الإنجليزية، والبرمجة في آن واحد، إلى جانب نافذة سياق تصل إلى 8 آلاف رمز (Token) ودعم تقنية MRL لتعديل الأبعاد، فإنه يوفر حالياً أقوى أساس ممكن لأنظمة RAG، والبحث الدلالي، وبناء قواعد المعرفة.
مراجعة لأبرز النقاط:
- أول نموذج تضمين أصيل يدعم خمس وسائط (نص + صور + فيديو + صوت + ملفات PDF).
- المركز الأول في اختبارات MTEB للغات المتعددة، متفوقاً بأكثر من 5 نقاط.
- نافذة سياق بسعة 8,192 رمزاً، أي أربعة أضعاف الجيل السابق.
- دعم تدريب MRL لمرونة في الأبعاد تتراوح بين 128 و3,072.
- تسعير تنافسي يبلغ 0.20 دولار لكل مليون رمز، مما يجعله عالي الكفاءة في سيناريوهات الوسائط المتعددة.
نوصي بالوصول السريع إلى Gemini Embedding 2 Preview عبر منصة APIYI (apiyi.com)، حيث يتيح لك مفتاح API واحد دعم نماذج التضمين الرائدة مثل Gemini وOpenAI، مما يسهل عليك المقارنة والتبديل بينها.
📝 كاتب المقال: الفريق التقني لـ APIYI | APIYI apiyi.com – منصة موحدة للوصول إلى أكثر من 300 نموذج ذكاء اصطناعي عبر API.
المراجع
-
مدونة جوجل الرسمية: إعلان إطلاق Gemini Embedding 2
- الرابط:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-embedding-2/ - الوصف: تتضمن فلسفة تصميم النموذج ومقدمة عن قدراته في الوسائط المتعددة.
- الرابط:
-
وثائق Gemini API للتضمين: دليل الاستخدام الرسمي للـ API
- الرابط:
ai.google.dev/gemini-api/docs/embeddings - الوصف: معايير API الكاملة وأمثلة على استدعاء النموذج.
- الرابط:
-
ورقة بحث Gemini Embedding: التفاصيل التقنية واختبارات الأداء
- الرابط:
arxiv.org/html/2503.07891v1 - الوصف: بيانات اختبار MTEB التفصيلية وتحليل معمارية النموذج.
- الرابط:
-
تسعير Gemini API: معلومات مفصلة عن تسعير كل وسيط
- الرابط:
ai.google.dev/gemini-api/docs/pricing - الوصف: تفاصيل الأسعار للنصوص، الصور، الصوت، والفيديو.
- الرابط: