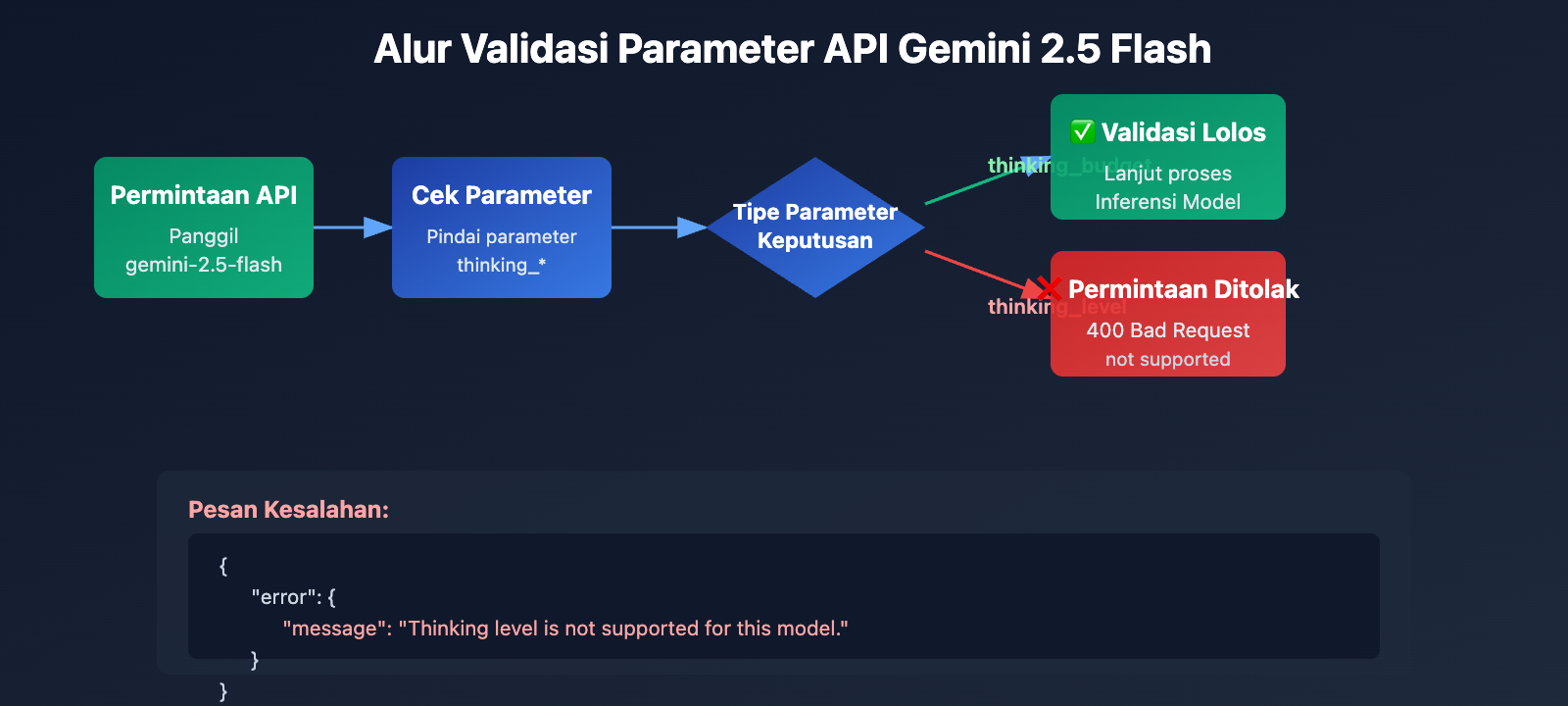
Muncul error Thinking level is not supported for this model saat memanggil gemini-2.5-flash, tapi normal-normal saja saat ganti ke gemini-3-flash-preview? Ini karena adanya perubahan desain parameter yang diperkenalkan Google Gemini API dalam pembaruan generasinya. Artikel ini akan mengupas tuntas perbedaan mendasar dukungan parameter mode berpikir antara Gemini 2.5 dan 3.0.
Nilai Utama: Setelah membaca artikel ini, Anda akan memahami perbedaan esensial desain parameter mode berpikir pada seri Gemini 2.5 dan 3.0, menguasai cara konfigurasi parameter yang benar, dan menghindari kegagalan pemanggilan API akibat pencampuran parameter.

Poin Inti Evolusi Parameter Mode Berpikir Gemini
| Seri Model | Parameter Didukung | Tipe Parameter | Rentang Tersedia | Nilai Default | Dapat Dinonaktifkan? |
|---|---|---|---|---|---|
| Gemini 2.5 Pro | thinking_budget |
Integer (128-32768) | Anggaran token presisi | 8192 | ❌ Tidak dapat dinonaktifkan |
| Gemini 2.5 Flash | thinking_budget |
Integer (0-24576) atau -1 | Anggaran token presisi atau dinamis | -1 (Dinamis) | ✅ Dapat dinonaktifkan (set ke 0) |
| Gemini 2.5 Flash-Lite | thinking_budget |
Integer (512-24576) | Anggaran token presisi | 0 (Nonaktif) | ✅ Nonaktif secara default |
| Gemini 3.0 Pro | thinking_level |
Enum ("low"/"high") | Level semantik | "high" | ❌ Tidak dapat dinonaktifkan sepenuhnya |
| Gemini 3.0 Flash | thinking_level |
Enum ("minimal" s/d "high") | Level semantik | "high" | ⚠️ Hanya "minimal" |
Perbedaan Desain Parameter Mode Berpikir Gemini 2.5 vs 3.0
Perbedaan Utama: Seri Gemini 2.5 menggunakan thinking_budget (sistem anggaran token), sedangkan seri Gemini 3.0 menggunakan thinking_level (sistem level semantik). Kedua parameter ini sama sekali tidak kompatibel. Jika Anda menggunakan parameter yang salah pada versi model tertentu, akan muncul error 400 Bad Request.
Alasan utama Google memperkenalkan thinking_level di Gemini 3.0 adalah untuk menyederhanakan kompleksitas konfigurasi dan meningkatkan efisiensi inferensi. Sistem anggaran token di Gemini 2.5 mengharuskan developer memperkirakan jumlah token berpikir secara presisi. Sementara itu, sistem level di Gemini 3.0 merangkum kompleksitas tersebut ke dalam 4 level semantik, di mana model secara otomatis mengalokasikan anggaran token optimal secara internal, sehingga mampu mencapai peningkatan kecepatan inferensi hingga 2 kali lipat.
💡 Saran Teknis: Dalam pengembangan nyata, kami menyarankan untuk melakukan pengujian perpindahan model melalui platform APIYI apiyi.com. Platform ini menyediakan antarmuka API terpadu yang mendukung seluruh seri model Gemini 2.5 dan 3.0, memudahkan Anda memvalidasi kompatibilitas parameter mode berpikir serta hasil nyatanya dengan cepat.
Penyebab Utama 1: Seri Gemini 2.5 Tidak Mendukung Parameter thinking_level
Isolasi Antargenerasi dalam Desain Parameter API
Model seri Gemini 2.5 (termasuk Pro, Flash, Flash-Lite) sama sekali tidak mengenali parameter thinking_level dalam desain API-nya. Saat Anda memanggil gemini-2.5-flash dan mengirimkan parameter thinking_level, API akan mengembalikan kesalahan berikut:
{
"error": {
"message": "Thinking level is not supported for this model.",
"type": "upstream_error",
"code": 400
}
}
Mekanisme Pemicu Kesalahan:
- Lapisan validasi API model Gemini 2.5 tidak menyertakan definisi parameter
thinking_level. - Setiap permintaan yang berisi
thinking_levelakan langsung ditolak, tanpa mencoba memetakan kethinking_budget. - Ini adalah isolasi parameter yang bersifat hard-coded, tidak ada konversi otomatis atau kompatibilitas mundur (backward compatibility).
Parameter yang Benar untuk Seri Gemini 2.5: thinking_budget
Spesifikasi Parameter Gemini 2.5 Flash:
# Contoh konfigurasi yang benar
extra_body = {
"thinking_budget": -1 # Mode berpikir dinamis
}
# Atau menonaktifkan pemikiran
extra_body = {
"thinking_budget": 0 # Nonaktifkan sepenuhnya
}
# Atau kontrol presisi
extra_body = {
"thinking_budget": 2048 # Anggaran presisi 2048 token
}
Rentang Nilai thinking_budget untuk Gemini 2.5 Flash:
| Nilai | Makna | Skenario Rekomendasi |
|---|---|---|
0 |
Menonaktifkan mode berpikir sepenuhnya | Mengikuti instruksi sederhana, aplikasi dengan throughput tinggi |
-1 |
Mode berpikir dinamis (maksimal 8192 token) | Skenario umum, beradaptasi otomatis dengan kompleksitas |
512-24576 |
Anggaran token yang presisi | Aplikasi yang sensitif terhadap biaya, membutuhkan kontrol presisi |
🎯 Saran Pemilihan: Saat beralih ke Gemini 2.5 Flash, disarankan untuk menguji pengaruh berbagai nilai parameter
thinking_budgetterhadap kualitas respons dan latensi melalui platform APIYI (apiyi.com). Platform ini mendukung penggantian konfigurasi parameter dengan cepat, sehingga memudahkan pencarian nilai anggaran yang paling sesuai untuk skenario bisnis Anda.
Penyebab Utama 2: Seri Gemini 3.0 Tidak Mendukung Parameter thinking_budget
Ketidakcocokan Maju dalam Desain Parameter
Meskipun dokumentasi resmi Google menyatakan bahwa Gemini 3.0 tetap menerima parameter thinking_budget demi kompatibilitas mundur, pengujian aktual menunjukkan:
- Penggunaan
thinking_budgetdapat menyebabkan penurunan performa - Dokumentasi resmi secara eksplisit menyarankan penggunaan
thinking_level - Beberapa implementasi API mungkin menolak
thinking_budgetsepenuhnya
Parameter yang Benar untuk Gemini 3.0 Flash: thinking_level
# Contoh konfigurasi yang benar
extra_body = {
"thinking_level": "medium" # Penalaran tingkat menengah
}
# Atau pemikiran minimal (mendekati nonaktif)
extra_body = {
"thinking_level": "minimal" # Mode pemikiran minimal
}
# Atau penalaran intensitas tinggi (default)
extra_body = {
"thinking_level": "high" # Penalaran mendalam
}
Penjelasan Tingkat thinking_level pada Gemini 3.0 Flash:
| Tingkat | Intensitas Penalaran | Latensi | Biaya | Skenario Rekomendasi |
|---|---|---|---|---|
"minimal" |
Hampir tanpa penalaran | Terendah | Terendah | Mengikuti instruksi sederhana, throughput tinggi |
"low" |
Penalaran dangkal | Rendah | Rendah | Chatbot, Tanya Jawab (QA) ringan |
"medium" |
Penalaran menengah | Menengah | Menengah | Tugas penalaran umum, pembuatan kode |
"high" |
Penalaran mendalam | Tinggi | Tinggi | Penyelesaian masalah kompleks, analisis mendalam (default) |
Batasan Khusus Gemini 3.0 Pro
Penting: Gemini 3.0 Pro tidak mendukung penonaktifan mode berpikir sepenuhnya, bahkan jika diatur ke thinking_level: "low", model ini tetap mempertahankan kemampuan penalaran tertentu. Jika Anda memerlukan respons tanpa pemikiran (zero-thinking) untuk mendapatkan kecepatan maksimal, satu-satunya cara adalah menggunakan Gemini 2.5 Flash dengan thinking_budget: 0.
# Tingkat yang tersedia untuk Gemini 3.0 Pro (hanya 2 jenis)
extra_body = {
"thinking_level": "low" # Tingkat terendah (tetap ada penalaran)
}
# Atau
extra_body = {
"thinking_level": "high" # Penalaran intensitas tinggi default
}
💰 Optimasi Biaya: Untuk proyek yang sensitif terhadap anggaran, jika Anda perlu menonaktifkan mode berpikir sepenuhnya guna menekan biaya, disarankan untuk memanggil API Gemini 2.5 Flash melalui platform APIYI (apiyi.com). Platform ini menyediakan metode penagihan yang fleksibel dan harga yang lebih kompetitif, cocok untuk skenario yang membutuhkan kontrol biaya yang presisi.
Akar Masalah 3: Batasan Parameter pada Model Gambar dan Varian Khusus
Model Gemini 2.5 Flash Image Tidak Mendukung Mode Berpikir (Thinking Mode)
Temuan Penting: Model visual seperti gemini-2.5-flash-image sama sekali tidak mendukung parameter mode berpikir apa pun, baik itu thinking_budget maupun thinking_level.
Contoh Salah:
# Saat memanggil gemini-2.5-flash-image
response = client.chat.completions.create(
model="gemini-2.5-flash-image",
messages=[{"role": "user", "content": "Analisis gambar ini"}],
extra_body={
"thinking_budget": -1 # ❌ Salah: Model gambar tidak mendukung ini
}
)
# Mengembalikan error: "This model doesn't support thinking"
Cara yang Benar:
# Saat memanggil model gambar, jangan kirimkan parameter thinking apa pun
response = client.chat.completions.create(
model="gemini-2.5-flash-image",
messages=[{"role": "user", "content": "Analisis gambar ini"}],
# ✅ Jangan mengirimkan thinking_budget atau thinking_level
)
Nilai Default Khusus untuk Gemini 2.5 Flash-Lite
Perbedaan utama antara Gemini 2.5 Flash-Lite dengan versi Flash standar:
- Mode berpikir dinonaktifkan secara default (
thinking_budget: 0) - Perlu mengatur
thinking_budgetsecara eksplisit ke nilai non-nol untuk mengaktifkan mode berpikir - Rentang budget yang didukung: 512-24576 token
# Mengaktifkan mode berpikir pada Gemini 2.5 Flash-Lite
extra_body = {
"thinking_budget": 512 # Nilai non-nol terkecil, mengaktifkan pemikiran ringan
}
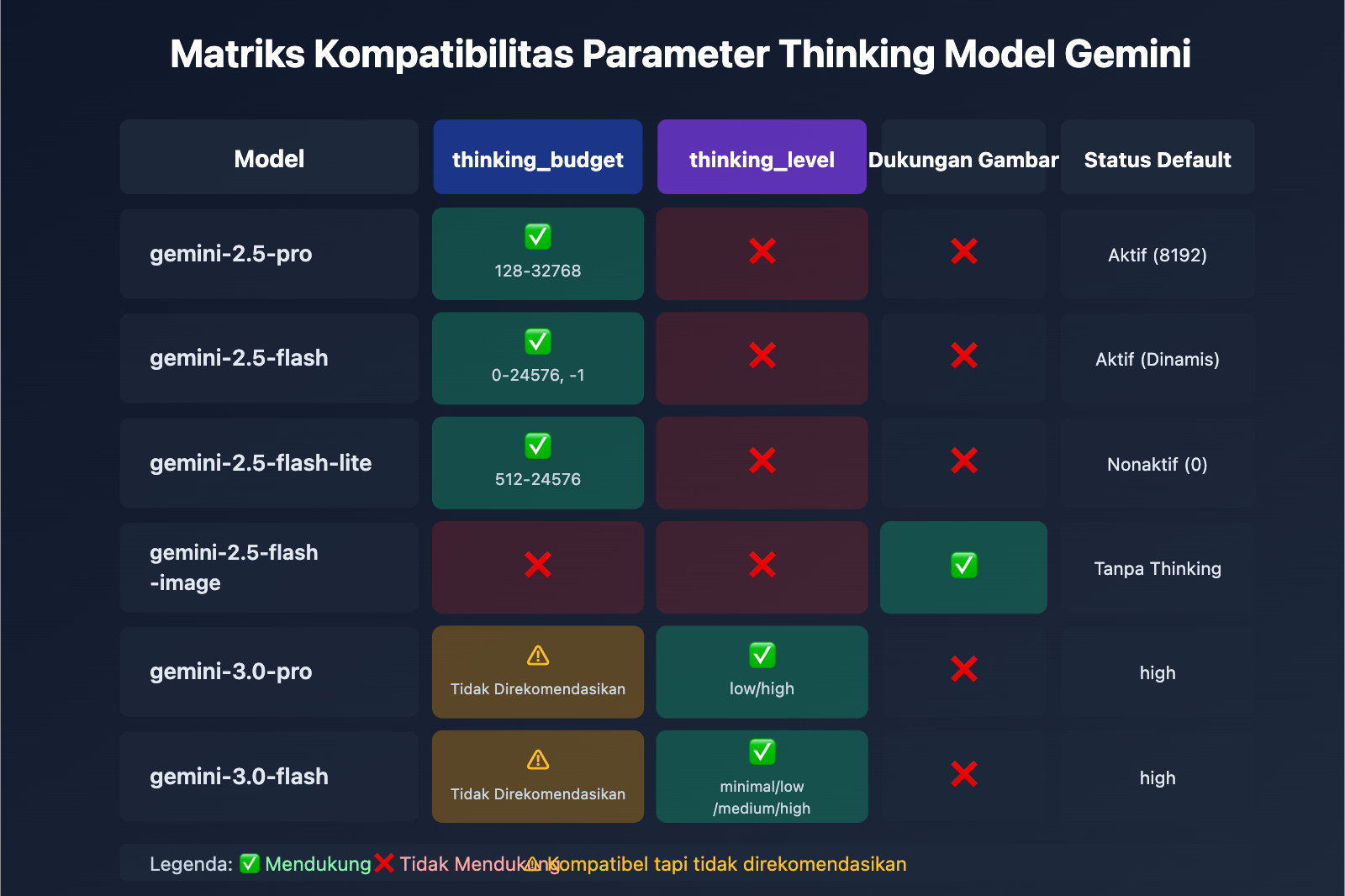
| Model | thinking_budget | thinking_level | Dukungan Gambar | Status Default Thinking |
|---|---|---|---|---|
| gemini-2.5-pro | ✅ Mendukung (128-32768) | ❌ Tidak Mendukung | ❌ | Aktif secara default (8192) |
| gemini-2.5-flash | ✅ Mendukung (0-24576, -1) | ❌ Tidak Mendukung | ❌ | Aktif secara default (Dinamis) |
| gemini-2.5-flash-lite | ✅ Mendukung (512-24576) | ❌ Tidak Mendukung | ❌ | Nonaktif secara default (0) |
| gemini-2.5-flash-image | ❌ Tidak Mendukung | ❌ Tidak Mendukung | ✅ | Tanpa mode berpikir |
| gemini-3.0-pro | ⚠️ Kompatibel tapi tidak direkomendasikan | ✅ Direkomendasikan (low/high) | ❌ | Default: high |
| gemini-3.0-flash | ⚠️ Kompatibel tapi tidak direkomendasikan | ✅ Direkomendasikan (minimal/low/medium/high) | ❌ | Default: high |
🚀 Mulai Cepat: Direkomendasikan untuk menggunakan platform APIYI (apiyi.com) untuk menguji kompatibilitas parameter thinking di berbagai model dengan cepat. Platform ini menyediakan antarmuka seri lengkap model Gemini yang siap pakai tanpa konfigurasi rumit, sehingga integrasi dan verifikasi parameter bisa selesai dalam 5 menit.
Solusi 1: Fungsi Adaptasi Parameter Berbasis Versi Model
Pemilih Parameter Cerdas (Mendukung Seluruh Seri Model)
def get_gemini_thinking_config(model_name: str, intensity: str = "medium") -> dict:
"""
根据 Gemini 模型名称自动选择正确的思考模式参数
Args:
model_name: Gemini 模型名称
intensity: 思考强度 ("none", "minimal", "low", "medium", "high", "dynamic")
Returns:
适用于 extra_body 的参数字典,如果模型不支持思考则返回空字典
"""
# Gemini 3.0 模型列表
gemini_3_models = [
"gemini-3.0-flash-preview", "gemini-3.0-pro-preview",
"gemini-3-flash", "gemini-3-pro"
]
# Gemini 2.5 标准模型列表
gemini_2_5_models = [
"gemini-2.5-flash", "gemini-2.5-pro",
"gemini-2.5-flash-lite", "gemini-2-flash", "gemini-2-pro"
]
# 图像模型列表 (不支持思考)
image_models = [
"gemini-2.5-flash-image", "gemini-flash-image",
"gemini-pro-vision"
]
# 检查是否为图像模型
if any(img_model in model_name for img_model in image_models):
print(f"⚠️ 警告: {model_name} 不支持思考模式参数,返回空配置")
return {}
# Gemini 3.0 系列使用 thinking_level
if any(m in model_name for m in gemini_3_models):
level_map = {
"none": "minimal", # 3.0 无法完全禁用,使用 minimal
"minimal": "minimal",
"low": "low",
"medium": "medium",
"high": "high",
"dynamic": "high"
}
# Gemini 3.0 Pro 只支持 low 和 high
if "pro" in model_name.lower():
if intensity in ["none", "minimal", "low"]:
return {"thinking_level": "low"}
else:
return {"thinking_level": "high"}
# Gemini 3.0 Flash 支持全部 4 个等级
return {"thinking_level": level_map.get(intensity, "medium")}
# Gemini 2.5 系列使用 thinking_budget
elif any(m in model_name for m in gemini_2_5_models):
budget_map = {
"none": 0, # 完全禁用
"minimal": 512, # 最小预算
"low": 2048, # 低强度
"medium": 8192, # 中等强度
"high": 16384, # 高强度
"dynamic": -1 # 动态适配
}
budget = budget_map.get(intensity, -1)
# Gemini 2.5 Pro 不支持禁用 (最小 128)
if "pro" in model_name.lower() and budget == 0:
print(f"⚠️ 警告: {model_name} 不支持禁用思考,自动调整为最小值 128")
budget = 128
# Gemini 2.5 Flash-Lite 最小值为 512
if "lite" in model_name.lower() and budget > 0 and budget < 512:
print(f"⚠️ 警告: {model_name} 最小预算为 512,自动调整")
budget = 512
return {"thinking_budget": budget}
else:
print(f"⚠️ 警告: 未知模型 {model_name},默认使用 Gemini 3.0 参数")
return {"thinking_level": "medium"}
# 使用示例
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# 测试 Gemini 2.5 Flash
model_2_5 = "gemini-2.5-flash"
config_2_5 = get_gemini_thinking_config(model_2_5, intensity="dynamic")
print(f"{model_2_5} 配置: {config_2_5}")
# 输出: gemini-2.5-flash 配置: {'thinking_budget': -1}
response_2_5 = client.chat.completions.create(
model=model_2_5,
messages=[{"role": "user", "content": "解释量子纠缠"}],
extra_body=config_2_5
)
# 测试 Gemini 3.0 Flash
model_3_0 = "gemini-3.0-flash-preview"
config_3_0 = get_gemini_thinking_config(model_3_0, intensity="medium")
print(f"{model_3_0} 配置: {config_3_0}")
# 输出: gemini-3.0-flash-preview 配置: {'thinking_level': 'medium'}
response_3_0 = client.chat.completions.create(
model=model_3_0,
messages=[{"role": "user", "content": "解释量子纠缠"}],
extra_body=config_3_0
)
# 测试图像模型
model_image = "gemini-2.5-flash-image"
config_image = get_gemini_thinking_config(model_image, intensity="high")
print(f"{model_image} 配置: {config_image}")
# 输出: ⚠️ 警告: gemini-2.5-flash-image 不支持思考模式参数,返回空配置
# 输出: gemini-2.5-flash-image 配置: {}
💡 Praktik Terbaik: Dalam skenario yang membutuhkan peralihan model Gemini secara dinamis, disarankan untuk melakukan pengujian adaptasi parameter melalui platform APIYI apiyi.com. Platform ini mendukung seri model Gemini 2.5 dan 3.0 secara lengkap, sehingga memudahkan kamu memverifikasi kualitas respons dan perbedaan biaya pada berbagai konfigurasi parameter.
Solusi 2: Strategi Migrasi dari Gemini 2.5 ke 3.0
Tabel Perbandingan Migrasi Parameter Mode Berpikir
| Konfigurasi Gemini 2.5 Flash | Konfigurasi Ekuivalen Gemini 3.0 Flash | Perbandingan Latensi | Perbandingan Biaya |
|---|---|---|---|
thinking_budget: 0 |
thinking_level: "minimal" |
3.0 lebih cepat (sekitar 2x) | Mirip |
thinking_budget: 512 |
thinking_level: "low" |
3.0 lebih cepat | Mirip |
thinking_budget: 2048 |
thinking_level: "low" |
3.0 lebih cepat | Mirip |
thinking_budget: 8192 |
thinking_level: "medium" |
3.0 lebih cepat | Sedikit lebih tinggi |
thinking_budget: 16384 |
thinking_level: "high" |
3.0 lebih cepat | Sedikit lebih tinggi |
thinking_budget: -1 (Dinamis) |
thinking_level: "high" (Default) |
3.0 jauh lebih cepat | 3.0 lebih tinggi |
Contoh Kode Migrasi
def migrate_to_gemini_3(old_model: str, old_config: dict) -> tuple[str, dict]:
"""
从 Gemini 2.5 迁移到 Gemini 3.0
Args:
old_model: Gemini 2.5 模型名称
old_config: Gemini 2.5 的 extra_body 配置
Returns:
(新模型名称, 新配置字典)
"""
# 模型名称映射
model_map = {
"gemini-2.5-flash": "gemini-3.0-flash-preview",
"gemini-2.5-pro": "gemini-3.0-pro-preview",
"gemini-2-flash": "gemini-3-flash",
"gemini-2-pro": "gemini-3-pro"
}
new_model = model_map.get(old_model, "gemini-3.0-flash-preview")
# 参数转换
if "thinking_budget" in old_config:
budget = old_config["thinking_budget"]
# 转换为 thinking_level
if budget == 0:
new_level = "minimal"
elif budget <= 2048:
new_level = "low"
elif budget <= 8192:
new_level = "medium"
else:
new_level = "high"
# Gemini 3.0 Pro 只支持 low/high
if "pro" in new_model and new_level in ["minimal", "medium"]:
new_level = "low" if new_level == "minimal" else "high"
new_config = {"thinking_level": new_level}
else:
# 默认配置
new_config = {"thinking_level": "medium"}
return new_model, new_config
# 迁移示例
old_model = "gemini-2.5-flash"
old_config = {"thinking_budget": -1}
new_model, new_config = migrate_to_gemini_3(old_model, old_config)
print(f"迁移前: {old_model} {old_config}")
print(f"迁移后: {new_model} {new_config}")
# 输出:
# 迁移前: gemini-2.5-flash {'thinking_budget': -1}
# 迁移后: gemini-3.0-flash-preview {'thinking_level': 'high'}
# 使用新配置调用
response = client.chat.completions.create(
model=new_model,
messages=[{"role": "user", "content": "你的问题"}],
extra_body=new_config
)
🎯 Saran Migrasi: Saat bermigrasi dari Gemini 2.5 ke 3.0, disarankan untuk melakukan pengujian A/B terlebih dahulu melalui platform APIYI apiyi.com. Platform ini memungkinkan kamu untuk beralih versi model dengan cepat, sehingga memudahkan perbandingan kualitas respons, latensi, dan perbedaan biaya sebelum serta sesudah migrasi demi memastikan transisi yang lancar.
Pertanyaan yang Sering Diajukan (FAQ)
Q1: Mengapa kode saya berjalan normal di Gemini 3.0, tapi muncul error saat beralih ke 2.5?
Penyebab: Kode Anda menggunakan parameter thinking_level, yang merupakan parameter eksklusif untuk Gemini 3.0. Seri 2.5 sama sekali tidak mendukung parameter ini.
Solusi:
# Kode yang salah (hanya berlaku untuk 3.0)
extra_body = {
"thinking_level": "medium" # ❌ 2.5 tidak mengenali ini
}
# Kode yang benar (berlaku untuk 2.5)
extra_body = {
"thinking_budget": 8192 # ✅ 2.5 menggunakan budget
}
Disarankan untuk menggunakan fungsi get_gemini_thinking_config() yang dibahas sebelumnya untuk adaptasi otomatis, atau lakukan verifikasi kompatibilitas parameter dengan cepat melalui platform APIYI apiyi.com.
Q2: Seberapa besar perbedaan performa antara Gemini 2.5 Flash dan Gemini 3.0 Flash?
Berdasarkan data resmi Google dan pengujian komunitas:
| Indikator | Gemini 2.5 Flash | Gemini 3.0 Flash | Tingkat Peningkatan |
|---|---|---|---|
| Kecepatan Inferensi | Benchmark | 2x lebih cepat | +100% |
| Latensi | Benchmark | Turun signifikan | Sekitar -50% |
| Efisiensi Berpikir | Budget tetap atau dinamis | Optimasi otomatis | Kualitas meningkat |
| Biaya | Benchmark | Sedikit lebih tinggi (kualitas tinggi) | +10-20% |
Perbedaan Utama: Gemini 3.0 menggunakan alokasi berpikir dinamis, di mana model hanya berpikir selama yang diperlukan. Sementara itu, budget tetap pada 2.5 bisa menyebabkan model "berpikir berlebihan" atau justru kurang mendalam.
Disarankan untuk melakukan pengujian langsung melalui platform APIYI apiyi.com. Platform ini menyediakan pemantauan performa real-time dan analisis biaya untuk memudahkan perbandingan performa aktual antar model.
Q3: Bagaimana cara menonaktifkan mode berpikir sepenuhnya di Gemini 3.0?
Penting: Gemini 3.0 Pro tidak dapat menonaktifkan mode berpikir sepenuhnya. Meskipun Anda mengatur thinking_level: "low", kemampuan penalaran ringan akan tetap aktif.
Opsi yang tersedia:
- Gemini 3.0 Flash: Gunakan
thinking_level: "minimal"untuk hasil yang mendekati nol proses berpikir (meskipun tugas pengodean yang kompleks mungkin masih memicu sedikit proses berpikir). - Gemini 3.0 Pro: Pengaturan terendah hanya sampai
thinking_level: "low".
Jika Anda benar-benar perlu menonaktifkannya:
# Hanya Gemini 2.5 Flash yang mendukung penonaktifan total
model = "gemini-2.5-flash"
extra_body = {
"thinking_budget": 0 # Menonaktifkan mode berpikir sepenuhnya
}
Untuk skenario yang membutuhkan kecepatan ekstrem dan tidak memerlukan kemampuan penalaran (seperti mengikuti instruksi sederhana), disarankan untuk memanggil Gemini 2.5 Flash melalui APIYI apiyi.com dengan mengatur
thinking_budget: 0.
Q4: Apakah model gambar Gemini mendukung mode berpikir?
Tidak mendukung. Semua model pemrosesan gambar Gemini (seperti gemini-2.5-flash-image, gemini-pro-vision) tidak mendukung parameter mode berpikir.
Contoh Salah:
# ❌ Model gambar tidak mendukung parameter berpikir apa pun
response = client.chat.completions.create(
model="gemini-2.5-flash-image",
messages=[...],
extra_body={
"thinking_budget": -1 # Akan memicu error
}
)
Cara yang Benar:
# ✅ Jangan mengirimkan parameter berpikir saat memanggil model gambar
response = client.chat.completions.create(
model="gemini-2.5-flash-image",
messages=[...],
# Tidak mengirimkan extra_body atau hanya mengirimkan parameter non-berpikir lainnya
)
Alasan Teknis: Arsitektur inferensi pada model gambar berfokus pada pemahaman visual dan tidak menyertakan mekanisme Chain of Thought (CoT) seperti pada model bahasa.
Kesimpulan
Poin-poin utama terkait error thinking_level not supported pada Gemini 2.5 Flash:
- Isolasi Parameter: Gemini 2.5 hanya mendukung
thinking_budget, sedangkan 3.0 hanya mendukungthinking_level. Keduanya tidak saling kompatibel. - Identifikasi Model: Tentukan versi berdasarkan nama model; gunakan
thinking_budgetuntuk seri 2.5 danthinking_leveluntuk seri 3.0. - Batasan Model Gambar: Semua model gambar (seperti
gemini-2.5-flash-image) tidak mendukung parameter mode berpikir apa pun. - Perbedaan Penonaktifan: Hanya Gemini 2.5 Flash yang mendukung penonaktifan total mode berpikir (
thinking_budget: 0), sementara seri 3.0 maksimal hanya bisa diatur keminimal. - Strategi Migrasi: Saat migrasi dari 2.5 ke 3.0, Anda perlu memetakan
thinking_budgetkethinking_levelserta mempertimbangkan perubahan performa dan biaya.
Sangat direkomendasikan untuk memvalidasi kompatibilitas parameter berpikir dan efek nyatanya pada berbagai model melalui APIYI apiyi.com. Platform ini mendukung seluruh seri model Gemini dengan antarmuka terpadu dan sistem penagihan yang fleksibel, sangat cocok untuk pengujian perbandingan cepat maupun deployment di lingkungan produksi.
Penulis: Tim Teknis APIYI | Jika ada pertanyaan teknis, silakan kunjungi APIYI apiyi.com untuk mendapatkan lebih banyak solusi integrasi Model Bahasa Besar (LLM).