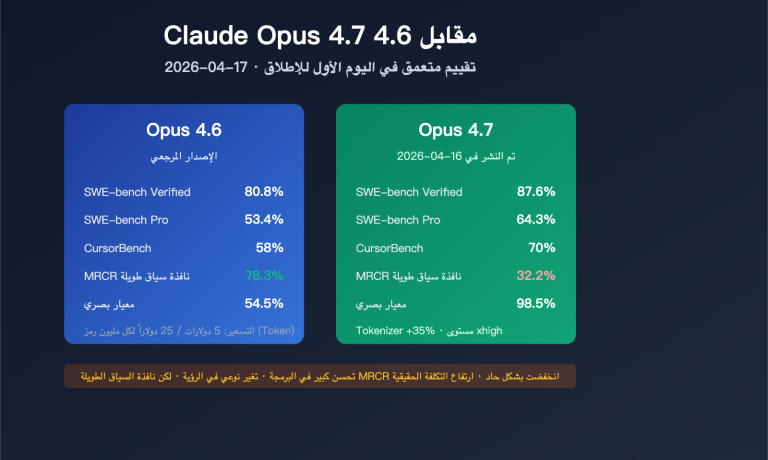
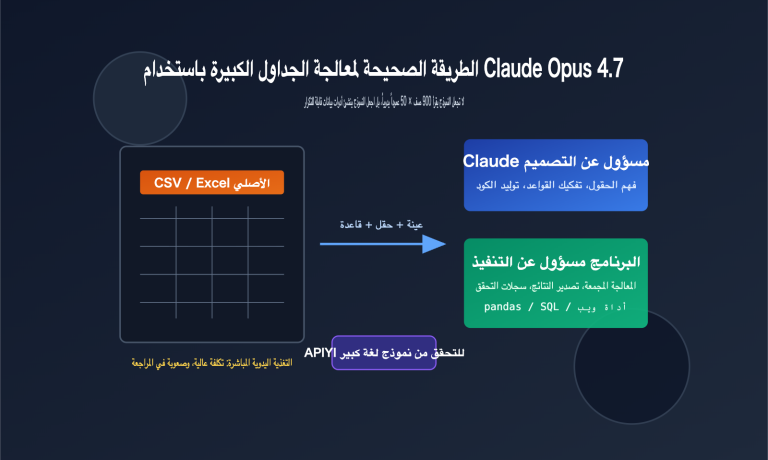
بحلول عام 2026، ستكون 41% من عمليات رفع الكود (Code Commits) ناتجة عن مساعدة الذكاء الاصطناعي، ولكن معدل العيوب في الكود الذي يولده الذكاء الاصطناعي أعلى بـ 1.7 ضعف مقارنة بالكود المكتوب بشرياً. ومع تسارع وتيرة توليد الكود، أصبحت قدرة مراجعة الكود غير كافية بشكل حاد، حيث يُتوقع حدوث فجوة في الجودة بنسبة 40% بحلول عام 2026.
لم تعد مراجعة الكود بواسطة الذكاء الاصطناعي خياراً بين "القيام به أو عدمه"، بل أصبحت مسألة "كيفية القيام به بشكل صحيح". سنستعرض في هذا المقال 7 ممارسات مثالية مُثبتة، مع تحليل معمق لسبب كون نموذجي Claude Opus 4.6 و Sonnet 4.6 هما الأنسب حالياً لمراجعة الكود.
القيمة الجوهرية: بعد قراءة هذا المقال، ستتقن سير العمل الكامل لمراجعة الكود بواسطة الذكاء الاصطناعي، وستعرف كيفية اختيار النموذج الأنسب لرفع جودة الكود في فريقك.
واقع مراجعة الكود بواسطة الذكاء الاصطناعي: لماذا أصبح الاهتمام بها ضرورة الآن
تحديات مراجعة الكود في عام 2026
| التحدي | البيانات | التأثير |
|---|---|---|
| طفرة في كود الذكاء الاصطناعي | 41% من عمليات الإرسال (Commits) مولدة بمساعدة الذكاء الاصطناعي | زيادة هائلة في متطلبات المراجعة |
| معدل عيوب كود الذكاء الاصطناعي | أعلى بـ 1.7 مرة من الكود البشري | الحاجة إلى مراجعة أكثر صرامة |
| فجوة الجودة | توقعات بظهور فجوة بنسبة 40% بحلول 2026 | قدرة المراجعة لا تواكب سرعة التوليد |
| المخاطر الأمنية | 45% من كود الذكاء الاصطناعي يتضمن ثغرات OWASP Top 10 | المراجعة الأمنية أصبحت ملحة للغاية |
| معدل قبول الاقتراحات | اقتراحات الذكاء الاصطناعي 16.6% فقط، مقابل 56.5% للبشر | جودة مراجعة الذكاء الاصطناعي بحاجة للتحسين |
مراجعة الكود بواسطة الذكاء الاصطناعي مقابل المراجعة البشرية
الذكاء الاصطناعي ليس هنا ليحل محل المراجع البشري، بل لتعزيز قدراته. تشير الفرق التي تستخدم مراجعة الكود بالذكاء الاصطناعي إلى:
- تقليل وقت المراجعة بنسبة 40-60%
- تحسين معدل اكتشاف العيوب — خاصة الثغرات الأمنية والحالات الحدية (Edge cases)
- تحسن كبير في اتساق نمط الكود
لكن لمراجعة الذكاء الاصطناعي حدود واضحة:
- ❌ لا يمكنه فهم المواعيد النهائية للأعمال وسياق المشروع
- ❌ لا يمكنه استيعاب التسويات التاريخية للأنظمة القديمة
- ❌ لا يمكنه تحمل المسؤولية النهائية عن المراجعة
- ❌ لا يمكنه القيام بنقل المعرفة بين أعضاء الفريق أو دور الموجه (Mentor)
🎯 الاستراتيجية المثلى: يقوم الذكاء الاصطناعي بالفحص الأولي (النمط، الأخطاء البرمجية، الأمان)، بينما يتخذ البشر القرار النهائي (الهيكلية، القصد، المخاطر). من خلال منصة APIYI (apiyi.com)، يمكنك استدعاء واجهة برمجة التطبيقات (API) لنموذج Claude Opus 4.6 أو Sonnet 4.6 لدمج مراجعة الكود بالذكاء الاصطناعي بسرعة في سير عمل CI/CD الحالي لديك.
7 ممارسات مثلى لمراجعة الكود بواسطة الذكاء الاصطناعي
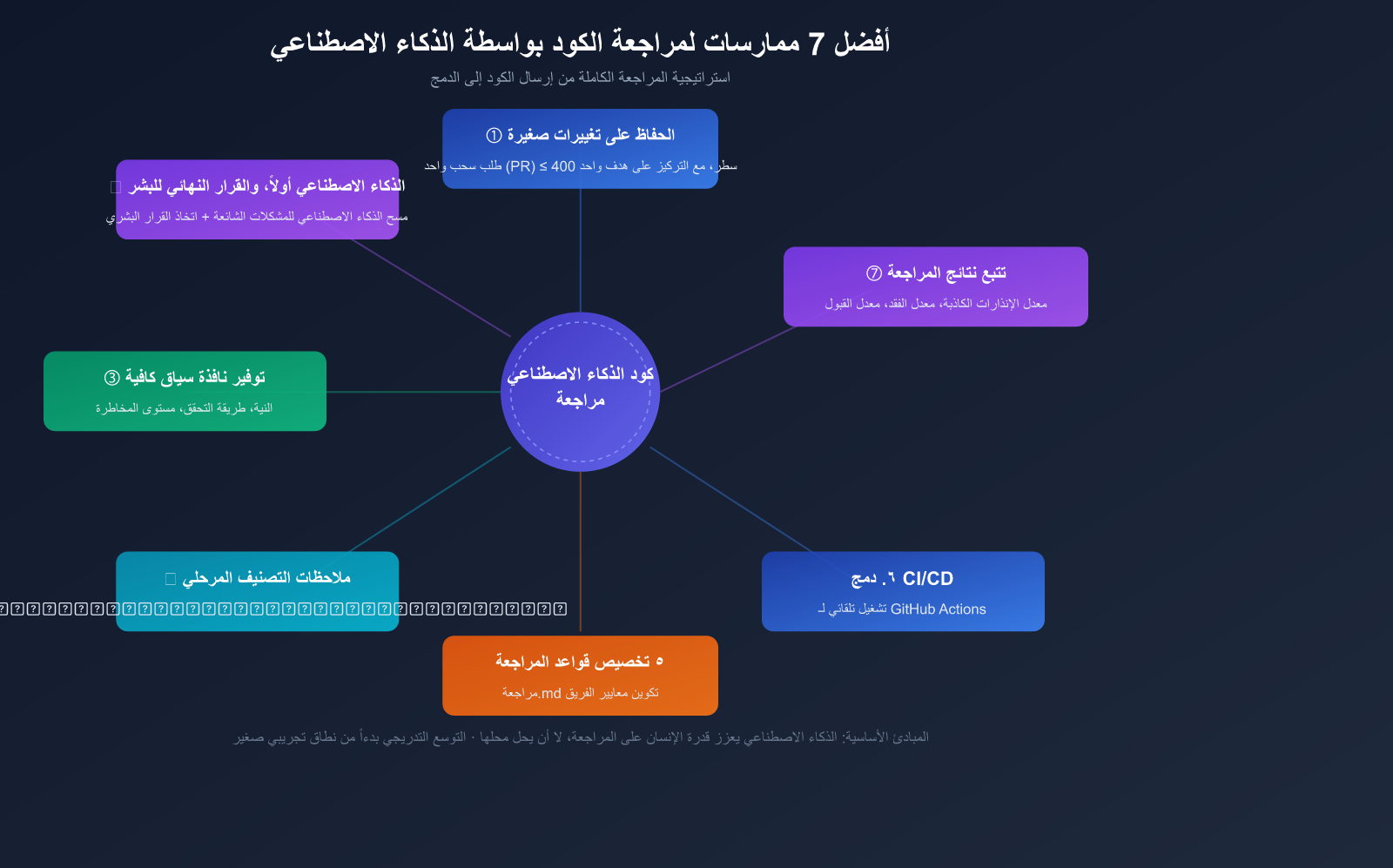
الممارسة الأولى: حافظ على التغييرات صغيرة ومركزة
يفقد مراجع الذكاء الاصطناعي تماسكه بشكل ملحوظ بعد أن يتجاوز حجم التغييرات (diff) 1000 سطر. حتى مع امتلاك Claude Opus 4.6 لنافذة سياق تصل إلى مليون رمز (token)، تظل جودة مراجعة التغييرات الكبيرة أقل من التغييرات الصغيرة.
طريقة العمل:
- اجعل طلب السحب (PR) الواحد يتراوح بين 200-400 سطر.
- قسّم عمليات إعادة الهيكلة الكبيرة إلى عدة طلبات سحب مستقلة منطقياً.
- اجعل كل طلب سحب يركز على مهمة واحدة فقط.
الممارسة الثانية: الذكاء الاصطناعي أولاً، والمراجعة البشرية نهائية
سير العمل الأكثر فعالية هو نموذج "المراجعة المزدوجة":
إرسال الكود ← مراجعة تلقائية بالذكاء الاصطناعي (المرحلة الأولى)
↓
تحديد المشكلات + تصنيف مستوى الخطورة
↓
المراجع البشري يركز على المناطق عالية المخاطر (المراجعة النهائية)
↓
الدمج أو الرفض
يتولى الذكاء الاصطناعي فحص جميع المشكلات الروتينية (النمط، التسمية، الكود الميت، الأخطاء البرمجية البسيطة)، بينما يركز البشر على:
- منطقية الهيكلية.
- صحة منطق الأعمال.
- القرارات الأمنية الحاسمة.
- تقييم تأثير الأداء.
الممارسة الثالثة: توفير سياق كافٍ
كلما زادت المعلومات التي تقدمها لمراجع الذكاء الاصطناعي، ارتفعت جودة المراجعة. نوصي بتضمين ما يلي في وصف طلب السحب (PR):
- الغرض من التغيير.
- الروابط ذات الصلة (مثل تذاكر Jira أو المهام).
- أي قيود فنية أو متطلبات أداء خاصة.
الغرض من التغيير
توضيح سبب إجراء هذا التغيير في جملة أو جملتين.
طريقة التحقق
- اجتياز اختبارات الوحدة (Unit Tests).
- إجراء اختبار يدوي لسيناريو XX.
- عدم وجود تراجع في الأداء.
مستوى المخاطر
منخفض/متوسط/مرتفع + توضيح
إقرار المساعدة بالذكاء الاصطناعي
تم إنشاء جزء XX من هذا التغيير بواسطة الذكاء الاصطناعي، يرجى مراجعته بعناية.
مناطق التركيز اليدوي
يرجى التركيز بشكل خاص على تغييرات منطق الصلاحيات في دليل src/auth/
// مثال على التحقق من الصلاحيات
function checkAuth(user, permission) {
// التحقق من وجود الصلاحية المطلوبة
return user.permissions.includes(permission);
}
الممارسة الرابعة: تصنيف مراجعة الملاحظات حسب الأهمية
من المشكلات الشائعة في المراجعة بواسطة الذكاء الاصطناعي هي "كثرة الضجيج"؛ حيث يتم خلط اقتراحات الأسلوب مع الأخطاء البرمجية (Bug) الجسيمة، مما يؤدي إلى تجاهل المطورين للملاحظات المهمة.
مستويات التصنيف الموصى بها:
| التصنيف | المعنى | طريقة التعامل |
|---|---|---|
| 🔴 Bug | خلل يجب إصلاحه قبل الدمج | يمنع الدمج |
| 🟡 Nit | مشكلة بسيطة تستحق الإصلاح ولكن لا تمنع الدمج | إصلاح اختياري |
| 🟣 Pre-existing | مشكلة قديمة لم يتم إدخالها في هذا التحديث | تُسجل دون منع الدمج |
| 💡 Suggestion | اقتراح للتحسين | يُقرر بعد المناقشة |
لقد طبقت ميزة مراجعة الكود الأصلية في Claude Code نظام التصنيف هذا (الأحمر/الأصفر/الأرجواني).
الممارسة الخامسة: تخصيص قواعد المراجعة
قد لا تتوافق المراجعة العامة بواسطة الذكاء الاصطناعي مع معايير فريقك. يمكنك تخصيص سلوك المراجعة عبر ملف الإعدادات:
# REVIEW.md (يوضع في المجلد الرئيسي للمشروع)
## يجب التحقق من:
- جميع استعلامات قاعدة البيانات يجب أن تستخدم عبارات مُعاملة (Parameterized statements)
- نقاط نهاية API يجب أن تتضمن وسيط المصادقة (Authentication middleware)
- يجب التحقق من صحة جميع مدخلات المستخدم
يمكن تخطيها
- نمط تسمية فئات CSS (تم تنسيقه تلقائيًا بواسطة prettier)
- ترتيب الاستيراد (تمت معالجته تلقائيًا بواسطة ruff)
- لغة التعليقات (يمكن استخدام الصينية أو الإنجليزية)
اتفاقيات الفريق
- إعطاء الأولوية للتركيب (Composition) على الوراثة (Inheritance)
- استخدام نمط النتيجة (Result pattern) لمعالجة الأخطاء
- مستوى السجلات: استخدم INFO لأحداث الأعمال، و DEBUG للتصحيح
الممارسة السادسة: التكامل في خط أنابيب CI/CD
يجب أن تكون مراجعة الكود بواسطة الذكاء الاصطناعي مؤتمتة، لا أن يتم تشغيلها يدويًا.
طريقة التكامل الموصى بها:
# مثال على GitHub Actions
name: AI Code Review
on:
pull_request:
types: [opened, synchronize]
jobs:
ai-review:
runs-on: ubuntu-latest
steps:
- uses: anthropics/claude-code-action@v1
with:
anthropic_api_key: ${{ secrets.ANTHROPIC_API_KEY }}
review_mode: "auto"
يمكنك أيضًا إجراء مراجعة مخصصة عن طريق استدعاء نموذج Claude مباشرة عبر API:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # واجهة APIYI الموحدة
)
diff_content = open("pr_diff.patch").read()
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "system", "content": """أنت خبير مراجعة كود محترف.
يرجى تحليل تغييرات الكود التالية وتصنيفها حسب مستوى الخطورة:
- 🔴 خطأ (Bug): يجب إصلاحه
- 🟡 ملاحظة (Nit): يوصى بإصلاحه
- 💡 اقتراح (Suggestion): اقتراح للتحسين
لكل مشكلة، حدد رقم السطر بدقة وقدم حلًا للإصلاح."""},
{"role": "user", "content": f"يرجى مراجعة تغييرات الكود التالية:\n\n{diff_content}"}
],
max_tokens=8192
)
print(response.choices[0].message.content)
الممارسة السابعة: تتبع نتائج المراجعة
مراجعة الكود بواسطة الذكاء الاصطناعي لا تنتهي بمجرد النشر. يجب تتبع المؤشرات الرئيسية باستمرار:
- معدل الإيجابيات الكاذبة (False Positive Rate): ما هي نسبة المشكلات التي حددها الذكاء الاصطناعي وكانت في الواقع مشكلات حقيقية؟
- معدل السلبيات الكاذبة (False Negative Rate): ما هي نسبة الأخطاء التي تم اكتشافها بعد النشر ولم يكتشفها الذكاء الاصطناعي؟
- معدل الاعتماد: نسبة الاقتراحات التي قبلها المطورون فعليًا من الذكاء الاصطناعي.
- تغير وقت المراجعة: هل انخفض متوسط وقت المراجعة البشري؟
💡 نصيحة للتنفيذ: إذا كان فريقك قد بدأ للتو في تجربة مراجعة الكود بواسطة الذكاء الاصطناعي، فمن المستحسن البدء بطلبات السحب (PRs) غير الحرجة. استخدم نموذج Claude Sonnet 4.6 عبر خدمة APIYI (apiyi.com) للتجارب الأولية؛ حيث تبلغ تكلفته خُمس تكلفة Opus، ويقدم جودة مراجعة قريبة جدًا منه، مما يجعله الخيار الأكثر فعالية من حيث التكلفة للبدء.
لماذا نوصي بـ Claude Opus 4.6 و Sonnet 4.6 لمراجعة الأكواد البرمجية
من بين العديد من نماذج الذكاء الاصطناعي، تتمتع سلسلة Claude 4.6 بمزايا فريدة في سيناريوهات مراجعة الأكواد البرمجية.
مقارنة المعايير الأساسية لنماذج Claude 4.6
| المعيار | Claude Opus 4.6 | Claude Sonnet 4.6 |
|---|---|---|
| معرف النموذج | claude-opus-4-6 |
claude-sonnet-4-6 |
| تاريخ الإصدار | 5 فبراير 2026 | 17 فبراير 2026 |
| نافذة السياق | 1 مليون توكن (تجريبي) | 1 مليون توكن (تجريبي) |
| الحد الأقصى للمخرجات | 128 ألف توكن | 64 ألف توكن |
| SWE-bench Verified | 81.42% | 79.6% |
| التسعير (إدخال/إخراج) | $5/$25 لكل مليون توكن | $3/$15 لكل مليون توكن |
| سيناريوهات الاستخدام | مراجعة البنية المعقدة، التدقيق الأمني | مراجعة طلبات السحب (PR) اليومية، فحص الأسلوب |
| سعر APIYI | أكثر توفيراً | أكثر توفيراً |
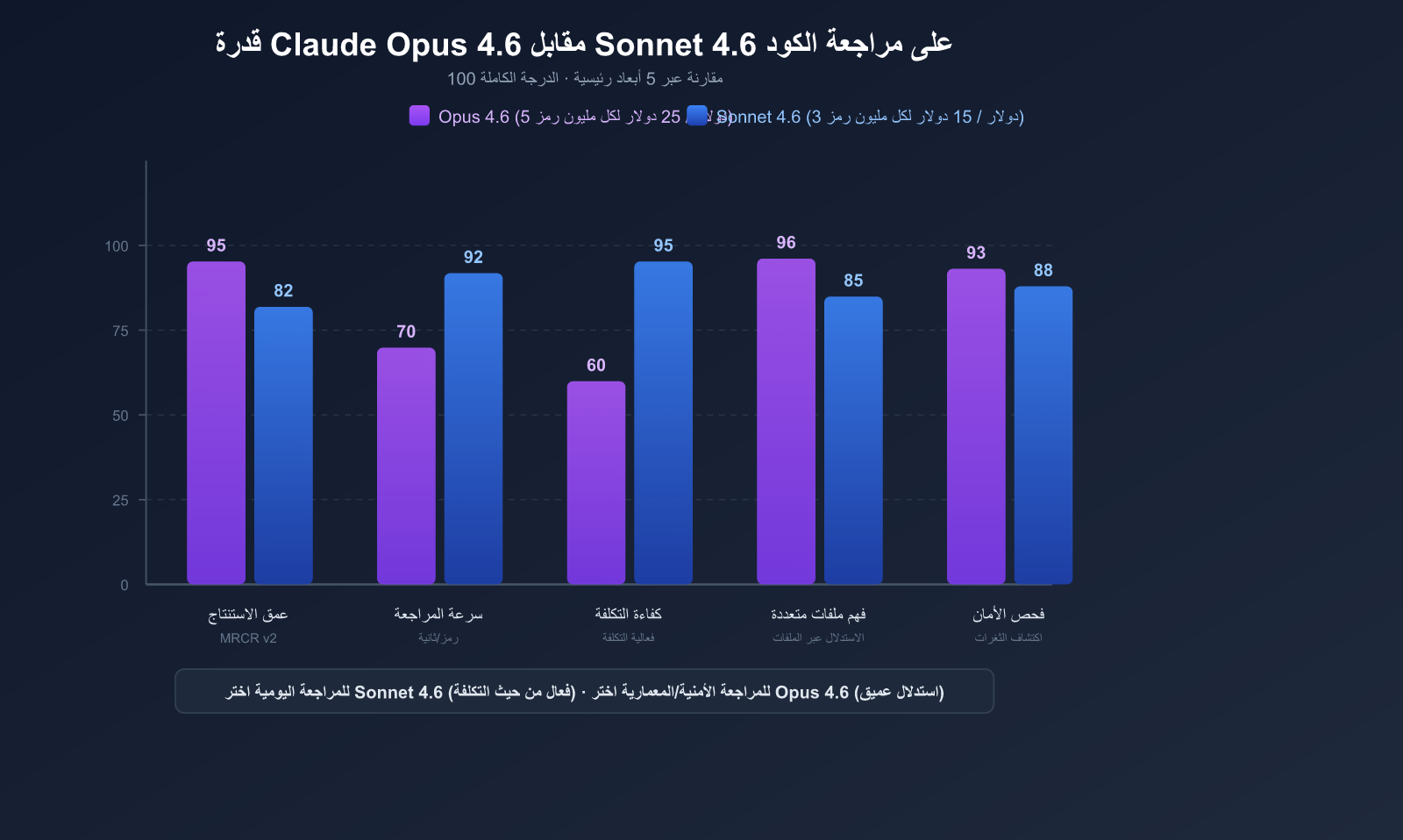
الميزة الأولى: نافذة سياق بحجم 1 مليون توكن
تعد هذه الميزة التقنية الأكثر أهمية في سيناريوهات مراجعة الأكواد البرمجية.
قد يتضمن طلب السحب (PR) في المشاريع الكبيرة عشرات الملفات. إن قيود نافذة السياق في نماذج الذكاء الاصطناعي التقليدية تعني اضطرارك لاقتطاع الكود، مما يجعل المراجع غير قادر على رؤية السياق الكامل.
تسمح نافذة سياق Claude 4.6 البالغة 1 مليون توكن باستيعاب ما يلي دفعة واحدة:
- فرق (diff) كامل لطلب السحب (عادةً بضع مئات إلى آلاف الأسطر)
- الكود الكامل للملفات ذات الصلة (سلاسل الاستيراد، الدوال المستدعاة)
- مخططات التبعية وتعريفات الأنواع
- ملفات الاختبار وملفات الإعدادات
- ملفات README ووثائق البنية المعمارية للمشروع
هذا يعني أن الذكاء الاصطناعي يمكنه المراجعة كأنه مطور خبير، مع فهم كامل للسياق.
الميزة الثانية: قدرة فائقة على الاستدلال عبر الملفات
القيمة الحقيقية لمراجعة الكود ليست في العثور على أخطاء نحوية، بل في اكتشاف المشاكل المنطقية عبر الملفات.
سجل نموذج Claude Opus 4.6 درجة 76% في اختبار MRCR v2 (الاستدلال عبر استرجاع ملفات متعددة)، بينما سجل Sonnet 4.5 نسبة 18.5% فقط. وهذا يعني أن Opus 4.6 يتفوق في السيناريوهات التالية:
- اكتشاف تعديل في واجهة برمجة التطبيقات (API) في الملف "أ" دون تحديث الاستدعاءات في الملف "ب".
- اكتشاف نقص في التحقق من البيانات عبر كامل المسار من المدخلات إلى قاعدة البيانات.
- تحديد ظروف السباق (Race Conditions) في سيناريوهات التزامن.
حالة واقعية: في الاختبارات، اكتشف Claude Opus 4.6 ظرف سباق في طلب سحب لنقل قاعدة بيانات مكون من 2400 سطر—وهو خلل في منطق التراجع (rollback) لا يتم تفعيله إلا عند انقطاع عملية النقل في منتصفها. هذا سيناريو لا يمكن للاختبارات الآلية تغطيته.
الميزة الثالثة: عمق تفكير تكيفي
قدم Claude 4.6 نمط adaptive thinking—حيث يقرر الذكاء الاصطناعي تلقائياً "مدى عمق التفكير" بناءً على تعقيد المشكلة.
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # واجهة APIYI الموحدة
)
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "system", "content": "راجع هذا التغيير في الكود بحثاً عن مشاكل أمنية."},
{"role": "user", "content": diff_content}
],
# تفكير Claude 4.6 التكيفي: حكم سريع للمشاكل البسيطة، وتحليل عميق للمشاكل المعقدة
extra_body={"thinking": {"type": "adaptive"}}
)
- عند مواجهة مشاكل أسلوب بسيطة ← حكم سريع، توفير في التوكن.
- عند مواجهة مشاكل معقدة في التزامن أو الأمن ← استدلال عميق، تقديم تحليل مفصل.
الميزة الرابعة: اكتشاف الثغرات الأمنية يتجاوز الأدوات التقليدية
تشير الأبحاث إلى أن نماذج اللغة الكبيرة (LLM) بمستوى Claude تتفوق بشكل ملحوظ على أدوات التحليل الساكن التقليدية في مراجعة الأكواد الأمنية:
| وجه المقارنة | Claude (LLM) | CodeQL (SAST تقليدي) |
|---|---|---|
| عدد الثغرات المكتشفة | 55 ثغرة | 27 ثغرة |
| اكتشاف ثغرات غير معروفة | 4 ثغرات يوم الصفر | 0 ثغرة |
| فئات الكشف | أكثر من 10 فئات (حقن، مصادقة، تسريب بيانات، تشفير، عيوب منطقية) | يعتمد على مطابقة الأنماط |
| دعم اللغات | أي لغة برمجة | لغات محددة |
| تصفية الإنذارات الكاذبة | تصفية تلقائية بواسطة الذكاء الاصطناعي | تتطلب تصفية يدوية |
أنواع الثغرات الأمنية التي يمكن لـ Claude اكتشافها:
- حقن SQL/الأوامر/LDAP/XPath/NoSQL
- عيوب المصادقة والتفويض
- مفاتيح مشفرة برمجياً، سجلات بيانات حساسة
- خوارزميات تشفير ضعيفة، سوء إدارة المفاتيح
- ظروف السباق (TOCTOU)
- إعدادات افتراضية غير آمنة، CORS
- تنفيذ تعليمات برمجية عن بعد (RCE) عبر إلغاء التسلسل، حقن pickle/eval
- XSS (منعكس، مخزن، قائم على DOM)
الميزة الخامسة: مرونة التكلفة
يبلغ سعر Sonnet 4.6 خُمس سعر Opus 4.6 فقط، ومع ذلك فهو يتأخر عنه بنسبة 1-2% فقط في اختبار SWE-bench.
استراتيجية الاختيار الموصى بها:
| السيناريو | النموذج الموصى به | السبب |
|---|---|---|
| مراجعة طلبات السحب اليومية | Sonnet 4.6 | أفضل قيمة مقابل سعر، جودة قريبة من Opus |
| كود حساس أمنياً | Opus 4.6 | أعمق استدلال، لا يغفل المشاكل الخطيرة |
| مراجعة إعادة الهيكلة الكبيرة | Opus 4.6 | أقوى قدرة على الاستدلال عبر الملفات |
| فحص الأسلوب والمعايير | Sonnet 4.6 | المهام البسيطة لا تحتاج لـ Opus |
| المراجعة الآلية في CI/CD | Sonnet 4.6 | تكلفة محكومة، مناسبة لكل عملية دفع (push) |
🚀 نصيحة للاختيار: توصية Anthropic الرسمية هي "استخدام Sonnet 4.6 افتراضياً، والترقية إلى Opus 4.6 فقط عند الحاجة إلى أعمق استدلال". في الاختبارات الداخلية لـ Claude Code، كانت نسبة تفضيل المطورين لـ Sonnet 4.6 أعلى بنسبة 70% مقارنة بالجيل السابق Sonnet 4.5، وحتى أعلى بنسبة 59% من الرائد السابق Opus 4.5. يمكنك الاستمتاع بأسعار أكثر توفيراً عند استدعاء كلا النموذجين عبر خدمة وكيل APIYI apiyi.com.
سير عمل متكامل لمراجعة الكود باستخدام الذكاء الاصطناعي
نظرة عامة على سير العمل
إرسال المطور لطلب سحب (PR)
↓
تفعيل المراجعة التلقائية عبر الذكاء الاصطناعي (Sonnet 4.6)
↓
┌─── تغييرات منخفضة المخاطر ──→ يضع الذكاء الاصطناعي علامة Nit، ويتم القبول تلقائياً
│
├─── تغييرات متوسطة المخاطر ──→ يضع الذكاء الاصطناعي علامة على المشكلات، ويتم التأكيد البشري السريع
│
└─── تغييرات عالية المخاطر ──→ الترقية إلى Opus 4.6 للمراجعة العميقة
↓
مراجعة نهائية من قبل خبير أمن
↓
الدمج أو الرفض
مثال برمجي: بناء نظام مراجعة مخصص يعتمد على الذكاء الاصطناعي
import openai
import subprocess
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # واجهة APIYI الموحدة
)
def get_pr_diff(pr_number):
"""جلب محتوى الفروقات (diff) لطلب السحب (PR)"""
result = subprocess.run(
["gh", "pr", "diff", str(pr_number)],
capture_output=True, text=True
)
return result.stdout
def review_code(diff, risk_level="medium"):
"""اختيار النموذج المناسب للمراجعة بناءً على مستوى المخاطر"""
model = "claude-opus-4-6" if risk_level == "high" else "claude-sonnet-4-6"
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": REVIEW_PROMPT},
{"role": "user", "content": f"راجع التغييرات التالية:\n\n{diff}"}
],
max_tokens=8192
)
return response.choices[0].message.content
# مثال على الاستخدام
diff = get_pr_diff(123)
review = review_code(diff, risk_level="high")
print(review)
عرض قالب الموجه (Prompt) الكامل للمراجعة
REVIEW_PROMPT = """أنت مهندس برمجيات أول ذو خبرة واسعة، وتقوم حالياً بإجراء مراجعة للكود.
## نقاط التركيز في المراجعة
1. **صحة المنطق**: هل يحقق الكود الوظيفة المطلوبة؟ هل هناك حالات حدية (edge cases) مفقودة؟
2. **الأمان**: هل توجد مخاطر أمنية مثل حقن الكود، XSS، CSRF، أو مفاتيح API مشفرة داخل الكود؟
3. **الأداء**: هل توجد استعلامات N+1، تخصيصات ذاكرة غير ضرورية، أو عمليات حظر (blocking operations)؟
4. **القابلية للصيانة**: هل التسميات واضحة؟ هل التعقيد تحت السيطرة؟ هل يوجد كود مكرر؟
5. **معالجة الأخطاء**: هل يتم التقاط الاستثناءات ومعالجتها بشكل صحيح؟
6. **أمان التزامن**: هل توجد مخاطر تتعلق بظروف السباق (race conditions) أو الجمود (deadlocks)؟
تنسيق المخرجات
يتم تصنيف المخرجات حسب مستوى الخطورة:
🔴 يجب إصلاحه (Bug/Security)
- [اسم الملف:رقم السطر] وصف المشكلة
- التأثير: …
- الإصلاح المقترح: …
🟡 إصلاح مقترح (Nit)
- [اسم الملف:رقم السطر] وصف المشكلة
- الاقتراح: …
💡 اقتراحات التحسين (Suggestion)
- [اسم الملف:رقم السطر] نقطة التحسين
- الشرح: …
إذا كانت جودة الكود جيدة ولم يتم العثور على أي مشاكل، يرجى ذكر "تمت المراجعة بنجاح، لم يتم العثور على مشاكل".
لا تقم باختلاق مشاكل غير موجودة لمجرد إكمال المخرجات.
💰 تحسين التكلفة: يمكنك إجراء مراجعة الكود باستخدام نموذج Claude 4.6 عبر APIYI (apiyi.com)، حيث يوفر أسعاراً أكثر تنافسية مقارنة بالموقع الرسمي. تدعم المنصة التبديل المرن بين نموذجي Opus 4.6 و Sonnet 4.6، مما يتيح لك اختيار النموذج الأكثر فعالية من حيث التكلفة بناءً على مستوى خطورة طلب السحب (PR).
قيود مراجعة الكود بواسطة الذكاء الاصطناعي وملاحظات هامة
5 قيود يجب أن تكون على دراية بها
- معدل الاسترجاع حوالي 50%: الثغرات التي يكتشفها نموذج اللغة الكبير تكون عادةً حقيقية (دقة ~80%)، لكنه يغفل عن حوالي نصف الثغرات الموجودة بالفعل.
- مخاطر حقن الموجه (Prompt Injection): قد تتعرض أدوات مراجعة الذكاء الاصطناعي لخطر الحقن عند معالجة طلبات سحب (PR) غير موثوقة.
- العمى عن السياق: لا يستطيع الذكاء الاصطناعي فهم السياق التجاري للمشروع، أو قدرات أعضاء الفريق، أو القرارات التاريخية المتخذة.
- تراكم التكاليف: إذا قمت بتفعيل المراجعة مع كل عملية رفع للكود (Commit)، فقد تصبح التكلفة مرتفعة في المستودعات ذات النشاط العالي.
- مخاطر الاعتماد المفرط: قد يبدأ أعضاء الفريق تدريجياً في التراخي في دقة المراجعة البشرية.
استراتيجيات التجنب
| القيد | استراتيجية التجنب |
|---|---|
| ارتفاع معدل الفشل في الكشف | الجمع بين مراجعة الذكاء الاصطناعي والمراجعة البشرية كضمان مزدوج |
| حقن الموجه | مراجعة طلبات السحب (PR) الواردة من مصادر موثوقة فقط |
| نقص السياق | توفير خلفية المشروع في ملف REVIEW.md |
| التكلفة العالية | استخدام Sonnet 4.6 للاستخدام اليومي، و Opus 4.6 للمسارات الحرجة |
| الاعتماد المفرط | وضع نظام يعتمد على "اقتراحات الذكاء الاصطناعي + القرار البشري" |
الأسئلة الشائعة
س1: هل يمكن لمراجعة الكود بواسطة الذكاء الاصطناعي أن تحل محل المراجعة البشرية بالكامل؟
لا. مراجعة الكود بواسطة الذكاء الاصطناعي هي "تعزيز" وليست "بديل". يتفوق الذكاء الاصطناعي في اكتشاف المشكلات النمطية (الأسلوب، الأخطاء البرمجية الشائعة، أنماط الثغرات المعروفة)، لكنه لا يستطيع فهم نوايا العمل، والمقايضات وراء قرارات الهندسة المعمارية، والمعرفة الضمنية في تعاون الفريق. أفضل ممارسة هي أن يقوم الذكاء الاصطناعي بالفحص الأولي، بينما يتخذ البشر القرار النهائي. يمكنك من خلال APIYI (apiyi.com) استدعاء نموذج Claude 4.6 لبناء سير عمل مراجعة ذكي بسرعة، مما يتيح للمراجعين البشريين التركيز على المهام ذات القيمة الأعلى.
س2: أيهما أختار لمراجعة الكود: Opus 4.6 أم Sonnet 4.6؟
في معظم الحالات، اختر Sonnet 4.6. فهو يتأخر بنسبة 1-2% فقط عن Opus في اختبار SWE-bench، لكن تكلفته تعادل خمس التكلفة فقط. لا تحتاج للترقية إلى Opus 4.6 إلا عند مراجعة الأكواد الحساسة أمنياً، أو إعادة هيكلة الأنظمة الضخمة، أو عندما تحتاج إلى استنتاج عميق عبر ملفات متعددة. يمكنك التبديل بمرونة بين النموذجين حسب الحاجة عبر APIYI (apiyi.com).
س3: ما هي تكلفة مراجعة الكود بواسطة الذكاء الاصطناعي تقريباً؟
تبلغ تكلفة ميزة المراجعة الأصلية في Claude Code ما بين 15 إلى 25 دولاراً في المرة الواحدة، اعتماداً على حجم طلب السحب (PR) وتعقيد قاعدة الكود. إذا قمت ببناء نظام مراجعة خاص بك عبر API، فالتكلفة تعتمد على استهلاك الرموز (Tokens). على سبيل المثال، باستخدام Sonnet 4.6، فإن مراجعة طلب سحب مكون من 500 سطر (حوالي 2000 رمز إدخال + 1000 رمز إخراج) تكلف حوالي 0.02 دولار. كما يمكنك الاستمتاع بأسعار أكثر تنافسية من خلال APIYI (apiyi.com).
س4: كيف يمكن تقييم فعالية مراجعة الكود بواسطة الذكاء الاصطناعي؟
نوصي بتتبع 4 مؤشرات رئيسية: (1) معدل الإيجابيات الكاذبة – نسبة المشكلات الحقيقية من بين ما حدده الذكاء الاصطناعي؛ (2) معدل الفشل في الاكتشاف – نسبة الأخطاء التي تم اكتشافها بعد النشر ولم يحددها الذكاء الاصطناعي؛ (3) معدل الاعتماد – نسبة الاقتراحات التي اعتمدها المطورون فعلياً؛ (4) التغير في وقت المراجعة – هل انخفض متوسط وقت المراجعة للمراجعين البشريين؟ نوصي بإجراء مراجعة أسبوعية خلال الشهرين الأولين.
س5: كيف أبدأ في تجربة مراجعة الكود بواسطة الذكاء الاصطناعي بسرعة؟
أبسط طريقة هي اتباع ثلاث خطوات: (1) التسجيل عبر APIYI (apiyi.com) للحصول على مفتاح API؛ (2) إجراء اختبار مراجعة لآخر طلب سحب (PR) قمت به باستخدام Sonnet 4.6؛ (3) اتخاذ قرار بشأن دمجه في نظام CI/CD الآلي بناءً على النتائج. ابدأ التجربة بأكواد غير حرجة، ثم قم بتوسيع نطاقها تدريجياً.
الخلاصة: مراجعة الكود بواسطة الذكاء الاصطناعي هي مضاعف لكفاءة الفريق
لم تعد مراجعة الكود بواسطة الذكاء الاصطناعي خياراً إضافياً، بل أصبحت قدرة أساسية لفرق تطوير البرمجيات في عام 2026. بفضل نافذة السياق التي تصل إلى مليون رمز، ونتائج تتجاوز 81% في اختبار SWE-bench، وقدرات التفكير التكيفي والكشف الأمني القوي، تعد نماذج Claude Opus 4.6 و Sonnet 4.6 الخيار الأمثل حالياً لمراجعة الكود.
نصائح الاختيار:
- المراجعة اليومية: Sonnet 4.6 هو الخيار الافتراضي، وهو بطل القيمة مقابل السعر.
- مراجعة الأمن/الهيكلية: قم بالترقية إلى Opus 4.6 للحصول على عمق استنتاجي لا يضاهى.
نوصي بالوصول السريع إلى سلسلة نماذج Claude 4.6 الكاملة عبر APIYI (apiyi.com) لبناء قدرات مراجعة الكود بالذكاء الاصطناعي لفريقك بأفضل تكلفة ممكنة.
المراجع
-
الموقع الرسمي لـ Anthropic: إعلان إطلاق Claude Opus 4.6 و Sonnet 4.6
- الرابط:
anthropic.com/news
- الرابط:
-
وثائق مراجعة الكود في Claude Code: دليل استخدام ميزة المراجعة الأصلية
- الرابط:
code.claude.com/docs/en/code-review
- الرابط:
-
مراجعة أمان Claude Code: إجراء GitHub مفتوح المصدر لمراجعة الأمان
- الرابط:
github.com/anthropics/claude-code-security-review
- الرابط:
-
أفضل ممارسات مراجعة الكود بواسطة الذكاء الاصطناعي لعام 2026: تحليل شامل للصناعة
- الرابط:
verdent.ai/guides
- الرابط:
-
ورقة بحث IRIS: الكشف عن الثغرات الأمنية عبر التحليل الساكن بمساعدة نماذج اللغة الكبيرة (LLM)
- الرابط:
arxiv.org
- الرابط:
المؤلف: فريق APIYI | نستكشف أفضل الممارسات لتمكين تطوير البرمجيات بواسطة الذكاء الاصطناعي. تفضل بزيارة APIYI على apiyi.com للحصول على واجهات برمجة التطبيقات (API) والدعم الفني لمجموعة نماذج Claude 4.6 الكاملة.