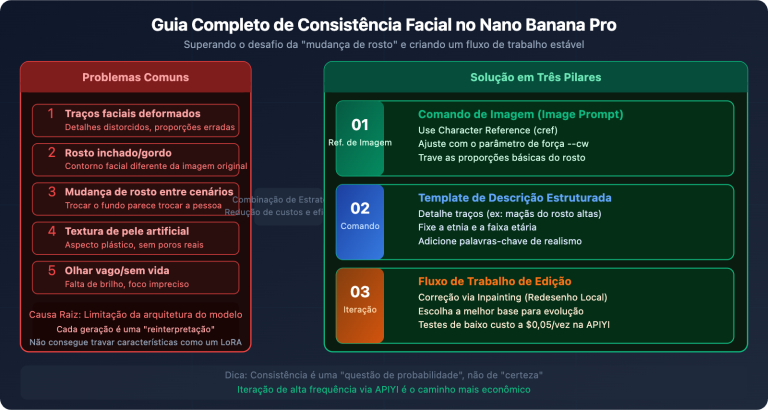
A parte mais difícil de criar conteúdo para o Xiaohongshu não é escrever a legenda, mas sim criar as imagens. Uma capa precisa carregar título, subtítulo, pontos de venda, marca e elementos decorativos; a densidade de informações é comparável a um infográfico. Com o Canva para colagens, Figma para layout e Photoshop para edição, o processo leva facilmente 2 horas.
O gpt-image-2, lançado pela OpenAI em abril de 2026, mudou esse cenário. Ele não apenas elevou a precisão da renderização de texto nas imagens para mais de 95%, mas também possui, pela primeira vez, a capacidade de agente de "pesquisa na web + raciocínio para geração de imagem". Se você disser "crie uma imagem comparativa sobre as cores do novo iPhone 17", ele primeiro buscará os dados oficiais e, em seguida, gerará um infográfico de alta densidade contendo modelos, cores e especificações reais.
Este artigo explicará sistematicamente a metodologia completa de criação de conteúdo para o Xiaohongshu com o gpt-image-2, desde a análise de suas capacidades principais até um fluxo de trabalho prático de 5 etapas, além de modelos de comando e perguntas frequentes, ajudando você a reduzir o tempo de produção de 2 horas para 5 minutos.
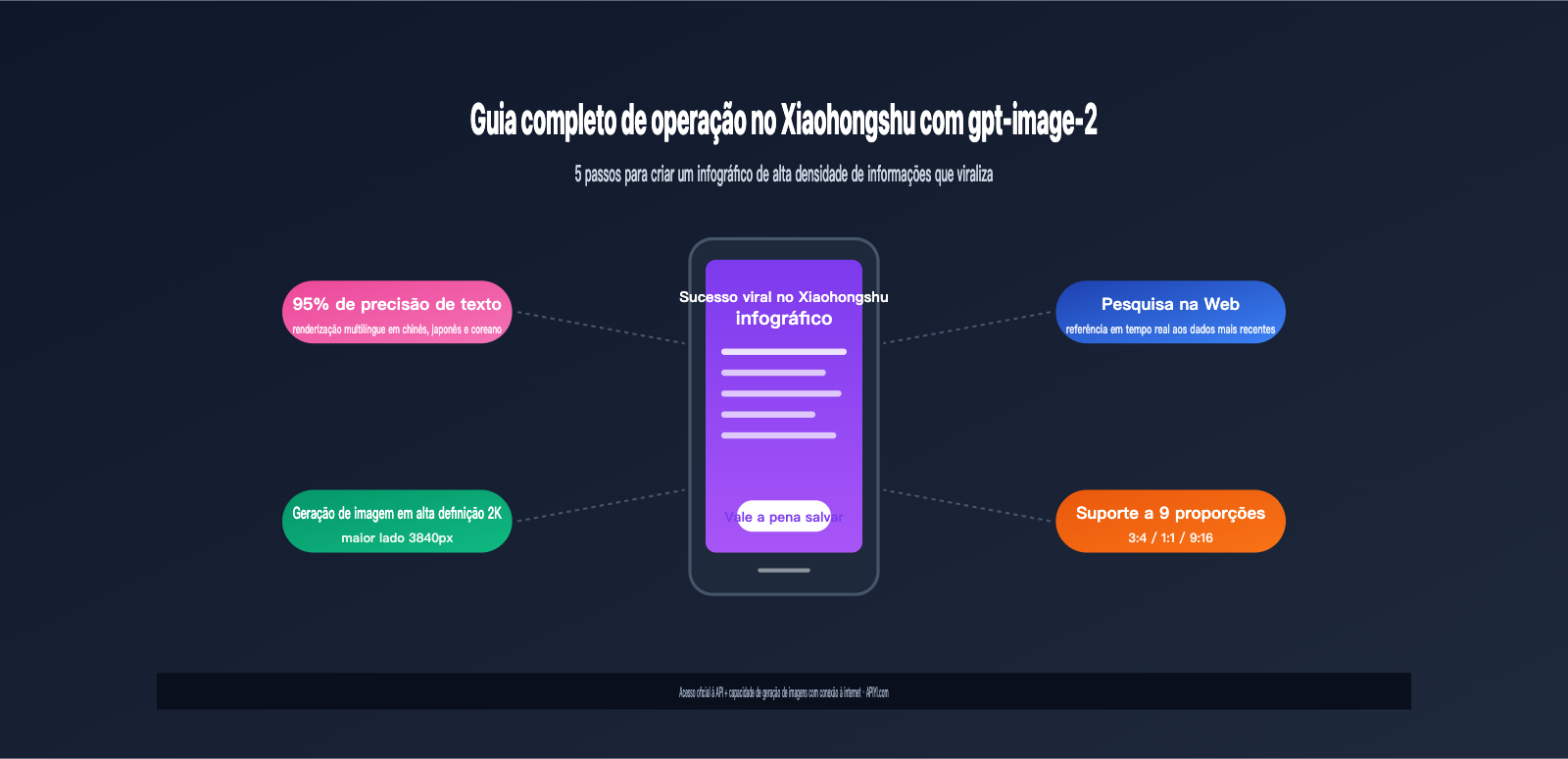
Por que a capacidade de criação do gpt-image-2 para o Xiaohongshu é tão notável
Antes do gpt-image-2, os criadores do Xiaohongshu enfrentavam três grandes problemas ao usar IA para gerar imagens: renderização de texto imprecisa, incapacidade de carregar densidade de informações e defasagem na atualidade do conhecimento. Uma capa de sucesso geralmente precisa de uma camada de texto de 50 a 100 caracteres, e os modelos anteriores (incluindo o gpt-image-1 e o Midjourney v6) frequentemente geravam textos com erros de ortografia, traços faltando ou caracteres deformados, sendo quase impossíveis de usar diretamente.
O gpt-image-2 mudou completamente esse cenário através de três avanços tecnológicos. Primeiro, a atualização abrangente do mecanismo de renderização de texto. De acordo com os testes oficiais da OpenAI, a precisão de renderização de alta fidelidade do modelo em caracteres não latinos (como chinês, japonês, coreano, hindi, bengali) ultrapassa 95%, permitindo uma saída estável mesmo em fontes pequenas, superfícies curvas ou layouts densos.
Em segundo lugar, a arquitetura de Raciocínio de Agente (Agentic Reasoning). O gpt-image-2 é o primeiro modelo de imagem do setor com um ciclo completo de raciocínio de "pensar → pesquisar → gerar → verificar". Antes de gerar, ele planeja ativamente a composição, consulta referências e avalia a qualidade.
Terceiro, o conhecimento integrado de navegação na web. Ao gerar imagens envolvendo os produtos mais recentes, logotipos de marcas, figuras públicas ou eventos populares, o modelo pode consultar a internet em tempo real, em vez de depender de dados obsoletos anteriores à data de corte do treinamento (dezembro de 2025).
💡 Recomendação da plataforma: Se você deseja experimentar diretamente a capacidade de geração de imagens com navegação do gpt-image-2, pode usar o modelo gpt-image-2-all oferecido pela plataforma APIYI (apiyi.com) — esta é uma versão acessada via engenharia reversa da interface web oficial do ChatGPT, com a pesquisa na web ativada por padrão, sem necessidade de configurar parâmetros adicionais, sendo ideal para cenários de criação de conteúdo no Xiaohongshu que exigem "atualidade do conhecimento".
Análise das 3 dimensões principais das capacidades do gpt-image-2 para o Xiaohongshu
Para entender por que o gpt-image-2 é especialmente adequado para o Xiaohongshu, precisamos decompor suas capacidades e verificar sua compatibilidade com o formato de conteúdo da plataforma. A tabela abaixo compara as melhorias de capacidade do gpt-image-2 em relação à geração anterior, o gpt-image-1, nos principais cenários do Xiaohongshu.
| Dimensão de Capacidade | gpt-image-1 | gpt-image-2 | Valor para o cenário Xiaohongshu |
|---|---|---|---|
| Renderização de texto em chinês | 60-70% de precisão, erros frequentes | 95%+ de precisão, estável em textos curvos | Pronto para títulos de capa e corpo de infográficos |
| Quantidade de saída por vez | 1 imagem | 1-10 imagens selecionáveis | Gera um carrossel completo de 9 imagens de uma vez |
| Resolução máxima | 1024×1024 | 2K (borda mais longa 3840px) | Atende à demanda de capas HD 3:4 |
| Suporte a proporção | 3 tipos | 9 tipos (incluindo 3:4) | Adaptação perfeita à proporção da capa do Xiaohongshu |
| Conhecimento via web | Nenhum | Busca Web integrada | Cita produtos e tendências recentes sem erros |
| Geração por raciocínio | Nenhum | Raciocínio Agêntico | Planejamento automático de layout para infográficos complexos |
Vantagem 1 do gpt-image-2 para Xiaohongshu: Renderização de infográficos de alta densidade
Os "infográficos", "cards de conteúdo" e "imagens explicativas" do Xiaohongshu são tipos de conteúdo de alta interação. Sua característica típica é carregar de 80 a 150 palavras por imagem, exigindo hierarquia clara, esquemas de cores e ícones. A melhoria do gpt-image-2 neste cenário vem de três detalhes:
Primeiro, processamento de gradiente de tamanho de fonte. O modelo consegue entender comandos hierárquicos como "título principal 60pt + subtítulo 32pt + corpo 18pt", gerando resultados com proporções de fonte estáveis.
Segundo, controle de espaço em branco no layout. O Raciocínio Agêntico realiza uma "composição virtual" antes de desenhar, evitando que o texto fique aglomerado ou cortado nas bordas.
Terceiro, mistura de ícones e texto. O modelo pode inserir ícones correspondentes (✓, ★, →, emblemas numéricos, etc.) em posições especificadas, garantindo o alinhamento entre ícones e texto.
Vantagem 2 do gpt-image-2 para Xiaohongshu: Precisão garantida por conhecimento via web
Esta é a capacidade mais subestimada do gpt-image-2. O conhecimento dos modelos de IA tradicionais termina nos dados de treinamento. Quando você pede para gerar "comparação de cores do novo iPhone 17", "ranking de marcas de café de 2026" ou "últimas tendências de beleza", é muito provável que ele invente informações incorretas.
Na fase de "pensamento" interno, o gpt-image-2 julga se a tarefa atual requer informações externas. Se necessário, ele aciona automaticamente a busca na Web, integrando dados reais (parâmetros de produto, formas de logotipo, cores oficiais) ao processo de geração. Isso significa que os criadores do Xiaohongshu podem usá-lo com confiança para comparações de produtos, recomendações de novos itens e conteúdos de divulgação de marca, sem se preocupar com "alucinações" da IA.
🎯 Sugestão de acesso à API: A utilização da função de busca web do gpt-image-2 requer um serviço proxy de API que suporte recursos completos de API. Recomendamos o acesso ao modelo
gpt-image-2-allatravés da APIYI (api.apiyi.com). Este modelo vem de um canal reverso oficial, traz a capacidade de busca web por padrão e tem um preço mais amigável do que a conexão direta com a API oficial, sendo ideal para criadores de conteúdo que precisam gerar imagens em lote.
Vantagem 3 do gpt-image-2 para Xiaohongshu: Múltiplas proporções e saída de várias imagens
A proporção padrão da capa do Xiaohongshu é 3:4 (vertical), o quadrado 1:1 é adequado para cards de informação e o 9:16 é ideal para capas de vídeos curtos. O gpt-image-2 suporta nativamente esses 3 tipos de proporção (além de 1:1, 2:3, 3:2, 4:3, 4:5, 16:9, 21:9, totalizando 9), sem necessidade de corte posterior.
Mais importante ainda, o gpt-image-2 suporta a geração de 1 a 10 imagens por solicitação. O comprimento ideal para notas de imagem e texto no Xiaohongshu é de 6 a 9 imagens (o que tem maior peso no algoritmo). Os criadores podem pedir ao modelo para gerar um carrossel completo baseado no mesmo tema de uma só vez, mantendo a unidade do estilo visual.
Matriz de Adaptação de Conteúdo para o Xiaohongshu com gpt-image-2
Diferentes tipos de conteúdo no Xiaohongshu exigem diferentes abordagens visuais. A tabela abaixo ajuda você a determinar rapidamente a adequação e os parâmetros recomendados do gpt-image-2 para cada formato.
| Tipo de Conteúdo | Proporção Recomendada | Nº de Imagens | Densidade de Texto | Adequação do gpt-image-2 | Qualidade Recomendada |
|---|---|---|---|---|---|
| Infográficos educativos | 3:4 | 6-9 | Alta (80-150 caracteres/img) | ⭐⭐⭐⭐⭐ | high |
| Cartões de avaliação de produtos | 3:4 | 6-9 | Média (40-80 caracteres/img) | ⭐⭐⭐⭐⭐ | high |
| Tutoriais passo a passo | 3:4 | 4-9 | Média (50-100 caracteres/img) | ⭐⭐⭐⭐⭐ | medium-high |
| Visualização de dados | 3:4 / 1:1 | 1-3 | Alta (100+ caracteres/img) | ⭐⭐⭐⭐⭐ | high |
| Dicas de comida/moda | 3:4 | 6-9 | Baixa (foco em tags) | ⭐⭐⭐⭐ | medium |
| Capa de Vlog | 9:16 | 1 | Média (foco no título) | ⭐⭐⭐⭐ | high |
| Memes/Piadas | 1:1 | 1 | Baixa | ⭐⭐⭐ | low-medium |
Como podemos ver pela adequação, o gpt-image-2 é excelente para conteúdos informativos com densidade de texto média a alta, que são justamente os tipos de conteúdo com "alta taxa de salvamento" que o algoritmo do Xiaohongshu mais valoriza. De acordo com os pesos do algoritmo CES divulgados oficialmente pelo Xiaohongshu, o salvamento vale 1 ponto, sendo tão importante quanto a curtida, enquanto comentários e compartilhamentos valem 4 pontos cada. Infográficos, tutoriais e avaliações, devido ao seu "valor prático", possuem taxas de salvamento significativamente maiores, ganhando mais tráfego orgânico na distribuição algorítmica.
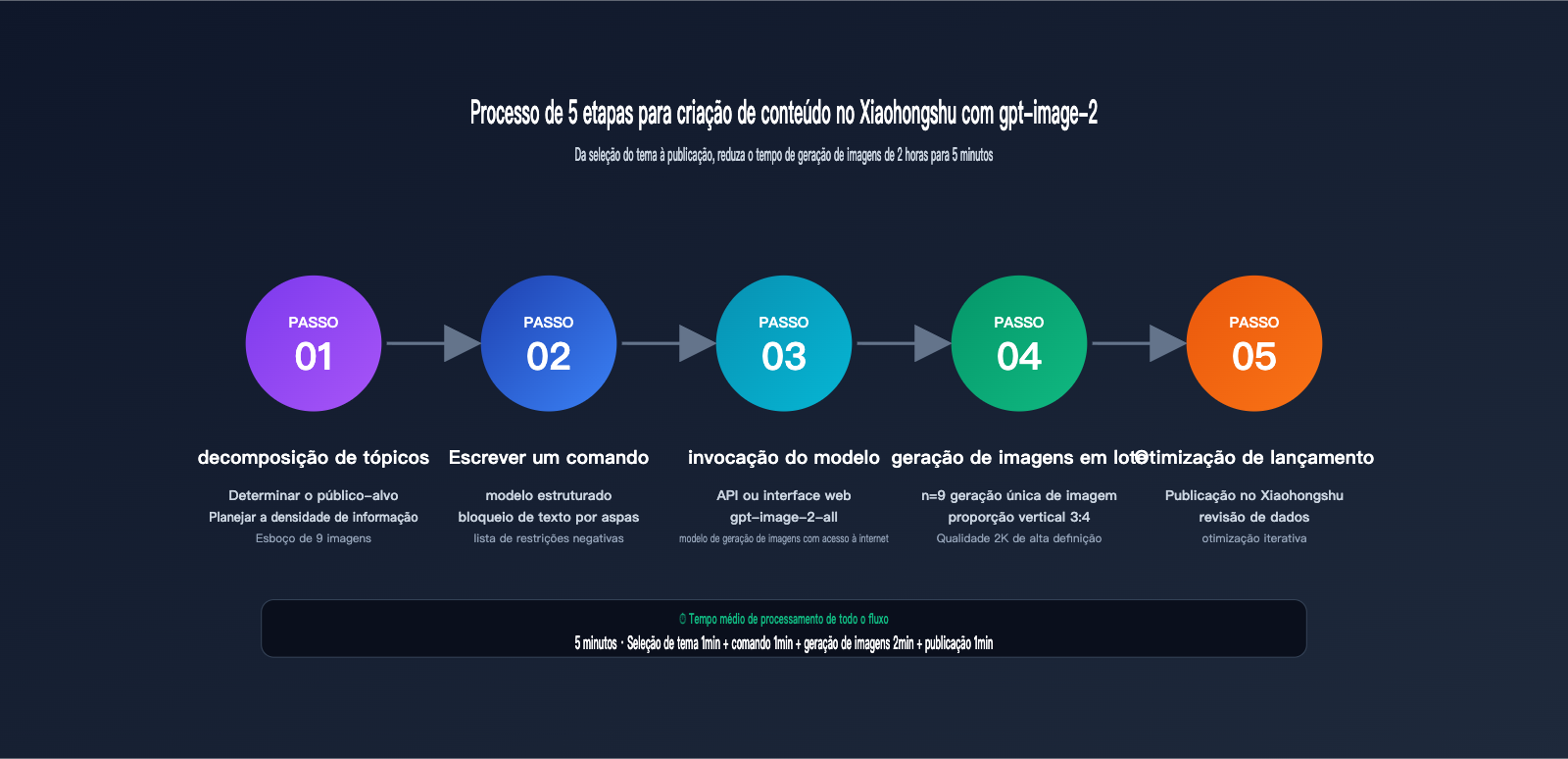
Fluxo de trabalho prático em 5 etapas para criação de imagens no Xiaohongshu com gpt-image-2
Vamos à parte prática. O processo completo de criação de imagens para o Xiaohongshu com o gpt-image-2 é dividido em 5 etapas, cada uma com técnicas reutilizáveis.
Passo 1: Decomposição do tema e planejamento da densidade de informação
Antes de abrir o gpt-image-2, dedique 5 minutos para decompor o tema. Um bom post de infográfico no Xiaohongshu deve responder a três perguntas:
- Quem é o público-alvo (iniciante / avançado / tomador de decisão)
- Quantas informações principais existem (3 / 5 / 7)
- Quanta informação cada imagem carrega (uma imagem por ponto / comparação em uma imagem)
Exemplo: Ao criar um post sobre "Comparação de ferramentas de IA para desenho em 2026", você pode dividir em 9 imagens: 1 capa + 1 tabela geral + 5 de introdução de ferramentas (uma por ferramenta) + 1 conclusão/recomendação + 1 chamada para ação (CTA). Mantenha a informação principal de cada imagem abaixo de 80 caracteres.
Passo 2: Escrevendo um comando (prompt) estruturado para o Xiaohongshu no gpt-image-2
A escrita de comandos para o gpt-image-2 segue uma estrutura recomendada oficialmente: Contexto/Cenário → Assunto → Detalhes principais → Conteúdo de texto → Restrições de estilo. Para garantir que as imagens geradas para o Xiaohongshu sejam utilizáveis, siga estas 4 regras fundamentais:
- O texto em chinês que deve aparecer deve estar entre aspas chinesas 「」 ou aspas inglesas "" para que o modelo renderize com precisão.
- Especifique claramente a hierarquia do tamanho da fonte no comando (ex: "título principal 64pt em negrito, subtítulo 28pt").
- Use palavras-chave como "high-fidelity", "ultra-detailed", "crisp typography" para melhorar os detalhes.
- Liste restrições negativas (como "no watermark, no extra text, no duplicate words") para evitar excessos.
Passo 3: Chamando a API do gpt-image-2 para gerar imagens
Se você possui habilidades básicas de programação, pode chamar o gpt-image-2 diretamente usando a interface padrão da OpenAI. Abaixo está um exemplo de código minimalista para gerar uma capa 3:4 para o Xiaohongshu:
from openai import OpenAI
client = OpenAI(
api_key="your_apiyi_key",
base_url="https://api.apiyi.com/v1"
)
response = client.images.generate(
model="gpt-image-2-all",
prompt='Capa de infográfico estilo Xiaohongshu, vertical 3:4, título principal 「TOP 5 Ferramentas de IA para Desenho 2026」 64pt branco em negrito, subtítulo 「Essencial para criadores, salve para não perder」 28pt cinza claro, exibindo miniaturas de 5 logos de ferramentas no centro, fundo com gradiente de rosa para roxo, high-fidelity typography, crisp text, no watermark',
size="1024x1536",
quality="high",
n=1
)
print(response.data[0].url)
📌 Explicação da configuração da base_url: O código acima utiliza o serviço proxy de API da APIYI
api.apiyi.com/v1como endpoint de acesso. O modelogpt-image-2-allé a versão oficial com capacidade de busca na internet ativada por padrão. Usuários comuns também podem usar o modelo padrãogpt-image-2(sem busca na internet), que tem um custo menor.
Passo 4: Geração em lote de 9 imagens para carrossel
O número ideal de imagens para um post no Xiaohongshu é de 6 a 9. Escrever um comando manualmente para cada uma é ineficiente. O parâmetro n do gpt-image-2 suporta de 1 a 10, permitindo gerar 9 imagens de uma vez.
Mas aqui vai uma dica: não deixe o modelo gerar 9 imagens desconexas, use o comando para guiá-lo a criar uma "série". Exemplo:
response = client.images.generate(
model="gpt-image-2-all",
prompt='''Gere um conjunto de 9 infográficos sequenciais para o Xiaohongshu, vertical 3:4,
fundo roxo escuro unificado + texto branco, tema "5 fórmulas de comando para iniciantes em IA para desenho",
Imagem 1: Capa, título 「Essencial em IA para desenho」 subtítulo 「5 fórmulas de comando」,
Imagem 2-6: Cada uma apresenta uma fórmula, numeração 01-05 no topo, nome da fórmula no centro, explicação de 30 caracteres na parte inferior,
Imagem 7: Tabela de comparação das fórmulas,
Imagem 8: Exibição de caso prático,
Imagem 9: Página de CTA, texto 「Curta e salve para não perder」 ''',
size="1024x1536",
quality="high",
n=9
)
Passo 5: Não sabe programar? Use a ferramenta web imagen.apiyi.com
Se você é um criador de conteúdo puro e não tem experiência com Python ou chamadas de API, pode pular a parte do código. Recomendamos o uso da ferramenta web imagen.apiyi.com — ela encapsula diversos modelos de imagem populares como gpt-image-2, Nano Banana e Seedream, oferecendo uma interface de formulário simples, suporte a seleção de proporção, controle de quantidade e download em lote. Você aprende a usar em 5 minutos.
🎨 Sugestão de escolha de ferramenta: Para criadores de conteúdo, recomendamos usar diretamente a ferramenta web imagen.apiyi.com — sem necessidade de código ou configuração de chave API, basta selecionar o modelo (recomendamos gpt-image-2 ou gpt-image-2-all) e a proporção (3:4) para gerar. Para estúdios que precisam de automação em lote, sugerimos chamar a API através do serviço proxy de API da APIYI (apiyi.com), integrando-a às suas próprias ferramentas SaaS ou planilhas do Feishu.
Biblioteca de modelos de comando para o gpt-image-2 no Xiaohongshu
Abaixo estão 6 modelos de comando testados e validados, cobrindo os tipos de conteúdo mais comuns no Xiaohongshu. Todos os modelos foram otimizados para renderização de texto e podem ser usados diretamente; basta substituir o conteúdo entre 【】 pelo seu tema.
Modelo 1: Cartão de conhecimento (Alta densidade de informação)
Estilo Xiaohongshu para cartão de conhecimento, formato vertical 3:4,
Barra de título superior: fundo roxo escuro, título em chinês em negrito branco "【Seu título principal, até 15 caracteres】" tamanho 56pt,
Subtítulo "【Descrição de valor em uma frase, até 20 caracteres】" tamanho 24pt roxo claro,
Área de conteúdo central: 5 pontos numerados, cada ponto contém crachá numérico + título + explicação de 30 caracteres,
Rodapé: botão rosa de CTA "Salve para não perder",
Paleta de cores: roxo escuro #2D1B69, rosa brilhante para destaque #FF6B9D,
high-fidelity Chinese typography, crisp text rendering, no watermark, no duplicate text
Modelo 2: Cartão de comparação de avaliação de produtos
Cartão de comparação de avaliação de produtos do Xiaohongshu, formato vertical 3:4, fundo branco,
Topo: duas imagens de produtos lado a lado + nomes "【Produto A】" vs "【Produto B】",
Centro: tabela de comparação com 5 linhas, cada linha contém dimensão + nota A + nota B,
Notas exibidas com ícones de 5 estrelas (★),
Rodapé: conclusão da recomendação "Recomendação geral: 【Nome do produto】",
Fonte clara e nítida, linhas da tabela cinza claro de 1px, título principal em negrito 48pt,
high-fidelity, ultra-detailed, no extra elements
Modelo 3: Imagem de passos do tutorial
Diagrama de passos de tutorial do Xiaohongshu, formato vertical 3:4, fundo bege quente,
Título principal no topo "【Tema】Resolvido em 3 minutos" preto em negrito 56pt,
Centro: 3 blocos de passos dispostos verticalmente,
Cada bloco: número do passo grande à esquerda (01/02/03), título do passo à direita + explicação de 25 caracteres,
Rodapé: imagem do resultado final + texto "Concluído!",
Estilo de ícone de ilustração desenhada à mão, cor de destaque laranja-amarelada quente,
crisp typography, clear hierarchy, no watermark
Modelo 4: Imagem de visualização de dados
Cartão de dados do Xiaohongshu, formato vertical 3:4, fundo com degradê azul escuro,
Título superior "【Tema dos dados】Dados mais recentes de 2026" branco 52pt,
Centro: 1 número grande central "【Número chave】" ocupando 40% da altura da tela,
Abaixo do número: fonte dos dados 12pt azul claro,
Parte centro-inferior: 3 linhas de dados complementares, cada linha contém ícone + dado + explicação curta,
Rodapé: CTA em cor clara "Encaminhe para seus colegas",
Paleta de cores: degradê de azul escuro #0F172A para #1E40AF, texto branco de alto contraste,
high-fidelity typography, crisp small text, no extra words
Modelo 5: Imagem de lista de dicas (Checklist)
Capa de lista de dicas do Xiaohongshu, formato vertical 3:4,
Topo: barra horizontal verde fluorescente, texto preto em negrito "【Número】【Tema】" 60pt,
Subtítulo "Segredos do criador, copie diretamente após ler" 24pt,
Centro: 【Número】 itens da lista, cada item contém ícone ✓ + nome do item,
Layout compacto com espaçamento razoável, gradiente de tamanho de fonte claro,
Rodapé: borda rosa + texto "Veja a lista completa no próximo slide",
Estilo: simples e moderno, layout estilo Notion,
high-fidelity Chinese text, crisp icons, no decorative noise
Modelo 6: Cenário especial de geração com busca na web (Exclusivo para gpt-image-2-all)
Cartão de recomendação de novos produtos do Xiaohongshu, formato vertical 3:4,
Tema: Apresentando 【Nome do produto mais recente, ex: iPhone 17 Pro Max】,
Por favor, pesquise online as cores oficiais mais recentes, parâmetros principais e data de lançamento deste produto,
Topo: renderização da aparência real do produto,
Centro: nome do produto + 3 pontos de venda principais (cores/capacidade/preço),
Rodapé: texto de recomendação "Vale a pena comprar? Decida depois de ler",
Estilo: Apple Style minimalista, fundo branco,
high-fidelity, accurate product details from web search, no fictional specs
💡 Dicas de uso dos modelos: Os modelos acima foram otimizados para a renderização de caracteres chineses. Sugerimos que, no primeiro uso, teste a composição com
quality="medium". Após confirmar que o layout está correto, mude paraquality="high"para a versão final, economizando de 30% a 40% dos custos. Para produção em massa, recomendamos a integração via APIYI (apiyi.com), que oferece melhor estabilidade e velocidade do que a conexão direta.
Comparação de capacidades: gpt-image-2 vs. ferramentas tradicionais de design
Muitos criadores perguntam: com Canva, Figma e Photoshop, por que mudar para o gpt-image-2? A tabela abaixo compara a eficiência real das quatro ferramentas nos principais cenários de operação do Xiaohongshu.
| Dimensão de comparação | gpt-image-2 | Canva | Figma | Photoshop |
|---|---|---|---|---|
| Tempo por imagem | 30s – 1 min | 15-30 min | 30-60 min | 1-2 horas |
| Tempo para 9 imagens | 5 min (n=9) | 3-4 horas | 4-6 horas | 8+ horas |
| Renderização de texto | 95%+ precisão | 100% (manual) | 100% (manual) | 100% (manual) |
| Capacidade criativa | Alta (geração IA) | Média (modelos) | Baixa (do zero) | Baixa (do zero) |
| Conhecimento online | ✅ Integrado | ❌ | ❌ | ❌ |
| Curva de aprendizado | Baixa | Baixa | Média | Alta |
| Custo mensal | $5-30 (uso) | $12.99/mês | $15/mês | $22.99/mês |
| Cenário ideal | Lote/Infográficos | Modelos prontos | Colaboração | Edição comercial |
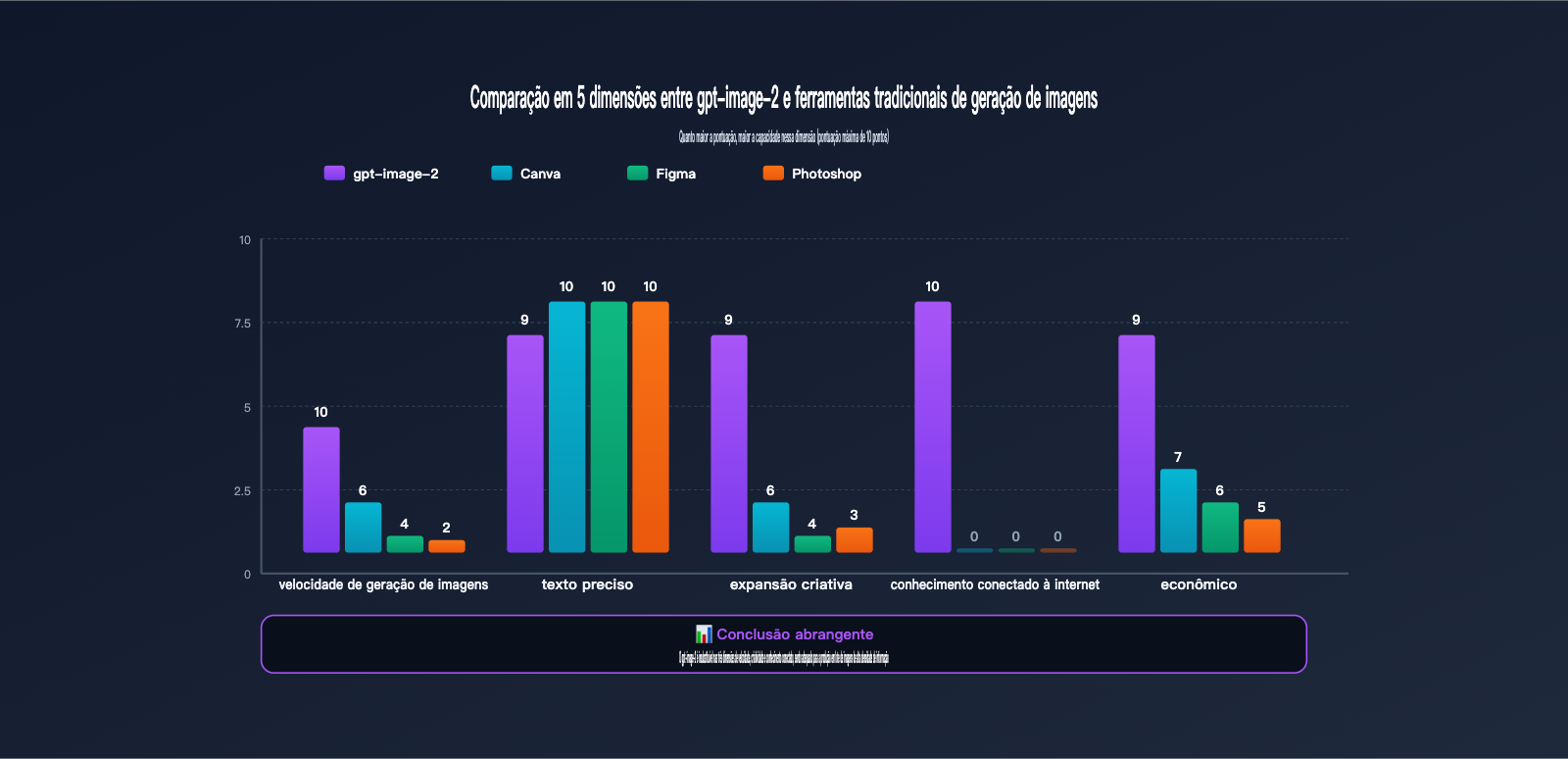
Como mostra a tabela comparativa, o gpt-image-2 não veio para substituir o Canva ou o Figma, mas sim para cobrir um cenário totalmente novo: a combinação de "disseminação criativa + produção em lote + conhecimento online". Se a sua conta no Xiaohongshu precisa publicar de 3 a 5 posts por semana, o gpt-image-2 pode reduzir o tempo de criação de 8-10 horas para menos de 1 hora.
FAQ: Perguntas frequentes sobre a operação do gpt-image-2 no Xiaohongshu
Q1: As imagens geradas pelo gpt-image-2 para o Xiaohongshu realmente não apresentam erros no chinês?
Testes práticos mostram uma taxa de precisão superior a 95%. A OpenAI declarou explicitamente em seu blog oficial que o gpt-image-2 é um Modelo de Linguagem Grande "poliglota", com melhorias significativas em caracteres não latinos, como chinês, japonês e coreano. No entanto, observe dois pontos: primeiro, o texto em chinês no comando deve estar entre aspas (ex: "texto aqui"), caso contrário, o modelo pode processá-lo como "compreensão" em vez de "cópia"; segundo, caracteres raros e tradicionais ainda podem apresentar erros, por isso recomendamos revisar os textos principais antes de publicar.
Q2: Quanto custa aproximadamente a geração de uma imagem 3:4 para o Xiaohongshu com o gpt-image-2?
De acordo com o preço oficial, uma imagem de alta qualidade de 1024×1536 (3:4) custa cerca de US$ 0,20 a US$ 0,25. Se você criar um carrossel de 9 imagens, o custo será de aproximadamente US$ 1,8 a US$ 2,3 (cerca de 13-17 RMB). Ao acessar através do serviço proxy de API da APIYI (apiyi.com), o preço costuma ser menor, com suporte a liquidação em RMB e emissão de nota fiscal, sendo ideal para criadores nacionais que utilizam o serviço em lote.
Q3: Como usar a função de "geração de imagem com acesso à internet" do gpt-image-2?
A função de internet é ativada por padrão na versão web do ChatGPT (modo Thinking). Na API, é necessário usar uma variante do modelo que suporte conectividade. Ao chamar o modelo gpt-image-2-all via APIYI (apiyi.com), a busca na internet é ativada automaticamente — basta mencionar no comando que você precisa de informações reais (como "lançamentos recentes", "cores oficiais" ou "parâmetros reais"), e o modelo disparará automaticamente a busca na web, integrando os resultados ao processo de geração.
Q4: Não sei programar, posso usar o gpt-image-2 para o Xiaohongshu?
Com certeza. Recomendamos usar a ferramenta web imagen.apiyi.com. Não é necessária configuração de API nem ambiente Python; basta selecionar o modelo (gpt-image-2 ou gpt-image-2-all) no formulário web, preencher o comando, escolher a proporção (3:4) e a quantidade, e clicar em gerar. A interface suporta chinês, download em lote e gerenciamento de histórico, sendo perfeita para criadores de conteúdo.
Q5: As imagens geradas pelo gpt-image-2 para o Xiaohongshu serão limitadas por serem "geradas por IA"?
Atualmente, o Xiaohongshu não possui regras públicas de limitação para "imagens geradas por IA". O algoritmo avalia principalmente a taxa de engajamento (curtidas, salvamentos, comentários, compartilhamentos e seguidores). Desde que suas imagens tenham alta densidade de informação e valor para o leitor, você receberá feedback positivo naturalmente. Recomendamos indicar a fonte da imagem na legenda (pode-se notar "produzido com auxílio de IA") para aumentar a transparência do conteúdo.
Q6: Quantas imagens o gpt-image-2 pode gerar de uma só vez?
Na API, o limite é de 10 imagens por solicitação (n=10), enquanto na versão web do ChatGPT o limite é de 8. Para o cenário de carrossel de 9 imagens do Xiaohongshu, a API consegue realizar o trabalho de uma só vez, com uma eficiência significativamente superior a outros modelos. Vale lembrar que, quanto maior o valor de 'n', maior será o tempo de fila e processamento; recomendamos configurar tarefas assíncronas para produção em lote.
Q7: Qual é mais adequado para o Xiaohongshu: gpt-image-2, Nano Banana Pro ou Seedream?
Em resumo: o gpt-image-2 é ideal para conteúdos com "alta densidade de informação + muito texto" (infográficos, cartões de avaliação, gráficos de dados); o Nano Banana Pro é indicado para "cenários criativos + consistência facial" (séries de histórias, narrativas visuais); e o Seedream é ideal para "estética oriental + renderização em chinês" (Hanfu, estilo nacional, pintura a tinta). Todos os três modelos podem ser testados no imagen.apiyi.com; sugerimos fazer um teste A/B antes de definir seu modelo principal.
Q8: Como manter o estilo consistente em várias imagens geradas pelo gpt-image-2?
Três técnicas principais: primeiro, gere tudo de uma vez usando n=9, assim o modelo manterá a consistência de estilo automaticamente; segundo, defina claramente a paleta de cores no comando (ex: "use consistentemente roxo #2D1B69 + rosa #FF6B9D"); terceiro, trave a estrutura de layout (ex: "todas as imagens devem ter título no topo + conteúdo no meio + CTA na parte inferior"). Se precisar de uma consistência de personagem/cenário mais forte, considere usar a função de edição de múltiplas imagens do gpt-image-2, gerando a partir de uma imagem de referência.
Resumo: 3 lógicas fundamentais para usar o gpt-image-2 no Xiaohongshu
Ao chegar aqui, podemos destilar 3 lógicas fundamentais para a criação de conteúdo no Xiaohongshu com o gpt-image-2:
Primeira: trate a geração de imagens como "design de produto" e não como "desenho". O raciocínio agente do gpt-image-2 faz dele um "designer que pensa". Quanto mais seu comando se parecer com um documento de requisitos de design (objetivos claros, hierarquia de informações, restrições visuais), mais preciso será o resultado.
Segunda: use a "densidade de informação" como uma arma de diferenciação. O algoritmo do Xiaohongshu recompensa conteúdos com alta taxa de salvamento, e a essência disso é o "valor prático". O avanço do gpt-image-2 na renderização de texto e layout permite que você crie "infográficos de alta densidade" que modelos do Canva não conseguem, sendo este o melhor caminho para contas novas ganharem destaque.
Terceira: use o "conhecimento conectado à internet" para garantir a atualidade do conteúdo. Para conteúdos que envolvem produtos recentes, eventos em alta ou dados oficiais, use obrigatoriamente modelos que suportam internet, como o gpt-image-2-all, para evitar erros causados por informações inventadas pela IA.
🚀 Sugestão de ação: Se você pretende incluir o gpt-image-2 no seu fluxo de trabalho no Xiaohongshu, sugerimos começar por dois caminhos: criadores individuais podem começar pela ferramenta web imagen.apiyi.com, gerando a primeira imagem em 3 minutos; estúdios com capacidade técnica podem acessar o modelo gpt-image-2-all via api.apiyi.com para construir uma linha de produção em lote. Ambos os acessos suportam geração com internet e possuem preços acessíveis, ideais para o uso em escala por equipes de criação nacionais.
Dominar o gpt-image-2 não tornará seu conteúdo viral da noite para o dia, mas reduzirá em 90% o custo de tempo na etapa de criação, permitindo que você dedique mais energia ao planejamento de pautas, refinamento de textos e gestão de interações — o que é, de fato, o maior valor das ferramentas de IA para criadores de conteúdo.
Autor deste artigo: Equipe técnica da APIYI — Focada em integração de API de modelos de linguagem grande e desenvolvimento de ferramentas de criação de conteúdo. Visite apiyi.com para mais avaliações de modelos, modelos de comando e guias de desenvolvimento.