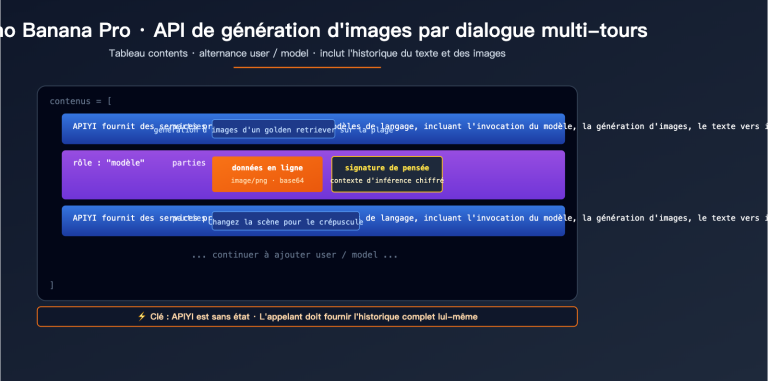
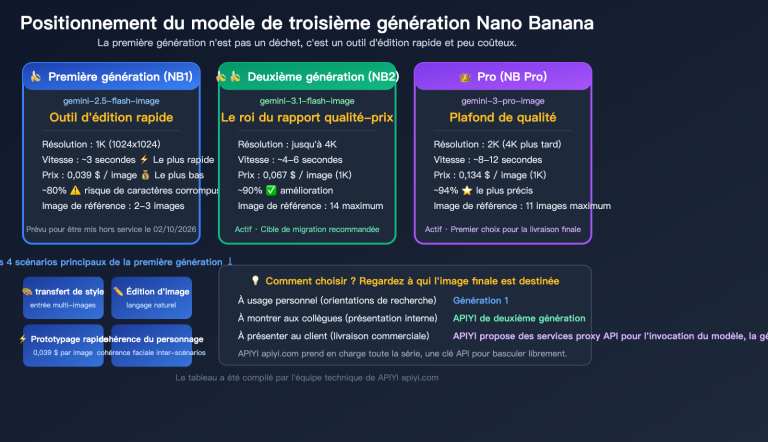
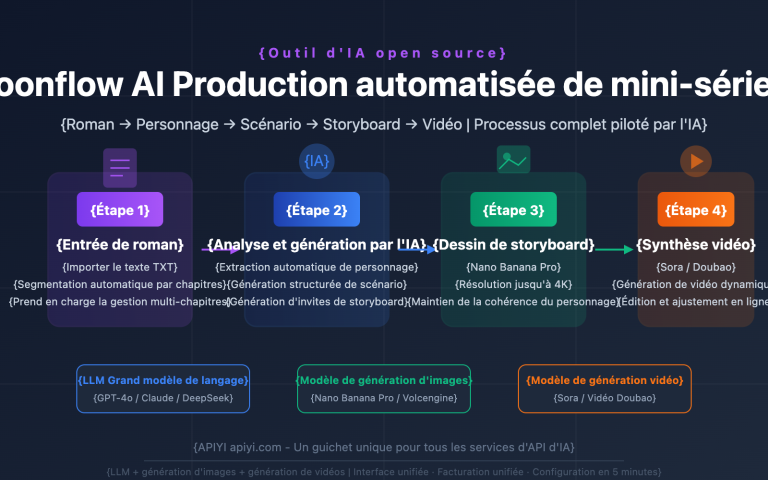
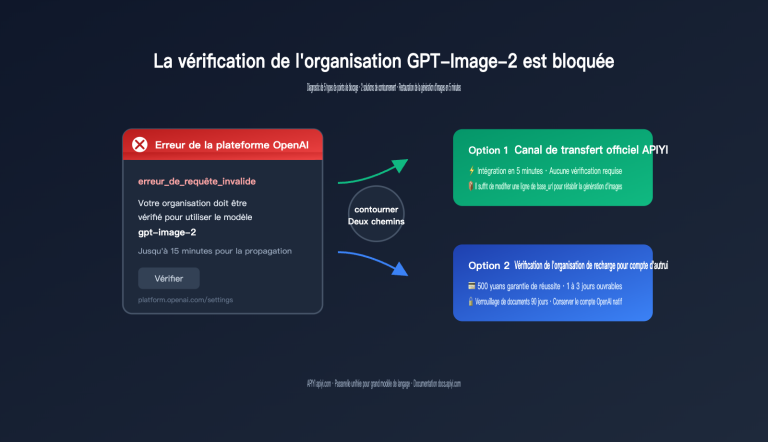
Le plus difficile quand on crée du contenu sur Xiaohongshu, ce n'est pas d'écrire le texte, c'est de concevoir les visuels. Une image de couverture doit intégrer un titre, un sous-titre, des arguments de vente, la marque et des éléments graphiques ; la densité d'informations est comparable à celle d'une infographie. Entre les montages sur Canva, la mise en page sur Figma et les retouches sur Photoshop, le processus prend facilement 2 heures.
Le lancement de gpt-image-2 par OpenAI en avril 2026 a changé la donne. Non seulement il porte la précision du rendu textuel dans les images à plus de 95 %, mais il est aussi le premier à intégrer des capacités d'agent autonome : "recherche en ligne + raisonnement pour la génération". Si vous lui demandez : "Crée une image comparative des coloris du dernier iPhone 17", il ira d'abord consulter les données officielles avant de générer une infographie haute densité incluant les modèles, les couleurs et les caractéristiques techniques réels.
Cet article détaille la méthodologie complète pour créer du contenu Xiaohongshu avec gpt-image-2, de l'analyse des capacités fondamentales au flux de travail en 5 étapes, en passant par des modèles d'invites et une FAQ. L'objectif : réduire votre temps de création de 2 heures à 5 minutes.
Pourquoi les capacités de création de gpt-image-2 pour Xiaohongshu sont exceptionnelles
Avant gpt-image-2, les créateurs sur Xiaohongshu utilisant l'IA faisaient face à trois problèmes majeurs : un rendu textuel imprécis, une incapacité à gérer une forte densité d'informations et un décalage temporel des connaissances. Une couverture virale nécessite généralement une couche de texte de 50 à 100 caractères, or les anciens modèles (y compris gpt-image-1 et Midjourney v6) généraient souvent des fautes de frappe, des traits manquants ou des caractères déformés, rendant les images quasi inutilisables.
gpt-image-2 a radicalement changé la donne grâce à trois percées technologiques. Premièrement, une mise à jour complète du moteur de rendu textuel : selon les tests officiels d'OpenAI, le modèle atteint un taux de précision de rendu haute fidélité supérieur à 95 % pour les caractères non latins (chinois, japonais, coréen, hindi, bengali, etc.), permettant une sortie stable même avec des polices de petite taille, sur des surfaces courbes ou dans des mises en page denses.
Deuxièmement, l'architecture de raisonnement par agent (Agentic Reasoning). gpt-image-2 est le premier modèle d'image de l'industrie à disposer d'une boucle de raisonnement complète "réflexion → recherche → génération → vérification". Avant de générer, il planifie activement la composition, consulte des références et évalue la qualité.
Troisièmement, l'intégration de connaissances en ligne. Lors de la génération d'images impliquant des produits récents, des logos de marques, des personnalités ou des événements d'actualité, le modèle peut interroger Internet en temps réel, sans dépendre de données obsolètes antérieures à sa date de fin d'entraînement (décembre 2025).
💡 Recommandation de plateforme : Pour tester directement les capacités de génération en ligne de gpt-image-2, vous pouvez utiliser le modèle gpt-image-2-all proposé par la plateforme APIYI (apiyi.com). Il s'agit d'une version intégrée par rétro-ingénierie depuis l'interface ChatGPT officielle, avec la recherche en ligne activée par défaut, sans configuration de paramètres supplémentaire. C'est l'outil idéal pour la création de contenu Xiaohongshu nécessitant une "actualité des connaissances".
Analyse des 3 dimensions clés des capacités de gpt-image-2 pour Xiaohongshu
Pour comprendre pourquoi gpt-image-2 est particulièrement adapté à Xiaohongshu, il faut décomposer ses capacités en fonction de l'adéquation avec les formats de contenu de la plateforme. Le tableau ci-dessous compare l'amélioration des capacités de gpt-image-2 par rapport à la génération précédente, gpt-image-1, dans les scénarios clés de Xiaohongshu.
| Dimension de capacité | gpt-image-1 | gpt-image-2 | Valeur pour Xiaohongshu |
|---|---|---|---|
| Rendu de texte chinois | 60-70% précis, erreurs fréquentes | 95%+ précis, stable sur les textes courbes | Directement utilisable pour les titres et infographies |
| Nombre d'images par sortie | 1 image | 1-10 images au choix | Génération complète d'un carrousel de 9 images |
| Résolution maximale | 1024×1024 | 2K (côté long 3840px) | Répond aux exigences de couverture HD 3:4 |
| Support du rapport d'aspect | 3 types | 9 types (dont 3:4) | Adaptation parfaite au format de couverture |
| Connaissances en ligne | Aucune | Recherche Web intégrée | Pas d'erreurs sur les produits et sujets récents |
| Génération par raisonnement | Non | Raisonnement agentique | Planification automatique de mise en page complexe |
Avantage n°1 de gpt-image-2 sur Xiaohongshu : rendu d'infographies à haute densité
Les "infographies", "fiches pratiques" et "images de vulgarisation" de Xiaohongshu sont des types de contenu à forte interaction. Leur caractéristique typique est une densité de 80 à 150 mots par image, nécessitant une hiérarchie claire, des couleurs bien choisies et des icônes précises. L'amélioration de gpt-image-2 dans ce domaine repose sur trois détails :
Premièrement, la gestion de la hiérarchie des polices. Le modèle peut comprendre des instructions telles que "Titre principal 60pt + sous-titre 32pt + corps de texte 18pt", assurant une stabilité dans les proportions de taille de police dans le résultat.
Deuxièmement, le contrôle des espaces blancs. Grâce au raisonnement agentique (Agentic Reasoning), le modèle effectue une "mise en page virtuelle" avant de dessiner, évitant ainsi que le texte ne soit trop serré ou coupé sur les bords.
Troisièmement, la composition mixte icônes-texte. Le modèle peut insérer des icônes correspondantes (✓, ★, →, badges numériques, etc.) à des positions spécifiées, garantissant un alignement parfait entre icônes et texte.
Avantage n°2 de gpt-image-2 sur Xiaohongshu : la précision grâce aux connaissances en ligne
C'est la capacité la plus sous-estimée de gpt-image-2. Les modèles IA traditionnels ont une limite de connaissances basée sur leurs données d'entraînement. Lorsque vous leur demandez de générer du contenu sur les "comparaisons de couleurs du dernier iPhone 17", le "classement des marques de café 2026" ou les "dernières tendances beauté", ils risquent fortement d'inventer des informations erronées.
Lors de sa phase de "réflexion" interne, gpt-image-2 détermine si la tâche nécessite des informations externes. Si tel est le cas, il déclenche automatiquement une recherche Web pour intégrer des données réelles (paramètres produits, formes de logos, couleurs officielles) dans le processus de génération. Cela permet aux créateurs sur Xiaohongshu d'utiliser l'outil en toute confiance pour des comparaisons de produits, des recommandations et de la vulgarisation de marque, sans craindre les "hallucinations" de l'IA.
🎯 Conseil pour l'intégration API : L'utilisation de la fonction en ligne de gpt-image-2 nécessite un service proxy API qui prend en charge toutes les capacités de l'API. Nous recommandons d'accéder au modèle
gpt-image-2-allvia APIYI (api.apiyi.com). Ce modèle provient du canal inverse officiel, intègre nativement la recherche en ligne, et propose des tarifs plus avantageux que l'API officielle directe, idéal pour la production de masse de contenu.
Avantage n°3 de gpt-image-2 sur Xiaohongshu : ratios multiples et sortie multi-images
Le ratio standard de la couverture sur Xiaohongshu est le 3:4 (format portrait). Le format carré 1:1 est idéal pour les fiches d'information, et le 9:16 pour les couvertures de courtes vidéos. gpt-image-2 prend en charge nativement ces 3 ratios (ainsi que 1:1, 2:3, 3:2, 4:3, 4:5, 16:9, 21:9, soit 9 au total), éliminant ainsi le besoin de recadrage ultérieur.
Plus important encore, gpt-image-2 permet de générer 1 à 10 images en une seule requête. La longueur optimale pour une note sur Xiaohongshu étant de 6 à 9 images (poids algorithmique maximal), les créateurs peuvent générer un carrousel complet basé sur un même thème en une seule fois, garantissant une cohérence visuelle uniforme.
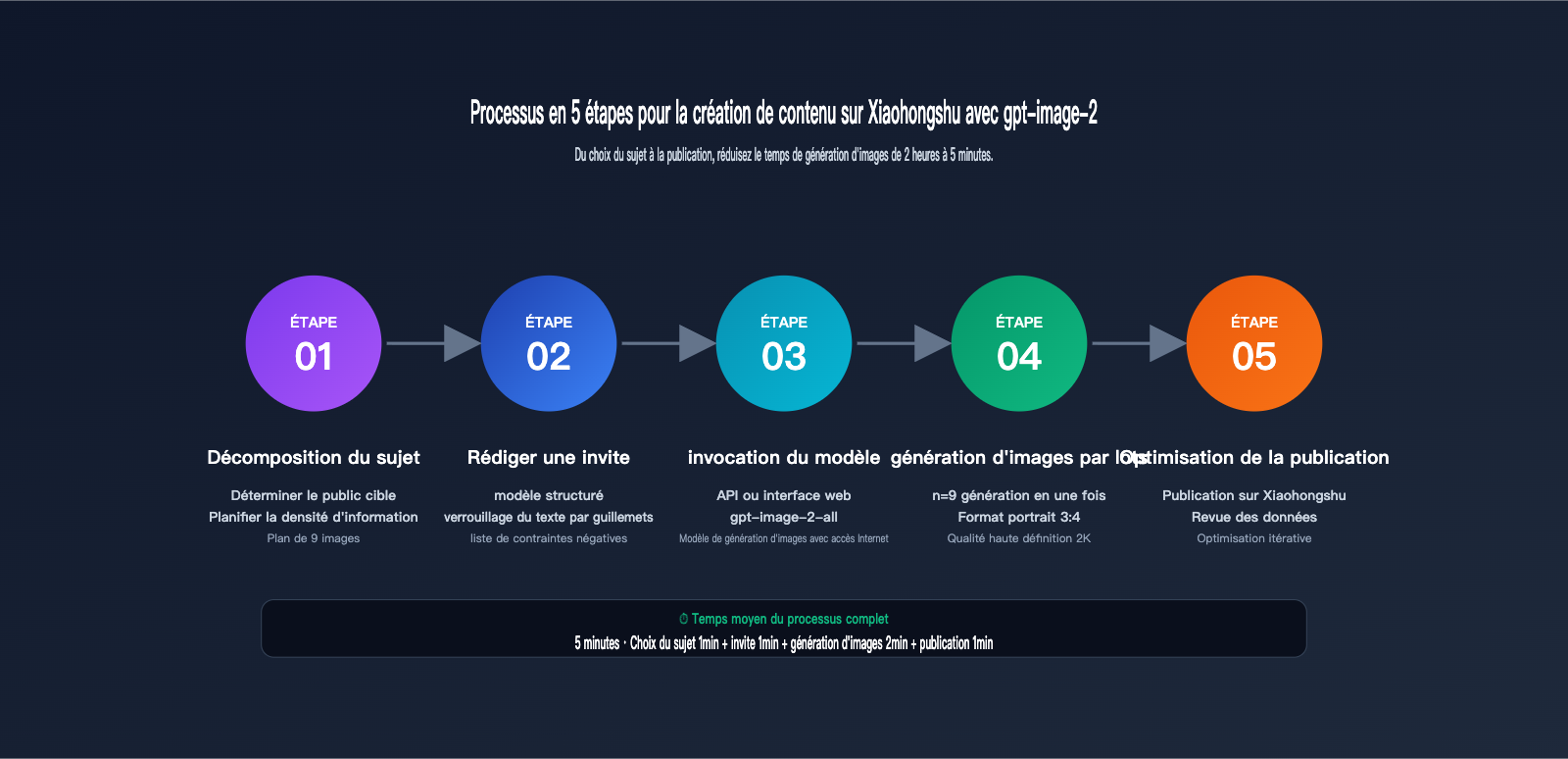
Matrice d'adaptation des contenus Xiaohongshu pour gpt-image-2
Chaque type de contenu sur Xiaohongshu a des exigences spécifiques en matière d'images. Le tableau ci-dessous vous aide à déterminer rapidement l'adéquation et les paramètres recommandés pour gpt-image-2 selon le format de votre contenu.
| Type de contenu | Ratio recommandé | Nombre d'images | Densité de texte | Adéquation gpt-image-2 | Qualité recommandée |
|---|---|---|---|---|---|
| Infographie éducative | 3:4 | 6-9 | Élevée (80-150 mots/image) | ⭐⭐⭐⭐⭐ | high |
| Fiche de test produit | 3:4 | 6-9 | Moyenne (40-80 mots/image) | ⭐⭐⭐⭐⭐ | high |
| Tutoriel étape par étape | 3:4 | 4-9 | Moyenne (50-100 mots/image) | ⭐⭐⭐⭐⭐ | medium-high |
| Visualisation de données | 3:4 / 1:1 | 1-3 | Élevée (100+ mots/image) | ⭐⭐⭐⭐⭐ | high |
| Recommandation food/mode | 3:4 | 6-9 | Faible (tags principalement) | ⭐⭐⭐⭐ | medium |
| Couverture de Vlog | 9:16 | 1 | Moyenne (titre principalement) | ⭐⭐⭐⭐ | high |
| Mèmes / Blagues | 1:1 | 1 | Faible | ⭐⭐⭐ | low-medium |
Comme le montre le niveau d'adéquation, gpt-image-2 excelle dans les contenus informatifs à densité de texte moyenne à élevée, ce qui correspond précisément aux types de contenus à "taux de mise en favoris élevé" privilégiés par l'algorithme de Xiaohongshu. Selon les poids de l'algorithme CES publiés officiellement par Xiaohongshu, la mise en favoris compte pour 1 point, soit autant qu'un like, tandis que les commentaires et les partages comptent chacun pour 4 points. Les infographies, tutoriels et tests produits, grâce à leur "valeur pratique", bénéficient d'un taux de mise en favoris nettement supérieur aux autres types, obtenant ainsi plus de trafic organique via la distribution algorithmique.
Processus pratique en 5 étapes pour la création de visuels Xiaohongshu avec gpt-image-2
Passons à la pratique. Le processus complet de création d'images Xiaohongshu avec gpt-image-2 se divise en 5 étapes, chacune comportant des astuces réutilisables.
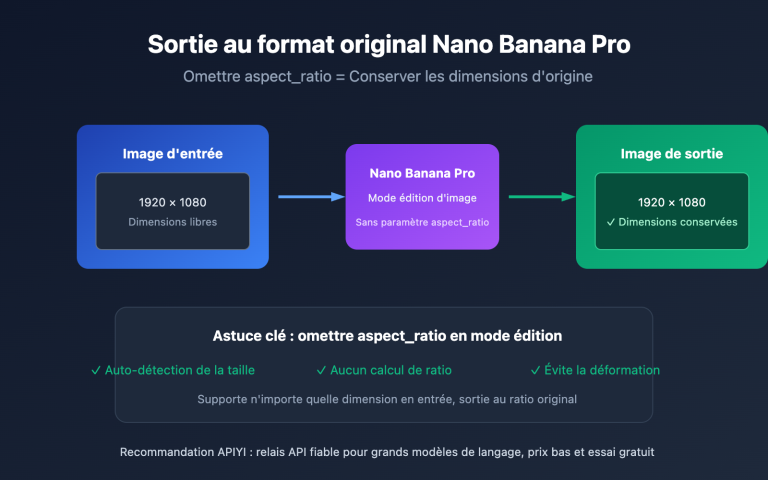
Étape 1 : Décomposition du sujet et planification de la densité d'information
Avant d'ouvrir gpt-image-2, consacrez 5 minutes à la décomposition de votre sujet. Une bonne note infographique sur Xiaohongshu doit répondre à trois questions :
- Qui est le lecteur cible (débutant / avancé / décideur)
- Combien d'informations clés (3 points / 5 points / 7 points)
- Quelle quantité d'informations par image (une image = un point de vue / une image = une comparaison)
Exemple : Pour une note sur le "Comparatif des outils de génération d'images par IA en 2026", vous pouvez diviser le contenu en 9 images : 1 couverture + 1 tableau récapitulatif + 5 présentations d'outils (une par image) + 1 conclusion/recommandation + 1 appel à l'action. Limitez l'information principale de chaque image à 80 mots.
Étape 2 : Rédaction d'une invite (prompt) structurée pour gpt-image-2
La rédaction d'invites pour gpt-image-2 suit une structure recommandée : Contexte/Scène → Sujet → Détails clés → Contenu textuel → Contraintes de style. Pour obtenir des images Xiaohongshu stables et utilisables, suivez ces 4 règles d'or :
- Le texte chinois à afficher doit être entouré de guillemets chinois 「」 ou anglais "" pour que le modèle le restitue avec précision.
- Spécifiez clairement la hiérarchie de la taille de la police dans l'invite (ex: "titre principal 64pt en gras, sous-titre 28pt").
- Utilisez des mots-clés comme "high-fidelity", "ultra-detailed", "crisp typography" pour améliorer les détails.
- Listez les contraintes négatives (ex: "no watermark, no extra text, no duplicate words") pour éviter les éléments superflus.
Étape 3 : Appel de l'API gpt-image-2 pour générer les images
Si vous avez des compétences de base en programmation, vous pouvez appeler gpt-image-2 directement via l'interface standard d'OpenAI. Voici un exemple de code minimaliste pour générer une couverture Xiaohongshu en 3:4 :
from openai import OpenAI
client = OpenAI(
api_key="your_apiyi_key",
base_url="https://api.apiyi.com/v1"
)
response = client.images.generate(
model="gpt-image-2-all",
prompt='Couverture infographique style Xiaohongshu, format vertical 3:4, titre principal 「TOP 5 des outils IA 2026」 64pt blanc en gras, sous-titre 「Indispensable pour les créateurs, à mettre en favoris」 28pt gris clair, affichage central des logos des 5 outils, fond dégradé rose à violet, high-fidelity typography, crisp text, no watermark',
size="1024x1536",
quality="high",
n=1
)
print(response.data[0].url)
📌 Note sur la configuration de base_url : Le code ci-dessus utilise le point d'accès APIYI
api.apiyi.com/v1. Le modèlegpt-image-2-allest la version officielle incluant la recherche en ligne par défaut. Les utilisateurs standards peuvent également utiliser le modèlegpt-image-2(sans recherche en ligne), à un coût inférieur.
Étape 4 : Génération par lots de 9 images (carrousel)
Le nombre idéal d'images pour une note Xiaohongshu est de 6 à 9. Rédiger une invite manuellement pour chaque image est inefficace. Le paramètre n de gpt-image-2 supporte une valeur de 1 à 10, permettant de générer 9 images en une seule fois.
Astuce : Ne laissez pas le modèle générer 9 images isolées, guidez-le via l'invite pour créer une "série cohérente". Exemple :
response = client.images.generate(
model="gpt-image-2-all",
prompt='''Générer un ensemble de 9 images cohérentes pour un carrousel éducatif Xiaohongshu, format vertical 3:4,
fond violet foncé uniforme + texte blanc, thème "5 formules de prompt indispensables pour débuter en IA",
Image 1 : Page de couverture, titre 「IA : Les bases」 sous-titre 「5 formules de prompt」,
Images 2-6 : Présentation d'une formule par image, numéro 01-05 en haut, nom de la formule au centre, explication de 30 mots en bas,
Image 7 : Tableau comparatif des formules,
Image 8 : Exemple pratique,
Image 9 : Page d'appel à l'action, texte 「Likez et mettez en favoris pour ne rien manquer」 ''',
size="1024x1536",
quality="high",
n=9
)
Étape 5 : Vous ne savez pas coder ? Utilisez l'outil web imagen.apiyi.com
Si vous êtes un créateur de contenu pur sans expérience en Python ou en API, vous pouvez ignorer la partie code. Nous recommandons l'outil web imagen.apiyi.com — il intègre gpt-image-2, Nano Banana, Seedream et d'autres modèles d'image majeurs. Il propose une interface de formulaire simplifiée, permet de choisir le ratio, le nombre d'images et le téléchargement par lots. Prise en main en 5 minutes.
🎨 Conseil de choix d'outil : Pour les créateurs, nous recommandons d'utiliser directement l'outil web imagen.apiyi.com — pas besoin de coder ou de configurer une API, choisissez simplement le modèle (recommandé : gpt-image-2 ou gpt-image-2-all) et le ratio (3:4). Pour les studios ayant besoin d'automatisation par lots, nous suggérons d'appeler l'API via APIYI apiyi.com pour une intégration dans vos propres outils SaaS ou feuilles de calcul Feishu.
Voici une bibliothèque de modèles d'invites (prompts) testés et approuvés pour créer des contenus percutants sur Xiaohongshu avec gpt-image-2. Tous les modèles ont été optimisés pour le rendu de texte. Vous pouvez les copier directement en remplaçant le contenu entre crochets 【】 par votre propre sujet.
Modèle 1 : Fiche de vulgarisation (haute densité d'information)
小红书风格知识科普卡片,3:4 竖版,
顶部标题栏:深紫色背景,白色加粗中文标题 「【你的主标题,15 字内】」 字号 56pt,
副标题 「【一句话价值描述,20 字内】」 字号 24pt 浅紫色,
中部内容区:5 个编号要点,每个要点包含数字徽章 + 标题 + 30 字解释,
底部:粉色 CTA 按钮 「收藏不迷路」,
配色:深紫主色 #2D1B69,亮粉强调色 #FF6B9D,
high-fidelity Chinese typography, crisp text rendering, no watermark, no duplicate text
Modèle 2 : Fiche comparative de produits
小红书产品测评对比卡,3:4 竖版,白色背景,
顶部:左右两个产品图 + 产品名 「【产品 A】」 vs 「【产品 B】」,
中部:5 行对比表格,每行包含维度名 + A 评分 + B 评分,
评分使用 5 颗星图标(★)显示,
底部:推荐结论 「综合推荐:【产品名称】」,
字体清晰锐利,表格线条 1px 浅灰,主标题加粗 48pt,
high-fidelity, ultra-detailed, no extra elements
Modèle 3 : Schéma d'étapes de tutoriel
小红书教程步骤示意图,3:4 竖版,米色温暖背景,
顶部主标题 「【主题】3 分钟搞定」 黑色加粗 56pt,
中部:3 个步骤区块垂直排列,
每个区块:左侧大号步骤数字(01/02/03),右侧步骤标题 + 25 字说明,
底部:成果展示图 + 文字 「完成!」,
手绘插画风格图标,温暖橙黄色强调色,
crisp typography, clear hierarchy, no watermark
Modèle 4 : Carte de visualisation de données
小红书数据卡片,3:4 竖版,深蓝色渐变背景,
顶部标题 「【数据主题】2026 最新数据」 白色 52pt,
中部:1 个核心大数字 「【关键数字】」 占据画面 40% 高度,
数字下方:数据来源说明 12pt 浅蓝色,
中下部:3 行小数据补充,每行包含图标 + 数据 + 简短说明,
底部:浅色 CTA 「转发分享给同事」,
配色:深蓝 #0F172A 到 #1E40AF 渐变,白色高对比文字,
high-fidelity typography, crisp small text, no extra words
Modèle 5 : Liste de conseils (Checklist)
小红书干货清单封面,3:4 竖版,
顶部:荧光绿色横条,黑色加粗文字 「【数字】个【主题】」 60pt,
副标题 「博主私藏,看完直接抄作业」 24pt,
中部:【数字】个清单项目,每项包含 ✓ 图标 + 项目名,
排版紧凑但留白合理,字号梯度清晰,
底部:粉色边框 + 文字 「完整清单看下一张」,
风格:简洁现代,Notion 风格排版,
high-fidelity Chinese text, crisp icons, no decorative noise
Modèle 6 : Scénario spécial avec recherche en ligne (dédié à gpt-image-2-all)
小红书新品种草卡,3:4 竖版,
主题:介绍【最新产品名,如 iPhone 17 Pro Max】,
请联网查询该产品的最新官方配色、关键参数、发布日期,
顶部:产品真实外观渲染图,
中部:产品名 + 3 行核心卖点(配色/容量/价格),
底部:种草文案 「值得入手吗?看完再决定」,
风格:Apple Style 简洁,白色背景,
high-fidelity, accurate product details from web search, no fictional specs
💡 Astuces d'utilisation : Ces modèles sont optimisés pour le rendu de texte chinois. Pour votre premier essai, utilisez
quality="medium"afin de valider la mise en page, puis passez àquality="high"pour le rendu final afin d'économiser 30 à 40 % de vos crédits. Pour une production en série, nous recommandons d'utiliser le service proxy API APIYI (apiyi.com) pour une meilleure stabilité et vitesse.
Comparaison des capacités : gpt-image-2 vs outils de création traditionnels
Beaucoup de créateurs se demandent : avec Canva, Figma ou Photoshop, pourquoi passer à gpt-image-2 ? Le tableau ci-dessous compare l'efficacité réelle de ces outils pour les besoins opérationnels sur Xiaohongshu.
| Dimension | gpt-image-2 | Canva | Figma | Photoshop |
|---|---|---|---|---|
| Temps par image | 30 s – 1 min | 15-30 min | 30-60 min | 1-2 h |
| Temps pour 9 images | 5 min (n=9) | 3-4 h | 4-6 h | 8 h+ |
| Rendu texte chinois | 95%+ précis | 100% (manuel) | 100% (manuel) | 100% (manuel) |
| Créativité | Élevée (générée par IA) | Moyenne (modèles) | Faible (partir de zéro) | Faible (partir de zéro) |
| Connaissances web | ✅ Intégrées | ❌ | ❌ | ❌ |
| Courbe d'apprentissage | Faible (savoir écrire) | Faible | Moyenne | Élevée |
| Coût mensuel | 5-30 $ (à l'usage) | 12,99 $ (abonnement) | 15 $ (abonnement) | 22,99 $ (abonnement) |
| Usage idéal | Production en série | Modèles prêts à l'emploi | Travail d'équipe | Retouche commerciale |
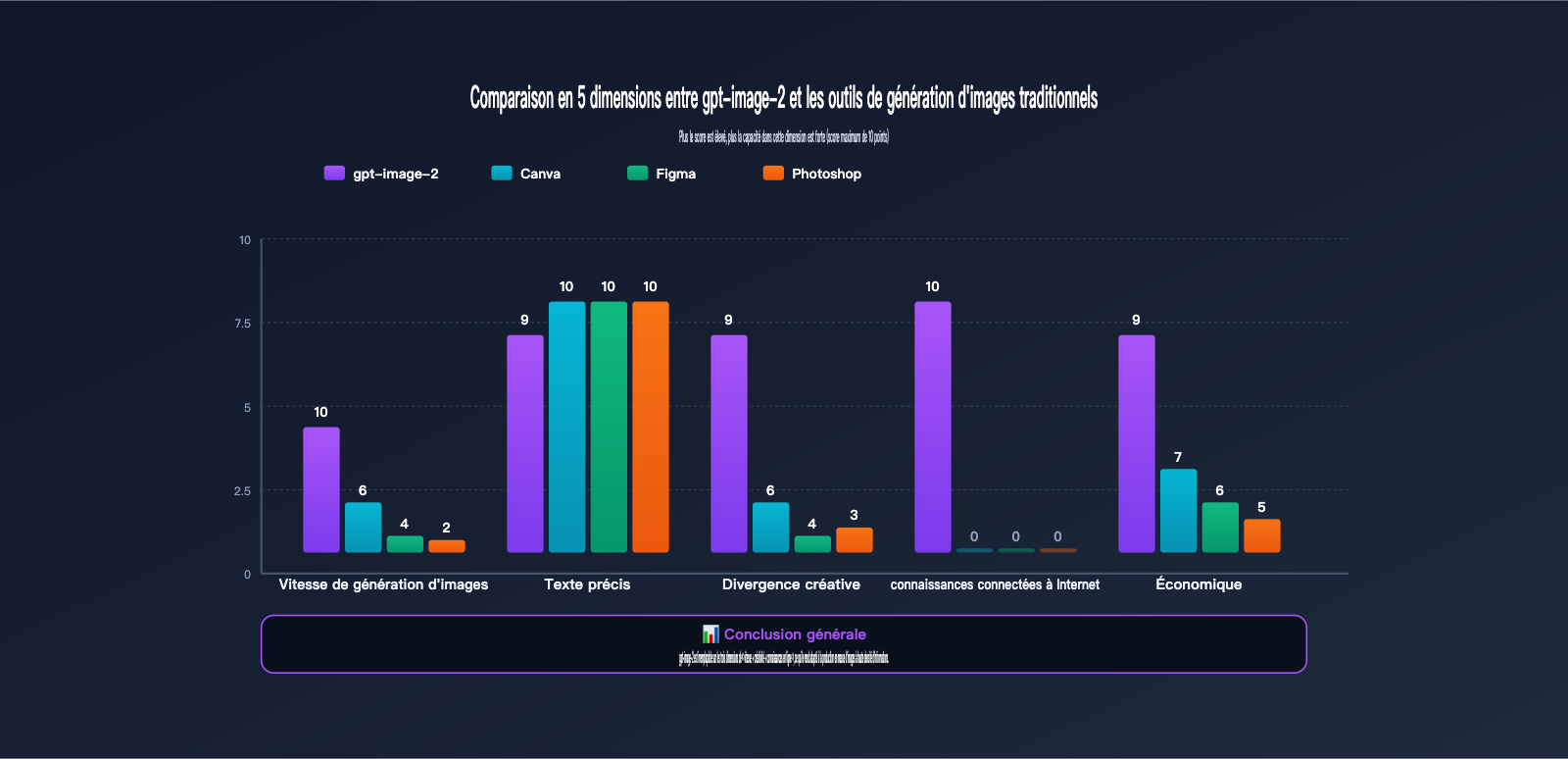
Comme le montre ce tableau, gpt-image-2 n'a pas pour vocation de remplacer Canva ou Figma, mais d'occuper un créneau inédit : une solution "3-en-1" combinant créativité, production en série et connaissances web. Si votre compte Xiaohongshu nécessite la publication régulière de 3 à 5 notes illustrées par semaine, gpt-image-2 peut réduire votre temps de création de 8-10 heures à moins d'une heure.
FAQ : Questions fréquentes sur l'utilisation de gpt-image-2 pour Xiaohongshu
Q1 : Les images générées par gpt-image-2 pour Xiaohongshu contiennent-elles vraiment des erreurs dans le texte chinois ?
Nos tests montrent un taux de précision supérieur à 95 %. Dans son article de blog officiel, OpenAI précise que gpt-image-2 est un modèle "polyglotte" avec des améliorations significatives pour les caractères non latins comme le chinois, le japonais et le coréen. Cependant, deux points sont à noter : premièrement, le texte chinois dans votre invite doit être placé entre guillemets (par exemple : « texte ici »), sinon le modèle risque de l'interpréter au lieu de le "copier" ; deuxièmement, les caractères rares ou traditionnels peuvent encore poser problème, nous vous conseillons donc de vérifier les textes clés avant la publication.
Q2 : Combien coûte environ la génération d'une image 3:4 pour Xiaohongshu avec gpt-image-2 ?
Selon la tarification officielle, une image haute qualité en 1024×1536 (3:4) coûte environ 0,20 $ à 0,25 $. Pour un carrousel de 9 images, comptez environ 1,8 $ à 2,3 $ (soit environ 13 à 17 yuans). En passant par le service proxy API APIYI (apiyi.com), les prix sont généralement plus bas, avec une prise en charge du paiement en yuans et de la facturation, ce qui est idéal pour les créateurs locaux effectuant des productions en série.
Q3 : Comment utiliser la fonction de "génération d'images connectée au Web" de gpt-image-2 ?
La fonction de navigation est activée par défaut sur la version Web de ChatGPT (mode Thinking). Pour l'API, vous devez utiliser une variante de modèle prenant en charge la connexion Web. Lorsque vous appelez le modèle gpt-image-2-all via APIYI (apiyi.com), la recherche Web est activée par défaut. Il vous suffit de mentionner dans votre invite les informations réelles que vous recherchez (ex: "dernières sorties", "coloris officiels", "paramètres réels") et le modèle intégrera automatiquement les résultats de recherche dans le processus de génération.
Q4 : Je ne sais pas coder, puis-je utiliser gpt-image-2 pour Xiaohongshu ?
Absolument. Nous vous recommandons l'outil Web imagen.apiyi.com. Aucune configuration d'API ou environnement Python n'est nécessaire. Il suffit de choisir le modèle dans le formulaire Web (gpt-image-2 ou gpt-image-2-all), de saisir votre invite, de sélectionner le format (3:4) et la quantité, puis de cliquer sur générer. L'interface est en chinois, prend en charge le téléchargement par lots et la gestion de l'historique, ce qui est parfait pour les créateurs de contenu.
Q5 : Les images Xiaohongshu générées par gpt-image-2 risquent-elles d'être limitées par l'algorithme en tant que "contenu généré par IA" ?
À l'heure actuelle, Xiaohongshu n'a pas de règle publique limitant les "images générées par IA". L'algorithme évalue principalement le taux d'engagement (likes, enregistrements, commentaires, partages, abonnements). Tant que vos images ont une densité d'information élevée et apportent de la valeur aux lecteurs, vous obtiendrez des retours positifs. Nous vous suggérons d'indiquer la source de l'image dans votre légende (par exemple, "créé avec l'aide de l'IA") pour plus de transparence.
Q6 : Combien d'images gpt-image-2 peut-il générer en une seule fois ?
Via l'API, vous pouvez générer jusqu'à 10 images par requête (n=10), et jusqu'à 8 images sur la version Web de ChatGPT. Pour un carrousel de 9 images sur Xiaohongshu, l'API permet de tout générer en une seule fois, ce qui est beaucoup plus efficace que les autres modèles. Attention toutefois : plus le nombre 'n' est élevé, plus le temps d'attente et de traitement augmente. Pour une production en série, nous recommandons de configurer des tâches asynchrones.
Q7 : Entre gpt-image-2, Nano Banana Pro et Seedream, lequel est le plus adapté à Xiaohongshu ?
En résumé : gpt-image-2 est idéal pour les contenus à "haute densité d'information + beaucoup de texte" (infographies, fiches de test, graphiques), Nano Banana Pro convient aux "scénarios créatifs + cohérence faciale" (séries narratives, récits multi-images), et Seedream est parfait pour "l'esthétique orientale + rendu chinois" (Hanfu, style traditionnel, encre de Chine). Les trois modèles sont disponibles sur imagen.apiyi.com ; nous vous conseillons de faire un test A/B avant de choisir votre modèle principal.
Q8 : Comment obtenir une cohérence de style sur plusieurs images avec gpt-image-2 ?
Trois astuces clés : premièrement, générez les 9 images en une seule fois avec n=9, le modèle maintiendra automatiquement la cohérence ; deuxièmement, verrouillez la palette de couleurs dans votre invite (ex: "utiliser uniformément le violet #2D1B69 + le rose #FF6B9D") ; troisièmement, verrouillez la structure de mise en page (ex: "toutes les images suivent une structure en trois parties : titre en haut, contenu au milieu, appel à l'action en bas"). Si vous avez besoin d'une cohérence plus poussée pour les personnages ou les décors, envisagez d'utiliser la fonction d'édition multi-images de gpt-image-2, basée sur une image de référence.
Conclusion : 3 logiques fondamentales pour utiliser gpt-image-2 sur Xiaohongshu
En résumé, voici les 3 piliers de la création de contenu pour Xiaohongshu avec gpt-image-2 :
Premièrement, considérez la génération d'images comme une "conception de produit" plutôt que comme du "dessin". Le raisonnement agentique de gpt-image-2 en fait un "designer qui réfléchit". Plus votre invite ressemble à un cahier des charges (objectifs clairs, hiérarchie de l'information, contraintes visuelles), plus le résultat sera précis.
Deuxièmement, utilisez la "densité d'information" comme arme de différenciation. L'algorithme de Xiaohongshu récompense les contenus à fort taux d'enregistrement, et la clé de ces enregistrements est la "valeur pratique". Les avancées de gpt-image-2 dans le rendu de texte et la mise en page vous permettent de créer des infographies denses impossibles à réaliser avec des modèles Canva classiques. C'est la meilleure stratégie pour faire décoller un nouveau compte.
Troisièmement, exploitez les "connaissances connectées" pour l'actualité. Pour les contenus impliquant les derniers produits, les événements chauds ou des données officielles, utilisez impérativement un modèle compatible avec la recherche Web comme gpt-image-2-all pour éviter que l'IA n'invente des informations.
🚀 Conseil pratique : Si vous souhaitez intégrer gpt-image-2 dans votre flux de travail Xiaohongshu, nous vous suggérons deux points d'entrée : les créateurs indépendants peuvent commencer avec l'outil Web imagen.apiyi.com pour obtenir une première image en 3 minutes ; les studios techniques peuvent se connecter via l'API APIYI (api.apiyi.com) pour utiliser le modèle gpt-image-2-all et construire une chaîne de production automatisée. Les deux options prennent en charge la génération connectée au Web, avec des tarifs avantageux adaptés aux équipes de création locales.
Maîtriser gpt-image-2 ne rendra pas votre compte Xiaohongshu viral du jour au lendemain, mais cela réduira de 90 % le temps consacré à la création visuelle, vous permettant de vous concentrer sur la stratégie de contenu, la rédaction et l'engagement — là où réside la véritable valeur ajoutée pour un créateur.
Auteur de cet article : L'équipe technique d'APIYI — Spécialisée dans l'intégration d'API de grands modèles de langage et le développement d'outils de création de contenu. Visitez apiyi.com pour plus d'évaluations de modèles, de modèles d'invites et de guides de développement.