Проблема медленных вызовов API для больших языковых моделей (БЯМ) от Alibaba Cloud Qwen3.5 — одна из самых обсуждаемых тем в сообществе разработчиков. Казалось бы, модели Qwen3.5-Plus и Qwen3.5-Flash, разработанные самой Alibaba, должны отлично работать на их собственной инфраструктуре. Однако на практике многие разработчики сталкиваются с разочарованием: собственные модели работают медленно на их же платформе, а вызовы сторонних моделей, таких как GLM-5, Kimi-K2.5, MiniMax-M2.5, через API Alibaba Cloud и вовсе вызывают заметные задержки.
Ключевая ценность: В этой статье мы глубоко разберем основные причины медленной работы API Alibaba Cloud с точки зрения трех аспектов: предоставления вычислительных ресурсов, архитектуры системы и стратегий распределения нагрузки. Мы также предложим три проверенных альтернативных решения, которые помогут вам добиться более быстрой работы при вызове моделей в ваших проектах.
- Заголовок: Медленные вызовы API Alibaba Cloud Qwen3.5: причины и решения
- Описание: Анализ причин медленной работы API Alibaba Cloud Qwen3.5 и предложение альтернативных решений для ускорения вызовов моделей.
Проблема медленных вызовов API для больших языковых моделей (БЯМ) от Alibaba Cloud Qwen3.5 — одна из самых обсуждаемых тем в сообществе разработчиков. Казалось бы, модели Qwen3.5-Plus и Qwen3.5-Flash, разработанные самой Alibaba, должны отлично работать на их собственной инфраструктуре. Однако на практике многие разработчики сталкиваются с разочарованием: собственные модели работают медленно на их же платформе, а вызовы сторонних моделей, таких как GLM-5, Kimi-K2.5, MiniMax-M2.5, через API Alibaba Cloud и вовсе вызывают заметные задержки.
Ключевая ценность: В этой статье мы глубоко разберем основные причины медленной работы API Alibaba Cloud с точки зрения трех аспектов: предоставления вычислительных ресурсов, архитектуры системы и стратегий распределения нагрузки. Мы также предложим три проверенных альтернативных решения, которые помогут вам добиться более быстрой работы при вызове моделей в ваших проектах.
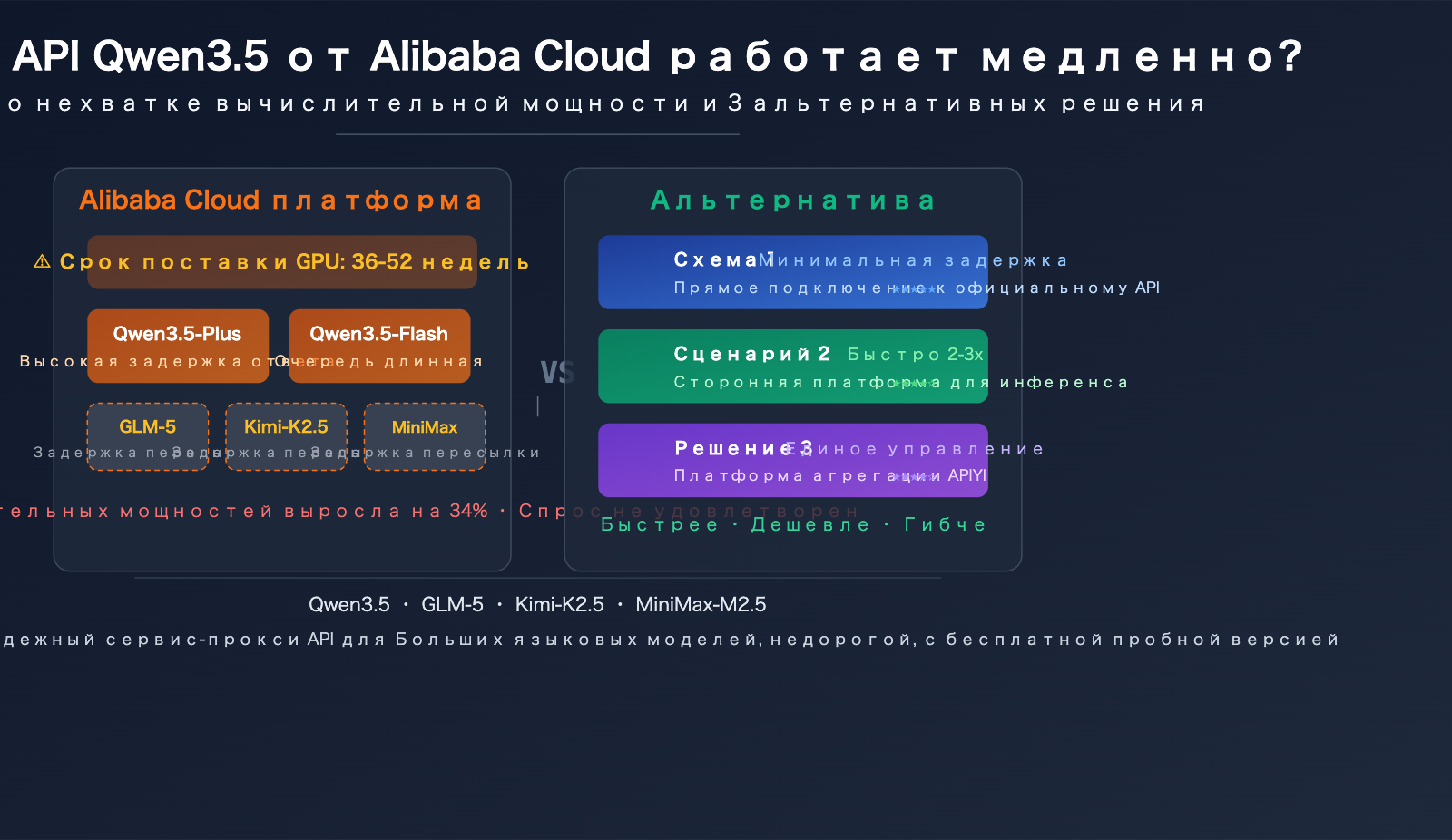
Анализ 5 основных причин медленной работы API Qwen3.5 от Alibaba Cloud
Причина 1: Серьезный дефицит глобальных мощностей GPU
Это не проблема только Alibaba Cloud, а структурный конфликт всей отрасли. Срок поставки GPU уровня дата-центров в 2026 году уже увеличился до 36-52 недель. Руководство Alibaba Cloud публично признало, что наблюдается "значительное узкое место" в поставках полупроводниковых компонентов, чипов памяти и модулей памяти в ближайшие 2-3 года.
| Показатель предложения вычислительных мощностей | 2025 год | 2026 год | Тенденция |
|---|---|---|---|
| Срок поставки GPU | 12-24 нед. | 36-52 нед. | ↑ Значительно увеличивается |
| Рост доходов Alibaba Cloud от ИИ | — | 34% | Взрывной спрос |
| Корректировка цен на вычислительные мощности Alibaba Cloud | Базовая цена | Повышение до 34% | ↑ С 18 апреля 2026 г. |
| Доля глобальных расходов на ИИ-инференс | 42% | 55% | Впервые превышает обучение |
Alibaba Cloud официально объявила о повышении цен на ИИ-вычислительные мощности с 18 апреля 2026 года, с увеличением до 34%. Прямая причина — "взрывной рост мирового спроса на ИИ и рост цен в цепочке поставок". Доходы Alibaba Cloud выросли на 34%, но компания заявила, что этого все равно недостаточно для удовлетворения спроса — это макроэкономический фон медленной работы API Qwen3.5.
Причина 2: Потребление вычислительных мощностей архитектурой модели Qwen3.5
Семейство Qwen3.5 использует архитектуру MoE (Mixture of Experts). Флагманская версия Qwen3.5-397B-A17B имеет общее количество параметров 397 миллиардов, при каждом инференсе активируется 17 миллиардов параметров. Даже легкая версия Qwen3.5-Flash (на базе 35B-A3B) изначально поддерживает 1 миллион токенов контекста и мультимодальный ввод (текст + изображения + видео).
| Версия модели | Общее количество параметров | Количество активируемых параметров | Контекстное окно по умолчанию | Поддержка мультимодальности |
|---|---|---|---|---|
| Qwen3.5-397B-A17B (флагман) | 397 млрд | 17 млрд | 262K → 1M | Текст + Изображения + Видео |
| Qwen3.5-Plus (API версия) | Не раскрывается | Не раскрывается | 1M | Текст + Изображения + Видео |
| Qwen3.5-Flash (API версия) | 35 млрд | 3 млрд | 1M | Текст + Изображения + Видео |
| Qwen3.5-122B-A10B | 122 млрд | 10 млрд | 262K | Текст + Изображения + Видео |
Эти модели с этапа обучения используют мультимодальную архитектуру с ранним слиянием (early-fusion), изначально поддерживая унифицированную обработку текста, изображений и видео. Цена мощных функций: вычислительные затраты на каждый запрос значительно выше, чем у моделей только для текста. В сочетании с контекстным окном в миллион токенов, использование видеопамяти и вычислительных ресурсов при одном инференсе значительно возрастает.
Причина 3: Дополнительная задержка при перепродаже Alibaba Cloud сторонних моделей
При вызове сторонних моделей, таких как GLM-5 (Zhipu AI), Kimi-K2.5 (Moonshot AI), MiniMax-M2.5 через платформу Alibaba Cloud DashScope, путь запроса фактически становится следующим:
Ваше приложение → Шлюз Alibaba Cloud API → Уровень диспетчеризации DashScope → Сервис сторонней модели
Каждый дополнительный уровень пересылки добавляет задержку. Что еще более важно, при перепродаже этих моделей Alibaba Cloud, приоритет выделения ресурсов GPU может быть ниже, чем у собственных моделей — ведь вычислительных мощностей и так не хватает. Общая обратная связь от разработчиков в сообществе: вызовы GLM-5, Kimi-K2.5, MiniMax-M2.5 через Alibaba Cloud заметно медленнее, чем через официальные API.
Причина 4: Недостаточная оптимизация стратегии диспетчеризации инференса
Специализированные сторонние платформы для инференса (например, SiliconFlow, Fireworks AI, Together AI) имеют значительные преимущества в эффективности инференса благодаря таким технологиям, как пользовательские ядра CUDA, слияние механизмов внимания и мелкозернистая диспетчеризация. Данные тестов показывают:
- SiliconFlow: скорость инференса до 2,3 раз выше, чем у универсальных облачных платформ, задержка снижена на 32%.
- Fireworks AI: технология FireAttention v2 заявляет об увеличении скорости до 8 раз, фактические тесты показывают около 747 TPS.
- Together AI: за счет спекулятивного декодирования и квантования FP4, скорость инференса открытых моделей увеличена до 2 раз.
Alibaba Cloud, как универсальная облачная платформа, уделяет больше внимания универсальности и стабильности при диспетчеризации инференса, а не максимальной оптимизации скорости. Это не оказывает существенного влияния при наличии достаточных вычислительных мощностей, но в периоды дефицита GPU разница становится более заметной.
Причина 5: Конкуренция за ресурсы между множеством арендаторов
Alibaba Cloud, как крупнейший поставщик облачных услуг в Китае, обслуживает огромное количество пользователей одновременно на своих кластерах ИИ-инференса. В пиковые периоды конкуренция за ресурсы GPU напрямую увеличивает время ожидания в очереди. Хотя разработанная Alibaba Cloud система пулинга ресурсов Aegaeon заявляет об увеличении утилизации GPU на 82%, по сути это "более тонкое деление ограниченного пирога" и не решает фундаментальную проблему недостаточного общего объема вычислительных мощностей.

GLM-5、Kimi-K2.5、MiniMax-M2.5: Сравнение задержки вызовов через Alibaba Cloud и официальные API
Разобравшись с причинами, переходим к конкретным сценариям вызова моделей. Ниже представлен сравнительный анализ опыта использования трех популярных моделей на разных платформах.
Анализ задержки при вызове API GLM-5 (Zhipu AI)
GLM-5 — флагманская модель от Zhipu AI, выпущенная в феврале 2026 года. Она имеет 744 миллиарда общих параметров и 40 миллиардов активируемых параметров, используя архитектуру MoE. Модель обучалась на чипах Huawei Ascend, поддерживает контекстное окно до 200 тысяч токенов и уже открыта для использования (лицензия MIT).
Ключевые особенности: GLM-5 изначально поддерживает режим Agent, позволяющий самостоятельно разбивать задачи на подзадачи и выполнять их, а также напрямую генерировать профессиональные офисные документы (.docx, .pdf, .xlsx). Стоимость использования: $1.00 за миллион входных токенов и $3.20 за миллион выходных токенов.
При вызове GLM-5 через Alibaba Cloud запросы проходят через дополнительные шлюзы и уровни диспетчеризации, что значительно увеличивает задержку. Прямое подключение к официальному API Zhipu AI (bigmodel.cn) позволяет запросам напрямую достигать собственных вычислительных кластеров Zhipu AI, обеспечивая более быстрый отклик.
Анализ задержки при вызове API Kimi-K2.5 (Moonshot AI)
Kimi-K2.5, выпущенная в январе 2026 года, представляет собой MoE модель с 1 триллионом параметров, при этом для каждого запроса активируется всего 32 миллиарда параметров. Модель предварительно обучена на 15 триллионах смешанных визуальных и текстовых токенов и изначально поддерживает мультимодальность.
Главная фишка: функция Agent Swarm — возможность одновременной координации до 100 специализированных AI-агентов для совместной работы, что сокращает время выполнения задач в 4.5 раза. На платформе SWE-Bench Verified модель превосходит Gemini 3 Pro, а Cursor AI подтвердил, что их функция Composer 2 построена на базе технологий Kimi.
При использовании сервиса-прокси API Alibaba Cloud для вызова Kimi-K2.5, дополнительные этапы перенаправления усугубляют работу этой триллионной модели, требующей значительных вычислительных ресурсов. Рекомендуется напрямую использовать официальный API Moonshot AI (platform.moonshot.ai).
Анализ задержки при вызове API MiniMax-M2.5
MiniMax-M2.5, выпущенная в феврале 2026 года, имеет 230 миллиардов общих параметров и 10 миллиардов активируемых. На платформе SWE-Bench Verified модель получила оценку 80.2%, а скорость выполнения задач на 37% выше, чем у M2.1, что сравнимо с Claude Opus 4.6.
Выдающееся преимущество в стоимости: модель позиционируется как первая передовая модель, "о которой пользователям не нужно беспокоиться с точки зрения затрат" — непрерывная работа в течение 1 часа со скоростью 100 токенов в секунду обойдется всего примерно в 1 доллар. Модель открыта на Hugging Face, рекомендуется для развертывания с использованием vLLM или SGLang.
| Модель | Время выпуска | Общие параметры | Активируемые параметры | Рекомендуемый способ вызова | Статус открытости |
|---|---|---|---|---|---|
| GLM-5 | 2026.02.11 | 7440 млрд | 40 млрд | Официальный API Zhipu AI | Открыта (MIT) |
| Kimi-K2.5 | 2026.01.27 | 1 трлн | 32 млрд | Официальный API Moonshot AI | Открыта |
| MiniMax-M2.5 | 2026.02.12 | 230 млрд | 10 млрд | Официальный API MiniMax / Сторонние | Открыта (MIT, модифицированная) |
🎯 Практические рекомендации: Для сторонних моделей, таких как GLM-5, Kimi-K2.5, MiniMax-M2.5, которые являются закрытыми или полуоткрытыми, рекомендуется прямое подключение к официальным API каждой компании для получения наилучшего опыта. Если требуется унифицированное управление API-интерфейсами нескольких моделей, платформа APIYI apiyi.com позволяет использовать один API-ключ для вызова множества моделей, предлагая при этом более выгодные цены.
Сторонние платформы для инференса против Alibaba Cloud: 3 главных преимущества развертывания открытых моделей
Для открытых моделей, таких как Qwen3.5, помимо официального API Alibaba Cloud, у разработчиков есть и другие варианты. Специализированные платформы для инференса часто демонстрируют производительность, не уступающую, а иногда и превосходящую оригинальные решения от облачных провайдеров.
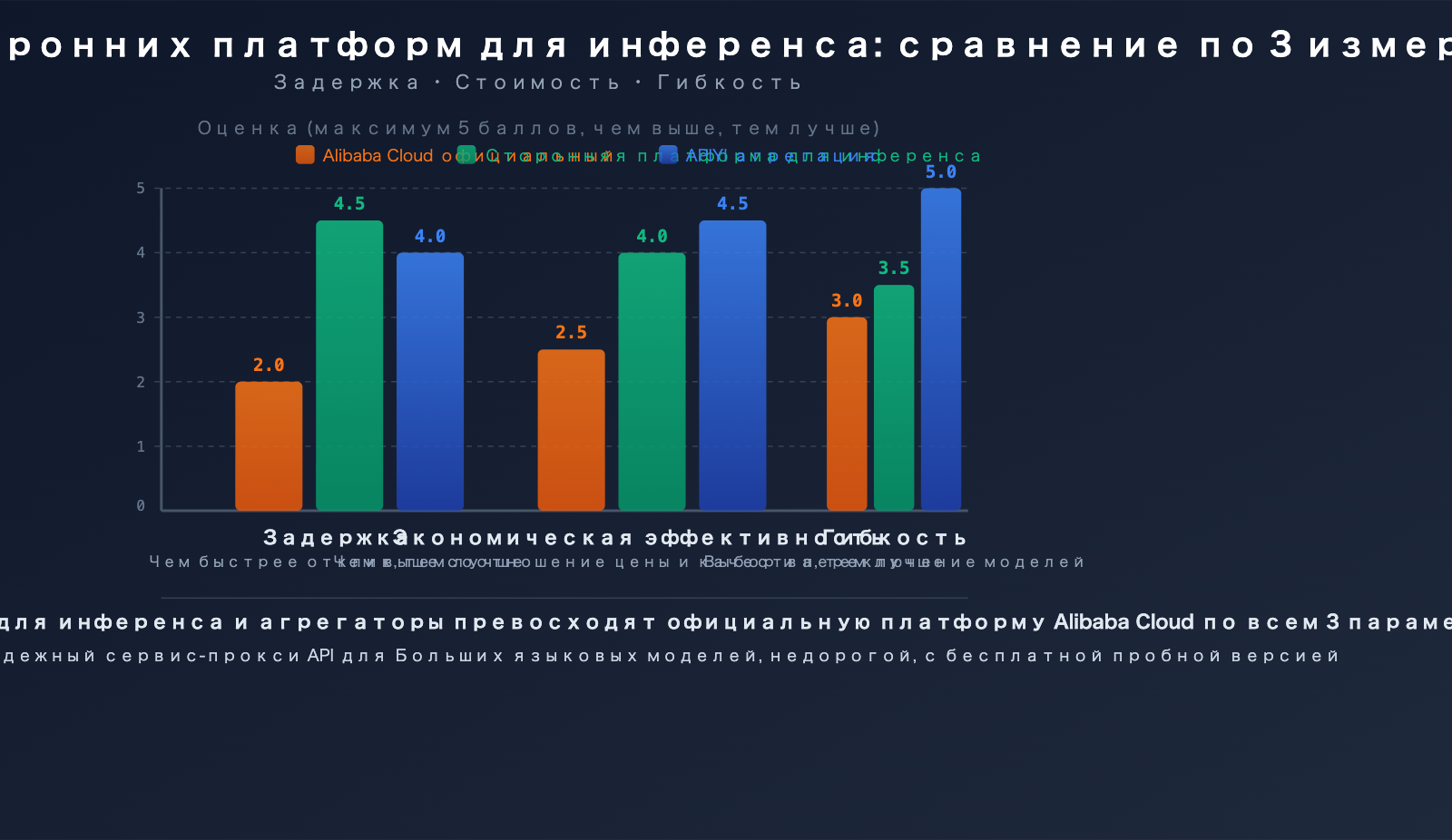
Преимущество 1: Более высокая скорость инференса
Ключевое конкурентное преимущество профессиональных платформ для инференса — скорость. Благодаря кастомизированным оптимизациям движков инференса, они достигают меньшей задержки при работе с одними и теми же моделями:
| Тип платформы | Типичная задержка | Пропускная способность | Преимущество в скорости |
|---|---|---|---|
| Универсальные облачные платформы (Alibaba Cloud и др.) | 100-300 мс | Базовый уровень | — |
| SiliconFlow | Снижение на 32% | Увеличение в 2.3 раза | Кастомные CUDA ядра |
| Fireworks AI | ~0.17 сек | ~747 TPS | FireAttention v2 |
| Together AI | — | Увеличение в 2 раза | Спекулятивное декодирование + FP4 квантизация |
| APIYI apiyi.com | Мульти-канальный выбор | Интеллектуальная маршрутизация | Автоматический выбор самого быстрого канала |
Преимущество 2: Более низкая стоимость
В 2026 году расходы на инференс впервые превысили расходы на обучение, составив 55% от общих затрат на облачную инфраструктуру для ИИ. В этом контексте оптимизация затрат на инференс становится критически важной:
- Вызов открытых моделей через сторонние API обычно стоит менее $1 за миллион токенов, что на 70-90% дешевле закрытых моделей.
- Профессиональные платформы для инференса используют новое поколение оборудования, такое как NVIDIA Blackwell, для снижения затрат на ИИ-инференс до 10 раз.
- Нет необходимости в создании собственных GPU-кластеров, оплата по факту использования, что идеально подходит для небольших команд и индивидуальных разработчиков.
Преимущество 3: Более гибкий выбор моделей
Сторонние платформы обычно поддерживают как открытые, так и закрытые модели, предоставляя унифицированный API-интерфейс и прозрачное ценообразование. Это означает:
- Отсутствие привязки к поставщику: Нет зависимости от какого-либо одного облачного провайдера.
- Быстрое переключение: Один интерфейс для вызова множества моделей, позволяющий сравнить результаты и выбрать оптимальный.
- Кастомизированная оптимизация: Открытые модели поддерживают квантизацию, дообучение, слияние и другие пользовательские операции.
💡 Рекомендации по выбору: Для открытых моделей, таких как Qwen3.5, развертывание на сторонних платформах для инференса может оказаться эффективнее, чем использование официального API Alibaba Cloud. Мы рекомендуем провести практическое тестирование и сравнение через платформу APIYI apiyi.com, которая агрегирует множество каналов инференса и автоматически выбирает для вас маршрут с наименьшей задержкой.
Быстрый старт работы с API для вызова открытых моделей: руководство за 5 минут
На примере Qwen3.5-Flash покажем, как быстро вызвать API открытых моделей через стороннюю платформу.
Минималистичный пример кода
import openai
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1" # Единый интерфейс APIYI
)
response = client.chat.completions.create(
model="qwen3.5-flash",
messages=[
{"role": "user", "content": "Проанализируй преимущества архитектуры MoE у Qwen3.5"}
]
)
print(response.choices[0].message.content)
Посмотреть полный код (с переключением между моделями и обработкой ошибок)
import openai
import time
# Инициализация клиента - единый вызов множества моделей через APIYI
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1"
)
# Список поддерживаемых моделей
models = [
"qwen3.5-flash", # Alibaba Qwen3.5-Flash
"qwen3.5-plus", # Alibaba Qwen3.5-Plus
"glm-5", # Zhipu GLM-5
"kimi-k2.5", # Moonshot Kimi-K2.5
"minimax-m2.5", # MiniMax-M2.5
]
prompt = "Объясни преимущества архитектуры MoE в инференсе больших языковых моделей в 3 предложениях"
for model_name in models:
try:
start = time.time()
response = client.chat.completions.create(
model=model_name,
messages=[{"role": "user", "content": prompt}],
max_tokens=500,
temperature=0.7
)
elapsed = time.time() - start
content = response.choices[0].message.content
print(f"\n[{model_name}] Время выполнения: {elapsed:.2f}с")
print(f"Ответ: {content[:200]}...")
except Exception as e:
print(f"\n[{model_name}] Ошибка вызова: {e}")
🚀 Быстрый старт: Рекомендуем использовать платформу APIYI apiyi.com для быстрого тестирования вышеуказанных моделей. При регистрации вы получите бесплатный кредит, а один API-ключ позволит вызывать популярные модели, такие как Qwen3.5, GLM-5, Kimi-K2.5, MiniMax-M2.5 и другие, без необходимости регистрироваться на каждой платформе отдельно.
Рекомендации по выбору способа вызова моделей для различных сценариев
Выберите наиболее подходящий способ вызова в зависимости от ваших реальных потребностей:
Сценарий 1: Необходимость вызова закрытых/полузакрытых моделей
Если вы в основном используете закрытые версии моделей, таких как GLM-5, Kimi-K2.5 (не саморазвернутые), рекомендуется:
- Первый выбор: Прямое подключение к официальным API каждой компании для минимальной задержки.
- Второй выбор: Использование агрегирующих платформ, таких как APIYI apiyi.com, для унифицированного вызова, жертвуя небольшой задержкой ради удобства управления.
Сценарий 2: Необходимость развертывания открытых моделей
Если вы используете открытые версии моделей, такие как Qwen3.5, GLM-5 (открытая версия), MiniMax-M2.5 (открытая версия):
- При наличии бюджета: Выбирайте специализированные платформы для инференса, такие как SiliconFlow, Together AI, для оптимальной задержки.
- Приоритет — соотношение цены и качества: Используйте агрегирующую платформу APIYI apiyi.com для вызова, которая автоматически маршрутизирует запросы по оптимальному каналу.
- Полный контроль: Используйте vLLM или SGLang для создания собственной службы инференса, что потребует наличия собственных ресурсов GPU.
Сценарий 3: Необходимость сравнения нескольких моделей
При необходимости быстрого сравнения эффективности нескольких моделей на начальном этапе разработки:
- Рекомендуется: Использовать унифицированный API-интерфейс (например, APIYI apiyi.com), чтобы после одной регистрации можно было переключаться и тестировать различные модели.
- Избегайте отдельной регистрации аккаунтов и управления несколькими API-ключами для каждой модели.
💰 Рекомендации по оптимизации затрат: Для проектов с ограниченным бюджетом вызов API открытых моделей через платформу APIYI apiyi.com является наиболее экономичным решением. Платформа предлагает гибкие тарифы, а стоимость вызова открытых моделей значительно ниже официальных цен на закрытые модели.
Частые вопросы
Q1: Qwen3.5-Flash заявлена как легковесная модель, почему API всё равно работает медленно?
Хотя Qwen3.5-Flash активирует всего 3 миллиарда параметров при каждом выводе, она по умолчанию поддерживает контекстное окно в 1 миллион токенов, а также имеет встроенную мультимодальную обработку (текст + изображения + видео) и поддержку вызова инструментов. Эти "скрытые расходы" приводят к тому, что фактическое потребление вычислительных ресурсов значительно выше, чем у чисто текстовых моделей с аналогичным количеством параметров. В условиях дефицита ресурсов GPU на Alibaba Cloud время ожидания в очереди ещё больше увеличивает воспринимаемую задержку.
Q2: Будет ли снижено качество при развёртывании открытых моделей на сторонних платформах?
Нет. Профессиональные сторонние платформы для инференса (например, SiliconFlow, Together AI) используют оригинальные веса открытых моделей в сочетании с оптимизированными движками для инференса. Качество такое же, как и у оригинальных моделей, а скорость инференса даже выше. Платформа APIYI apiyi.com позволяет быстро сравнить качество и скорость инференса различных каналов, чтобы выбрать оптимальное решение.
Q3: Когда улучшится ситуация с вычислительными ресурсами на Alibaba Cloud?
Согласно публичным заявлениям руководства Alibaba Cloud, дефицит GPU, как ожидается, сохранится в течение 2-3 лет. В краткосрочной перспективе Alibaba Cloud скорее будет повышать эффективность использования существующих GPU с помощью технологий пулинга ресурсов, таких как Aegaeon, а не значительно расширять мощности. Разработчикам рекомендуется не ждать оптимизации платформы, а активно выбирать более подходящие решения для вызовов — прямое подключение к официальным API или сторонние платформы для инференса являются жизнеспособными альтернативами на данный момент. Вы можете бесплатно протестировать скорость вызова различных моделей через APIYI apiyi.com.
Вывод: Стратегии решения проблемы медленного API Qwen3.5 на Alibaba Cloud
Основная причина медленной реакции API Qwen3.5 на Alibaba Cloud — глобальный дефицит вычислительных ресурсов GPU, усугубляемый высоким потреблением вычислительных ресурсов архитектурой модели и конкуренцией за ресурсы между множеством арендаторов. Проблемы с производительностью при вызове сторонних моделей, таких как GLM-5, Kimi-K2.5, MiniMax-M2.5, через Alibaba Cloud, по сути, вызваны той же причиной — Alibaba Cloud в первую очередь обеспечивает вычислительными ресурсами собственные модели, а распределение ресурсов для сторонних моделей находится на втором плане.
3 ключевых рекомендации:
- Прямое подключение к официальным API для закрытых моделей: Используйте Zhipu API для GLM-5, Moonshot API для Kimi-K2.5, MiniMax API для MiniMax-M2.5, чтобы избежать задержек при перенаправлении через промежуточные слои.
- Выбор сторонних платформ для открытых моделей: Открытые модели, такие как Qwen3.5, на профессиональных платформах для инференса могут работать лучше, чем через официальный API Alibaba Cloud.
- Использование агрегирующих платформ для унифицированного управления: Если вам нужно использовать несколько моделей одновременно, рекомендуется использовать APIYI apiyi.com для вызова всех моделей через один интерфейс, что обеспечивает как эффективность, так и удобство управления.
Дефицит вычислительных ресурсов будет нормой для всей отрасли в ближайшие 2-3 года. Вместо того чтобы пассивно ждать расширения мощностей облачных платформ, лучше активно оптимизировать стратегии вызовов — выбор наиболее подходящей комбинации платформ и моделей является лучшим путём к повышению качества работы AI-приложений.
Автор: Команда APIYI | Больше советов по вызову API AI-моделей вы можете найти на APIYI apiyi.com, где доступны последние руководства и бесплатные тестовые квоты.
📚 Справочные материалы
-
Официальная документация серии моделей Qwen3.5: Технические спецификации моделей Tongyi Qianwen от Alibaba Cloud.
- Ссылка:
github.com/QwenLM/Qwen3.5 - Описание: Содержит полные параметры модели, результаты тестов и руководство по использованию.
- Ссылка:
-
Объявление об изменении цен на вычислительные мощности Alibaba Cloud: Повышение цен на AI-вычисления с апреля 2026 года.
- Ссылка:
www.alibabacloud.com - Описание: Официальное разъяснение дисбаланса спроса и предложения на вычислительные мощности.
- Ссылка:
-
Технический отчет GLM-5: Технические детали флагманской модели от Zhipu AI.
- Ссылка:
github.com/THUDM/GLM-5 - Описание: Объяснение архитектуры MoE с 744 миллиардами параметров и режима Agent.
- Ссылка:
-
Официальная документация Kimi-K2.5: Модель с триллионом параметров от Moonshot AI.
- Ссылка:
platform.moonshot.ai/docs/guide/kimi-k2-5-quickstart - Описание: Руководство по функции Agent Swarm и подключению через API.
- Ссылка:
-
Технический блог MiniMax-M2.5: Подробное описание передовых открытых моделей.
- Ссылка:
www.minimax.io/news/minimax-m25 - Описание: Результаты тестов производительности, рекомендации по развертыванию и анализ затрат.
- Ссылка: