ملاحظة من المؤلف: دون الحاجة لتغيير قنوات النماذج الرخيصة، سنشرح بالتفصيل كيف يعمل OpenClaw على توفير التكاليف من خلال التحكم في طول الـ Token المدخل: عزل المهام في محادثات جديدة، استرجاع كتل التعليمات البرمجية بدقة بدلاً من حشو النص بالكامل، تقليم السياق، البحث المحلي عبر QMD، وغيرها من الاستراتيجيات الست الرئيسية.
يُعرف OpenClaw باستهلاكه العالي للـ Token؛ حيث أحرق بعض المستخدمين 21.5 مليون Token في يوم واحد، بفاتورة شهرية تجاوزت 600 دولار. رد الفعل الأول للكثيرين هو التحول إلى قنوات نماذج أرخص، لكن هذا يأتي على حساب الجودة. الطريقة الحقيقية لتوفير الـ Token هي التحكم في جانب الإدخال – فكمية السياق التي تغذي بها النموذج هي العامل الحاسم في التكلفة. يركز هذا المقال على سؤال جوهري: كيف نحول استهلاك الـ Token من "حشو النص بالكامل" إلى "التغذية الدقيقة"، دون تغيير النموذج ودون المساس بالجودة.
القيمة الجوهرية: بعد قراءة هذا المقال، ستتقن 6 استراتيجيات عملية للتحكم في الـ Token المدخل، مع توقعات بتوفير 50-90% من تكاليف الـ Token.
النقاط الجوهرية لتوفير الـ Token في OpenClaw
لنضع فرضية أساسية أولاً: ما نناقشه هنا هو طرق توفير الـ Token دون تغيير النموذج ودون خفض الجودة. أنت تستخدم Claude Opus 4.6 أو GPT-5 بالسعر الكامل، النموذج يظل كما هو، وما نوفره هو في جانب المدخلات (Input).
| الاستراتيجية | نسبة التوفير | صعوبة التنفيذ | الفكرة الجوهرية |
|---|---|---|---|
| عزل المهام في محادثات جديدة | 60-80% | منخفضة | فتح محادثة جديدة لكل مهمة مستقلة لتجنب تراكم التاريخ |
| استرجاع دقيق لكتل الكود | 40-95% | متوسطة | تزويد النموذج بأجزاء الكود ذات الصلة فقط، لا الملف كاملاً |
| تقليم السياق | 30-50% | منخفضة | تنظيف سجل المحادثة غير الضروري يدوياً أو تلقائياً |
| البحث المحلي QMD | 80-90% | متوسطة | بحث متجه محلي، وإرسال الأجزاء ذات الصلة فقط |
| تخزين الموجه مؤقتاً (Prompt Caching) | 80-90% (تكلفة الإدخال) | منخفضة | الاستفادة من التخزين المؤقت لتجنب إعادة إرسال موجهات النظام |
| إيقاف وضع التفكير (Thinking) | 10-50 ضعف | منخفضة | إيقاف وضع التفكير للمهام التي لا تتطلب استنتاجاً |
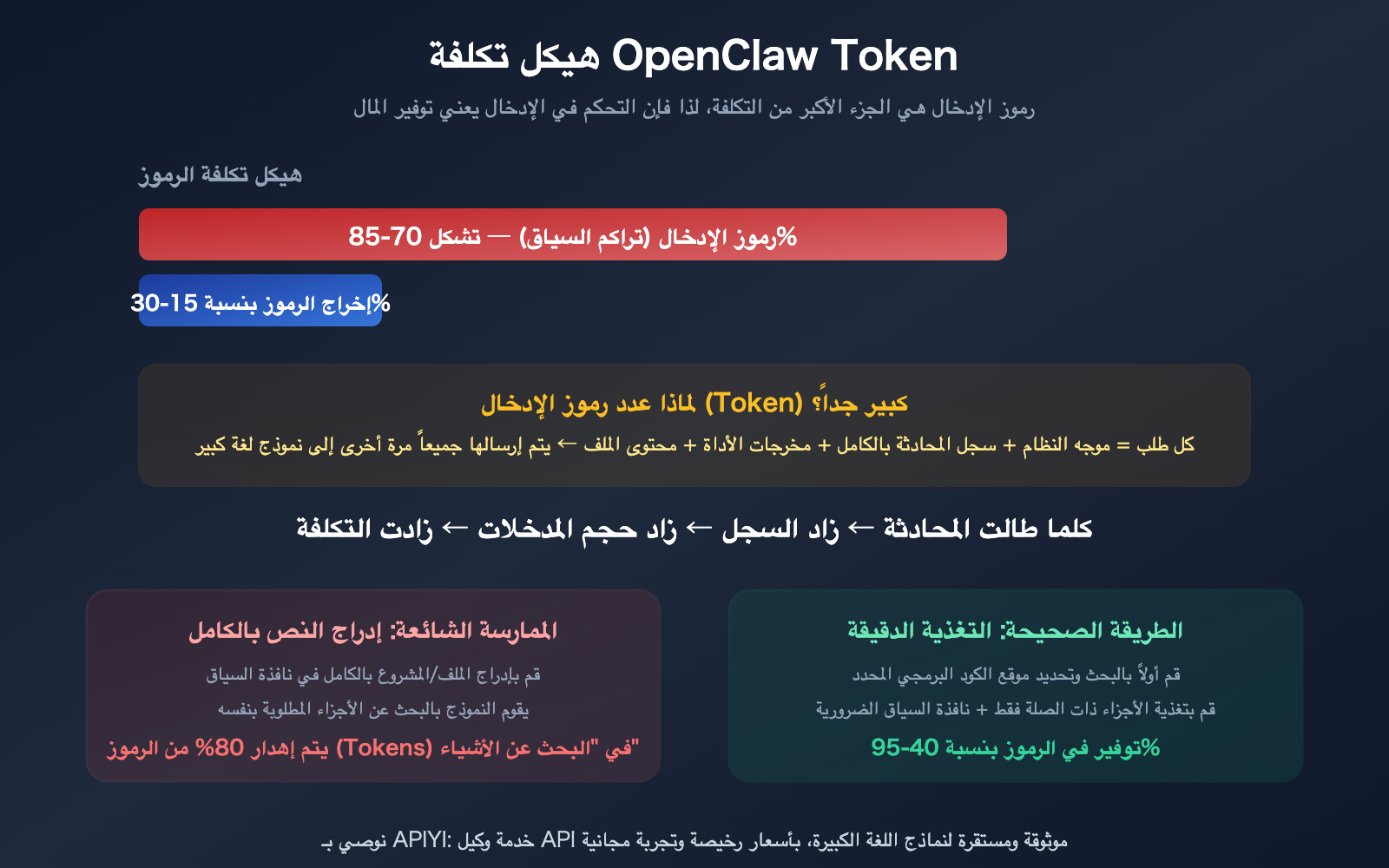
الآلية الأساسية لاستهلاك الـ Token في OpenClaw
فهم كيفية توفير الـ Token يتطلب فهم سبب استهلاك OpenClaw لها بكثرة.
في كل مرة ترسل فيها رسالة في OpenClaw، فإنه لا يرسل رسالتك الحالية فقط، بل يعيد إرسال سجل المحادثة بالكامل إلى النموذج. كلما طالت المحادثة، زاد حجم الـ Token المدخلة في كل طلب.
بشكل أكثر تحديداً، يتضمن الإدخال في الطلب الواحد:
- موجه النظام (System Prompt): التعليمات الأساسية لـ OpenClaw، وعادة ما تكون 2000-5000 Token.
- AGENTS.md / SOUL.md: ملفات إعداد مساحة العمل.
- المهارات (Skills) المحملة: كل مهارة مفعلة تستهلك Token.
- سجل المحادثة الكامل: جميع الرسائل منذ بداية الجلسة وحتى الآن.
- نتائج استدعاء الأدوات: مخرجات كل عملية قراءة للملفات أو تنفيذ للأوامر.
- نتائج استرجاع الذاكرة: المحتوى ذو الصلة الذي تم استرجاعه من مكتبة الذاكرة.
في جلسة OpenClaw مستمرة لمدة 30 دقيقة، قد يصل حجم الـ Token المدخلة للرسالة الأخيرة إلى 100 ألف أو حتى مليون Token، بينما معظم محتوى الـ 29 دقيقة السابقة لم يعد مفيداً للمهمة الحالية.
الاستراتيجية الأولى: فتح محادثات جديدة للمهام المختلفة في OpenClaw
هذه هي الاستراتيجية الأبسط والأكثر فعالية.
لماذا توفر المحادثات الجديدة الـ Token؟
لنفترض أنك قمت بـ 3 مهام في نفس الجلسة: إصلاح خطأ (Bug) A ← كتابة ميزة B ← إعادة هيكلة الوحدة C. عند الوصول للمهمة الثالثة، تتضمن مدخلات النموذج سجل المحادثة بالكامل ونتائج قراءة الملفات للمهمتين السابقتين، وهي معلومات غير مفيدة إطلاقاً لإعادة هيكلة الوحدة C.
في نفس الجلسة:
سجل محادثة المهمة A (20 ألف Token)
+ محتوى ملفات المهمة A (30 ألف Token)
+ سجل محادثة المهمة B (25 ألف Token)
+ محتوى ملفات المهمة B (40 ألف Token)
+ رسالة المهمة C الحالية (5 آلاف Token)
= 120 ألف Token كمدخلات (منها 115 ألف عبارة عن عبء تاريخي)
عند فتح محادثة جديدة:
رسالة المهمة C الحالية (5 آلاف Token)
+ موجه النظام (3 آلاف Token)
= 8 آلاف Token كمدخلات (توفير بنسبة 93%)
أفضل الممارسات في سيناريوهات المحادثة
| السيناريو | هل تفتح محادثة جديدة؟ | السبب |
|---|---|---|
| الانتقال إلى مهمة مختلفة تماماً | نعم | سياق المهمة السابقة غير مفيد إطلاقاً |
| تعديلات تكرارية لنفس الميزة | لا (استمر) | الحاجة إلى سياق النقاش السابق |
| إصلاح أخطاء مختلفة في ملفات مختلفة | نعم | كل خطأ مستقل ولا يحتاج لسياق متقاطع |
| تعديلات متتالية على نفس الوحدة | لا (استمر) | يحتاج النموذج لفهم نية التعديلات السابقة |
| تجاوز المحادثة لـ 20 جولة | نعم (أو ضغط السياق) | تراكم التاريخ أصبح كبيراً جداً |
🎯 نصيحة عملية: معيار بسيط للحكم – إذا وجدت نفسك بحاجة لقول "انسَ ما سبق، لنقم بشيء آخر الآن"، فافتح محادثة جديدة مباشرة.
هذا المبدأ لا ينطبق على OpenClaw فحسب، بل على Claude Code وأدوات البرمجة بالذكاء الاصطناعي الأخرى. كل طلب API مستقل يتم إجراؤه عبر APIYI (apiyi.com) يعتبر "محادثة جديدة" بطبيعته، ولا توجد مشكلة في تراكم السياق.
الاستراتيجية الثانية: الاسترجاع الدقيق لكتل الكود في OpenClaw، دون إغراق النموذج بالنصوص
هذا هو جوهر مقالنا — كيف تجعل النموذج يرى فقط كتل الكود التي تحتاج إلى تعديل، بدلاً من حشو الملف بالكامل أو حتى المشروع بأكمله؟
جوهر المشكلة: لماذا يعد "حشو النص بالكامل" هدراً؟
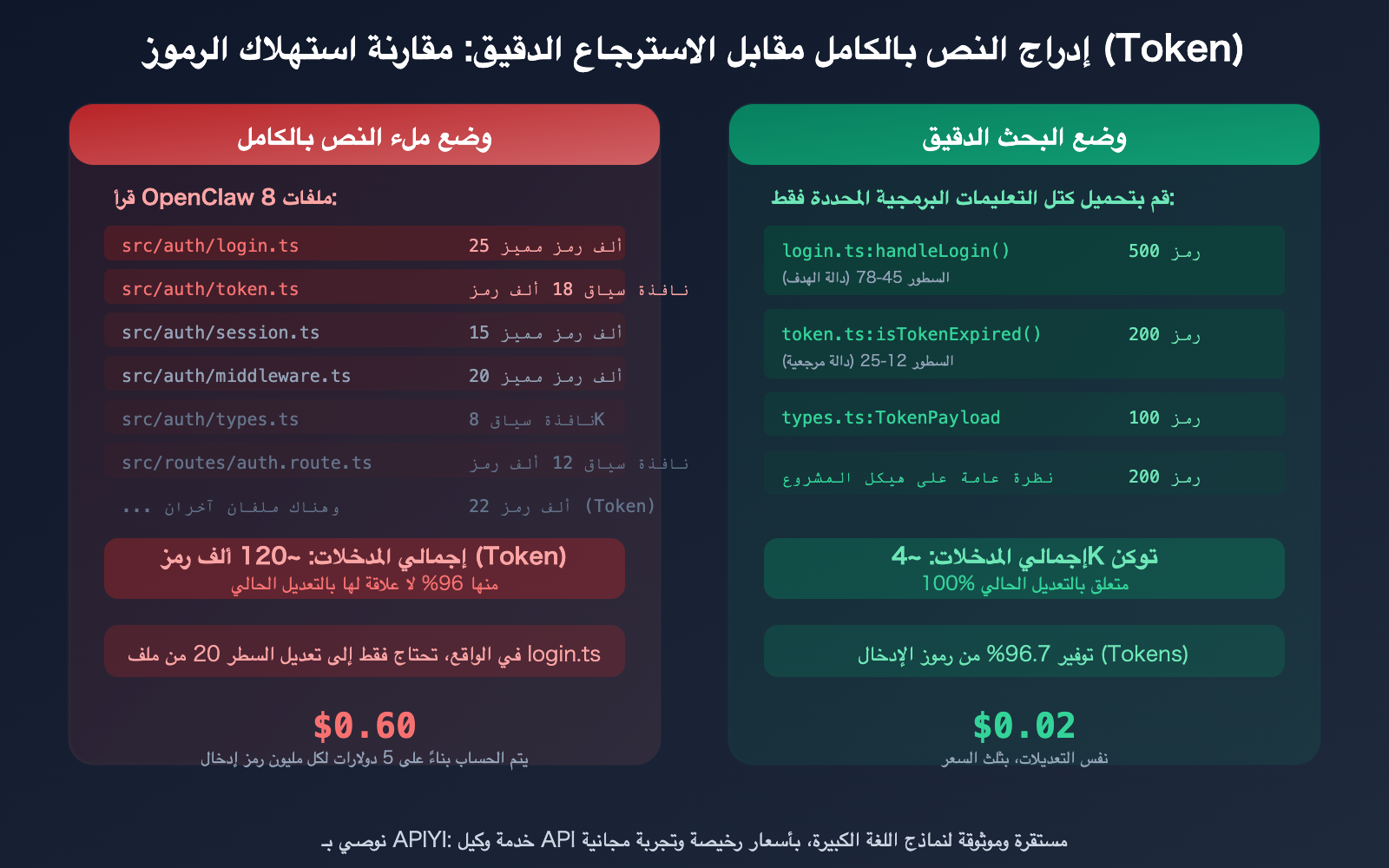
تشير البيانات البحثية إلى أن 80% من الرموز (Tokens) في وكلاء البرمجة المعتمدين على الذكاء الاصطناعي تُهدر في "عملية البحث". سيناريو نموذجي: تطلب من OpenClaw تعديل دالة معينة، فيقوم بقراءة 25 ملفاً فقط للعثور على الدوال الثلاث ذات الصلة — وتتحمل أنت تكلفة الرموز لقراءة تلك الملفات الـ 25 بالكامل.
يحتوي الملف الذي يضم 1000 سطر على حوالي 15,000 إلى 25,000 رمز. إذا كنت تحتاج فقط إلى تعديل 20 سطراً (حوالي 300-500 رمز)، ولكن تم إطعام النموذج بالملف كاملاً، فإن 96-98% من رموز الإدخال قد ضاعت هباءً.
4 طرق للاسترجاع الدقيق لكتل الكود في OpenClaw
الطريقة الأولى: تحديد الملف ورقم السطر بدقة
بدلاً من قول "عدّل وظيفة تسجيل الدخول"، قل "عدّل الدالة handleLogin في الملف src/auth/login.ts من السطر 45 إلى 78". كلما كانت تعليماتك أكثر دقة، قل عدد الملفات التي يقرؤها OpenClaw.
❌ "إصلاح خطأ في تسجيل الدخول"
→ OpenClaw يقرأ أكثر من 10 ملفات، ويستهلك أكثر من 200 ألف رمز
✅ "إصلاح فحص المؤشر الفارغ في الملف src/auth/login.ts عند السطر 52"
→ OpenClaw يقرأ الجزء ذي الصلة من ملف واحد فقط، ويستهلك حوالي 20 ألف رمز
الطريقة الثانية: الاستفادة من البحث الدلالي المحلي عبر QMD
يمكن لـ QMD (قاعدة بيانات الذاكرة السريعة) في OpenClaw بناء فهرس متجه محلياً، واسترجاع مقتطفات الكود ذات الصلة فقط لإرسالها إلى النموذج.
طريقة التفعيل: قم بتشغيل QMD في إعدادات OpenClaw، وسيقوم تلقائياً بفهرسة ملفات مشروعك وسجل المحادثات. عند إجراء استعلام لاحق، سيبحث QMD محلياً عن كتل الكود ذات الصلة ويرسل فقط الأجزاء المطابقة بدقة إلى النموذج.
الطريقة الثالثة: استخدام صيغة @file للإشارة المباشرة
في OpenClaw، يمكنك استخدام صيغة @file للإشارة إلى الملفات بدقة، مما يمنع النموذج من البحث العشوائي:
عدّل الدالة handleLogin في @src/auth/login.ts،
وأضف منطق المعالجة لانتهاء صلاحية refreshToken.
بالرجوع إلى الطريقة isTokenExpired في @src/auth/token.ts.
بهذه الطريقة، سيقوم OpenClaw بتحميل الملفين اللذين حددتهما فقط، بدلاً من مسح دليل src/auth/ بالكامل.
الطريقة الرابعة: توجيه النموذج عبر ملف هيكلية المشروع
اكتب نظرة عامة على هيكلية المشروع في ملف AGENTS.md أو SOUL.md؛ ليعرف OpenClaw "أي وظيفة توجد في أي ملف"، مما يقلل من عمليات المسح الاستكشافي للملفات.
## هيكلية المشروع
- متعلقات المصادقة: src/auth/ (login.ts, token.ts, session.ts)
- إدارة المستخدمين: src/user/ (profile.ts, settings.ts)
- مسارات API: src/routes/ (auth.route.ts, user.route.ts)
هذه النظرة العامة لا تستهلك سوى بضع مئات من الرموز، لكنها توفر على OpenClaw عشرات الآلاف من الرموز التي كانت ستُهدر في مسح الملفات بشكل أعمى.
الاستراتيجيات من 3 إلى 6: تقنيات متقدمة لتوفير الـ Token في OpenClaw
الاستراتيجية الثالثة: تقليم السياق (Context Pruning)
يدعم OpenClaw تقليم السياق يدوياً وتلقائياً. عندما تصبح المحادثة طويلة جداً، يمكنك تنظيف رسائل السجل التي لم تعد بحاجة إليها.
قدم إصدار OpenClaw 2026.3.7 إضافات محرك السياق (Context Engine Plugins)، مما يسمح لإضافات الطرف الثالث بتوفير استراتيجيات بديلة لإدارة السياق (كان هذا الجزء مدمجاً في الكود الأساسي سابقاً). يمكن لإضافة lossless-claw ضغط سجل المحادثة دون فقدان المعلومات الأساسية.
نصائح عملية:
- بعد إكمال كل مهمة فرعية، قم بتنظيف مخرجات استدعاء الأدوات غير ذات الصلة يدوياً.
- اضبط
contextTokens: 50000لتقييد حجم نافذة السياق. - استخدم وظيفة الضغط (compact) لتقليص سجل المحادثة.
الاستراتيجية الرابعة: البحث الدلالي المحلي QMD
يُعد QMD (قاعدة بيانات الذاكرة السريعة) ميزة البحث المتجهي المحلي في OpenClaw. حيث يقوم بإنشاء قاعدة بيانات متجهية على الجهاز المحلي لفهرسة سجل المحادثات والمستندات. عند إجراء استعلام، يتم البحث عن المحتوى ذي الصلة محلياً أولاً، ولا يتم إرسال سوى الأجزاء الأكثر صلة إلى النموذج.
النتيجة: تقليل تكلفة الـ Token للإدخال بنسبة 80-90%.
الاستراتيجية الخامسة: الاستفادة من التخزين المؤقت للموجه (Prompt Caching)
تدعم عائلات نماذج Claude وGPT ميزة التخزين المؤقت للموجه (Prompt Caching)؛ فعندما لا يتغير موجه النظام أو السياق الشائع، يستخدم الـ API تلقائياً النسخة المخزنة مؤقتاً، مما يقلل تكلفة الـ Token للإدخال بنسبة 80-90%.
لكن هناك قيد رئيسي: لا يتم دعم التخزين المؤقت للموجه عند استدعاء Claude عبر تنسيق متوافق مع OpenAI (/v1/chat/completions)، بل يجب استخدام التنسيق الأصلي لـ Anthropic (/v1/messages). إذا كنت تستخدم خدمة APIYI (apiyi.com)، فإن المنصة تدعم التخزين المؤقت للموجه بالتنسيق الأصلي.
الاستراتيجية السادسة: إيقاف التفكير (Thinking) للمهام غير الاستنتاجية
يؤدي وضع التفكير/الاستنتاج (Thinking/Reasoning) إلى زيادة استهلاك الـ Token بمقدار 10-50 ضعفاً. إذا كانت المهمة الحالية لا تتطلب استنتاجاً عميقاً (مثل التنسيق البسيط، نقل الملفات، أو استبدال النصوص)، فإن إيقاف وضع التفكير يمكن أن يوفر الكثير.
| نوع المهمة | هل يتطلب التفكير؟ | فرق الـ Token |
|---|---|---|
| تحليل الأخطاء المعقدة | نعم | استهلاك طبيعي |
| تصميم البنية | نعم | استهلاك طبيعي |
| تنسيق بسيط | لا | توفير 10-50 ضعفاً عند الإيقاف |
| نقل/إعادة تسمية الملفات | لا | توفير 10-50 ضعفاً عند الإيقاف |
| توليد كود نمطي | حسب الحالة | يمكن إيقافه للقوالب البسيطة |
تلميح: تحل ميزة ضغط السياق في Claude Code وتقليم السياق في OpenClaw نفس المشكلة، وهي التحكم في تراكم الـ Token للإدخال. إذا كنت تستخدم الأداتين معاً، يمكنك إدارة رصيد استدعاء الـ API بشكل موحد عبر APIYI (apiyi.com).
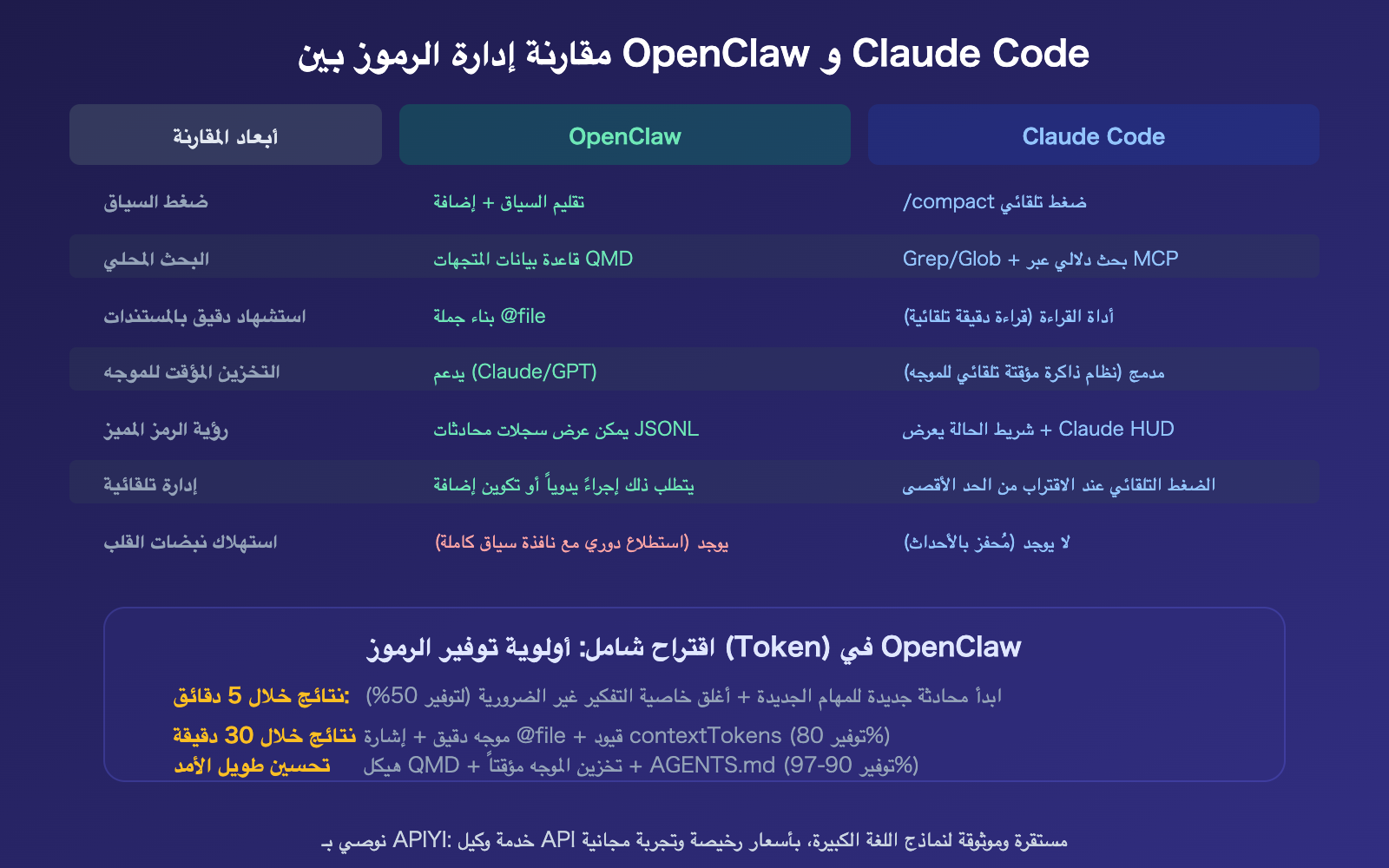
مقارنة توفير الـ Token بين OpenClaw و Claude Code
يواجه كلا الأداتين نفس المشكلة، لكن الحلول تختلف.
الأسئلة الشائعة
س1: ماذا أفعل إذا كان النموذج لا يعرف سياق المشروع بعد بدء محادثة جديدة؟
استخدم نظام الذاكرة (Memory) في OpenClaw وملف AGENTS.md. تقوم الذاكرة تلقائياً باسترجاع معلومات سياق المشروع ذات الصلة في الجلسات الجديدة (عن طريق إرسال الأجزاء الأكثر أهمية فقط، بدلاً من كامل سجل المحادثة). قم بكتابة هيكل المشروع والاتفاقيات الرئيسية في ملف AGENTS.md ليتم تحميله تلقائياً في كل محادثة جديدة—وهذا أكثر كفاءة بكثير من إدراج سجل محادثة مكون من 20 جولة.
س2: كيف أعرف مقدار استهلاك الـ Token في الجلسة الحالية؟
يتم حفظ سجلات محادثات OpenClaw في ملفات JSONL داخل المجلد .openclaw/agents.main/sessions/ حيث يمكنك الاطلاع مباشرة على عدد الـ Token لكل طلب. الطريقة الأكثر ملاءمة هي استخدام لوحة تحكم الاستهلاك الخاصة بمزود الـ API—عند الاستدعاء عبر خدمة وكيل API من APIYI (apiyi.com)، يمكنك رؤية الاستهلاك الدقيق للـ Token والتكاليف لكل طلب في الخلفية.
س3: ما الفرق بين QMD والبحث المباشر باستخدام grep؟
أداة grep تقوم بمطابقة دقيقة—إذا بحثت عن "handleLogin" ستجد فقط الأماكن التي تحتوي على هذا النص. أما QMD فهو بحث دلالي (Semantic Search)—إذا بحثت عن "معالجة أخطاء تسجيل دخول المستخدم"، فسيجد جميع كتل الكود ذات الصلة دلالياً، حتى لو لم تكن كلمات "تسجيل دخول" أو "معالجة أخطاء" موجودة في الكود. دقة البحث الدلالي أعلى، مما يقلل من المحتوى غير ذي الصلة الذي يتم إرساله للنموذج، وبالتالي يوفر المزيد من الـ Token.
س4: لماذا تستهلك خاصية Heartbeat الكثير من الـ Token؟
تقوم آلية Heartbeat (نبض القلب) في OpenClaw بفحص حالة المهمة بشكل دوري. إذا تم ضبط الفاصل الزمني قصيراً جداً (مثلاً كل 5 دقائق)، فسيتم إرسال سياق المحادثة الكامل إلى النموذج مع كل نبضة—وقد لاحظ بعض المستخدمين أن ميزة فحص البريد التلقائي استهلكت 50 دولاراً في يوم واحد. الحل: قم بزيادة الفاصل الزمني للنبضات، أو أوقف خاصية Heartbeat عندما لا تكون بحاجة للمراقبة التلقائية.
الخلاصة
النقاط الجوهرية لتوفير الـ Token في OpenClaw (دون تغيير النموذج أو خفض الجودة):
- الـ Token المدخلة هي الجزء الأكبر من التكلفة (70-85%): إعادة إرسال كامل سجل المحادثة في كل طلب تجعل المحادثات الطويلة مكلفة. أبسط طريقة للتوفير هي بدء محادثات جديدة للمهام المختلفة.
- البحث الدقيق عن كتل الكود هو أكبر عامل مؤثر: الانتقال من "حشو كامل النص" (120 ألف Token) إلى "التغذية الدقيقة" (4 آلاف Token) يوفر 96% من التكلفة لنفس التعديلات. الطريقة: تحديد أرقام الأسطر بدقة، استخدام إشارات @file، البحث الدلالي بـ QMD، وتحديد الهيكل في AGENTS.md.
- مسار التحسين على ثلاث مراحل: نتائج خلال 5 دقائق (محادثة جديدة + إيقاف Thinking، توفير 50%) ← نتائج خلال 30 دقيقة (توجيهات دقيقة + تقييد السياق، توفير 80%) ← على المدى الطويل (QMD + التخزين المؤقت Caching، توفير 97%).
نوصي بإدارة استدعاءات API الخاصة بـ OpenClaw عبر APIYI (apiyi.com)، حيث توفر المنصة إحصائيات دقيقة لاستهلاك الـ Token ومراقبة التكاليف، مما يساعدك على قياس الأثر الفعلي لكل تحسين تقوم به.
📚 المراجع
-
دليل استخدام الرموز (Tokens) والتحكم في التكاليف لـ OpenClaw: الوثائق الرسمية لإدارة الرموز.
- الرابط:
docs.openclaw.ai/reference/token-use - الوصف: يتضمن إعدادات
contextTokensوتحسين نبضات القلب (Heartbeat).
- الرابط:
-
تجربة عملية لتقليل استهلاك الرموز في OpenClaw: من 600 دولار إلى 20 دولار: إطار عمل كامل للتحسين عبر ثلاث مراحل.
- الرابط:
blog.laozhang.ai/en/posts/openclaw-save-money-practical-guide - الوصف: يتضمن معاملات الإعداد المحددة ونسب التوفير المتوقعة.
- الرابط:
-
وكلاء البرمجة بالذكاء الاصطناعي يهدرون 80% من الرموز في البحث عن الملفات: دراسة حول دقة السياق.
- الرابط:
medium.com/@jakenesler/context-compression-to-reduce-llm-costs - الوصف: يشرح لماذا يعد الاسترجاع الدقيق أكثر فعالية من زيادة نافذة السياق.
- الرابط:
-
مركز وثائق APIYI: إحصائيات استخدام الرموز ومراقبة التكاليف.
- الرابط:
docs.apiyi.com - الوصف: يدعم إدارة استدعاءات API لكل من OpenClaw و Claude Code.
- الرابط:
المؤلف: الفريق التقني لـ APIYI
تبادل الخبرات: نرحب بمناقشاتكم في قسم التعليقات، وللمزيد من المعلومات يمكنكم زيارة مركز وثائق APIYI عبر الرابط docs.apiyi.com