“gemini-3.1-flash-lite-image 到底支不支持推理模式?”是最近在 API 调用群里被问得最多的问题之一。答案是肯定的,而且这不是猜测——我们结合 Google 官方文档,通过 APIYI 网关做了三组对照实验,拿到了真实的 token 消耗和延迟数据。本文将从参数结构、实测数据、计费规则三个角度,把 thinkingLevel 这个开关讲透。
核心价值: 读完本文,你会明确 gemini-3.1-flash-lite-image 的推理模式怎么开、开了之后多花多少 token、以及什么场景值得为这份延迟买单。

gemini-3.1-flash-lite-image 推理模式核心结论
先给结论,再讲细节。Google 官方文档明确写道,借助 gemini-3.1-flash-image 和 gemini-3.1-flash-lite-image,开发者可以控制模型使用的思考量,这意味着 flash-lite 这一档同样内置了推理能力,并非只有旗舰模型才有。但并不是所有图片模型都支持这个参数,下表是三款主流 Gemini 图片模型的支持情况对比。
| 模型 | 是否支持 thinkingLevel | 可调档位 | 默认档位 | 备注 |
|---|---|---|---|---|
| gemini-3.1-flash-image | ✅ 支持 | minimal / high | minimal | 官方文档明确列出 |
| gemini-3.1-flash-lite-image | ✅ 支持 | minimal / high | minimal | 与 flash-image 共用同一套 thinkingConfig |
| gemini-3-pro-image | ⚠️ 参数无效 | 恒定,不可调 | 内部固定 | 传入 high 不报错,但实测无变化 |
需要特别说明的是,thinkingLevel 只有两档可选,不是像文本模型那样支持连续调节的思考预算。官方原文提到“minimal 思考并不代表模型完全不思考”,也就是说即便是默认档位,模型内部也会做一定量的基础推理,只是不会像 high 档那样进行多轮构图校验。
这也是一个值得关注的行业信号。在更早一代的图片生成模型里,无论是 nano banana 还是初版 flash-image,官方接口都没有暴露过思考等级这类参数,模型要么按固定策略出图,要么完全靠提示词工程去补偿构图缺陷。到了 3.1 这一代,Google 把“先规划、再生成”的推理机制开放给了 flash 系列,本质上是把此前只在文本模型里验证过的思考范式,迁移到了图片生成场景。理解这个背景,有助于判断未来其他厂商的图片模型是否也会走上同样的路线。
🎯 Техническая рекомендация: если вы вызываете модели Gemini для изображений через APIYI apiyi.com, сначала запустите бизнес-процесс на стандартном уровне minimal, а потом уже по качеству результата решайте, нужно ли переключаться на high. Платформа даёт единый интерфейс, так что gemini-3.1-flash-image, flash-lite-image и pro-image можно вызывать через один и тот же код, что удобно для A/B-сравнения.
Подробный разбор параметра thinkingLevel и способа вызова
thinkingLevel — это не самостоятельный параметр, а объект thinkingConfig, вложенный в generationConfig, и используется он вместе с includeThoughts. includeThoughts определяет, возвращать ли вызывающей стороне сводку размышлений модели, а thinkingLevel — насколько «сильно» модель будет думать. Это два независимых переключателя, не путайте их.

В таблице ниже собраны тип и диапазон значений двух ключевых полей внутри объекта thinkingConfig.
| Поле | Тип | Возможные значения | Значение по умолчанию | Назначение |
|---|---|---|---|---|
| thinkingLevel | строка-перечисление | minimal / high |
minimal |
Управляет интенсивностью рассуждений модели, работает только в image-моделях серии flash |
| includeThoughts | логическое значение | true / false |
false |
Возвращает ли ответ сводку процесса размышлений, не влияет на биллинг |
При реальном вызове структура для трёх основных языков абсолютно одинаковая: в config просто добавляется объект thinkingConfig. Например, на Python это выглядит так:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Вызов через единый шлюз APIYI
)
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-image",
messages=[{"role": "user", "content": "Нарисуй кота, который пьёт кофе на фоне заснеженных гор"}],
extra_body={
"thinkingConfig": {
"thinkingLevel": "high",
"includeThoughts": True
}
}
)
print(response.choices[0].message.content)
Посмотреть полный пример нативного REST-вызова
{
"contents": [{"parts": [{"text": "Нарисуй кота, который пьёт кофе на фоне заснеженных гор"}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"thinkingConfig": {
"thinkingLevel": "high",
"includeThoughts": true
}
}
}
Структура вызова в JavaScript SDK такая же, просто вместо REST-стиля snake_case используется объект thinkingConfig в camelCase, а остальные имена полей не меняются. Логика вызова в трёх языках по сути не отличается — достаточно запомнить одно правило: thinkingConfig всегда находится только внутри generationConfig.
Есть ещё один момент, на котором часто спотыкаются: значения thinkingLevel чувствительны к регистру и задаются строковым перечислением. В официальных примерах встречались варианты "High" и "high" в разном регистре; на практике оба варианта распознаются шлюзом и работают, но лучше не полагаться на неописанное поведение. В боевом коде лучше везде использовать нижний регистр — "high" и "minimal" — так вы не зависите от возможного ужесточения проверки регистра на стороне upstream.
Совет: через APIYI apiyi.com можно получить бесплатный тестовый лимит и сразу проверить, корректно ли
thinkingConfigпроходит через шлюз. Это обычно проще, чем отдельно получать официальный ключ и отлаживать всё на своей стороне.
Данные APIYI в реальных тестах: как thinkingLevel влияет на token и задержку
Как ни подробно описывай параметры в документации, реальные замеры всё равно нагляднее. Мы взяли один и тот же промпт и на изображении 1K, через шлюз APIYI, отдельно протестировали gemini-3.1-flash-image в режимах minimal и high, а также случай, когда в gemini-3-pro-image принудительно передаётся high.
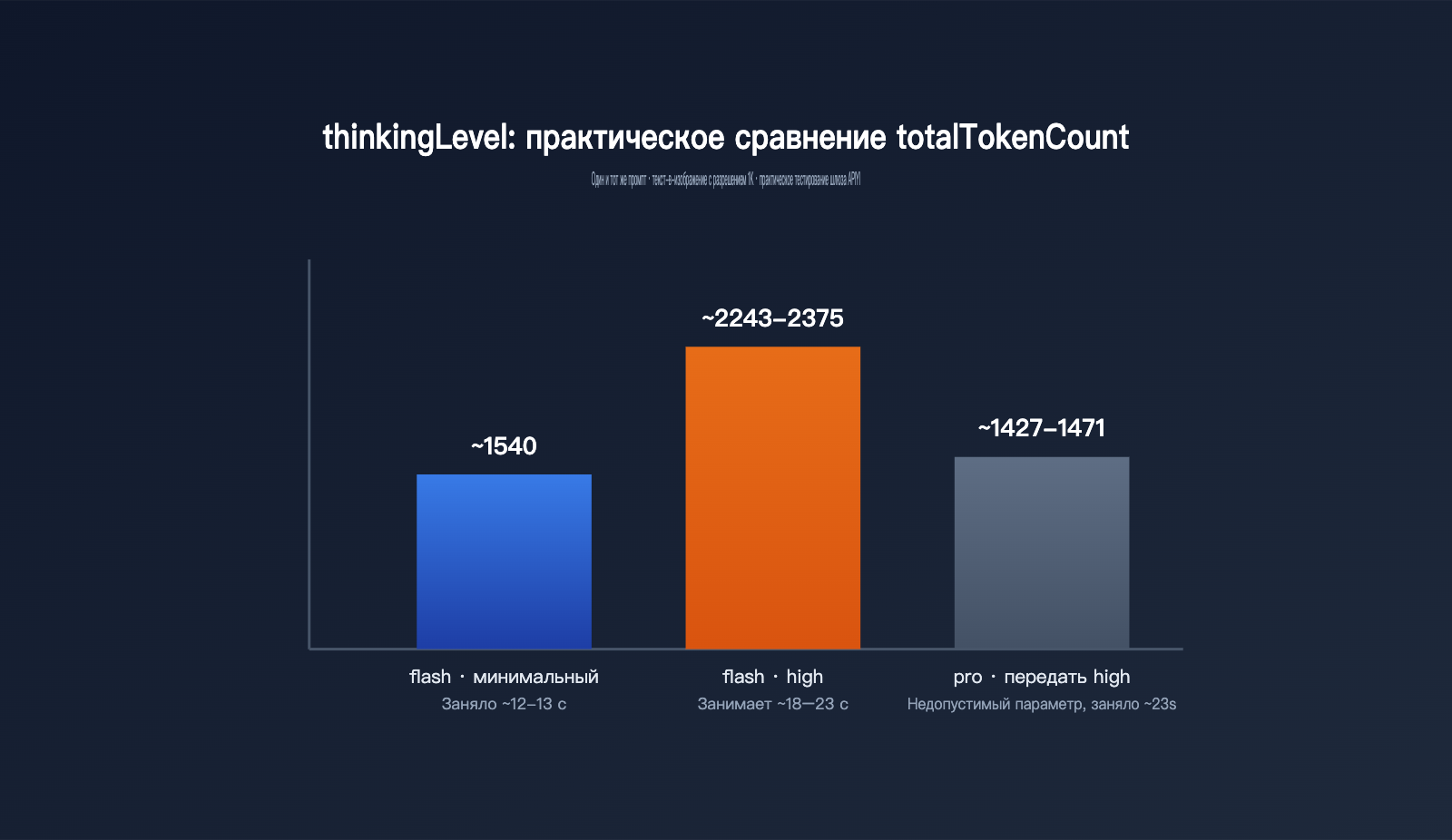
| Модель / настройка | thoughtsTokenCount | image tokens | totalTokenCount | Время |
|---|---|---|---|---|
| gemini-3.1-flash-image · minimal (по умолчанию) | такого поля нет | 1120 | около 1540 | около 12–13 сек. |
| gemini-3.1-flash-image · high | 700–792 | 1120 | около 2243–2375 | около 18–23 сек. |
| gemini-3-pro-image · передан high | 181–214 (как и по умолчанию) | 1120 | около 1427–1471 | около 23 сек. |
Из этих данных видно три важных вещи. Во-первых, когда thinkingLevel переключается на high, thoughtsTokenCount вырастает с нуля по сути до диапазона 700–800; в ответе в режиме по умолчанию этого поля вообще нет. Общий расход токенов увеличивается почти на 50%, а задержка ответа растёт с 12–13 секунд до 18–23 секунд. То есть на «размышления» действительно уходит и время, и деньги.
Во-вторых, независимо от того, minimal это или high, число токенов самой картинки остаётся 1120. Значит, thinkingLevel влияет только на то, как модель «думает», но не меняет ни разрешение изображения, ни его стоимость.
В-третьих, если передать high в gemini-3-pro-image, ошибка не возникнет, но значение thoughtsTokenCount остаётся в диапазоне 181–214 и почти не отличается от режима по умолчанию. Это подтверждает вывод из официальной документации: у pro-image поведение размышлений фиксировано, внешняя настройка на него не влияет.
То есть если в вашей бизнес-логике один и тот же thinkingConfig массово отправляется в flash, flash-lite и pro, то pro-image просто молча проигнорирует этот параметр. Ошибки не будет, но и ожидаемого изменения глубины размышлений тоже не произойдёт.
И ещё один важный нюанс: приведённые выше данные — это не разовый замер. Для каждой настройки один и тот же промпт отправлялся несколько раз, а затем брался диапазон значений. Поэтому у high thoughtsTokenCount и получается таким, 700–792, а не одним фиксированным числом. У задач, связанных с размышлениями, есть определённая доля случайности: промежуточный путь рассуждений каждый раз немного отличается, поэтому и расход токенов чуть плавает. Но общий порядок величин и рост задержки воспроизводятся стабильно. Не бывает такого, чтобы high вдруг оказался быстрее minimal, или чтобы количество токенов размышлений внезапно улетело в несколько тысяч.
Токены для размышлений в image-моделях и правила тарификации
Многие разработчики, впервые увидев поле thoughtsTokenCount, по привычке сравнивают его с затратами на размышления у текстовых моделей. Но у image-моделей механизм размышления на самом деле разбит на две части, и это важно понимать для контроля бюджета.
| Параметр | Размышления текстовой модели | Размышления image-модели |
|---|---|---|
| Форма результата размышлений | Чистая текстовая цепочка рассуждений | Текстовое резюме + максимум две временные наброски компоновки |
| Порядок объёма токенов в тексте размышлений | Может доходить до тысяч | В Pro-версии не больше 400, в Flash high — примерно 700–800 |
| Основное поле, на которое ложится стоимость | thoughtsTokenCount |
Наброски попадают в candidatesTokenCount и тарифицируются как обычный image part |
| Тариф за одну набросанную картинку | Не применимо | Для 1K-разрешения примерно 1120 токенов, около 0.0336 доллара за штуку |
Влияние includeThoughts на стоимость |
Не влияет, тарификация фиксированная | Не влияет, тарификация фиксированная |
В официальной документации отдельно подчёркивается: независимо от того, выставите вы includeThoughts в true или false, токены, потраченные на размышления, всё равно будут тарифицироваться как обычно. Мы это подтвердили и на практике — после включения includeThoughts структура ответа и общая сумма оплаты вообще не меняются, просто в ответе появляется текстовое резюме размышлений для отладки. Иначе говоря, includeThoughts — это переключатель «показывать или не показывать», а не «платить или не платить». Этот нюанс легко неправильно понять.
Ещё важнее другое: основная часть стоимости у image-модели сидит не в поле thoughtsTokenCount, а во временных изображениях компоновки, которые создаются в процессе рассуждения. В документации сказано, что на этапе размышления модель может сгенерировать максимум две временные картинки, чтобы проверить компоновку и логику. Эти наброски возвращаются как обычные image part и учитываются в candidatesTokenCount, то есть оплачиваются по стандартному тарифу для выходных изображений. Получается, что один запуск генерации с high может незаметно добавить одну-две «невидимые» картинки в чек, и при расчёте бюджета это легко упустить.
Если посчитать на пальцах, картина станет понятнее. Допустим, запрос на генерацию изображения в 1K-разрешении идёт в режиме high, текст размышлений расходует около 750 токенов, и модель действительно создаёт две временные наброски. Тогда вместе с финальным изображением получится три image part, а при цене примерно 1120 токенов и 0.0336 доллара за штуку стоимость только на изображения уже приближается к 0.1 доллара. Если добавить сюда ещё и текст размышлений, общий расход может оказаться в 2–3 раза выше, чем в minimal. При этом появятся ли две наброски на самом деле, зависит от того, как модель оценивает ваш промпт, так что high-режим не всегда генерирует полный набор из двух временных картинок. Именно поэтому в реальных тестах общий объём токенов плавает в диапазоне 2243–2375, а не удваивается строго по формуле.
💰 Оптимизация затрат: если ваша команда чувствительна к стоимости токенов, лучше сначала проверить реальный
totalTokenCountв логах вызовов на платформе APIYI apiyi.com, а уже потом решать, стоит ли постоянно держатьhighвключённым. Так вы не упустите расходы на наброски и не выйдете за рамки бюджета.
В каких сценариях выбирать high, а когда достаточно minimal
На основе практических тестов — простая схема принятия решения.

| Бизнес-сценарий | Рекомендуемый режим | Причина |
|---|---|---|
| Массовая генерация маркетинговых картинок, где точность компоновки не критична | minimal (по умолчанию) |
Ниже задержка, стоимость токенов под контролем, для повседневной генерации этого достаточно |
| Сложная компоновка с несколькими объектами, нужен точный текстовый макет или строгие пространственные отношения | high |
Дополнительное размышление повышает точность компоновки, и за качество здесь действительно стоит заплатить |
| Карточки товаров, постеры и другие сценарии, где цена ошибки в деталях высокая | high |
Меньше повторных перерисовок, а в сумме это часто выходит дешевле |
| Реальное интерактивное использование, где критична скорость ответа | minimal |
В high задержка растягивается на 5–10 секунд, для плотного интерактива это уже тяжеловато |
Вызов gemini-3-pro-image |
Не нужно задавать | У этой модели поведение размышления фиксированное, и передаваемый параметр не сработает |
Если коротко, high лучше подходит там, где важнее «попасть с первого раза», чем быстро получить картинку. Если в вашем приложении часто приходится запускать повторные генерации и подбирать промпт, чтобы добиться нужной компоновки, тогда разумнее сразу включить high — пусть отдельный вызов и дороже, зато выше шанс получить хороший результат за одну попытку, а в сумме это обычно выгоднее.
На практике самый надёжный вариант — сделать thinkingLevel настраиваемым параметром, а не жёстко прописывать его в коде. Например, можно автоматически маршрутизировать запросы по типу задачи: для пакетных операций оставлять minimal по умолчанию, а для запросов с точной вёрсткой или несколькими объектами в кадре переключаться на high. Так вы и среднюю стоимость удержите под контролем, и не будете жертвовать качеством в важных кейсах. Если же в команде одновременно используются flash, flash-lite и pro, лучше вынести обработку параметров в единый слой и передавать thinkingLevel только тем моделям, которые его поддерживают, чтобы не прокидывать лишние параметры в pro-image и потом не тратить время на отладку.
🚀 Быстрый старт: для прототипа удобно использовать платформу APIYI apiyi.com. Одна и та же
base_urlпозволяет переключаться междуminimalиhighдля сравнения, без отдельной настройки авторизации под каждый режим.
Часто задаваемые вопросы
Q1: У gemini-3.1-flash-lite-image и gemini-3.1-flash-image одинаковое поведение при выводе?
Обе модели используют одну и ту же структуру параметра thinkingConfig, и поддерживаемые уровни у них тоже одинаковые — minimal и high. Но flash-lite — это облегчённая версия, поэтому в реальности глубина рассуждения и детализация финального изображения обычно слабее, чем у flash-image. Это видно и по названию: серия flash-lite в текстовых моделях всегда означала «быстрее, дешевле, но чуть менее точно», и в изображениях логика компромисса та же. Режим high может частично компенсировать слабые стороны лёгкой модели в сложной композиции, но полностью догнать flash-image всё равно сложно. Если нужен количественный сравнительный тест, можно через платформу APIYI apiyi.com одновременно вызвать обе модели на одном и том же наборе промптов и напрямую сравнить thoughtsTokenCount и результат генерации изображений.
Q2: Если передать в gemini-3-pro-image параметр `thinkingLevel`, будет ошибка?
Ошибки не будет. Наши тесты показали, что при передаче параметра high запрос нормально возвращается, но thoughtsTokenCount остаётся в диапазоне 181–214 и почти не отличается от сценария без параметра. Это значит, что внутреннее поведение рассуждения у этой модели фиксировано и внешней настройке не поддаётся. При пакетном вызове нескольких моделей лучше в бизнес-коде отдельно проверять имя модели, чтобы не думать, что параметр уже сработал.
Q3: Нужно ли после включения режима `high` дополнительно менять разрешение или качество изображения?
Нет, не нужно. По результатам тестов токены изображения в режимах minimal и high стабильно держатся на уровне 1120, а значит thinkingLevel влияет только на внутренний процесс вывода модели и не меняет разрешение итогового изображения. Разрешение по-прежнему отдельно задаётся через параметры размера в imageConfig и не связано с уровнем рассуждения. Проще говоря, thinkingLevel и параметры разрешения — это две независимые ручки: одна отвечает за то, насколько тщательно модель «думает», другая — за то, насколько крупно и детально она «рисует». Их можно свободно комбинировать, без взаимных ограничений.
Итог
gemini-3.1-flash-lite-image действительно поддерживает режим вывода с рассуждением — это подтверждено и официальной документацией, и тестами команды APIYI. У thinkingLevel есть только два варианта — minimal и high; при включении high число токенов рассуждения вырастает до 700+ и общий отклик становится примерно на 5–10 секунд длиннее, но расход токенов на итоговое изображение не меняется. А вот gemini-3-pro-image, хотя и принимает этот параметр без ошибки, фактически его не использует. Понимание логики «текст размышлений идёт в thoughtsTokenCount, а набросок композиции — в candidatesTokenCount» — это ключ к контролю стоимости генерации изображений. Если нужно быстро переключаться между несколькими моделями Gemini Image и проверять их поведение, удобнее всего делать это через единый шлюз APIYI apiyi.com, чтобы не заводить отдельные API-ключи для каждой модели и не поддерживать лишний код вызова.
Данные в статье получены в ходе практических тестов технической команды APIYI. Если хотите обсудить детали вызова моделей Gemini Image, обращайтесь в техническую поддержку APIYI apiyi.com.
Справочные материалы
- Официальная документация Gemini API — генерация изображений: описание параметра уровней размышления (thinking levels)
- Ссылка:
ai.google.dev/gemini-api/docs/generate-content/image-generation
- Ссылка: