作者注:实测数据揭示 Gemini 和 DeepSeek 翻译同一篇文章时 Token 消耗差 2-2.5 倍的根本原因——Tokenizer 编码效率差异,并提供多语言场景下的成本优化建议
同一篇中文文章,用 Gemini 和 DeepSeek 分别翻译成英文、日语、法语,翻译质量和完整性完全一致——但 API 返回的 Completion Token 竟然差了 2-2.5 倍。这是 API 计费 Bug 吗?还是有更深层的技术原因?
核心价值: 通过真实测试数据,帮你理解 Tokenizer 差异如何影响 API 成本,并掌握在多语言翻译场景下选择最具性价比模型的方法。
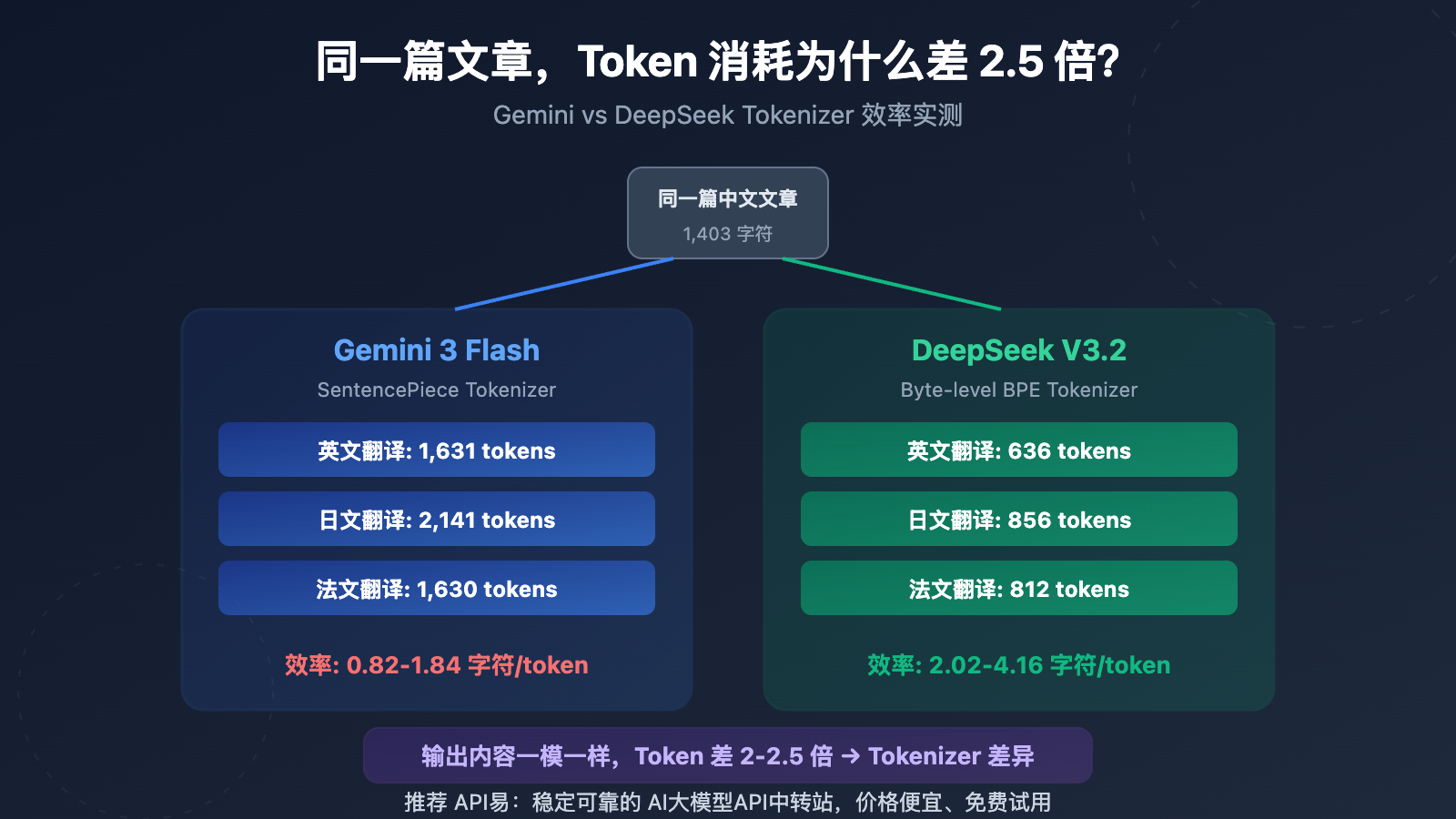
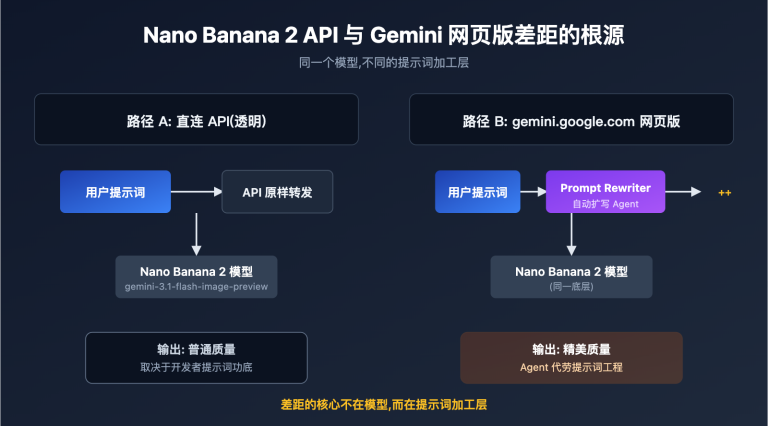
Gemini vs DeepSeek Tokenizer 效率核心数据
| 对比维度 | Gemini 3 Flash | DeepSeek V3.2 | 差异倍数 |
|---|---|---|---|
| 英文翻译 Completion Token | 1,631 | 636 | Gemini 多 2.56x |
| 日文翻译 Completion Token | 2,141 | 856 | Gemini 多 2.50x |
| 法文翻译 Completion Token | 1,630 | 812 | Gemini 多 2.01x |
| 编码效率(字符/Token) | 0.82-1.84 | 2.02-4.16 | DeepSeek 高 2-2.8x |
| 翻译输出行数 | 64 行 | 64 行 | 完全一致 |
Gemini vs DeepSeek Tokenizer 差异的根本原因
我们使用同一段 1,403 字符的中文测试文本(包含 Markdown 表格、代码块、SVG 占位符、CTA),分别调用 gemini-3-flash-preview 和 deepseek-v3.2 翻译到英文、日语、法语 3 种语言,然后对比 API 返回的 Token 统计和实际输出内容。
结果非常明确:输出字符数几乎完全相同(差异不到 1%),但 Token 数差 2-2.5 倍。这证明问题出在 Tokenizer(分词器),而非模型的输出策略。
Gemini vs DeepSeek Tokenizer 的技术原理
Tokenizer 是什么? 简单来说,Tokenizer 就是将文本切分成模型能理解的最小单元(Token)的工具。不同模型使用不同的 Tokenizer,就像不同的压缩软件——同一个文件,ZIP 和 RAR 压缩后大小不同,但解压后内容完全一致。
Gemini 的 SentencePiece Tokenizer:使用 Unigram 语言模型,词表大小约 256,000 个 Token。对 CJK(中日韩)字符倾向于拆分为更小的子词单元。实测中,日文输出的编码效率仅 0.82 字符/Token,意味着平均每个日文字符需要 1.2 个 Token 来表示。
DeepSeek 的 Byte-level BPE Tokenizer:词表大小约 128,000 个 Token,但专门针对多语言场景进行了优化。引入了组合标点和换行符 Token,提升了 CJK 文本的压缩效率。日文输出达到 2.02 字符/Token,效率是 Gemini 的 2.46 倍。
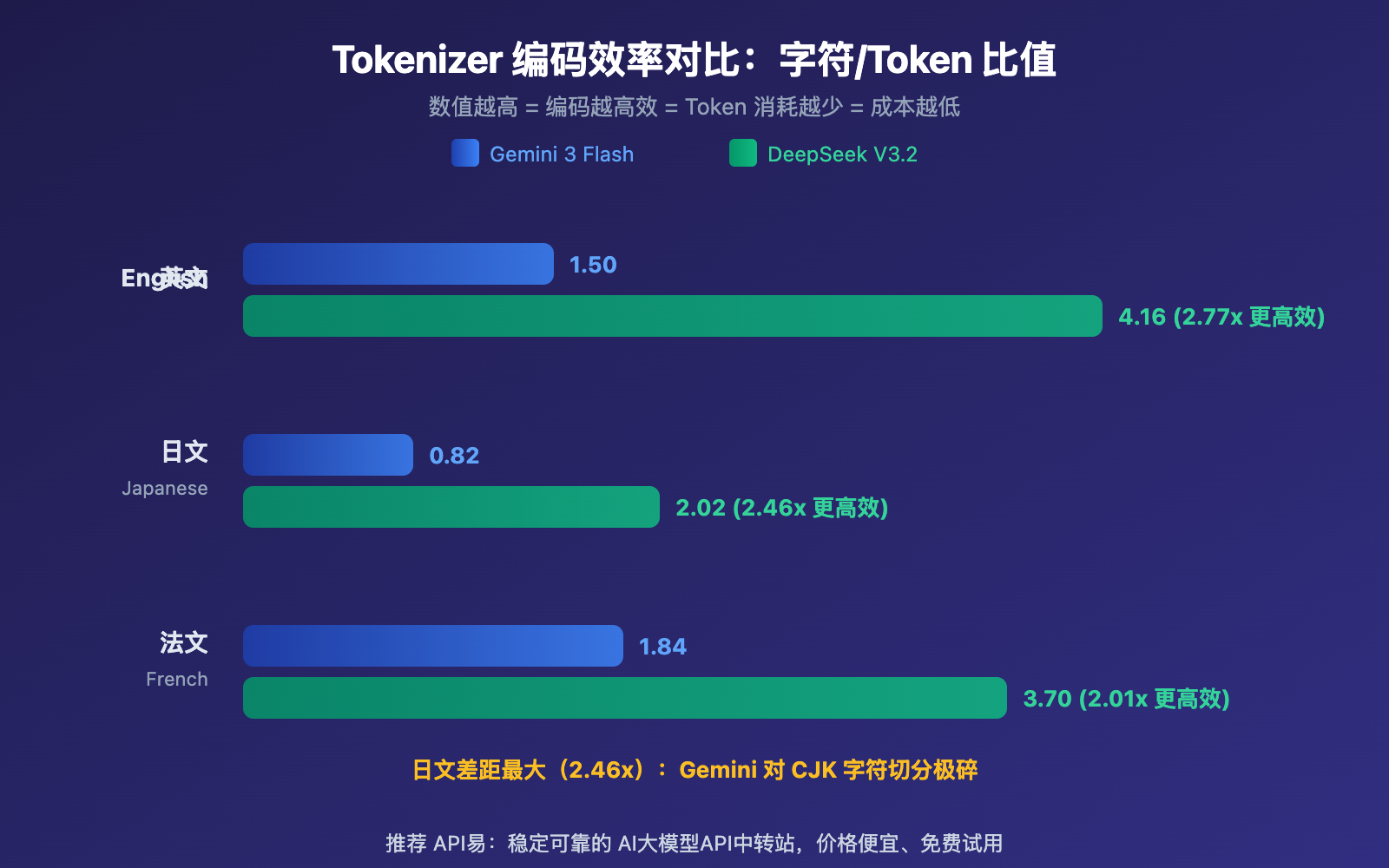
Gemini vs DeepSeek Tokenizer 成本影响分析
理解了 Tokenizer 效率差异后,关键问题是:Token 数多就意味着花钱更多吗? 不一定。最终成本取决于 Token 数量 × 单价。
Gemini vs DeepSeek 翻译成本实测
以翻译一篇典型的技术博客文章(约 30,000 Prompt Token)到 11 种语言为例:
| 成本维度 | Gemini 3 Flash | DeepSeek V3.2 |
|---|---|---|
| 预估单语言 Completion Token | ~80,000 | ~30,000 |
| 11 种语言总 Completion Token | ~880,000 | ~330,000 |
| Output 单价(每百万 Token) | $3.00 | $0.42 |
| 11 语言 Output 总费用 | $2.64 | $0.14 |
| Input 单价(每百万 Token) | $0.50 | $0.28 |
| 11 次 Input 总费用 | $0.17 | $0.09 |
| 单篇文章翻译总成本 | $2.81 | $0.23 |
从实测成本对比来看,DeepSeek 在多语言翻译场景下的费用优势非常明显——同样的翻译任务,DeepSeek 的成本仅为 Gemini 的约 1/12。这个差距由两个因素叠加造成:Tokenizer 效率(2-2.5x)× Token 单价差异(5-7x)。
Gemini vs DeepSeek 翻译速度与质量
但成本不是唯一的考量因素:
| 指标 | Gemini 3 Flash | DeepSeek V3.2 |
|---|---|---|
| 推理速度 | 145-189 tokens/s | 12-26 tokens/s |
| 速度倍数 | 6-10x 更快 | 基准 |
| 翻译质量 | 优秀 | 优秀 |
| 翻译完整性 | 100%(64 行) | 100%(64 行) |
| Markdown 格式保持 | 良好 | 良好 |
Gemini 的推理速度是 DeepSeek 的 6-10 倍。如果你需要快速批量翻译、时间成本高于 Token 成本,Gemini 仍然是更好的选择。
🎯 选择建议: 如果翻译量大且对时间不敏感,DeepSeek 的成本优势显著。如果需要快速交付,Gemini 的速度优势明显。通过 API易 apiyi.com 可以同时接入两个模型,用统一接口灵活切换,找到你场景下的最优平衡点。
Tokenizer 效率差异对不同语言的影响
Tokenizer 对不同语言的影响程度差异很大。CJK(中日韩)语言受影响最严重,拉丁语系相对较轻。
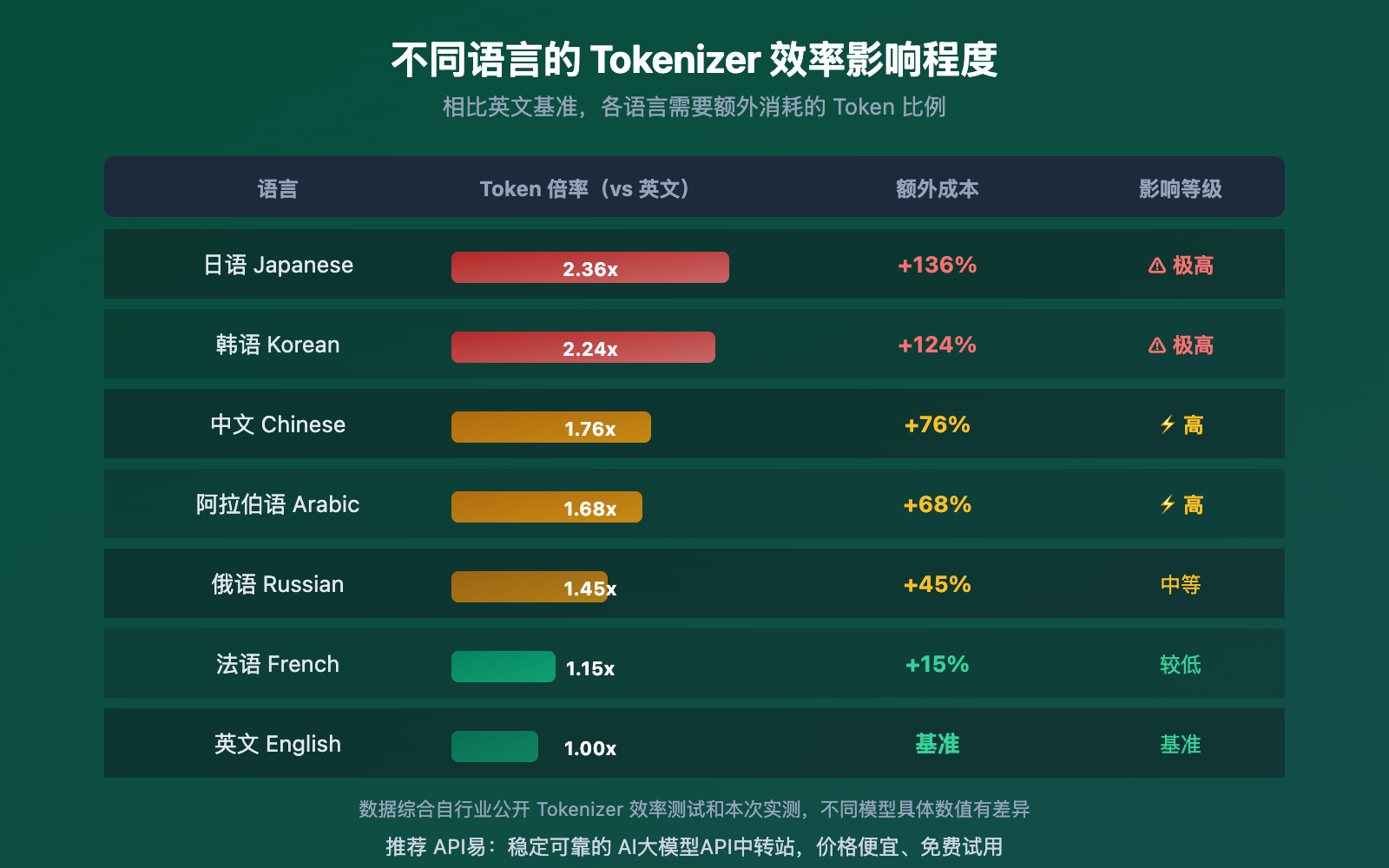
从数据中可以明确看到:
- 日语受影响最大:在 Gemini 上日语编码效率仅 0.82 字符/Token,这解释了为什么翻译含大量中日文的文章时 Token 消耗会显著增加
- 法语差异最小:拉丁语系语言的 Tokenizer 效率差距相对较小(仅 2.01x),因为大多数 Tokenizer 的训练语料以英文为主,拉丁语系受益
- 中文处于中间:约 1.76 倍于英文基准,但使用 DeepSeek 等中文优化模型时差距会缩小
🎯 多语言翻译建议: 如果你的翻译任务涉及日语、韩语等 CJK 语言,选择 Tokenizer 效率更高的模型(如 DeepSeek、Qwen)可以显著降低成本。通过 API易 apiyi.com 的统一接口,你可以方便地在不同模型间切换测试。
Gemini vs DeepSeek Tokenizer 场景选择指南
| 使用场景 | 推荐模型 | 核心原因 |
|---|---|---|
| 大批量多语言翻译 | DeepSeek V3.2 | Token 效率高 + 单价低,成本仅 1/12 |
| 紧急翻译交付 | Gemini 3 Flash | 速度快 6-10 倍,适合时间紧迫场景 |
| CJK 语言密集翻译 | DeepSeek V3.2 | CJK Tokenizer 效率优势达 2.5x |
| 拉丁语系翻译 | 差异较小 | 两者效率差距仅 2x,按单价选择即可 |
| 实时对话场景 | Gemini 3 Flash | 低延迟,用户体验更好 |
| 成本敏感批处理 | DeepSeek V3.2 | 综合成本最低 |
🎯 实用建议: 实际项目中往往需要兼顾成本和速度。我们建议通过 API易 apiyi.com 同时接入 Gemini 和 DeepSeek,根据任务紧急程度动态切换模型。平台支持统一 Key 调用所有主流模型。
常见问题
Q1: Gemini Token 消耗多是不是 API 计费 Bug?
不是 Bug。这是 Tokenizer 编码效率差异导致的正常现象。就像同一个文件用 ZIP 和 RAR 压缩后大小不同一样,不同模型的 Tokenizer 对同一段文本生成的 Token 数量不同,但处理的内容完全一致。我们的实测验证了输出字符数差异不到 1%。
Q2: Token 数多是否意味着翻译质量更好?
不是。Token 数量只反映 Tokenizer 的编码方式,与翻译质量无关。实测中两个模型的翻译质量和完整性均表现优秀,输出行数完全一致(64 行)。选择模型时应该关注翻译质量、速度和综合成本,而非单纯的 Token 数。
Q3: 如何在项目中优化多语言翻译的 Token 成本?
推荐以下策略:
- 对 CJK 语言(中、日、韩)优先使用 DeepSeek 等 Tokenizer 效率高的模型
- 对拉丁语系可以灵活选择,差距较小
- 通过 API易 apiyi.com 接入多个模型,用统一 API 实现按语言自动路由
- 设置 Token 消耗监控时,针对不同模型设置不同的阈值,避免误报
总结
Gemini vs DeepSeek Tokenizer 效率对比的核心结论:
- Token 差异源于 Tokenizer,不是 Bug: 同一段文本,DeepSeek 的 Tokenizer 编码效率比 Gemini 高 2-2.8 倍,CJK 语言差距最显著
- 成本差异叠加放大: Tokenizer 效率差异(2-2.5x)× Token 单价差异(5-7x)= 实际成本差距可达 12 倍
- 速度 vs 成本的权衡: Gemini 速度快 6-10 倍但 Token 成本高,DeepSeek 成本低但速度慢——根据场景灵活选择
理解 Tokenizer 效率差异,是优化 AI API 使用成本的关键一步。在多语言翻译等 Token 密集型场景下,选对模型可以节省大量费用。
推荐通过 API易 apiyi.com 统一接入多个模型,用一个 Key 灵活切换,找到每个场景下的最佳性价比方案。
📚 参考资料
-
Tokenizer 性能基准测试: 全面对比主流模型 Tokenizer 效率
- 链接:
llm-calculator.com/blog/tokenization-performance-benchmark - 说明: 包含 GPT-4o、DeepSeek、Qwen 等模型的 Tokenizer 效率数据
- 链接:
-
CJK 文本与 AI 大模型最佳实践: CJK 字符 Tokenizer 处理机制
- 链接:
tonybaloney.github.io/posts/cjk-chinese-japanese-korean-llm-ai-best-practices.html - 说明: 深入分析 CJK 语言在不同 Tokenizer 下的 Token 消耗差异
- 链接:
-
Gemini Tokenizer 解析: Google Gemini 的 SentencePiece 分词器原理
- 链接:
dejan.ai/blog/gemini-toknizer - 说明: 详细分析 Gemini 256K 词表的编码机制和效率特点
- 链接:
-
DeepSeek V3 技术报告: Byte-level BPE Tokenizer 的多语言优化
- 链接:
arxiv.org/html/2412.19437v1 - 说明: DeepSeek 128K 词表的设计理念和多语言压缩效率
- 链接:
作者: APIYI 技术团队
技术交流: 欢迎在评论区讨论,更多资料可访问 API易 docs.apiyi.com 文档中心