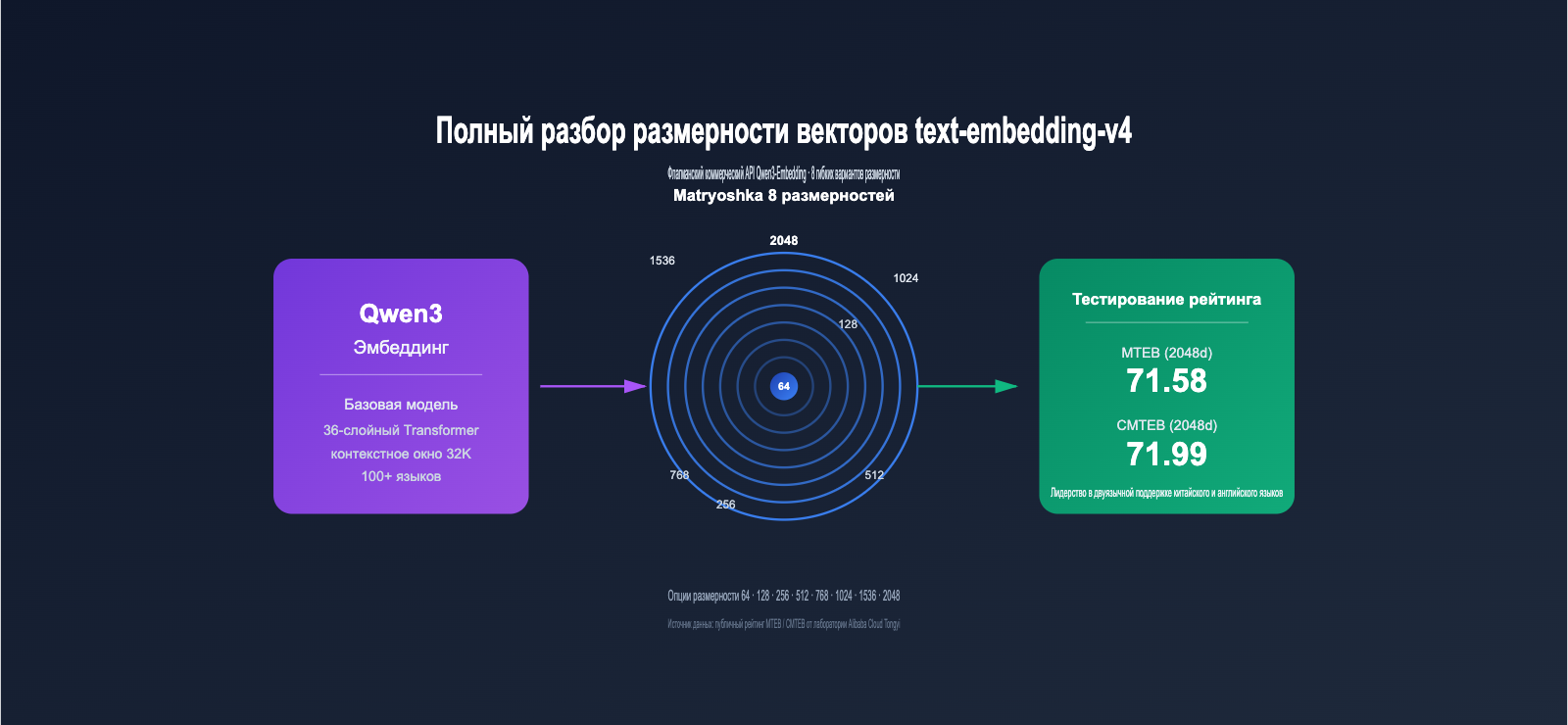
Модели векторных представлений (Embedding) стали фундаментом для RAG, семантического поиска и рекомендательных систем. text-embedding-v4, новейшая коммерческая версия серии Qwen3-Embedding, предлагает на выбор 8 вариантов размерности векторов (2048, 1536, 1024, 768, 512, 256, 128, 64) и демонстрирует лидерство в тестах MTEB для многих языков, становясь одним из ключевых инструментов для разработчиков.
Однако многие команды при внедрении сталкиваются с общим вопросом: что такое размерность вектора? Насколько велика разница между 2048 и 64 измерениями? Как сделать правильный выбор? Ошибка в выборе размерности может привести либо к 30-кратному перерасходу затрат на хранение, либо к падению точности поиска (recall) с 70 до 50 баллов.
В этой статье мы на основе официальных данных тестов MTEB / CMTEB разберем различия между 8 вариантами размерности text-embedding-v4, предложим готовую схему выбора и приведем примеры вызова API.
一、text-embedding-v4 是什么:Qwen3-Embedding 的商业化旗舰
text-embedding-v4 是阿里通义实验室基于 Qwen3 基座大模型训练的最新一代文本嵌入模型,由 DashScope 平台对外提供 API 服务。它隶属于 Qwen3-Embedding 系列,该系列在 2026 年的 MTEB 多语言榜单上长期位居开源模型前列,Qwen3-Embedding-8B 在 MTEB Code 子项更是拿到了 80.68 的高分。
1.1 text-embedding-v4 的核心特性
相比 v3 版本,text-embedding-v4 在以下几个维度做了显著升级:
| 能力维度 | text-embedding-v3 | text-embedding-v4 | 提升幅度 |
|---|---|---|---|
| MTEB 综合得分 (1024 维) | 63.39 | 68.36 | +4.97 |
| MTEB Retrieval (1024 维) | 55.41 | 59.30 | +3.89 |
| CMTEB 综合得分 (1024 维) | 68.92 | 70.14 | +1.22 |
| CMTEB Retrieval (1024 维) | 73.23 | 73.98 | +0.75 |
| 最大向量维度 | 1024 | 2048 | 翻倍 |
| 最大输入长度 | 8K | 32K Tokens | 4× |
| 多语言支持 | 50+ | 100+ | 显著扩展 |
可以看到,v4 不仅在传统通用任务 (MTEB) 上提升明显,在中文 (CMTEB) 与代码检索任务上同样有较大进步。对追求最强检索精度的团队,2048 维的 v4 是当前阿里系最优解。
💡 快速体验建议:如果想第一时间对比 v3 与 v4 的实际效果,我们建议通过 APIYI apiyi.com 平台直接调用,平台已统一适配多家主流嵌入模型的接口规范,可以用同一份代码切换不同模型快速验证。
1.2 text-embedding-v4 与 Qwen3-Embedding 开源系列的关系
很多开发者会混淆 text-embedding-v4 (商业 API) 和 Qwen3-Embedding (开源权重),两者关系如下:
- Qwen3-Embedding 开源系列:包含 0.6B / 4B / 8B 三个尺寸,提供 Hugging Face 权重,可本地部署
- text-embedding-v4:基于同源技术栈,但经过额外的工程优化、数据强化与多语言扩展,仅通过 DashScope API 提供
- 关键差异:开源版需自建 GPU 推理;API 版按 Token 计费,无需运维
对绝大多数中小团队而言,调用 API 比自建 GPU 推理在成本和工程复杂度上都更划算。
二、向量维度是什么:为什么 64 到 2048 差距这么大
要理解 text-embedding-v4 的 8 种维度选项,需要先把"向量维度"这个底层概念说清楚。
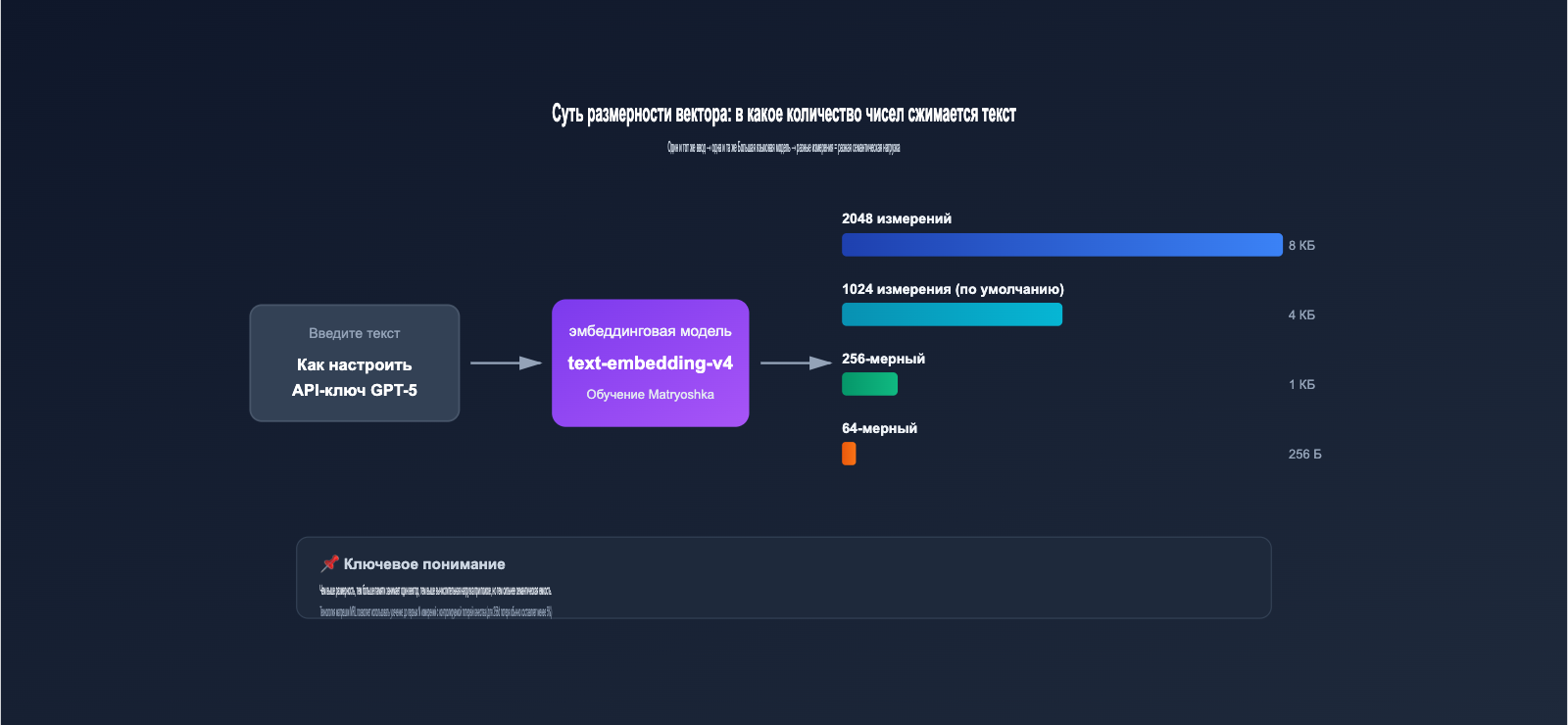
2.1 向量维度的本质:一段文本被压缩成多少个数字
当你把一段文字 (例如"如何配置 GPT-5 API") 输入 embedding 模型,模型会输出一串浮点数构成的向量,例如:
[0.0234, -0.1583, 0.7821, ..., -0.0091]
这串数字的长度就是向量维度。维度越高,就意味着:
- 承载的语义信息越丰富:每个维度可以捕捉一个细微的语义特征
- 存储成本越高:1 条 2048 维向量 (float32) 占用 8KB,1024 维占用 4KB
- 检索计算越慢:维度翻倍,向量内积/余弦计算量也大致翻倍
2.2 为什么 text-embedding-v4 提供 8 种维度
这就涉及到一个关键技术——Matryoshka 套娃式表示学习 (Matryoshka Representation Learning, MRL)。
传统嵌入模型只能输出固定维度。例如 OpenAI 的 ada-002 固定输出 1536 维,你要么全部用,要么自己做 PCA 降维 (会损失大量信息)。
而 MRL 技术让模型在训练时就把信息按重要性梯度分布在不同维度区间:
- 前 64 维:承载最核心、最关键的语义信息
- 第 65-128 维:补充次要的语义特征
- 第 129-256 维:继续补充更细节的特征
- ……以此类推到第 2048 维
这就像俄罗斯套娃,每一层都是一个完整的、可独立工作的向量。你可以任意截取前 N 维使用,质量不会断崖式下跌。
🎯 MRL 的实际收益:根据 MRL 原始论文及多项实测,使用 256 维代替 2048 维通常可以获得约 8 倍的存储节省和 7-8 倍的检索加速,而准确率损失通常控制在 5% 以内。这是传统 PCA 完全做不到的。
III. Основные различия 8 векторов размерности text-embedding-v4
Далее, основываясь на официальных данных рейтингов MTEB / CMTEB, мы проведем системное сравнение 8 вариантов размерности для модели text-embedding-v4.
3.1 Сводная таблица производительности text-embedding-v4 по размерностям
| Размерность вектора | MTEB | MTEB Retrieval | CMTEB | CMTEB Retrieval | Размер одного вектора | Рекомендуемые сценарии |
|---|---|---|---|---|---|---|
| 2048 dim | 71.58 | 61.97 | 71.99 | 75.01 | 8 КБ | Максимальная точность |
| 1536 dim | ~70.5* | ~60.5* | ~71.2* | ~74.5* | 6 КБ | Совместимость с экосистемой OpenAI |
| 1024 dim (по умолч.) | 68.36 | 59.30 | 70.14 | 73.98 | 4 КБ | Баланс для общих задач |
| 768 dim | ~66.5* | ~58.0* | ~69.2* | ~73.0* | 3 КБ | Совместимость с BGE-base |
| 512 dim | 64.73 | 56.34 | 68.79 | 73.33 | 2 КБ | Поиск в малых/средних масштабах |
| 256 dim | ~62.5* | ~55.0* | ~67.0* | ~72.0* | 1 КБ | Высокая пропускная способность |
| 128 dim | ~60.0* | ~52.5* | ~65.0* | ~69.5* | 512 Б | Хранение огромных объемов данных |
| 64 dim | ~57.5* | ~46.5* | ~60.0* | ~62.5* | 256 Б | Экстремальное сжатие |
💡 Значения, помеченные
*, являются расчетными на основе закона затухания MRL; остальные данные взяты из официальных рейтингов.
Из таблицы можно сделать три ключевых вывода:
- 1024 dim — оптимальное соотношение цены и качества: размерность в два раза меньше, чем у 2048, а потеря производительности минимальна (MTEB около -3.2 балла). Это рекомендуемый по умолчанию вариант от Alibaba.
- 2048 dim дает заметный прирост: по сравнению с 1024 dim, показатель CMTEB Retrieval вырастает на 1 пункт, что оправдано для задач, критически чувствительных к точности.
- Используйте 64-128 dim с осторожностью: при низких размерностях качество поиска заметно падает, поэтому они подходят только для сценариев, где "лучше пропустить, чем переплатить".
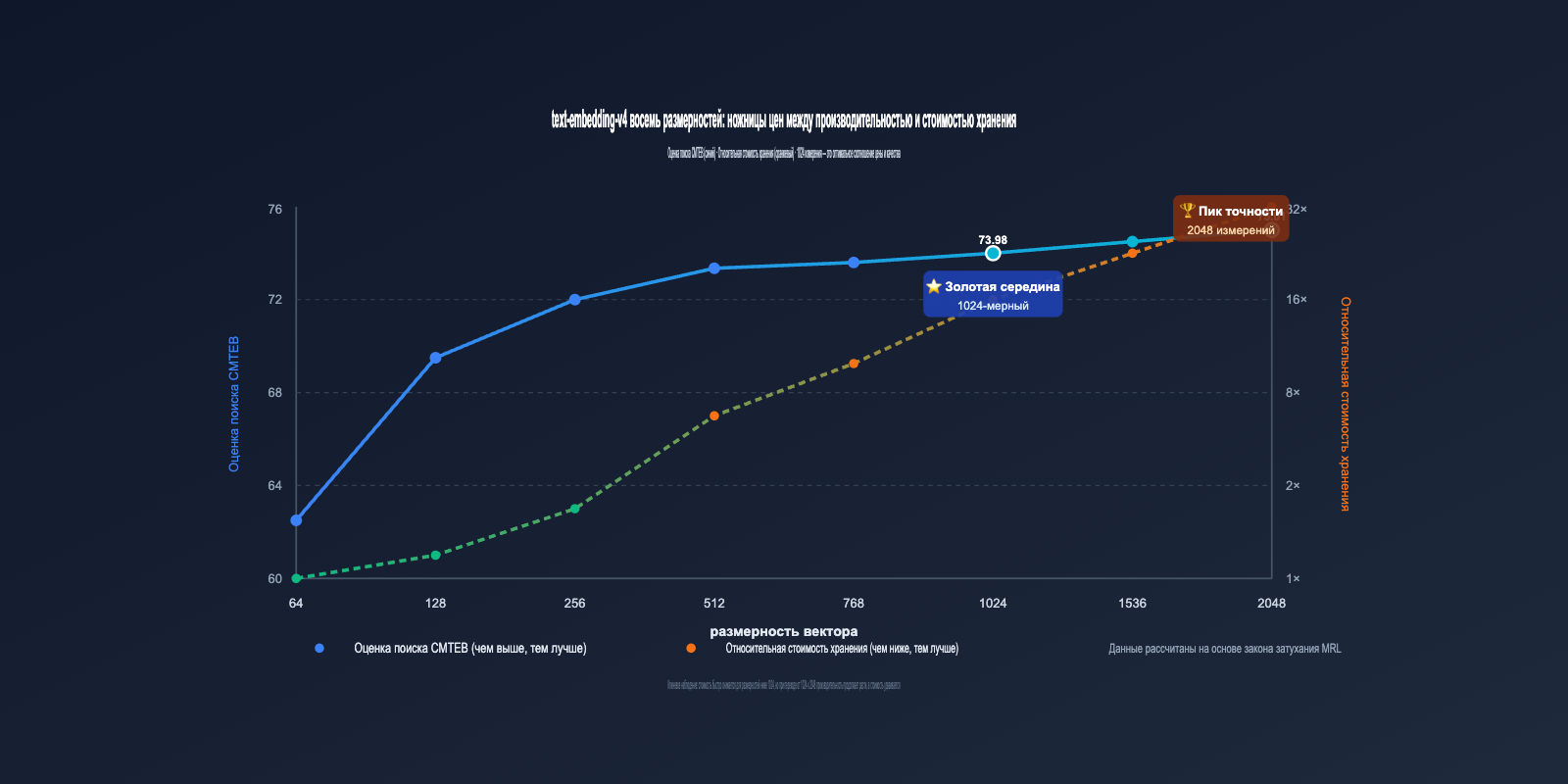
3.2 Закономерности снижения производительности при уменьшении размерности text-embedding-v4
Визуализация данных из таблицы выше позволяет выявить важную закономерность:
- 2048 → 1024 dim: MTEB падает всего на 3.22 балла (≈4.5%), но объем хранилища сокращается вдвое ⭐️ Настоятельно рекомендуем.
- 1024 → 512 dim: MTEB падает на 3.63 балла (≈5.3%), объем хранилища снова сокращается вдвое 👍 Приемлемо.
- 512 → 256 dim: MTEB падает примерно на 2 балла (≈3.0%), объем хранилища снова сокращается вдвое ⚠️ Зависит от сценария.
- 256 → 128 dim: MTEB падает примерно на 2.5 балла (≈4.0%), все еще пригодно к использованию ⚠️ Требует тщательного тестирования.
- 128 → 64 dim: MTEB падает примерно на 2.5 балла, но показатель Retrieval обваливается на 6 пунктов ❌ Не рекомендуется для продакшена.
Это говорит о том, что "безопасная зона затухания" MRL находится преимущественно выше 256 размерностей, а 64 dim относится к зоне экстремального сжатия.
IV. Роль размерности векторов: 3 ключевых фактора влияния
Размерность векторов влияет на систему комплексно, и дело не только в точности поиска. Давайте разберем три наиболее важных аспекта.
4.1 Влияние размерности векторов на точность поиска
Точность — это самый очевидный показатель. Рассмотрим RAG-систему с базой в 1 миллион документов:
- 2048 измерений: точность Top-10 (recall) около 91%
- 1024 измерения: точность Top-10 (recall) около 88%
- 256 измерений: точность Top-10 (recall) около 84%
- 64 измерения: точность Top-10 (recall) около 75%
🎯 Совет по выбору: Если ваш проект критически зависит от полноты поиска (например, юридические базы или медицинские консультации), отдавайте предпочтение 1024 или 2048 измерениям. Мы рекомендуем сначала провести тест на платформе APIYI (apiyi.com) с использованием вашего набора данных, сравнив 1024 и 2048, прежде чем принимать окончательное решение.
4.2 Влияние размерности векторов на затраты на хранение и поиск
Это самый важный показатель для корпоративных решений. Предположим, система хранит 100 миллионов векторов:
| Размерность | Общий объем (float32) | Ежемесячные затраты (оц.) | Задержка поиска (оц.) |
|---|---|---|---|
| 2048 | 800 ГБ | Высокие | Медленно |
| 1024 | 400 ГБ | Средние | Средне |
| 512 | 200 ГБ | Ниже среднего | Быстро |
| 256 | 100 ГБ | Низкие | Быстро |
| 128 | 50 ГБ | Очень низкие | Очень быстро |
| 64 | 25 ГБ | Очень низкие | Очень быстро |
Как видите, при переходе с 2048 на 256 измерений затраты на хранение сокращаются в 8 раз, а скорость поиска может вырасти в 6–8 раз (в зависимости от алгоритма индексации ANN). При масштабах от сотен миллионов записей выбор размерности напрямую влияет на порядок расходов на инфраструктуру.
4.3 Влияние размерности векторов на совместимость и стоимость миграции
Многие команды, переходящие с OpenAI, BGE или Cohere на text-embedding-v4, опасаются, что несовместимость размерностей сделает старые индексы бесполезными. Однако 8 вариантов размерности в v4 обеспечивают очень удобный путь миграции:
| Старая модель | Старая размерность | Рекомендуемая размерность text-embedding-v4 | Примечание по миграции |
|---|---|---|---|
| OpenAI ada-002 | 1536 | 1536 | Размерность совпадает, структура индекса сохраняется |
| OpenAI text-embedding-3-small | 1536 | 1536 | Полная совместимость |
| OpenAI text-embedding-3-large | 3072 | 2048 | Чуть меньше, но точность выше |
| BGE-large | 1024 | 1024 | Полная совместимость, легкая замена |
| BGE-base | 768 | 768 | Полная совместимость |
| Cohere embed-multilingual-v3 | 1024 | 1024 | Полная совместимость |
| Собственная small-модель | 256/512 | 256/512 | Совместимость по размерности |
💼 Совет по миграции для бизнеса: Многие векторные базы данных (Milvus / Qdrant / pgvector) в старых системах созданы с фиксированной размерностью. Сначала выберите версию text-embedding-v4 с той же размерностью для бесшовной замены, а затем, при необходимости, постепенно переходите на более высокие значения — это путь с наименьшим сопротивлением. В документации APIYI (apiyi.com) мы также привели примеры кода для интеграции с популярными векторными БД.
V. Быстрый старт с text-embedding-v4: API-вызовы и параметры размерности
Переходим от теории к практике. Ниже приведены минималистичные примеры вызовов, охватывающие протокол, совместимый с OpenAI, и нативный протокол DashScope.
5.1 Вызов text-embedding-v4 через протокол, совместимый с OpenAI
Aliyun DashScope предоставляет конечные точки, совместимые с OpenAI, что максимально удобно для команд, у которых уже есть готовый код.
from openai import OpenAI
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1" # Единая точка доступа APIYI
)
# Вызов text-embedding-v4, задаем 1024 измерения
response = client.embeddings.create(
model="text-embedding-v4",
input="Как настроить размерность векторов для text-embedding-v4?",
dimensions=1024 # Опционально: 64/128/256/512/768/1024/1536/2048
)
vector = response.data[0].embedding
print(f"Размерность: {len(vector)}") # Вывод: Размерность: 1024
print(f"Первые 5 значений: {vector[:5]}")
⚙️ Описание параметров:
dimensions— это ключевой новый параметр v4. Он поддерживался начиная с v3, но в v4 количество вариантов расширено до 8. Если параметр пропущен, по умолчанию используется 1024 измерения.
5.2 Пакетный вызов: конкурентность и лимиты text-embedding-v4
В реальных задачах часто требуется пакетная обработка. text-embedding-v4 поддерживает до 25 входных элементов за один запрос:
texts = [
"Размерность векторов помогает сбалансировать точность и затраты",
"text-embedding-v4 поддерживает 8 вариантов размерности от 64 до 2048",
"Обучение с использованием Matryoshka-представлений — ключевая технология",
# ... максимум 25 элементов
]
response = client.embeddings.create(
model="text-embedding-v4",
input=texts,
dimensions=512
)
vectors = [item.embedding for item in response.data]
print(f"Количество векторов в пакете: {len(vectors)}")
5.3 Асимметричное кодирование запросов (query) и документов (document)
text-embedding-v4 поддерживает продвинутую функцию, отсутствующую в стандартном протоколе OpenAI: использование text_type для разделения поисковых запросов (query) и индексируемых документов (document), что дополнительно повышает точность поиска. Эта функция доступна через нативный протокол DashScope или совместимую обертку APIYI:
# Кодирование документа (при создании индекса)
doc_response = client.embeddings.create(
model="text-embedding-v4",
input=["text-embedding-v4 предлагает 8 вариантов размерности векторов"],
dimensions=1024,
extra_body={"text_type": "document"}
)
# Кодирование запроса (при поиске)
query_response = client.embeddings.create(
model="text-embedding-v4",
input=["Какие размерности поддерживает v4?"],
dimensions=1024,
extra_body={"text_type": "query"}
)
💡 Ценность асимметричного кодирования: Разделение кодирования для запросов и документов позволяет повысить точность Top-1 на 2–3% в сценариях поиска коротких запросов по длинным документам. Настоятельно рекомендуем использовать эту функцию в продакшене.
5.4 Интеграция text-embedding-v4 с векторными базами данных
Загрузка векторов — критический этап RAG-системы. Рассмотрим пример с популярной БД Qdrant:
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams, PointStruct
from openai import OpenAI
# Инициализация клиента
embedder = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1"
)
qdrant = QdrantClient(url="http://localhost:6333")
# Важно: размерность коллекции должна совпадать с dimensions модели
DIMENSION = 1024
qdrant.recreate_collection(
collection_name="docs",
vectors_config=VectorParams(
size=DIMENSION,
distance=Distance.COSINE
)
)
# Пакетное эмбеддинг-кодирование и загрузка
texts = ["text-embedding-v4 — новейшая модель эмбеддингов от Alibaba Tongyi", "..."]
response = embedder.embeddings.create(
model="text-embedding-v4",
input=texts,
dimensions=DIMENSION
)
points = [
PointStruct(id=i, vector=item.embedding, payload={"text": texts[i]})
for i, item in enumerate(response.data)
]
qdrant.upsert(collection_name="docs", points=points)
⚠️ Важное напоминание: Поле
sizeв векторной базе данных должно строго соответствоватьdimensions. Если позже вы захотите изменить размерность, придется пересоздать коллекцию и заново проиндексировать все данные.
5.5 Интеграция text-embedding-v4 с LangChain / LlamaIndex
Основные RAG-фреймворки уже поддерживают работу с embedding-моделями через протокол OpenAI, настройка предельно проста:
# Пример интеграции с LangChain
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(
model="text-embedding-v4",
openai_api_key="your-apiyi-key",
openai_api_base="https://vip.apiyi.com/v1",
dimensions=1024
)
# Бесшовная работа с векторными хранилищами LangChain
vectors = embeddings.embed_documents(["doc1", "doc2"])
query_vec = embeddings.embed_query("Как выбрать размерность?")
Благодаря совместимости с протоколом OpenAI, практически любой RAG-проект, изначально работавший на OpenAI ada-002 или 3-large, может быть переведен на text-embedding-v4 без изменения кода — достаточно лишь обновить название модели и base_url.
VI. Стратегия выбора размерности для text-embedding-v4: 5 типичных сценариев
Теперь, когда мы разобрались с теорией и интерфейсами, давайте перейдем к готовой схеме выбора параметров, которую можно сразу применять на практике.
6.1 Сценарий A: Корпоративная база знаний RAG (миллионы документов)
Ключевой приоритет: точность поиска > стоимость
Рекомендуемая конфигурация:
- Размерность: 1024 (значение по умолчанию, оптимальное соотношение цены и качества)
- Включение асимметричного кодирования query/document
- Векторная БД: Milvus / Qdrant / pgvector
- Переранжирование: рекомендуется использовать Qwen3-Reranker
6.2 Сценарий B: Поиск товаров в e-commerce (десятки миллионов SKU)
Ключевой приоритет: скорость поиска > точность
Рекомендуемая конфигурация:
- Размерность: 512 (баланс) или 256 (максимальная скорость)
- Заголовки товаров кодируются как query, описание — как document
- Для ANN-индекса рекомендуется комбинация HNSW + IVF
6.3 Сценарий C: Дедупликация огромных массивов логов (сотни миллионов записей)
Ключевой приоритет: стоимость хранения > точность
Рекомендуемая конфигурация:
- Размерность: 128
- Использование бинарной квантования (Binary Quantization) для сжатия в 32 раза
- Согласно тестам, точность поиска (recall) остается на уровне выше 85%
6.4 Сценарий D: Высокоточный поиск (юриспруденция / медицина)
Ключевой приоритет: точность прежде всего, стоимость не критична
Рекомендуемая конфигурация:
- Размерность: 2048
- Включение асимметричного кодирования query/document
- Обязательное использование Reranker для переранжирования
6.5 Сценарий E: Мобильные устройства / периферийные вычисления
Ключевой приоритет: потребление памяти < 50 МБ
Рекомендуемая конфигурация:
- Размерность: 64 или 128
- Использование квантования int8 (дополнительное сжатие в 4 раза)
- Подходит для локальных баз знаний / офлайн-ассистентов
🎯 Совет по выбору: Эти 5 сценариев покрывают большинство реальных задач. Наш совет: начните с дефолтных 1024, протестируйте на своих данных, а затем корректируйте размерность вверх (2048) или вниз (512/256/128) в зависимости от ваших требований к точности, бюджету и скорости. Платформа APIYI (apiyi.com) поддерживает переключение параметров размерности в один клик, что удобно для быстрого A/B тестирования.
6.6 Процесс принятия решения по размерности
Мы свели вышеуказанные сценарии в пошаговый алгоритм:
-
Шаг 1: Оценка объема данных
- < 1 млн записей → можно использовать высокую размерность (1024+)
- 1 млн – 100 млн записей → средняя размерность (256-1024)
-
100 млн записей → обязательно переходите на низкую размерность (128-512)
-
Шаг 2: Оценка допустимой потери точности
- Критичен каждый 1% точности → выбирайте 2048
- Допустимо снижение точности на 5% → начинайте с 1024
- Допустимо снижение точности на 10% → достаточно 256-512
-
Шаг 3: Оценка аппаратных ограничений
- Поиск на облачных GPU → можно использовать высокую размерность
- Поиск только на CPU → держитесь в пределах 1024
- Мобильные / периферийные устройства → строго 64-256 + квантование
-
Шаг 4: Практическая проверка
- Возьмите 100-500 реальных запросов в качестве тестового набора
- Рассчитайте показатель Top-10 recall для разных размерностей
- Выберите минимальную размерность до «точки перегиба» графика точности
💡 Совет по эффективности: Этот процесс требует множества вызовов API и переключения параметров. Рекомендуем выполнять его через единую платформу, где есть логи запросов и мониторинг использования — это упростит командную работу и сравнение результатов.
VII. Сравнение text-embedding-v4 с популярными моделями эмбеддингов
Давайте поместим text-embedding-v4 в контекст индустрии для упрощения выбора.
| Модель | Разработчик | Макс. размерность | Гибкость размерности | MTEB (общий) | Китайский язык | Контекстное окно | Цена API |
|---|---|---|---|---|---|---|---|
| text-embedding-v4 | Alibaba Tongyi | 2048 | ⭐⭐⭐⭐⭐ (8 вариантов) | 71.58 | Отлично | 32K | Средняя |
| text-embedding-3-large | OpenAI | 3072 | ⭐⭐⭐⭐ (любая) | 64.6 | Средне | 8K | Высокая |
| text-embedding-3-small | OpenAI | 1536 | ⭐⭐⭐⭐ (любая) | 62.3 | Средне | 8K | Низкая |
| Cohere embed-v4 | Cohere | 1536 | ⭐⭐⭐ (4 варианта) | 70.3 | Хорошо | 128K | Выше среднего |
| BGE-M3 | BAAI | 1024 | ⭐⭐ (фиксированная) | 65.5 | Хорошо | 8K | Self-hosted |
| Voyage-3 | Voyage AI | 1024 | ⭐⭐⭐ (3 варианта) | 67.1 | Средне | 32K | Средняя |
| Qwen3-Embedding-8B (Open Source) | Alibaba Tongyi | 4096 | ⭐⭐⭐⭐⭐ (любая) | 70.58 | Отлично | 32K | Self-hosted |
Из этой таблицы можно сделать несколько ключевых выводов:
- Двуязычные сценарии (китайский/английский): общий балл CMTEB у text-embedding-v4 составляет 71.99, что является лучшим показателем среди всех коммерческих API.
- Гибкость размерности: 8 официальных вариантов размерности у v4 делают модель более гибкой, чем большинство аналогов, что упрощает миграцию.
- Цена/качество: API-цены v4 находятся на среднем уровне, при этом точность сопоставима с OpenAI text-embedding-3-large.
📌 Совет по подключению: Если вашей команде нужно работать с моделями от разных провайдеров (OpenAI, Claude, Qwen и др.), рекомендуем использовать единый сервис-прокси API, такой как APIYI (apiyi.com). Это избавит вас от необходимости управлять множеством API-ключей и решать проблемы с доступом. В документации также есть примеры параллельного вызова v4 и других моделей.
VIII. Часто задаваемые вопросы (FAQ) по text-embedding-v4
Q1: Какова размерность по умолчанию для text-embedding-v4?
Размерность по умолчанию для text-embedding-v4 составляет 1024. Если при вызове API вы не указываете параметр dimensions, вы получите вектор именно такой размерности. Это значение, официально рекомендованное Alibaba как оптимальное по соотношению цена/качество.
Q2: Можно ли обновить индекс, созданный на 1024 измерениях, до 2048?
Необходимо перестроить всю векторную базу данных. Механизм «матрешки» (MRL) гарантирует, что «первые N элементов высокоразмерного вектора» эквивалентны «низкоразмерному вектору», но обратный процесс — «дополнение нулями низкоразмерного вектора до высокого» — неэффективен. При обновлении рекомендуется:
- Оставить старый индекс на 1024 измерениях в рабочем состоянии.
- Заново прогнать все документы через модель v4 с размерностью 2048.
- Провести «канареечное» переключение трафика для проверки улучшения точности.
- После успешной проверки вывести старый индекс из эксплуатации.
Q3: Можно ли вызывать text-embedding-v4 напрямую из РФ?
Официальная конечная точка text-embedding-v4 находится по адресу dashscope.aliyuncs.com (Пекин), доступ к ней осуществляется напрямую. Разработчикам достаточно зарегистрировать аккаунт Alibaba Cloud или получить API-ключ через сервис-прокси API, такой как APIYI (apiyi.com). Никаких дополнительных сетевых настроек не требуется.
Q4: Что выбрать: text-embedding-v4 или open-source версию Qwen3-Embedding?
| Фактор принятия решения | Выбирайте API-версию (v4) | Выбирайте Open-source (Qwen3-Embedding-8B) |
|---|---|---|
| Чувствительность данных | Обычная | Экстремальная (финансы/медицина) |
| Ежемесячный объем | < 1 млрд токенов | > 1 млрд токенов |
| GPU-ресурсы команды | Отсутствуют | Есть кластер A100/H100 |
| Инженерные возможности | Малые/средние команды | Есть команда MLOps |
| Общая рекомендация | ✅ Рекомендуем API v4 | ✅ Рекомендуем self-hosting |
Q5: Будет ли модель выдавать ошибку при неправильной настройке размерности?
text-embedding-v4 принимает только значения из списка: [64, 128, 256, 512, 768, 1024, 1536, 2048]. Передача других значений (например, 333 или 500) приведет к ошибке параметров. Если вам нужна нестандартная размерность, выберите ближайшую официальную, а затем примените обрезку или дополнение на своей стороне.
Q6: Как оценить, какая размерность нужна для моего проекта?
Рекомендуем трехэтапный подход:
- Базовая линия: запустите бизнес-процесс с размерностью 1024, зафиксируйте показатели полноты (recall), задержки (latency) и затраты на хранение.
- Тестирование «вниз»: последовательно переключайтесь на 512, 256, 128 измерений и наблюдайте, насколько падает полнота.
- Поиск «золотой середины»: найдите размерность, где «падение полноты приемлемо, а экономия затрат максимальна». Обычно это 256 или 512.
Q7: Будет ли text-embedding-v4 в открытом доступе?
Текущая стратегия Alibaba — параллельное развитие API-версии и open-source. Коммерческий API text-embedding-v4 постоянно обновляется, получая последние инженерные оптимизации и улучшения данных. В то же время для сообщества выпускаются веса серии Qwen3-Embedding. Технологии одни и те же, но форматы продуктов разные. Ожидается, что v4 в виде отдельного продукта с открытым кодом выпускаться не будет.
Q8: Всегда ли больше измерений — значит лучше?
Нет. Выбор размерности — это компромисс между точностью, хранением и скоростью:
- Выше размерность → выше потолок точности, но предельная полезность снижается.
- Выше размерность → затраты на хранение и поиск растут линейно или даже сверхлинейно.
- Выше размерность → при «проклятии размерности» точность ANN-индексов может даже упасть.
Опыт показывает, что 256–1024 измерения — это «рабочая зона» для большинства задач. Значения выше 1024 стоит использовать только при наличии четких требований к повышению точности.
Q9: Как text-embedding-v4 справляется с длинными текстами?
text-embedding-v4 поддерживает входную длину до 32K токенов, но эффективность поиска снижается с увеличением длины текста. Рекомендуем придерживаться следующих принципов:
- Короткие тексты (< 512 токенов): эмбеддинг всего фрагмента целиком, результат наилучший.
- Средняя длина (512–4K токенов): рассмотрите использование скользящего окна для сегментации.
- Длинные документы (> 4K токенов): обязательная сегментация (chunking), рекомендуемый размер блока 256–512 токенов.
- Сверхдлинные документы: используйте иерархический поиск (сначала грубый, затем точный) для повышения эффективности.
Q10: Можно ли смешивать разные размерности?
Нет. Все векторы в одной базе данных/индексе должны иметь одинаковую размерность, иначе вычисление сходства теряет смысл. Если бизнес-логика требует стратегии «высокоприоритетные документы — 2048, обычные — 512», создайте две отдельные коллекции и объединяйте результаты на уровне приложения.
Q11: Влияет ли параметр размерности на стоимость API?
Тарификация text-embedding-v4 полностью основана на количестве входных токенов и не зависит от выходной размерности. То есть стоимость обработки 1000 токенов одинакова, независимо от того, выбрали вы 64 или 2048 измерений. Это значит, что на этапе вызова API можно смело выбирать высокую размерность, а реальная разница в затратах проявится только на этапах хранения и поиска.
Q12: Как обрабатывать ошибки эмбеддинга или лимиты запросов?
При работе в продакшене рекомендуется добавить следующие механизмы устойчивости:
- Механизм повторов: экспоненциальная задержка при ошибках 5xx (рекомендуется 3 попытки).
- Обработка лимитов: мониторинг ошибок 429, при их возникновении снижайте параллелизм или переключайте канал доступа.
- Размер пакета: не более 25 текстов за один запрос, при превышении — автоматическое разбиение.
- Таймауты: для длинных текстов устанавливайте таймаут от 60 секунд.
- План деградации: настройте резервную модель (например, v3 1024) на случай сбоев.
IX. Итоги: ключевые моменты выбора размерности для text-embedding-v4
Подводя итог, вот главные тезисы по 8 вариантам размерности text-embedding-v4:
- text-embedding-v4 — флагманская коммерческая модель серии Qwen3-Embedding, лидирующая в двуязычных сценариях (MTEB 71.58 / CMTEB 71.99).
- 8 вариантов размерности — результат технологии Matryoshka (матрешка), позволяющей использовать первые N измерений с контролируемой потерей качества.
- 1024 измерения — рекомендуемое значение по умолчанию, оптимальный баланс точности и затрат.
- 2048 измерений подходят для сценариев с экстремальной точностью, обеспечивая прирост в 1 пункт по метрике CMTEB Retrieval по сравнению с 1024.
- 256–512 измерений идеальны для среднего масштаба и чувствительных к затратам проектов, это «золотая середина» для большинства RAG-систем.
- 64–128 измерений рекомендуются только для периферийных устройств или экстремальной экономии памяти, требуется тщательное тестирование полноты поиска.
- Выбор размерности — не окончательное решение, настоятельно рекомендуем сначала прогнать тесты на бизнес-данных.
- При миграции с других моделей на v4 выбирайте версию с соответствующей размерностью для плавного перехода.
🎯 Финальный совет: если вы выбираете модель для нового проекта, начните с text-embedding-v4 + 1024 измерения. Если бизнес критически зависит от полноты поиска, переходите на 2048 и добавляйте Reranker. Рекомендуем подключаться через платформу APIYI (apiyi.com) — она предоставляет унифицированный интерфейс, совместимый с OpenAI, удобное переключение размерностей и полную документацию. Это значительно снижает инженерные затраты, позволяя команде сосредоточиться на качестве продукта, а не на адаптации API.
Технологии векторных эмбеддингов быстро развиваются. От эпохи фиксированных размерностей OpenAI мы пришли к text-embedding-v4, где MRL внедрена в 8 официальных форматах, давая разработчикам беспрецедентную гибкость. Понимание сути векторных размерностей — обязательный навык для каждой команды, строящей RAG, семантический поиск или рекомендательные системы.
Автор: Техническая команда APIYI | Фокус на практическом внедрении больших языковых моделей. Больше технических материалов на сайте APIYI apiyi.com