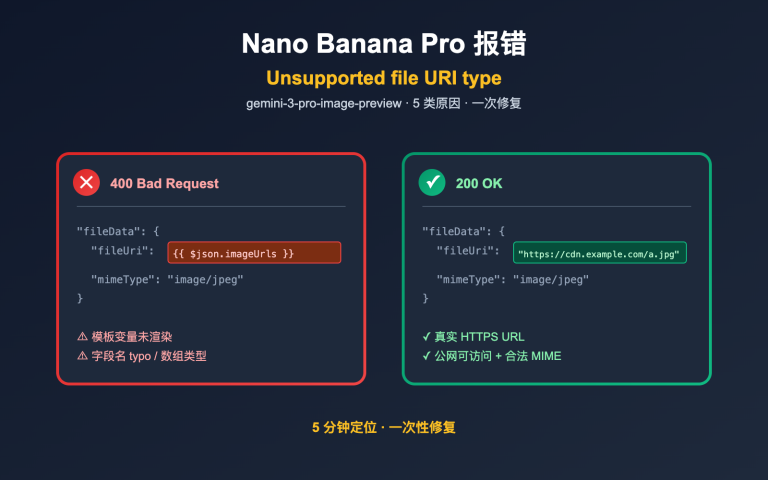
一句话结论: 把
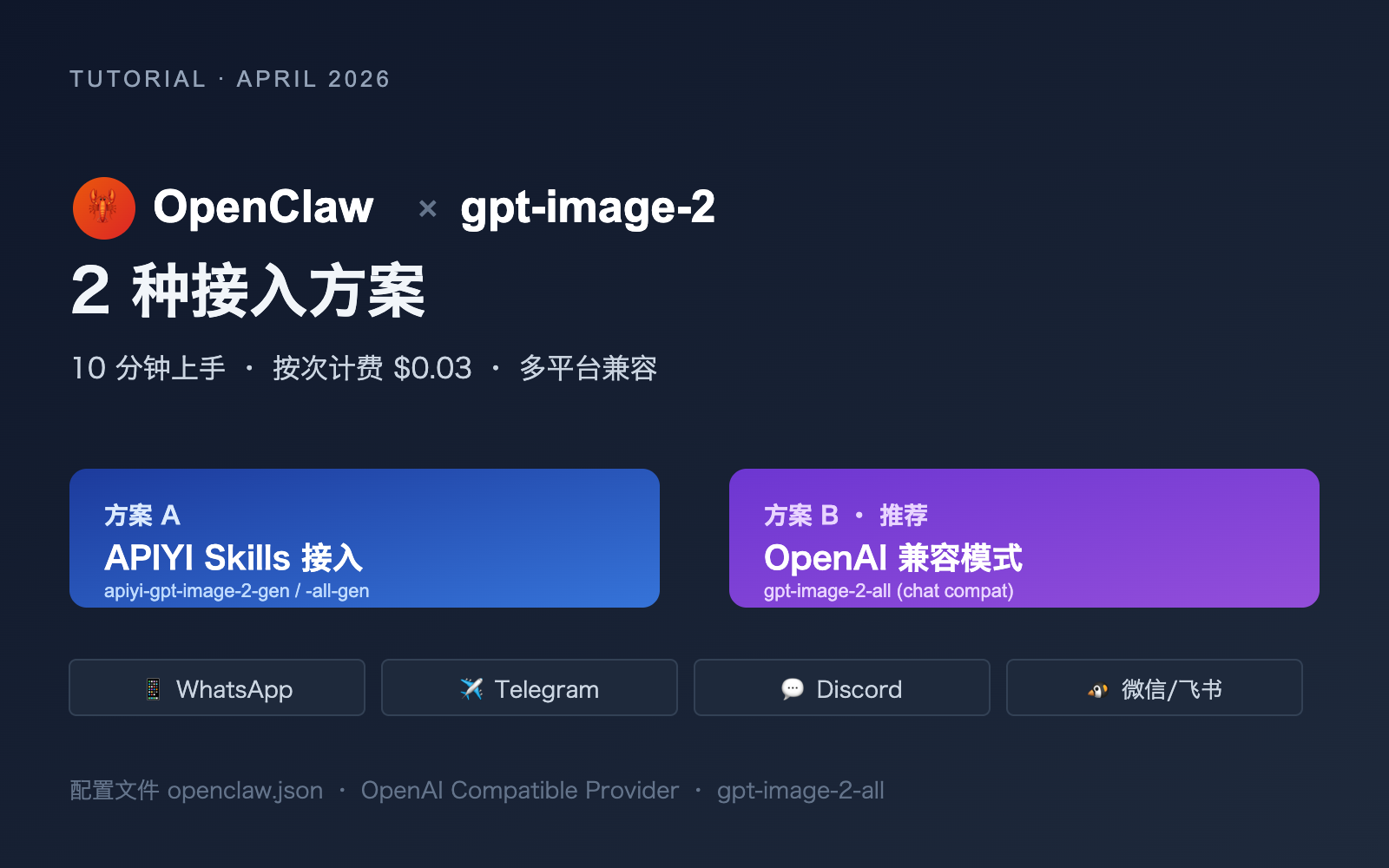
gpt-image-2接入 OpenClaw 有两条路径——方案 A 是用 APIYI 的 GPT-Image Skills,5 分钟即可完成,适合 Codex CLI/Cursor 等支持 Skills 的客户端;方案 B 是用 OpenAI 对话兼容模式 + 官逆模型gpt-image-2-all,按次计费 ($0.03/次,折扣前),最适合 OpenClaw 通过 WhatsApp/Telegram/Discord 等消息平台直接生图的场景。
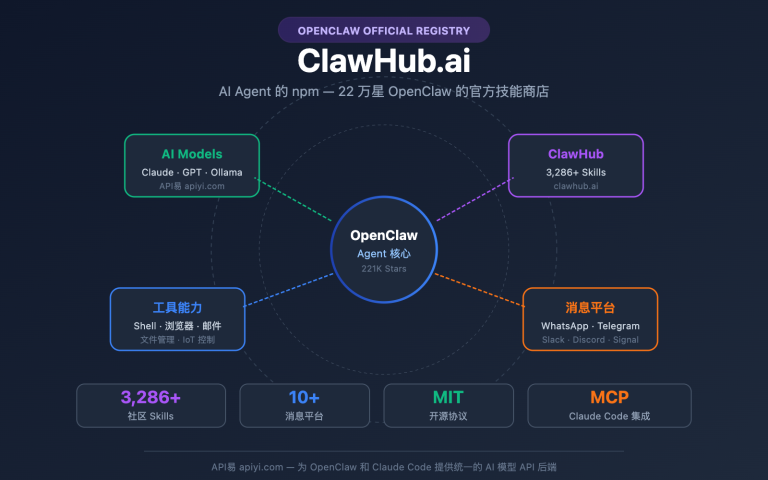
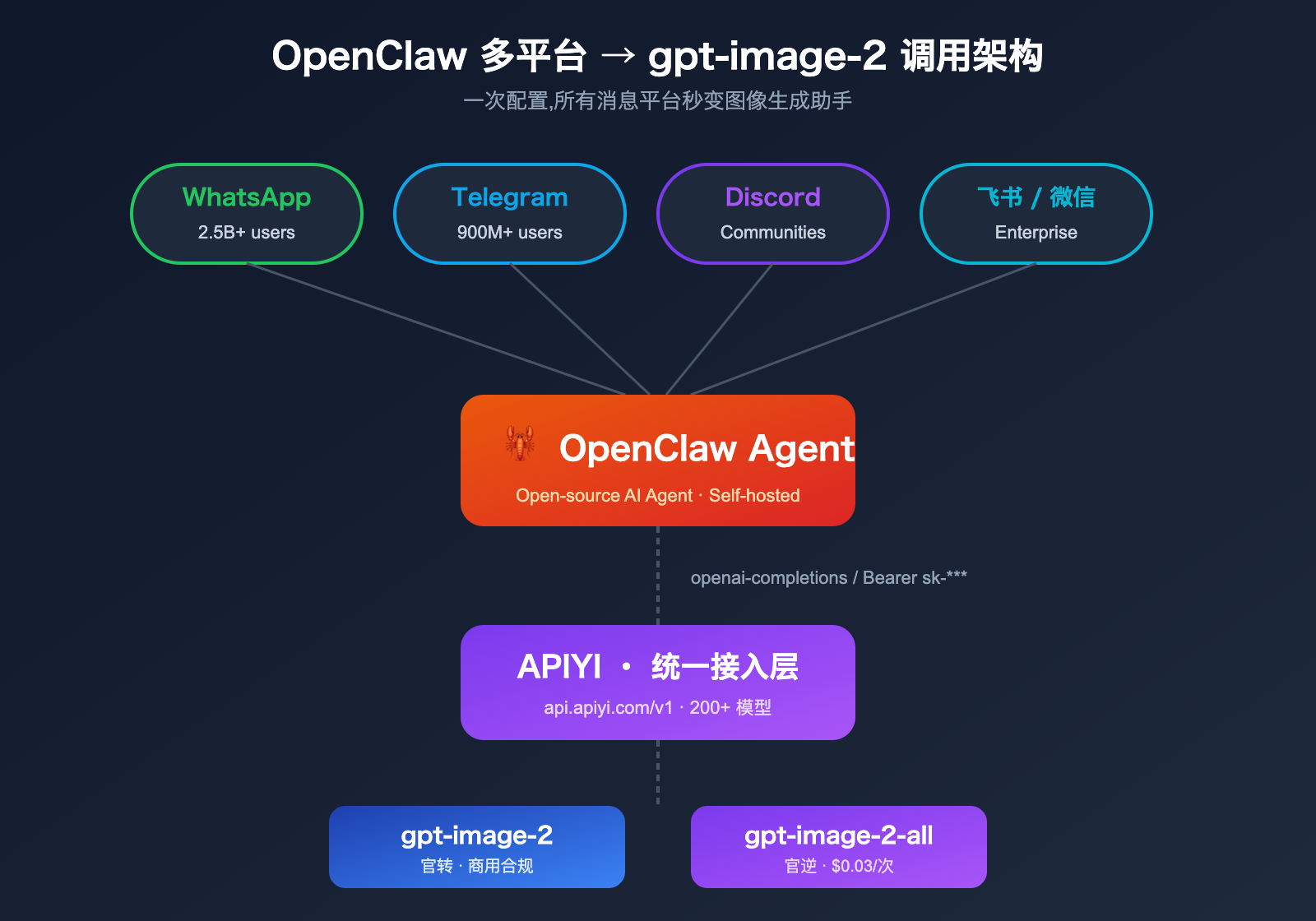
OpenClaw (github.com/openclaw/openclaw) 是 2026 年最受关注的开源自主 AI Agent 之一,支持 WhatsApp、Telegram、Slack、Discord、iMessage、Feishu、微信、企业微信等 20+ 消息平台。它本身模型无关 (model-agnostic),通过 OpenAI 兼容协议接入第三方 API 服务,这给 gpt-image-2 这种顶级图像模型提供了完美的整合入口。
本文从架构选型到落地配置,完整讲清楚两种接入方案的差异,并给出可直接复用的 openclaw.json 配置代码。
一、为什么 OpenClaw 接 gpt-image-2 需要专门的方案
很多用户的第一反应是: "OpenClaw 不是已经支持 OpenAI 了吗,直接配置 OpenAI API Key 不就行了?" 这个想法在原理上没错,但在工程落地上有 3 个绕不过的问题。
1.1 直接接 OpenAI 官方 API 的三个限制
| 限制项 | 具体表现 | 影响 |
|---|---|---|
| 地区访问 | 中国大陆/部分东南亚地区无法直连 api.openai.com | 服务无法启动 |
| 计费门槛 | 需要海外信用卡 + Tier 1 起 (Tier 5 才能稳定用 image API) | 个人/小团队难以满足 |
| Organization Verified | gpt-image-2 高质量参数需要组织验证 (人脸识别) | 国内开发者卡在验证环节 |
🎯 快速上手建议: 如果你已经在 OpenClaw 中接入了其他模型 (例如 Claude),只需要替换
models.providers配置即可让gpt-image-2在所有 OpenClaw 支持的消息平台 (WhatsApp/Telegram/Discord 等) 中可用。我们建议通过 API易 apiyi.com 平台接入,该平台已经处理好上述三个问题,提供国内低延迟节点和按次计费方案。
1.2 OpenClaw 调用图像生成的两种内部机制
OpenClaw 在内部对图像生成有两种实现路径:
路径 A: 走 image_generate 工具
- 配置: models.providers.openai.baseUrl
- 调用: 标准 OpenAI Images API (POST /v1/images/generations)
- 适用: gpt-image-2 / gpt-image-1 / DALL-E 3
路径 B: 走 chat completions 工具
- 配置: 自定义 OpenAI 兼容 provider
- 调用: 标准 Chat API (POST /v1/chat/completions)
- 适用: 任何能在对话流中返回图片的"对话型图像模型"
关键认知: gpt-image-2-all 是 APIYI 提供的"对话兼容版"图像模型,它把图像生成能力封装在标准 chat completions 协议中,响应格式中直接返回图片 URL。这种设计让 OpenClaw 可以像调用普通对话模型一样调用它,无需切换到专门的 image API。
1.3 两种方案的本质差异
| 维度 | 方案 A: Skills | 方案 B: OpenAI 兼容模式 |
|---|---|---|
| 调用方式 | 通过预装 Skill 触发 | 标准 chat completions 调用 |
| 客户端要求 | 需要支持 Skills (Codex CLI/Cursor 等) | 任何 OpenAI 兼容客户端 |
| OpenClaw 适配 | 间接支持 (通过 Agent 子调用) | ✅ 直接支持 |
| 部署成本 | 需要 npm 安装 + 配置环境变量 | 仅需修改 openclaw.json |
| 模型类型 | gpt-image-2 (官转) / gpt-image-2-all (官逆) | gpt-image-2-all (官逆,推荐) |
| 计费方式 | 按 token / 按图片 | 按次 $0.03 (折扣前) |
| 适用场景 | 开发工具中代码生成图片 | 消息平台对话生图 |
二、方案 A: 通过 APIYI Skills 接入 gpt-image-2
如果你的工作流是: 在 Codex CLI / Cursor / OpenCode / Gemini CLI 等开发工具中,调用 OpenClaw Agent 执行任务时顺便生成图片,Skills 方案是最优雅的接入方式。
2.1 Skills 方案的两个可选模型
APIYI 在 GitHub 开源了两个 Skills (作者: wuchubuzai2018,仓库: expert-skills-hub):
| Skill 名称 | 底层模型 | 特点 | 推荐场景 |
|---|---|---|---|
apiyi-gpt-image-2-gen |
gpt-image-2 (官转) | OpenAI 官方,质量最高 | 商用项目、需 Indemnification |
apiyi-gpt-image-2-all-gen |
gpt-image-2-all (官逆) | 按次计费,接入门槛低 | 个人项目、快速原型 |
2.2 安装 Skills (3 行命令)
# 1. 安装官转版 (推荐商用)
npx skills add https://github.com/wuchubuzai2018/expert-skills-hub --skill apiyi-gpt-image-2-gen
# 2. 或者安装官逆版 (按次计费版)
npx skills add https://github.com/wuchubuzai2018/expert-skills-hub --skill apiyi-gpt-image-2-all-gen
# 3. 配置环境变量
export APIYI_API_KEY="sk-your-key-from-apiyi-console"
🎯 API Key 获取: 注册账号后,进入"API Keys"页面创建新的 Key,以
sk-开头。Key 在所有提供的服务中通用,包括官转和官逆模型。
2.3 在 OpenClaw 中调用已安装的 Skills
OpenClaw 通过 Agent 配置,可以在执行复杂任务时子调用已安装的 Skills:
# openclaw 配置片段 (示意)
agents:
- id: image-helper
description: "图片生成助手"
skills:
- apiyi-gpt-image-2-gen
- apiyi-gpt-image-2-all-gen
triggers:
- keyword: "生成图片"
- keyword: "画一张"
实际使用时,只需要在 OpenClaw 接入的消息平台中(例如 Telegram)发送:
@OpenClawBot 帮我生成一张赛博朋克风格的咖啡馆插图,1024x1024
OpenClaw 会:
- 识别触发词,激活 image-helper agent
- 调用 apiyi-gpt-image-2-gen Skill
- 通过 APIYI 平台调用
gpt-image-2 - 返回图片 URL 到对话中
2.4 Skills 方案的优势与限制
优势:
- ✅ 复用社区维护的 Skill 代码,不用自己写图像生成逻辑
- ✅ 自动处理 prompt 优化、错误重试、图片格式转换
- ✅ 与开发工具 (Codex CLI/Cursor) 原生兼容
限制:
- ❌ OpenClaw 对 Skills 的支持依赖具体 Agent 配置
- ❌ 需要 Node.js 环境
- ❌ 不支持纯消息平台 (例如纯 WhatsApp 用户) 的开箱即用调用
如果你的 OpenClaw 主要用于消息平台,直接看方案 B。
三、方案 B: OpenAI 兼容模式接入 gpt-image-2-all
这是最适合 OpenClaw 主流场景的接入方式——通过修改 OpenClaw 的 models.providers 配置,把 APIYI 作为自定义 OpenAI 兼容 provider 注册进去,然后调用 gpt-image-2-all 这个对话兼容版本的图像模型。

3.1 修改 openclaw.json 配置
OpenClaw 的核心配置文件位于 ~/.openclaw/openclaw.json (macOS/Linux) 或 %APPDATA%\openclaw\openclaw.json (Windows)。
{
"models": {
"providers": {
"apiyi": {
"api": "openai-completions",
"baseUrl": "https://api.apiyi.com/v1",
"apiKey": "sk-your-key-from-apiyi-console",
"models": [
{
"id": "gpt-image-2-all",
"name": "GPT Image 2 (对话兼容版)",
"contextWindow": 8000,
"maxTokens": 4096,
"capabilities": ["text", "image_generation"]
}
]
}
}
},
"gateway": {
"http": {
"endpoints": {
"chatCompletions": {
"enabled": true
}
}
}
}
}
🎯 base_url 配置: 上述配置的 baseUrl 必须以
/v1结尾。标准 endpoint 与 OpenAI 官方接口完全兼容,无需修改其他参数。
3.2 重启 OpenClaw 并验证
# 重启 OpenClaw 服务 (根据安装方式)
openclaw restart
# 或者通过 systemd
sudo systemctl restart openclaw
# 验证 provider 已加载
openclaw models list | grep apiyi
成功输出示例:
Provider: apiyi (status: ✓ healthy)
Models:
- apiyi/gpt-image-2-all (chat + image_generation)
3.3 在消息平台中调用
配置完成后,任何接入 OpenClaw 的消息平台都可以直接生图。以 Telegram 为例:
[用户消息]
画一张穿宇航服的小猫坐在月球表面的图片,卡通风格
[OpenClaw 响应]
🎨 正在为您生成图片...
[图片] https://files.apiyi.com/generated/xxx.png
✅ 生成完成,本次消耗 $0.03
3.4 完整的 chat completions 调用示例 (开发者参考)
如果你想从代码层调试,以下是 OpenClaw 内部对 gpt-image-2-all 的调用方式:
import openai
client = openai.OpenAI(
api_key="sk-your-key",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-image-2-all",
messages=[
{
"role": "user",
"content": "画一张穿宇航服的小猫坐在月球表面的图片,卡通风格"
}
]
)
# response 中会包含图片 URL (Markdown 格式)
print(response.choices[0].message.content)
# 输出: 
📦 完整版含错误处理 (点击展开)
import os
import openai
import logging
from openai import APIError, RateLimitError
client = openai.OpenAI(
api_key=os.environ["APIYI_API_KEY"],
base_url="https://api.apiyi.com/v1",
timeout=120.0 # 图像生成需要更长超时
)
def generate_image_via_chat(prompt: str, max_retries: int = 3):
"""通过 chat completions 调用 gpt-image-2-all"""
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model="gpt-image-2-all",
messages=[{"role": "user", "content": prompt}],
stream=False
)
content = response.choices[0].message.content
return parse_image_url(content)
except RateLimitError:
logging.warning(f"Rate limit, retry {attempt+1}/{max_retries}")
continue
except APIError as e:
logging.error(f"API error: {e}")
if attempt == max_retries - 1:
raise
return None
def parse_image_url(content: str) -> str:
"""从 Markdown 响应中提取图片 URL"""
import re
match = re.search(r'!\[.*?\]\((.*?)\)', content)
return match.group(1) if match else None
if __name__ == "__main__":
url = generate_image_via_chat(
"画一张穿宇航服的小猫坐在月球表面的图片,卡通风格"
)
print(f"图片 URL: {url}")
四、gpt-image-2 vs gpt-image-2-all: 模型选型决策
OpenClaw 用户最常问的问题是: 到底用官转还是官逆? 这取决于你的具体场景和优先级。

4.1 两个模型的关键差异
| 维度 | gpt-image-2 (官转) | gpt-image-2-all (官逆) |
|---|---|---|
| 调用接口 | /v1/images/generations |
/v1/chat/completions |
| OpenClaw 适配 | 需 Skills 间接调用 | 直接走 chat 工具 |
| 计费模型 | 按 token + 输出尺寸 | 按次 $0.03 (折扣前) |
| 单次成本 | $0.04 – $0.19 (随质量) | $0.03 固定 |
| 内容安全 | OpenAI 双层 (auto/low) | 同源安全策略 |
| Indemnification | ✅ 适用 | ❌ 不适用 |
| 响应速度 | 8-15 秒 | 10-20 秒 |
| 支持分辨率 | 最高 2K | 最高 1024×1024 |
| 商用建议 | ✅ 推荐 | 仅限内部/原型 |
4.2 不同场景的选型建议
| 业务场景 | 推荐模型 | 原因 |
|---|---|---|
| 个人用 OpenClaw + Telegram 玩生图 | gpt-image-2-all | 按次便宜、配置简单 |
| 企业 SaaS 集成 OpenClaw 客服 | gpt-image-2 | 商用合规、Indemnification |
| 跨境电商商品图批量生成 | gpt-image-2 | 2K 分辨率、商用授权 |
| 内部团队 brainstorm 工具 | gpt-image-2-all | 成本可控、原型够用 |
| 教育/科普内容图片生成 | gpt-image-2-all | 单次低成本、批量友好 |
🎯 混合策略建议: 实际项目中,我们建议开发阶段使用
gpt-image-2-all控制成本,正式上线切换到gpt-image-2。API易 apiyi.com 平台两个模型共用同一个 API Key,只需要修改请求中的model字段即可切换,迁移成本接近零。
4.3 计费实例对比
假设一个 OpenClaw 群机器人每天处理 100 次图片生成请求:
| 模型 | 单价 | 日成本 | 月成本 (30 天) | 年成本 |
|---|---|---|---|---|
| gpt-image-2 (high quality) | $0.19 | $19 | $570 | $6,840 |
| gpt-image-2 (medium) | $0.07 | $7 | $210 | $2,520 |
| gpt-image-2-all | $0.03 | $3 | $90 | $1,080 |
| gpt-image-2-all (折扣后) | ~$0.02 | $2 | $60 | $720 |
关键洞察: 对于个人/小团队的 OpenClaw 部署,选 gpt-image-2-all 一年能省 $5,000+,且功能差异在消息平台场景中并不明显。
五、OpenClaw + gpt-image-2 实战场景示例
讲完原理和配置,看几个真实可复制的应用场景。
5.1 场景一: Telegram 群组的图片生成助手
配置: OpenClaw 接入 Telegram + APIYI 自定义 provider + gpt-image-2-all
用户体验:
[群成员 A]
@OpenClawBot 给我画一张周一早会的卡通插图,要有困倦的程序员和大杯咖啡
[OpenClawBot]
🎨 正在生成,预计 15 秒...
[图片显示]
✅ 已生成 (本次 $0.03)
👍 喜欢的话发我 ⭐️
配置要点:
- 在
openclaw.json中添加 telegram channel 配置 - 设置图片生成的关键词触发器: "画一张" / "生成图片" / "draw" / "create image"
- 启用 rate limiting,避免群成员滥用
5.2 场景二: WhatsApp 客服自动配图
业务背景: 跨境电商客服在 WhatsApp 上回复客户,需要快速生成商品场景图。
配置:
{
"agents": {
"wa-cs-agent": {
"channel": "whatsapp",
"model": "apiyi/gpt-image-2-all",
"system_prompt": "你是电商客服助手,当用户询问商品时,可以生成商品场景图辅助说明。",
"tools": ["image_generate", "knowledge_search"]
}
}
}
对话示例:
[客户]
这款蓝牙耳机戴起来好看吗?
[客服 Agent]
我帮您生成一张实际佩戴场景的参考图 👇
[图片: 年轻人户外慢跑佩戴蓝牙耳机的场景]
您可以参考这个佩戴效果,我们的耳机重量仅 8g,长时间佩戴也不会感觉沉重 🏃
5.3 场景三: Discord 社区的内容创作机器人
业务背景: 一个游戏社区 Discord,管理员希望机器人能根据用户描述生成游戏角色立绘。
实现思路:
- OpenClaw 接入 Discord
- 使用 slash command
/generate触发图像生成 - 结合用户 role 做权限管理 (普通用户每日 5 次,会员无限)
- 调用
gpt-image-2-all节省成本
Discord 命令注册片段:
@bot.command(name="generate")
async def generate_image(ctx, *, prompt: str):
# 检查用户权限和当日配额
if not check_quota(ctx.author):
await ctx.send("❌ 今日配额已用完,升级会员解除限制")
return
# 调用 OpenClaw 的 chat completions endpoint
image_url = await openclaw_client.generate(
model="apiyi/gpt-image-2-all",
prompt=prompt
)
await ctx.send(f"🎨 {ctx.author.mention} 你的角色立绘:\n{image_url}")
decrement_quota(ctx.author)
5.4 场景四: 企业微信 + 飞书内部工具
业务背景: 企业内部需要快速生成会议海报、社交媒体配图、活动 banner。
OpenClaw 配置策略:
- 接入企业微信和飞书双 channel
- 配置使用
gpt-image-2(官转,商用合规) - 加入企业品牌词关键词审核 (避免生成竞品 logo)
- 所有生成图片记录到内部对象存储,便于二次使用
🎯 企业级集成建议: 企业级场景建议使用官转模型 (
gpt-image-2) 以确保 Indemnification 保护。同时建议通过 API易 apiyi.com 这类支持企业对公账户、月度发票的中转平台接入,便于财务记账和合规审计。
六、按次计费 $0.03 是怎么算的: 成本透明化
很多用户对"按次计费"的具体含义有疑问。这一节把 gpt-image-2-all 的计费逻辑讲清楚。
6.1 单次调用的成本明细
gpt-image-2-all 计费规则 (折扣前)
─────────────────────────────────
基础生成成本: $0.03 / 次
├─ 1024×1024 标准分辨率: 包含
├─ 1024×1792 (竖图): 包含
├─ 1792×1024 (横图): 包含
└─ 失败请求 (safety violations): 不计费
附加成本: $0
├─ 不按 token 计费
├─ 不按图片字节计费
└─ 不区分 prompt 长度
6.2 与官转模型的成本对比
| 调用模式 | 单次价格 (折扣前) | 备注 |
|---|---|---|
| gpt-image-2 low quality 1024² | ~$0.04 | 按 token 折算 |
| gpt-image-2 medium quality 1024² | ~$0.07 | 按 token 折算 |
| gpt-image-2 high quality 1024² | ~$0.19 | 按 token 折算 |
| gpt-image-2 high 2K | ~$0.27 | 高分辨率溢价 |
| gpt-image-2-all (任意分辨率) | $0.03 | 按次固定 |
6.3 折扣后的实际成本
APIYI 平台对充值金额提供阶梯折扣:
| 充值金额 | 折扣率 | gpt-image-2-all 实际单价 |
|---|---|---|
| < $50 | 无折扣 | $0.030 |
| $50 – $200 | 9 折 | $0.027 |
| $200 – $1000 | 8 折 | $0.024 |
| $1000+ | 7 折 | $0.021 |
| 企业月结 | 协商定价 | 可低至 $0.018 |
🎯 成本优化建议: 如果你的 OpenClaw 部署预计每月调用超过 5000 次图片生成,建议联系 API易 apiyi.com 商务团队申请企业月结方案,可以拿到 7 折以下的价格,适合做 AI 产品的开发者和创业团队。
6.4 为什么按次计费比按 token 更适合 OpenClaw 场景
OpenClaw 主要使用消息平台,用户的生图请求长度差异很大:
- 短 prompt: "画一只猫" (~5 token)
- 长 prompt: "画一张赛博朋克风格的未来城市夜景,霓虹灯倒映在湿漉漉的街道上,远处有飞行汽车…" (~80 token)
如果按 token 计费,长 prompt 用户会"心理负担"主动缩短描述,反而损失图片质量。按次计费让用户专注于描述质量,而非 token 长度——这是 gpt-image-2-all 设计的核心理念。
七、OpenClaw 接 gpt-image-2 高频 FAQ
Q1: OpenClaw 默认配置就支持 gpt-image-2 吗?
不支持。OpenClaw 默认只接 OpenAI 官方 API,中国大陆用户无法直连,且 gpt-image-2 需要 Tier 5 以上账户才能稳定使用。必须通过自定义 provider (例如配置 APIYI 作为 OpenAI 兼容服务) 才能用上。
Q2: 我修改了 openclaw.json 后,OpenClaw 没识别到新 provider?
排查步骤:
- JSON 格式检查:
cat ~/.openclaw/openclaw.json | jq .(无报错说明格式正确) - 重启服务:
openclaw restart或对应的 systemctl 命令 - 查看日志:
openclaw logs --tail 100检查是否有 provider 加载错误 - 验证 baseUrl: 确保以
/v1结尾,不要写/v1/(尾随斜杠) - 验证 apiKey: 在控制台确认 Key 仍有效
Q3: 调用 gpt-image-2-all 时报 "model not found" 错误?
通常是以下原因之一:
models数组中的id字段拼错 (应该是gpt-image-2-all,不是gpt-image-2-all-model)api字段写成openai而非openai-completions- OpenClaw 版本过旧 (需要 ≥ v0.45 才完整支持自定义 provider)
Q4: gpt-image-2-all 生成的图片可以商用吗?
法律层面: APIYI 在用户协议中说明了官逆模型的使用限制,严格商用建议使用官转模型 (gpt-image-2)。原因是官逆通道本身违反 OpenAI ToS,产生的图片在 Indemnification 保护范围之外。
实际选择:
- 个人项目、内部工具、原型验证: ✅ 用 gpt-image-2-all
- 商品广告、客户交付物、品牌素材: ✅ 用 gpt-image-2
Q5: 在 WhatsApp/Telegram 中调用 gpt-image-2-all 经常超时?
图像生成的实际耗时是 10-20 秒,如果消息平台显示超时,可能是:
- OpenClaw
requestTimeout配置过短 (建议设置 ≥ 60 秒) - 网络抖动 (中转节点可选 Hong Kong / Singapore 改善延迟)
- 模型负载高峰 (建议加 retry 逻辑,通常重试一次成功率 > 95%)
Q6: 一个 API Key 能同时供多个 OpenClaw 实例使用吗?
可以。但建议:
- 单 Key 总 QPS 控制在 50 以内 (避免触发限流)
- 大规模部署 (10+ 实例) 时使用多个 Key 做负载分摊
- 在控制台启用"使用日志",方便排查跨实例的问题
Q7: OpenClaw 调用图片生成时,如何把图片永久保存到自己的对象存储?
OpenClaw 默认会把图片 URL 直接返回给消息平台,但生成的 URL 通常有有效期 (24-72 小时)。如果需要永久保存:
# 在 OpenClaw agent hook 中配置
async def post_image_generation_hook(image_url: str):
# 下载图片到本地
image_data = await download(image_url)
# 上传到企业对象存储
permanent_url = await upload_to_oss(image_data, bucket="ai-images")
return permanent_url
Q8: 如何在 OpenClaw 中限制单用户的每日生图次数?
OpenClaw 自带 rate limiting 机制,在 openclaw.json 中配置:
{
"rateLimits": {
"imageGeneration": {
"perUser": {
"daily": 50,
"hourly": 10
},
"perChannel": {
"daily": 500
}
}
}
}
Q9: gpt-image-2-all 不支持参考图编辑 (image-to-image) 吗?
当前版本不支持。如果需要参考图编辑,有两个方案:
- 使用
gpt-image-2官转模型,通过/v1/images/edits端点 (需用 Skills 方案接入) - 等待 APIYI 后续推出的
gpt-image-2-all-edit变体 (路线图中)
Q10: OpenClaw 接 gpt-image-2 会上报使用数据给 OpenAI 吗?
API 调用本身一定会。任何通过 API 调用的 prompt 和生成的图片,OpenAI 服务器都会有日志记录 (用于安全审查,默认 30 天保留)。但 OpenAI 明确承诺不会用 API 数据训练模型,这一点写在 Service Terms 中。
八、总结: OpenClaw 接入 gpt-image-2 的最佳实践
回顾本文,接入路径的选择可以归纳为三句话。
8.1 三句话决策建议
✅ 如果你只用 OpenClaw + 消息平台 (WhatsApp/Telegram/Discord)
→ 选方案 B: OpenAI 兼容模式 + gpt-image-2-all
理由: 配置最简单、按次计费最透明、与 chat 流原生兼容
✅ 如果你用 Codex CLI / Cursor + OpenClaw 联动开发
→ 选方案 A: APIYI Skills (apiyi-gpt-image-2-gen)
理由: Skills 生态更适合开发工具链
✅ 如果你做企业级商用产品
→ 选方案 A + gpt-image-2 官转
理由: Indemnification 保护、商用合规、2K 分辨率
8.2 完整接入 Checklist
接入完成后,用以下清单做最后检查:
| 检查项 | 通过标准 |
|---|---|
| openclaw.json 格式 | 通过 jq 校验无错误 |
| baseUrl 配置 | 以 /v1 结尾,无尾斜杠 |
| apiKey 验证 | curl 测试可正常返回 |
| chatCompletions endpoint | 已设置 enabled: true |
| 模型列表 | openclaw models list 看到 apiyi/* |
| 消息平台测试 | 发"画一张猫"能正常返回图片 |
| 错误日志 | openclaw logs 无 ERROR 级别输出 |
| Rate limit | 已配置防滥用阈值 |
8.3 进一步优化方向
接入完成只是起点。在生产环境中,还可以做这些优化:
- Prompt 增强: 在 OpenClaw agent 配置中加 system prompt,自动给用户的简短描述补全风格、构图等参数
- 图片缓存: 对相同 prompt 做哈希,命中缓存的请求不重复调用 API
- 多模型 fallback: 主模型 (gpt-image-2-all) 失败时,自动降级到备用模型 (例如 Imagen 4)
- 生成日志: 把 prompt 和生成结果记录到数据库,便于事后审计和数据分析
🎯 总体建议:
gpt-image-2与OpenClaw的组合是 2026 年 AI Agent 落地最值得尝试的搭配之一——把顶级图像模型直接放到日常使用的消息平台中,极大降低了 AI 工具的使用门槛。建议通过 API易 apiyi.com 平台快速完成接入,该平台同时支持官转和官逆两种模式,可以根据实际使用情况灵活切换。
OpenClaw 的开放架构让它能接入几乎任何 OpenAI 兼容服务,而 gpt-image-2 是当前图像生成领域的最强模型之一。把这两者结合,你就拥有了一个跑在 WhatsApp/Telegram/Discord 上的 SOTA 级图像生成助手——这在一年前还是不可想象的能力组合。
最后送一句话: "工具的价值不在于功能多强,而在于多快能用到日常工作流中。" OpenClaw + gpt-image-2 的组合恰好满足这个标准——10 分钟完成配置,马上就能用,这是它最大的魅力。
作者: APIYI Team — 企业级 AI 大模型 API 接入平台 apiyi.com,提供 gpt-image-2、gpt-image-2-all、Claude 4.7、Gemini 3 Pro 等 200+ 主流模型的统一接口调用,支持 OpenAI 兼容协议,适配 OpenClaw、Cursor、Codex CLI、Open WebUI 等主流客户端。
参考资料: OpenClaw 官方文档 docs.openclaw.ai · GPT-Image Skills GitHub: github.com/wuchubuzai2018/expert-skills-hub