При разработке AI-приложений на базе Qwen3-Max многие разработчики сталкиваются с неприятной ошибкой 429 You exceeded your current quota. В этой статье мы подробно разберем механизмы ограничения скорости (rate limiting) в Qwen3-Max от Alibaba Cloud и предложим 5 проверенных решений, которые помогут вам навсегда забыть о проблемах с лимитами.
Ключевая польза: Прочитав эту статью, вы поймете принципы ограничения скорости Qwen3-Max, освоите различные способы обхода лимитов и выберете наиболее подходящий вариант для стабильной работы с этой большой языковой моделью на триллион параметров.
Обзор проблемы лимитов Qwen3-Max
Типичное сообщение об ошибке
Если ваше приложение слишком часто обращается к API Qwen3-Max, вы можете получить следующий ответ в формате JSON:
{
"error": {
"message": "You exceeded your current quota, please check your plan and billing details.",
"type": "insufficient_quota",
"code": "insufficient_quota"
},
"status": 429
}
Эта ошибка означает, что вы превысили квоту или достигли лимита запросов, установленного в Model Studio (DashScope) от Alibaba Cloud.
Последствия ограничений Qwen3-Max
| Сценарий использования | Проявление проблемы | Уровень критичности |
|---|---|---|
| Разработка AI-агентов | Частые разрывы в многошаговых диалогах | Высокий |
| Пакетная обработка данных | Задачи не могут быть завершены полностью | Высокий |
| Приложения реального времени | Ухудшение пользовательского опыта из-за отказов | Высокий |
| Генерация кода | Обрыв вывода длинных фрагментов кода | Средний |
| Тестирование и отладка | Резкое снижение эффективности разработки | Средний |
Подробный разбор механизма лимитов (Rate Limit) в Qwen3-Max
Официальные квоты Alibaba Cloud
Согласно официальной документации Alibaba Cloud Model Studio, для Qwen3-Max установлены следующие ограничения:
| Версия модели | RPM (Запросов/мин) | TPM (Токенов/мин) | RPS (Запросов/сек) |
|---|---|---|---|
| qwen3-max | 600 | 1 000 000 | 10 |
| qwen3-max-2025-09-23 | 60 | 100 000 | 1 |
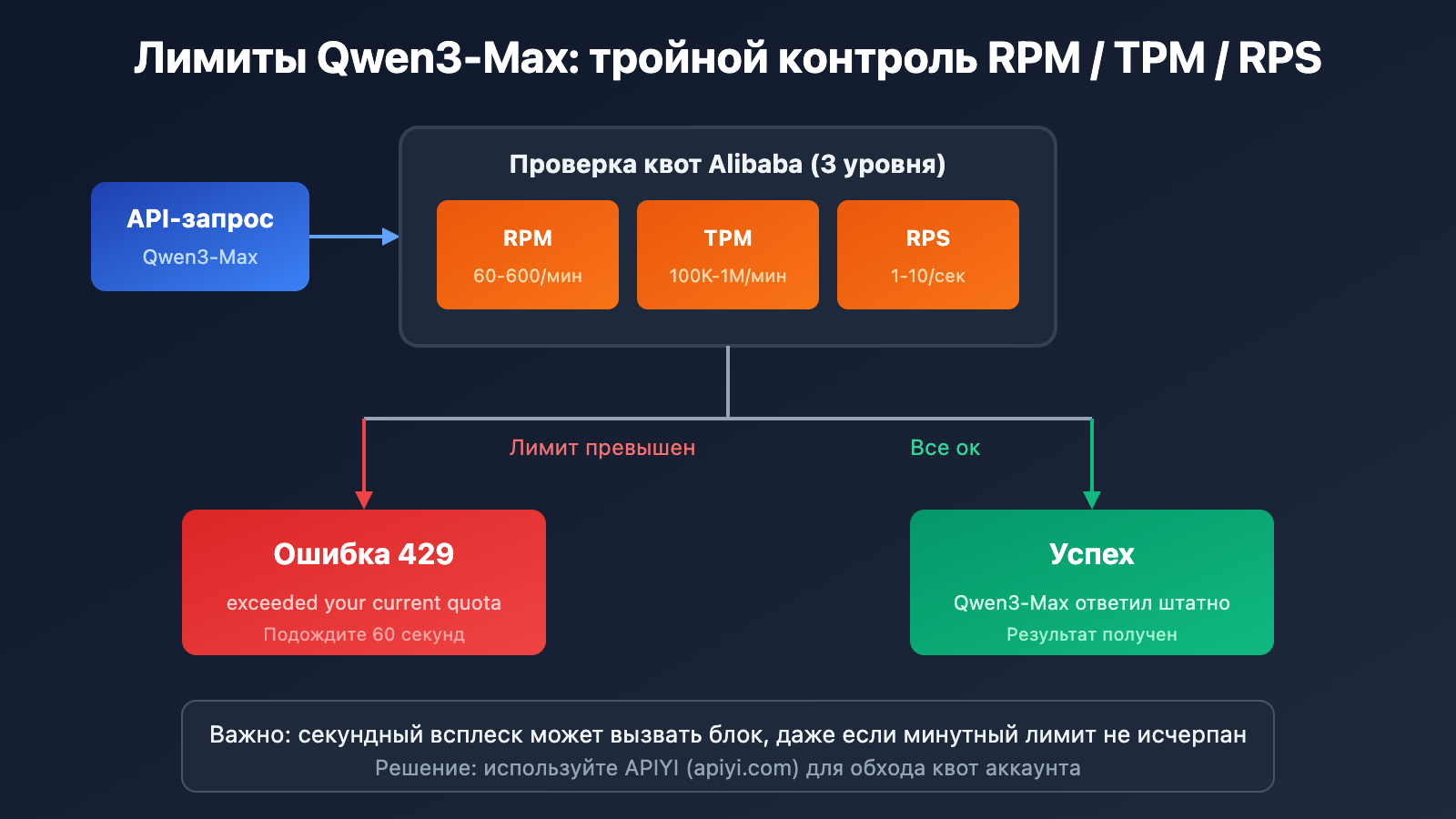
4 сценария срабатывания лимитов Qwen3-Max
Alibaba Cloud применяет механизм двойного контроля. При срабатывании любого условия возвращается ошибка 429:
| Тип ошибки | Сообщение | Причина |
|---|---|---|
| Превышение частоты запросов | Requests rate limit exceeded | Превышен RPM или RPS |
| Превышение лимита токенов | You exceeded your current quota | Превышен TPM или TPS |
| Защита от всплесков | Request rate increased too quickly | Слишком резкий рост числа запросов |
| Исчерпание лимита | Free allocated quota exceeded | Закончились бесплатные токены |
Формула расчета лимитов
Фактическое ограничение = min(Лимит RPM, RPS × 60)
= min(Лимит TPM, TPS × 60)
Важно: Даже если суммарно за минуту вы не вышли за рамки, резкий скачок запросов в течение одной секунды может привести к блокировке.
5 способов решить проблему с лимитами Qwen3-Max
Обзор решений
| Решение | Сложность | Эффект | Стоимость | Когда использовать |
|---|---|---|---|---|
| API-прокси (APIYI) | Низкая | Полное решение | Экономнее | В любой ситуации |
| Сглаживание трафика | Средняя | Облегчение | Бесплатно | При небольших превышениях |
| Ротация аккаунтов | Высокая | Облегчение | Высокая | Корпоративный сектор |
| Фолбэк на другие модели | Средняя | Резервный вариант | Средняя | Для второстепенных задач |
| Запрос на повышение квот | Низкая | Ограниченный | Бесплатно | Постоянным пользователям |
Способ 1: Использование прокси-сервиса APIYI (Рекомендуется)
Это самый простой и эффективный способ. При использовании платформы APIYI вы обходите жесткие квоты, привязанные к конкретному аккаунту Alibaba Cloud.
Почему APIYI решает проблему лимитов
| Параметр | Прямое подключение | Через APIYI |
|---|---|---|
| Ограничение квот | RPM/TPM на уровне аккаунта | Общий пул ресурсов платформы |
| Частота ошибок 429 | Часто | Практически отсутствуют |
| Цена | Официальная цена | Скидка (множитель 0.88) |
| Стабильность | Зависит от вашего аккаунта | Гарантирована мульти-каналами |
Пример кода (Python)
from openai import OpenAI
# Используем APIYI, чтобы забыть о лимитах и 429 ошибках
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen3-max",
messages=[
{"role": "user", "content": "Объясни принцип работы архитектуры MoE"}
]
)
print(response.choices[0].message.content)
🎯 Вердикт: Использование apiyi.com для работы с Qwen3-Max не только снимает проблему лимитов, но и обходится дешевле (тариф 0.88 от официального). APIYI сотрудничает с Alibaba Cloud напрямую, обеспечивая стабильность и выгодные условия.
Посмотреть полный код (с обработкой ошибок и ретраями)
import time
from openai import OpenAI
from openai import APIError, RateLimitError
class Qwen3MaxClient:
"""Клиент для Qwen3-Max через APIYI — работаем без лимитов"""
def __init__(self, api_key: str):
self.client = OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # Эндпоинт APIYI
)
self.model = "qwen3-max"
def chat(self, message: str, max_retries: int = 3) -> str:
"""
Отправка сообщения. Через APIYI лимиты практически недостижимы.
"""
for attempt in range(max_retries):
try:
response = self.client.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": message}],
max_tokens=4096
)
return response.choices[0].message.content
except RateLimitError as e:
# С APIYI вы вряд ли сюда попадете, но на всякий случай:
if attempt < max_retries - 1:
wait_time = 2 ** attempt
print(f"Лимит превышен, повтор через {wait_time} сек...")
time.sleep(wait_time)
else:
raise e
except APIError as e:
print(f"Ошибка API: {e}")
raise e
return ""
def batch_chat(self, messages: list[str]) -> list[str]:
"""Массовая обработка сообщений без страха перед 429"""
results = []
for msg in messages:
result = self.chat(msg)
results.append(result)
return results
# Пример использования
if __name__ == "__main__":
client = Qwen3MaxClient(api_key="your-apiyi-key")
# Одиночный запрос
response = client.chat("Напиши алгоритм быстрой сортировки на Python")
print(response)
# Массовые запросы — APIYI проглотит их без проблем
questions = [
"Что такое архитектура MoE?",
"Сравни Transformer и RNN",
"Как работает механизм внимания (attention)?"
]
answers = client.batch_chat(questions)
for q, a in zip(questions, answers):
print(f"Q: {q}\nA: {a}\n")
Способ 2: Стратегии сглаживания запросов
Если вы работаете напрямую с Alibaba Cloud, придется внедрять механизмы контроля трафика.
Экспоненциальная задержка (Backoff)
import time
import random
def call_with_backoff(func, max_retries=5):
"""Стратегия повторов с экспоненциальной задержкой"""
for attempt in range(max_retries):
try:
return func()
except Exception as e:
if "429" in str(e) and attempt < max_retries - 1:
# Экспоненциальная задержка + рандомизация (jitter)
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"Лимит! Ждем {wait_time:.2f} сек перед повтором...")
time.sleep(wait_time)
else:
raise e
Буферизация через очередь
import asyncio
from collections import deque
class RequestQueue:
"""Очередь для плавного распределения запросов к Qwen3-Max"""
def __init__(self, rpm_limit=60):
self.queue = deque()
self.interval = 60 / rpm_limit # Интервал между запросами
self.last_request = 0
async def throttled_request(self, request_func):
"""Выполнение запроса с ограничением скорости"""
now = time.time()
wait_time = self.interval - (now - self.last_request)
if wait_time > 0:
await asyncio.sleep(wait_time)
self.last_request = time.time()
return await request_func()
На заметку: Сглаживание лишь смягчает проблему. Для серьезных нагрузок лучше перейти на APIYI.
Способ 3: Ротация нескольких аккаунтов
Корпоративные пользователи иногда используют пул аккаунтов для увеличения суммарной квоты.

from itertools import cycle
class MultiAccountClient:
"""Клиент с ротацией аккаунтов"""
def __init__(self, api_keys: list[str]):
self.clients = cycle([
OpenAI(api_key=key, base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")
for key in api_keys
])
def chat(self, message: str) -> str:
client = next(self.clients)
response = client.chat.completions.create(
model="qwen3-max",
messages=[{"role": "user", "content": message}]
)
return response.choices[0].message.content
| Количество аккаунтов | Эффективный RPM | Эффективный TPM | Сложность управления |
|---|---|---|---|
| 1 | 600 | 1 000 000 | Низкая |
| 3 | 1 800 | 3 000 000 | Средняя |
| 5 | 3 000 | 5 000 000 | Высокая |
| 10 | 6 000 | 10 000 000 | Очень высокая |
💡 Совет: Управление пулом аккаунтов — это головная боль с оплатой и мониторингом. Проще использовать APIYI, где все заботы о пуле берет на себя платформа.
Способ 4: Фолбэк (降级) на резервную модель
Если Qwen3-Max "уперся" в лимит, можно автоматически переключиться на модель попроще.
class FallbackClient:
"""Клиент Qwen с поддержкой фолбэка"""
MODEL_PRIORITY = [
"qwen3-max", # Основная
"qwen-plus", # Резерв 1
"qwen-turbo", # Резерв 2
]
def __init__(self, api_key: str):
self.client = OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # Рекомендуется использовать через APIYI
)
def chat(self, message: str) -> tuple[str, str]:
"""Возвращает (текст ответа, модель)"""
for model in self.MODEL_PRIORITY:
try:
response = self.client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": message}]
)
return response.choices[0].message.content, model
except Exception as e:
if "429" in str(e):
print(f"Лимит {model}, переключаемся на более легкую модель...")
continue
raise e
raise Exception("Все модели недоступны")
Способ 5: Запрос на повышение квот
Для долгосрочных проектов можно попробовать официально увеличить лимиты в Alibaba Cloud.
Как подать заявку:
- Зайдите в консоль Alibaba Cloud.
- Перейдите в раздел управления квотами Model Studio.
- Отправьте запрос на повышение (Quota Increase).
- Ждите рассмотрения (обычно от 1 до 3 рабочих дней).
Требования:
- Верифицированный аккаунт.
- Отсутствие задолженностей.
- Четкое описание вашего сценария использования.
Сравнение затрат при использовании Qwen3-Max и решение проблем с лимитами (Rate Limits)
Анализ стоимости
| Провайдер | Цена за вход (0-32K) | Цена за выход | Ситуация с лимитами |
|---|---|---|---|
| Alibaba Cloud (прямо) | $1.20/1 млн | $6.00/1 млн | Строгие ограничения RPM/TPM |
| APIYI (скидка 12%) | $1.06/1 млн | $5.28/1 млн | Практически без ограничений |
| Разница | Экономия 12% | Экономия 12% | — |
Расчет общих затрат
Допустим, объем вызовов в месяц составляет 10 миллионов токенов (входные и выходные данные поровну):
| Вариант | Ежемесячные расходы | Влияние лимитов | Общая оценка |
|---|---|---|---|
| Alibaba Cloud (прямо) | $36.00 | Частые прерывания, нужны повторные попытки | Фактическая стоимость выше |
| Прокси APIYI | $31.68 | Стабильно, без прерываний | Лучшее соотношение цены и качества |
| Схема с несколькими аккаунтами | $36.00+ | Высокие затраты на управление | Не рекомендуется |
💰 Оптимизация затрат: APIYI (apiyi.com) является партнером Alibaba Cloud. Это позволяет не только получить стандартную скидку 12%, но и полностью решить проблему с ограничениями скорости. Для сценариев со средней и высокой частотой использования общая стоимость владения получается ниже.
Часто задаваемые вопросы
Q1: Почему я сталкиваюсь с лимитами Qwen3-Max в самом начале использования?
У Alibaba Cloud Model Studio бесплатные лимиты для новых аккаунтов ограничены, а для новой версии qwen3-max-2025-09-23 квоты еще ниже (RPM 60, TPM 100,000). Если вы используете Snapshot-версии, ограничения будут еще жестче.
Рекомендуем использовать APIYI (apiyi.com) — это позволит обойти квоты на уровне индивидуального аккаунта.
Q2: Как быстро снимаются ограничения?
Лимиты Alibaba Cloud работают по принципу скользящего окна:
- Ограничение RPM (запросы в минуту): восстановление примерно через 60 секунд.
- Ограничение TPM (токены в минуту): восстановление примерно через 60 секунд.
- Защита от всплесков трафика: может потребоваться больше времени.
Использование платформы APIYI избавляет от постоянного ожидания и повышает эффективность разработки.
Q3: Как обеспечивается стабильность прокси-сервиса APIYI?
APIYI имеет партнерские отношения с Alibaba Cloud и использует модель «общего пула квот» уровня платформы:
- Балансировка нагрузки по нескольким каналам.
- Автоматическое переключение при сбоях (failover).
- Гарантия доступности 99.9%.
По сравнению с ограничениями личного аккаунта, сервис уровня платформы гораздо более стабилен и надежен.
Q4: Нужно ли сильно менять код для перехода на APIYI?
Почти нет. APIYI полностью совместим с форматом OpenAI SDK, вам нужно изменить всего две строки:
# До (прямое подключение к Alibaba Cloud)
client = OpenAI(
api_key="sk-xxx",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# После (через прокси APIYI)
client = OpenAI(
api_key="your-apiyi-key", # Меняем на ключ APIYI
base_url="https://api.apiyi.com/v1" # Меняем адрес на APIYI
)
Названия моделей и форматы параметров полностью идентичны, никаких других правок не требуется.
Q5: Какие еще модели, кроме Qwen3-Max, поддерживает APIYI?
Платформа APIYI поддерживает единый доступ к более чем 200 популярным моделям ИИ, включая:
- Вся серия Qwen: qwen3-max, qwen-plus, qwen-turbo, qwen-vl и др.
- Серия Claude: claude-3-opus, claude-3-sonnet, claude-3-haiku.
- Серия GPT: gpt-4o, gpt-4-turbo, gpt-3.5-turbo.
- Другие: Gemini, DeepSeek, Moonshot и т.д.
Все модели доступны через единый интерфейс и один API Key.
Итоги: Решение проблемы лимитов (Rate Limits) для Qwen3-Max
Дерево принятия решений
Столкнулись с ошибкой 429 в Qwen3-Max
│
├─ Нужно радикальное решение → Используйте прокси APIYI (Рекомендуется)
│
├─ Небольшие ограничения → Сглаживание запросов + экспоненциальная задержка
│
├─ Масштабное использование → Ротация аккаунтов или APIYI Enterprise
│
└─ Второстепенные задачи → Переход на резервную модель
Краткий обзор ключевых моментов
| Ключевой момент | Описание |
|---|---|
| Причина лимитов | Тройное ограничение Alibaba Cloud: RPM/TPM/RPS |
| Лучшее решение | Сервис APIYI, решает проблему полностью |
| Выгода | Скидка до 88%, дешевле прямого подключения |
| Сложность миграции | Нужно только поменять base_url и api_key |
Рекомендуем использовать APIYI (apiyi.com) для быстрого обхода лимитов Qwen3-Max — это обеспечит стабильную работу и приятные цены.
Справочные материалы
-
Документация Alibaba Cloud по лимитам (Rate Limits): Официальное описание ограничений
- Ссылка:
alibabacloud.com/help/en/model-studio/rate-limit
- Ссылка:
-
Документация Alibaba Cloud по кодам ошибок: Подробная расшифровка кодов
- Ссылка:
alibabacloud.com/help/en/model-studio/error-code
- Ссылка:
-
Документация модели Qwen3-Max: Официальные технические характеристики
- Ссылка:
alibabacloud.com/help/en/model-studio/what-is-qwen-llm
- Ссылка:
Техподдержка: Если возникли вопросы по использованию Qwen3-Max, вы всегда можете получить помощь в APIYI (apiyi.com).