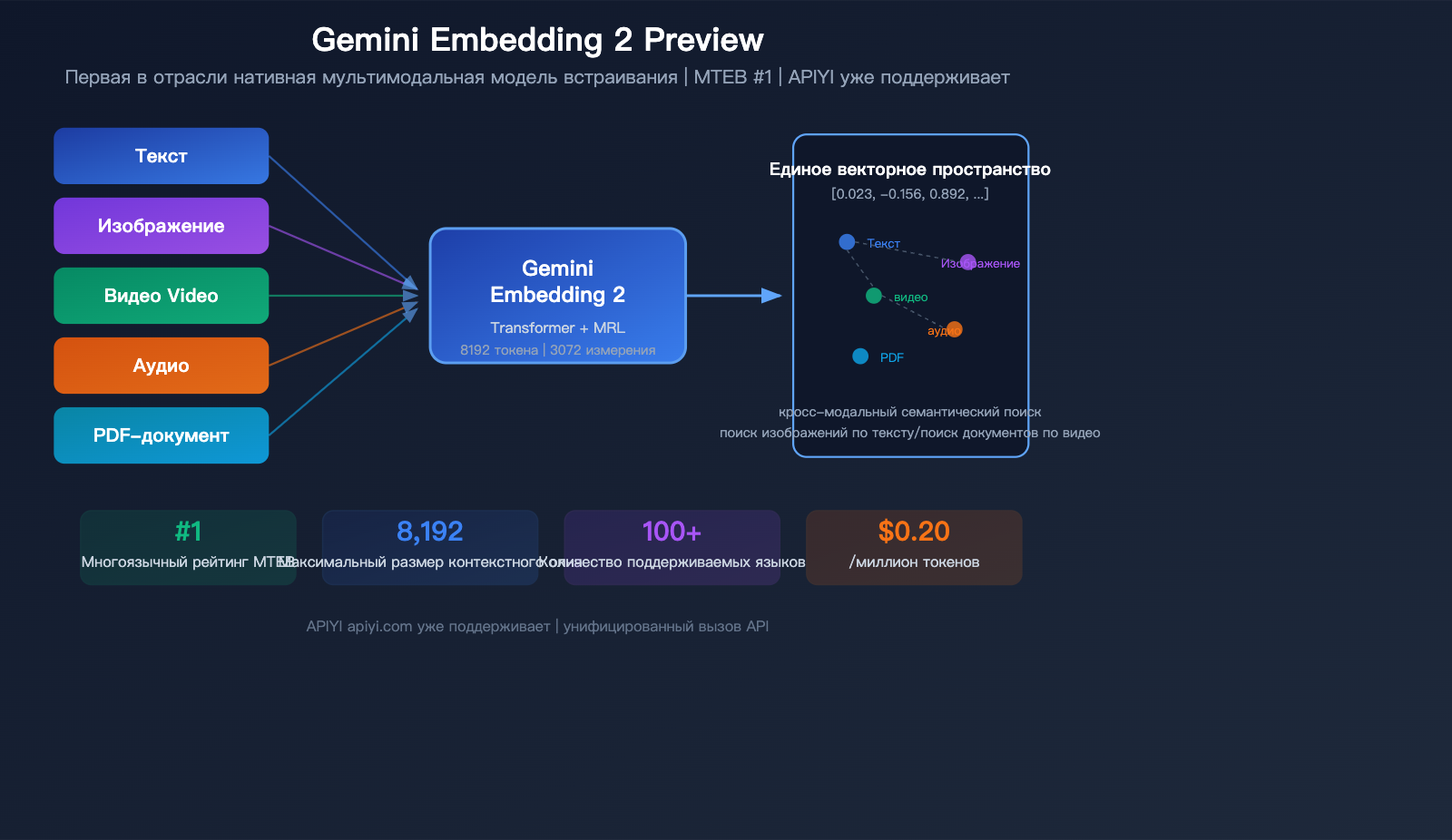
В марте 2026 года Google представила важную модель — Gemini Embedding 2 Preview, первую в индустрии нативную мультимодальную модель эмбеддингов. Она способна отображать текст, изображения, видео, аудио и PDF-документы в единое векторное пространство. В многоязычном бенчмарке MTEB модель заняла 1-е место, опередив ближайшего конкурента более чем на 5 процентных пунктов.
Ключевая ценность: из этой статьи вы узнаете о 5 главных технических прорывах Gemini Embedding 2 Preview, сравнении производительности и цен с аналогами, а также о том, как быстро подключиться к ней через API.
Что такое Gemini Embedding 2 Preview
Gemini Embedding 2 Preview — это новейшая модель эмбеддингов, представленная Google 10 марта 2026 года. Она построена на архитектуре Gemini и использует структуру трансформера с двунаправленным вниманием. Это первая модель эмбеддингов от Google с нативной поддержкой мультимодального ввода.
| Спецификация | Детали |
|---|---|
| ID модели | gemini-embedding-2-preview |
| Дата выпуска | 10 марта 2026 г. |
| Статус | Preview (предварительная версия, официальный релиз ожидается) |
| Размерность вывода по умолчанию | 3 072 |
| Диапазон размерностей | 128 — 3 072 |
| Макс. токенов на входе | 8 192 (в 4 раза больше, чем у предыдущего поколения) |
| Мультимодальность | Текст, изображения, видео, аудио, PDF |
| Поддержка языков | 100+ языков |
| Обучение Matryoshka | Поддерживается (можно обрезать размерность без потери качества) |
| Платформы | Gemini API, Vertex AI, APIYI apiyi.com |
Ключевые отличия от предыдущих моделей
| Характеристика | text-embedding-004 | gemini-embedding-001 | gemini-embedding-2-preview |
|---|---|---|---|
| Макс. токенов на входе | 2 048 | 2 048 | 8 192 |
| Размерность вывода | до 768 | 128-3 072 | 128-3 072 |
| Мультимодальность | Только текст | Только текст | Текст+Изображения+Видео+Аудио+PDF |
| Тип задачи | поле task_type |
поле task_type |
Встроенные инструкции в промпте |
| Поддержка MRL | Нет | Да | Да |
| Цена / млн токенов | Сервис закрыт | $0.15 | $0.20 |
🎯 Совет по подключению: APIYI apiyi.com уже поддерживает вызов модели gemini-embedding-2-preview.
Подключиться можно через интерфейс, совместимый с OpenAI, без необходимости отдельно настраивать API-ключ Google.
Подробный разбор 5 технологических прорывов
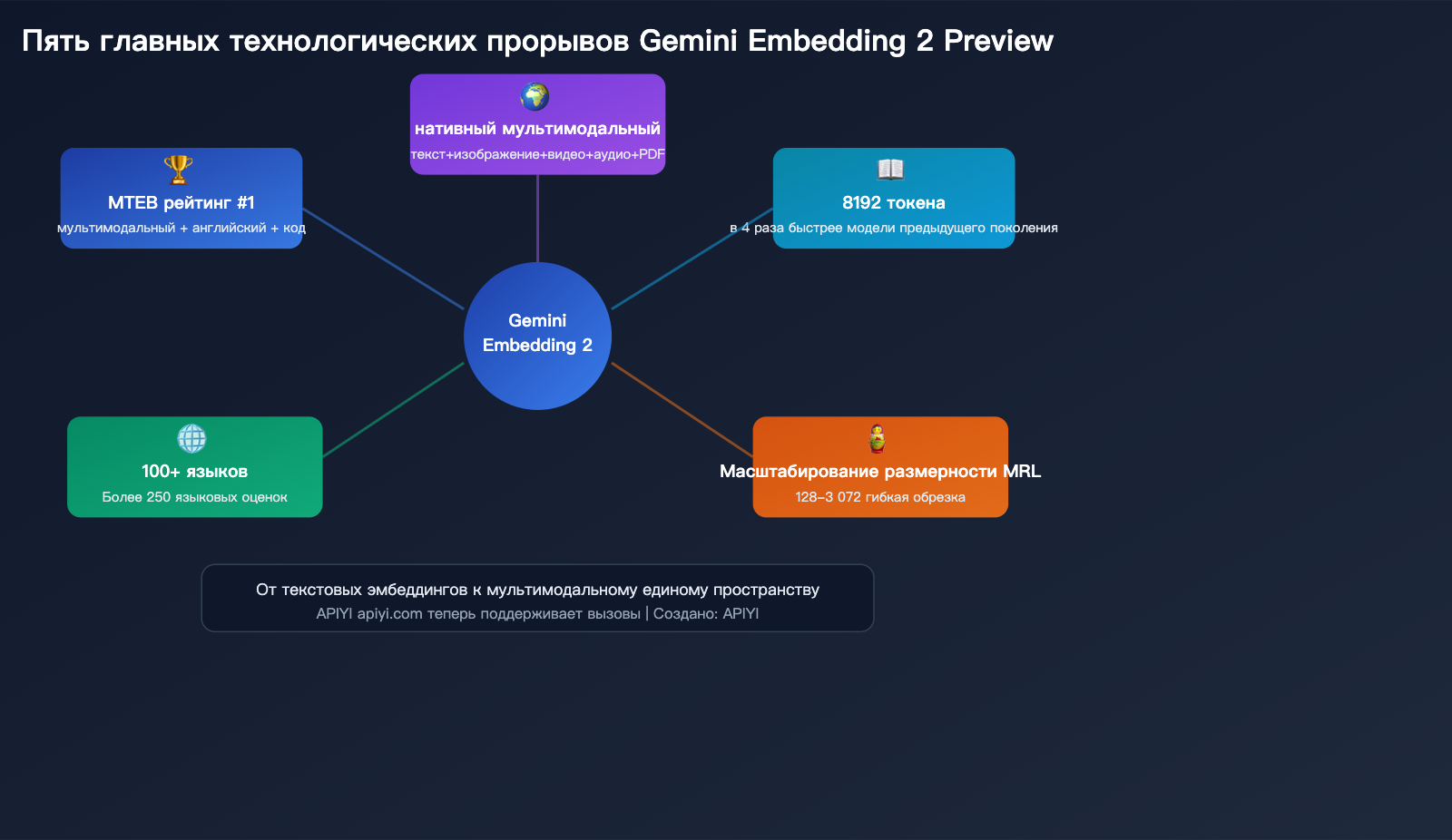
Прорыв 1: Единое мультимодальное векторное пространство
Это главное преимущество Gemini Embedding 2 — контент из 5 различных модальностей отображается в одно и то же векторное пространство.
| Модальность | Формат | Лимит на запрос | Примечание |
|---|---|---|---|
| Текст | Обычный текст | 8 192 токена | Поддержка 100+ языков |
| Изображения | PNG, JPEG | До 6 штук | Прямая обработка пикселей |
| Видео | MP4, MOV | До 120 сек | Авто-сэмплинг до 32 кадров |
| Аудио | MP3, WAV | До 80 сек | Нативная обработка, без транскрибации |
| Документы PDF | До 6 страниц | Включает возможности OCR |
Практические сценарии:
- Поиск изображений по текстовому описанию ("красный спорткар на гоночном треке" → выдача подходящих фото).
- Поиск похожих видеофрагментов по изображению.
- Поиск документов по голосовому описанию.
- Создание кросс-модальных баз знаний.
Ранее в моделях эмбеддингов это было невозможно: серия OpenAI text-embedding-3 поддерживает только текст. Если вам нужен был поиск по изображениям, приходилось сначала использовать визуальную модель для извлечения описания, что добавляло лишний шаг и приводило к потере данных.
Прорыв 2: Контекстное окно 8 192 токена
Увеличение окна с 2 048 до 8 192 токенов означает, что теперь можно эмбеддить более длинные фрагменты документов.
Для систем RAG (поиск с дополнением генерацией) это крайне полезно:
- Раньше документы приходилось разбивать на мелкие фрагменты по 500–1000 токенов.
- Теперь можно использовать блоки по 2000–4000 токенов, сохраняя больше контекста.
- Больше размер фрагмента = меньше разбиений = более полные результаты поиска.
Прорыв 3: Масштабируемость размерности (Matryoshka)
Gemini Embedding 2 обучена с использованием Matryoshka Representation Learning (MRL). Модель концентрирует наиболее важную семантическую информацию в первых размерностях вектора.
Это позволяет гибко выбирать размерность в зависимости от задачи:
| Размерность | Размер вектора | Сценарий использования | Потеря качества |
|---|---|---|---|
| 3 072 (по умолч.) | 12.3 КБ | Максимальная точность | Нет |
| 1 536 | 6.1 КБ | Баланс точности и хранения | Минимальная |
| 768 | 3.1 КБ | Выбор для масштабных систем | Незначительная |
| 256 | 1.0 КБ | Системы рекомендаций в реальном времени | Средняя |
| 128 | 0.5 КБ | Сценарии экстремального сжатия | Заметная |
Примечание: При использовании размерности менее 3 072 необходимо вручную нормализовать вектор перед расчетом сходства.
Прорыв 4: Поддержка 100+ языков
В бенчмарке MTEB Gemini Embedding 2 была протестирована на 250+ языках, что значительно превышает охват конкурентов.
Ключевые показатели производительности:
- Майнинг параллельных текстов (Bitext Mining): 79.32 балла.
- Кросс-языковый поиск (XOR-Retrieve): Recall@5kt 90.42 балла.
- Мультиязычное понимание (XTREME-UP): MRR@10 64.33 балла.
Прорыв 5: Первое место в рейтингах MTEB
| Бенчмарк | Оценка | Место | Отрыв |
|---|---|---|---|
| MTEB Multilingual (Mean Task) | 68.32 | 1-е | +5.09 |
| MTEB Multilingual (Mean Type) | 59.64 | 1-е | — |
| MTEB English v2 (Mean Task) | 73.30 | 1-е | — |
| MTEB English v2 (Mean Type) | 67.67 | 1-е | — |
| MTEB Code (Mean All) | 74.66 | 1-е | — |
Для сравнения: модель gte-Qwen2-7B-instruct, занимающая второе место, имеет 62.51 балла в мультиязычном MTEB. Gemini Embedding 2 опережает её почти на 6 баллов, что является огромным разрывом в сфере эмбеддингов.
💡 Совет разработчикам: Если вы создаете RAG-систему или приложение для семантического поиска,
Gemini Embedding 2 — самый мощный выбор на текущий момент, особенно для мультиязычных задач и работы с кодом.
Через APIYI apiyi.com можно подключить эту модель в один клик, а также использовать модели OpenAI для сравнения результатов.
Сравнение цен и производительности с конкурентами
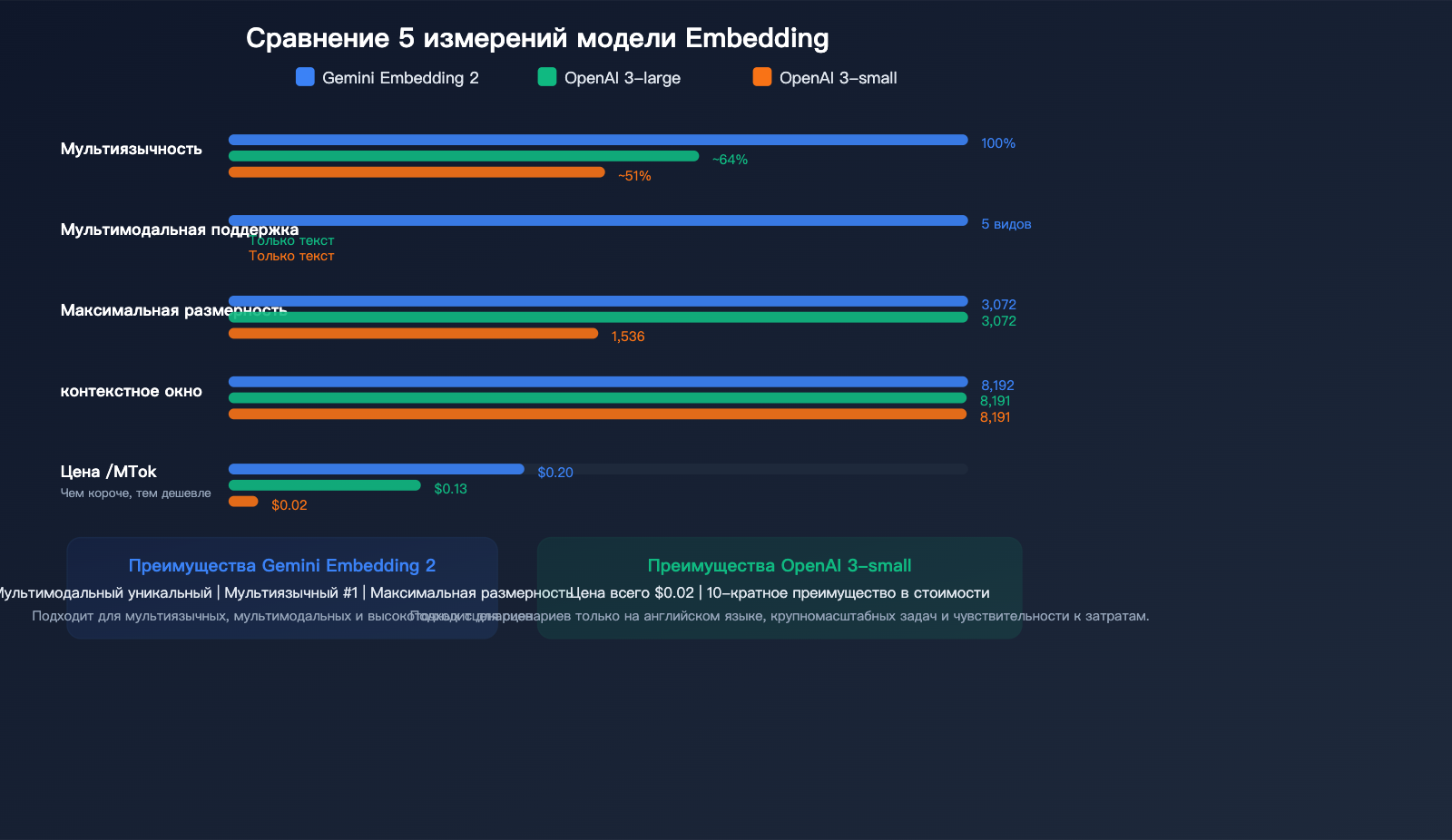
Сравнение цен на текстовые эмбеддинги
| Модель | Цена за 1 млн токенов | Макс. размерность | Макс. вход | Мультимодальность | Рейтинг (языки) |
|---|---|---|---|---|---|
| Gemini Embedding 2 | $0.20 | 3 072 | 8 192 | ✅ 5 модальностей | #1 |
| gemini-embedding-001 | $0.15 | 3 072 | 2 048 | ❌ | — |
| OpenAI text-embedding-3-large | $0.13 | 3 072 | 8 191 | ❌ | — |
| OpenAI text-embedding-3-small | $0.02 | 1 536 | 8 191 | ❌ | — |
Цены на мультимодальный контент (эксклюзивно для Gemini Embedding 2):
| Тип ввода | Цена (обычная) / 1 млн токенов | Цена (batch) / 1 млн токенов |
|---|---|---|
| Текст | $0.20 | $0.10 |
| Изображение | $0.45 (~$0.00012/шт.) | $0.225 |
| Аудио | $6.50 (~$0.00016/сек.) | $3.25 |
| Видео | $12.00 (~$0.00079/кадр) | $6.00 |
Рекомендации по выбору
| Сценарий использования | Рекомендуемая модель | Почему? |
|---|---|---|
| Чистый текст, чувствительность к цене | OpenAI text-embedding-3-small | Самый дешевый вариант ($0.02) |
| Чистый текст, высокая точность | Gemini Embedding 2 или OpenAI 3-large | Точность сопоставима, но Gemini лучше работает с языками |
| Мультимодальный поиск | Gemini Embedding 2 | Единственное нативное мультимодальное решение |
| Мультиязычный поиск | Gemini Embedding 2 | #1 в рейтинге MTEB по языкам |
| Поиск по коду | Gemini Embedding 2 | #1 в рейтинге MTEB по коду |
| Масштабируемость и экономия | OpenAI 3-small + Batch API | Преимущество в цене в 10 раз |
🎯 Совет: Выбор модели эмбеддинга зависит от ваших задач.
Мы рекомендуем использовать платформу APIYI (apiyi.com) для подключения моделей Gemini и OpenAI,
чтобы сравнить качество поиска на реальных данных перед принятием решения. Платформа поддерживает единый интерфейс, поэтому переключение между моделями не потребует изменения кода.
Подробное руководство по вызову API
Способ указания типа задачи (важное изменение)
В отличие от gemini-embedding-001, в Gemini Embedding 2 больше не используется параметр task_type. Теперь тип задачи задается путем внедрения инструкций непосредственно в текст запроса.
8 поддерживаемых типов задач:
| Тип задачи | Формат запроса (Query) | Формат документа |
|---|---|---|
| Поиск/Извлечение | task: search result | query: {контент} |
title: {заголовок} | text: {контент} |
| Вопросы и ответы | task: question answering | query: {вопрос} |
title: {заголовок} | text: {контент} |
| Проверка фактов | task: fact checking | query: {утверждение} |
title: {заголовок} | text: {контент} |
| Поиск кода | task: code retrieval | query: {описание} |
title: {заголовок} | text: {код} |
| Классификация | task: classification | query: {контент} |
Тот же формат |
| Кластеризация | task: clustering | query: {контент} |
Тот же формат |
| Сходство предложений | task: sentence similarity | query: {предложение} |
Тот же формат |
Для документов, у которых нет заголовка, используйте title: none.
Пример вызова на Python
import openai
# Вызов через унифицированный интерфейс APIYI
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# Текстовое вложение (embedding) - сценарий поиска
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input="task: search result | query: что такое векторная база данных",
dimensions=768 # Доступные размерности: 128-3072
)
embedding = response.data[0].embedding
print(f"Размерность вектора: {len(embedding)}")
print(f"Первые 5 значений: {embedding[:5]}")
Посмотреть полный код процесса RAG-поиска
import openai
import numpy as np
from typing import List
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
def get_embedding(text: str, task: str = "search result", dim: int = 768) -> List[float]:
"""Получение вектора вложения для текста"""
formatted = f"task: {task} | query: {text}"
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input=formatted,
dimensions=dim
)
vec = response.data[0].embedding
# При использовании MRL (Matryoshka Representation Learning)
# для усеченных размерностей требуется ручная нормализация
if dim < 3072:
norm = np.linalg.norm(vec)
vec = (np.array(vec) / norm).tolist()
return vec
def get_doc_embedding(title: str, text: str, dim: int = 768) -> List[float]:
"""Получение вектора вложения для документа"""
formatted = f"title: {title} | text: {text}"
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input=formatted,
dimensions=dim
)
vec = response.data[0].embedding
if dim < 3072:
norm = np.linalg.norm(vec)
vec = (np.array(vec) / norm).tolist()
return vec
def cosine_similarity(a: List[float], b: List[float]) -> float:
"""Вычисление косинусного сходства"""
a, b = np.array(a), np.array(b)
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# Пример использования
query_vec = get_embedding("как оптимизировать RAG-поиск")
doc_vec = get_doc_embedding(
"Руководство по оптимизации RAG",
"В этой статье описаны 5 методов улучшения качества RAG-поиска..."
)
similarity = cosine_similarity(query_vec, doc_vec)
print(f"Сходство: {similarity:.4f}")
🚀 Быстрый старт: Рекомендуем использовать платформу APIYI (apiyi.com) для быстрого подключения Gemini Embedding 2.
Платформа предоставляет API, совместимый с OpenAI, что позволяет интегрироваться за 5 минут,
а также поддерживает унифицированный вызов моделей от OpenAI, Gemini, Cohere и других.
Важные примечания
Ограничения статуса Preview
| Ограничение | Описание | Влияние |
|---|---|---|
| Возможные изменения | Спецификации и цены могут меняться в стадии Preview | Для продакшена рекомендуется предусмотреть план отката |
| Несовместимость векторных пространств | Нельзя смешивать с векторами старых моделей | При обновлении потребуется полная переиндексация |
| Необходимость нормализации | При размерности < 3072 требуется ручная нормализация | В коде нужно добавить шаг нормализации |
| Строгие лимиты скорости | Квоты ниже, чем у GA-моделей | Для масштабных задач нужно запрашивать увеличение лимитов |
| Использование данных | Данные бесплатного уровня могут использоваться для обучения | Для конфиденциальных данных используйте платный уровень |
Что нужно учесть при миграции со старых моделей
- Обязательная переиндексация: Векторные пространства разных моделей несовместимы, их нельзя смешивать в одной базе данных.
- Изменение формата типов задач: Вместо параметра
task_typeтеперь используются встроенные инструкции в промпте. - Нормализация: Если вы используете размерность, отличную от стандартной, добавьте логику нормализации в код.
- Тестирование перед миграцией: Сначала сравните качество поиска новой и старой моделей в тестовой среде, прежде чем переходить на новую версию.
Часто задаваемые вопросы
Q1: В чем преимущество Gemini Embedding 2 Preview перед OpenAI text-embedding-3-large?
Основные преимущества заключаются в трех аспектах: нативная мультимодальная поддержка (OpenAI поддерживает только текст), 1-е место в рейтинге MTEB по мультиязычности (с большим отрывом) и более высокое качество эмбеддингов кода. Однако OpenAI text-embedding-3-large стоит дешевле ($0,13 против $0,20), и если вам нужны эмбеддинги только для английского текста, качество моделей очень близко. Через сервис-прокси API APIYI (apiyi.com) вы можете вызывать обе модели и сравнивать их на реальных данных.
Q2: Какое практическое применение у мультимодальных эмбеддингов?
Самое прямое применение — это кросс-модальный поиск: пользователь вводит текст, а система возвращает соответствующие изображения, видео или документы. Например, в e-commerce можно искать товары по запросу «красное платье», или в корпоративной базе знаний искать фрагменты обучающих видео по текстовому описанию. Раньше для этого требовалось сначала использовать визуальную модель для извлечения описания, а затем эмбеддить текст. Gemini Embedding 2 работает с исходными изображениями/видео напрямую, что минимизирует потерю информации.
Q3: Какую размерность выбрать? Большая ли разница между 768 и 3072?
Для большинства задач 768 измерений — это «золотая середина»: стоимость хранения в 4 раза ниже, чем у 3072, а потеря качества поиска минимальна (благодаря обучению Matryoshka). Если ваш набор данных невелик (<1 млн записей) и требования к точности экстремально высоки, используйте 3072. Если данных много или требуется поиск в реальном времени, 768 или даже 256 измерений будут вполне разумным выбором.
Q4: Как APIYI поддерживает Gemini Embedding 2? Нужна ли дополнительная настройка?
APIYI (apiyi.com) уже поддерживает модель gemini-embedding-2-preview. Вызов осуществляется через стандартный интерфейс эмбеддингов, совместимый с OpenAI, поэтому дополнительный Google API-ключ не требуется. Просто укажите gemini-embedding-2-preview в параметре model, остальные параметры (например, dimensions) полностью соответствуют интерфейсу OpenAI.

Итоги: новый стандарт мультимодальных эмбеддингов
Gemini Embedding 2 Preview — это важная веха в развитии моделей эмбеддингов, знаменующая переход от чисто текстовых моделей к по-настоящему единому мультимодальному пространству. Заняв первые места в трех категориях MTEB (мультиязычность, английский язык и код), а также предложив контекстное окно на 8 тыс. токенов и масштабируемость размерности MRL, модель предоставляет мощнейший фундамент для RAG-систем, семантического поиска и построения баз знаний.
Ключевые выводы:
- Первая в индустрии нативная пятимодальная модель эмбеддингов (текст + изображения + видео + аудио + PDF).
- 1-е место в бенчмарке MTEB (мультиязычность), опережение конкурентов на 5+ баллов.
- Контекстное окно 8 192 токена — в 4 раза больше, чем у предыдущего поколения.
- Поддержка обучения MRL с гибкой настройкой размерности от 128 до 3 072.
- Цена $0,20 за 1 млн токенов — отличная стоимость для мультимодальных задач.
Рекомендуем быстро подключиться к Gemini Embedding 2 Preview через APIYI (apiyi.com). Один API-ключ позволяет работать как с Gemini, так и с другими популярными моделями эмбеддингов, что очень удобно для сравнения и переключения между ними.
📝 Автор статьи: Техническая команда APIYI | APIYI apiyi.com — платформа для унифицированного доступа к API 300+ больших языковых моделей.
Справочные материалы
-
Официальный блог Google: Анонс Gemini Embedding 2
- Ссылка:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-embedding-2/ - Описание: концепция дизайна модели и обзор мультимодальных возможностей.
- Ссылка:
-
Документация Gemini API по эмбеддингам: Официальное руководство по использованию API
- Ссылка:
ai.google.dev/gemini-api/docs/embeddings - Описание: полные параметры API и примеры вызова модели.
- Ссылка:
-
Исследовательская работа по Gemini Embedding: Технические детали и бенчмарки
- Ссылка:
arxiv.org/html/2503.07891v1 - Описание: подробные данные тестирования MTEB и анализ архитектуры модели.
- Ссылка:
-
Ценообразование Gemini API: Подробная информация о стоимости для каждой модальности
- Ссылка:
ai.google.dev/gemini-api/docs/pricing - Описание: детализированные тарифы для текста, изображений, аудио и видео.
- Ссылка: