Anmerkung des Autors: Ohne auf günstigere Modell-Kanäle auszuweichen, erkläre ich im Detail, wie OpenClaw durch die Kontrolle der Eingabe-Token-Länge Kosten spart: Isolierung neuer Dialogaufgaben, präzise Code-Block-Suche statt Volltext-Einspeisung, Kontext-Kürzung, lokale QMD-Suche und 6 weitere Strategien.
OpenClaw ist berüchtigt für seinen hohen Token-Verbrauch – manche Nutzer verbrauchen an einem Tag 21,5 Millionen Token, was zu monatlichen Rechnungen von über 600 $ führt. Die erste Reaktion vieler ist der Wechsel zu günstigeren Modell-Anbietern, doch das geht zulasten der Qualität. Der wahre Weg zur Token-Einsparung liegt in der Kontrolle der Eingabeseite – die Menge des Kontexts, den Sie dem Modell füttern, ist der entscheidende Kostenfaktor. Dieser Artikel konzentriert sich auf eine Kernfrage: Wie lässt sich die Eingabe-Token-Menge von "Volltext-Einspeisung" auf "präzise Zufuhr" reduzieren, ohne das Modell zu wechseln oder die Qualität zu mindern?
Kernnutzen: Nach der Lektüre dieses Artikels beherrschen Sie 6 praktische Strategien zur Kontrolle der Eingabe-Token, mit denen Sie voraussichtlich 50–90 % Ihrer Token-Kosten einsparen können.
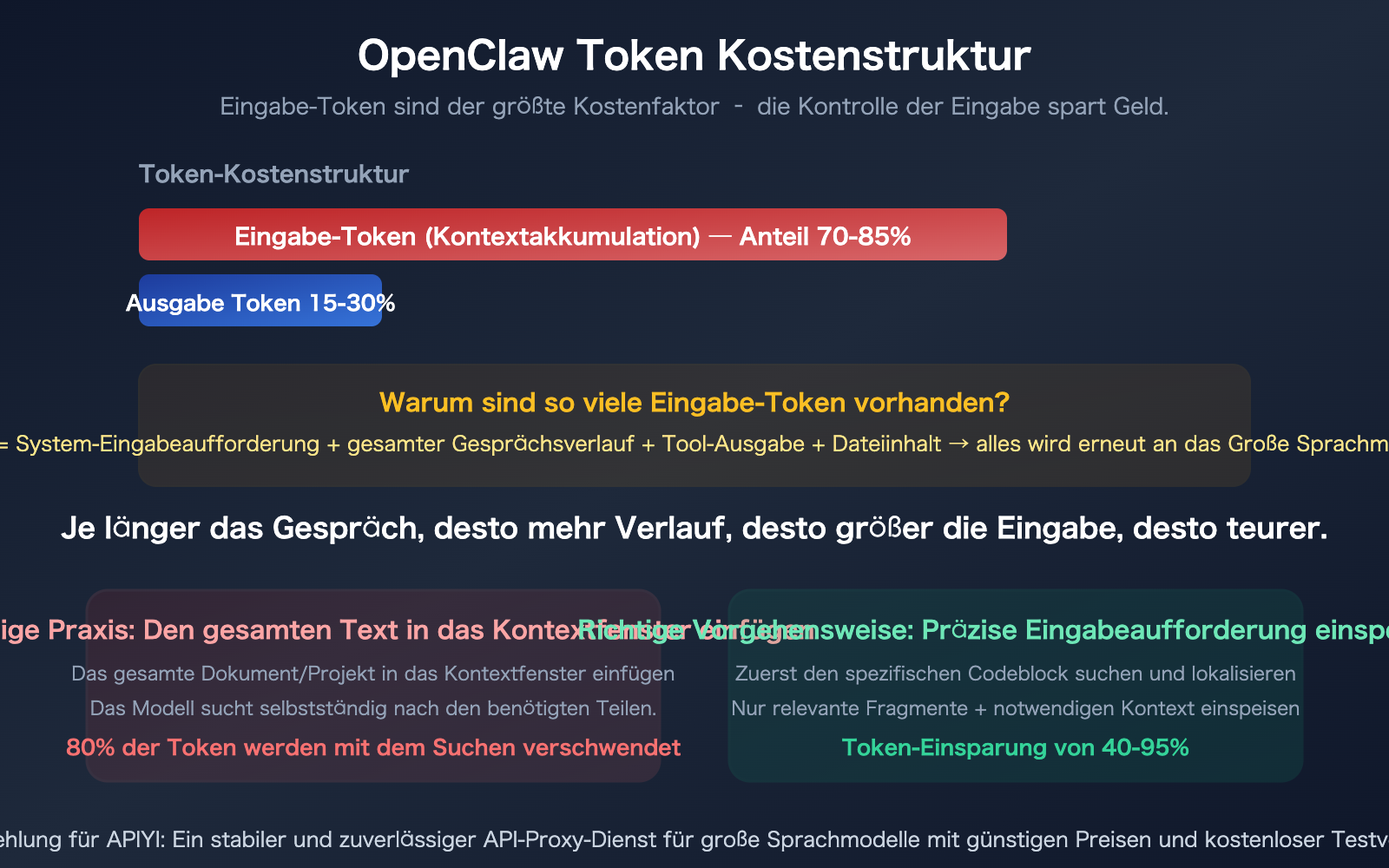
OpenClaw: Kernpunkte zur Token-Einsparung
Zuerst eine wichtige Voraussetzung: In diesem Artikel geht es um Methoden zur Token-Einsparung, ohne das Modell zu wechseln oder die Qualität zu mindern. Sie nutzen weiterhin das reguläre Claude Opus 4.6 oder GPT-5; die Einsparungen erfolgen rein auf der Eingabeseite.
| Strategie | Einsparungsrate | Implementierungsaufwand | Kernkonzept |
|---|---|---|---|
| Neue Chats für Aufgaben | 60-80% | Niedrig | Für jede Aufgabe einen neuen Chat starten, um Altlasten zu vermeiden |
| Präzise Code-Suche | 40-95% | Mittel | Nur relevante Code-Schnipsel übergeben, nicht den gesamten Text |
| Kontext-Bereinigung | 30-50% | Niedrig | Manuelles oder automatisches Löschen unnötiger Chat-Verläufe |
| QMD lokale Suche | 80-90% | Mittel | Lokale Vektorsuche, nur relevante Fragmente senden |
| Prompt Caching | 80-90% (Eingabekosten) | Niedrig | Cache nutzen, um wiederholtes Senden von System-Prompts zu vermeiden |
| Thinking-Modus deaktivieren | 10-50x | Niedrig | Thinking-Modus bei Nicht-Schlussfolgerungsaufgaben ausschalten |
Die zugrunde liegenden Mechanismen des Token-Verbrauchs in OpenClaw
Um Token zu sparen, muss man verstehen, warum OpenClaw überhaupt so viele Token verbraucht.
Jedes Mal, wenn Sie eine Nachricht in OpenClaw senden, wird nicht nur diese eine Nachricht übertragen – es wird der gesamte Chat-Verlauf erneut an das Modell gesendet. Je länger das Gespräch, desto größer wird die Eingabe-Token-Anzahl bei jeder Anfrage.
Im Detail enthält eine Anfrage folgende Eingaben:
- System-Prompt: Die Kernanweisungen von OpenClaw, normalerweise 2000-5000 Token.
- AGENTS.md / SOUL.md: Konfigurationsdateien des Arbeitsbereichs.
- Geladene Skills: Jeder aktivierte Skill belegt Token.
- Vollständiger Chat-Verlauf: Alle Nachrichten vom Beginn der Sitzung bis jetzt.
- Ergebnisse von Werkzeugaufrufen: Ausgaben von Dateilesevorgängen oder Befehlsausführungen.
- Memory-Suchergebnisse: Relevante Inhalte, die aus dem Gedächtnisspeicher abgerufen wurden.
In einer 30-minütigen OpenClaw-Sitzung kann die Eingabe der letzten Nachricht bereits 100.000 oder sogar 1 Million Token erreichen – obwohl der Großteil der ersten 29 Minuten für die aktuelle Aufgabe längst irrelevant ist.
Strategie 1: Neue Chats für unterschiedliche Aufgaben in OpenClaw
Dies ist die einfachste und effektivste Strategie.
Warum neue Chats Token sparen
Angenommen, Sie erledigen drei Aufgaben im selben Chat: Bug A beheben → Funktion B schreiben → Modul C refactoren. Bei der dritten Aufgabe enthält die Eingabe des Modells den gesamten Verlauf und alle Dateiinhalte der ersten beiden Aufgaben – obwohl diese für das Refactoring von Modul C völlig nutzlos sind.
Im selben Chat:
Chat-Verlauf Aufgabe A (20K Token)
+ Dateiinhalte Aufgabe A (30K Token)
+ Chat-Verlauf Aufgabe B (25K Token)
+ Dateiinhalte Aufgabe B (40K Token)
+ Aktuelle Nachricht Aufgabe C (5K Token)
= 120K Token Eingabe (davon sind 115K historischer Ballast)
Neuer Chat:
Aktuelle Nachricht Aufgabe C (5K Token)
+ System-Prompt (3K Token)
= 8K Token Eingabe (93% Ersparnis)
Best Practices für Chat-Szenarien
| Szenario | Neuer Chat? | Grund |
|---|---|---|
| Wechsel zu einer völlig anderen Aufgabe | Ja | Kontext der vorherigen Aufgabe ist nutzlos |
| Iterative Anpassung derselben Funktion | Nein | Kontext der vorherigen Diskussion wird benötigt |
| Behebung verschiedener Bugs in verschiedenen Dateien | Ja | Jeder Bug ist isoliert, kein übergreifender Kontext nötig |
| Kontinuierliche Änderung desselben Moduls | Nein | Modell muss die Absicht der vorherigen Änderungen verstehen |
| Chat überschreitet 20 Runden | Ja oder Komprimierung | Historische Ansammlung ist bereits zu groß |
🎯 Praxistipp: Ein einfaches Entscheidungskriterium – wenn Sie sagen müssen: "Vergiss das Vorherige, mach jetzt etwas anderes", dann starten Sie direkt einen neuen Chat.
Dieses Prinzip gilt nicht nur für OpenClaw, sondern auch für Claude Code und andere KI-Codierungstools. Jeder unabhängige API-Aufruf, der über APIYI (apiyi.com) getätigt wird, ist von Natur aus ein "neuer Chat" und leidet nicht unter Kontext-Ansammlungen.
Strategie 2: Präzise Code-Abfrage mit OpenClaw statt Volltext-Upload
Dies ist der Kernpunkt dieses Artikels – wie erreicht man, dass das Modell nur die tatsächlich zu ändernden Codeblöcke sieht, anstatt das gesamte Projekt oder ganze Dateien zu übermitteln?
Das Problem: Warum "Volltext-Upload" Ressourcen verschwendet
Untersuchungen zeigen, dass KI-Coding-Agents 80 % ihrer Token mit der "Suche" verschwenden. Ein typisches Szenario: Sie beauftragen OpenClaw mit der Änderung einer Funktion, und der Agent liest erst einmal 25 Dateien, nur um die drei relevanten Funktionen zu finden – die Token-Kosten für das Lesen aller 25 Dateien gehen zu Ihren Lasten.
Eine 1000 Zeilen lange Datei umfasst etwa 15.000 bis 25.000 Token. Wenn Sie nur 20 Zeilen (ca. 300–500 Token) ändern müssen, aber die gesamte Datei an das Modell gesendet wird, sind 96–98 % der Eingabe-Token verschwendet.
4 Methoden für die präzise Code-Abfrage mit OpenClaw
Methode 1: Dateien und Zeilennummern explizit angeben
Sagen Sie nicht einfach "Login-Funktion reparieren", sondern "Ändere die Funktion handleLogin in src/auth/login.ts in den Zeilen 45-78". Je präziser die Anweisung, desto weniger Dateien muss OpenClaw lesen.
❌ "Login-Bug beheben"
→ OpenClaw liest 10+ Dateien, verbraucht 200K+ Token
✅ "Null-Pointer-Check in src/auth/login.ts in Zeile 52 reparieren"
→ OpenClaw liest nur den relevanten Teil einer Datei, verbraucht ~20K Token
Methode 2: Lokale semantische Suche mit QMD
Die QMD (Quick Memory Database) von OpenClaw erstellt lokal einen Vektor-Index. Nach der Suche nach relevanten Code-Fragmenten wird nur der wichtigste Inhalt an das Modell gesendet.
Aktivierung: Schalten Sie QMD in den OpenClaw-Einstellungen ein. Es indiziert automatisch Ihre Projektdateien und den Gesprächsverlauf. Bei zukünftigen Abfragen findet QMD lokal die passenden Codeblöcke und sendet nur diese präzisen Fragmente an das Modell.
Methode 3: Gezielte Referenzierung mit der @file-Syntax
In OpenClaw können Sie die @file-Syntax verwenden, um Dateien präzise zu referenzieren und zu verhindern, dass das Modell eigenständig suchen muss:
Ändere die handleLogin-Funktion in @src/auth/login.ts,
um die Logik für abgelaufene Refresh-Tokens hinzuzufügen.
Siehe dazu die Methode isTokenExpired in @src/auth/token.ts.
Auf diese Weise lädt OpenClaw nur die zwei von Ihnen angegebenen Dateien, anstatt das gesamte src/auth/-Verzeichnis zu scannen.
Methode 4: Führung durch Projektstruktur-Dateien
Beschreiben Sie die Projektstruktur in einer AGENTS.md oder SOUL.md, damit OpenClaw weiß, "welche Funktion in welcher Datei liegt". Dies reduziert explorative Dateiscans.
## Projektstruktur
- Authentifizierung: src/auth/ (login.ts, token.ts, session.ts)
- Benutzerverwaltung: src/user/ (profile.ts, settings.ts)
- API-Routen: src/routes/ (auth.route.ts, user.route.ts)
Diese Übersicht verbraucht nur wenige hundert Token, erspart OpenClaw aber zehntausende Token für blindes Scannen.
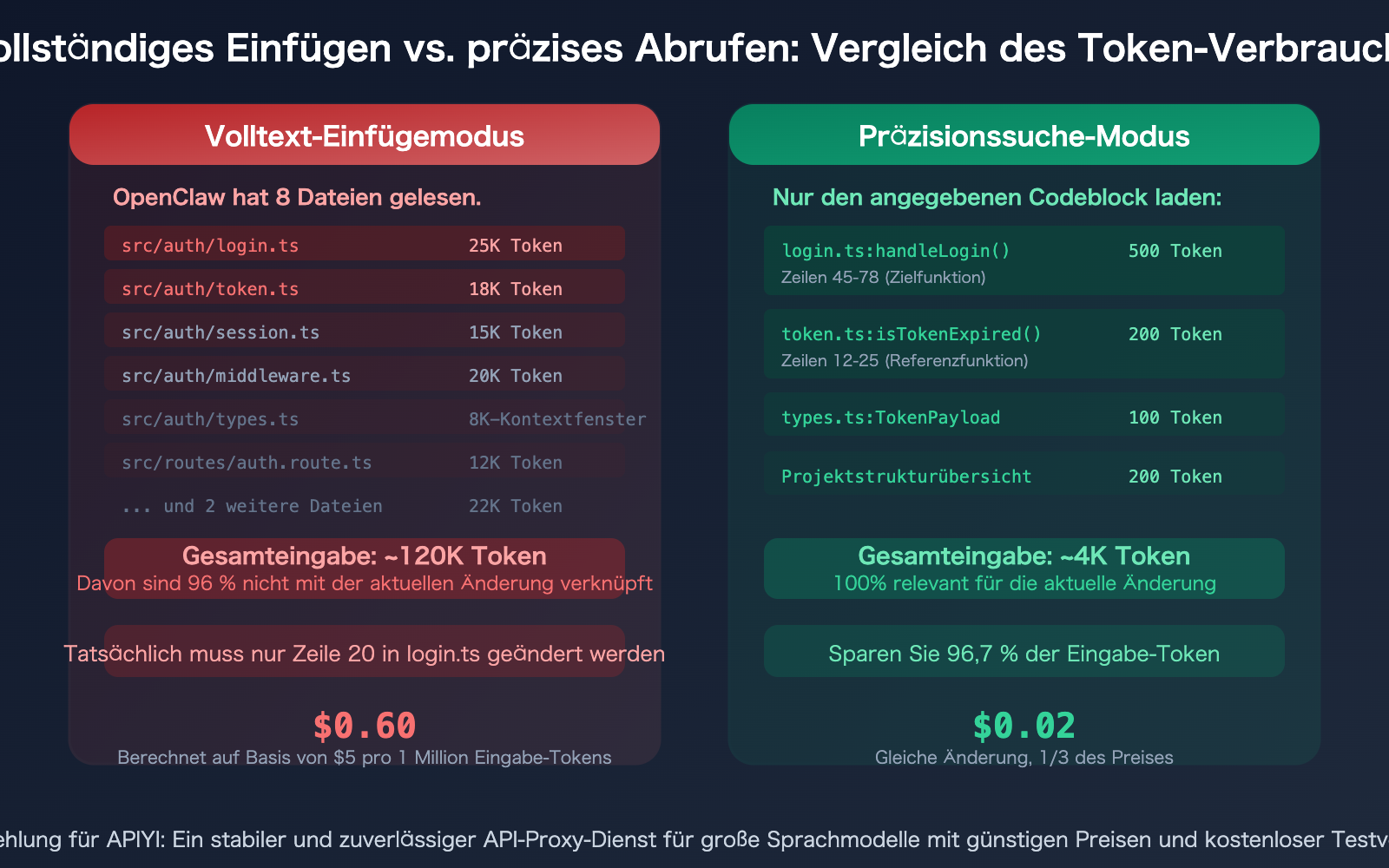
Strategien drei bis sechs: Fortgeschrittene Token-Spar-Tipps für OpenClaw
Strategie drei: Kontext-Bereinigung (Context Pruning)
OpenClaw unterstützt sowohl manuelle als auch automatische Kontext-Bereinigung. Wenn Unterhaltungen zu lang werden, können nicht mehr benötigte Nachrichten aus dem Verlauf entfernt werden.
Mit OpenClaw 2026.3.7 wurden Context Engine Plugins eingeführt, die es Drittanbietern ermöglichen, alternative Strategien zur Kontextverwaltung anzubieten (früher war dies fest im Kern verankert). Das lossless-claw-Plugin kann den Gesprächsverlauf komprimieren, ohne dabei wichtige Informationen zu verlieren.
Praktische Tipps:
- Bereinigen Sie nach Abschluss einer Teilaufgabe manuell die Ausgaben irrelevanter Tool-Aufrufe.
- Begrenzen Sie das Kontextfenster mit
contextTokens: 50000. - Nutzen Sie die Compact-Funktion zur Komprimierung des Gesprächsverlaufs.
Strategie vier: QMD lokale semantische Suche
QMD (Quick Memory Database) ist die lokale Vektorsuchfunktion von OpenClaw. Sie erstellt eine Vektordatenbank auf dem lokalen Gerät, um den Gesprächsverlauf und Dokumente zu indizieren. Bei einer Anfrage wird zuerst lokal nach relevanten Inhalten gesucht, sodass nur die wichtigsten Fragmente an das Modell gesendet werden.
Ergebnis: Reduzierung der Input-Token-Kosten um 80-90 %.
Strategie fünf: Nutzung von Prompt Caching
Sowohl Claude als auch die GPT-Modellfamilie unterstützen Prompt Caching – wenn System-Prompts oder häufig genutzter Kontext unverändert bleiben, verwendet die API automatisch die zwischengespeicherte Version, was die Kosten für Input-Token um 80-90 % senkt.
Ein wichtiger Hinweis: Beim Aufruf von Claude über das OpenAI-kompatible Format (/v1/chat/completions) wird Prompt Caching nicht unterstützt; Sie müssen das native Anthropic-Format (/v1/messages) verwenden. Wenn Sie den Dienst über APIYI (apiyi.com) nutzen, unterstützt die Plattform das native Prompt Caching.
Strategie sechs: Thinking bei Nicht-Inferenz-Aufgaben deaktivieren
Der Thinking/Reasoning-Modus lässt den Token-Verbrauch um das 10- bis 50-fache ansteigen. Wenn die aktuelle Aufgabe keine tiefgreifende Schlussfolgerung erfordert (z. B. einfache Formatierung, Verschieben von Dateien, Textersetzung), spart das Deaktivieren des Thinking-Modus erheblich Kosten.
| Aufgabentyp | Thinking erforderlich? | Token-Unterschied |
|---|---|---|
| Komplexe Bug-Analyse | Ja | Normaler Verbrauch |
| Architektur-Design | Ja | Normaler Verbrauch |
| Einfache Formatierung | Nein | 10-50x Ersparnis |
| Datei verschieben/umbenennen | Nein | 10-50x Ersparnis |
| Boilerplate-Code generieren | Je nach Fall | Bei einfachen Vorlagen deaktivierbar |
Hinweis: Die Kontext-Kompaktierung von Claude Code und die Kontext-Bereinigung von OpenClaw lösen dasselbe Problem – die Kontrolle der kumulierten Input-Token. Wenn Sie beide Tools verwenden, können Sie Ihre API-Kontingente zentral über APIYI (apiyi.com) verwalten.
Vergleich: Token-Einsparung bei OpenClaw vs. Claude Code
Beide Tools adressieren dieselbe Herausforderung, verfolgen jedoch unterschiedliche Lösungsansätze.

Häufig gestellte Fragen (FAQ)
Q1: Was tun, wenn das Modell nach Beginn einer neuen Unterhaltung den Projektkontext nicht kennt?
Nutzen Sie das Memory-System von OpenClaw und die Datei AGENTS.md. Das Memory-System ruft automatisch relevante Projektkontextinformationen in neuen Sitzungen ab (es werden nur die relevantesten Fragmente gesendet, nicht der gesamte Verlauf). Wenn Sie die Projektstruktur und wichtige Konventionen in AGENTS.md hinterlegen, werden diese bei jeder neuen Sitzung automatisch geladen – das ist wesentlich effizienter, als den gesamten Verlauf von 20 Gesprächsrunden mitzuschleppen.
Q2: Wie kann ich den Token-Verbrauch der aktuellen Sitzung einsehen?
Die Gesprächsprotokolle von OpenClaw werden in JSONL-Dateien im Verzeichnis .openclaw/agents.main/sessions/ gespeichert; dort können Sie die Token-Anzahl jeder Anfrage direkt einsehen. Noch bequemer ist das Nutzungs-Dashboard Ihres API-Anbieters – bei einem Modellaufruf über APIYI (apiyi.com) können Sie im Backend den exakten Token-Verbrauch und die Kosten jeder Anfrage nachverfolgen.
Q3: Was ist der Unterschied zwischen QMD und einer direkten Suche mit grep?
grep führt eine exakte Übereinstimmung durch – wenn Sie nach "handleLogin" suchen, finden Sie nur Stellen, die genau diese Zeichenfolge enthalten. QMD hingegen ist eine semantische Suche – wenn Sie nach "Fehlerbehandlung bei der Benutzeranmeldung" suchen, findet es alle semantisch relevanten Codeblöcke, selbst wenn die Begriffe "Anmeldung" oder "Fehlerbehandlung" gar nicht im Code vorkommen. Die semantische Suche ist präziser, reduziert den irrelevanten Inhalt für das Modell und spart somit deutlich mehr Token.
Q4: Warum verbraucht der Heartbeat so viele Token?
Der Heartbeat-Mechanismus von OpenClaw prüft regelmäßig den Aufgabenstatus. Wenn das Intervall zu kurz eingestellt ist (z. B. alle 5 Minuten), wird bei jedem Heartbeat der vollständige Sitzungskontext an das Modell gesendet – einige Nutzer haben berichtet, dass die automatische E-Mail-Prüfung so 50 $ an einem Tag verbraucht hat. Lösung: Verlängern Sie das Heartbeat-Intervall oder pausieren Sie den Heartbeat, wenn keine automatische Überwachung erforderlich ist.
Zusammenfassung
Die Kernpunkte, um mit OpenClaw Token zu sparen (ohne das Modell zu wechseln oder die Qualität zu mindern):
- Eingabe-Token sind der größte Kostenfaktor (70-85 %): Bei jeder Anfrage den gesamten Gesprächsverlauf erneut zu senden, macht Unterhaltungen mit zunehmender Dauer teurer. Der einfachste Weg zum Sparen: Starten Sie für unterschiedliche Aufgaben neue Unterhaltungen.
- Präzises Abrufen von Codeblöcken ist der größte Hebel: Von "alles hineinstopfen" (120K Token) zu "gezielte Eingabe" (4K Token) spart bei der gleichen Änderung 96 %. Methoden: Geben Sie explizit Dateizeilennummern an, nutzen Sie @file-Referenzen, QMD-semantische Suche und die Strukturdeklaration in AGENTS.md.
- Dreistufiger Optimierungspfad: 5 Minuten Aufwand (neue Unterhaltung + Thinking ausschalten, spart 50 %) → 30 Minuten Aufwand (präzise Anweisungen + Kontextbegrenzung, spart 80 %) → Langfristig (QMD + Caching, spart 97 %).
Wir empfehlen, die API-Aufrufe von OpenClaw über APIYI (apiyi.com) zu verwalten. Die Plattform bietet eine präzise Statistik zum Token-Verbrauch und eine Kostenüberwachung, damit Sie den tatsächlichen Effekt jeder Optimierung quantifizieren können.
📚 Referenzmaterialien
-
OpenClaw Token-Nutzung und Kostenkontrollleitfaden: Offizielle Dokumentation zur Token-Verwaltung
- Link:
docs.openclaw.ai/reference/token-use - Beschreibung: Enthält Konfigurationen für contextTokens und Heartbeat-Optimierung
- Link:
-
OpenClaw Token-Einsparungen in der Praxis: Von 600 $ auf 20 $: Vollständiges dreistufiges Optimierungs-Framework
- Link:
blog.laozhang.ai/en/posts/openclaw-save-money-practical-guide - Beschreibung: Enthält spezifische Konfigurationsparameter und erwartete Einsparungsraten
- Link:
-
KI-Coding-Agenten: 80 % der Token-Verschwendung durch Suche: Studie zur Kontextgenauigkeit
- Link:
medium.com/@jakenesler/context-compression-to-reduce-llm-costs - Beschreibung: Erklärt, warum präzises Retrieval effektiver ist als die bloße Vergrößerung des Kontextfensters
- Link:
-
APIYI-Dokumentationszentrum: Token-Nutzungsstatistiken und Kostenüberwachung
- Link:
docs.apiyi.com - Beschreibung: Unterstützt die Verwaltung von Modellaufrufen für OpenClaw und Claude Code
- Link:
Autor: APIYI Technik-Team
Technischer Austausch: Diskutieren Sie gerne in den Kommentaren; weitere Informationen finden Sie im APIYI-Dokumentationszentrum unter docs.apiyi.com