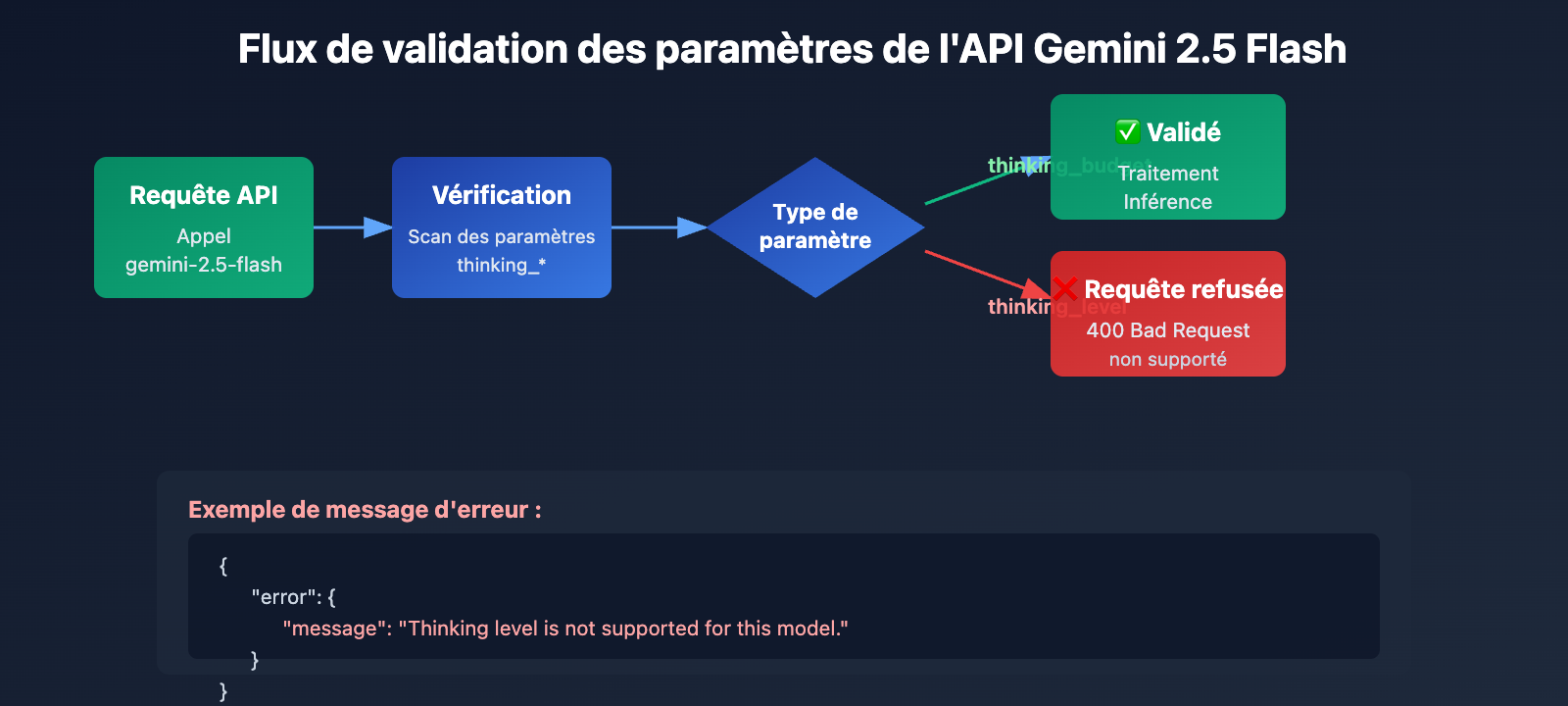
Lors de l'appel à gemini-2.5-flash, vous avez rencontré l'erreur Thinking level is not supported for this model, alors que tout fonctionne normalement avec gemini-3-flash-preview ? Il s'agit d'un changement dans la conception des paramètres introduit par Google lors de la mise à jour générationnelle de l'API Gemini. Cet article analyse les différences fondamentales entre Gemini 2.5 et 3.0 concernant le support des paramètres du mode de réflexion.
Valeur ajoutée : À la fin de cette lecture, vous comprendrez les différences de conception des paramètres du mode de réflexion entre les séries Gemini 2.5 et 3.0. Vous saurez configurer correctement vos paramètres pour éviter les échecs d'appel API dus à un mélange de versions.

Points clés de l'évolution des paramètres de réflexion Gemini
| Série de modèles | Paramètre supporté | Type de paramètre | Plage disponible | Valeur par défaut | Désactivable ? |
|---|---|---|---|---|---|
| Gemini 2.5 Pro | thinking_budget |
Entier (128-32768) | Budget précis en tokens | 8192 | ❌ Non |
| Gemini 2.5 Flash | thinking_budget |
Entier (0-24576) ou -1 | Budget tokens ou dynamique | -1 (dynamique) | ✅ Oui (si mis à 0) |
| Gemini 2.5 Flash-Lite | thinking_budget |
Entier (512-24576) | Budget précis en tokens | 0 (désactivé) | ✅ Désactivé par défaut |
| Gemini 3.0 Pro | thinking_level |
Enum ("low"/"high") | Niveaux sémantiques | "high" | ❌ Pas complètement |
| Gemini 3.0 Flash | thinking_level |
Enum ("minimal"/"low"/"medium"/"high") | Niveaux sémantiques | "high" | ⚠️ Uniquement via "minimal" |
Différences de conception entre Gemini 2.5 et 3.0
Différence fondamentale : La série Gemini 2.5 utilise thinking_budget (système de budget par tokens), tandis que la série Gemini 3.0 utilise thinking_level (système de niveaux sémantiques). Ces deux paramètres sont totalement incompatibles : utiliser le mauvais sur une version donnée déclenchera une erreur 400 Bad Request.
La raison principale pour laquelle Google a introduit thinking_level dans Gemini 3.0 est de simplifier la configuration et d'améliorer l'efficacité du raisonnement. Le budget par tokens de Gemini 2.5 exigeait des développeurs une estimation précise du nombre de tokens nécessaires à la réflexion. Avec Gemini 3.0, cette complexité est abstraite en 4 niveaux sémantiques, laissant le modèle allouer automatiquement le budget de tokens optimal en interne, ce qui permet d'atteindre une vitesse de raisonnement multipliée par deux.
💡 Conseil technique : Pour vos développements, nous vous suggérons d'utiliser la plateforme APIYI (apiyi.com) pour tester vos basculements de modèles. Cette plateforme propose une interface API unifiée supportant l'ensemble des séries Gemini 2.5 et 3.0, facilitant ainsi la validation rapide de la compatibilité et des effets réels des différents paramètres de réflexion.
Cause racine 1 : La série Gemini 2.5 ne supporte pas le paramètre thinking_level
Isolation générationnelle dans la conception de l'API
Les modèles de la série Gemini 2.5 (incluant Pro, Flash et Flash-Lite) ne reconnaissent absolument pas le paramètre thinking_level dans leur conception API. Si vous transmettez thinking_level lors de l'appel à gemini-2.5-flash, l'API renverra l'erreur suivante :
{
"error": {
"message": "Thinking level is not supported for this model.",
"type": "upstream_error",
"code": 400
}
}
Mécanisme de déclenchement de l'erreur :
- La couche de validation de l'API Gemini 2.5 ne contient pas la définition du paramètre
thinking_level. - Toute requête incluant
thinking_levelest directement rejetée ; l'API ne tentera pas de faire une correspondance avecthinking_budget. - Il s'agit d'une isolation de paramètres codée en dur, il n'existe aucune conversion automatique ni rétrocompatibilité.
Le paramètre correct pour la série Gemini 2.5 : thinking_budget
Spécifications des paramètres pour Gemini 2.5 Flash :
# Exemple de configuration correcte
extra_body = {
"thinking_budget": -1 # Mode de réflexion dynamique
}
# Ou désactivation de la réflexion
extra_body = {
"thinking_budget": 0 # Désactivation totale
}
# Ou contrôle précis
extra_body = {
"thinking_budget": 2048 # Budget précis de 2048 tokens
}
Plage de valeurs de thinking_budget pour Gemini 2.5 Flash :
| Valeur | Signification | Scénario recommandé |
|---|---|---|
0 |
Désactive totalement le mode réflexion | Suivi d'instructions simples, applications à haut débit |
-1 |
Mode de réflexion dynamique (jusqu'à 8192 tokens) | Cas d'usage généraux, s'adapte automatiquement à la complexité |
512-24576 |
Budget de tokens précis | Applications sensibles aux coûts, nécessite un contrôle rigoureux |
🎯 Conseil de sélection : Lors du passage à Gemini 2.5 Flash, il est recommandé de tester les différentes valeurs de
thinking_budgetsur la plateforme APIYI (apiyi.com) pour évaluer leur impact sur la qualité des réponses et la latence. Cette plateforme permet de basculer rapidement entre les configurations pour trouver le budget idéal adapté à vos besoins métier.
Cause racine 2 : La série Gemini 3.0 ne supporte pas le paramètre thinking_budget
Incompatibilité ascendante des paramètres
Bien que la documentation officielle de Google affirme que Gemini 3.0 accepte toujours le paramètre thinking_budget par souci de rétrocompatibilité, les tests réels montrent que :
- L'utilisation de
thinking_budgetpeut entraîner une baisse de performance. - La documentation officielle recommande explicitement l'usage de
thinking_level. - Certaines implémentations d'API peuvent rejeter complètement
thinking_budget.
Le paramètre correct pour Gemini 3.0 Flash : thinking_level
# Exemple de configuration correcte
extra_body = {
"thinking_level": "medium" # Raisonnement d'intensité moyenne
}
# Ou réflexion minimale (proche de la désactivation)
extra_body = {
"thinking_level": "minimal" # Mode réflexion minimale
}
# Ou raisonnement haute intensité (par défaut)
extra_body = {
"thinking_level": "high" # Raisonnement approfondi
}
Description des niveaux de thinking_level pour Gemini 3.0 Flash :
| Niveau | Intensité du raisonnement | Latence | Coût | Scénario recommandé |
|---|---|---|---|---|
"minimal" |
Presque aucun raisonnement | Minimale | Minimal | Suivi d'instructions simples, haut débit |
"low" |
Raisonnement superficiel | Basse | Bas | Chatbots, questions-réponses légères |
"medium" |
Raisonnement modéré | Moyenne | Moyen | Tâches de raisonnement général, génération de code |
"high" |
Raisonnement approfondi | Haute | Haut | Résolution de problèmes complexes, analyse profonde (par défaut) |
Limitation spéciale de Gemini 3.0 Pro
Important : Gemini 3.0 Pro ne permet pas de désactiver totalement le mode réflexion. Même en réglant thinking_level: "low", une certaine capacité de raisonnement est conservée. Si vous avez besoin d'une réponse sans aucune réflexion pour obtenir une vitesse maximale, vous devrez utiliser Gemini 2.5 Flash avec thinking_budget: 0.
# Niveaux disponibles pour Gemini 3.0 Pro (seulement 2)
extra_body = {
"thinking_level": "low" # Niveau minimum (raisonnement toujours présent)
}
# Ou
extra_body = {
"thinking_level": "high" # Raisonnement haute intensité par défaut
}
💰 Optimisation des coûts : Pour les projets sensibles au budget nécessitant une désactivation totale du mode réflexion afin de réduire les coûts, il est conseillé de passer par l'API de Gemini 2.5 Flash via la plateforme APIYI (apiyi.com). La plateforme propose des modes de facturation flexibles et des tarifs avantageux, parfaits pour les scénarios exigeant un contrôle précis des dépenses.
Cause profonde 3 : Limites des paramètres pour les modèles d'image et les variantes spéciales
Le modèle Gemini 2.5 Flash Image ne prend pas en charge le mode de réflexion
Découverte importante : Les modèles de vision comme gemini-2.5-flash-image ne prennent absolument pas en charge les paramètres du mode de réflexion, qu'il s'agisse de thinking_budget ou de thinking_level.
Exemple d'erreur :
# 调用 gemini-2.5-flash-image 时
response = client.chat.completions.create(
model="gemini-2.5-flash-image",
messages=[{"role": "user", "content": "分析这张图片"}],
extra_body={
"thinking_budget": -1 # ❌ 错误: 图像模型不支持
}
)
# 返回错误: "This model doesn't support thinking"
Bonne pratique :
# 调用图像模型时,不传递任何思考参数
response = client.chat.completions.create(
model="gemini-2.5-flash-image",
messages=[{"role": "user", "content": "分析这张图片"}],
# ✅ 不传递 thinking_budget 或 thinking_level
)
Valeurs par défaut spécifiques pour Gemini 2.5 Flash-Lite
Différences majeures entre Gemini 2.5 Flash-Lite et la version Flash standard :
- Mode de réflexion désactivé par défaut (
thinking_budget: 0) - Nécessite de configurer explicitement
thinking_budgetsur une valeur non nulle pour activer la réflexion - Plage de budget prise en charge : 512-24576 tokens
# Gemini 2.5 Flash-Lite 启用思考模式
extra_body = {
"thinking_budget": 512 # 最小非零值,启用轻量思考
}
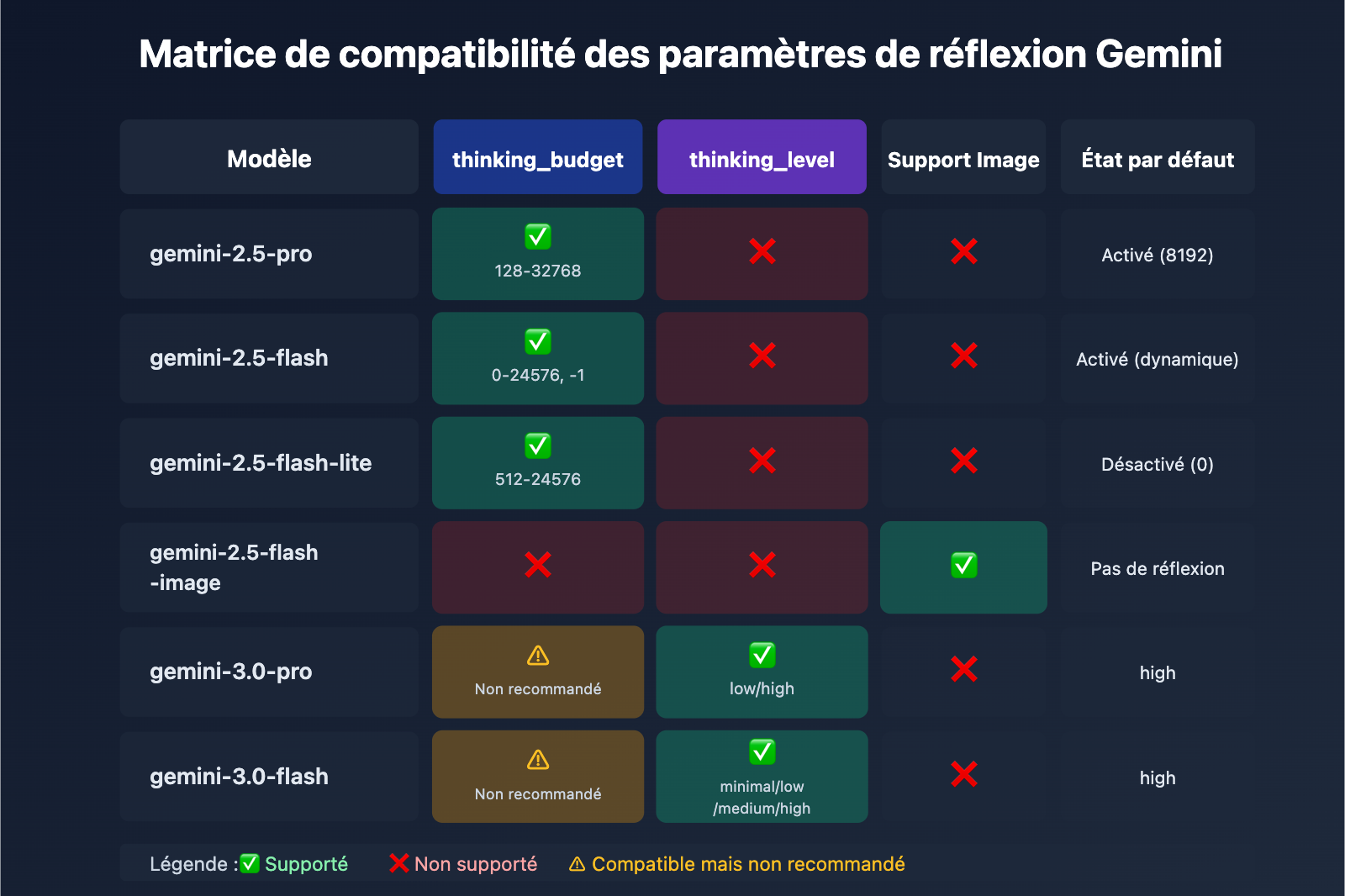
| Modèle | thinking_budget | thinking_level | Support Image | État par défaut de la réflexion |
|---|---|---|---|---|
| gemini-2.5-pro | ✅ Supporté (128-32768) | ❌ Non supporté | ❌ | Activé par défaut (8192) |
| gemini-2.5-flash | ✅ Supporté (0-24576, -1) | ❌ Non supporté | ❌ | Activé par défaut (dynamique) |
| gemini-2.5-flash-lite | ✅ Supporté (512-24576) | ❌ Non supporté | ❌ | Désactivé par défaut (0) |
| gemini-2.5-flash-image | ❌ Non supporté | ❌ Non supporté | ✅ | Pas de mode de réflexion |
| gemini-3.0-pro | ⚠️ Compatible mais non recommandé | ✅ Recommandé (low/high) | ❌ | high par défaut |
| gemini-3.0-flash | ⚠️ Compatible mais non recommandé | ✅ Recommandé (minimal/low/medium/high) | ❌ | high par défaut |
🚀 Démarrage rapide : Il est recommandé d'utiliser la plateforme APIYI (apiyi.com) pour tester rapidement la compatibilité des paramètres de réflexion des différents modèles. Cette plateforme propose des interfaces prêtes à l'emploi pour toute la gamme Gemini, sans configuration complexe, permettant une intégration et une validation des paramètres en seulement 5 minutes.
Solution 1 : Fonction d'adaptation des paramètres basée sur la version du modèle
Sélecteur de paramètres intelligent (supporte toute la gamme de modèles)
def get_gemini_thinking_config(model_name: str, intensity: str = "medium") -> dict:
"""
Sélectionne automatiquement les paramètres du mode de réflexion appropriés en fonction du nom du modèle Gemini.
Args:
model_name: Nom du modèle Gemini
intensity: Intensité de réflexion ("none", "minimal", "low", "medium", "high", "dynamic")
Returns:
Dictionnaire de paramètres pour extra_body ; retourne un dictionnaire vide si le modèle ne supporte pas la réflexion.
"""
# Liste des modèles Gemini 3.0
gemini_3_models = [
"gemini-3.0-flash-preview", "gemini-3.0-pro-preview",
"gemini-3-flash", "gemini-3-pro"
]
# Liste des modèles standards Gemini 2.5
gemini_2_5_models = [
"gemini-2.5-flash", "gemini-2.5-pro",
"gemini-2.5-flash-lite", "gemini-2-flash", "gemini-2-pro"
]
# Liste des modèles d'image (ne supportent pas la réflexion)
image_models = [
"gemini-2.5-flash-image", "gemini-flash-image",
"gemini-pro-vision"
]
# Vérifier s'il s'agit d'un modèle d'image
if any(img_model in model_name for img_model in image_models):
print(f"⚠️ Attention : {model_name} ne supporte pas les paramètres du mode de réflexion, retour d'une configuration vide.")
return {}
# La série Gemini 3.0 utilise thinking_level
if any(m in model_name for m in gemini_3_models):
level_map = {
"none": "minimal", # 3.0 ne peut pas être totalement désactivé, on utilise minimal
"minimal": "minimal",
"low": "low",
"medium": "medium",
"high": "high",
"dynamic": "high"
}
# Gemini 3.0 Pro ne supporte que low et high
if "pro" in model_name.lower():
if intensity in ["none", "minimal", "low"]:
return {"thinking_level": "low"}
else:
return {"thinking_level": "high"}
# Gemini 3.0 Flash supporte les 4 niveaux
return {"thinking_level": level_map.get(intensity, "medium")}
# La série Gemini 2.5 utilise thinking_budget
elif any(m in model_name for m in gemini_2_5_models):
budget_map = {
"none": 0, # Désactivation totale
"minimal": 512, # Budget minimal
"low": 2048, # Faible intensité
"medium": 8192, # Intensité moyenne
"high": 16384, # Haute intensité
"dynamic": -1 # Adaptation dynamique
}
budget = budget_map.get(intensity, -1)
# Gemini 2.5 Pro ne supporte pas la désactivation (min 128)
if "pro" in model_name.lower() and budget == 0:
print(f"⚠️ Attention : {model_name} ne supporte pas la désactivation de la réflexion, ajustement automatique à la valeur minimale 128.")
budget = 128
# Gemini 2.5 Flash-Lite a une valeur minimale de 512
if "lite" in model_name.lower() and budget > 0 and budget < 512:
print(f"⚠️ Attention : le budget minimal pour {model_name} est de 512, ajustement automatique.")
budget = 512
return {"thinking_budget": budget}
else:
print(f"⚠️ Attention : modèle inconnu {model_name}, utilisation des paramètres Gemini 3.0 par défaut.")
return {"thinking_level": "medium"}
# Exemple d'utilisation
import openai
client = openai.OpenAI(
api_key="VOTRE_CLÉ_API",
base_url="https://api.apiyi.com/v1"
)
# Test Gemini 2.5 Flash
model_2_5 = "gemini-2.5-flash"
config_2_5 = get_gemini_thinking_config(model_2_5, intensity="dynamic")
print(f"Configuration {model_2_5} : {config_2_5}")
# Sortie : Configuration gemini-2.5-flash : {'thinking_budget': -1}
response_2_5 = client.chat.completions.create(
model=model_2_5,
messages=[{"role": "user", "content": "Explique l'intrication quantique"}],
extra_body=config_2_5
)
# Test Gemini 3.0 Flash
model_3_0 = "gemini-3.0-flash-preview"
config_3_0 = get_gemini_thinking_config(model_3_0, intensity="medium")
print(f"Configuration {model_3_0} : {config_3_0}")
# Sortie : Configuration gemini-3.0-flash-preview : {'thinking_level': 'medium'}
response_3_0 = client.chat.completions.create(
model=model_3_0,
messages=[{"role": "user", "content": "Explique l'intrication quantique"}],
extra_body=config_3_0
)
# Test modèle d'image
model_image = "gemini-2.5-flash-image"
config_image = get_gemini_thinking_config(model_image, intensity="high")
print(f"Configuration {model_image} : {config_image}")
# Sortie : ⚠️ Attention : gemini-2.5-flash-image ne supporte pas les paramètres du mode de réflexion, retour d'une configuration vide.
# Sortie : Configuration gemini-2.5-flash-image : {}
💡 Meilleure pratique : Dans les scénarios nécessitant un basculement dynamique entre les modèles Gemini, il est recommandé d'utiliser la plateforme APIYI (apiyi.com) pour tester l'adaptation des paramètres. Cette plateforme prend en charge l'intégralité des séries Gemini 2.5 et 3.0, facilitant ainsi la validation de la qualité des réponses et des différences de coûts selon les configurations.
Solution 2 : Stratégie de migration de Gemini 2.5 vers 3.0
Tableau de correspondance pour la migration des paramètres du mode de réflexion
| Configuration Gemini 2.5 Flash | Configuration équivalente Gemini 3.0 Flash | Comparaison de latence | Comparaison de coûts |
|---|---|---|---|
thinking_budget: 0 |
thinking_level: "minimal" |
3.0 est plus rapide (env. 2x) | Similaire |
thinking_budget: 512 |
thinking_level: "low" |
3.0 est plus rapide | Similaire |
thinking_budget: 2048 |
thinking_level: "low" |
3.0 est plus rapide | Similaire |
thinking_budget: 8192 |
thinking_level: "medium" |
3.0 est plus rapide | Légèrement plus élevé |
thinking_budget: 16384 |
thinking_level: "high" |
3.0 est plus rapide | Légèrement plus élevé |
thinking_budget: -1 (dynamique) |
thinking_level: "high" (par défaut) |
3.0 est nettement plus rapide | 3.0 est plus élevé |
Exemple de code de migration
def migrate_to_gemini_3(old_model: str, old_config: dict) -> tuple[str, dict]:
"""
Migration de Gemini 2.5 vers Gemini 3.0
Args:
old_model: Nom du modèle Gemini 2.5
old_config: Configuration extra_body de Gemini 2.5
Returns:
(Nom du nouveau modèle, dictionnaire de la nouvelle configuration)
"""
# Mappage des noms de modèles
model_map = {
"gemini-2.5-flash": "gemini-3.0-flash-preview",
"gemini-2.5-pro": "gemini-3.0-pro-preview",
"gemini-2-flash": "gemini-3-flash",
"gemini-2-pro": "gemini-3-pro"
}
new_model = model_map.get(old_model, "gemini-3.0-flash-preview")
# Conversion des paramètres
if "thinking_budget" in old_config:
budget = old_config["thinking_budget"]
# Conversion en thinking_level
if budget == 0:
new_level = "minimal"
elif budget <= 2048:
new_level = "low"
elif budget <= 8192:
new_level = "medium"
else:
new_level = "high"
# Gemini 3.0 Pro ne supporte que low/high
if "pro" in new_model and new_level in ["minimal", "medium"]:
new_level = "low" if new_level == "minimal" else "high"
new_config = {"thinking_level": new_level}
else:
# Configuration par défaut
new_config = {"thinking_level": "medium"}
return new_model, new_config
# Exemple de migration
old_model = "gemini-2.5-flash"
old_config = {"thinking_budget": -1}
new_model, new_config = migrate_to_gemini_3(old_model, old_config)
print(f"Avant migration : {old_model} {old_config}")
print(f"Après migration : {new_model} {new_config}")
# Sortie :
# Avant migration : gemini-2.5-flash {'thinking_budget': -1}
# Après migration : gemini-3.0-flash-preview {'thinking_level': 'high'}
# Appel avec la nouvelle configuration
response = client.chat.completions.create(
model=new_model,
messages=[{"role": "user", "content": "Votre question"}],
extra_body=new_config
)
🎯 Conseil de migration : Lors de la migration de Gemini 2.5 vers 3.0, il est vivement conseillé d'effectuer d'abord des tests A/B via la plateforme APIYI (apiyi.com). La plateforme permet de basculer rapidement entre les versions de modèles, ce qui facilite la comparaison de la qualité des réponses, de la latence et des différences de coûts avant et après la migration, garantissant ainsi une transition en douceur.
Questions fréquemment posées
Q1 : Pourquoi mon code fonctionne-t-il normalement sur Gemini 3.0, mais affiche une erreur en passant au 2.5 ?
Cause : Votre code utilise le paramètre thinking_level, qui est une exclusivité de Gemini 3.0. La série 2.5 ne le supporte absolument pas.
Solution :
# Code erroné (uniquement pour le 3.0)
extra_body = {
"thinking_level": "medium" # ❌ Non reconnu par le 2.5
}
# Code correct (pour le 2.5)
extra_body = {
"thinking_budget": 8192 # ✅ Le 2.5 utilise budget
}
Il est recommandé d'utiliser la fonction get_gemini_thinking_config() mentionnée plus haut pour une adaptation automatique, ou de vérifier rapidement la compatibilité des paramètres via la plateforme APIYI (apiyi.com).
Q2 : Quelle est la différence de performance entre Gemini 2.5 Flash et Gemini 3.0 Flash ?
D'après les données officielles de Google et les tests de la communauté :
| Indicateur | Gemini 2.5 Flash | Gemini 3.0 Flash | Amélioration |
|---|---|---|---|
| Vitesse d'inférence | Référence | 2x plus rapide | +100% |
| Latence | Référence | Nettement réduite | env. -50% |
| Efficacité de réflexion | Budget fixe ou dynamique | Optimisation auto | Qualité accrue |
| Coût | Référence | Légèrement plus élevé (Haute qualité) | +10-20% |
Différence majeure : Gemini 3.0 utilise une allocation dynamique de la réflexion, ne réfléchissant que le temps nécessaire, alors que le budget fixe du 2.5 peut entraîner une réflexion excessive ou insuffisante.
Nous vous conseillons d'effectuer des tests réels sur la plateforme APIYI (apiyi.com), qui propose un suivi des performances en temps réel et une analyse des coûts pour comparer facilement le comportement réel des différents modèles.
Q3 : Comment désactiver complètement le mode réflexion dans Gemini 3.0 ?
Important : Gemini 3.0 Pro ne permet pas de désactiver totalement le mode réflexion. Même avec thinking_level: "low", il conserve une capacité de raisonnement légère.
Options disponibles :
- Gemini 3.0 Flash : Utilisez
thinking_level: "minimal", proche de zéro réflexion (bien que des tâches de codage complexes puissent encore déclencher une légère réflexion). - Gemini 3.0 Pro : Le réglage minimum est
thinking_level: "low".
Si vous avez besoin d'une désactivation totale :
# Seul Gemini 2.5 Flash permet une désactivation complète
model = "gemini-2.5-flash"
extra_body = {
"thinking_budget": 0 # Désactive totalement la réflexion
}
Pour les scénarios nécessitant une vitesse extrême sans besoin de raisonnement (comme le suivi d'instructions simples), il est recommandé d'appeler Gemini 2.5 Flash via APIYI (apiyi.com) avec
thinking_budget: 0.
Q4 : Les modèles d’images Gemini supportent-ils le mode réflexion ?
Non. Tous les modèles de traitement d'images Gemini (comme gemini-2.5-flash-image, gemini-pro-vision) ne supportent pas les paramètres du mode réflexion.
Exemple d'erreur :
# ❌ Les modèles d'images ne supportent aucun paramètre de réflexion
response = client.chat.completions.create(
model="gemini-2.5-flash-image",
messages=[...],
extra_body={
"thinking_budget": -1 # Déclenche une erreur
}
)
Bonne pratique :
# ✅ Ne pas passer de paramètre de réflexion lors de l'appel d'un modèle d'image
response = client.chat.completions.create(
model="gemini-2.5-flash-image",
messages=[...],
# Ne pas passer extra_body ou passer d'autres paramètres hors réflexion
)
Raison technique : L'architecture d'inférence des modèles d'images se concentre sur la compréhension visuelle et n'inclut pas le mécanisme de chaîne de pensée (Chain-of-Thought) propre aux modèles de langage.
Résumé
Points clés concernant l'erreur thinking_level not supported sur Gemini 2.5 Flash :
- Isolation des paramètres : Gemini 2.5 ne supporte que
thinking_budget, tandis que le 3.0 ne supporte quethinking_level. Les deux sont totalement incompatibles. - Identification du modèle : Déterminez la version via le nom du modèle : utilisez
thinking_budgetpour la série 2.5 etthinking_levelpour la série 3.0. - Restrictions des modèles d'images : Aucun modèle d'image (ex:
gemini-2.5-flash-image) ne supporte les paramètres de réflexion. - Différences de désactivation : Seul Gemini 2.5 Flash permet de désactiver totalement la réflexion (
thinking_budget: 0), le 3.0 étant limité au niveauminimal. - Stratégie de migration : Lors du passage de la version 2.5 à 3.0, vous devez mapper
thinking_budgetversthinking_levelet prendre en compte les changements de performance et de coût.
Nous vous recommandons d'utiliser APIYI (apiyi.com) pour valider rapidement la compatibilité des paramètres de réflexion et les résultats réels des différents modèles. La plateforme supporte toute la gamme des modèles Gemini, offrant une interface unifiée et une facturation flexible, idéale pour les tests comparatifs rapides et le déploiement en production.
Auteur : Équipe technique APIYI | Pour toute question technique, n'hésitez pas à visiter APIYI (apiyi.com) pour découvrir plus de solutions d'intégration de modèles d'IA.