很多人第一次用 ChatGPT 网页版会有个错觉:输入一份 PDF 或一句话,它「啪」地一下吐出 5 张风格统一的配图;可一旦切到 API,把 n 调到 5,得到的却是 5 张大同小异、像抽卡一样的随机变体。同一个模型,为什么差别这么大?
这篇文章不打算给一个标准答案,而是把我们在客户支持中反复遇到的这个问题拆开来聊。我们会讲清楚 GPT Image 组图生成背后的两条完全不同的技术路径,解释为什么 n 参数做不出真正的「组图」,以及如果你想用 API 自己实现多图一致性,有哪些可落地的办法。
一、GPT Image 组图生成的两条技术路径
要理解这件事,先要承认一个容易被忽略的前提:「一次生成多张图」和「生成一组有逻辑关系的图」是两回事。前者只是数量上的批量,后者才是大家口中真正的「组图」。
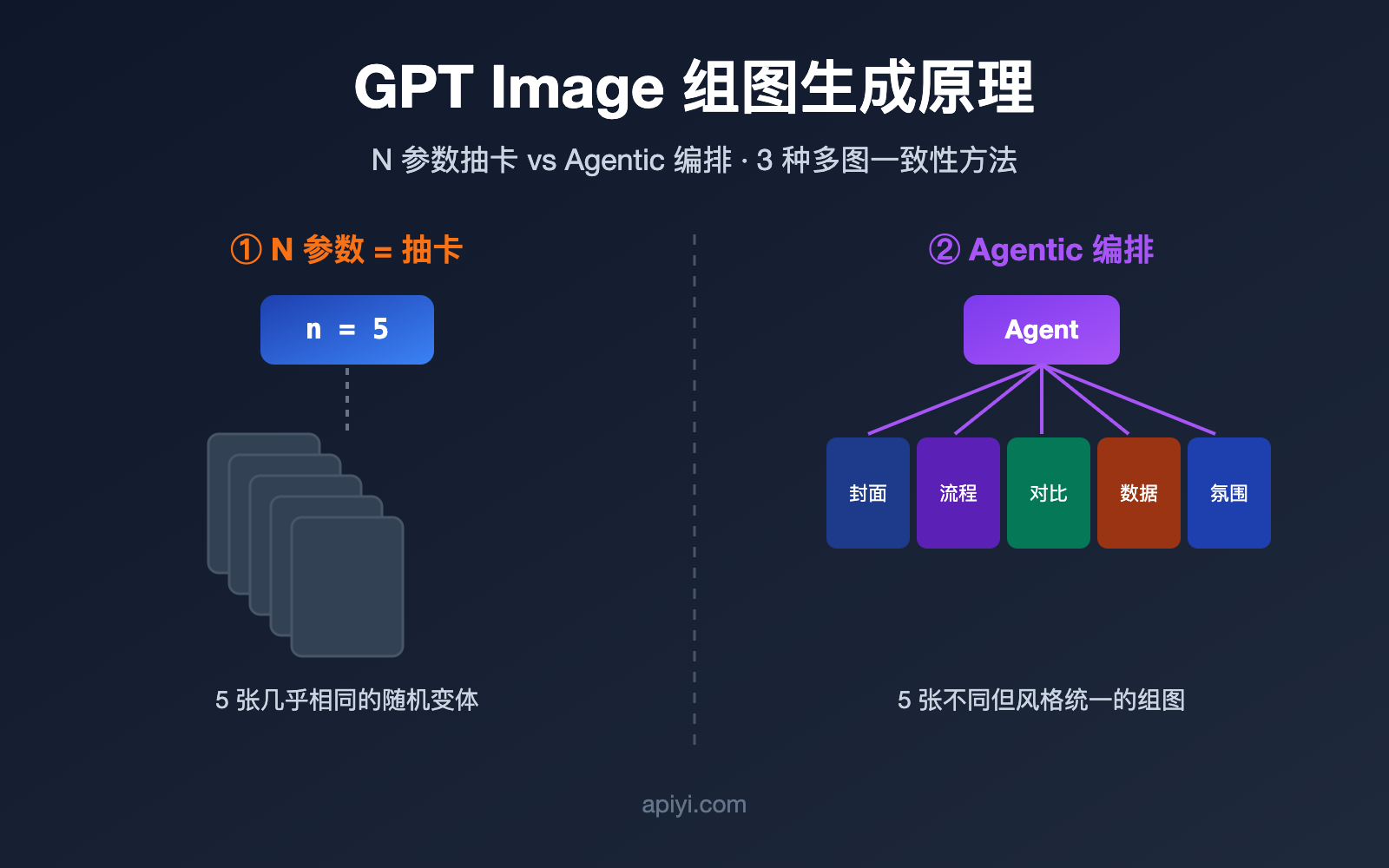
GPT Image 在工程实现上对应两条路径。第一条是模型层的批量采样,也就是 API 里的 n 参数:同一个提示词、同一份输入,让模型并行采样出多张结果。第二条是应用层的 Agentic 编排,由一个 Agent(智能体)先理解需求、把它拆成若干个子任务,再分别调用生图能力,最后拼成一组。
下面这张表先把两条路径的核心差异摆清楚,后面几节再逐条展开。
| 维度 | API 的 n 参数(批量采样) | Agentic 编排(应用层) |
|---|---|---|
| 本质 | 同一提示词重复随机采样 | 拆分需求后多次独立生成 |
| 每张图内容 | 几乎相同,只有随机差异 | 各不相同,但主题关联 |
| 是否理解「组」 | 不理解,纯并发 | 理解,有规划逻辑 |
| 费用 | 单图价格 × N | 多次调用费用累加 |
| 一致性来源 | 提示词与随机种子 | 参考图 + 统一提示约束 |
| 典型场景 | 海选一张满意的图 | 系列插画、PPT 配图、绘本 |
简单说,n 参数解决的是「多给我几张备选」,而组图需要的是「按一个主题给我一系列内容」。这也是为什么直接调 API 想复刻网页版体验时,总觉得差了点意思。如果你想同时验证这两种路径的真实表现,可以在 API易 apiyi.com 上用同一套密钥分别测试,省去多平台来回切换的成本。
二、为什么 API 的 n 参数做不出真正的组图
很多开发者的第一反应是:既然要 5 张图,那把 n 设成 5 不就行了?实际跑一遍就会发现,出来的 5 张图往往是「同一个东西的 5 个微小变体」,而不是「一组互相配合的图」。
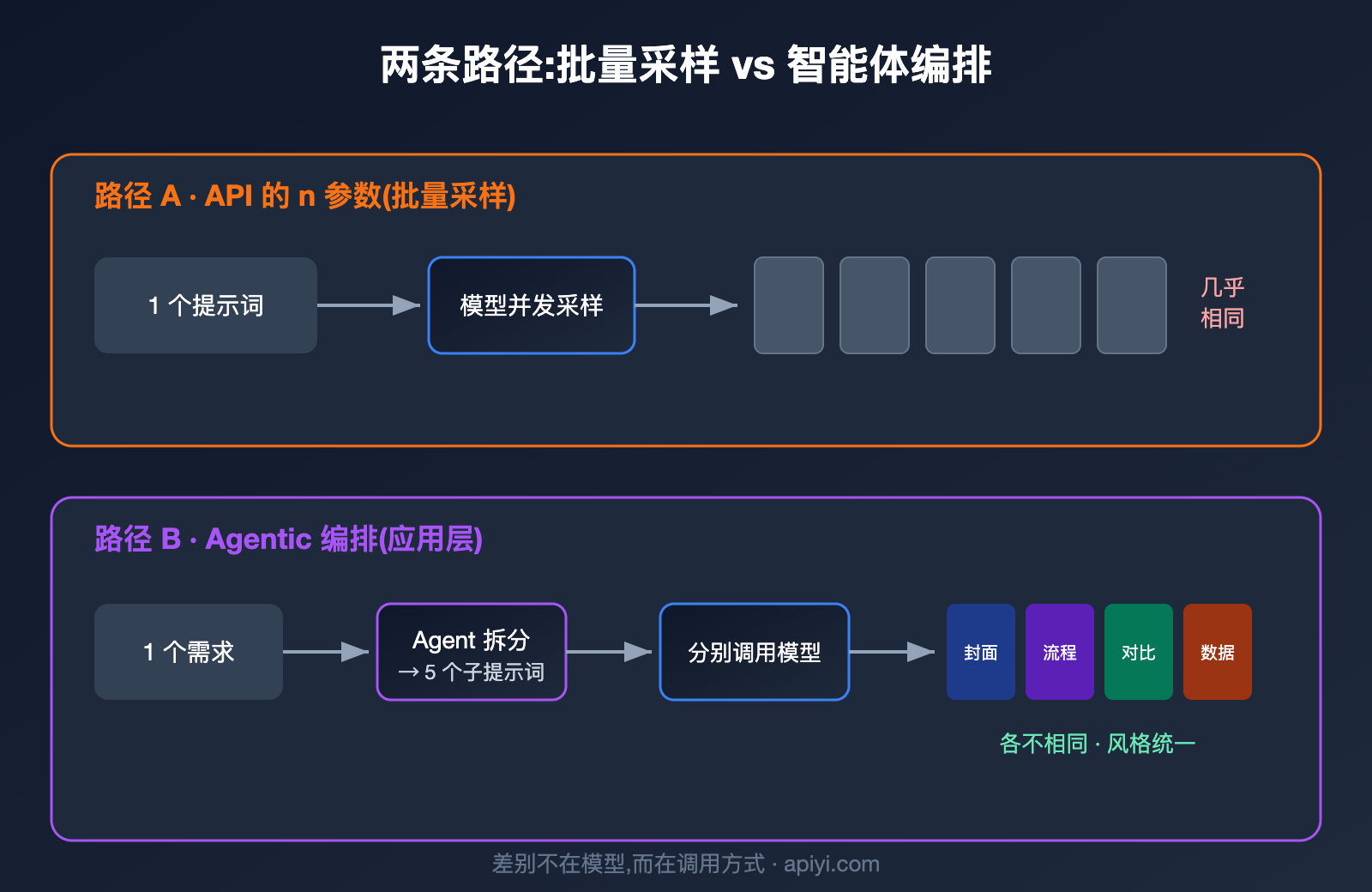
原因在于 n 参数的工作机制。它并不会改变你的提示词,而是用同一个提示词再跑几遍,靠模型生成过程中的随机采样制造差异。OpenAI 开发者社区里有一句很贴切的描述:这些图来自「同一输入下随机采样产生的变化」(random sampling variations)。换句话说,这就是抽卡——同样的卡池,抽 5 次,卡面相似、稀有度随机。
这带来两个直接后果。其一,你无法在一次调用里表达「第一张画封面、第二张画流程、第三张画对比」这种结构化需求,因为提示词只有一个。其二,费用是线性叠加的:n=5 就是按 5 张图计费,而不是打包优惠。
下表用一个具体场景说明这个差异,假设你想为一篇文章生成 5 张不同用途的配图。
| 需求 | 用 n=5 的结果 | 你真正想要的 |
|---|---|---|
| 封面图 | 5 张都是封面候选 | 1 张封面 |
| 流程图 | 拿不到 | 1 张流程图 |
| 对比图 | 拿不到 | 1 张对比图 |
| 数据图 | 拿不到 | 1 张数据图 |
| 配图 | 拿不到 | 1 张氛围图 |
结论很清楚:n 参数适合「我要一张好图,多给几个候选让我挑」,不适合「我要一套内容不同的组图」。理解了这一点,就不会再纠结于「为什么 API 出不来网页版那种效果」——因为你用错了工具。想低成本验证 n 参数的抽卡特性,API易 apiyi.com 支持按调用量计费,跑几组对比实验花不了多少钱。
三、网页版组图背后的 Agentic 编排原理
那 ChatGPT 网页版凭什么能「一个 PDF 出 5 张图」?答案就是上面提到的第二条路径——Agentic 编排,而这恰好是 2026 年 4 月发布的 GPT Image 2 / ChatGPT Images 2.0 带来的关键升级。
按照 OpenAI 的官方定位,GPT Image 2 是首个把「推理能力」内置进图像模型的版本:它在动笔之前会先研究、规划、推理图像结构(proactively researches, plans, and reasons),这套机制在网页端被称为 Thinking 模式。所以当你丢进去一份 PDF,模型不是简单地「读图」,而是先理解文档讲了什么、需要几张图、每张图分别承担什么角色,再逐张生成。
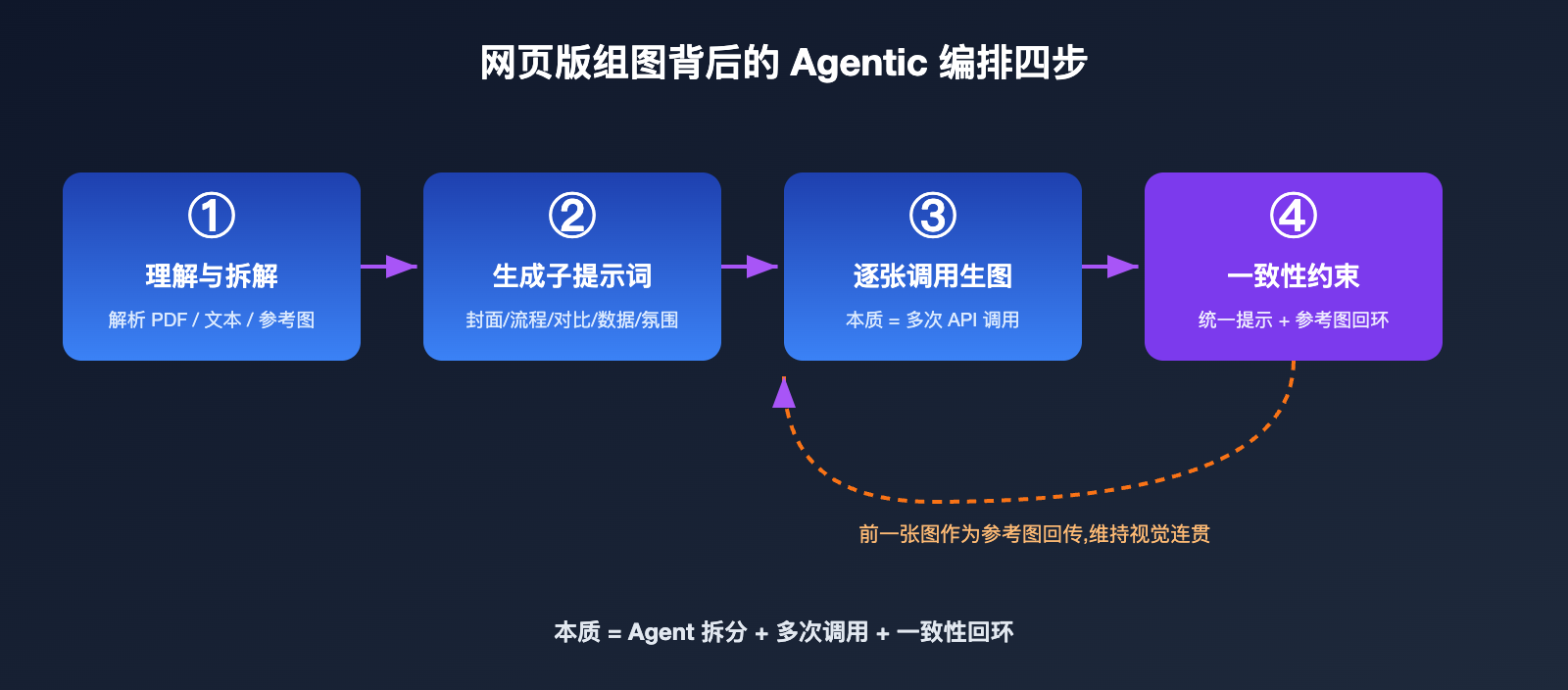
把这个过程翻译成工程语言,大致是四步:
- 理解与拆解:Agent 解析输入(文本、PDF、参考图),判断需要几张图、每张图的主题。
- 生成子提示词:为每张图各写一条独立的提示词,例如「整体架构图」「关键流程图」「数据对比图」。
- 逐张调用生图:对每条子提示词分别调用底层生图能力,本质上是多次 API 调用。
- 一致性约束:在每条提示词里注入统一的风格描述,并把前面生成的图作为参考图传给后面,保证整组视觉统一。
学术界也在用类似思路。多智能体框架(如视频生成里的 ViMax、文生图里的 Maestro)会把一个大需求拆成多个细粒度的视觉子问题,并行生成、择优选取,再把前一帧或前一张图作为后续生成的参考,以此维持角色和场景的连贯。GPT Image 2 的过人之处,是把这套原本要工程师手搭的编排,收进了模型自身的推理回路里。
这里也藏着真正的难点:多次独立调用天然会漂移。每一张图都是一次新的随机采样,角色长相、配色、画风都可能跑偏。这就是我们和客户聊到的那个核心问题——「如何保持视觉一致性」,它比「如何出多张图」难得多。下一节就专门讲怎么对付它。
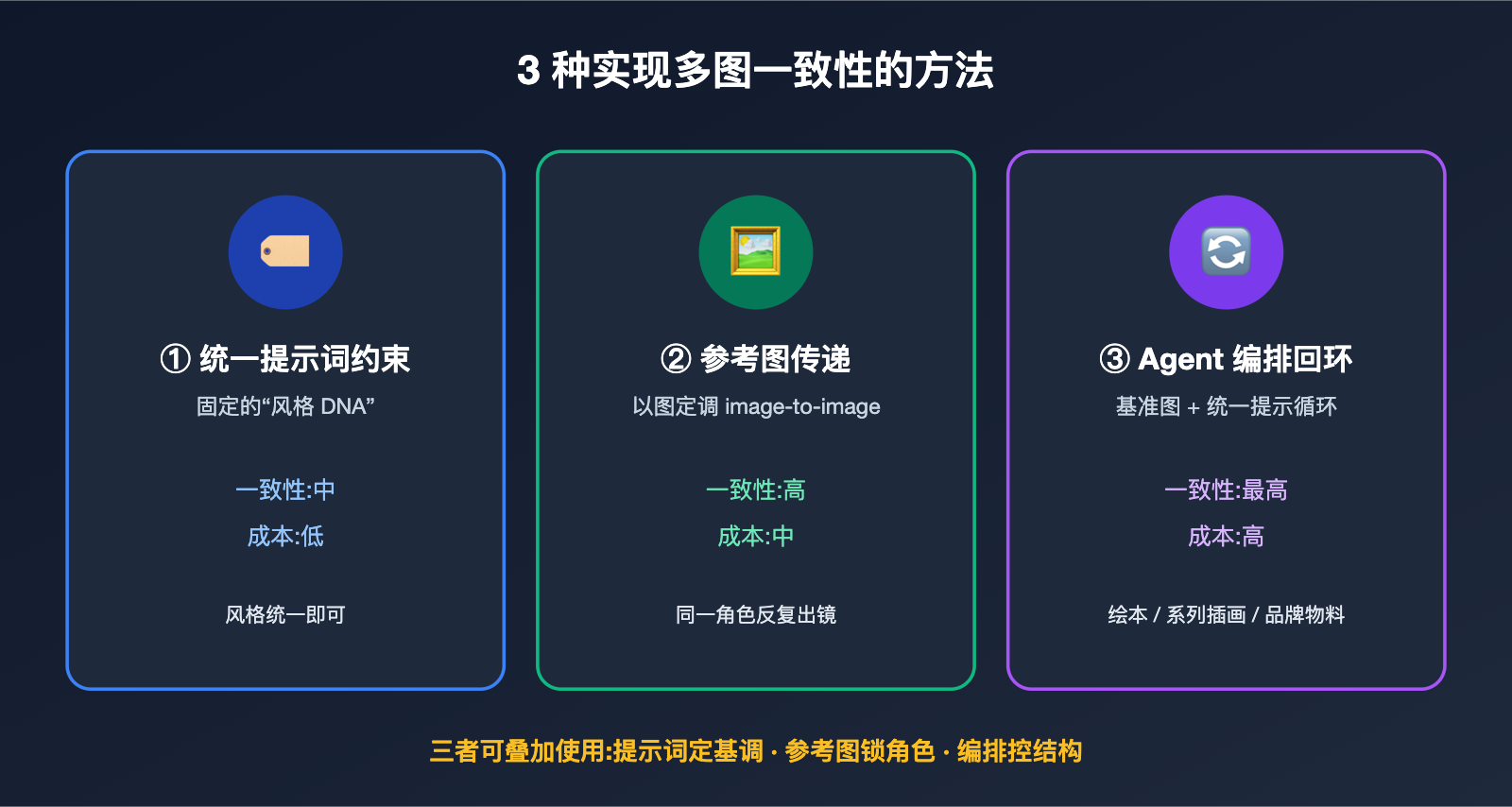
四、用 API 复刻组图:3 种实现多图一致性的方法
如果你不想依赖网页版,而是要在自己的产品里实现 GPT Image 组图生成,那就得自己搭那套编排逻辑,核心是用工程手段把「视觉一致性」补回来。结合实践,我们总结出三种由浅入深、可以叠加使用的方法。
方法一:统一提示词约束(角色描述表)。 最低成本的做法,是为整组图写一段固定的「风格 DNA」,每次调用都原样附在提示词里。比如「统一采用扁平插画风格、主色为深蓝与琥珀色、人物为短发女性工程师」。社区里把这种固定描述叫 character bible(角色圣经),描述越具体,跨图一致性越高。
方法二:参考图传递(image-to-image)。 把已经生成满意的第一张图,作为参考图传给后续每一次调用。GPT Image 2 在编辑/参考场景下可接收多张参考图(官方文档标注最多可达 16 张,具体以平台实测为准),这让「以图定调」成为组图一致性的主力手段。它的效果通常比纯文字描述更稳,尤其是角色长相这类细节。
方法三:Agent 编排 + 参考图回环。 把前两种结合进一个循环:先生成第一张作为基准图,后续每张都带着基准图 + 统一提示词去生成,必要时把上一张也一起作为参考。这就是网页版 Thinking 模式在做的事,只是你把它显式地写进了代码。
下面是一段精简的编排示例,演示「先出基准图,再带着参考图生成系列图」的骨架逻辑。
from openai import OpenAI
# base_url 指向 API易,统一管理多模型密钥
client = OpenAI(base_url="https://api.apiyi.com/v1", api_key="YOUR_KEY")
STYLE = "扁平插画风格,主色深蓝与琥珀,人物为短发女工程师" # 角色描述表
shots = ["封面:人物站在数据中心前", "流程:人物在白板画架构", "总结:人物竖起大拇指"]
# 1. 先生成基准图,锁定整组风格
base = client.images.generate(model="gpt-image-2", prompt=f"{shots[0]},{STYLE}")
# 2. 后续每张都带统一风格约束(进阶可叠加 base 作为参考图传入 edits 接口)
for shot in shots[1:]:
img = client.images.generate(model="gpt-image-2", prompt=f"{shot},{STYLE}")
# save(img) ...
为了帮你快速选择,下表对比三种方法的特点与适用场景。
| 方法 | 一致性强度 | 实现成本 | 适用场景 |
|---|---|---|---|
| 统一提示词约束 | 中 | 低 | 风格统一即可,角色不严格 |
| 参考图传递 | 高 | 中 | 同一角色/产品反复出镜 |
| Agent 编排回环 | 最高 | 高 | 绘本、系列插画、品牌物料 |
三种方法可以叠加:用提示词定基调,用参考图锁角色,用编排控结构。我们建议先从「统一提示词 + 参考图」起步,跑通后再上完整编排。在 API易 apiyi.com,gpt-image-2、gpt-image-1.5 等模型共用同一个 base_url 和密钥,方便你在不改代码的情况下切换模型做一致性对比测试。
五、GPT Image 组图生成的成本与模型选择
组图意味着多次调用,成本会被放大,所以选对模型很关键。目前 GPT Image 系列在生产环境常用的有几档,定位各有侧重。
| 模型 | 定位 | 是否支持推理编排 | 适合的组图场景 |
|---|---|---|---|
| gpt-image-2 | 旗舰,内置推理 | 是(Thinking) | 高质量系列物料、含文字海报 |
| gpt-image-1.5 | 上一代旗舰 | 部分 | 质量与成本平衡的批量出图 |
| gpt-image-1 | 经典稳定 | 否 | 风格简单的常规配图 |
| gpt-image-1-mini | 轻量低价 | 否 | 大批量、对质量要求不高 |
关于费用要有个清醒认识:组图是「按张数累加」计费的。以 1024×1024 为例,不同质量档位单张价格大致从几毫美元到两毫多美元不等(具体以官方与平台实时报价为准),一组 5 张图就是 5 张的钱。如果你要批量生产上千张,成本会很可观,提前估算很有必要。
我们的建议是:草稿阶段用 mini 或低质量档快速验证构图与一致性,定稿阶段再用 gpt-image-2 出高质量终图。这种「低成本试错 + 高质量定稿」的组合,能在保证效果的同时把账单压下来。API易 apiyi.com 提供统一的用量看板,组图调用花了多少、用了哪个模型一目了然,适合需要控制成本的团队。
六、常见问题 FAQ
Q1:API 到底能不能一次出一组不同的图?
不能,靠 n 参数不行。n 只是同一提示词的随机采样(抽卡),内容几乎相同。真正的组图必须靠应用层编排:拆分需求、多次调用、再做一致性约束。
Q2:网页版 ChatGPT 出组图是用了什么黑科技?
不是黑科技,是 GPT Image 2 把 Agentic 推理内置了。它在生成前会先规划「需要几张图、每张画什么」,再逐张生成,本质仍是多次调用,只是规划过程对用户透明。
Q3:多图一致性最有效的办法是什么?
实践中参考图传递最稳:把第一张满意的图作为参考传给后续每次调用,角色和配色的还原度明显高于纯文字描述。再叠加一段固定的风格描述表,效果更佳。你可以在 API易 apiyi.com 上用 gpt-image-2 的参考图接口直接验证。
Q4:组图生成会很贵吗?
取决于张数、分辨率和质量档位,因为是按张累加。建议草稿用轻量模型、定稿用旗舰模型,并通过平台用量看板监控开销。
Q5:用哪个模型做组图最划算?
追求质量和文字渲染选 gpt-image-2;要平衡成本选 gpt-image-1.5;大批量低要求可用 gpt-image-1-mini。共用一套接口时,切换模型几乎零成本。
七、总结
回到最初那个问题:同一个模型,API 像抽卡、网页版能出组图,差别不在模型,而在调用方式。n 参数是模型层的批量采样,解决「多给几张候选」;真正的 GPT Image 组图生成是应用层的 Agentic 编排,靠拆分需求、多次调用和一致性约束拼出来。
这其中,多图一致性始终是最难的一环。好在我们有三件趁手的工具:统一的角色描述表定基调、参考图传递锁角色、Agent 编排回环控结构,三者叠加基本能逼近网页版的体验。GPT Image 2 的价值,正是把这套编排能力收进了模型的推理回路,让普通用户也能享受到。
这个话题未必有标准答案,更多是一种经验分享——希望能帮你少走一些弯路。如果你想动手验证文中的每一种方法,API易 apiyi.com 提供 gpt-image-2、gpt-image-1.5 等模型的统一接口和用量看板,是做组图实验和成本对比的便捷起点,更多接入细节可参考帮助中心 help.apiyi.com。
本文为 API易技术团队基于客户支持实践整理的探讨性内容,模型规格与价格请以官方及平台实时信息为准。