<!– 背景 –>
<!– 裝飾背景網格 –>
<!– 頂部標題區 –>
<!– 分隔線 –>
<!– 左側:費用下降可視化 –>
<!– $600 大標籤(原始費用)–>
<!– 下降箭頭 –>
<!– $60 小標籤(優化後費用)–>
<!– 節省標註 –>
<!– 中間分隔 –>
<!– 右側:三大省錢手段卡片 –>
<!– 卡片1:緩存計費 –>
<!– 卡片2:接口格式選擇 –>
<!– 卡片3:API 渠道選擇 –>
<!– 右側 QMD 補充信息 –>
<!– 節省路徑列表 –>
<!– 底部信息條 –>
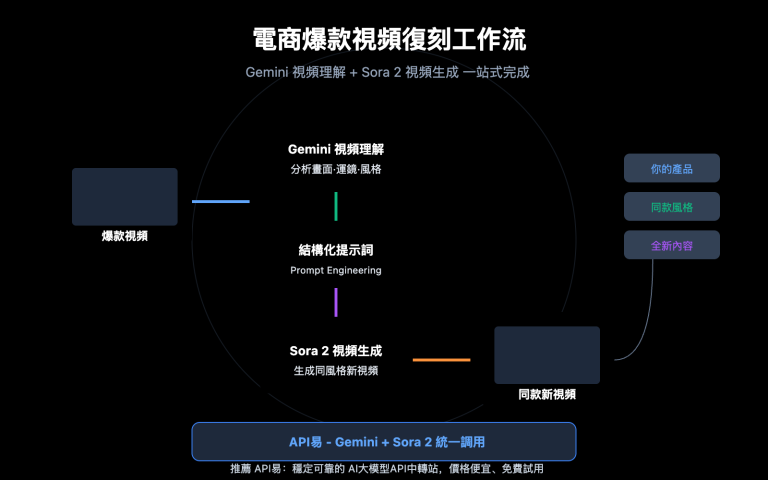
你在用 OpenClaw 處理日常工作流,但每個月看到 API 賬單時卻心頭一緊——$300、$500、甚至 $600 以上?
這不是你的問題,這是 OpenClaw 的架構設計使然。未經優化的 OpenClaw 實例,在執行每一個任務時都會把大量"不必要的內容"發給 AI 模型,白白消耗 Token。
好消息是:幾個關鍵設置可以讓賬單下降 80-90%,而且大多數人並不知道其中最有效的一招——用 Claude 原生格式接口,而不是 OpenAI 兼容模式。
本文深度解析 OpenClaw Token 高消耗的根本原因,手把手教你用對接口、配置緩存、選擇正確的 API 渠道,把每月賬單從 $600 降到 $60。
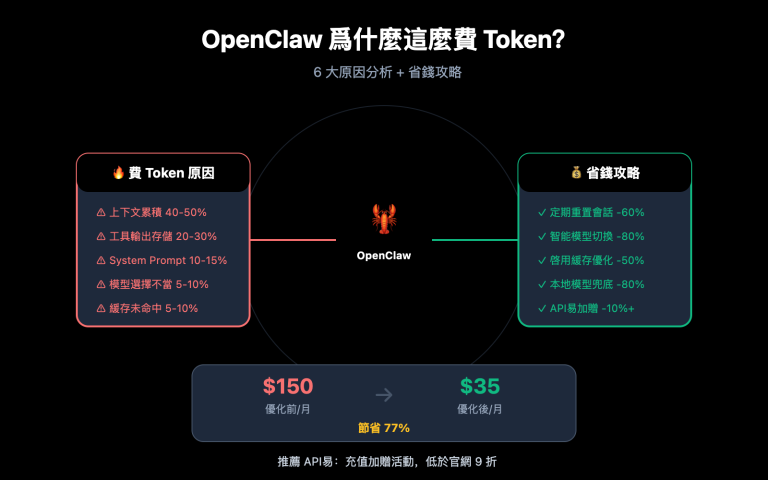
一、OpenClaw 爲什麼這麼費 Token:3 個核心原因
原因 1:每次請求都重發整個對話歷史
這是最容易被忽視、但影響最大的原因。
OpenClaw 在設計上遵循"完整上下文"原則:每次向 AI 模型發請求時,會把從對話開始以來的所有歷史消息一併發送。這樣模型才能"記住"之前做了什麼、說了什麼。
舉個例子:
第 1 輪:用戶發 50 tokens,AI 回覆 200 tokens → 本次發送 250 tokens
第 2 輪:用戶發 50 tokens,AI 回覆 200 tokens → 本次發送 500 tokens(含第1輪)
第 3 輪:用戶發 50 tokens,AI 回覆 200 tokens → 本次發送 750 tokens(含第1+2輪)
...
第 10 輪:本次實際只新增 250 tokens,但發送量已是 2,500 tokens
在一個處理複雜任務的 OpenClaw 工作流中,這種"雪球效應"會讓 Token 消耗以幾何級數增長。上下文歷史通常佔總 Token 消耗的 40-50%。
原因 2:系統提示詞每次都重新發送
OpenClaw 的系統提示詞(System Prompt)定義了 Agent 的身份、能力邊界、可用工具列表、行爲規範等核心內容,通常在 5,000-10,000 tokens 之間。
關鍵問題:這個巨大的 System Prompt 在每一次 API 調用中都會被完整發送一遍。
假設你每天用 OpenClaw 處理 50 次任務,每次 System Prompt 是 8,000 tokens:
每日 System Prompt 消耗 = 50 × 8,000 = 400,000 tokens
每月消耗 ≈ 12,000,000 tokens(僅 System Prompt!)
以 Claude Sonnet 4.6 的輸入價格($3/百萬 tokens)計算,僅 System Prompt 一項每月就要 $36。這還不算對話內容和輸出。
原因 3:推理模式讓 Token 暴增 10-50 倍
當 OpenClaw 遇到複雜任務時,它會啓用"思維鏈"或"推理模式"(Thinking/Reasoning)。這種模式讓 AI 先"想清楚再說",輸出質量更高——但代價是 Token 消耗暴增。
推理 Token 的消耗特點:
- 思維過程產生大量中間 Token(通常不可見,但計費)
- 複雜任務的推理過程可能產生 10,000-50,000 tokens
- 如果不加以控制,幾個複雜任務就能耗光一天的預算
| Token 消耗場景 | 普通模式 | 推理模式 | 倍數差距 |
|---|---|---|---|
| 簡單問答任務 | ~500 tokens | ~2,000 tokens | 4倍 |
| 郵件處理流程 | ~2,000 tokens | ~15,000 tokens | 7.5倍 |
| 代碼分析任務 | ~5,000 tokens | ~80,000 tokens | 16倍 |
| 複雜多步研究 | ~10,000 tokens | ~200,000 tokens | 20倍+ |
🎯 快速診斷: 如果你的 OpenClaw 賬單異常高,先檢查 Token 日誌中的推理模式使用情況。
關閉非必要任務的推理模式,是最立竿見影的節省手段之一。
切換到更合適的模型也能大幅降低成本——通過 API易 apiyi.com 可以快速在不同模型之間切換測試。
三大原因的消耗佔比
<!– 標題 –>
<!– 環形圖(用 SVG path 模擬,圓心 220,240,外徑100,內徑55)–> <!– 總360度:對話歷史45% = 162°,SP重複 28% = 100.8°,推理模式22% = 79.2°,其餘5% = 18° –>
<!– 扇區1:對話歷史 45% (藍色) → 0° to 162° –> <!– 使用簡化矩形條形圖替代環形圖,更穩定 –>
<!– 環形圖用arc描述: cx=220, cy=250 –> <!– Sector 1: 對話歷史 45% → 0° to 162° (從頂部開始) –> <!– startAngle=270°, endAngle=270+162=432°=72° –> <!– 扇形: 大弧 (162>180? No, 162<180, large-arc=0) –>
<!– 座標計算 (cx=220, cy=250, r=110) –> <!– start: (220+110*cos(270°), 250+110*sin(270°)) = (220, 140) –> <!– end45%: (220+110*cos(72°), 250+110*sin(72°)) = (220+33.98, 250+104.65) = (253.98, 354.65) –>
<!– Sector 1: 對話歷史 45% – 藍色 –>
<!– Sector 2: SP重複 28% → 162° to 262.8° (100.8°, large-arc=0) –>
<!– start: 253.98,354.65 → end: (220+110*cos(72+100.8)=cos(172.8°), 250+110*sin(172.8°)) –>
<!– cos(172.8°)=-0.9921, sin(172.8°)=0.1253 → (110.87, 263.78) –>
<!– Sector 3: 推理模式 22% → 262.8° to 342° (79.2°, large-arc=0) –>
<!– start: 110.87,263.78 → end: (220+110*cos(172.8+79.2)=cos(252°), 250+110*sin(252°)) –>
<!– cos(252°)=-0.309, sin(252°)=-0.9511 → (185.99, 145.38) –>
<!– Sector 4: 其他 5% → 342° to 360° (18°, large-arc=0) –>
<!– start: 185.99,145.38 → end: (220,140) → –>
<!– 中心文字 –>
<!– 圖例(右側) –>
<!– 圖例1:對話歷史 –>
<!– 圖例2:System Prompt –>
<!– 圖例3:推理模式 –>
<!– 圖例4:其他 –>
<!– 底部提示 –>
理解三大消耗來源,是制定省錢策略的前提:
| 消耗來源 | 佔總消耗比例 | 是否可優化 | 主要優化手段 |
|---|---|---|---|
| 對話歷史(上下文累積) | 40-50% | ✅ 高度可優化 | 緩存、定期清理、QMD |
| 系統提示詞重複發送 | 25-30% | ✅ 高度可優化 | 緩存計費(節省 90%) |
| 推理/思維鏈模式 | 20-25% | ✅ 按需開啓 | 只對複雜任務啓用 |
| 工具調用和輸出 | 5-15% | ⚡ 有限優化 | 精簡工具描述 |
二、最被忽視的省錢神器:Claude 緩存計費
什麼是 Claude 緩存計費
Claude 的 Prompt Caching(提示詞緩存)是 Anthropic 於 2024 年底推出的原生功能,核心邏輯是:把頻繁重複發送的內容在服務器端緩存起來,後續調用直接讀取緩存,而非重新處理。
緩存讀取的價格:僅爲正常輸入價格的 10%(省 90%)
這意味着:每次發送 8,000 tokens 的 System Prompt,開啓緩存後,重複命中時只需按 800 tokens 計費。對於每天發送數十次請求的 OpenClaw 用戶,這一項優化就能節省 數百美元/月。
緩存計費的完整價格體系
| 緩存類型 | 費用倍數 | 有效時長 | 適用場景 |
|---|---|---|---|
| 正常輸入 Token | 1× 基礎價格 | 不緩存 | 每次重新處理 |
| 緩存寫入(首次) | 1.25× | 5 分鐘 TTL | 建立緩存 |
| 緩存寫入(長效) | 2× | 1 小時 TTL | 頻繁調用場景 |
| 緩存讀取(命中) | 0.1×(省90%) | 有效期內 | 重複請求 |
實際節省計算示例:
場景:OpenClaw 系統提示詞 8,000 tokens
每天調用 50 次,其中 48 次命中緩存
不使用緩存:50 × 8,000 = 400,000 tokens
費用 = 400,000 × $3/1M = $1.20/天 = $36/月
使用緩存: 2 次寫入:2 × 8,000 × 1.25 = 20,000 tokens = $0.06
48 次命中:48 × 8,000 × 0.1 = 38,400 tokens = $0.12
每天費用 ≈ $0.18 → 每月 ≈ $5.40
節省:$36 - $5.40 = $30.60/月(僅 System Prompt 一項)
節省比例:85%
如何在 OpenClaw 中啓用緩存計費
緩存計費的啓用有一個必要前提:必須使用 Anthropic 原生格式接口(/v1/messages),而不是 OpenAI 兼容模式(/v1/chat/completions)。
正確配置方式(Python SDK 示例):
import anthropic
# 必須使用 Anthropic 原生 SDK,不能用 OpenAI SDK
client = anthropic.Anthropic(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1" # API易 支持 Anthropic 原生格式
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
system=[
{
"type": "text",
"text": "你是一個專業的 AI 助理...[8000 tokens 的系統提示詞]",
"cache_control": {"type": "ephemeral"} # ← 關鍵:標記此內容爲緩存候選
}
],
messages=[
{"role": "user", "content": "幫我整理今天的郵件"}
]
)
緩存的技術約束:
- 最多設置 4 個緩存斷點(
cache_control標記) - Sonnet 系列:最小可緩存內容 ≥ 1,024 tokens
- Opus / Haiku 4.5:最小可緩存內容 ≥ 4,096 tokens
- 支持緩存的模型:Claude Opus 4、Sonnet 4.6、Sonnet 4.5、Sonnet 4、Sonnet 3.7、Haiku 4.5、Haiku 3.5、Haiku 3 等
🎯 重要提示: API易 apiyi.com 完整支持 Anthropic 原生格式調用,
包括cache_control參數。在 API易 用原生格式調用 Claude 模型,
可以同時享受緩存計費(省最高 90%)+ API易 八折優惠,雙重疊加效果顯著。
三、關鍵認知:爲什麼 OpenAI 兼容模式無法節省 Token
這是大多數 OpenClaw 用戶最容易踩坑的地方。
兩種接口格式的本質差異
很多第三方 AI 工具和中轉站爲了方便用戶,提供了 OpenAI 兼容模式——即用 OpenAI 的 /v1/chat/completions 接口格式來調用 Claude 等非 OpenAI 模型。
表面上,這樣做讓用戶可以"一套代碼調所有模型"。但有一個致命缺陷:
/v1/chat/completions 接口格式中沒有 cache_control 參數的位置——因爲這是 Anthropic 專有的原生功能。
當你通過 OpenAI 兼容格式調用 Claude 時:
- 你的請求被轉換爲 OpenAI 格式
- 中轉站/代理再把它轉爲 Anthropic 原生格式
- 但
cache_control信息在第一步就已丟失 - Claude 服務器收到的請求沒有緩存標記,每次都按完整 Token 計費
<!– 標題 –>
<!– 中間分隔線 –>
<!– ============ 左側:OpenAI 兼容模式 ============ –>
<!– 流程節點1:用戶代碼 –>
<!– 箭頭 –>
<!– 流程節點2:OpenAI 兼容接口 –>
<!– 箭頭 –>
<!– 流程節點3:中轉轉換 –>
<!– 箭頭 –>
<!– 流程節點4:Claude API – 失敗 –>
<!– 費用說明框 –>
<!– ============ 右側:Anthropic 原生模式 ============ –>
<!– 流程節點1 –>
<!– 箭頭 –>
<!– 流程節點2:原生接口 –>
<!– 箭頭 –>
<!– 流程節點3:直達 Claude –>
<!– 箭頭 –>
<!– 流程節點4:Claude API 成功 –>
<!– 費用說明框 –>
OpenAI 兼容模式 vs Anthropic 原生格式對比
| 對比維度 | OpenAI 兼容模式 | Anthropic 原生格式 |
|---|---|---|
| 接口路徑 | /v1/chat/completions |
/v1/messages |
| Claude 緩存支持 | ❌ 不支持 | ✅ 完整支持 |
cache_control 參數 |
❌ 無此字段 | ✅ 支持 4 個斷點 |
| System Prompt 每次計費 | 💸 全額(1× 價格) | 💰 緩存讀取(0.1× 價格) |
| 代碼複雜度 | 低(通用代碼) | 中(需用 Anthropic SDK) |
| 省錢效果(高頻場景) | 0% | 最高 90% |
非原廠 API 部署的額外問題
除了接口格式的問題,還有一個容易混淆的情況:雲廠商部署的"同名"模型,不等於原廠。
以 GLM-5(智譜 AI)爲例:
- z.ai 官網原廠 API:支持智譜自研的緩存計費功能
- 阿里雲 / 騰訊雲等部署的 GLM-5:使用雲廠商的 API 網關,不具備原廠緩存計費功能
這不是 GLM-5 的問題,而是非原廠部署的通病:雲廠商在託管模型時,通常只對外暴露標準的對話 API,不透傳模型原廠的私有特性(如緩存計費等)。
類比:就像通過代理購買的商品,享受不到廠商官方的專項售後服務。
實際影響:
場景:每天 50 次調用,System Prompt 6,000 tokens
原廠 API(支持緩存):
寫入:2 次 × 6,000 × 1.25 = 15,000 tokens
讀取:48 次 × 6,000 × 0.1 = 28,800 tokens
等效消耗 ≈ 43,800 tokens/天
非原廠 API(無緩存):
全額:50 次 × 6,000 = 300,000 tokens/天
差距:無緩存消耗是有緩存的 6.85 倍
四、原廠 API 對比:如何選擇最適合 OpenClaw 的接入方案
四種接入方案對比
| 接入方案 | 價格(相對原價) | 緩存支持 | 多模型支持 | 適用場景 |
|---|---|---|---|---|
| Anthropic 官方 API | 100%(原價) | ✅ 完整 | ❌ 僅 Claude | 預算充足、純 Claude 用戶 |
| API易(Anthropic 原生格式) | 80%(八折) | ✅ 完整 | ✅ 多模型 | 推薦:省錢 + 靈活切換 |
| 通用中轉站(OpenAI 兼容) | 85-95%不等 | ❌ 不支持 | ✅ 多模型 | 不使用 Claude 緩存時 |
| 雲廠商非原廠部署 | 90-110%不等 | ❌ 不支持 | ❌ 單一模型 | 企業合規要求場景 |
API易 的雙重省錢邏輯
API易 在 Claude 模型上的優勢在於:同時支持 Anthropic 原生格式和八折價格。
這兩點疊加起來,意味着:
普通用戶(原價 + OpenAI 兼容,無緩存):
每月 System Prompt Token 消耗:12,000,000 tokens
費用 = 12,000,000 × $3/1M = $36
API易 用戶(八折 + 原生格式 + 緩存):
實際計費 Token ≈ 1,440,000 tokens(緩存後)
費用 = 1,440,000 × $3×0.8/1M = $3.46
綜合節省 = ($36 - $3.46) / $36 ≈ 90%
🎯 選型建議: 如果你在用 OpenClaw 且模型主要選擇 Claude,
強烈建議通過 API易 apiyi.com 用 Anthropic 原生格式接入。
八折基礎價 + 緩存節省的 90%,雙重疊加可讓賬單降低 85-90%。
同時 API易 還支持 GLM-5、GPT 等多模型,方便你隨時切換對比效果。
五、OpenClaw 省錢全攻略:5 個可立即執行的步驟
步驟 1:切換到 Anthropic 原生格式接口
這是最重要的一步,直接決定你能否享受緩存計費。
OpenClaw 配置方法:
在 OpenClaw 的模型配置(config.json)中,找到 models.providers 字段,按以下格式添加 API易 作爲提供商,關鍵是將 api 字段設爲 "anthropic-messages",這樣才能使用 Anthropic 原生格式並支持緩存計費:
{
"models": {
"providers": {
"apiyi": {
"baseUrl": "https://api.apiyi.com",
"apiKey": "sk-令牌填這裏",
"api": "anthropic-messages",
"headers": {
"anthropic-version": "2023-06-01",
"anthropic-beta": ""
},
"models": [
{
"id": "claude-sonnet-4-6",
"name": "claude-sonnet-4-6",
"reasoning": false,
"input": ["text"],
"contextWindow": 200000,
"maxTokens": 16384
},
{
"id": "claude-sonnet-4-6-thinking",
"name": "claude-sonnet-4-6-thinking",
"reasoning": false,
"input": ["text"],
"contextWindow": 200000,
"maxTokens": 16384
}
]
}
}
}
}
配置要點說明:
"api": "anthropic-messages"← 最關鍵,指定使用/v1/messages原生格式,而非/v1/chat/completions兼容格式"baseUrl": "https://api.apiyi.com"← API易 的 base URL(無需加/v1,OpenClaw 會自動拼接)"anthropic-version": "2023-06-01"← Anthropic API 版本頭,缺少此頭會導致請求失敗contextWindow: 200000← Claude Sonnet 4.6 支持 200K 上下文窗口
驗證緩存是否生效:
查看 API 響應頭或日誌中的 cache_read_input_tokens 和 cache_creation_input_tokens 字段。如果有值,說明緩存已生效:
# 驗證緩存響應
response = client.messages.create(...)
# 檢查 usage 字段
print(response.usage)
# 輸出示例:
# Usage(
# input_tokens=150, # 當次新增 token
# cache_creation_input_tokens=8000, # 首次寫入緩存(按 1.25× 計費)
# cache_read_input_tokens=0, # 後續命中緩存(按 0.1× 計費)
# output_tokens=300
# )
🎯 接入方式: 通過 API易 apiyi.com 註冊並獲取 API Key 後,
將base_url設爲https://api.apiyi.com/v1即可使用 Anthropic 原生格式,
無需修改其他代碼,Claude 緩存計費立即生效。
步驟 2:合理放置緩存斷點
緩存斷點(cache_control)的位置至關重要。應該緩存那些"大而固定"的內容:
# 最佳實踐:緩存系統提示詞 + 工具定義
response = client.messages.create(
model="claude-sonnet-4-6",
system=[
{
"type": "text",
"text": SYSTEM_PROMPT, # 5,000-10,000 tokens 的主系統提示
"cache_control": {"type": "ephemeral"} # 斷點1
},
{
"type": "text",
"text": TOOL_DEFINITIONS, # 工具列表(通常也很大)
"cache_control": {"type": "ephemeral"} # 斷點2
}
],
messages=conversation_history, # 對話歷史(不緩存,每次變化)
...
)
緩存策略要點:
- ✅ 適合緩存:系統提示詞、工具定義、大塊靜態文檔、RAG 檢索的文檔內容
- ❌ 不適合緩存:當前用戶消息、動態生成的內容、每次變化的數據
- ⚠️ 注意順序:緩存是前綴匹配的,靜態內容必須放在消息序列的靠前位置
步驟 3:啓用 QMD 減少上下文長度
QMD(Quick Memory Database,快速記憶數據庫)是 OpenClaw 的本地語義搜索功能。它的工作原理:
傳統方式:
每次發送 [全部歷史對話] → 消耗大量 Token
QMD 方式:
本地建立向量數據庫 → 搜索最相關的歷史片段
每次只發送 [最相關的 3-5 條歷史記錄] → 節省 60-97% Token
QMD 的實際節省效果:根據 OpenClaw 官方文檔,QMD 可實現 60-97% 的 Token 節省,具體比例取決於對話歷史的體量和任務類型。
啓用方式(OpenClaw 設置界面):
- Settings → Memory → Enable QMD
- 設置 QMD 存儲路徑(本地,數據不上傳)
- 設置相關性閾值(推薦 0.7 以上,避免噪音歷史記錄)
步驟 4:按任務類型選擇合適的模型
不是所有任務都需要最強的模型。正確的模型分配是成本控制的關鍵:
任務分級策略:
簡單任務(日程提醒、格式轉換、簡單搜索)
→ 使用 Claude Haiku 4.5(最快,最便宜)
→ 約爲 Sonnet 價格的 1/5
中等任務(郵件處理、文件整理、代碼 review)
→ 使用 Claude Sonnet 4.6(均衡)
→ 成功率 86.9%(PinchBench 第一)
複雜任務(架構分析、多步研究、複雜推理)
→ 使用 Claude Opus 4.6(最強推理)
→ 只在確實需要時啓用推理模式
步驟 5:週期性清理上下文
對話歷史是 Token 消耗的最大來源之一(40-50%)。建議:
- 設置最大上下文輪數:超過 15-20 輪後自動總結並清理歷史
- 任務完成後手動清理:開啓新任務前重置上下文
- 啓用 OpenClaw 的會話壓縮功能:用 AI 將長曆史壓縮爲摘要
五步優化的綜合效果預估
以一箇中度使用 OpenClaw 的用戶爲基準(未優化月費約 $300-600),執行上述五步後的預期效果:
| 優化步驟 | 針對消耗來源 | 預期節省比例 | 執行難度 |
|---|---|---|---|
| 1. 切換 Anthropic 原生格式 | System Prompt 重複計費 | 節省 85-90% (SP 部分) | ⭐ 低(改 base_url) |
| 2. 設置緩存斷點 | 工具定義 + 靜態文檔 | 節省 80-90% (工具部分) | ⭐⭐ 低中 |
| 3. 啓用 QMD | 對話歷史 Token | 節省 60-97% (歷史部分) | ⭐⭐ 低中 |
| 4. 模型按任務分級 | 全部 Token 成本 | 節省 30-70% (模型差價) | ⭐⭐⭐ 中 |
| 5. 週期性清理上下文 | 歷史累積雪球效應 | 節省 20-40% (長期收益) | ⭐ 低 |
🎯 執行優先級建議: 步驟 1(切換原生格式)和步驟 3(啓用 QMD)是收益最高、操作最簡單的兩步,
建議優先完成這兩步,通常可讓賬單立降 60-80%。
通過 API易 apiyi.com 接入 Claude,步驟 1 只需修改base_url一行配置,5 分鐘內完成。
六、實戰配置:OpenClaw + API易 + Claude 緩存的完整示例
以下是一個完整的、已優化的 OpenClaw 配置示例,適合大多數用戶直接複用:
import anthropic
# 通過 API易 使用 Anthropic 原生格式
client = anthropic.Anthropic(
api_key="sk-your-apiyi-key", # API易 Key(apiyi.com 註冊獲取)
base_url="https://api.apiyi.com/v1"
)
# 定義系統提示詞(大塊內容,適合緩存)
SYSTEM_PROMPT = """
你是一個專業的 AI 智能助理,運行在 OpenClaw 平臺上。
你的職責包括:管理日程、處理郵件、整理文件、協助代碼開發...
[通常有 5,000-10,000 tokens 的詳細說明]
"""
# 定義工具列表(也是大塊固定內容,適合緩存)
TOOL_DEFINITIONS = """
可用工具:calendar_api, email_api, file_system, code_runner...
[工具詳細說明,通常 2,000-5,000 tokens]
"""
def call_openclaw_with_cache(conversation_history: list, user_message: str):
"""優化後的 OpenClaw API 調用,啓用緩存"""
response = client.messages.create(
model="claude-sonnet-4-6", # PinchBench 排名第一
max_tokens=4096,
# 系統提示詞:標記緩存斷點
system=[
{
"type": "text",
"text": SYSTEM_PROMPT,
"cache_control": {"type": "ephemeral"} # 緩存斷點1
},
{
"type": "text",
"text": TOOL_DEFINITIONS,
"cache_control": {"type": "ephemeral"} # 緩存斷點2
}
],
# 對話歷史 + 新消息
messages=[
*conversation_history, # 歷史消息(不緩存,每次變化)
{"role": "user", "content": user_message}
]
)
# 打印 Token 使用情況(用於監控優化效果)
usage = response.usage
print(f"輸入 Token: {usage.input_tokens}")
print(f"緩存寫入: {usage.cache_creation_input_tokens}")
print(f"緩存讀取: {usage.cache_read_input_tokens}")
print(f"輸出 Token: {usage.output_tokens}")
return response.content[0].text
🎯 快速上手: 將上述代碼中的
api_key替換爲你在 API易 apiyi.com 註冊後獲得的 Key,
無需其他修改,即可立即使用 Anthropic 原生格式 + 緩存計費 + API易 八折優惠的組合。
常見問題解答
Q: API易 是否真的支持 Anthropic 原生格式(/v1/messages)?
是的,API易 apiyi.com 同時支持兩種接口格式:
- Anthropic 原生格式:
/v1/messages(支持緩存計費) - OpenAI 兼容格式:
/v1/chat/completions(方便通用代碼)
對於 Claude 模型,強烈建議使用 Anthropic 原生格式,這樣才能享受緩存計費。使用 anthropic Python SDK 並將 base_url 指向 API易 即可。
🎯 訪問 API易 apiyi.com 註冊賬號,控制檯中可以看到兩種格式的接入示例代碼。
Q: 緩存 5 分鐘 TTL 夠用嗎?如何判斷是否需要 1 小時 TTL?
這取決於你的調用頻率:
- 如果你的 OpenClaw 調用間隔 < 5 分鐘(如持續處理任務流),使用默認 5 分鐘 TTL 即可
- 如果調用間隔在 5 分鐘到 1 小時之間(如處理完一批任務後停頓),考慮 1 小時 TTL(費用爲 2× 寫入價格,但緩存命中率更高)
- 如果調用間隔 > 1 小時,緩存意義有限,每次重新寫入即可
Q: 使用 GLM-5 等國產模型時,有什麼省錢建議?
GLM-5 的緩存功能需要通過智譜 AI 官網(z.ai)的原生 API 調用,阿里雲等第三方部署無法使用。
API易 同樣支持 GLM-5 等國產模型,價格在八折以下,方便你在測試階段用統一接口對比各模型效果。在確定適合場景的模型後,再決定是繼續用 API易 還是直連原廠。
Q: 我已經在用第三方中轉站,遷移到支持原生格式的平臺有多難?
遷移成本非常低。唯一需要修改的是代碼中的兩個參數:
# 遷移前(OpenAI 兼容格式)
from openai import OpenAI
client = OpenAI(api_key="sk-xxx", base_url="舊中轉站地址")
response = client.chat.completions.create(model="claude-sonnet-4-6", ...)
# 遷移後(Anthropic 原生格式,支持緩存)
import anthropic
client = anthropic.Anthropic(
api_key="sk-新API易Key", # ← 換成 API易 的 Key
base_url="https://api.apiyi.com/v1" # ← 換成 API易 的地址
)
response = client.messages.create(model="claude-sonnet-4-6", ...)
# 然後在 system 參數中加 cache_control 即可啓用緩存
主要工作量在於將 chat.completions.create 改爲 messages.create,消息格式有細微差異(role/content 結構一致,但 system 從字符串改爲對象列表)。通常半天內可以完成遷移。
Q: 如何驗證我的 OpenClaw 實例是否已成功啓用緩存?
最直接的方法:在連續調用兩次時,觀察 API 響應中的 usage 對象:
- 第一次調用:
cache_creation_input_tokens有值(緩存寫入) - 第二次調用:
cache_read_input_tokens有值(緩存命中)
如果第二次調用的 cache_read_input_tokens 等於 System Prompt 的 Token 數,說明緩存完全生效。
Q: 推理/思維模式(Extended Thinking)一定要關嗎?
不一定要完全關閉,但應該按需使用。建議策略:
- 簡單任務(郵件分類、日程安排):關閉推理模式
- 中等任務(代碼 review、信息彙總):默認關閉,遇到困難時開啓
- 複雜任務(架構決策、多步驟研究):開啓,但設置合理的
budget_tokens上限
在 Claude API 中,可以通過 thinking: {"type": "enabled", "budget_tokens": 5000} 限制推理模式的最大 Token 消耗。
總結:OpenClaw 省錢的核心邏輯
讓我們把所有節省手段用一張圖總結:
<!– 標題 –>
<!– Y軸標籤 –>
<!– Y軸參考線 –>
<!– 圖表高度:$600 對應 250px 高,底部基線 y=343,頂部最高 y=93 –> <!– 比例:1$ = 250/600 = 0.4167px –> <!– $600=250px, $300=125px, $80=33px, $64=27px, $60=25px –>
<!– 柱1:基準 $600,高度 250 –>
<!– 箭頭1→2 –>
<!– 柱2:啓用 QMD $300,高度 125 –>
<!– 箭頭2→3 –>
<!– 柱3:緩存 $80,高度 33 –>
<!– 箭頭3→4 –>
<!– 柱4:八折 API $64,高度 27 –>
<!– 箭頭4→5 –>
<!– 柱5:推理優化 $60,高度 25 –>
<!– 綜合節省標註橫線 –>
<!– 底部總結 –>
回顧本文的核心要點:
三大高消耗根因:
- 對話歷史每次重發(佔 40-50% 消耗)
- System Prompt 每次重發(佔 25-30%)
- 推理模式無節制使用(佔 20-25%)
最高效的省錢手段:
- 🥇 Claude 緩存計費:省最高 90%(必須用 Anthropic 原生格式)
- 🥈 QMD 本地語義搜索:省 60-97% 的歷史上下文 Token
- 🥉 模型按任務分級:輕任務用 Haiku,重任務用 Sonnet/Opus
- API 渠道選 API易:八折基礎價 + 原生格式支持
最關鍵的一個認知:
OpenAI 兼容格式(/v1/chat/completions)無法傳遞
cache_control,
即便通過中轉站調用 Claude,也享受不到緩存摺扣。
要省錢,必須用 Anthropic 原生格式(/v1/messages)。
🎯 立即行動: 訪問 API易 apiyi.com 註冊,獲取支持 Anthropic 原生格式的 API Key。
把 base_url 換成https://api.apiyi.com/v1,3 分鐘內完成切換,
當天就能看到 Token 賬單的顯著下降。Claude 模型八折,多模型統一接口,
是 OpenClaw 用戶降本提效的最優選擇。
本文所有 API 價格數據基於 2026 年 3 月公開資料,實際價格請以各平臺官方公告爲準。
作者:APIYI Team | 更多 OpenClaw 使用技巧,歡迎訪問 API易 apiyi.com 幫助中心