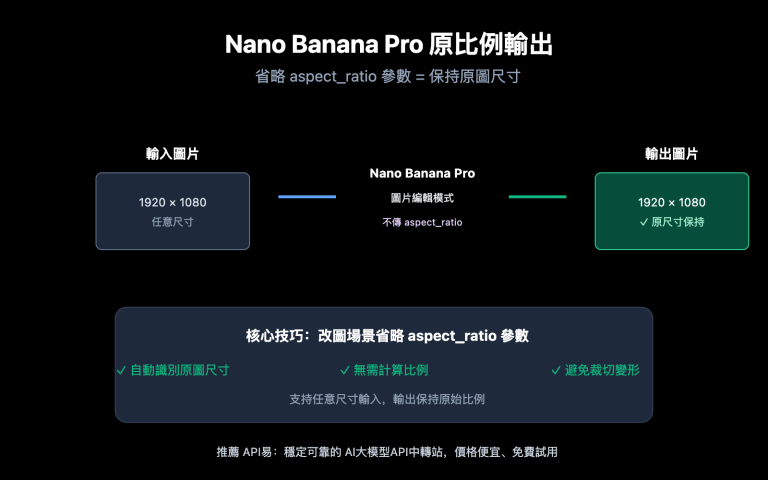
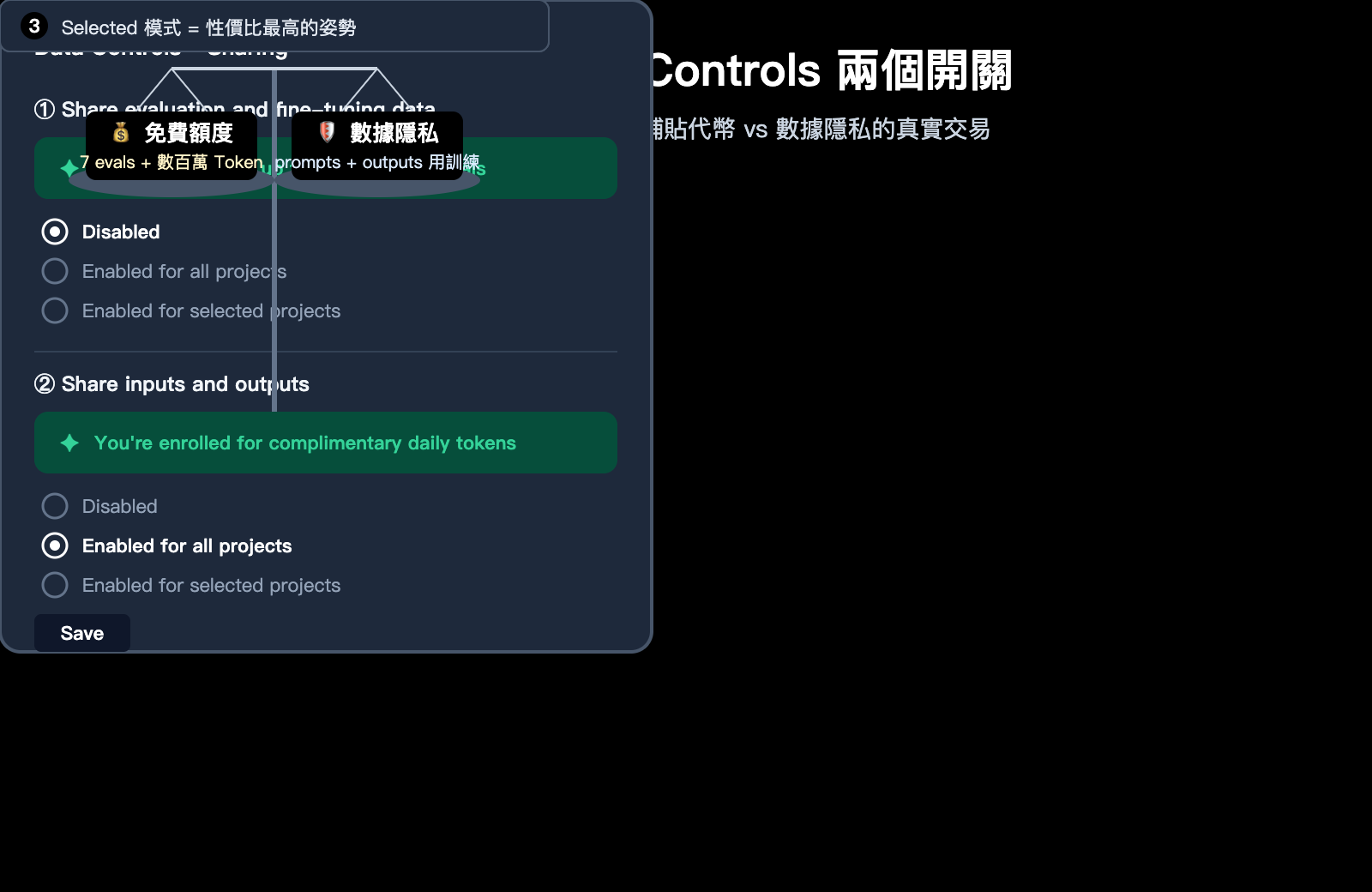
最近有客戶問我們:他點開 OpenAI 後臺的 Data Controls 頁面,看到兩個開關 —— "Share evaluation and fine-tuning data with OpenAI" 和 "Share inputs and outputs with OpenAI",每個都有 Disabled / Enabled for all projects / Enabled for selected projects 三檔可選。第一個上面帶綠色提示 "You're eligible for up to 7 free weekly evals",第二個則寫 "You're enrolled for complimentary daily tokens",看上去都在送資源,但他不確定到底值不值得開,開了之後會有什麼代價。
這兩個開關的本質是 OpenAI 用"免費額度"換"訓練 / 評估數據"的雙向交易,開啓的代價是真實的 —— 評估數據、API 輸入輸出會被 OpenAI 用來改進未來模型。在 API易 apiyi.com 的客戶裏,我們見過有人把它開了半年才發現是個隱私漏洞,也見過把它關了半年才發現自己每天浪費了百萬級的免費 Token 額度。本文用英文官方資料把兩個開關的真實作用、可獲額度、隱私影響、推薦配置一次性講透。
OpenAI Data Controls 兩個設置項的核心定義
打開 Settings → Data Controls → Sharing 這個頁面,你會看到兩個獨立但常被混淆的開關。它們共享內容不同、回報不同、隱私影響也完全不在同一量級,理解它們的邊界是做正確決策的前提。
| 設置項 | Share evaluation and fine-tuning data | Share inputs and outputs |
|---|---|---|
| 共享內容 | 評估提示詞 + 結果 + grading logic + 微調數據 | API 調用的全部輸入和輸出 |
| 免費回報 | 每週最多 7 次免費 eval 運行 | 每日補貼代幣(按 tier 和模型組分配) |
| 數據用途 | 改進評估流水線 + 訓練未來模型 | 直接用於訓練 / 改進模型 |
| 默認狀態 | Disabled | Disabled |
| 開關粒度 | Disabled / All / Selected 三檔 | Disabled / All / Selected 三檔 |
| 操作權限 | 僅 Org Owner | 僅 Org Owner |
| 生效範圍 | 開啓之後產生的數據才共享 | 開啓之後產生的流量才共享 |
| 關閉難度 | 隨時切換 | 隨時切換 |
🎯 快速理解建議: 如果你只是想"安全地拿到免費額度",可以把開關設置成 "Enabled for selected projects",單獨建一個測試項目用來跑 dev / 內部腳本,主項目和生產 API 流量經由 API易 apiyi.com 網關走,避免一次性把所有項目都暴露給數據訓練管道。
Share evaluation and fine-tuning data 設置詳解
這個開關的字面意思是"共享評估和微調數據",但實際共享的範圍比名字暗示的更廣。開啓之後,OpenAI 不僅會拿到你的 eval prompts 和 completions,還會拿到你定義的 grading logic(評判標準)以及 fine-tuning 數據集中的 prompts + completions。這意味着:你怎麼給模型打分、你認爲什麼樣的回答是好的、你訓練數據裏的領域知識,都會被 OpenAI 收集。
回報是每週最多 7 次免費 eval 運行。OpenAI 在幫助中心明確表示,"Evaluations you share with OpenAI are currently processed at no cost for up to 7 runs per week"。超過這個限額或使用不參與免費額度的模型,仍按標準 Token 價計費。這個數字看似不大,但對於經常做模型選型對比的團隊,每週 7 次免費跑可以省下幾十到幾百美元的 eval 成本。
值得注意的是開關只對開啓之後產生的數據生效,歷史數據不會回溯共享,關閉之後也不會"撤回"已共享的數據。所以決策應該基於"未來 6-12 個月你打算共享多少 eval 數據",而不是"我現在已經有什麼數據"。
| 維度 | 開啓的收益 | 開啓的代價 |
|---|---|---|
| 直接收益 | 每週 7 次免費 eval | / |
| 間接收益 | 評估流水線被 OpenAI 優化 | / |
| 數據代價 | / | 評估 prompts、completions、grading 標準被收集 |
| 業務代價 | / | 微調數據集泄露領域 know-how |
| 可逆性 | 可隨時關閉 | 已共享數據不可撤回 |
🎯 何時開啓 Eval/FT 共享: 如果你的 eval 是基於公開 benchmark 或非敏感測試集,開起來基本無害;如果 eval prompts 包含客戶真實數據、內部業務規則、專有 grading 邏輯,建議設成 Selected 模式只對沙盒項目開啓。
Share inputs and outputs 設置詳解
這是兩個開關裏"代價更大、回報也更可觀"的一個。開啓之後,凡是經過這個項目的 API 調用,輸入 prompt 和輸出 completion 都會被 OpenAI 收集並用於訓練或改進模型。這一點和默認 API 行爲有本質區別 —— 默認情況下,OpenAI 自 2023 年 3 月起明確不會用 API 數據訓練模型,開啓這個開關相當於主動撤銷這條保護。
回報是每日補貼代幣(complimentary daily tokens),按賬戶 tier 和模型組階梯發放。這是 OpenAI 公開數據中最具體的免費額度方案,每天 00:00 UTC 自動重置。
| 模型組 | Tier 1-2 每日上限 | Tier 3-5 每日上限 | 重置時間 |
|---|---|---|---|
| 旗艦模型組 | 250,000 tokens | 1,000,000 tokens | 00:00 UTC |
| 小模型組 | 2,500,000 tokens | 10,000,000 tokens | 00:00 UTC |
旗艦模型組和小模型組並不是按性能粗略劃分,而是 OpenAI 明確列出的清單 —— 調用清單外的模型不計入免費額度。
| 模型組 | 包含的具體模型 |
|---|---|
| 旗艦組 | gpt-5, gpt-5-codex, gpt-5-chat-latest, gpt-4.5-preview, gpt-4.1, gpt-4o, o1, o3, o1-preview |
| 小模型組 | gpt-5-mini, gpt-5-nano, gpt-4.1-mini, gpt-4.1-nano, gpt-4o-mini, o1-mini, o4-mini, codex-mini-latest |

🎯 代幣額度的真實價值: 以 gpt-4o-mini 輸入 $0.15/M、輸出 $0.60/M 估算,Tier 1-2 每天 2.5M 小模型 token = 每天約 $1-2 的免費額度,全月可省 $30-60;Tier 3-5 升到每天 10M 小模型 token,全月可省 $120-240。如果只是爲了拿這部分額度,開整個組織流量並不划算,建議起一個獨立測試項目並設成 Selected 模式。
默認 API 隱私 vs 開啓共享後的真實差異
很多團隊對"默認 API 是不是會被訓練"這個問題理解不清。OpenAI 的實際策略是:默認 API 不用於訓練,但保留 30 天用於濫用監控(abuse monitoring)。Zero Data Retention(零數據保留)是另一回事,需要企業客戶單獨聯繫 OpenAI 銷售團隊申請,不是網頁一鍵開關。
理解這條基線之後,再看兩個開關的影響就很清晰:開啓 Inputs/Outputs 是"主動放棄 2023 年起的訓練保護",開啓 Eval/FT 是"在前者之外額外貢獻評估方法論"。兩個都不影響 30 天濫用監控保留,也無法疊加 ZDR。
| 維度 | 默認 API(兩個都關) | 開 Inputs/Outputs | 開 Eval/FT Data |
|---|---|---|---|
| 是否用於訓練 | ❌ 不訓練 | ✅ 用於訓練 | ✅ 用於訓練 + 評估 |
| Abuse 監控保留 | 30 天 | 30 天 | 30 天 |
| 數據可否撤回 | / | ❌ 已共享不可撤回 | ❌ 已共享不可撤回 |
| ZDR 是否兼容 | ✅ 可申請 ZDR | ❌ 與開關互斥 | ❌ 與開關互斥 |
| 適合場景 | 生產 / 合規 / PII | dev / 測試 / 公開數據 | 公開 benchmark eval |
🎯 隱私決策建議: 如果你的業務對數據隱私有任何合規要求(GDPR、HIPAA、企業 NDA、客戶 PII 等),兩個開關都應該保持 Disabled,並且把高敏流量經由 API易 apiyi.com 網關或申請 ZDR;如果只是個人項目、內部工具、Hackathon 演示等公開場景,可以放心 Enabled for all projects。
OpenAI Data Controls 是否值得開啓的 4 項決策框架
直接給"開 / 不開"的二元答案太粗暴。我們用 4 類典型業務場景做矩陣,每一類都有它合理的配置。決策的核心維度是兩個:數據敏感性(你處理的內容是否涉及隱私 / 商業機密)和調用規模(你能從免費額度裏拿回多少實際價值)。
| 業務類型 | 數據敏感性 | 推薦 Inputs/Outputs | 推薦 Eval/FT |
|---|---|---|---|
| 個人開發 / Hackathon | 低 | Enabled for all | Enabled for all |
| 內部 R&D / 模型選型 | 中 | Enabled for selected | Enabled for selected |
| To-C 應用(含 PII) | 高 | Disabled 或 Selected(dev 項目) | Disabled |
| 企業 / 合規場景 | 極高 | Disabled + 走 ZDR | Disabled |
第一類是個人開發或 Hackathon 項目。這種場景下 Token 消耗本來就主要是公開 prompt(如比賽題、Demo 代碼),開啓共享既能拿到每日補貼又不會暴露任何敏感信息,性價比最高。第二類是內部 R&D,建議用 Selected 模式 —— 單獨建一個 "data-share-test" 項目專門跑可共享的實驗,主開發項目保持 Disabled。
第三類是 To-C 應用,往往涉及用戶輸入、對話歷史、個人信息。這種情況兩個開關都建議關掉,免費額度對單用戶量級的應用收益不大,而一旦用戶 PII 被收集進訓練管道很難追溯。第四類是企業或合規場景,比如醫療、金融、政府客戶,應該直接走 ZDR 或者 API易 apiyi.com 這類合規網關,連 30 天 abuse monitoring 都規避掉。

🎯 三檔選項怎麼選: 如果決定開啓某個開關,優先選 "Enabled for selected projects" 而不是 "Enabled for all projects"。這樣可以專門劃一個 "training-eligible" 項目用作 dev / 測試,生產項目繼續保持隔離,未來調整也隻影響那一個項目,遷移成本極低。
OpenAI Data Controls 常見 FAQ
Q1:開啓 Inputs/Outputs 之後,OpenAI 會立刻拿走我所有歷史數據嗎?
不會。兩個開關都明確寫了"Only traffic sent after turning this setting on will be shared" / "Only evaluation and fine-tuning data created after turning this setting on will be shared"。開關只對開啓之後產生的數據生效,歷史數據不會被回溯共享。
Q2:免費 Token 是不是和 Credit Grants 同一回事?
不是同一回事但有關聯。Inputs/Outputs 共享獲得的是"每日代幣池",到 00:00 UTC 自動重置;OpenAI 後臺 Credit Grants 一欄看到的"零碎美分"小額 grants 是這個池子按使用量折算成美元價值的事後記賬,可以理解成同一個項目的兩種展示。
Q3:我開了 Selected 模式只對一個項目共享,主項目流量就完全安全嗎?
完全安全。OpenAI 在 settings 界面可以精確選哪些項目參與共享,未選中的項目流量按默認 API 行爲處理 —— 不訓練、保留 30 天 abuse monitoring。如果對此還有擔憂,可以把主項目流量進一步切到 API易 apiyi.com 這類網關,從架構上徹底隔離。
Q4:Eval/FT 共享的"7 free weekly evals"具體是怎麼計數的?
按"運行次數"計數,不是按 Token 計數。每運行一次 eval(不管處理多少樣本)算一次,每週最多 7 次免費。超出後按 eval 用到的模型走標準 Token 價計費,部分模型不在免費名單內,運行也會按價計費。
Q5:把 Inputs/Outputs 關掉之後,已經被收集的數據能要回來嗎?
不能。OpenAI 政策明確規定已共享數據不可撤回,關閉開關只能阻止未來的數據進入訓練管道。這就是爲什麼我們一直建議生產流量用 API易 apiyi.com 這種網關做"硬隔離" —— 默認就不進 OpenAI 訓練管道,比"事後關掉"更可靠。
OpenAI Data Controls 的 3 條總結
第一,這兩個開關是真正的"雙向交易":用真實可量化的數據(eval 方法論、API 輸入輸出)換可量化的免費額度(每週 7 次 eval、每日數百萬到數千萬 Token)。理解這是交易而非純贈送,決策纔不會跑偏。
第二,默認 API 不訓練但 30 天 abuse 監控仍在。如果業務對隱私有任何合規要求,兩個開關都應該 Disabled,並通過 ZDR 申請或 API易 apiyi.com 這類合規網關進一步收緊。開關只決定"是否額外授權訓練",不決定"是否被監控"。
第三,優先用 Selected 模式做"分項目隔離"。新建一個獨立項目專門承接可共享的 dev / 測試流量,把生產項目和敏感數據完全隔離開。這樣既拿到了免費額度,又不讓任何一條用戶數據流進訓練管道,是性價比最高的姿勢。

如果你正在權衡這兩個開關,最穩妥的姿勢是先按"個人 / 內部 / To-C / 企業"四類對號入座決定檔位,再用 Selected 模式起一個獨立測試項目薅免費額度,主生產流量經由 API易 apiyi.com 網關做架構隔離,這樣既能享受 OpenAI 的免費政策,也保住了用戶數據和業務 know-how 的隱私邊界。
📌 作者:APIYI 技術團隊 — 持續追蹤 OpenAI Data Controls、ZDR、計費策略等關鍵政策變更,爲開發者提供統一計費、隱私可控的多模型 API 網關體驗,瞭解更多請訪問 API易 apiyi.com。