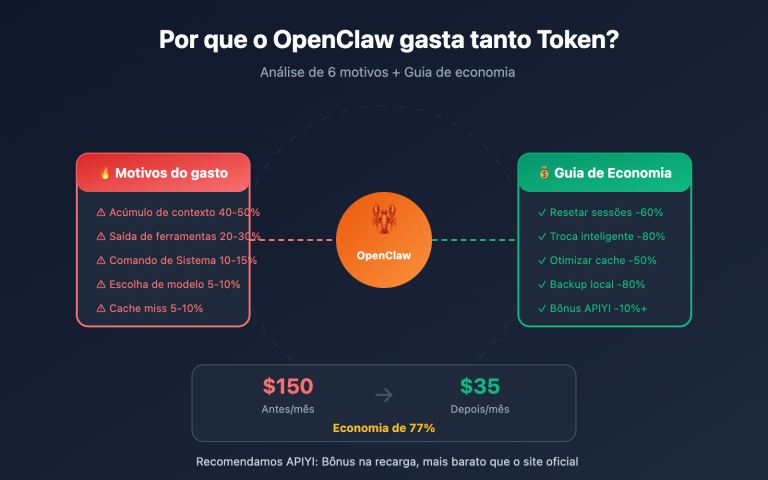
O cache de comandos (Prompt Caching) é um tópico de custo inevitável para quase todos os usuários de API de Modelos de Linguagem Grande em 2026. Ao executar uma aplicação de RAG com um comando de sistema de 8K, a diferença na fatura mensal entre usar ou não o cache pode ser superior a 10 vezes. No entanto, muitos desenvolvedores, ao alternarem entre OpenAI e Anthropic, acabam tropeçando em um detalhe oculto: os modelos de cobrança de cache das duas empresas são completamente diferentes.

A diferença mais crucial pode ser resumida em uma frase: a gravação em cache da série GPT é cobrada pelo preço base de 1x, sem sobretaxas, enquanto a gravação em cache da série Claude cobra uma sobretaxa de 1,25x (5 minutos) ou 2x (1 hora). Essa diferença parece pequena, mas, quando aplicada ao tráfego real de negócios, afeta significativamente o ponto de equilíbrio. Este artigo, baseado na verificação item a item da documentação oficial de ambas as empresas, esclarece as regras de cobrança, condições de disparo, descontos de leitura, estratégias de TTL e cálculos de retorno sobre o investimento para ajudar você a fazer uma estimativa de custos mais precisa.
5 Diferenças principais entre o cache de comandos do GPT e do Claude
Vamos direto ao ponto. A tabela abaixo é a mais importante deste artigo; ela reúne os 5 pontos cruciais que são facilmente ignorados na camada de cache de ambas as empresas para facilitar a comparação.
| Dimensão | OpenAI GPT | Anthropic Claude |
|---|---|---|
| Cobrança de gravação | Preço base 1x, sem sobretaxa | 5min: 1,25x; 1h: 2x |
| Cobrança de leitura | ~0,1x (até 90% de desconto) | 0,1x (preço após 10% de desconto) |
| Método de disparo | Totalmente automático, sem alterar código | Opt-in explícito, requer cache_control |
| Limite mínimo de tokens | Unificado em 1024 tokens | 1024 / 2048 / 4096 (conforme o modelo) |
| TTL do cache | Padrão 5–10 min ocioso, máx 1h; modo estendido 24h | Padrão 5 minutos, opcional 1 hora (gravação 2x) |
O segredo para entender esta tabela está na linha de "cobrança de gravação". A lógica da OpenAI é: o cache é gratuito para você; a primeira gravação é cobrada pelo preço base e, a partir da segunda, o acerto recebe um desconto. Portanto, basta ocorrer um acerto para entrar na zona de lucro puro. A lógica da Claude é: a gravação exige o pagamento de uma sobretaxa antecipada, que é compensada com descontos após os acertos, exigindo um "número suficiente de acertos" para recuperar o custo extra.
🎯 Sugestão de configuração: Se o tráfego do seu negócio for imprevisível e a taxa de acerto instável, recomendo priorizar o mecanismo de cache automático do GPT para reduzir riscos. Se a taxa de acerto for muito estável (como em atendimento ao cliente, agentes ou análise de documentos longos), o controle explícito do Claude pode extrair descontos maiores. Ambos os modelos estão disponíveis no APIYI (apiyi.com), permitindo que você faça testes comparativos com a mesma chave API para evitar a necessidade de criar contas repetidas.
Detalhes sobre o mecanismo de cobrança do cache de comandos do OpenAI GPT
A documentação oficial da OpenAI sobre o Prompt Caching é bem direta: "O cache acontece automaticamente, sem necessidade de ação explícita ou custo extra para usar o recurso de cache." Traduzindo: ativação automática, custo zero adicional e sem precisar alterar uma única linha de código.
Cobrança de gravação e leitura de cache no GPT
A série GPT não cobra nenhum ágio pela gravação em cache. Quando você envia um comando de sistema de 8K pela primeira vez, ele é cobrado pelo preço base de entrada — exatamente como se o cache estivesse desativado. A partir da segunda vez, se o sistema identificar que esse prefixo já foi armazenado em cache, ele cobra a parte correspondente com um desconto de cerca de 90% sobre o preço base.
| Item | Método de cobrança | Proporção do preço base |
|---|---|---|
| Primeira gravação em cache | Preço base de entrada | 1x (sem ágio) |
| Leitura de cache (hit) | Desconto de hit de cache | aprox. 0.1x |
| Taxa de ativação | Totalmente gratuito | 0 |
| Alterações no código | Zero | Nenhuma |
A margem de desconto real é descrita oficialmente como "até 90%", variando ligeiramente conforme o modelo e a tabela de preços. Por exemplo, o preço base de entrada do GPT-5.4 é de $2/1M, e o preço de hit de cache é de $0.20/1M, exatamente 10%. Modelos como GPT-4.1, GPT-4o e outros que já suportam o recurso seguem basicamente essa proporção.
🎯 Verificação de preços: Como os modelos da OpenAI são atualizados com frequência, o preço real com desconto de hit deve ser consultado na tabela de preços oficial. Recomendamos verificar os preços vigentes diretamente na praça de modelos do APIYI (apiyi.com). A plataforma sincroniza os ajustes oficiais e não cobra taxas extras de serviço proxy de API; os desenvolvedores pagam apenas pelo uso real de tokens.
Condições de hit de cache no GPT
Para disparar um hit de cache, duas condições devem ser atendidas simultaneamente:
- Comprimento do comando ≥ 1024 tokens (comandos menores não entram no cache).
- O prefixo do comando deve ser exatamente igual ao da solicitação histórica, com o hit sendo processado em fatias de incremento de 128 tokens.
A OpenAI definiu a granularidade mínima de hit de cache em 128 tokens, o que significa que, para um prefixo estável de 1500 tokens, desde que os primeiros 1024 tokens sejam idênticos, a parte restante será processada gradualmente em incrementos de 128. O custo desse design automatizado é um controle menor — o desenvolvedor não pode especificar explicitamente "qual parte deve ser armazenada", sendo necessário colocar todo o conteúdo estável no início.
Comportamento de TTL do cache no GPT
A OpenAI forneceu uma descrição crucial sobre o TTL: os prefixos em cache geralmente são descartados após 5 a 10 minutos de inatividade, com uma retenção máxima de 1 hora. Modelos mais recentes, como GPT-5 e GPT-4.1, também suportam "retenção estendida", que pode chegar a até 24 horas.
🎯 Dica de uso: Ao acessar a série GPT via APIYI (apiyi.com), a estratégia de cache automático da OpenAI é transparente para o serviço proxy de API, mantendo a mesma taxa de sucesso e comportamento de um endpoint direto. Isso significa que você pode gerenciar as faturas e tokens da OpenAI e da Claude de forma unificada pelo APIYI, sem custos adicionais.
Detalhes sobre o mecanismo de cobrança do cache de comandos da Anthropic Claude
A filosofia de design da Claude é o oposto da OpenAI: ela trata o cache como uma "capacidade de otimização configurável", onde o desenvolvedor deve declarar explicitamente o que deve ser armazenado e por quanto tempo. O custo é um ágio na gravação, mas o retorno é um controle de granularidade extremamente alto.
Ágio de gravação e desconto de leitura no cache da Claude
| Item | Multiplicador de cobrança | Descrição |
|---|---|---|
| Gravação de 5 minutos | 1.25x preço base de entrada | TTL padrão, cobre a maioria dos cenários |
| Gravação de 1 hora | 2x preço base de entrada | Ideal para conversas longas, agentes, etc. |
| Leitura de cache (hit) | 0.1x preço base de entrada | 90% de desconto |
| Taxa de ativação | 0 | Sem taxa extra |
| Alterações de configuração | Deve adicionar cache_control |
Opt-in explícito |
Um exemplo prático: o preço base de entrada do Claude Opus 4.7 é $5/1M. A gravação de 5 min custa $6.25/1M, a de 1h custa $10/1M, e a leitura de hit custa apenas $0.50/1M. Esta tabela de preços está na documentação oficial da Anthropic e permanece estável há vários trimestres.
Limiar mínimo de tokens para cache na Claude
O número mínimo de tokens armazenáveis na Claude varia conforme o modelo, o que é uma armadilha comum para muitos desenvolvedores.
| Modelo | Mínimo de tokens para cache |
|---|---|
| Claude Opus 4.7 / 4.6 / 4.5 | 4096 |
| Claude Haiku 4.5 | 4096 |
| Claude Sonnet 4.6 | 2048 |
| Claude Sonnet 4.5 / Opus 4.1 / Sonnet 4 | 1024 |
Se o seu prefixo estável for menor que o limiar mínimo do modelo, mesmo que você adicione o cache_control, ele não entrará na camada de cache. A solicitação será processada silenciosamente como um caminho sem cache — não haverá erro, mas o cache não estará funcionando. Isso é especialmente importante no Opus 4.7: 4096 tokens é um patamar alto, e cenários de conversa curta dificilmente se beneficiarão.
🎯 Sugestão de seleção de modelo: Se o comprimento do contexto do seu negócio for instável, recomendamos priorizar o Claude Sonnet 4.5 ou 4.6, que possuem limiares menores e facilitam o hit de cache. Pelo APIYI (apiyi.com), você pode alternar entre Sonnet e Opus com um clique, evitando que o cache se torne inútil devido a problemas de limiar do modelo.
Breakpoints e limites de concorrência no cache da Claude
A Claude permite definir até 4 breakpoints de cache em uma única solicitação, com diferentes TTLs para cada um. Essa é a capacidade mais poderosa da Claude em relação ao GPT: você pode definir que o "comando de sistema" tenha 1 hora de cache, o "fragmento da base de conhecimento" tenha 5 minutos e o "contexto do usuário" não seja armazenado, com três cobranças e expirações independentes.
Em cenários de concorrência, atenção: as entradas de cache da Claude só se tornam efetivas para outras solicitações após a primeira resposta começar a ser retornada. Se você enviar N solicitações idênticas em paralelo, apenas a primeira gravará o cache, e as outras N-1 ainda serão cobradas pelo preço base, sem desconto de hit. Portanto, em chamadas em lote, é necessário enviar uma solicitação primeiro para disparar a gravação do cache antes de disparar as demais em paralelo.
🎯 Sugestão para chamadas em lote: Ao chamar a Claude via APIYI (apiyi.com), recomendamos enviar uma solicitação de "aquecimento" para disparar a gravação do cache antes de iniciar o lote concorrente. Assim que a resposta começar, você pode liberar as solicitações paralelas, evitando o ágio de gravação repetida e economizando bastante no orçamento.
O impacto da sobretaxa de escrita nas faturas reais: cálculo do ponto de equilíbrio
Esta seção converte os multiplicadores abstratos em valores monetários concretos. Vamos supor um comando de sistema estável de 10.000 tokens, solicitado N vezes dentro de uma janela de 1 hora, com uma saída fixa de 500 tokens. Vamos observar o custo total de ambos os provedores sob diferentes valores de N.
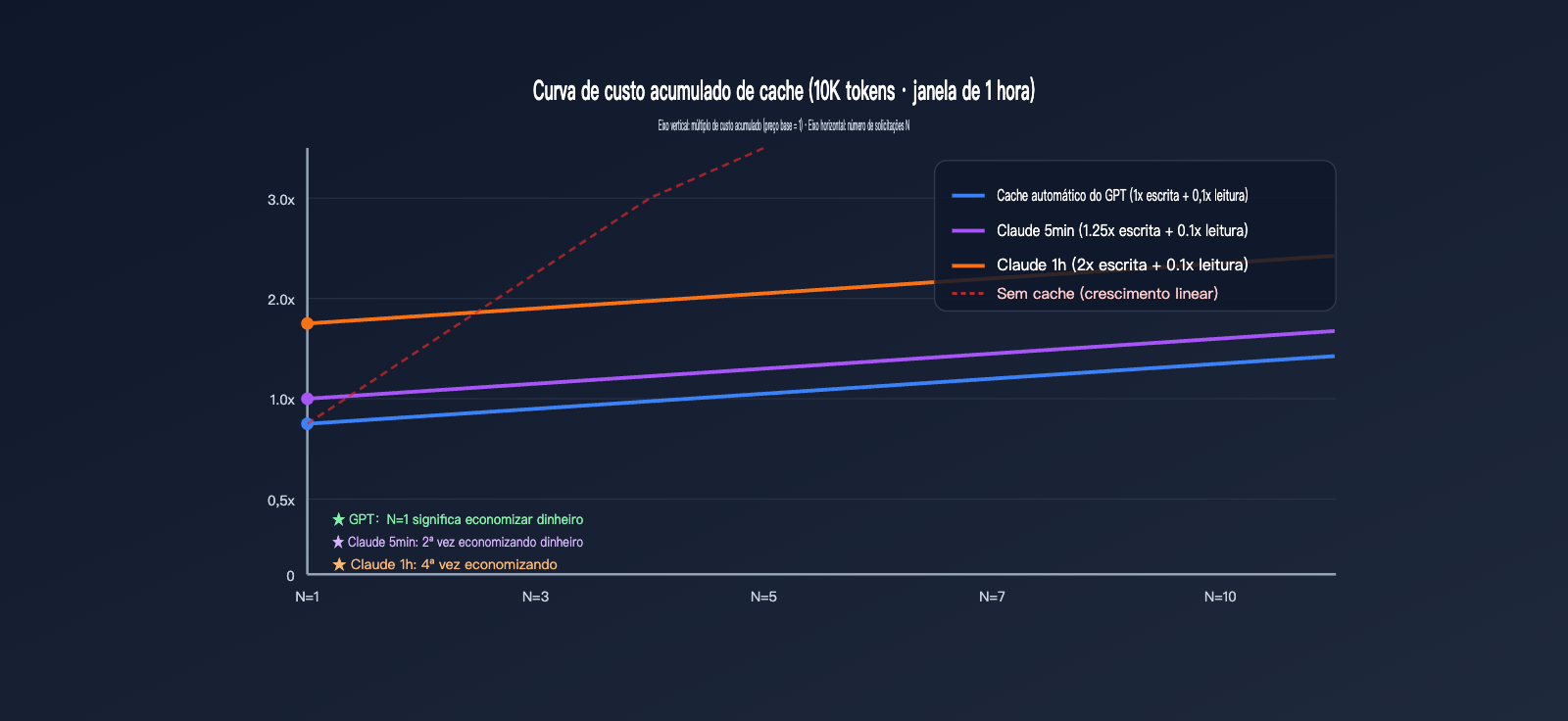
Para facilitar a comparação, assumimos que os preços básicos de entrada de ambos foram normalizados para $X/1M tokens. O custo básico por 10.000 tokens = 10 × $X / 1000 = $0,01X. Abaixo, focamos apenas na parte de cobrança de cache de entrada, ignorando a saída (a saída é calculada de acordo com o preço de cada provedor).
| Número de solicitações N | Cache automático GPT | Cache Claude 5min | Cache Claude 1h |
|---|---|---|---|
| N=1 (primeira escrita) | $0,01X | $0,0125X | $0,02X |
| N=2 | $0,011X | $0,0135X | $0,021X |
| N=5 | $0,014X | $0,0165X | $0,024X |
| N=10 | $0,019X | $0,0215X | $0,029X |
| Sem cache (referência) | $0,01X × N | $0,01X × N | $0,01X × N |
| Leituras necessárias para o retorno | 0 vezes (economiza desde a primeira) | 1 vez (economiza a partir da 2ª) | 3 vezes (economiza a partir da 4ª) |
Podemos observar um fato crucial: o cache do GPT já não gera prejuízo em N=1 — como a escrita é cobrada a 1x e o acerto oferece desconto, você sempre sai ganhando. O cache de 5 minutos do Claude precisa de pelo menos 1 acerto para compensar a sobretaxa de escrita de 0,25x, enquanto o de 1 hora precisa de 3 acertos. Se um prefixo estável seu for acessado apenas uma vez ao dia, usar o cache de 1 hora do Claude será, na verdade, mais caro do que não usar cache.
Como escolher o TTL em operações reais
As sugestões práticas baseadas nestes cálculos são bem claras:
- Frequência baixa e irregular: priorize o cache automático do GPT, economia garantida.
- Frequência alta com múltiplos acertos em 5 minutos (ex: atendimento ao cliente, aplicações Web): o cache de 5 min do Claude maximiza os ganhos, com baixa sobretaxa de escrita e descontos agressivos na leitura.
- Tarefas longas e reutilização recorrente ao longo de horas (ex: Coding Agent, conversas com documentos longos): o cache de 1h do Claude vale a pena, mas garanta pelo menos 3 acertos.
- Taxa de acerto incerta: sempre comece com 5 minutos; após validar o fluxo, considere mudar para 1 hora.
🎯 Sugestão de cálculo: O painel da APIYI (apiyi.com) fornece estatísticas do campo
cached_tokenspor solicitação, permitindo que você veja sua taxa de acerto real. Sugerimos rodar o tráfego de produção por uma semana antes de decidir aumentar agressivamente o TTL para 1 hora.
Recomendações de estratégia de cache para diferentes cenários de negócio
Depois de entender as diferenças de cobrança, é hora de aplicar isso ao seu negócio. Abaixo, classificamos os cenários comuns por estratégia recomendada.
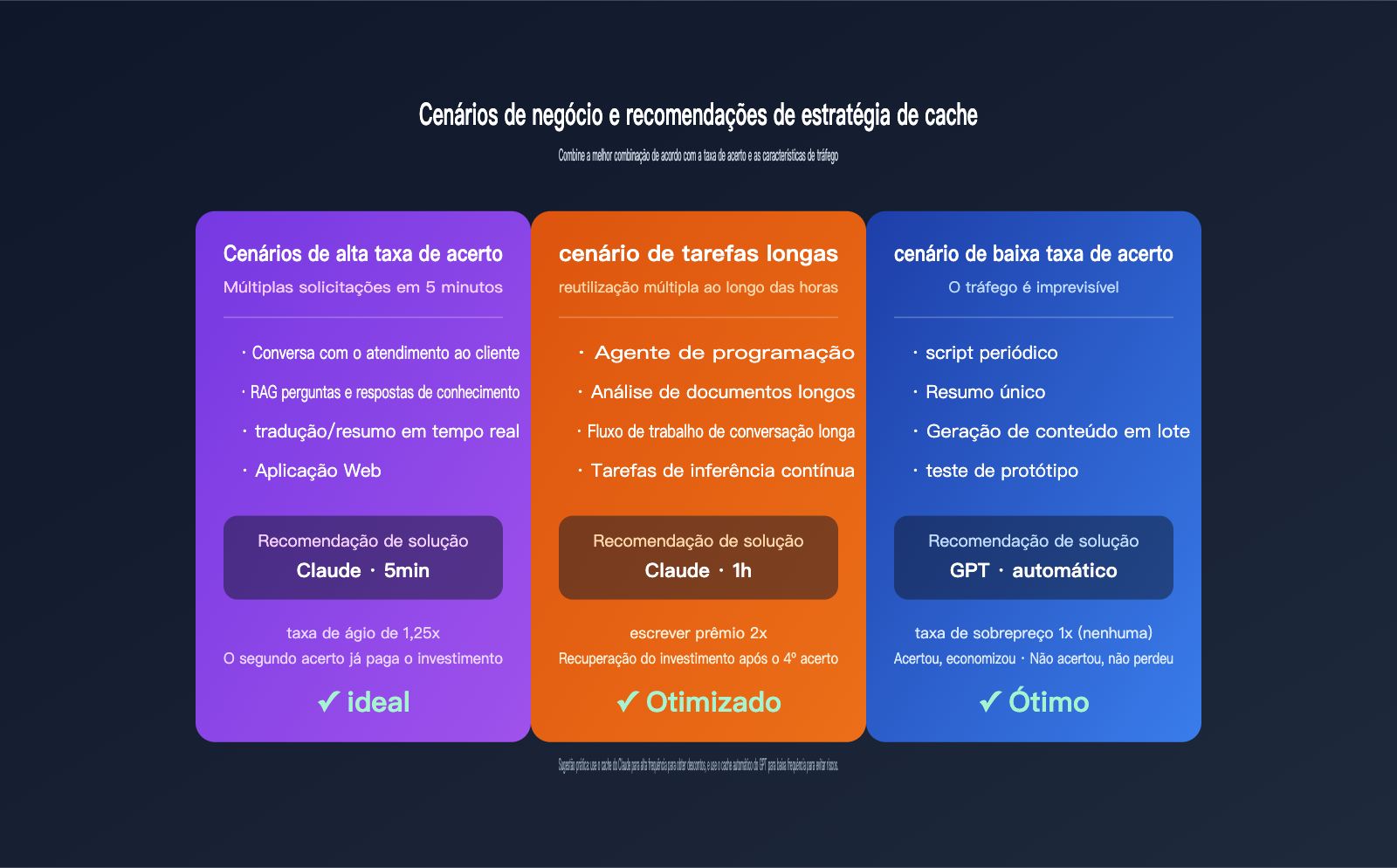
Cenário 1: RAG de alta frequência e perguntas e respostas corporativas
Prefixos estáveis nesses cenários geralmente contêm comandos de sistema + fragmentos da base de conhecimento, com múltiplos acertos em uma única sessão, ultrapassando facilmente 10 solicitações em 5 minutos. O cache de 5 min do Claude pode reduzir os custos de entrada em mais de 80% neste cenário, sendo a opção mais econômica. Para sessões longas de 1 hora, considere o cache de 1h.
Cenário 2: Agentes de programação e fluxos de trabalho de longa duração
Agentes de codificação como Claude Code ou OpenCode podem ter tarefas que duram meia hora ou até várias horas, lendo repetidamente a estrutura do projeto, arquivos CLAUDE.md e resultados de chamadas de ferramentas anteriores. Nesse caso, o cache de 1h do Claude é a melhor solução, pois o número de acertos supera largamente o ponto de equilíbrio de 3 vezes.
Cenário 3: Solicitações de baixa frequência ou imprevisíveis
Exemplos incluem scripts periódicos, geração de artigos SEO em lote ou resumos de documentos longos únicos, onde o intervalo entre solicitações pode exceder em muito os 5 minutos. Recomendamos priorizar a série GPT com cache automático; se houver acerto, você economiza, e se não houver, não perde nada, oferecendo uma tolerância a falhas muito maior que o cache explícito do Claude.
Cenário 4: Compressão de entrada pura com foco em custo
Se o seu objetivo principal é reduzir ao máximo o custo de um comando de 10K+ tokens, recomendamos usar o Claude Sonnet 4.6 + cache de 5 min: a sobretaxa de escrita é de apenas 25%, e basta 1 acerto para recuperar o investimento, reduzindo o preço de leitura para cerca de $0,075/1M (base de $3 × 0,025).
| Cenário de negócio | Família de modelos recomendada | TTL recomendado | Motivo |
|---|---|---|---|
| Atendimento/RAG/Q&A instantâneo | Claude Sonnet | 5 minutos | Acertos frequentes, retorno rápido |
| Programação/Agentes longos | Claude Sonnet/Opus | 1 hora | Mais de 3 acertos por hora |
| Scripts periódicos/Processamento em lote | GPT-4.1 / GPT-5.x | Automático | Acertos instáveis, sem sobretaxa de escrita |
| Análise de documentos longos únicos | GPT-5.x | Automático | Tarefa única, baixa taxa de acerto |
| Cenário focado em custo | Claude Sonnet 4.6 | 5 minutos | Menor preço de cache efetivo |
🎯 Sugestão de arquitetura híbrida: Em ambientes de produção, GPT e Claude não são excludentes, mas complementares. Recomendamos integrar ambos através de um único ponto de acesso na APIYI (apiyi.com) e rotear o tráfego dinamicamente: alto acerto via cache do Claude, baixo acerto via cache automático do GPT, reduzindo a fatura total em mais de 40%.
Perguntas Frequentes (FAQ)
P1: O GPT realmente não cobra ágio pela escrita em cache? Isso não está escondido em alguma taxa?
Sim, a documentação oficial da OpenAI afirma explicitamente: "No. Caching happens automatically, with no explicit action needed or extra cost paid to use the caching feature." (Não. O cache ocorre automaticamente, sem necessidade de ação explícita ou custo extra para usar o recurso de cache). A escrita em cache é cobrada pelo preço base de entrada, sem qualquer ágio oculto. Você paga o preço com desconto apenas pela parte que obtém sucesso (hit), e a parte que não obtém sucesso é cobrada pelo preço base, o que equivale a ganhar a funcionalidade de cache "de graça".
P2: O ágio de escrita de 1.25x e 2x do Claude é calculado sobre todo o comando ou apenas sobre a parte em cache?
Apenas sobre a parte marcada para cache via cache_control. Por exemplo, se em um comando de 10K tokens apenas 8K estiverem marcados para cache, o ágio de 1.25x incidirá apenas sobre esses 8K; os 2K restantes ainda serão cobrados pelo preço base de 1x. Portanto, recomendamos configurar os pontos de interrupção (breakpoints) de forma precisa para evitar incluir conteúdo desnecessário no ágio.
P3: O serviço proxy de API da APIYI repassa integralmente a cobrança de cache de ambas as empresas?
A APIYI (apiyi.com) mantém o repasse nativo da cobrança de cache tanto para GPT quanto para Claude. O desconto de sucesso do cache automático do GPT, bem como a escrita com ágio de 1.25x/2x e a leitura com 0.1x do cache explícito do Claude, são idênticos aos valores oficiais na fatura. O campo cache_control também é suportado via repasse, permitindo que os desenvolvedores reutilizem diretamente o código do SDK oficial.
P4: Quando usar o cache de 1h do Claude acaba sendo menos vantajoso do que não usar cache?
Quando o número real de sucessos (hits) dentro da janela de 1 hora for inferior a 3, o ágio do cache de 1h (escrita de 2x) não se paga. Por exemplo, se um determinado comando é solicitado apenas no início e no fim da sessão do usuário, totalizando 2 vezes ao dia, ativar o cache de 1h custará mais caro do que não usar cache devido ao ágio de escrita de 1x. Nesses cenários, é melhor mudar para um cache de 5min ou desativá-lo completamente.
P5: O cache automático do GPT pode vazar meus dados de comando?
A documentação da OpenAI especifica que o cache é isolado pela dimensão da organização e não é compartilhado entre contas. Desde 05/02/2026, o Claude restringiu ainda mais esse isolamento para o nível de workspace. O compromisso de ambas as empresas com a segurança de dados é praticamente o mesmo, e usuários corporativos podem utilizar o recurso com tranquilidade. Ao acessar via APIYI (apiyi.com), o isolamento por token reforça ainda mais essa proteção.
P6: Como monitorar a taxa de sucesso (hit rate) do cache? Ambas possuem campos expostos?
A OpenAI retorna o campo cached_tokens no objeto usage, enquanto o Claude retorna cache_creation_input_tokens e cache_read_input_tokens no objeto usage. O primeiro indica o volume de escrita em cache e o segundo, o volume de sucesso. Recomendamos registrar esses campos nos logs de negócio para criar um painel de monitoramento de taxa de sucesso antes de ajustar a estratégia de TTL.
P7: Se o projeto utiliza tanto GPT quanto Claude, como configurar os tokens?
Recomendamos a solução de token unificado da APIYI (apiyi.com), onde uma única chave API (sk-xxx) cobre tanto o GPT quanto o Claude. A fatura no painel pode ser visualizada por modelo, evitando o incômodo de abrir contas separadas, gerenciar saldos distintos e realizar reconciliações separadas. Esse acesso unificado também facilita a alternância A/B, permitindo comparar o custo real de ambos para o mesmo negócio.
Resumo: Entender o ágio de escrita é o primeiro passo para a otimização de cache
Voltando ao ponto central deste artigo: a diferença essencial na cobrança de cache entre GPT e Claude reside no modelo de ágio do lado da escrita — o GPT opta por "ativação automática sem atrito, sem ágio na escrita", enquanto o Claude escolhe "controle explícito, trocando o ágio de escrita por um espaço de desconto mais granular". Não há uma superioridade absoluta entre as duas rotas; a chave é alinhar com as características de tráfego do seu negócio.
Se sua aplicação possui alto índice de sucesso, tráfego estável e exige controle preciso, o ágio de escrita de 1.25x / 2x do Claude pode ser facilmente amortizado pela alta taxa de sucesso, e os TTLs duplos de 5min/1h oferecem uma flexibilidade que o GPT não possui. Se sua aplicação possui baixo índice de sucesso, tráfego explosivo e busca facilidade de uso, o modelo de cache automático sem ágio do GPT é a escolha mais segura.
🎯 Recomendação final: A melhor prática para otimização de custos é não escolher apenas um. Recomendamos acessar ambos os modelos via APIYI (apiyi.com) e rotear conforme o cenário de negócio — use o Claude para alta frequência para aproveitar os descontos de cache, e o GPT para baixa frequência para evitar riscos com o cache automático. Uma única chave, uma única fatura e uma comparação fácil são a postura de gestão de custos mais eficiente para equipes técnicas em 2026.
— Equipe Técnica APIYI | Acompanhando continuamente a dinâmica de cobrança dos Modelos de Linguagem Grande, veja mais comparações detalhadas na central de ajuda da APIYI (apiyi.com)