智譜AI在 2026 年 2 月 11 日正式發佈了 GLM-5,這是目前參數規模最大的開源大語言模型之一。GLM-5 採用 744B MoE 混合專家架構,每次推理激活 40B 參數,在推理、編碼和 Agent 任務上達到了開源模型的最佳水平。
核心價值: 讀完本文,你將掌握 GLM-5 的技術架構原理、API 調用方法、Thinking 推理模式配置,以及如何在實際項目中發揮這個 744B 開源旗艦模型的最大價值。

GLM-5 核心參數一覽
在深入技術細節之前,先看一下 GLM-5 的關鍵參數:
| 參數 | 數值 | 說明 |
|---|---|---|
| 總參數量 | 744B (7440 億) | 當前最大開源模型之一 |
| 活躍參數 | 40B (400 億) | 每次推理實際使用 |
| 架構類型 | MoE 混合專家 | 256 專家,每 token 激活 8 個 |
| 上下文窗口 | 200,000 tokens | 支持超長文檔處理 |
| 最大輸出 | 128,000 tokens | 滿足長文本生成需求 |
| 預訓練數據 | 28.5T tokens | 較上代增加 24% |
| 許可證 | Apache-2.0 | 完全開源,支持商業使用 |
| 訓練硬件 | 華爲昇騰芯片 | 全國產算力,不依賴海外硬件 |
GLM-5 的一個顯著特點是它完全基於華爲昇騰芯片和 MindSpore 框架訓練,實現了對國產算力棧的完整驗證。這對於國內開發者來說,意味着技術棧的自主可控又多了一個強有力的選擇。
GLM 系列版本演進
GLM-5 是智譜AI GLM 系列的第五代產品,每一代都有顯著的能力躍升:
| 版本 | 發佈時間 | 參數規模 | 核心突破 |
|---|---|---|---|
| GLM-4 | 2024-01 | 未公開 | 多模態基礎能力 |
| GLM-4.5 | 2025-03 | 355B (32B 活躍) | MoE 架構首次引入 |
| GLM-4.5-X | 2025-06 | 同上 | 強化推理,旗艦定位 |
| GLM-4.7 | 2025-10 | 未公開 | Thinking 推理模式 |
| GLM-4.7-FlashX | 2025-12 | 未公開 | 超低成本快速推理 |
| GLM-5 | 2026-02 | 744B (40B 活躍) | Agent 能力突破,幻覺率降 56% |
從 GLM-4.5 的 355B 到 GLM-5 的 744B,總參數量翻了一倍多;活躍參數從 32B 提升到 40B,增幅 25%;預訓練數據從 23T 增加到 28.5T tokens。這些數字背後是智譜AI在算力、數據和算法三個維度上的全面投入。
🚀 快速體驗: GLM-5 已上線 API易 apiyi.com,價格與官網一致,充值加贈活動下來大約可以享受 8 折優惠,適合想要快速體驗這款 744B 旗艦模型的開發者。
GLM-5 MoE 架構技術解析
GLM-5 爲什麼選擇 MoE 架構
MoE (Mixture of Experts) 是當前大模型擴展的主流技術路線。相比 Dense 架構 (所有參數都參與每次推理),MoE 架構只激活一小部分專家網絡來處理每個 token,在保持大模型知識容量的同時大幅降低推理成本。
GLM-5 的 MoE 架構設計有以下關鍵特性:
| 架構特性 | GLM-5 實現 | 技術價值 |
|---|---|---|
| 專家總數 | 256 個 | 知識容量極大 |
| 每 token 激活 | 8 個專家 | 推理效率高 |
| 稀疏率 | 5.9% | 僅使用小部分參數 |
| 注意力機制 | DSA + MLA | 降低部署成本 |
| 內存優化 | MLA 減少 33% | 顯存佔用更低 |
簡單來說,GLM-5 雖然有 744B 參數,但每次推理只激活 40B (約 5.9%),這意味着它的推理成本遠低於同等規模的 Dense 模型,同時又能利用 744B 參數所蘊含的豐富知識。
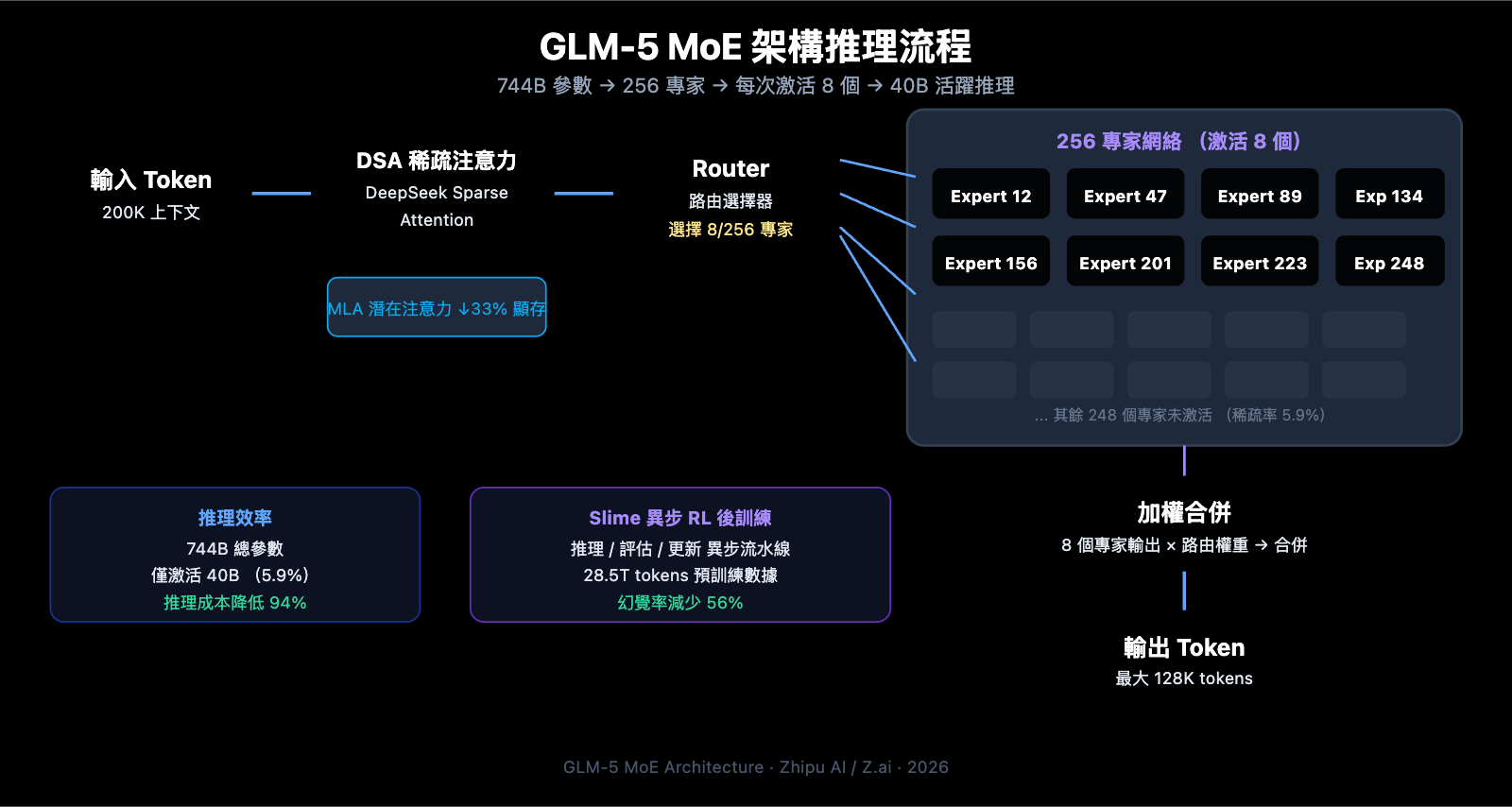
GLM-5 的 DeepSeek Sparse Attention (DSA)
GLM-5 集成了 DeepSeek Sparse Attention 機制,這項技術在保持長上下文能力的同時,顯著降低了部署成本。配合 Multi-head Latent Attention (MLA),GLM-5 在 200K tokens 的超長上下文窗口下依然能夠高效運行。
具體來說:
- DSA (DeepSeek Sparse Attention): 通過稀疏注意力模式減少注意力計算的複雜度。傳統的全注意力機制在處理 200K tokens 時計算量極大,DSA 通過選擇性關注關鍵 token 位置來降低計算開銷,同時保持信息的完整性
- MLA (Multi-head Latent Attention): 將注意力頭的 KV 緩存壓縮到潛在空間中,減少約 33% 的內存佔用。在長上下文場景下,KV 緩存通常是顯存的主要消耗者,MLA 有效緩解了這個瓶頸
這兩項技術的結合意味着:即使是 744B 規模的模型,通過 FP8 量化後也可以在 8 張 GPU 上運行,大幅降低了部署門檻。
GLM-5 後訓練: Slime 異步 RL 系統
GLM-5 採用了名爲 "slime" 的新型異步強化學習基礎設施進行後訓練。傳統的 RL 訓練存在效率瓶頸——生成、評估和更新步驟之間存在大量等待時間。Slime 通過異步化這些步驟,實現了更細粒度的後訓練迭代,大幅提升訓練吞吐量。
傳統 RL 訓練流程中,模型需要先完成一批推理、等待評估結果、再進行參數更新,三個步驟串行執行。Slime 將這三個步驟解耦爲獨立的異步流水線,使得推理、評估和更新可以並行進行,從而顯著提升了訓練效率。
這項技術改進直接反映在了 GLM-5 的幻覺率上——較前代版本減少了 56%。更充分的後訓練迭代讓模型在事實準確性上獲得了明顯改善。
GLM-5 與 Dense 架構的對比
爲了更好地理解 MoE 架構的優勢,我們可以將 GLM-5 與假設的同等規模 Dense 模型進行對比:
| 對比維度 | GLM-5 (744B MoE) | 假設 744B Dense | 實際差異 |
|---|---|---|---|
| 每次推理參數 | 40B (5.9%) | 744B (100%) | MoE 減少 94% |
| 推理顯存需求 | 8x GPU (FP8) | 約 96x GPU | MoE 顯著更低 |
| 推理速度 | 較快 | 極慢 | MoE 更適合實際部署 |
| 知識容量 | 744B 全量知識 | 744B 全量知識 | 相當 |
| 專業化能力 | 不同專家擅長不同任務 | 統一處理 | MoE 更精細 |
| 訓練成本 | 較高但可控 | 極高 | MoE 性價比更優 |
MoE 架構的核心優勢在於: 它用 744B 參數的知識容量,換來了僅需 40B 參數推理成本的高效率。這就是爲什麼 GLM-5 能在保持前沿性能的同時,提供遠低於同級別閉源模型的定價。
GLM-5 API 調用快速上手
GLM-5 API 請求參數詳解
在編寫代碼之前,先了解 GLM-5 的 API 參數配置:
| 參數 | 類型 | 必需 | 默認值 | 說明 |
|---|---|---|---|---|
model |
string | ✅ | – | 固定爲 "glm-5" |
messages |
array | ✅ | – | 標準 chat 格式消息 |
max_tokens |
int | ❌ | 4096 | 最大輸出 token 數 (上限 128K) |
temperature |
float | ❌ | 1.0 | 採樣溫度,越低越確定 |
top_p |
float | ❌ | 1.0 | 核採樣參數 |
stream |
bool | ❌ | false | 是否流式輸出 |
thinking |
object | ❌ | disabled | {"type": "enabled"} 開啓推理 |
tools |
array | ❌ | – | Function Calling 工具定義 |
tool_choice |
string | ❌ | auto | 工具選擇策略 |
GLM-5 極簡調用示例
GLM-5 兼容 OpenAI SDK 接口格式,只需更換 base_url 和 model 參數即可快速接入:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # API易統一接口
)
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "你是一位資深的 AI 技術專家"},
{"role": "user", "content": "解釋 MoE 混合專家架構的工作原理和優勢"}
],
temperature=0.7,
max_tokens=4096
)
print(response.choices[0].message.content)
上面這段代碼就是 GLM-5 最基礎的調用方式。模型 ID 使用 glm-5,接口完全兼容 OpenAI 的 chat.completions 格式,現有項目遷移只需修改兩個參數。
GLM-5 Thinking 推理模式
GLM-5 支持 Thinking 推理模式,類似 DeepSeek R1 和 Claude 的擴展思考能力。啓用後,模型會在回答前進行內部鏈式推理,對複雜數學、邏輯和編程問題的表現顯著提升:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # API易統一接口
)
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "user", "content": "證明: 對於所有正整數 n, n^3 - n 能被 6 整除"}
],
extra_body={
"thinking": {"type": "enabled"}
},
temperature=1.0 # Thinking 模式建議使用 1.0
)
print(response.choices[0].message.content)
GLM-5 Thinking 模式使用建議:
| 場景 | 是否開啓 Thinking | temperature 建議 | 說明 |
|---|---|---|---|
| 數學證明/競賽題 | ✅ 開啓 | 1.0 | 需要深度推理 |
| 代碼調試/架構設計 | ✅ 開啓 | 1.0 | 需要系統分析 |
| 邏輯推理/分析 | ✅ 開啓 | 1.0 | 需要鏈式思考 |
| 日常對話/寫作 | ❌ 關閉 | 0.5-0.7 | 不需要複雜推理 |
| 信息提取/摘要 | ❌ 關閉 | 0.3-0.5 | 追求穩定輸出 |
| 創意內容生成 | ❌ 關閉 | 0.8-1.0 | 需要多樣性 |
GLM-5 流式輸出
對於需要實時交互的場景,GLM-5 支持流式輸出,用戶可以在模型生成的過程中逐步看到結果:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
stream = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "user", "content": "用 Python 實現一個帶緩存的 HTTP 客戶端"}
],
stream=True,
temperature=0.6
)
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
GLM-5 Function Calling 與 Agent 構建
GLM-5 原生支持 Function Calling,這是構建 Agent 系統的核心能力。GLM-5 在 HLE w/ Tools 上拿到 50.4% 的成績超越了 Claude Opus (43.4%),說明它在工具調用和任務編排上表現出色:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
tools = [
{
"type": "function",
"function": {
"name": "search_documents",
"description": "搜索知識庫中的相關文檔",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "搜索關鍵詞"},
"top_k": {"type": "integer", "description": "返回結果數量", "default": 5}
},
"required": ["query"]
}
}
},
{
"type": "function",
"function": {
"name": "execute_code",
"description": "在沙箱環境中執行 Python 代碼",
"parameters": {
"type": "object",
"properties": {
"code": {"type": "string", "description": "要執行的 Python 代碼"},
"timeout": {"type": "integer", "description": "超時時間(秒)", "default": 30}
},
"required": ["code"]
}
}
}
]
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "你是一個能夠搜索文檔和執行代碼的AI助手"},
{"role": "user", "content": "幫我查一下 GLM-5 的技術參數,然後用代碼畫一個性能對比圖"}
],
tools=tools,
tool_choice="auto"
)
# 處理工具調用
message = response.choices[0].message
if message.tool_calls:
for tool_call in message.tool_calls:
print(f"調用工具: {tool_call.function.name}")
print(f"參數: {tool_call.function.arguments}")
查看 cURL 調用示例
curl https://api.apiyi.com/v1/chat/completions \
-H "Authorization: Bearer $API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "glm-5",
"messages": [
{"role": "system", "content": "你是一位資深軟件工程師"},
{"role": "user", "content": "設計一個分佈式任務調度系統的架構"}
],
"max_tokens": 8192,
"temperature": 0.7,
"stream": true
}'
🎯 技術建議: GLM-5 兼容 OpenAI SDK 格式,現有項目只需修改
base_url和model兩個參數即可遷移。通過 API易 apiyi.com 平臺調用,可以享受統一接口管理和充值加贈優惠。
GLM-5 Benchmark 性能實測
GLM-5 核心 Benchmark 數據
GLM-5 在多個主流 benchmark 上展現了開源模型的最強水平:
| Benchmark | GLM-5 | Claude Opus 4.5 | GPT-5 | 測試內容 |
|---|---|---|---|---|
| MMLU | 85.0% | 88.7% | 90.2% | 57 學科知識 |
| MMLU Pro | 70.4% | – | – | 增強版多學科 |
| GPQA | 68.2% | 71.4% | 73.1% | 研究生級科學 |
| HumanEval | 90.0% | 93.2% | 92.5% | Python 編程 |
| MATH | 88.0% | 90.1% | 91.3% | 數學推理 |
| GSM8k | 97.0% | 98.2% | 98.5% | 數學應用題 |
| AIME 2026 I | 92.7% | 93.3% | – | 數學競賽 |
| SWE-bench | 77.8% | 80.9% | 80.0% | 真實軟件工程 |
| HLE w/ Tools | 50.4% | 43.4% | – | 帶工具推理 |
| IFEval | 88.0% | – | – | 指令遵循 |
| Terminal-Bench | 56.2% | 57.9% | – | 終端操作 |
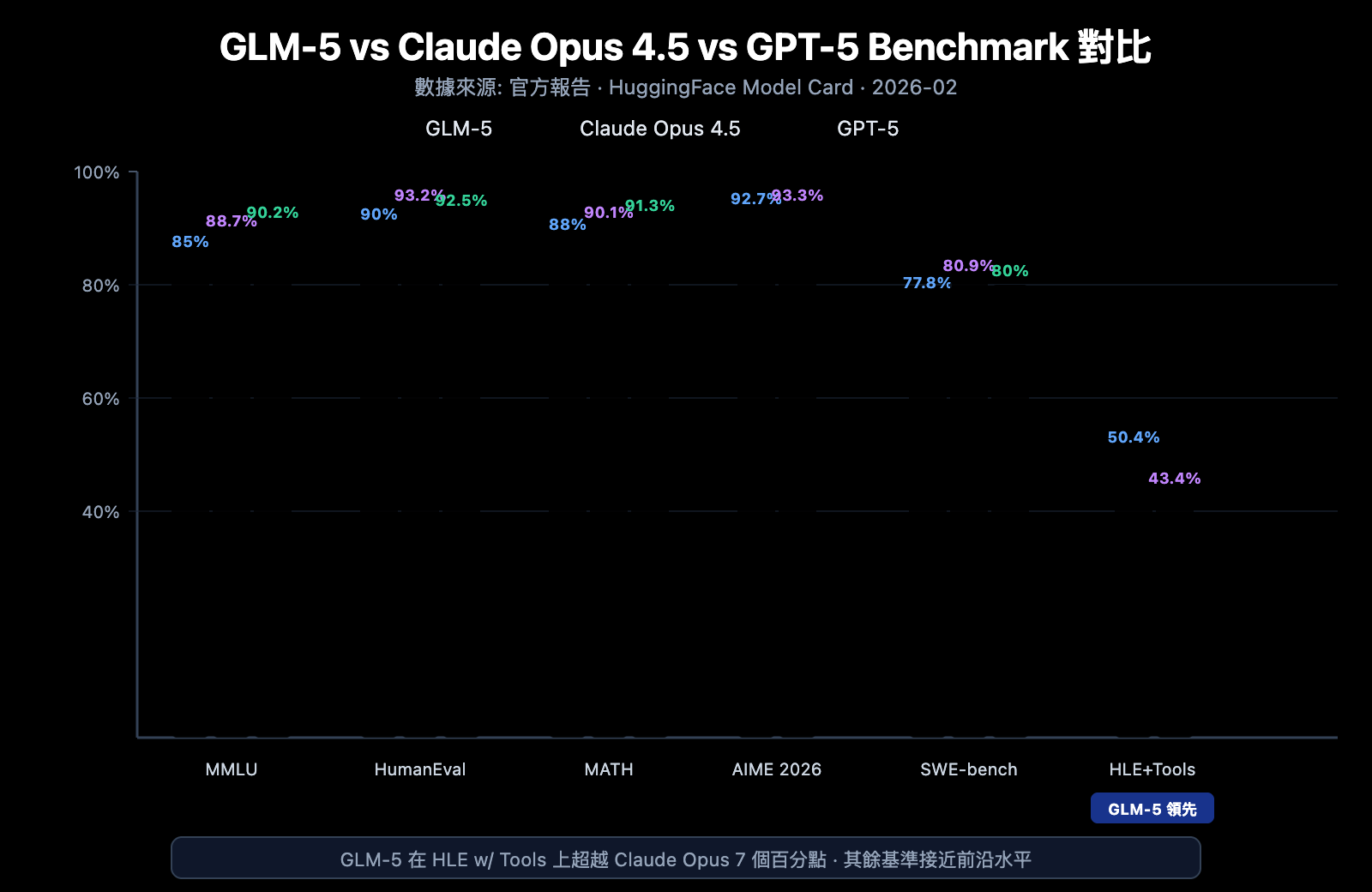
GLM-5 性能分析: 4 大核心優勢
從 benchmark 數據可以看到幾個值得關注的點:
1. GLM-5 Agent 能力: HLE w/ Tools 超越閉源模型
GLM-5 在 Humanity's Last Exam (帶工具使用) 上拿到了 50.4% 的成績,超越了 Claude Opus 的 43.4%,僅次於 Kimi K2.5 的 51.8%。這說明 GLM-5 在 Agent 場景下——需要規劃、調用工具、迭代求解的複雜任務中——已經具備了前沿模型水平。
這個結果與 GLM-5 的設計理念一致: 它從架構到後訓練都針對 Agent 工作流進行了專門優化。對於想要構建 AI Agent 系統的開發者來說,GLM-5 提供了一個開源且高性價比的選擇。
2. GLM-5 編碼能力: 進入第一梯隊
HumanEval 90%、SWE-bench Verified 77.8%,說明 GLM-5 在代碼生成和真實軟件工程任務上已經非常接近 Claude Opus (80.9%) 和 GPT-5 (80.0%) 的水平。作爲開源模型,SWE-bench 77.8% 是一個重要的突破——這意味着 GLM-5 已經能夠理解真實的 GitHub issue、定位代碼問題並提交有效的修復。
3. GLM-5 數學推理: 接近天花板
AIME 2026 I 上 GLM-5 拿到 92.7%,僅落後 Claude Opus 0.6 個百分點。GSM8k 97% 也說明在中等難度的數學問題上,GLM-5 已經非常可靠。MATH 88% 的成績同樣位於第一梯隊。
4. GLM-5 幻覺控制: 大幅降低
根據官方數據,GLM-5 較前代版本幻覺率減少了 56%。這得益於 Slime 異步 RL 系統帶來的更充分的後訓練迭代。在需要高準確性的信息提取、文檔摘要和知識庫問答場景中,更低的幻覺率直接轉化爲更可靠的輸出質量。
GLM-5 與同級開源模型的定位
在當前開源大模型競爭格局中,GLM-5 的定位比較明確:
| 模型 | 參數規模 | 架構 | 核心優勢 | 許可證 |
|---|---|---|---|---|
| GLM-5 | 744B (40B 活躍) | MoE | Agent + 低幻覺 | Apache-2.0 |
| DeepSeek V3 | 671B (37B 活躍) | MoE | 性價比 + 推理 | MIT |
| Llama 4 Maverick | 400B (17B 活躍) | MoE | 多模態 + 生態 | Llama License |
| Qwen 3 | 235B | Dense | 多語言 + 工具 | Apache-2.0 |
GLM-5 的差異化優勢主要體現在三個方面: Agent 工作流的專門優化 (HLE w/ Tools 領先)、極低的幻覺率 (減少 56%)、以及全國產算力訓練所帶來的供應鏈安全。對於需要在國內部署前沿開源模型的企業來說,GLM-5 是一個值得重點關注的選項。
GLM-5 定價與成本分析
GLM-5 官方定價
| 計費類型 | Z.ai 官方價格 | OpenRouter 價格 | 說明 |
|---|---|---|---|
| 輸入 Token | $1.00/M | $0.80/M | 每百萬輸入 token |
| 輸出 Token | $3.20/M | $2.56/M | 每百萬輸出 token |
| 緩存輸入 | $0.20/M | $0.16/M | 緩存命中時的輸入價格 |
| 緩存存儲 | 暫時免費 | – | 緩存數據存儲費用 |
GLM-5 與競品價格對比
GLM-5 的定價策略非常有競爭力,特別是與閉源前沿模型相比:
| 模型 | 輸入 ($/M) | 輸出 ($/M) | 相對 GLM-5 成本 | 模型定位 |
|---|---|---|---|---|
| GLM-5 | $1.00 | $3.20 | 基準 | 開源旗艦 |
| Claude Opus 4.6 | $5.00 | $25.00 | 約 5-8x | 閉源旗艦 |
| GPT-5 | $1.25 | $10.00 | 約 1.3-3x | 閉源旗艦 |
| DeepSeek V3 | $0.27 | $1.10 | 約 0.3x | 開源性價比 |
| GLM-4.7 | $0.60 | $2.20 | 約 0.6-0.7x | 上代旗艦 |
| GLM-4.7-FlashX | $0.07 | $0.40 | 約 0.07-0.13x | 超低成本 |
從價格看,GLM-5 定位在 GPT-5 和 DeepSeek V3 之間——比大部分閉源前沿模型便宜很多,但比輕量級開源模型略貴。考慮到 744B 的參數規模和開源最強的性能表現,這個定價是合理的。
GLM 全系列產品線與定價
如果 GLM-5 不完全匹配你的場景,智譜還提供了完整的產品線供選擇:
| 模型 | 輸入 ($/M) | 輸出 ($/M) | 適用場景 |
|---|---|---|---|
| GLM-5 | $1.00 | $3.20 | 複雜推理、Agent、長文檔 |
| GLM-5-Code | $1.20 | $5.00 | 代碼開發專用 |
| GLM-4.7 | $0.60 | $2.20 | 中等複雜度通用任務 |
| GLM-4.7-FlashX | $0.07 | $0.40 | 高頻低成本調用 |
| GLM-4.5-Air | $0.20 | $1.10 | 輕量平衡 |
| GLM-4.7/4.5-Flash | 免費 | 免費 | 入門體驗和簡單任務 |
💰 成本優化: GLM-5 已上線 API易 apiyi.com,價格與 Z.ai 官方一致。通過平臺充值加贈活動,實際使用成本大約可以降到官方價格的 8 折,適合有持續調用需求的團隊和開發者。
GLM-5 適用場景與選型建議
GLM-5 適合哪些場景
根據 GLM-5 的技術特點和 benchmark 表現,以下是具體的場景推薦:
強烈推薦的場景:
- Agent 工作流: GLM-5 專爲長週期 Agent 任務設計,HLE w/ Tools 50.4% 超越 Claude Opus,適合構建自主規劃和工具調用的 Agent 系統
- 代碼工程任務: HumanEval 90%、SWE-bench 77.8%,勝任代碼生成、Bug 修復、代碼審查和架構設計
- 數學與科學推理: AIME 92.7%、MATH 88%,適合數學證明、公式推導和科學計算
- 超長文檔分析: 200K 上下文窗口,處理完整代碼庫、技術文檔、法律合同等超長文本
- 低幻覺問答: 幻覺率減少 56%,適合知識庫問答、文檔摘要等需要高準確性的場景
可以考慮其他方案的場景:
- 多模態任務: GLM-5 本體僅支持文本,需要圖像理解請選擇 GLM-4.6V 等視覺模型
- 極致低延遲: 744B MoE 模型的推理速度不如小模型,高頻低延遲場景建議使用 GLM-4.7-FlashX
- 超低成本批量處理: 大批量文本處理如果對質量要求不高,DeepSeek V3 或 GLM-4.7-FlashX 成本更低
GLM-5 與 GLM-4.7 選型對比
| 對比維度 | GLM-5 | GLM-4.7 | 選型建議 |
|---|---|---|---|
| 參數規模 | 744B (40B 活躍) | 未公開 | GLM-5 更大 |
| 推理能力 | AIME 92.7% | ~85% | 複雜推理選 GLM-5 |
| Agent 能力 | HLE w/ Tools 50.4% | ~38% | Agent 任務選 GLM-5 |
| 編碼能力 | HumanEval 90% | ~85% | 代碼開發選 GLM-5 |
| 幻覺控制 | 減少 56% | 基準 | 高準確性選 GLM-5 |
| 輸入價格 | $1.00/M | $0.60/M | 成本敏感選 GLM-4.7 |
| 輸出價格 | $3.20/M | $2.20/M | 成本敏感選 GLM-4.7 |
| 上下文長度 | 200K | 128K+ | 長文檔選 GLM-5 |
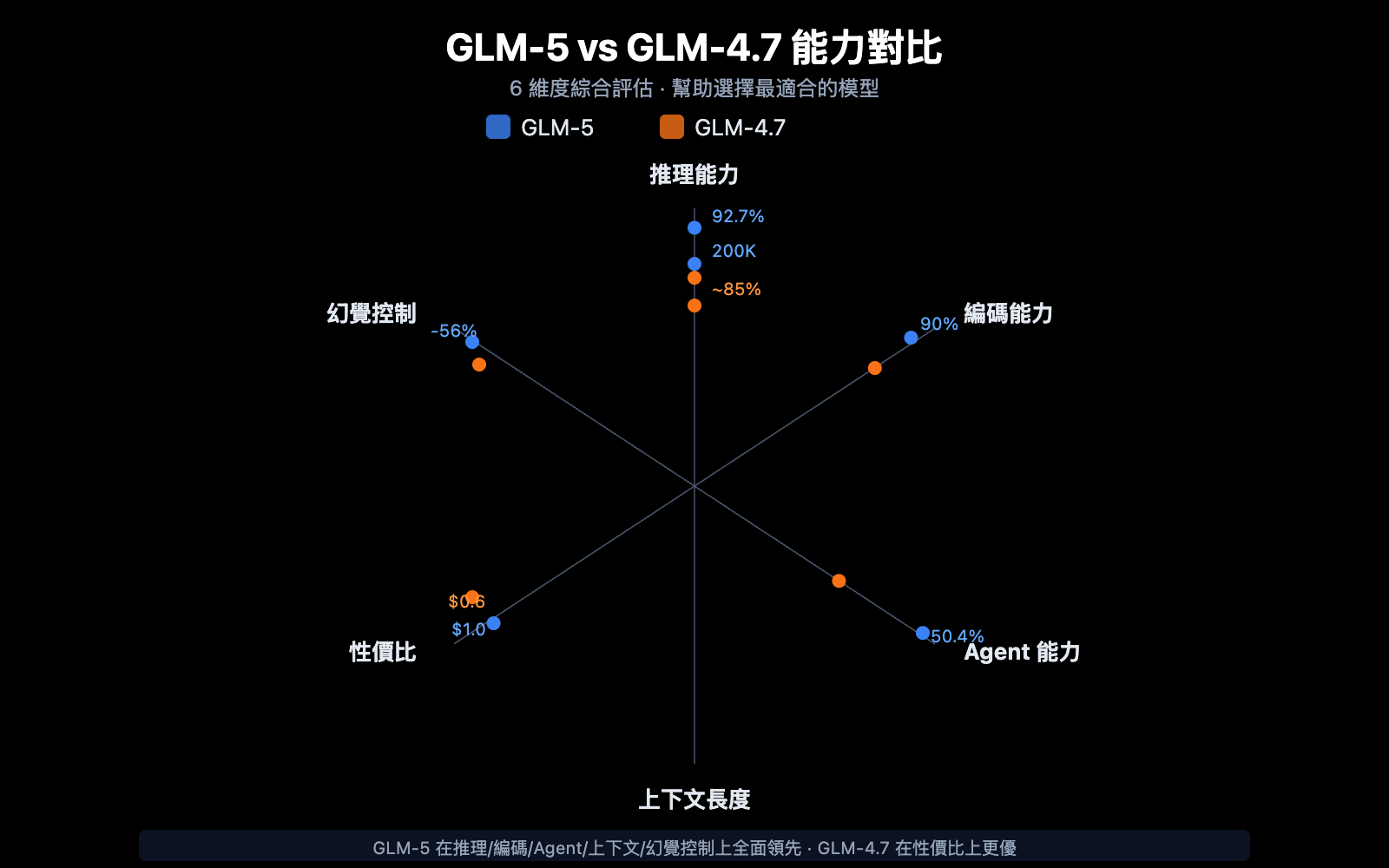
💡 選擇建議: 如果你的項目需要頂級推理能力、Agent 工作流或超長上下文處理,GLM-5 是更好的選擇。如果預算有限且任務複雜度適中,GLM-4.7 也是不錯的性價比方案。兩個模型都可以通過 API易 apiyi.com 平臺調用,方便隨時切換測試。
GLM-5 API 調用常見問題
Q1: GLM-5 和 GLM-5-Code 有什麼區別?
GLM-5 是通用旗艦模型 (輸入 $1.00/M,輸出 $3.20/M),適合各類文本任務。GLM-5-Code 是代碼專用增強版 (輸入 $1.20/M,輸出 $5.00/M),在代碼生成、調試和工程任務上經過額外優化。如果你的主要場景是代碼開發,GLM-5-Code 值得嘗試。兩個模型都支持通過統一的 OpenAI 兼容接口調用。
Q2: GLM-5 的 Thinking 模式會影響輸出速度嗎?
會。Thinking 模式下,GLM-5 會先生成內部推理鏈再輸出最終答案,所以首 token 延遲 (TTFT) 會增加。對於簡單問題建議關閉 Thinking 模式以獲得更快響應。複雜的數學、編程和邏輯問題建議開啓,雖然慢一些但準確率會明顯提升。
Q3: 從 GPT-4 或 Claude 遷移到 GLM-5 需要改哪些代碼?
遷移非常簡單,只需修改兩個參數:
- 將
base_url改爲 API易的接口地址https://api.apiyi.com/v1 - 將
model參數改爲"glm-5"
GLM-5 完全兼容 OpenAI SDK 的 chat.completions 接口格式,包括 system/user/assistant 角色、流式輸出、Function Calling 等功能。通過統一的 API 中轉平臺還可以在同一個 API Key 下切換調用不同廠商的模型,非常方便進行 A/B 測試。
Q4: GLM-5 支持圖片輸入嗎?
不支持。GLM-5 本體是純文本模型,不支持圖像、音頻或視頻輸入。如果需要圖像理解能力,可以使用智譜的 GLM-4.6V 或 GLM-4.5V 等視覺變體模型。
Q5: GLM-5 的上下文緩存功能怎麼使用?
GLM-5 支持上下文緩存 (Context Caching),緩存輸入的價格僅爲 $0.20/M,是正常輸入的 1/5。在長對話或需要重複處理相同前綴的場景中,緩存功能可以顯著降低成本。緩存存儲目前暫時免費。在多輪對話中,系統會自動識別並緩存重複的上下文前綴。
Q6: GLM-5 的最大輸出長度是多少?
GLM-5 支持最大 128,000 tokens 的輸出長度。對於大多數場景,默認的 4096 tokens 就足夠了。如果需要生成長文本 (如完整的技術文檔、大段代碼),可以通過 max_tokens 參數調整。需要注意的是,輸出越長,token 消耗和等待時間都會相應增加。
GLM-5 API 調用最佳實踐
在實際使用 GLM-5 時,以下幾個實踐經驗可以幫助你獲得更好的效果:
GLM-5 System Prompt 優化
GLM-5 對 system prompt 的響應質量很高,合理設計 system prompt 可以顯著提升輸出質量:
# 推薦: 明確角色定義 + 輸出格式要求
messages = [
{
"role": "system",
"content": """你是一位資深的分佈式系統架構師。
請遵循以下規則:
1. 回答要結構化,使用 Markdown 格式
2. 給出具體的技術方案而非泛泛而談
3. 如果涉及代碼,提供可運行的示例
4. 在適當位置標註潛在風險和注意事項"""
},
{
"role": "user",
"content": "設計一個支持百萬級併發的消息隊列系統"
}
]
GLM-5 temperature 調優指南
不同任務對 temperature 的敏感度不同,以下是實測建議:
- temperature 0.1-0.3: 代碼生成、數據提取、格式轉換等需要精確輸出的任務
- temperature 0.5-0.7: 技術文檔、問答、摘要等需要穩定且有一定表達靈活度的任務
- temperature 0.8-1.0: 創意寫作、頭腦風暴等需要多樣性的任務
- temperature 1.0 (Thinking 模式): 數學推理、複雜編程等深度推理任務
GLM-5 長上下文處理技巧
GLM-5 支持 200K tokens 的上下文窗口,但在實際使用中需要注意:
- 重要信息前置: 將最關鍵的上下文放在 prompt 開頭位置,而非末尾
- 分段處理: 超過 100K tokens 的文檔建議分段處理後合併,以獲得更穩定的輸出
- 利用緩存: 多輪對話中,相同的前綴內容會自動被緩存,緩存輸入價格僅 $0.20/M
- 控制輸出長度: 長上下文輸入時適當設置
max_tokens,避免輸出過長增加不必要的成本
GLM-5 本地部署參考
如果你需要在自有基礎設施上部署 GLM-5,以下是主要的部署方式:
| 部署方式 | 推薦硬件 | 精度 | 特點 |
|---|---|---|---|
| vLLM | 8x A100/H100 | FP8 | 主流推理框架,支持投機解碼 |
| SGLang | 8x H100/B200 | FP8 | 高性能推理,Blackwell GPU 優化 |
| xLLM | 華爲昇騰 NPU | BF16/FP8 | 國產算力適配 |
| KTransformers | 消費級 GPU | 量化 | GPU 加速推理 |
| Ollama | 消費級硬件 | 量化 | 最簡單的本地體驗 |
GLM-5 提供 BF16 全精度和 FP8 量化兩種權重格式,可從 HuggingFace (huggingface.co/zai-org/GLM-5) 或 ModelScope 下載。FP8 量化版本在保持大部分性能的同時,顯著降低了顯存需求。
部署 GLM-5 需要的關鍵配置:
- 張量並行: 8 路 (tensor-parallel-size 8)
- 顯存利用率: 建議設爲 0.85
- 工具調用解析器: glm47
- 推理解析器: glm45
- 投機解碼: 支持 MTP 和 EAGLE 兩種方式
對於大多數開發者來說,通過 API 調用是最高效的方式,省去了部署運維成本,只需專注於應用開發。需要私有化部署的場景可以參考官方文檔:
github.com/zai-org/GLM-5
GLM-5 API 調用總結
GLM-5 核心能力速查
| 能力維度 | GLM-5 表現 | 適用場景 |
|---|---|---|
| 推理 | AIME 92.7%, MATH 88% | 數學證明、科學推理、邏輯分析 |
| 編碼 | HumanEval 90%, SWE-bench 77.8% | 代碼生成、Bug 修復、架構設計 |
| Agent | HLE w/ Tools 50.4% | 工具調用、任務規劃、自主執行 |
| 知識 | MMLU 85%, GPQA 68.2% | 學科問答、技術諮詢、知識提取 |
| 指令 | IFEval 88% | 格式化輸出、結構化生成、規則遵循 |
| 準確性 | 幻覺率減少 56% | 文檔摘要、事實覈查、信息提取 |
GLM-5 開源生態價值
GLM-5 採用 Apache-2.0 許可證開源,這意味着:
- 商業自由: 企業可以免費使用、修改和分發,無需支付許可費
- 微調定製: 可以基於 GLM-5 進行領域微調,構建行業專屬模型
- 私有部署: 敏感數據不出內網,滿足金融、醫療、政府等合規要求
- 社區生態: HuggingFace 上已有 11+ 量化變體和 7+ 微調版本,生態持續擴展
GLM-5 作爲智譜AI的最新旗艦模型,在開源大模型領域樹立了新的標杆:
- 744B MoE 架構: 256 專家系統,每次推理激活 40B 參數,在模型容量和推理效率之間取得出色平衡
- 開源最強 Agent: HLE w/ Tools 50.4% 超越 Claude Opus,專爲長週期 Agent 工作流設計
- 全國產算力訓練: 基於 10 萬塊華爲昇騰芯片訓練,驗證了國產算力棧的前沿模型訓練能力
- 高性價比: 輸入 $1/M、輸出 $3.2/M,遠低於同級別閉源模型,開源社區可自由部署和微調
- 200K 超長上下文: 支持完整代碼庫和大型技術文檔的一次性處理,最大輸出 128K tokens
- 56% 低幻覺: Slime 異步 RL 後訓練大幅提升了事實準確性
推薦通過 API易 apiyi.com 快速體驗 GLM-5 的各項能力,平臺價格與官方一致,充值加贈活動約可享受 8 折優惠。
本文由 APIYI Team 技術團隊撰寫,更多 AI 模型使用教程請關注 API易 apiyi.com 幫助中心。