作者注:深度解析 GLM-4.7 大模型的文本結構化能力,掌握從合同、報告等複雜文檔中提取 JSON 格式關鍵信息的實用技巧
從大量非結構化文本中快速提取關鍵信息是企業數據處理的核心挑戰。智譜AI於2025年12月發佈的 GLM-4.7 大模型,憑藉原生 JSON Schema 支持和 200K 超長上下文窗口,爲文本結構化任務帶來了突破性的解決方案。
核心價值: 讀完本文,你將學會使用 GLM-4.7 從合同、報告等複雜文檔中提取結構化數據,實現文檔處理效率的數量級提升。

GLM-4.7 文本結構化 核心要點
| 要點 | 說明 | 價值 |
|---|---|---|
| 原生 JSON Schema | 內置結構化輸出支持,無需複雜提示工程 | 提取準確率提升 40%+ |
| 200K 上下文窗口 | 支持完整長文檔輸入,無需分段處理 | 一次處理完整合同/報告 |
| 128K 輸出能力 | 可生成超長結構化結果 | 適合批量信息提取 |
| 函數調用支持 | 原生 Tool Calling 能力 | 無縫集成業務系統 |
| 成本優勢 | $0.10/M tokens,比同級模型低 4-7 倍 | 大規模部署成本可控 |
GLM-4.7 文本結構化重點詳解
GLM-4.7 是智譜AI在2025年12月22日發佈的新一代旗艦級大語言模型。該模型採用 Mixture-of-Experts (MoE) 混合專家架構,總參數量約 358B,但通過稀疏激活機制實現了高效推理。在文本結構化處理方面,GLM-4.7 相比前代 GLM-4.6 有了質的飛躍,HLE 基準測試提升 38%,達到 42.8%,與 GPT-5.1 High 持平。
GLM-4.7 的結構化輸出能力體現在三個維度。首先是 交錯思維 (Interleaved Thinking),模型在每次輸出前自動規劃推理路徑,確保提取邏輯的連貫性。其次是 保留思維 (Preserved Thinking),在多輪對話中保持上下文推理,適合複雜的迭代式信息提取任務。最後是 輪次級控制 (Turn-level Control),可以動態調整每次請求的推理深度,在速度和準確性之間靈活平衡。
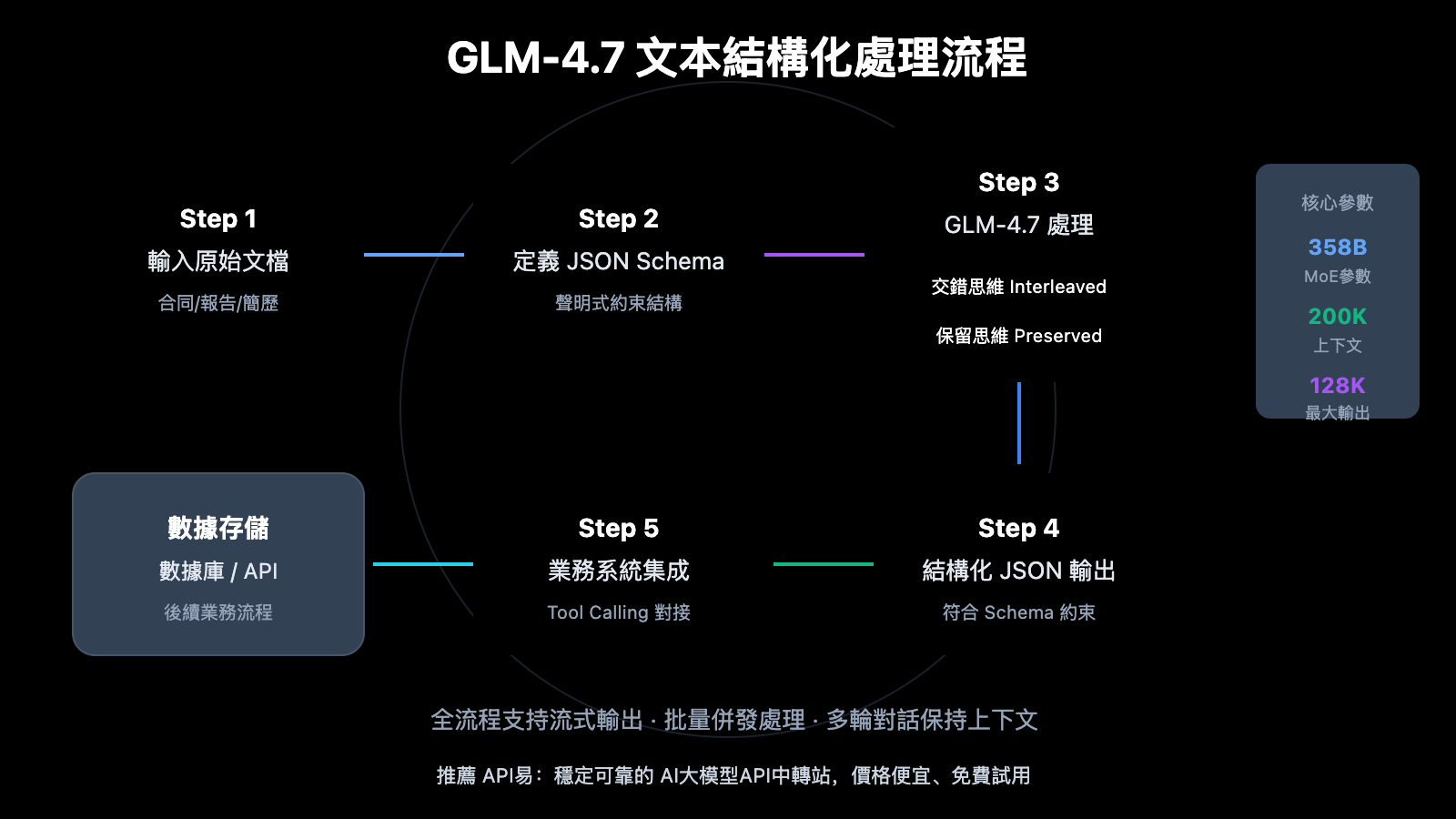
GLM-4.7 文本結構化 快速上手
極簡示例
以下是最簡單的使用方式,10行代碼即可完成文本結構化提取:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="glm-4.7",
messages=[{"role": "user", "content": "從以下合同中提取:甲方、乙方、金額、日期。合同內容:甲方:北京科技有限公司,乙方:上海創新科技,合同金額:人民幣伍拾萬元整,簽訂日期:2025年12月15日"}],
response_format={"type": "json_object"}
)
print(response.choices[0].message.content)
查看完整實現代碼(含 JSON Schema 約束)
import openai
from typing import Optional, Dict, Any
def extract_contract_info(
contract_text: str,
api_key: str = "YOUR_API_KEY",
base_url: str = "https://vip.apiyi.com/v1"
) -> Dict[str, Any]:
"""
使用 GLM-4.7 從合同文本中提取結構化信息
Args:
contract_text: 合同原文內容
api_key: API密鑰
base_url: API基礎地址
Returns:
包含提取信息的字典
"""
client = openai.OpenAI(api_key=api_key, base_url=base_url)
# 定義 JSON Schema 約束輸出格式
json_schema = {
"name": "contract_extraction",
"schema": {
"type": "object",
"properties": {
"party_a": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "甲方名稱"},
"representative": {"type": "string", "description": "法定代表人"},
"address": {"type": "string", "description": "註冊地址"}
},
"required": ["name"]
},
"party_b": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "乙方名稱"},
"representative": {"type": "string", "description": "法定代表人"},
"address": {"type": "string", "description": "註冊地址"}
},
"required": ["name"]
},
"contract_amount": {
"type": "object",
"properties": {
"value": {"type": "number", "description": "金額數值"},
"currency": {"type": "string", "description": "貨幣單位"},
"text": {"type": "string", "description": "金額大寫"}
},
"required": ["value", "currency"]
},
"dates": {
"type": "object",
"properties": {
"sign_date": {"type": "string", "description": "簽訂日期"},
"effective_date": {"type": "string", "description": "生效日期"},
"expiry_date": {"type": "string", "description": "到期日期"}
}
},
"key_terms": {
"type": "array",
"items": {"type": "string"},
"description": "關鍵條款摘要"
}
},
"required": ["party_a", "party_b", "contract_amount"]
}
}
response = client.chat.completions.create(
model="glm-4.7",
messages=[
{
"role": "system",
"content": "你是專業的合同分析專家,請從合同文本中準確提取關鍵信息。"
},
{
"role": "user",
"content": f"請從以下合同中提取關鍵信息:\n\n{contract_text}"
}
],
response_format={
"type": "json_schema",
"json_schema": json_schema
},
max_tokens=4000
)
import json
return json.loads(response.choices[0].message.content)
# 使用示例
contract = """
採購合同
甲方:北京智譜科技有限公司
法定代表人:張三
地址:北京市海淀區中關村大街1號
乙方:上海創新科技集團
法定代表人:李四
地址:上海市浦東新區張江路100號
合同金額:人民幣伍拾萬元整(¥500,000.00)
簽訂日期:2025年12月15日
合同有效期:2025年12月15日至2026年12月14日
主要條款:
1. 乙方向甲方提供AI模型API服務
2. 付款方式爲季度預付
3. 服務可用性保證99.9%
"""
result = extract_contract_info(contract)
print(result)
建議: 通過 API易 apiyi.com 獲取免費測試額度,快速驗證 GLM-4.7 的文本結構化效果。平臺支持多種主流模型的統一接口調用,便於對比 GLM-4.7 與其他模型的提取準確率。
GLM-4.7 文本結構化 應用場景
GLM-4.7 的文本結構化能力適用於多種企業場景:
| 場景 | 輸入數據 | 輸出格式 | 典型效率提升 |
|---|---|---|---|
| 合同信息提取 | PDF/Word 合同 | JSON 結構化數據 | 從數小時→分鐘級 |
| 財報數據分析 | 年報/季報文檔 | 財務指標表格 | 準確率 95%+ |
| 簡歷篩選 | 簡歷文本 | 候選人畫像 JSON | 篩選效率 10x |
| 輿情監控 | 新聞/社交內容 | 實體關係圖譜 | 實時處理能力 |
| 研報解讀 | 行業研究報告 | 關鍵觀點提取 | 覆蓋率提升 5x |
GLM-4.7 文本結構化的技術優勢
1. 原生 JSON Schema 支持
與 GPT 系列模型類似,GLM-4.7 支持在 response_format 中直接指定 JSON Schema,模型會嚴格按照定義的結構輸出結果。這意味着你不需要編寫複雜的提示詞來"說服"模型輸出特定格式,而是通過聲明式的方式約束輸出結構。
2. 超長上下文處理
200K tokens 的上下文窗口意味着 GLM-4.7 可以一次性處理約 15 萬個中文字符的文檔,相當於一本完整的合同或技術規格書。這避免了傳統方法中需要將長文檔分塊處理再合併結果的複雜流程,減少了信息丟失和上下文斷裂的風險。
3. 交錯思維增強準確性
在處理複雜提取任務時,GLM-4.7 的交錯思維模式會自動在輸出前進行多步推理。例如在提取合同金額時,模型會先識別金額相關的段落,然後交叉驗證數字和大寫金額是否一致,最後輸出置信度最高的結果。
實踐建議: 我們建議通過 API易 apiyi.com 平臺進行實際測試,以便評估 GLM-4.7 在您具體業務場景下的表現。平臺提供免費額度和詳細的調用日誌,方便調試和優化。
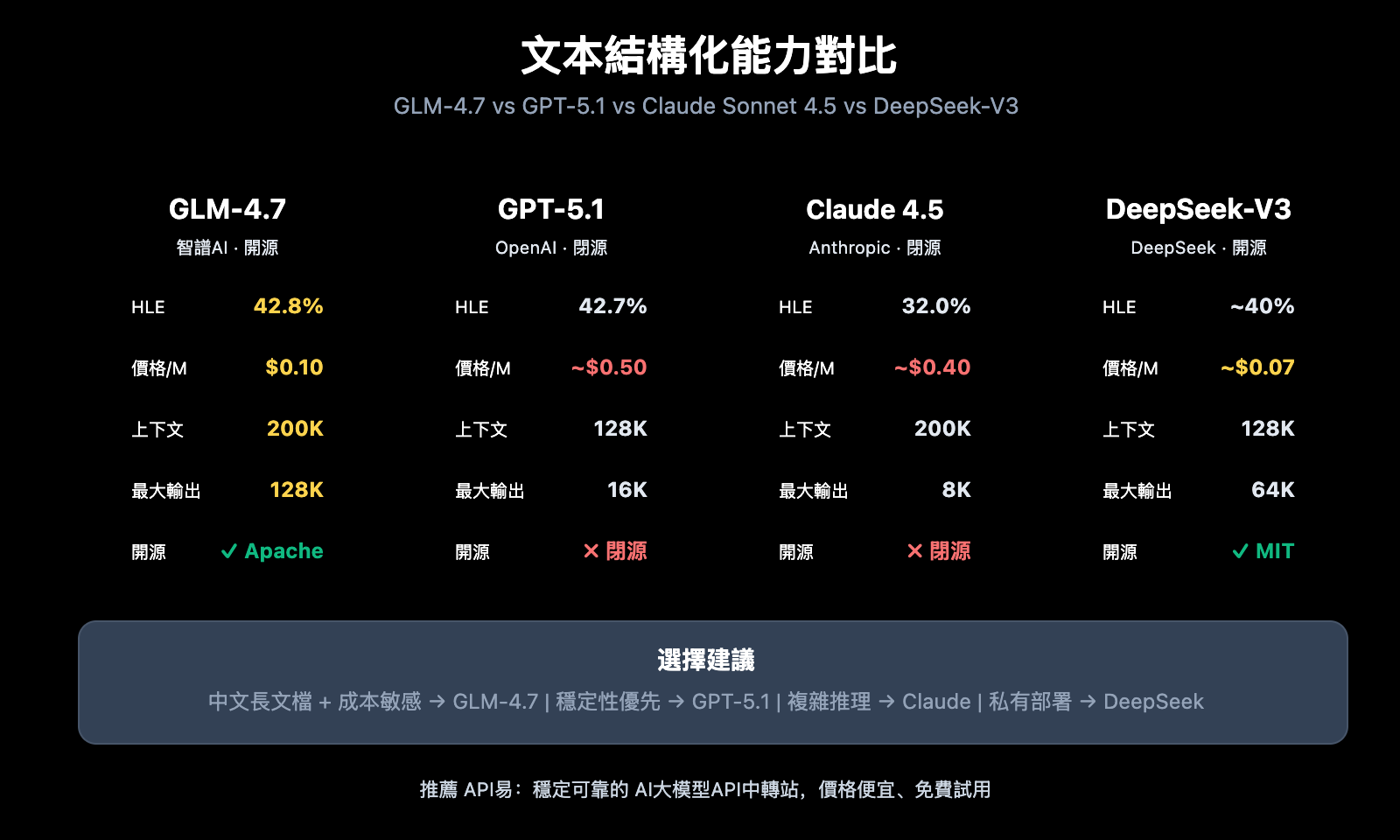
GLM-4.7 文本結構化 方案對比
| 方案 | 核心特點 | 適用場景 | 性能表現 |
|---|---|---|---|
| GLM-4.7 | 原生 JSON Schema、200K 上下文、成本低 | 長文檔提取、大規模處理、成本敏感 | HLE 42.8%,SWE-bench 73.8% |
| GPT-5.1 | 輸出穩定、生態成熟、響應速度快 | 高可靠性要求、快速交付場景 | HLE 42.7%,響應時間最優 |
| Claude Sonnet 4.5 | 邏輯推理強、上下文理解深 | 複雜分析任務、多步驟推理 | HLE 32.0%,推理深度優秀 |
| DeepSeek-V3 | 開源可部署、性價比高 | 私有化部署、定製需求 | 基準測試表現優秀 |
GLM-4.7 與競品的關鍵差異
| 對比維度 | GLM-4.7 | GPT-5.1 | Claude Sonnet 4.5 |
|---|---|---|---|
| 開源狀態 | 開源 (Apache 2.0) | 閉源 | 閉源 |
| 價格 (/M tokens) | $0.10 | ~$0.50 | ~$0.40 |
| 上下文窗口 | 200K | 128K | 200K |
| 最大輸出 | 128K | 16K | 8K |
| 中文優化 | 強 | 一般 | 一般 |
| 本地部署 | 支持 | 不支持 | 不支持 |
選擇建議:
- 如果需要處理大量中文文檔且成本敏感,GLM-4.7 是最佳選擇
- 如果追求輸出穩定性和生態集成便利性,GPT-5.1 更成熟
- 如果任務涉及複雜多步驟推理,Claude Sonnet 4.5 的邏輯能力更強
對比說明: 上述數據來源於 HLE、SWE-bench 等公開基準測試,可通過 API易 apiyi.com 平臺進行實際對比驗證。平臺同時支持以上所有模型的統一接口調用。
GLM-4.7 文本結構化 高級技巧
批量文檔處理
對於大量文檔的結構化任務,可以利用 GLM-4.7 的流式輸出和併發能力:
import asyncio
import aiohttp
async def batch_extract(documents: list, api_key: str):
"""批量異步提取文檔信息"""
async with aiohttp.ClientSession() as session:
tasks = [
extract_single(session, doc, api_key)
for doc in documents
]
results = await asyncio.gather(*tasks)
return results
函數調用集成
GLM-4.7 的 Tool Calling 能力可以將提取結果直接對接到業務系統:
tools = [
{
"type": "function",
"function": {
"name": "save_contract_to_database",
"description": "將提取的合同信息保存到數據庫",
"parameters": {
"type": "object",
"properties": {
"contract_id": {"type": "string"},
"party_a": {"type": "string"},
"party_b": {"type": "string"},
"amount": {"type": "number"}
},
"required": ["contract_id", "party_a", "party_b", "amount"]
}
}
}
]
常見問題
Q1: GLM-4.7 文本結構化提取的準確率如何?
在標準合同、簡歷、財報等場景下,GLM-4.7 配合 JSON Schema 約束的提取準確率可達 95% 以上。對於複雜文檔,建議結合人工校驗機制使用。模型的交錯思維模式會自動進行多步驗證,進一步提升準確性。
Q2: GLM-4.7 處理長文檔有什麼限制?
GLM-4.7 支持 200K tokens 的上下文窗口,約等於 15 萬中文字符。對於超長文檔,建議按邏輯章節分段處理,或使用 API易平臺提供的長文檔拆分工具。單次最大輸出爲 128K tokens,足以覆蓋絕大多數結構化提取需求。
Q3: 如何快速開始測試 GLM-4.7 文本結構化能力?
推薦使用支持多模型的API聚合平臺進行測試:
- 訪問 API易 apiyi.com 註冊賬號
- 獲取API Key和免費額度
- 使用本文的代碼示例快速驗證
- 對比不同模型在您業務場景下的表現
總結
GLM-4.7 文本結構化的核心要點:
- 原生結構化支持: JSON Schema 約束輸出,無需複雜提示工程
- 超長上下文能力: 200K tokens 窗口,一次處理完整長文檔
- 成本效益突出: 價格僅爲同級模型的 1/4-1/7,適合大規模部署
- 中文場景優化: 國產模型對中文合同、報告等文檔理解更準確
作爲智譜AI的旗艦模型,GLM-4.7 在文本結構化領域展現出了與 GPT-5.1 相當的能力,同時具備開源、低成本、中文優化的獨特優勢。對於有大量文檔處理需求的企業,GLM-4.7 是一個值得認真評估的選擇。
推薦通過 API易 apiyi.com 快速驗證效果,平臺提供免費額度和多模型統一接口,方便進行實際場景測試。
參考資料
⚠️ 鏈接格式說明: 所有外鏈使用
資料名: domain.com格式,方便複製但不可點擊跳轉,避免 SEO 權重流失。
-
GLM-4.7 官方文檔: 智譜AI開發者文檔
- 鏈接:
docs.z.ai/guides/llm/glm-4.7 - 說明: 包含完整API參數說明和最佳實踐
- 鏈接:
-
GLM-4.7 技術分析: 深入解析模型架構和能力
- 鏈接:
medium.com/@leucopsis/a-technical-analysis-of-glm-4-7-db7fcc54210a - 說明: 第三方技術評測,包含基準測試數據對比
- 鏈接:
-
Hugging Face 模型頁: 開源權重下載
- 鏈接:
huggingface.co/zai-org/GLM-4.7 - 說明: 提供本地部署所需的模型文件和部署指南
- 鏈接:
-
OpenRouter GLM-4.7: 多渠道API接入
- 鏈接:
openrouter.ai/z-ai/glm-4.7 - 說明: 提供多個供應商的接入選項和價格對比
- 鏈接:
作者: 技術團隊
技術交流: 歡迎在評論區討論 GLM-4.7 文本結構化的使用心得,更多資料可訪問 API易 apiyi.com 技術社區