作者注:深度解析 MiniMax-M2.7 与 M2.7-highspeed 两款模型的核心能力、性能基准和 API 接入方式,帮助开发者以极低成本获得旗舰级 AI 能力
MiniMax 于 2026 年 3 月 18 日发布了 MiniMax-M2.7 旗舰大模型,这是首个深度参与自身进化过程的 AI 模型。仅用 10B 激活参数就达到了与 Claude Opus 4.6、GPT-5 同级的 Tier-1 性能,同时价格低至主流旗舰的 1/50。同步推出的 MiniMax-M2.7-highspeed 版本更将输出速度提升 66%,达到 100 tps。
核心价值: 通过真实基准数据和接入教程,帮你判断 MiniMax-M2.7 是否是当前性价比最高的旗舰模型选择。

MiniMax-M2.7 核心要点
| 要点 | 说明 | 价值 |
|---|---|---|
| 230B 总参数 / 10B 激活 | 稀疏混合专家架构(MoE),每次推理仅激活 10B 参数 | 旗舰性能 + 极低推理成本 |
| 递归自进化训练 | 模型自主运行 100+ 轮迭代优化自身训练流程 | 无需人工干预即可提升 30% 性能 |
| SWE-bench 78% | 软件工程基准大幅领先 Opus 4.6 的 55% | 编程和工程任务首选 |
| 价格仅为 Opus 的 1/50 | 输入 $0.30/M,输出 $1.20/M tokens | 企业级大规模部署成本骤降 |
MiniMax-M2.7 技术架构详解
MiniMax-M2.7 采用稀疏混合专家(Sparse Mixture-of-Experts)Transformer 架构,总参数量达到 230B,但每个 Token 仅激活 10B 参数。这一设计让 M2.7 成为同性能级别中体积最小的模型——用最低的计算资源实现了与 Claude Opus 4.6、GPT-5 同级别的 Tier-1 表现。
上下文窗口达到 205K tokens(约 307 页 A4 文档),支持长文档分析、大型代码库理解等场景。在 Artificial Analysis Intelligence Index 评测中,M2.7 以满分 50 分位列 136 个同级模型第一。
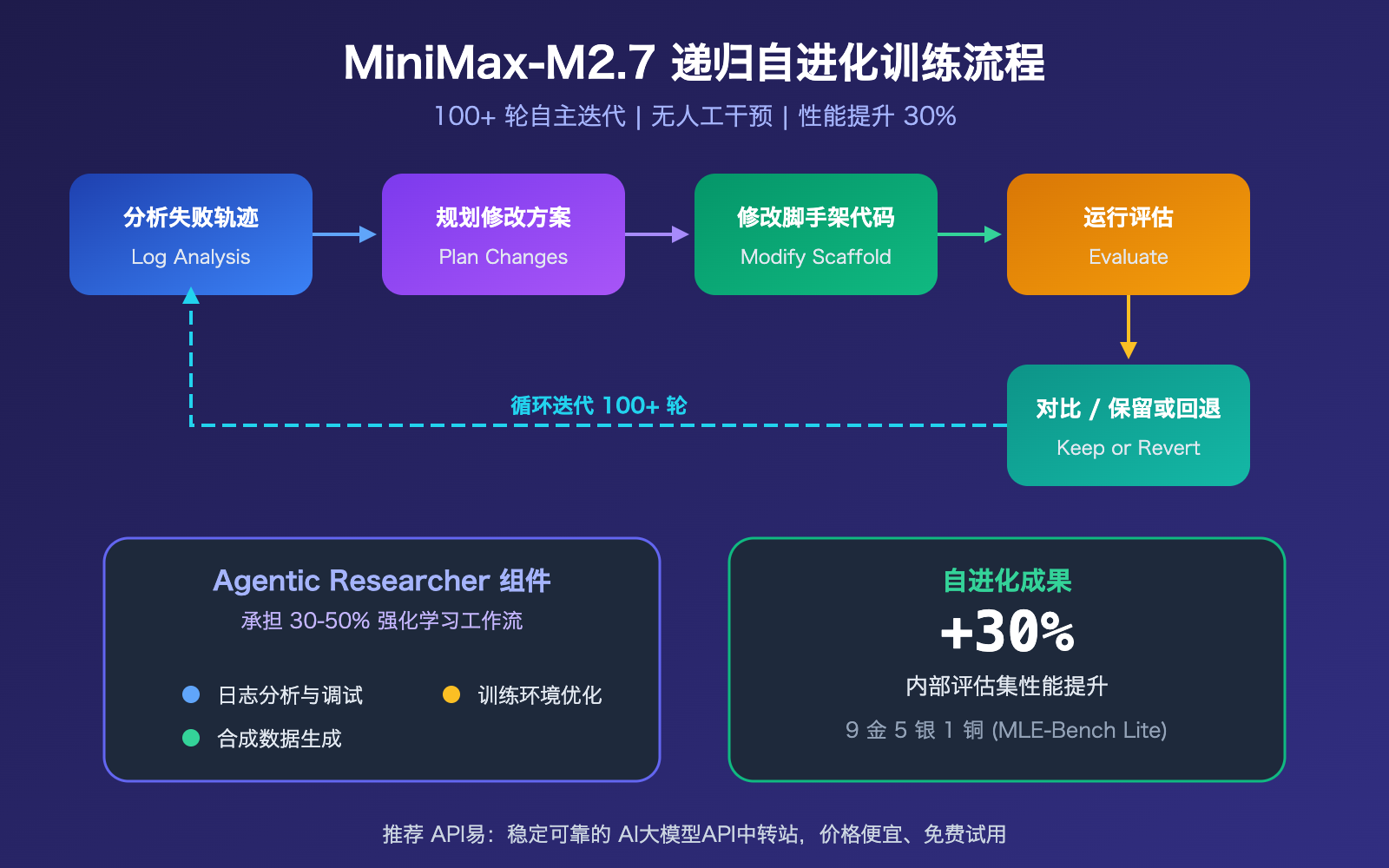
MiniMax-M2.7 递归自进化机制
"递归自进化"是 M2.7 最具突破性的技术亮点。模型在训练过程中自主执行了一个完整的迭代循环:分析失败轨迹 → 规划修改 → 修改训练脚手架代码 → 运行评估 → 对比结果 → 决定保留或回退。这个过程完全自主运行了 100+ 轮。
其核心组件"Agentic Researcher"承担了 30-50% 的强化学习工作流,包括日志分析与调试、合成数据生成以及训练环境优化。最终实现了无人工干预下 30% 的性能提升。
MiniMax-M2.7 性能基准与模型对比
MiniMax-M2.7 基准测试成绩
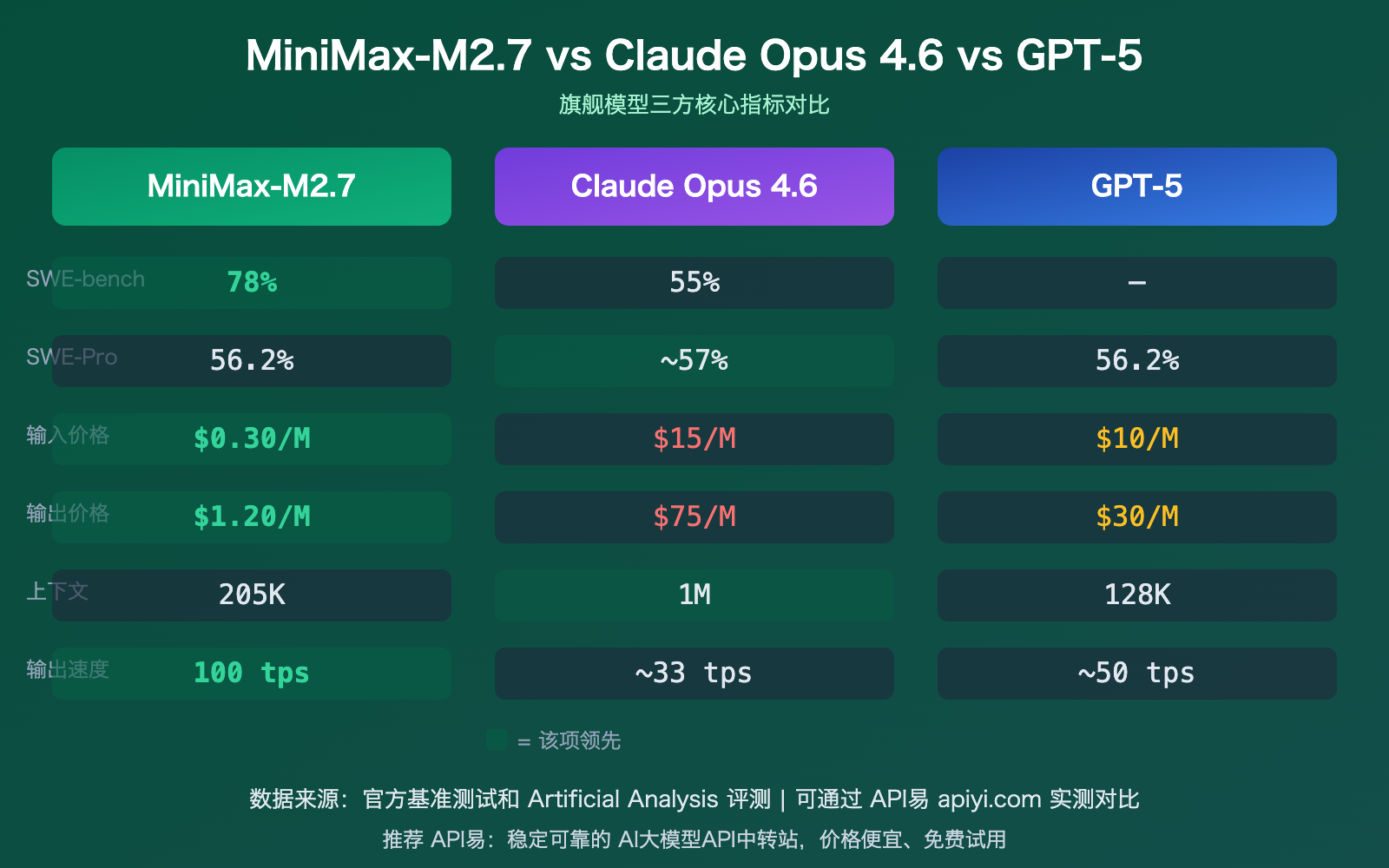
| 基准测试 | M2.7 得分 | Claude Opus 4.6 | GPT-5 系列 | 说明 |
|---|---|---|---|---|
| SWE-bench Verified | 78% | 55% | — | 软件工程实战,大幅领先 |
| SWE-Pro | 56.2% | ~57% | 56.2% (Codex) | 接近旗舰水准 |
| VIBE-Pro | 55.6% | — | — | 端到端项目交付 |
| Terminal Bench 2 | 57.0% | — | — | 复杂工程系统 |
| MLE-Bench Lite | 66.6% | 75.7% | 71.2% (5.4) | ML 竞赛,9金5银1铜 |
| GDPval-AA ELO | 1495 | — | — | 办公生产力第一 |
MiniMax-M2.7 价格对比
M2.7 的定价策略极具冲击力,在几乎同等性能水平下,成本仅为主流旗舰模型的几十分之一:
| 指标 | MiniMax-M2.7 | Claude Opus 4.6 | GPT-5 | 倍数差异 |
|---|---|---|---|---|
| 输入价格 | $0.30/M | $15/M | $10/M | 50x / 33x 更便宜 |
| 输出价格 | $1.20/M | $75/M | $30/M | 62x / 25x 更便宜 |
| 上下文窗口 | 205K | 1M | 128K | 介于两者之间 |
| 激活参数 | 10B | — | — | 最小的 Tier-1 模型 |
🎯 选择建议: MiniMax-M2.7 在编程和工程任务上表现出色,性价比极高。我们建议通过 API易 apiyi.com 平台快速接入测试,该平台支持 MiniMax-M2.7 和 M2.7-highspeed 的统一接口调用,便于与其他旗舰模型进行实际对比。
MiniMax-M2.7-highspeed 高速版详解
MiniMax-M2.7-highspeed 是 M2.7 旗舰系列的性能优化版本,与标准版产出完全相同的结果——两者智能水平一致,highspeed 版本专为对延迟敏感的应用场景而设计。
MiniMax-M2.7-highspeed 核心优势
- 输出速度: 达到 100 tokens/s,比标准版提升 66%
- 亚秒级延迟: 优化了首 Token 响应时间,适合实时交互
- 增强推理骨干架构: 底层推理引擎专门优化,非简单量化降级
- 结果一致性: 与标准版输出完全相同,不牺牲智能水平
MiniMax-M2.7-highspeed 适用场景
| 场景 | 说明 | 为何选择 highspeed |
|---|---|---|
| 交互式编程助手 | IDE 内实时代码补全和重构 | 亚秒级响应提升编码体验 |
| 实时智能体循环 | Agent Loop 多步推理执行 | 减少每步等待,加速整体流程 |
| 高吞吐企业流水线 | 批量文档处理、数据提取 | 100 tps 大幅缩短完成时间 |
| 在线客服系统 | 实时对话和问题解答 | 用户无感知的快速响应 |
建议: 如果你的应用对响应速度有严格要求,MiniMax-M2.7-highspeed 是目前旗舰级模型中速度最快的选择之一。通过 API易 apiyi.com 可以直接调用该模型。
MiniMax-M2.7 API 快速上手
极简示例
以下是通过 API易平台调用 MiniMax-M2.7 的最简代码,10 行即可运行:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="MiniMax-M2.7",
messages=[{"role": "user", "content": "分析这段代码的性能瓶颈并给出优化建议"}]
)
print(response.choices[0].message.content)
查看完整实现代码(含 highspeed 版本切换)
import openai
from typing import Optional
def call_minimax_m27(
prompt: str,
model: str = "MiniMax-M2.7",
system_prompt: Optional[str] = None,
max_tokens: int = 2000,
use_highspeed: bool = False
) -> str:
"""
调用 MiniMax-M2.7 或 M2.7-highspeed
Args:
prompt: 用户输入
model: 模型名称
system_prompt: 系统提示词
max_tokens: 最大输出 token 数
use_highspeed: 是否使用 highspeed 版本
"""
if use_highspeed:
model = "MiniMax-M2.7-highspeed"
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
response = client.chat.completions.create(
model=model,
messages=messages,
max_tokens=max_tokens
)
return response.choices[0].message.content
# 标准版调用
result = call_minimax_m27(
prompt="用 Python 实现一个高效的 LRU 缓存",
system_prompt="你是一位资深的 Python 工程师"
)
# highspeed 版调用(适合实时场景)
fast_result = call_minimax_m27(
prompt="快速解释这段代码的作用",
use_highspeed=True
)
建议: 通过 API易 apiyi.com 获取免费测试额度,快速验证 MiniMax-M2.7 在你的业务场景中的表现。平台支持标准版和 highspeed 版的一键切换。
MiniMax-M2.7 与竞品模型方案对比
| 方案 | 核心特点 | 适用场景 | 性价比 |
|---|---|---|---|
| MiniMax-M2.7 | 10B 激活参数,SWE-bench 78% | 编程、Agent 工作流、大规模部署 | 极高($0.30/$1.20) |
| M2.7-highspeed | 100 tps,66% 速度提升 | 实时交互、IDE 集成、Agent Loop | 极高 + 快 |
| Claude Opus 4.6 | 1M 上下文,综合能力最强 | 超长文档、复杂推理、全能任务 | 中等($15/$75) |
| GPT-5 | 成熟生态,多模态支持 | 通用场景、多模态应用 | 中等($10/$30) |
对比说明: 上述数据来源于官方基准测试和 Artificial Analysis 第三方评测,可通过 API易 apiyi.com 平台进行实际对比验证。
常见问题
Q1: MiniMax-M2.7 和 M2.7-highspeed 输出结果有区别吗?
两者输出完全一致。highspeed 版本通过优化推理引擎实现更快的 Token 生成速度(100 tps),但不改变模型的智能水平和输出质量。如果你的场景对延迟不敏感,使用标准版即可。
Q2: MiniMax-M2.7 的”递归自进化”意味着模型会持续变化吗?
不会。递归自进化是 MiniMax 在训练阶段采用的技术方法——模型自主迭代优化了训练流程和参数。一旦发布,模型权重就是固定的。你调用的 API 会得到稳定一致的输出。
Q3: 如何快速开始测试 MiniMax-M2.7?
推荐使用支持多模型的 API 聚合平台进行测试:
- 访问 API易 apiyi.com 注册账号
- 获取 API Key 和免费额度
- 使用本文的代码示例快速验证
- 切换 model 参数即可在标准版和 highspeed 版之间切换
总结
MiniMax-M2.7 API 调用的核心要点:
- 极致性价比: 10B 激活参数达到 Tier-1 性能,价格仅为 Opus 的 1/50,是大规模部署的首选
- 编程能力突出: SWE-bench Verified 78% 大幅领先竞品,软件工程任务表现卓越
- highspeed 版本: 100 tps 输出速度适合实时交互和 Agent 循环场景,智能水平与标准版完全一致
对于追求性价比的开发者和企业用户,MiniMax-M2.7 是当前市场上最值得关注的旗舰模型之一。
推荐通过 API易 apiyi.com 快速验证效果,平台提供免费额度和多模型统一接口,支持 MiniMax-M2.7 标准版和 highspeed 版的一键切换。
📚 参考资料
-
MiniMax M2.7 官方发布: 模型架构和自进化技术详情
- 链接:
minimax.io/news/minimax-m27-en - 说明: 官方技术博客,包含基准测试和架构细节
- 链接:
-
MiniMax M2.7 模型页面: 技术规格和 API 文档
- 链接:
minimax.io/models/text/m27 - 说明: 模型参数、定价和接入方式
- 链接:
-
Artificial Analysis 评测: 第三方独立性能评测
- 链接:
artificialanalysis.ai/models/minimax-m2-7 - 说明: 独立的速度和智能指数评测数据
- 链接:
-
API易平台文档: 快速接入 MiniMax-M2.7
- 链接:
docs.apiyi.com - 说明: API Key 获取、模型列表和调用示例
- 链接:
作者: APIYI 技术团队
技术交流: 欢迎在评论区讨论,更多资料可访问 API易 docs.apiyi.com 文档中心