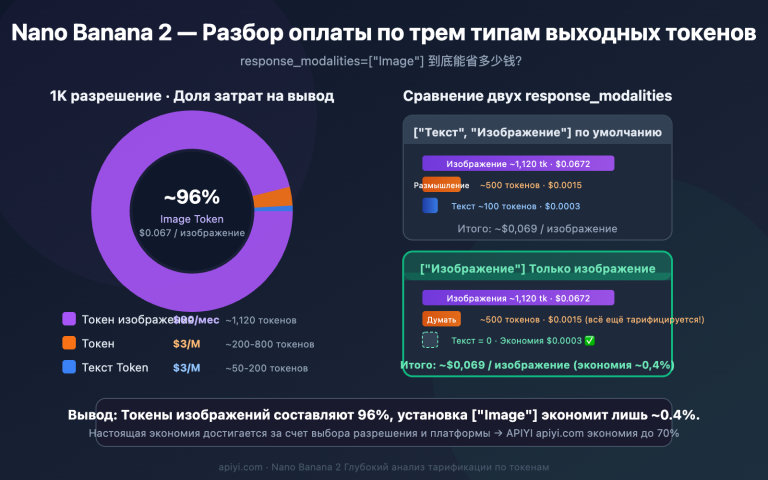
Авторская заметка: глубокий разбор структуры полей, формирования массива contents, механизма thoughtSignature и практического кода для API многораундовой генерации изображений Nano Banana Pro (gemini-3-pro-image-preview).
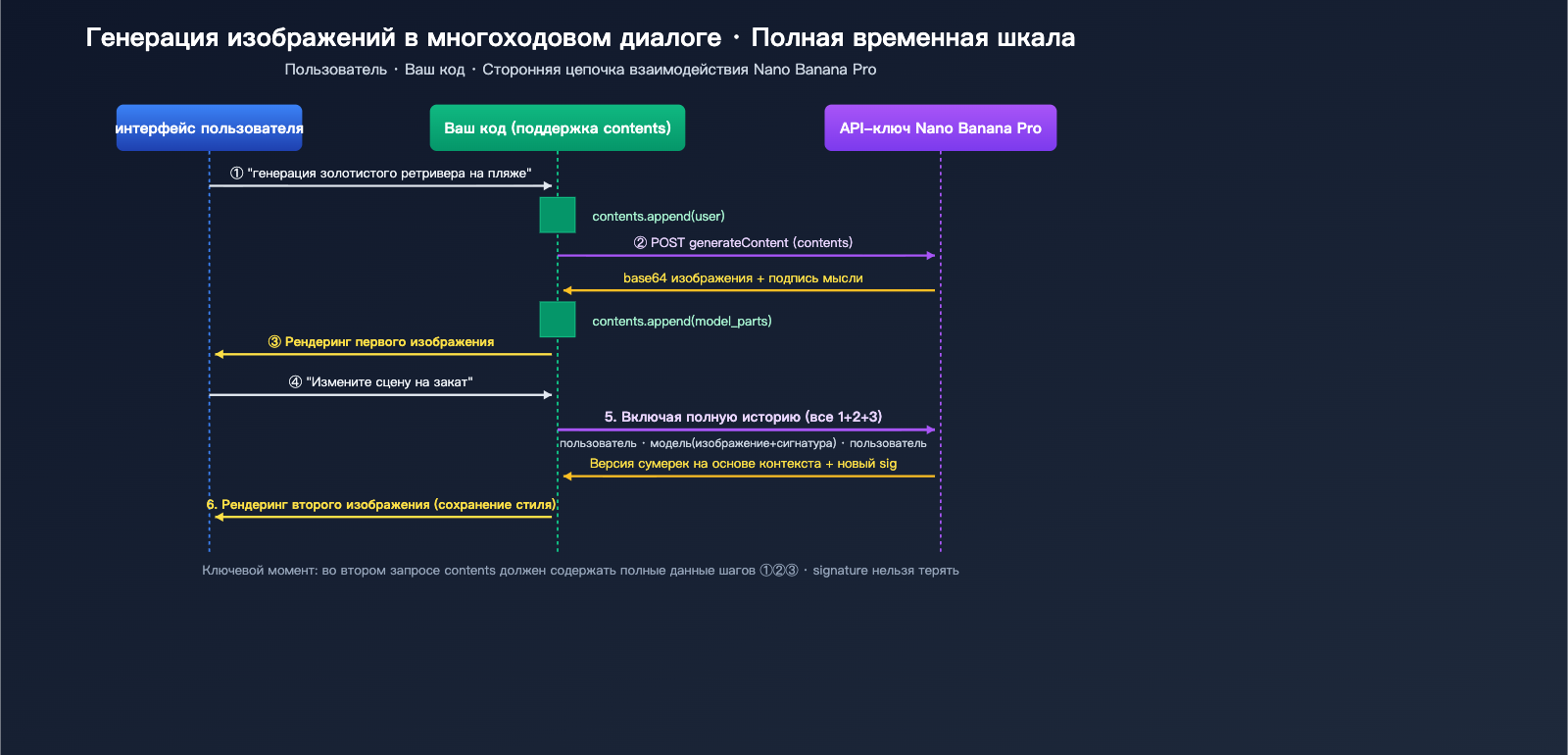
Многие разработчики при первом подключении к Nano Banana Pro сталкиваются с одной и той же проблемой: в веб-интерфейсе gemini.google.com можно последовательно уточнять запрос («поменяй фон на закат», «добавь кота»), и модель идеально «помнит» предыдущее изображение. Однако при вызове официального API модель словно теряет память. Причина в том, что Gemini API по своей сути не имеет состояния (stateless), поэтому многораундовый контекст должен вручную формироваться на стороне вызывающего приложения. В этой статье мы подробно разберем поля API для многораундовой генерации Nano Banana Pro, реализацию на Python SDK и REST, а также критически важный механизм thoughtSignature, который поможет вам за 3 шага создать такой же плавный процесс генерации, как в веб-версии.
Ценность материала: после прочтения вы освоите правильное построение массива contents, сможете реализовать рабочий процесс «редактирования на основе предыдущего изображения» в своих приложениях и избежите трех типичных ошибок: «забывание изображения», «пустая трата токенов» и «потеря сигнатуры».

Основные моменты многораундовой генерации в Nano Banana Pro
| Пункт | Описание | Ценность |
|---|---|---|
| API без состояния | Интерфейс gemini-3-pro-image-preview не хранит историю |
Контекст диалога должен поддерживаться вызывающей стороной |
| Массив contents | Чередование ролей user/model, каждый запрос несет полную историю | Один запрос позволяет модели «видеть» прошлый диалог |
| Передача изображений | Ранее сгенерированные изображения должны передаваться обратно в contents через inline_data |
Модель редактирует изображение, а не создает его заново |
| thoughtSignature | Зашифрованная сигнатура размышлений, сохраняющая контекст вывода | Ключевые инструкции по редактированию не будут забыты |
| Автоматизация SDK | Объект chat в официальном Python SDK автоматически управляет историей |
Экономит до 80% кода при миграции с REST |
Фундаментальное различие между многораундовой генерацией и веб-агентом
gemini.google.com — это агентское приложение, созданное Google. На фронтенде оно поддерживает полное «состояние диалога» (включая текст каждого раунда, сгенерированные изображения и сигнатуры размышлений). Каждый раз, когда вы отправляете новое сообщение, агент упаковывает всю историю и отправляет её базовой модели. Именно поэтому веб-интерфейс работает так плавно — вся работа по «памяти» ложится на плечи агента.
Когда же вы вызываете generateContent API напрямую, вы получаете «голый» интерфейс вызова модели. Каждый HTTP-запрос — это независимый вывод, и модель ничего не знает о предыдущем диалоге. Чтобы воспроизвести опыт веб-версии, вам нужно самостоятельно реализовать агента в своем коде: правильно заполнить contents историей сообщений пользователя и ответами модели (включая изображения и сигнатуры), а затем отправить запрос.
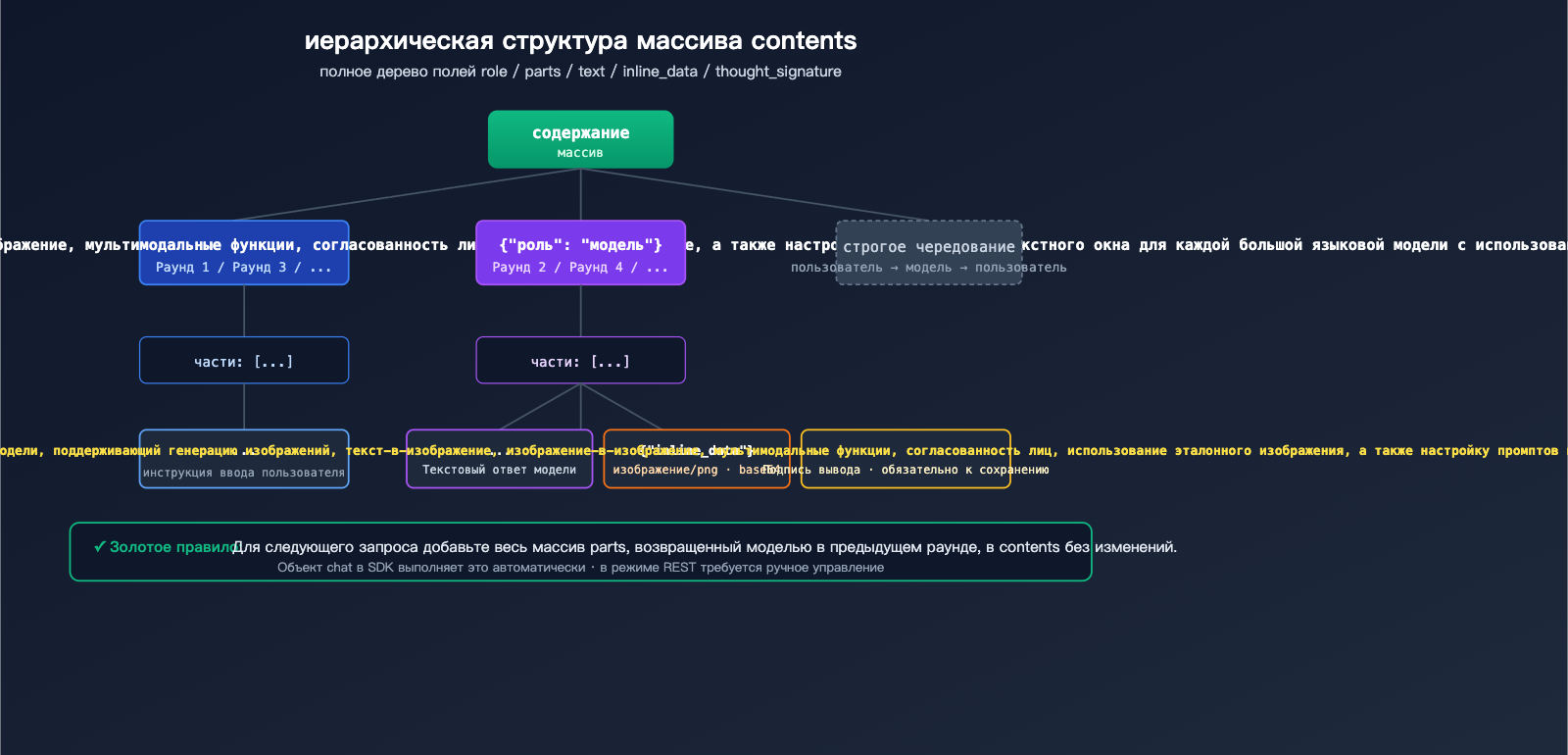
Подробный разбор структуры полей для многоходовой генерации изображений в Nano Banana Pro
Основные спецификации массива contents
contents — это стандартное поле Gemini API для представления истории диалога. Оно представляет собой JSON-массив, где каждый элемент соответствует одной реплике:
| Поле | Тип | Описание |
|---|---|---|
role |
string | "user" или "model", должны строго чередоваться |
parts |
array | Фрагменты содержимого реплики (могут сочетать текст/изображения/подписи) |
parts[].text |
string | Текстовое содержимое, например, промпт или диалог |
parts[].inline_data.mime_type |
string | Формат изображения, обычно "image/png" |
parts[].inline_data.data |
string | Данные изображения в кодировке base64 |
parts[].thought_signature |
string | Криптографическая подпись, сгенерированная моделью (появляется только в роли model) |
Пример тела запроса для полноценного диалога из двух шагов:
{
"contents": [
{"role": "user", "parts": [{"text": "Сгенерируй золотистого ретривера, бегущего по пляжу"}]},
{"role": "model", "parts": [
{"inline_data": {"mime_type": "image/png", "data": "<base64 первой сгенерированной картинки>"}},
{"thought_signature": "<криптографическая подпись>"}
]},
{"role": "user", "parts": [{"text": "Измени сцену на закат"}]}
],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"],
"imageConfig": {"aspectRatio": "16:9", "imageSize": "2K"}
}
}
Два способа передачи изображений
Во втором запросе модель должна «видеть» изображение, созданное на первом этапе. Nano Banana Pro поддерживает два способа передачи:
# Способ 1: inline_data с вложенным base64 (подходит для небольших изображений, просто и быстро)
{
"inline_data": {
"mime_type": "image/png",
"data": base64.b64encode(image_bytes).decode()
}
}
# Способ 2: file_data с ссылкой на ресурс, загруженный через Files API (подходит для больших изображений или повторного использования)
{
"file_data": {
"mime_type": "image/png",
"file_uri": "files/abc123xyz"
}
}
Важный совет:
inline_data— самый простой способ для разовых задач. Режимfile_dataлучше использовать, если нужно многократно обращаться к одному и тому же «тяжелому» изображению — это значительно уменьшает размер запроса и расходы на передачу данных.
Быстрый старт: многоходовая генерация в Nano Banana Pro
Минималистичный пример (автоматическое управление через Python SDK)
Если вы используете официальный Python SDK, для реализации потребуется всего 10 строк кода:
from google import genai
client = genai.Client(api_key="YOUR_API_KEY")
chat = client.chats.create(model="gemini-3-pro-image-preview")
# Шаг 1: Генерация начального изображения
r1 = chat.send_message("Сгенерируй золотистого ретривера, бегущего по пляжу")
# Шаг 2: Редактирование на основе первого изображения (объект chat автоматически хранит историю)
r2 = chat.send_message("Измени сцену на закат и добавь летящую чайку")
# Шаг 3: Дальнейшее редактирование
r3 = chat.send_message("А теперь сделай собаку темно-коричневой")
Объект chat внутри себя поддерживает полный список contents (включая thoughtSignature для каждого шага), поэтому разработчику не нужно вникать в детали структуры полей. Каждый вызов send_message автоматически упаковывает и отправляет историю диалога.
Посмотреть полный пример вызова через совместимый с OpenAI интерфейс
Если вы используете платформы вроде APIYI (apiyi.com), поддерживающие API, совместимый с OpenAI, можно использовать стандартный OpenAI SDK:
import openai
import base64
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Ведем локальный список messages (аналог contents)
messages = [
{"role": "user", "content": "Сгенерируй золотистого ретривера, бегущего по пляжу"}
]
# Шаг 1
response1 = client.chat.completions.create(
model="gemini-3-pro-image-preview",
messages=messages
)
img1_url = response1.choices[0].message.content # Извлекаем URL или base64 картинки
# Добавляем ответ модели в историю
messages.append({"role": "assistant", "content": img1_url})
# Шаг 2: Добавляем новую инструкцию
messages.append({"role": "user", "content": "Измени сцену на закат"})
response2 = client.chat.completions.create(
model="gemini-3-pro-image-preview",
messages=messages
)
# Продолжаем на шаге 3...
messages.append({"role": "assistant", "content": response2.choices[0].message.content})
messages.append({"role": "user", "content": "Добавь летящую чайку"})
response3 = client.chat.completions.create(
model="gemini-3-pro-image-preview",
messages=messages
)
Ключевой момент: в режиме совместимости с OpenAI массив messages эквивалентен нативному contents, а роль "model" меняется на "assistant" — платформа выполнит преобразование автоматически.
Рекомендация: Для сценариев многоходового редактирования лучше использовать объект
chatиз SDK или вести локальный списокmessages, чтобы не собиратьcontentsвручную. Вы можете зарегистрироваться на APIYI (apiyi.com) для получения бесплатных лимитов, чтобы сначала протестировать работу через SDK, а затем переходить к оптимизации REST-запросов.
Ручная настройка REST-запросов для многоходового диалога с генерацией изображений в Nano Banana Pro
Реализация через чистый REST без использования SDK
В некоторых сценариях (например, при работе через сервис-прокси API, узлы ComfyUI или low-code платформы) использование официального SDK невозможно, поэтому приходится формировать REST-запросы вручную. Ниже приведен полный пример вызова через curl:
# Первый этап: генерация изображения по текстовому запросу
curl -X POST \
"https://vip.apiyi.com/v1beta/models/gemini-3-pro-image-preview:generateContent" \
-H "x-goog-api-key: YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [
{"role": "user", "parts": [{"text": "Нарисуй золотистого ретривера, бегущего по пляжу"}]}
],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"]
}
}'
# В ответе вы получите: parts[0].inline_data.data (изображение в формате base64)
# А также parts[0].thought_signature
Для второго этапа запроса необходимо передать весь ответ модели из первого этапа (включая изображение и сигнатуру) обратно в поле contents:
curl -X POST \
"https://vip.apiyi.com/v1beta/models/gemini-3-pro-image-preview:generateContent" \
-H "x-goog-api-key: YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [
{"role": "user", "parts": [{"text": "Нарисуй золотистого ретривера, бегущего по пляжу"}]},
{"role": "model", "parts": [
{"inline_data": {"mime_type": "image/png", "data": "<base64 из первого ответа>"}},
{"thought_signature": "<signature из первого ответа>"}
]},
{"role": "user", "parts": [{"text": "Измени сцену на закат"}]}
],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"]
}
}'
Сравнение трех режимов вызова
| Способ вызова | Управление историей | Подходящие сценарии | Сложность освоения |
|---|---|---|---|
Официальный Python SDK (объект chat) |
Автоматически | Бэкенд-сервисы, эксперименты в Notebook | ⭐ Минимальная |
OpenAI-совместимый API (массив messages) |
Полуавтоматически | Миграция существующих проектов с OpenAI | ⭐⭐ Низкая |
Нативный REST (массив contents) |
Полностью вручную | ComfyUI, low-code, кроссплатформенность | ⭐⭐⭐ Средняя |
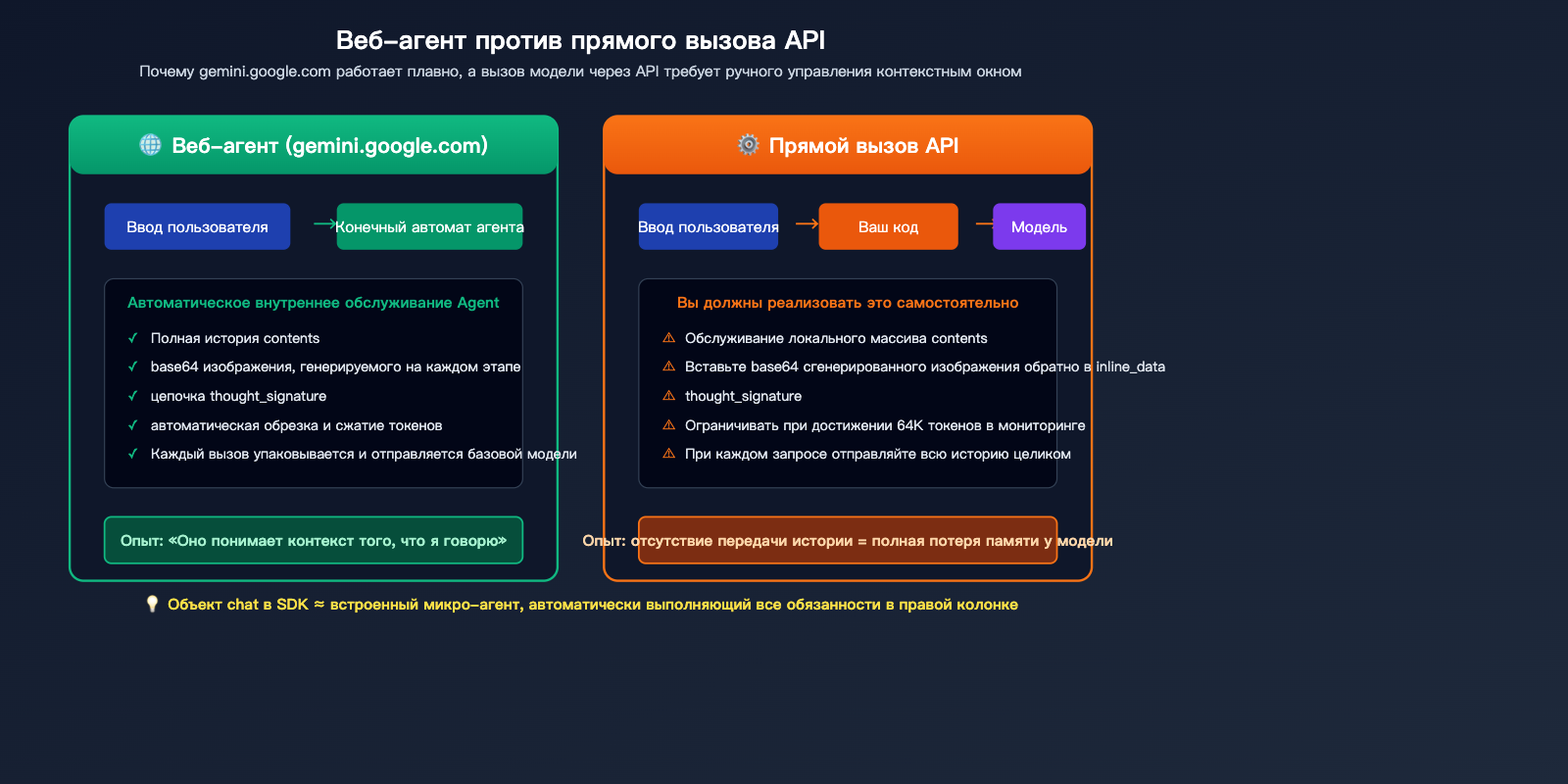
Примечание к данным: На графике выше показаны ключевые различия между автоматическим управлением через Agent и ручным управлением через API. Вы можете сравнить производительность обоих способов на платформе APIYI (apiyi.com).
Механизм thoughtSignature в Nano Banana Pro для генерации изображений в многоходовом диалоге
Что такое thoughtSignature
thoughtSignature — это «зашифрованная подпись размышлений», представленная в серии Gemini 3. Это компактное кодирование внутреннего состояния рассуждений модели. Оно не читаемо для человека, но позволяет модели быстро восстановить контекст в следующем шаге диалога. Основные функции:
- Сохранение логики решений: Например, если в первом шаге модель «решила» использовать светлые тона, во втором шаге она унаследует этот стиль через подпись.
- Повышение согласованности: Персонажи, сцены и композиция остаются стабильными при многократном редактировании.
- Экономия токенов: Нет необходимости постоянно повторять в промпте «сохраняй исходный стиль».
Когда обязательно нужно передавать signature
| Сценарий | Нужно ли передавать signature |
|---|---|
| Одиночный запрос (разовая генерация) | ❌ Не нужно |
| Многоходовое редактирование (изменение на основе предыдущего изображения) | ✅ Обязательно |
| Восстановление истории между сессиями | ✅ Обязательно (требуется самостоятельная сериализация) |
| Только текстовый диалог (без изображений) | ✅ Обязательно, для непрерывности рассуждений |
Практика: шаблон кода для ручного управления signature
import requests
import base64
import json
API_BASE = "https://vip.apiyi.com/v1beta"
MODEL = "gemini-3-pro-image-preview"
HEADERS = {
"x-goog-api-key": "YOUR_API_KEY",
"Content-Type": "application/json"
}
class NanoBananaChat:
"""Минималистичный чат-клиент с ручным управлением contents + signature"""
def __init__(self):
self.contents = []
def send(self, text: str, attach_image_b64: str = None) -> dict:
# Формируем сообщение пользователя для текущего шага
user_parts = [{"text": text}]
if attach_image_b64:
user_parts.append({
"inline_data": {"mime_type": "image/png", "data": attach_image_b64}
})
self.contents.append({"role": "user", "parts": user_parts})
# Отправляем запрос
resp = requests.post(
f"{API_BASE}/models/{MODEL}:generateContent",
headers=HEADERS,
json={
"contents": self.contents,
"generationConfig": {"responseModalities": ["TEXT", "IMAGE"]}
}
).json()
# Добавляем ответ модели (включая signature) обратно в contents
model_parts = resp["candidates"][0]["content"]["parts"]
self.contents.append({"role": "model", "parts": model_parts})
return model_parts
# Пример использования
chat = NanoBananaChat()
parts1 = chat.send("Сгенерируй золотистого ретривера, бегущего по пляжу")
parts2 = chat.send("Измени сцену на закат") # Автоматически передает историю и signature
parts3 = chat.send("Добавь летящую чайку")
Совет по оптимизации: При подключении через APIYI (apiyi.com) платформа автоматически передает поле
thought_signature. Разработчику достаточно лишь убедиться, что «весь массив model parts добавляется обратно в contents», не вникая в содержимое самой подписи.
Практические сценарии многоходовой генерации изображений с Nano Banana Pro
Сценарий 1: Поэтапный дизайн брендинга
Частая задача маркетинговой команды: на основе одного концепт-арта продукта постепенно корректировать текст, цветовую гамму и верстку. Преимущество API для многоходовой генерации в том, что в каждом новом запросе достаточно описывать лишь «инкрементальные изменения», не пересказывая всю концепцию заново:
chat = client.chats.create(model="gemini-3-pro-image-preview")
chat.send_message("Создай постер кофейного бренда с темно-синим градиентным фоном, слева размести изображение продукта")
chat.send_message("Измени заголовок на «Awaken Your Morning»")
chat.send_message("Добавь место под QR-код в правом нижнем углу")
chat.send_message("Сделай стиль более современным, убери декоративные рамки")
Сценарий 2: Редактирование на основе эталонных изображений
Nano Banana Pro поддерживает до 14 эталонных изображений за один раз. В сочетании с многоходовым диалогом это позволяет выстроить мощный рабочий процесс для синтеза изображений:
# Загружаем фото человека + эталонное изображение одежды
chat.send_message([
"Одень человека с первого изображения в одежду со второго изображения",
{"inline_data": {"mime_type": "image/png", "data": person_b64}},
{"inline_data": {"mime_type": "image/png", "data": outfit_b64}}
])
# Последующая доработка
chat.send_message("Замени вырез горловины на V-образный")
chat.send_message("Замени фон на лаконичный серый")
Сценарий 3: Восстановление истории между сессиями
Если пользователь закрыл страницу и открыл её снова, для продолжения диалога необходимо сохранить массив contents в базе данных:
import json
# Сохранение
with open(f"sessions/{user_id}.json", "w") as f:
json.dump(chat.get_history(), f)
# Восстановление
with open(f"sessions/{user_id}.json") as f:
history = json.load(f)
restored_chat = client.chats.create(
model="gemini-3-pro-image-preview",
history=history
)
restored_chat.send_message("Продолжаем, сделай фон немного светлее")
Ограничения контекстного окна
| Ресурс | Ограничение |
|---|---|
| Входной контекст | 64K токенов |
| Выходной контекст | 32K токенов |
| Макс. кол-во эталонных изображений на запрос | 14 шт. |
| Рекомендуемое кол-во ходов истории | не более 8-10 |
| Макс. разрешение одного изображения | 2K (по умолчанию 1K) |
Совет по сценариям: Когда диалог превышает 8-10 ходов, рекомендуется принудительно «обрезать» раннюю историю или заменить её кратким резюме от LLM, иначе количество токенов быстро приблизится к лимиту в 64K. В продакшене обязательно добавьте счетчик токенов, чтобы принимать решение об обрезке на стороне клиента.
Часто задаваемые вопросы
Q1: Я вызываю API напрямую, контекста нет. Как реализовать непрерывный диалог, как в веб-версии?
API не имеет состояния (stateless), поэтому ваш код должен поддерживать локальный массив contents (или объект chat из SDK). При каждом запросе отправляйте полную историю (включая текст пользователя, изображения, сгенерированные моделью, и thought_signature), чтобы модель «помнила» предыдущий контекст. Самый простой способ — использовать официальный Python SDK client.chats.create(), который управляет этим автоматически.
Q2: Какие поля нужно передавать для изображений, сгенерированных на предыдущем шаге?
Изображения нужно помещать в массив parts «роли модели» из предыдущего шага в формате inline_data (base64 + mime_type). Также обязательно возвращайте thought_signature, полученную от модели. Если вы используете сервисы-прокси API, такие как APIYI (apiyi.com), платформа автоматически обработает маппинг этих полей, и разработчику нужно будет лишь поддерживать стандартный список messages.
Q3: Обязательно ли передавать thoughtSignature? Что будет, если не передать?
Настоятельно рекомендуется передавать. Если этого не сделать, модель при многоходовом редактировании может «забыть» ключевые решения предыдущего шага (стиль, цветовую гамму, композицию), из-за чего каждый раз генерация будет выглядеть как новая. Официальная документация указывает, что для многоходовых сценариев signature должна сохраняться. SDK делает это автоматически, а в REST-режиме нужно вручную добавлять части модели обратно в contents.
Q4: Что делать, если история слишком длинная? Будет ли ошибка при превышении 64K токенов?
Да, при превышении 64K входных токенов запрос будет отклонен. Стратегии оптимизации:
- Обрезка: оставляйте только последние 4-6 ходов истории.
- Даунсэмплинг изображений: передавайте исторические изображения в разрешении 1K вместо 2K.
- Замена резюме: используйте LLM для сжатия первых ходов в текстовое описание.
- Разделение сессий: при смене темы диалога начинайте новую сессию.
Q5: Как быстро протестировать возможности многоходовой генерации Nano Banana Pro?
Рекомендуем использовать агрегаторы, поддерживающие модели Gemini, например APIYI (apiyi.com):
- Зарегистрируйтесь и получите API-ключ с бесплатным лимитом.
- Выберите модель
gemini-3-pro-image-preview. - Используйте пример кода на Python из этой статьи, чтобы сделать 3-5 ходов редактирования.
- Сравните связность результатов на каждом шаге, чтобы понять, подходит ли это под ваши бизнес-задачи.
Резюме
Ключевые моменты API для многораундовой генерации изображений Nano Banana Pro:
- Отсутствие состояния (stateless): API не запоминает историю, поэтому вызывающая сторона должна самостоятельно поддерживать массив
contents. - Чередование ролей: Роли
userиmodelдолжны строго чередоваться, аpartsв каждом раунде могут содержать комбинацию текста, изображений и сигнатур. - Возврат изображений: Изображение, сгенерированное на предыдущем этапе, должно быть передано обратно в формате
inline_data, иначе модель его «не увидит». - Механизм подписи:
thought_signature— это ключ к согласованности в многораундовом диалоге; при использовании REST-режима её необходимо передавать вручную. - Упрощение через SDK: Объект
chatв официальном Python SDK автоматически управляет всеми вышеперечисленными деталями.
Разработчикам, желающим быстро реализовать функционал, аналогичный веб-версии, лучше всего использовать объект chat из официального SDK или режим messages в интерфейсе, совместимом с OpenAI. Это позволит избежать сложностей, возникающих при ручном формировании REST-запросов.
Рекомендуем подключаться к возможностям многораундовой генерации Nano Banana Pro через APIYI (apiyi.com). Платформа поддерживает как нативные поля Gemini, так и вызовы в режиме совместимости с OpenAI, предоставляет бесплатные тестовые лимиты и позволяет быстро проверить эффективность многораундового редактирования для бесшовной миграции ваших проектов.
📚 Справочные материалы
-
Официальная документация по генерации изображений Gemini API: Авторитетный источник по многораундовой генерации.
- Ссылка:
ai.google.dev/gemini-api/docs/image-generation - Описание: Спецификации поля
contents, полные примеры для Python SDK и REST.
- Ссылка:
-
Карточка модели Gemini 3 Pro Image Preview: Описание возможностей и ограничений модели.
- Ссылка:
ai.google.dev/gemini-api/docs/models/gemini-3-pro-image-preview - Описание: Ключевые параметры, такие как контекстное окно, разрешение, количество эталонных изображений и т.д.
- Ссылка:
-
Форум Google AI Developers — Multi-turn Nano Banana: Практические примеры от сообщества.
- Ссылка:
discuss.ai.google.dev/t/multi-turn-nano-banana-example - Описание: Обсуждение реальными разработчиками лучших практик многораундового диалога.
- Ссылка:
-
Документация Vertex AI Gemini 3 Pro Image: Справочник для корпоративного развертывания.
- Ссылка:
docs.cloud.google.com/vertex-ai/generative-ai/docs/models/gemini/3-pro-image - Описание: Продвинутые методы использования
thought_signatureи ссылокfile_data.
- Ссылка:
-
Документация по подключению к APIYI Nano Banana Pro: Быстрый старт для разработчиков из РФ и СНГ.
- Ссылка:
help.apiyi.com - Описание: Примеры использования интерфейсов, совместимых с OpenAI, и нативных интерфейсов Gemini.
- Ссылка:
Автор: Техническая команда APIYI
Обмен опытом: Приглашаем вас поделиться в комментариях практическими вопросами, с которыми вы столкнулись при многораундовой генерации изображений. Больше советов по настройке Nano Banana Pro можно найти в центре документации APIYI по адресу docs.apiyi.com.