Ao chamar o gemini-2.5-flash, você encontrou o erro Thinking level is not supported for this model, mas ao mudar para o gemini-3-flash-preview tudo funcionou normalmente? Essa é uma mudança no design de parâmetros introduzida pela Google Gemini API na atualização geracional do modelo. Este artigo analisará sistematicamente as diferenças fundamentais no suporte aos parâmetros do modo de pensamento entre o Gemini 2.5 e o 3.0.
Valor Central: Ao ler este artigo, você entenderá as diferenças essenciais no design dos parâmetros do modo de pensamento das séries Gemini 2.5 e 3.0, dominará os métodos de configuração corretos e evitará falhas nas chamadas de API causadas pelo uso misto de parâmetros.

Principais Pontos da Evolução dos Parâmetros do Modo de Pensamento do Gemini
| Série do Modelo | Parâmetros Suportados | Tipo de Parâmetro | Intervalo Disponível | Valor Padrão | Pode ser desativado? |
|---|---|---|---|---|---|
| Gemini 2.5 Pro | thinking_budget |
Inteiro (128-32768) | Orçamento exato de tokens | 8192 | ❌ Não desativável |
| Gemini 2.5 Flash | thinking_budget |
Inteiro (0-24576) ou -1 | Orçamento de tokens exato ou dinâmico | -1 (dinâmico) | ✅ Sim (definir como 0) |
| Gemini 2.5 Flash-Lite | thinking_budget |
Inteiro (512-24576) | Orçamento exato de tokens | 0 (desativado) | ✅ Desativado por padrão |
| Gemini 3.0 Pro | thinking_level |
Enum ("low"/"high") | Nível semântico | "high" | ❌ Não totalmente desativável |
| Gemini 3.0 Flash | thinking_level |
Enum ("minimal"/"low"/"medium"/"high") | Nível semântico | "high" | ⚠️ Apenas "minimal" |
Diferenças de Design entre Gemini 2.5 e 3.0 no Modo de Pensamento
Diferença Principal: A série Gemini 2.5 utiliza thinking_budget (sistema de orçamento de tokens), enquanto a série Gemini 3.0 utiliza thinking_level (sistema de níveis semânticos). Esses dois parâmetros são totalmente incompatíveis, e o uso na versão errada do modelo resultará em um erro 400 Bad Request.
A principal razão pela qual o Google introduziu o thinking_level no Gemini 3.0 é simplificar a complexidade da configuração e aumentar a eficiência da inferência. O sistema de orçamento de tokens do Gemini 2.5 exige que os desenvolvedores estimem com precisão a quantidade de tokens de pensamento, enquanto o sistema de níveis do Gemini 3.0 abstrai essa complexidade em 4 níveis semânticos. O modelo aloca internamente o orçamento ideal de tokens, alcançando uma velocidade de inferência até 2 vezes maior.
💡 Sugestão Técnica: No desenvolvimento real, recomendamos usar a plataforma APIYI (apiyi.com) para realizar testes de troca de modelo. A plataforma oferece uma interface de API unificada, suportando todas as séries de modelos Gemini 2.5 e 3.0, facilitando a verificação rápida da compatibilidade e do efeito prático de diferentes parâmetros do modo de pensamento.
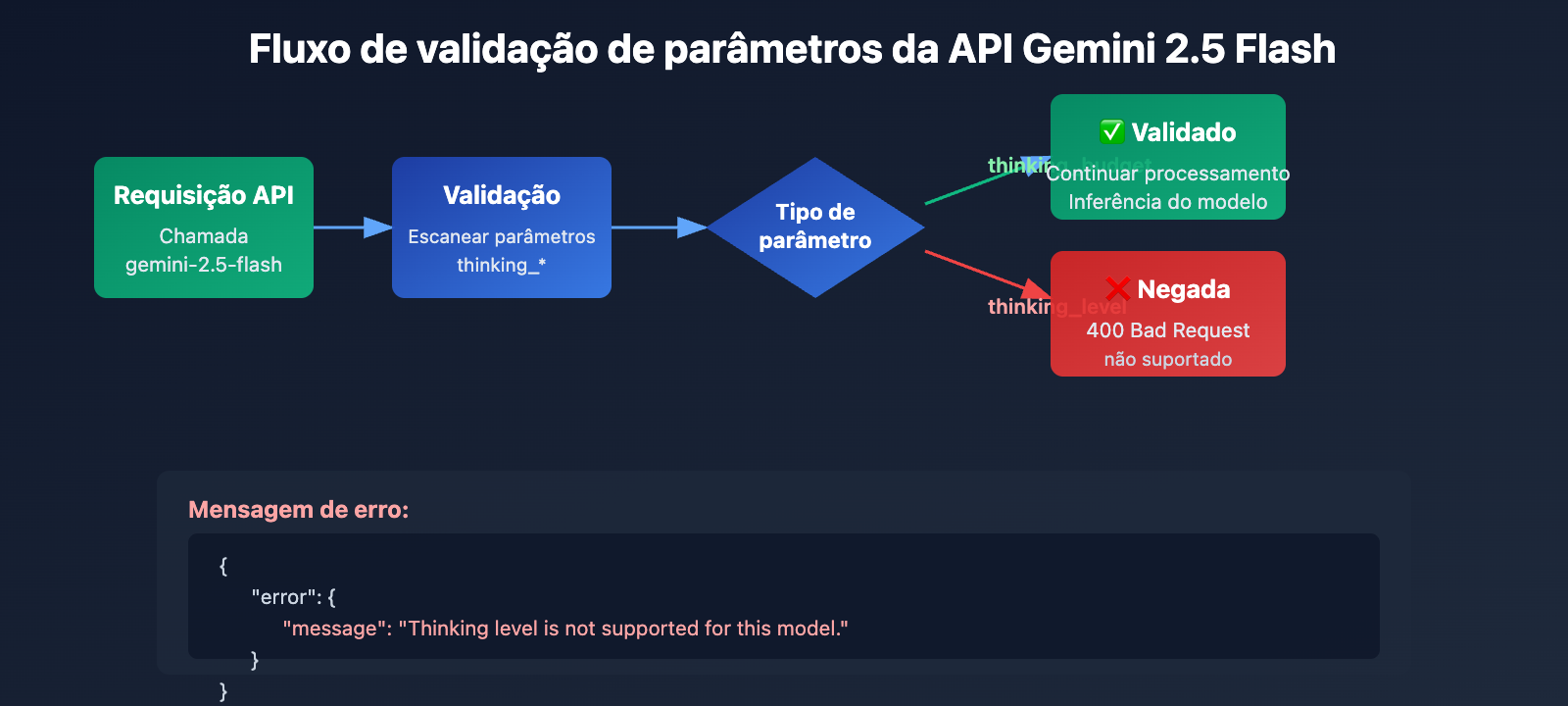
Causa Raiz 1: A série Gemini 2.5 não suporta o parâmetro thinking_level
Isolamento geracional no design de parâmetros da API
Os modelos da série Gemini 2.5 (incluindo Pro, Flash e Flash-Lite) não reconhecem de forma alguma o parâmetro thinking_level em seu design de API. Ao passar o parâmetro thinking_level ao chamar o gemini-2.5-flash, a API retornará o seguinte erro:
{
"error": {
"message": "Thinking level is not supported for this model.",
"type": "upstream_error",
"code": 400
}
}
Mecanismo de acionamento do erro:
- A camada de validação da API do modelo Gemini 2.5 não contém a definição do parâmetro
thinking_level. - Qualquer requisição que contenha
thinking_levelserá rejeitada diretamente, sem tentativa de mapeamento parathinking_budget. - Este é um isolamento de parâmetros codificado rigidamente (hardcoded), sem conversão automática ou compatibilidade retroativa.
Parâmetro correto para a série Gemini 2.5: thinking_budget
Especificação de parâmetros do Gemini 2.5 Flash:
# 正确配置示例
extra_body = {
"thinking_budget": -1 # 动态思考模式
}
# 或禁用思考
extra_body = {
"thinking_budget": 0 # 完全禁用
}
# 或精确控制
extra_body = {
"thinking_budget": 2048 # 精确 2048 token 预算
}
Intervalo de valores de thinking_budget para o Gemini 2.5 Flash:
| Valor | Significado | Cenário recomendado |
|---|---|---|
0 |
Desativa totalmente o modo de pensamento | Seguimento de instruções simples, aplicações de alto rendimento |
-1 |
Modo de pensamento dinâmico (até 8192 tokens) | Cenários gerais, adaptação automática à complexidade |
512-24576 |
Orçamento preciso de tokens | Aplicações sensíveis a custo, requer controle preciso |
🎯 Sugestão de escolha: Ao mudar para o Gemini 2.5 Flash, recomenda-se testar primeiro o impacto de diferentes valores do parâmetro
thinking_budgetna qualidade da resposta e na latência através da plataforma APIYI (apiyi.com). A plataforma permite alternar rapidamente as configurações de parâmetros, facilitando encontrar o valor de orçamento mais adequado para o seu cenário de negócio.
Causa Raiz 2: A série Gemini 3.0 não suporta o parâmetro thinking_budget
Incompatibilidade futura no design de parâmetros
Embora a documentação oficial do Google afirme que o Gemini 3.0 ainda aceita o parâmetro thinking_budget para fins de compatibilidade retroativa, testes reais mostram que:
- O uso de
thinking_budgetpode levar a uma queda de desempenho - A documentação oficial recomenda explicitamente o uso de
thinking_level - Algumas implementações de API podem rejeitar completamente o
thinking_budget
Parâmetro correto para o Gemini 3.0 Flash: thinking_level
# 正确配置示例
extra_body = {
"thinking_level": "medium" # 中等强度推理
}
# 或最小思考 (接近禁用)
extra_body = {
"thinking_level": "minimal" # 最小思考模式
}
# 或高强度推理 (默认)
extra_body = {
"thinking_level": "high" # 深度推理
}
Explicação dos níveis de thinking_level para o Gemini 3.0 Flash:
| Nível | Intensidade de Raciocínio | Latência | Custo | Cenário recomendado |
|---|---|---|---|---|
"minimal" |
Quase sem raciocínio | Mínima | Mínimo | Seguimento de instruções simples, alto rendimento |
"low" |
Raciocínio superficial | Baixa | Baixo | Chatbots, QA leve |
"medium" |
Raciocínio médio | Média | Médio | Tarefas de raciocínio geral, geração de código |
"high" |
Raciocínio profundo | Alta | Alto | Resolução de problemas complexos, análise profunda (padrão) |
Restrições especiais do Gemini 3.0 Pro
Importante: O Gemini 3.0 Pro não permite desativar completamente o modo de pensamento; mesmo configurando thinking_level: "low", ele manterá uma certa capacidade de raciocínio. Se precisar de uma resposta sem pensamento para obter velocidade máxima, você deve usar o thinking_budget: 0 do Gemini 2.5 Flash.
# Gemini 3.0 Pro 可用等级 (仅 2 种)
extra_body = {
"thinking_level": "low" # 最低等级 (仍有推理)
}
# 或
extra_body = {
"thinking_level": "high" # 默认高强度推理
}
💰 Otimização de custos: Para projetos sensíveis ao orçamento que precisam desativar completamente o modo de pensamento para reduzir custos, recomenda-se chamar a API do Gemini 2.5 Flash através da plataforma APIYI (apiyi.com). A plataforma oferece métodos de faturamento flexíveis e preços mais competitivos, sendo ideal para cenários que exigem controle preciso de custos.
Causa Raiz 3: Restrições de Parâmetros para Modelos de Imagem e Variantes Especiais
O modelo Gemini 2.5 Flash Image não suporta o modo de pensamento
Descoberta importante: Modelos de visão como o gemini-2.5-flash-image não suportam de forma alguma qualquer parâmetro de modo de pensamento, seja thinking_budget ou thinking_level.
Exemplo de erro:
# Ao chamar o gemini-2.5-flash-image
response = client.chat.completions.create(
model="gemini-2.5-flash-image",
messages=[{"role": "user", "content": "Analise esta imagem"}],
extra_body={
"thinking_budget": -1 # ❌ Erro: O modelo de imagem não suporta isso
}
)
# Retorna o erro: "This model doesn't support thinking"
Forma correta:
# Ao chamar modelos de imagem, não envie nenhum parâmetro de pensamento
response = client.chat.completions.create(
model="gemini-2.5-flash-image",
messages=[{"role": "user", "content": "Analise esta imagem"}],
# ✅ Não envie thinking_budget ou thinking_level
)
Valores padrão especiais do Gemini 2.5 Flash-Lite
Principais diferenças entre o Gemini 2.5 Flash-Lite e a versão Flash padrão:
- Modo de pensamento desativado por padrão (
thinking_budget: 0) - É necessário configurar explicitamente o
thinking_budgetcom um valor diferente de zero para ativar o pensamento - Intervalo de orçamento suportado: 512-24576 tokens
# Ativando o modo de pensamento no Gemini 2.5 Flash-Lite
extra_body = {
"thinking_budget": 512 # Valor mínimo não nulo para ativar o pensamento leve
}
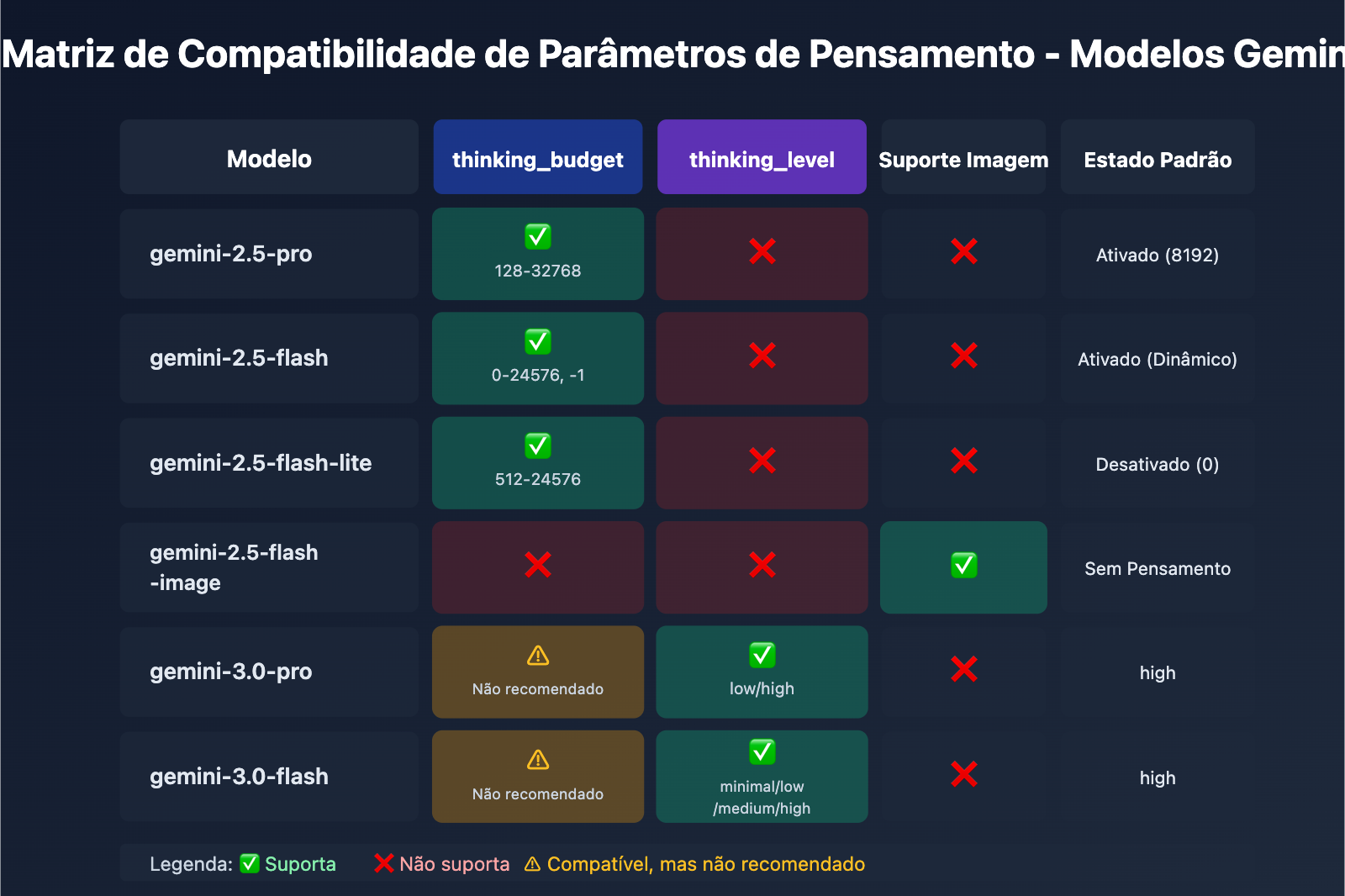
| Modelo | thinking_budget | thinking_level | Suporte de Imagem | Estado Padrão do Pensamento |
|---|---|---|---|---|
| gemini-2.5-pro | ✅ Suporta (128-32768) | ❌ Não suporta | ❌ | Ativado por padrão (8192) |
| gemini-2.5-flash | ✅ Suporta (0-24576, -1) | ❌ Não suporta | ❌ | Ativado por padrão (Dinâmico) |
| gemini-2.5-flash-lite | ✅ Suporta (512-24576) | ❌ Não suporta | ❌ | Desativado por padrão (0) |
| gemini-2.5-flash-image | ❌ Não suporta | ❌ Não suporta | ✅ | Sem modo de pensamento |
| gemini-3.0-pro | ⚠️ Compatível, mas não recomendado | ✅ Recomendado (low/high) | ❌ | Padrão: high |
| gemini-3.0-flash | ⚠️ Compatível, mas não recomendado | ✅ Recomendado (minimal/low/medium/high) | ❌ | Padrão: high |
🚀 Início Rápido: Recomendamos usar a plataforma APIYI (apiyi.com) para testar rapidamente a compatibilidade dos parâmetros de pensamento em diferentes modelos. A plataforma oferece acesso imediato a toda a série de modelos Gemini, sem necessidade de configurações complexas — você faz a integração e a validação dos parâmetros em menos de 5 minutos.
Solução 1: Baseada em uma função de adaptação de parâmetros por versão do modelo
Seletor inteligente de parâmetros (Suporte a toda a linha Gemini)
def get_gemini_thinking_config(model_name: str, intensity: str = "medium") -> dict:
"""
Seleciona automaticamente os parâmetros corretos do modo de raciocínio com base no nome do modelo Gemini.
Args:
model_name: Nome do modelo Gemini
intensity: Intensidade do raciocínio ("none", "minimal", "low", "medium", "high", "dynamic")
Returns:
Dicionário de parâmetros adequado para extra_body; retorna um dicionário vazio se o modelo não suportar raciocínio.
"""
# Lista de modelos Gemini 3.0
gemini_3_models = [
"gemini-3.0-flash-preview", "gemini-3.0-pro-preview",
"gemini-3-flash", "gemini-3-pro"
]
# Lista de modelos padrão Gemini 2.5
gemini_2_5_models = [
"gemini-2.5-flash", "gemini-2.5-pro",
"gemini-2.5-flash-lite", "gemini-2-flash", "gemini-2-pro"
]
# Lista de modelos de imagem (não suportam raciocínio)
image_models = [
"gemini-2.5-flash-image", "gemini-flash-image",
"gemini-pro-vision"
]
# Verifica se é um modelo de imagem
if any(img_model in model_name for img_model in image_models):
print(f"⚠️ Aviso: {model_name} não suporta parâmetros de modo de raciocínio, retornando configuração vazia")
return {}
# A linha Gemini 3.0 usa thinking_level
if any(m in model_name for m in gemini_3_models):
level_map = {
"none": "minimal", # O 3.0 não permite desativar totalmente, usa-se minimal
"minimal": "minimal",
"low": "low",
"medium": "medium",
"high": "high",
"dynamic": "high"
}
# O Gemini 3.0 Pro suporta apenas low e high
if "pro" in model_name.lower():
if intensity in ["none", "minimal", "low"]:
return {"thinking_level": "low"}
else:
return {"thinking_level": "high"}
# O Gemini 3.0 Flash suporta todos os 4 níveis
return {"thinking_level": level_map.get(intensity, "medium")}
# A linha Gemini 2.5 usa thinking_budget
elif any(m in model_name for m in gemini_2_5_models):
budget_map = {
"none": 0, # Desativa completamente
"minimal": 512, # Orçamento mínimo
"low": 2048, # Baixa intensidade
"medium": 8192, # Média intensidade
"high": 16384, # Alta intensidade
"dynamic": -1 # Adaptação dinâmica
}
budget = budget_map.get(intensity, -1)
# O Gemini 2.5 Pro não permite desativação (mínimo 128)
if "pro" in model_name.lower() and budget == 0:
print(f"⚠️ Aviso: {model_name} não suporta desativar o raciocínio, ajustando automaticamente para o valor mínimo de 128")
budget = 128
# O valor mínimo para o Gemini 2.5 Flash-Lite é 512
if "lite" in model_name.lower() and budget > 0 and budget < 512:
print(f"⚠️ Aviso: O orçamento mínimo para {model_name} é 512, ajustando automaticamente")
budget = 512
return {"thinking_budget": budget}
else:
print(f"⚠️ Aviso: Modelo desconhecido {model_name}, usando parâmetros padrão do Gemini 3.0")
return {"thinking_level": "medium"}
# Exemplo de uso
import openai
client = openai.OpenAI(
api_key="SUA_CHAVE_API",
base_url="https://api.apiyi.com/v1"
)
# Testando Gemini 2.5 Flash
model_2_5 = "gemini-2.5-flash"
config_2_5 = get_gemini_thinking_config(model_2_5, intensity="dynamic")
print(f"Configuração {model_2_5}: {config_2_5}")
# Saída: Configuração gemini-2.5-flash: {'thinking_budget': -1}
response_2_5 = client.chat.completions.create(
model=model_2_5,
messages=[{"role": "user", "content": "Explique o entrelaçamento quântico"}],
extra_body=config_2_5
)
# Testando Gemini 3.0 Flash
model_3_0 = "gemini-3.0-flash-preview"
config_3_0 = get_gemini_thinking_config(model_3_0, intensity="medium")
print(f"Configuração {model_3_0}: {config_3_0}")
# Saída: Configuração gemini-3.0-flash-preview: {'thinking_level': 'medium'}
response_3_0 = client.chat.completions.create(
model=model_3_0,
messages=[{"role": "user", "content": "Explique o entrelaçamento quântico"}],
extra_body=config_3_0
)
# Testando modelo de imagem
model_image = "gemini-2.5-flash-image"
config_image = get_gemini_thinking_config(model_image, intensity="high")
print(f"Configuração {model_image}: {config_image}")
# Saída: ⚠️ Aviso: gemini-2.5-flash-image não suporta parâmetros de modo de raciocínio, retornando configuração vazia
# Saída: Configuração gemini-2.5-flash-image: {}
💡 Melhor Prática: Em cenários onde é necessário alternar dinamicamente entre modelos Gemini, recomendamos realizar testes de adaptação de parâmetros através da plataforma APIYI (apiyi.com). A plataforma oferece suporte completo às séries Gemini 2.5 e 3.0, facilitando a validação da qualidade das respostas e das diferenças de custo em diversas configurações.
Solução 2: Estratégia de migração do Gemini 2.5 para o 3.0
Tabela de correspondência de parâmetros de modo de raciocínio
| Configuração Gemini 2.5 Flash | Configuração equivalente Gemini 3.0 Flash | Comparação de Latência | Comparação de Custo |
|---|---|---|---|
thinking_budget: 0 |
thinking_level: "minimal" |
3.0 é mais rápido (aprox. 2x) | Semelhante |
thinking_budget: 512 |
thinking_level: "low" |
3.0 é mais rápido | Semelhante |
thinking_budget: 2048 |
thinking_level: "low" |
3.0 é mais rápido | Semelhante |
thinking_budget: 8192 |
thinking_level: "medium" |
3.0 é mais rápido | Um pouco mais alto |
thinking_budget: 16384 |
thinking_level: "high" |
3.0 é mais rápido | Um pouco mais alto |
thinking_budget: -1 (Dinâmico) |
thinking_level: "high" (Padrão) |
3.0 é significativamente mais rápido | 3.0 é mais alto |
Exemplo de código para migração
def migrate_to_gemini_3(old_model: str, old_config: dict) -> tuple[str, dict]:
"""
Migra do Gemini 2.5 para o Gemini 3.0
Args:
old_model: Nome do modelo Gemini 2.5
old_config: Configuração extra_body do Gemini 2.5
Returns:
(Novo nome do modelo, Novo dicionário de configuração)
"""
# Mapeamento de nomes de modelos
model_map = {
"gemini-2.5-flash": "gemini-3.0-flash-preview",
"gemini-2.5-pro": "gemini-3.0-pro-preview",
"gemini-2-flash": "gemini-3-flash",
"gemini-2-pro": "gemini-3-pro"
}
new_model = model_map.get(old_model, "gemini-3.0-flash-preview")
# Conversão de parâmetros
if "thinking_budget" in old_config:
budget = old_config["thinking_budget"]
# Converte para thinking_level
if budget == 0:
new_level = "minimal"
elif budget <= 2048:
new_level = "low"
elif budget <= 8192:
new_level = "medium"
else:
new_level = "high"
# Gemini 3.0 Pro suporta apenas low/high
if "pro" in new_model and new_level in ["minimal", "medium"]:
new_level = "low" if new_level == "minimal" else "high"
new_config = {"thinking_level": new_level}
else:
# Configuração padrão
new_config = {"thinking_level": "medium"}
return new_model, new_config
# Exemplo de migração
old_model = "gemini-2.5-flash"
old_config = {"thinking_budget": -1}
new_model, new_config = migrate_to_gemini_3(old_model, old_config)
print(f"Antes da migração: {old_model} {old_config}")
print(f"Depois da migração: {new_model} {new_config}")
# Saída:
# Antes da migração: gemini-2.5-flash {'thinking_budget': -1}
# Depois da migração: gemini-3.0-flash-preview {'thinking_level': 'high'}
# Chamada usando a nova configuração
response = client.chat.completions.create(
model=new_model,
messages=[{"role": "user", "content": "Sua pergunta"}],
extra_body=new_config
)
🎯 Sugestão de Migração: Ao migrar do Gemini 2.5 para o 3.0, recomendamos realizar primeiro um teste A/B através da plataforma APIYI (apiyi.com). A plataforma permite alternar versões de modelos rapidamente, facilitando a comparação da qualidade da resposta, latência e diferença de custos para garantir uma migração suave.
Perguntas Frequentes
P1: Por que meu código funciona no Gemini 3.0, mas dá erro ao mudar para o 2.5?
Causa: Seu código está usando o parâmetro thinking_level, que é exclusivo da série Gemini 3.0. A série 2.5 não oferece suporte a esse parâmetro.
Solução:
# Código incorreto (apenas para o 3.0)
extra_body = {
"thinking_level": "medium" # ❌ O 2.5 não reconhece
}
# Código correto (para o 2.5)
extra_body = {
"thinking_budget": 8192 # ✅ O 2.5 utiliza budget
}
Recomendamos usar a função get_gemini_thinking_config() mencionada anteriormente para adaptação automática, ou validar a compatibilidade de parâmetros rapidamente através da plataforma APIYI (apiyi.com).
P2: Qual a diferença de desempenho entre o Gemini 2.5 Flash e o Gemini 3.0 Flash?
De acordo com dados oficiais do Google e testes da comunidade:
| Indicador | Gemini 2.5 Flash | Gemini 3.0 Flash | Melhoria |
|---|---|---|---|
| Velocidade de Inferência | Base | 2x mais rápido | +100% |
| Latência | Base | Significativamente menor | Cerca de -50% |
| Eficiência de Pensamento | Budget fixo ou dinâmico | Otimização automática | Aumento de qualidade |
| Custo | Base | Um pouco mais alto (alta qualidade) | +10-20% |
Diferença central: O Gemini 3.0 utiliza alocação dinâmica de pensamento, pensando apenas o tempo necessário para cada tarefa, enquanto o budget fixo do 2.5 pode resultar em pensamento excessivo ou insuficiente.
Sugerimos realizar testes práticos na plataforma APIYI (apiyi.com), que oferece monitoramento de desempenho em tempo real e análise de custos para comparar o comportamento real de diferentes modelos.
P3: Como desativar completamente o modo de pensamento no Gemini 3.0?
Importante: O Gemini 3.0 Pro não permite desativar totalmente o modo de pensamento. Mesmo definindo thinking_level: "low", ele manterá uma capacidade leve de raciocínio.
Opções disponíveis:
- Gemini 3.0 Flash: Use
thinking_level: "minimal"para quase zero de pensamento (embora tarefas complexas de programação ainda possam gerar um raciocínio leve). - Gemini 3.0 Pro: O nível mínimo permitido é
thinking_level: "low".
Se você precisar desativar completamente:
# Apenas o Gemini 2.5 Flash suporta desativação total
model = "gemini-2.5-flash"
extra_body = {
"thinking_budget": 0 # Desativa completamente o pensamento
}
Para cenários que exigem velocidade máxima e não necessitam de raciocínio (como seguir instruções simples), recomendamos chamar o Gemini 2.5 Flash via APIYI (apiyi.com) com
thinking_budget: 0.
P4: Os modelos de imagem do Gemini suportam o modo de pensamento?
Não. Nenhum modelo de processamento de imagem do Gemini (como gemini-2.5-flash-image ou gemini-pro-vision) suporta parâmetros de modo de pensamento.
Exemplo de erro:
# ❌ Modelos de imagem não suportam nenhum parâmetro de pensamento
response = client.chat.completions.create(
model="gemini-2.5-flash-image",
messages=[...],
extra_body={
"thinking_budget": -1 # Causará um erro
}
)
Forma correta:
# ✅ Ao chamar modelos de imagem, não envie parâmetros de pensamento
response = client.chat.completions.create(
model="gemini-2.5-flash-image",
messages=[...],
# Não passe extra_body ou passe apenas parâmetros que não sejam de pensamento
)
Motivo técnico: A arquitetura de inferência dos modelos de imagem é focada na compreensão visual e não inclui o mecanismo de cadeia de pensamento (Chain of Thought) dos modelos de linguagem.
Resumo
Pontos fundamentais sobre o erro thinking_level not supported no Gemini 2.5 Flash:
- Isolamento de Parâmetros: O Gemini 2.5 só aceita
thinking_budget, e o 3.0 só aceitathinking_level. Eles são totalmente incompatíveis entre si. - Identificação do Modelo: Identifique a versão pelo nome do modelo: use
thinking_budgetpara a série 2.5 ethinking_levelpara a série 3.0. - Restrições de Modelos de Imagem: Modelos focados em imagem (como o
gemini-2.5-flash-image) não aceitam nenhum parâmetro de modo de pensamento. - Diferenças na Desativação: Somente o Gemini 2.5 Flash permite desativar o pensamento totalmente (
thinking_budget: 0); na série 3.0, o mínimo é o nívelminimal. - Estratégia de Migração: Ao migrar do 2.5 para o 3.0, você precisará mapear o
thinking_budgetpara othinking_levele considerar as mudanças em desempenho e custo.
Recomendamos utilizar a APIYI (apiyi.com) para validar rapidamente a compatibilidade dos parâmetros de pensamento e o efeito real em diferentes modelos. A plataforma suporta toda a linha Gemini, oferecendo uma interface unificada e faturamento flexível, ideal para testes comparativos e implantação em produção.
Autor: Equipe Técnica APIYI | Se tiver dúvidas técnicas, visite a APIYI (apiyi.com) para explorar mais soluções de integração de modelos de IA.