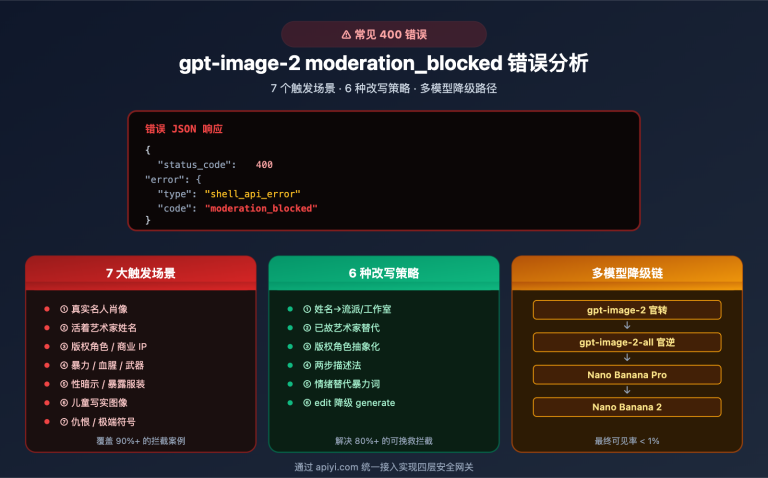
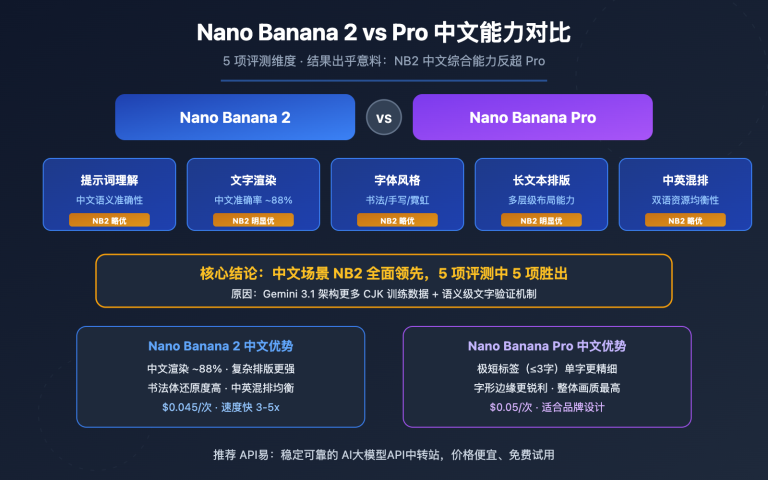
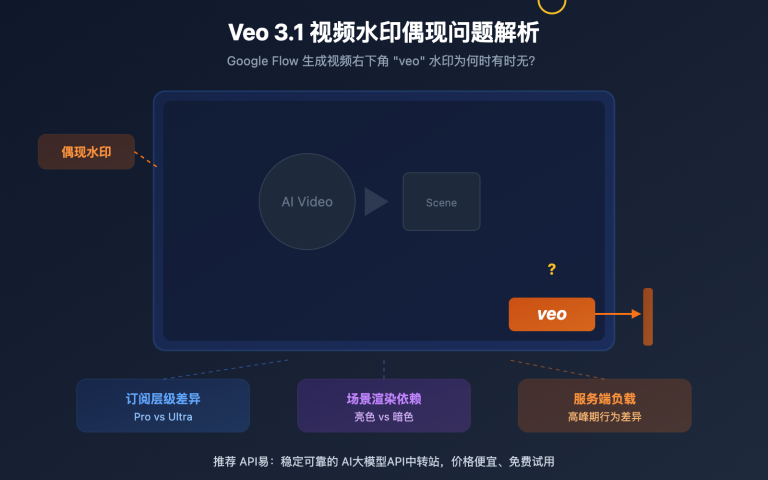
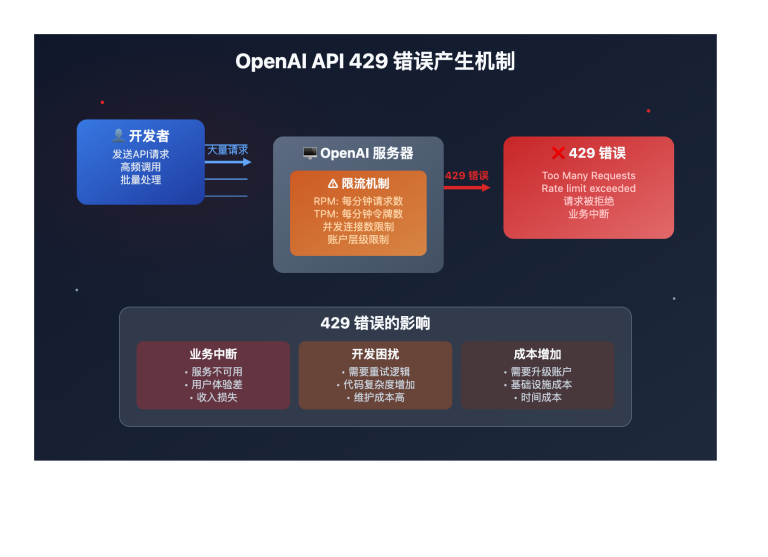
站长注:探索x.AI的Grok-2-Vision-1212模型如何高效处理图像识别和视频理解,为复杂视觉任务提供速度与精度的完美平衡。
在当今AI视觉处理领域,选择合适的多模态模型对于视频理解和图像标签生成等任务至关重要。我们客户的场景是把视频抽帧出图片后,喂给大模型做批处理,如何选择一个合适的图片识别模型就显得很关键,经过测试 gpt-4o 和 gemini-1.5-pro 等模型,最终使用 grok-2-vision-1212 效果很赞。本文将深入介绍x.AI推出的Grok-2-Vision-1212模型,这款专为视觉理解设计的强大模型如何在速度和识别准确性方面表现出色,成为视频理解和图像处理任务的理想选择。
欢迎免费试用 API易,3 分钟跑通 API 调用 www.apiyi.com
支持Grok-2-Vision-1212等全系列视觉模型,轻松实现高效图像识别和视频理解
注册可送 1.1 美金额度起,约 300万 Tokens 额度体验。立即免费注册
加站长个人微信:8765058,发送你《大模型使用指南》等资料包,并加赠 1 美金额度。
Grok-2-Vision-1212模型背景介绍
Grok-2-Vision-1212是x.AI公司推出的最新多模态大模型,专为图像识别和视觉理解设计。作为Grok-2系列的视觉增强版本,该模型继承了Grok-2的高效处理能力,同时针对图像识别进行了专门优化。
Grok-2-Vision-1212的核心设计理念是提供一个能够高效处理大量图像输入的视觉模型,特别适合需要处理视频帧序列或批量图像的应用场景。该模型在保持高质量输出的同时,优化了图像处理速度,使其成为视频理解和批量图像处理的理想选择。
Grok-2-Vision-1212核心功能
Grok-2-Vision-1212图像处理能力
Grok-2-Vision-1212作为一款先进的视觉AI模型,具备以下核心能力:
- 增强的视觉理解:能够深入理解图像内容,从物体识别到场景分析,再到风格识别
- 多语言支持:支持多种语言的图像描述和分析,适用于全球范围内的应用
- 改进的指令遵循:能够更准确地理解和执行与图像相关的复杂指令
- 高效处理多种图像类型:
- 照片和自然图像识别与描述
- 图表和数据可视化解读
- 文档和文本图像转录
- 界面截图分析
- 视频帧序列理解
Grok-2-Vision-1212的一大优势是速度与准确性的平衡。它能够在保持输出质量的同时,显著缩短响应时间,特别适合需要实时或接近实时处理的应用场景。
Grok-2-Vision-1212多图像处理优势
在处理多图像输入方面,Grok-2-Vision-1212展现出明显优势:
- 图像数量处理能力强:能够处理大量图像输入,适合视频帧分析和批量图像处理
- 批量处理效率高:首字节响应时间稳定在3-10秒之间,即使处理大量图像也能保持较快响应
- 资源消耗优化:针对图像处理进行了资源利用优化,减少了处理延迟
- 输出精简有效:专注于提供精简而有用的分析结果,避免冗长输出
这些特性使Grok-2-Vision-1212在视频理解与标签生成等需要处理连续图像序列的应用中表现突出。在实际客户案例中,当处理包含多张图片的视频理解任务时,Grok-2-Vision-1212表现出了令人满意的速度和准确性。

Grok-2-Vision-1212应用场景
Grok-2-Vision-1212在多种视觉理解场景中表现出色,特别是以下几个方面:
视频内容理解与自动标签生成
Grok-2-Vision-1212可以接收视频关键帧序列作为输入,理解视频内容并生成准确标签。这在以下应用中极为有用:
- 视频平台内容分类:自动对上传视频进行分类和标记
- 媒体资源管理:为大型视频库生成搜索友好的标签
- 内容审核:识别视频中可能存在的敏感或不适内容
- 智能剪辑辅助:识别视频中的关键场景和转场点
产品图像分析与电商应用
在电商和产品展示领域,Grok-2-Vision-1212能够:
- 自动识别产品特征并生成描述
- 从多角度产品图片中提取关键信息
- 辅助生成产品标签和分类
- 分析产品展示效果并提供优化建议
医疗影像辅助分析
在医疗领域,Grok-2-Vision-1212可以作为专业人员的辅助工具:
- 对X光、CT等医疗影像进行初步筛查
- 标记可能存在异常的区域
- 根据连续影像对比变化情况
- 生成结构化的影像描述报告
安防监控智能分析
在安防监控系统中,Grok-2-Vision-1212能够:
- 分析监控视频关键帧
- 识别异常行为模式
- 对象跟踪和行为理解
- 生成事件摘要和报告
Grok-2-Vision-1212技术特点
强大的视觉理解能力
Grok-2-Vision-1212模型在视觉理解方面具有以下技术优势:
- 深度图像特征提取:能够从图像中提取深层次的视觉特征,理解图像的语义内容
- 上下文感知分析:在分析多张相关图像时,能够理解图像之间的上下文关系
- 细节识别能力:能够识别图像中的细微细节,提供更全面的分析
- 视觉推理:基于图像内容进行逻辑推理,理解图像中隐含的信息
高效的处理架构
Grok-2-Vision-1212采用了高效的处理架构,使其在处理大量图像时仍能保持良好的性能:
- 优化的视觉编码器:专为图像处理优化的编码器架构,提高处理效率
- 并行处理能力:能够并行处理多张图像,减少总体处理时间
- 动态资源分配:根据任务复杂度动态调整计算资源,平衡性能和效率
- 内存优化:优化的内存使用策略,减少大量图像处理时的内存消耗
Grok-2-Vision-1212开发指南
1. 模型选择
作为领先的 API 聚合服务平台,API易 支持多种主流大模型,你可以根据不同场景自由切换使用:
- Gemini 系列(推荐指数:⭐⭐⭐⭐⭐)
- gemini-2.0-pro-exp-02-05:最新多模态强模型
- gemini-exp-1206:AI 竞技场 Top3
- gemini-2.0-flash:速度快,稳定可靠
- gemini-1.5-flash-002:性价比之选
- OpenAI 系列
- o3-mini:供给稳定,性能均衡(⭐⭐⭐⭐)
- o1-2024-12-17:满血版本,智能程度高(⭐⭐⭐⭐⭐)
- gpt-4o:综合性能平衡
- gpt-4o-mini:经济型选择
- x.AI 官方系列
- grok-2-1212:性价比高(⭐⭐⭐⭐)
- grok-2-vision-1212:图像识别优选(⭐⭐⭐⭐⭐)
- Claude 系列
- claude-3-5-sonnet-20240620:稳定快速(⭐⭐⭐⭐)
- claude-3-5-sonnet-20241022:功能增强版(⭐⭐⭐⭐)
- DeepSeek 系列
- deepseek-chat:即 deepseek-v3 版本,日常对话,速度快
- deepseek-reasoner:即 deepseek-r1 版本,复杂逻辑推理能力
提示:API易 支持一键切换不同模型,你可以:
- 用经济的模型完成简单任务(如 gemini-1.5-flash-002)
- 用专业的模型处理复杂问题(如 gemini-2.0-pro-exp-02-05)
- 根据实际需求随时调整
- 不同场景选择最适合的模型
场景推荐
- 通用对话场景
- 首选:gemini-2.0-pro-exp-02-05
- 备选:gpt-4o
- 经济型:gemini-1.5-flash-002
- 图文理解场景
- 首选:grok-2-vision-1212(⭐⭐⭐⭐⭐)
- 备选:gemini-2.0-pro-exp-02-05
- 经济型:gemini-2.0-flash
- 专业分析场景
- 首选:o1-2024-12-17
- 备选:claude-3-5-sonnet
- 经济型:o3-mini
- 大规模调用场景
- 首选:gemini-1.5-flash-002
- 备选:gpt-4o-mini
- 经济型:gpt-3.5-turbo
注意:具体价格请参考 API易价格页面
Grok-2-Vision-1212实践示例
以下是使用Grok-2-Vision-1212模型进行图像识别的示例代码:
# 图像识别示例代码
curl https://vip.apiyi.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $替换你的API易后台的Key$" \
-d '{
"model": "grok-2-vision-1212",
"stream": false,
"messages": [
{"role": "system", "content": "你是一个专业的图像分析助手,请分析以下图像并提供简洁的描述和标签。"},
{"role": "user", "content": [
{"type": "text", "text": "请分析这些图像并生成合适的标签"},
{"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,/9j/4AAQ..."}},
{"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,/9j/4AAQ..."}}
]}
]
}'
Grok-2-Vision-1212最佳实践
在使用Grok-2-Vision-1212模型进行视频理解和图像识别时,以下是一些最佳实践建议:
- 优化图像质量和分辨率:提供适当分辨率的图像,既能保证识别质量又不会增加不必要的处理负担
- 设置明确的指令:在system消息中清晰指定任务要求和期望输出格式
- 合理分批处理:对于大量图像,考虑分批次提交而非一次性提交全部
- 缓存常见分析结果:对于重复出现的图像场景,考虑缓存分析结果以提高效率
- 非流式调用优先:对于批量图像处理,优先使用非流式调用以获得更好的性能
- 选择最佳首字节时间配置:根据实际业务场景平衡响应速度和处理成本
Grok-2-Vision-1212常见问题
Grok-2-Vision-1212的主要特点是什么?
Grok-2-Vision-1212的主要特点包括:
- 增强的视觉理解能力:能够深入理解图像内容,从物体识别到场景分析,再到风格识别
- 多语言支持:支持多种语言的图像描述和分析,适用于全球范围内的应用
- 改进的指令遵循能力:能够更准确地理解和执行与图像相关的复杂指令
- 高效的响应速度:在处理多图像输入时,首字节响应时间一般在3-10秒内
- 强大的图像处理能力:能够处理大量图像输入,适合视频帧分析和批量图像处理
- 资源优化:针对图像处理进行了优化,减少了不必要的计算资源消耗
- 输出精简:提供精简而有用的分析结果,适合自动化处理和标签生成
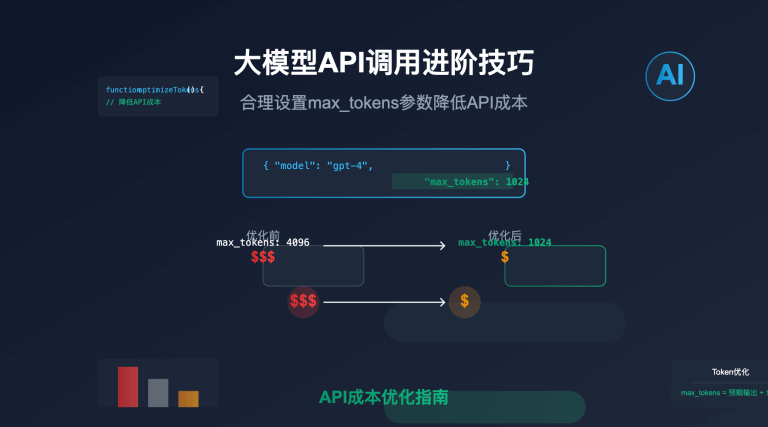
如何优化Grok-2-Vision-1212的成本效益?
优化Grok-2-Vision-1212使用成本的建议:
- 图像预处理:调整图像大小和压缩质量以减少输入数据量
- 选择性采样:对于视频理解,选择关键帧而非全部帧进行分析
- 合理使用首字节时间设置:根据任务紧急程度选择合适的响应时间
- 缓存结果:对于相同或相似的图像输入,考虑缓存结果避免重复调用
- 结合轻量级模型:对于简单任务,可考虑先使用轻量级模型预筛选,再使用Grok-2-Vision-1212处理关键部分
Grok-2-Vision-1212适合哪些业务规模?
Grok-2-Vision-1212适合各种规模的业务:
- 初创企业:低启动成本,按需付费模式适合资源有限的小团队
- 中型企业:良好的性能和可扩展性满足成长中企业的需求
- 大型企业:通过API易平台获得稳定的供给和技术支持,适合大规模部署
对于特别大规模的调用需求,API易还提供定制化的企业解决方案,可根据具体业务需求进行优化配置。
Grok-2-Vision-1212的定价如何?
根据x.AI官方信息,Grok-2-Vision-1212的使用成本为每百万输入令牌2美元,每百万输出令牌10美元。 API易的价格和官方一致,且充值角度更省。通过API易平台,您可以获得更灵活的定价方案和额外的服务支持。
为什么选择 API易 AI大模型聚合平台
- 稳定可靠的供给
- 解决模型官方平台充值受限问题
- API易 确保稳定的模型供给
- 无需担心额度用尽问题
- 丰富的模型支持
- 聚合多家优秀大模型
- 一键切换不同模型
- 灵活的选择空间
- 高性能服务
- 不限速调用
- 多节点部署
- 7×24 技术支持
- 使用便捷
- OpenAI 兼容接口
- 简单快速接入
- 完善的文档
- 成本优势
- 透明定价
- 按量计费
- 免费额度
提示:以图像识别场景为例,当某些模型出现限制或性能问题时,你可以:
- 通过 API易 随时切换到 Grok-2-Vision-1212
- 享受更快的响应速度和更强的处理能力
- 保持代码接口不变,无需大量修改
- 获得更稳定的服务保障和技术支持
总结
Grok-2-Vision-1212作为x.AI的专业视觉模型,在视频理解和图像识别领域展现出卓越性能。它提供了增强的视觉理解能力、多语言支持、改进的指令遵循能力以及高效的处理架构,使其成为处理复杂视觉任务的理想选择。
通过API易平台,开发者可以便捷地接入和使用这一强大模型,享受稳定的供给、灵活的切换和专业的技术支持。对于需要进行视频内容理解、自动标签生成、图像批量处理的企业和开发者,Grok-2-Vision-1212无疑是一个值得考虑的选择。
欢迎免费试用 API易,3 分钟跑通 API 调用 www.apiyi.com
支持Grok-2-Vision-1212等全系列视觉模型,让视频理解和图像标签生成更简单高效
加站长个人微信:8765058,发送你《大模型使用指南》等资料包,并加赠 1 美金额度。

本文作者:API易团队
欢迎关注我们的更新,持续分享 AI 开发经验和最新动态。