Die größte Herausforderung bei der Erstellung von Inhalten für Xiaohongshu ist nicht das Schreiben der Texte, sondern das Design der Bilder. Ein Titelbild muss Titel, Untertitel, Alleinstellungsmerkmale, Branding und dekorative Elemente enthalten – die Informationsdichte ist vergleichbar mit einer Infografik. Mit Canva, Figma und Photoshop dauert dieser Prozess oft bis zu zwei Stunden.
OpenAI hat dies mit der im April 2026 veröffentlichten gpt-image-2 geändert. Sie steigert nicht nur die Genauigkeit der Textwiedergabe in Bildern auf über 95 %, sondern verfügt erstmals über "Agentic"-Fähigkeiten, die Websuche und bildbasierte Schlussfolgerungen kombinieren. Wenn Sie sagen: „Erstelle eine Vergleichsgrafik über die neuesten iPhone 17-Farbvarianten“, recherchiert das Modell zuerst die offiziellen Daten und generiert dann eine informationsdichte Grafik mit echten Modellbezeichnungen, Farben und technischen Spezifikationen.
In diesem Artikel stellen wir systematisch die komplette Methodik für die Erstellung von Xiaohongshu-Inhalten mit gpt-image-2 vor – von der Analyse der Kernfähigkeiten über einen 5-Schritte-Workflow bis hin zu Prompt-Vorlagen und FAQs, damit Sie die Zeit für die Bilderstellung von 2 Stunden auf 5 Minuten reduzieren können.
Warum die Erstellung von Xiaohongshu-Inhalten mit gpt-image-2 so herausragend ist
Vor gpt-image-2 sahen sich Xiaohongshu-Ersteller bei der KI-Bilderzeugung mit drei Hauptproblemen konfrontiert: ungenaue Textwiedergabe, mangelnde Informationsdichte und veraltetes Wissen. Ein virales Cover benötigt in der Regel eine Textebene von 50-100 Zeichen, doch frühere Modelle (einschließlich gpt-image-1 und Midjourney v6) erzeugten oft Tippfehler, fehlende Striche oder Zeichenverzerrungen, was sie fast unbrauchbar machte.
gpt-image-2 hat diesen Status quo durch drei technologische Durchbrüche grundlegend verändert. Erstens das umfassende Upgrade der Text-Rendering-Engine: Laut offiziellen Tests von OpenAI erreicht das Modell eine hohe Wiedergabetreue von über 95 % bei nicht-lateinischen Schriftzeichen wie Chinesisch, Japanisch, Koreanisch, Hindi und Bengalisch und kann selbst bei kleiner Schriftgröße, gekrümmten Flächen und dichten Layouts stabile Ergebnisse liefern.
Zweitens die Agentic-Reasoning-Architektur. gpt-image-2 ist das branchenweit erste Bildmodell mit einem vollständigen Schlussfolgerungskreislauf von „Nachdenken → Suchen → Generieren → Überprüfen“. Vor der Generierung plant es aktiv den Bildaufbau, prüft Referenzen und bewertet die Qualität.
Drittens die integrierte Wissensdatenbank mit Internetzugang. Wenn das Modell Bilder generiert, die neueste Produkte, Markenlogos, Persönlichkeiten oder aktuelle Ereignisse betreffen, kann es in Echtzeit das Internet abfragen, anstatt sich auf veraltete Daten vor dem Trainingsstichtag (Dezember 2025) zu verlassen.
💡 Plattform-Empfehlung: Um die netzwerkbasierte Bilderzeugungsfähigkeit von gpt-image-2 direkt zu erleben, können Sie das Modell gpt-image-2-all verwenden, das von der Plattform APIYI (apiyi.com) bereitgestellt wird – dies ist eine Version, die von der offiziellen ChatGPT-Webseite abgeleitet wurde. Sie verfügt standardmäßig über eine aktivierte Websuche und erfordert keine zusätzliche Konfiguration der Parameter, was sie ideal für Xiaohongshu-Content-Szenarien macht, die „Wissensaktualität“ erfordern.
Analyse der Kernfähigkeiten von gpt-image-2 für Xiaohongshu
Um zu verstehen, warum gpt-image-2 besonders gut für Xiaohongshu geeignet ist, müssen wir seine Fähigkeiten im Hinblick auf die Inhaltsformate der Plattform analysieren. Die folgende Tabelle vergleicht die Leistungssteigerungen von gpt-image-2 gegenüber der Vorgängerversion gpt-image-1 in den wichtigsten Xiaohongshu-Szenarien.
| Fähigkeitsdimension | gpt-image-1 | gpt-image-2 | Wert für Xiaohongshu |
|---|---|---|---|
| Chinesische Textwiedergabe | 60-70 % genau, oft Tippfehler | 95 %+ genau, stabil bei gekrümmtem Text | Direkt für Cover-Titel & Infografiken nutzbar |
| Bilder pro Durchgang | 1 Bild | 1-10 Bilder wählbar | Erstellung kompletter 9-Bild-Slideshows |
| Maximale Auflösung | 1024×1024 | 2K (längste Seite 3840px) | Erfüllt 3:4 HD-Cover-Anforderungen |
| Seitenverhältnis | 3 Formate | 9 Formate (inkl. 3:4) | Perfekte Anpassung an Xiaohongshu-Cover |
| Web-Wissen | Keine | Integrierte Websuche | Aktuelle Produkte & Trends ohne Fehler |
| KI-Bild-Logik | Keine | Agentic Reasoning | Automatische Layoutplanung für Infografiken |
gpt-image-2 Vorteil 1: Hochdichte Infografik-Wiedergabe
"Infografiken", "Wissenskarten" und "Erklärbilder" sind auf Xiaohongshu besonders interaktionsstark. Typisch ist eine Dichte von 80-150 Wörtern pro Bild, was klare Hierarchien, Farbschemata und Icons erfordert. Die Verbesserungen von gpt-image-2 basieren auf drei Details:
Erstens: Abgestufte Schriftgrößen. Das Modell versteht Anweisungen wie "Haupttitel 60pt + Untertitel 32pt + Fließtext 18pt" und sorgt für stabile Proportionen.
Zweitens: Kontrolle der Weißräume. Durch "Agentic Reasoning" führt das Modell vor dem Zeichnen ein "virtuelles Layout" durch, um zu verhindern, dass Text gequetscht oder am Rand abgeschnitten wird.
Drittens: Mischsatz aus Icons und Text. Das Modell kann Icons (✓, ★, →, Zahlen-Badges etc.) präzise an den gewünschten Stellen einfügen und sorgt für eine saubere Ausrichtung.
gpt-image-2 Vorteil 2: Websuche garantiert Genauigkeit
Dies ist die am meisten unterschätzte Fähigkeit von gpt-image-2. Das Wissen traditioneller KI-Modelle endet mit den Trainingsdaten. Wenn Sie Inhalte wie "iPhone 17 Farbvergleich", "Kaffeemarken-Ranking 2026" oder "Neueste Beauty-Trends" erstellen lassen, entstehen oft erfundene Fakten.
gpt-image-2 prüft in einer internen "Denkphase", ob externe Informationen erforderlich sind. Falls ja, wird automatisch eine Websuche ausgelöst, und die gefundenen Daten (Produktdaten, Logo-Formen, offizielle Farben) fließen in die Bilderzeugung ein. Xiaohongshu-Creator können das Modell also bedenkenlos für Produktvergleiche, Empfehlungen und Marken-Wissensbeiträge nutzen, ohne "Halluzinationen" befürchten zu müssen.
🎯 API-Anbindungsempfehlung: Die Nutzung der Websuche von gpt-image-2 erfordert einen API-Proxy-Dienst, der den vollen Funktionsumfang unterstützt. Wir empfehlen die Anbindung des Modells
gpt-image-2-allüber APIYI (api.apiyi.com). Dieses Modell stammt aus dem offiziellen Reverse-Kanal, bietet standardmäßig Websuche und ist preislich attraktiver als die direkte Anbindung – ideal für Creator, die in Serie produzieren.
gpt-image-2 Vorteil 3: Mehrere Formate und Bildserien
Das Standardformat für Xiaohongshu-Cover ist 3:4 (Hochformat), 1:1 eignet sich für Infokarten und 9:16 für Kurzvideo-Cover. gpt-image-2 unterstützt diese 3 Formate nativ (sowie 1:1, 2:3, 3:2, 4:3, 4:5, 16:9, 21:9 – insgesamt 9), ohne dass ein nachträglicher Zuschnitt nötig ist.
Noch wichtiger: gpt-image-2 unterstützt die Erstellung von 1-10 Bildern pro Anfrage. Da die optimale Länge für Xiaohongshu-Beiträge 6-9 Bilder beträgt (höchste Gewichtung durch den Algorithmus), können Creator das Modell anweisen, eine komplette, visuell konsistente Slideshow zu einem Thema in einem Rutsch zu erstellen.
gpt-image-2 Anpassungsmatrix für Xiaohongshu-Inhalte
Verschiedene Arten von Xiaohongshu-Inhalten stellen unterschiedliche Anforderungen an Bilder. Die folgende Tabelle hilft Ihnen dabei, die Eignung von gpt-image-2 für jedes Inhaltsformat sowie die empfohlenen Parameter schnell zu bestimmen.
| Inhaltstyp | Empfohlenes Seitenverhältnis | Anzahl Bilder | Textdichte | gpt-image-2 Eignung | Empfohlene Qualität |
|---|---|---|---|---|---|
| Wissensvermittlung | 3:4 | 6-9 | Hoch (80-150 Wörter/Bild) | ⭐⭐⭐⭐⭐ | high |
| Produktbewertung | 3:4 | 6-9 | Mittel (40-80 Wörter/Bild) | ⭐⭐⭐⭐⭐ | high |
| Tutorial-Schritte | 3:4 | 4-9 | Mittel (50-100 Wörter/Bild) | ⭐⭐⭐⭐⭐ | medium-high |
| Datenvisualisierung | 3:4 / 1:1 | 1-3 | Hoch (100+ Wörter/Bild) | ⭐⭐⭐⭐⭐ | high |
| Essen/Mode-Empfehlungen | 3:4 | 6-9 | Niedrig (hauptsächlich Tags) | ⭐⭐⭐⭐ | medium |
| Vlog-Cover | 9:16 | 1 | Mittel (hauptsächlich Titel) | ⭐⭐⭐⭐ | high |
| Memes/Witze | 1:1 | 1 | Niedrig | ⭐⭐⭐ | low-medium |
Wie an der Eignung zu erkennen ist, ist gpt-image-2 besonders stark bei informationellen Inhalten mit mittlerer bis hoher Textdichte. Dies sind genau die Inhalte mit einer "hohen Speicherquote", die vom Xiaohongshu-Algorithmus bevorzugt werden. Laut den offiziellen CES-Algorithmus-Gewichtungen von Xiaohongshu zählt eine Speicherung (Favorisierung) 1 Punkt und ist damit genauso wichtig wie ein Like, während Kommentare und Shares jeweils 4 Punkte zählen. Infografiken, Tutorials und Bewertungsbeiträge erzielen aufgrund ihres "praktischen Nutzens" eine deutlich höhere Speicherquote als andere Typen und erhalten dadurch mehr organische Reichweite.
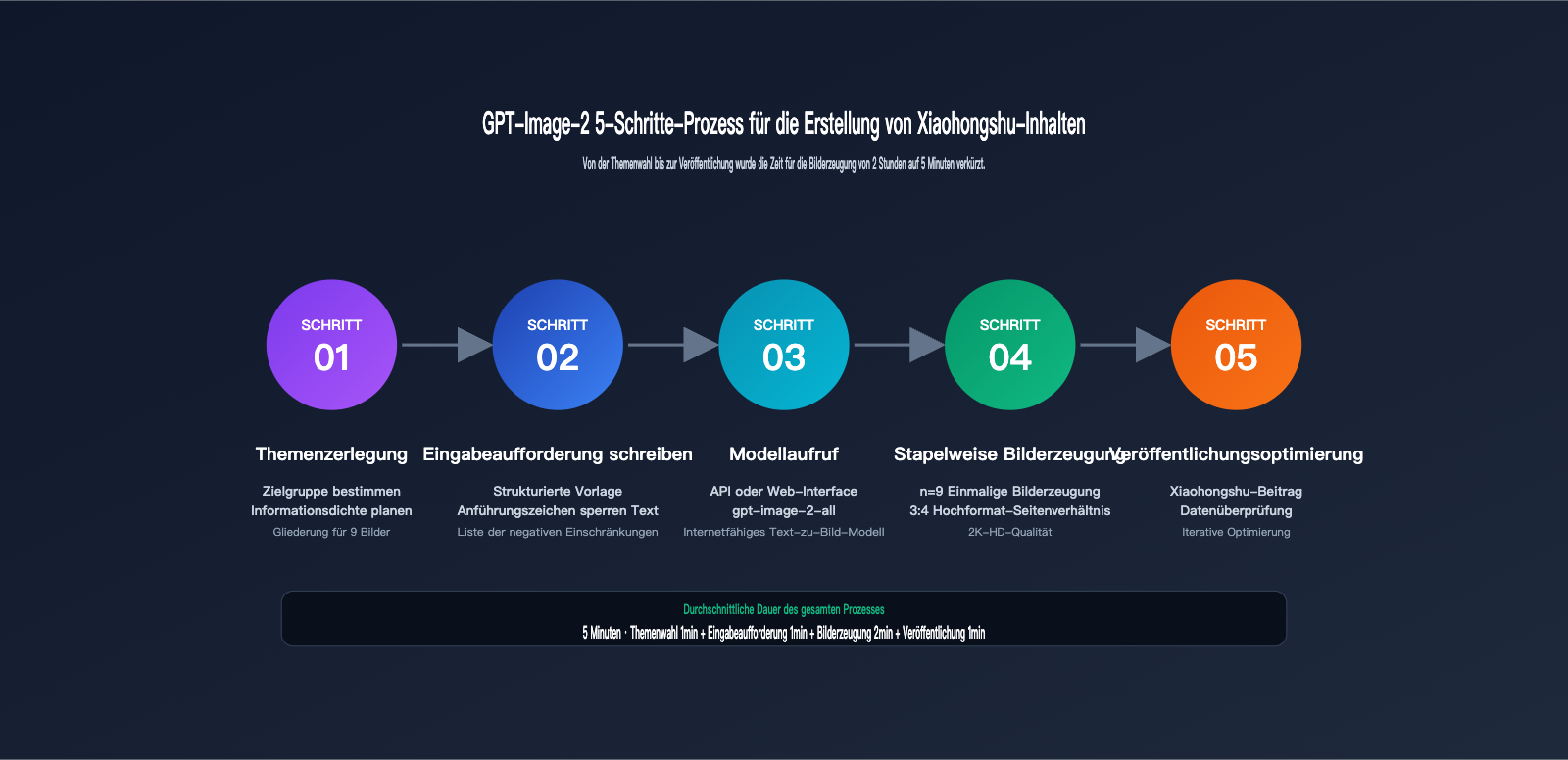
Der 5-Schritte-Prozess für die Erstellung von Xiaohongshu-Grafiken mit gpt-image-2
Kommen wir nun zur praktischen Umsetzung. Der vollständige Prozess zur Erstellung von Xiaohongshu-Bildern mit gpt-image-2 lässt sich in 5 Schritte unterteilen, für die es jeweils wiederverwendbare Techniken gibt.
Schritt 1: Themenanalyse und Planung der Informationsdichte
Bevor Sie gpt-image-2 öffnen, nehmen Sie sich 5 Minuten Zeit für eine Themenanalyse. Ein guter Xiaohongshu-Infografik-Beitrag sollte drei Fragen beantworten:
- Wer ist die Zielgruppe? (Anfänger / Fortgeschrittene / Entscheidungsträger)
- Wie viele Kerninformationen gibt es? (3 / 5 / 7 Punkte)
- Wie viel Information trägt jedes Bild? (Ein Bild pro Punkt / Ein Bild mit mehreren Vergleichen)
Beispiel: Für einen Beitrag zum Thema "Vergleich von KI-Bildtools 2026" könnten Sie 9 Bilder einplanen: 1 Cover + 1 Übersichtstabelle + 5 Tool-Vorstellungen (eine pro Tool) + 1 Fazit + 1 Call-to-Action. Die Kerninformation pro Bild sollte 80 Wörter nicht überschreiten.
Schritt 2: Strukturierte gpt-image-2 Eingabeaufforderung (Prompt) schreiben
Für das Schreiben von Prompts für gpt-image-2 gibt es eine offiziell empfohlene Struktur: Hintergrund/Szenario → Subjekt → Schlüsselsdetails → Textinhalt → Stilvorgaben. Damit die generierten Xiaohongshu-Bilder stabil und brauchbar sind, gelten 4 Grundregeln:
- Chinesische Texte müssen in chinesische Anführungszeichen 「」 oder englische Anführungszeichen "" gesetzt werden, damit das Modell sie präzise rendert.
- Geben Sie im Prompt explizit die Schriftgrößenhierarchie an (z. B. "Haupttitel 64pt fett, Untertitel 28pt").
- Verwenden Sie Schlüsselwörter wie "high-fidelity", "ultra-detailed", "crisp typography", um die Details zu verbessern.
- Listen Sie negative Einschränkungen auf (z. B. "no watermark, no extra text, no duplicate words"), um unnötige Zusätze zu vermeiden.
Schritt 3: Modellaufruf über die gpt-image-2 API
Wenn Sie über grundlegende API-Kenntnisse verfügen, können Sie gpt-image-2 direkt über die OpenAI-Standard-Schnittstelle aufrufen. Hier ist ein minimalistisches Code-Beispiel für die Erstellung eines 3:4 Xiaohongshu-Covers:
from openai import OpenAI
client = OpenAI(
api_key="your_apiyi_key",
base_url="https://api.apiyi.com/v1"
)
response = client.images.generate(
model="gpt-image-2-all",
prompt='Xiaohongshu-Stil Infografik-Cover, 3:4 Hochformat, Haupttitel 「2026 AI 绘图工具 TOP 5」 64pt weiß fett, Untertitel 「博主必看,收藏不亏」 28pt hellgrau, mittig 5 Tool-Logo-Thumbnails, Hintergrund mit Farbverlauf von Pink zu Violett, high-fidelity typography, crisp text, no watermark',
size="1024x1536",
quality="high",
n=1
)
print(response.data[0].url)
📌 Hinweis zur base_url-Konfiguration: Der obige Code verwendet APIYI
api.apiyi.com/v1als Endpunkt. Das Modellgpt-image-2-allist die offizielle Version, die standardmäßig über eine Internet-Suchfunktion verfügt. Normale Nutzer können auch das Standardmodellgpt-image-2(ohne Internetzugriff) verwenden, das kostengünstiger ist.
Schritt 4: Batch-Generierung für 9-teilige Bildergalerien
Die optimale Anzahl für Xiaohongshu-Beiträge liegt bei 6-9 Bildern. Wenn Sie manuell für jedes Bild einen Prompt schreiben, ist das zu ineffizient. Der n-Parameter von gpt-image-2 unterstützt Werte von 1-10, sodass Sie 9 Bilder auf einmal generieren können.
Ein wichtiger Tipp hierbei: Lassen Sie das Modell nicht 9 völlig unzusammenhängende Bilder generieren, sondern führen Sie es durch den Prompt dazu, eine "Bilderserie" zu erstellen. Beispiel:
response = client.images.generate(
model="gpt-image-2-all",
prompt='''Generiere eine Serie von 9 zusammenhängenden Xiaohongshu-Infografiken, 3:4 Hochformat,
einheitlicher dunkelvioletter Hintergrund + weißer Text, Thema "5 Prompt-Formeln, die jeder KI-Bild-Anfänger kennen muss",
Bild 1: Cover-Seite, Titel 「AI 绘图必学」 Untertitel 「5 个 Prompt 公式」,
Bild 2-6: Jedes Bild stellt eine Formel vor, oben Nummerierung 01-05, mittig Formelname, unten 30 Wörter Erklärung,
Bild 7: Vergleichstabelle der Formeln,
Bild 8: Praxisbeispiel,
Bild 9: Call-to-Action-Seite, Text 「点赞收藏不迷路」 ''',
size="1024x1536",
quality="high",
n=9
)
Schritt 5: Kein Programmierer? Nutzen Sie das Web-Tool imagen.apiyi.com
Wenn Sie ein reiner Content-Creator sind und keine Erfahrung mit Python oder API-Aufrufen haben, können Sie den Code-Teil komplett überspringen. Wir empfehlen das Web-Tool imagen.apiyi.com – es bündelt gpt-image-2, Nano Banana, Seedream und andere gängige Bildmodelle. Es bietet eine einfache Formularoberfläche, unterstützt die Auswahl von Seitenverhältnissen, Bildanzahl und Batch-Downloads. Sie können innerhalb von 5 Minuten loslegen.
🎨 Empfehlung zur Werkzeugwahl: Für reine Creator empfehlen wir direkt das Web-Tool imagen.apiyi.com – kein Programmieren, keine API-Konfiguration erforderlich. Einfach Modell (empfohlen: gpt-image-2 oder gpt-image-2-all) und Seitenverhältnis (3:4) wählen und generieren. Für Studios, die eine automatisierte Stapelverarbeitung benötigen, empfiehlt sich der API-Aufruf über APIYI apiyi.com, um das Tool an eigene SaaS-Lösungen oder Feishu-Tabellen anzubinden.
gpt-image-2 Xiaohongshu-Prompt-Vorlagenbibliothek
Hier sind 6 praxiserprobte Prompt-Vorlagen, die die gängigsten Inhaltstypen auf Xiaohongshu abdecken. Alle Vorlagen wurden für die Textdarstellung optimiert. Du kannst sie direkt kopieren und den Inhalt in den Klammern 【】 durch dein jeweiliges Thema ersetzen.
Vorlage 1: Wissens-Infokarte (höchste Informationsdichte)
Xiaohongshu-Stil Wissens-Infokarte, 3:4 Hochformat,
Obere Titelleiste: Dunkelvioletter Hintergrund, weißer fetter chinesischer Titel „【Dein Haupttitel, max. 15 Zeichen】“ Schriftgröße 56pt,
Untertitel „【Ein Satz zur Wertbeschreibung, max. 20 Zeichen】“ Schriftgröße 24pt hellviolett,
Mittlerer Inhaltsbereich: 5 nummerierte Punkte, jeder Punkt enthält ein Zahlenabzeichen + Titel + 30 Zeichen Erklärung,
Unten: Pinkfarbener CTA-Button „Speichern, um es wiederzufinden“,
Farbschema: Dunkelviolett als Hauptfarbe #2D1B69, leuchtendes Pink als Akzentfarbe #FF6B9D,
high-fidelity Chinese typography, crisp text rendering, no watermark, no duplicate text
Vorlage 2: Produktvergleichskarte
Xiaohongshu-Produktvergleichskarte, 3:4 Hochformat, weißer Hintergrund,
Oben: Produktbilder links und rechts + Produktname „【Produkt A】“ vs „【Produkt B】“,
Mitte: Vergleichstabelle mit 5 Zeilen, jede Zeile enthält Dimensionsname + A-Bewertung + B-Bewertung,
Bewertung erfolgt über 5-Sterne-Symbole (★),
Unten: Empfehlungsfazit „Gesamtempfehlung:【Produktname】“,
Klare und scharfe Schriftart, Tabellenlinien 1px hellgrau, Haupttitel fett 48pt,
high-fidelity, ultra-detailed, no extra elements
Vorlage 3: Tutorial-Schritt-für-Schritt-Grafik
Xiaohongshu-Tutorial-Schrittgrafik, 3:4 Hochformat, beiger warmer Hintergrund,
Oberer Haupttitel „【Thema】in 3 Minuten erledigt“ schwarz fett 56pt,
Mitte: 3 Schrittblöcke vertikal angeordnet,
Jeder Block: Große Schrittnummer links (01/02/03), rechts Schritttitel + 25 Zeichen Erklärung,
Unten: Ergebnisbild + Text „Fertig!“,
Handgezeichneter Illustrationsstil, warme orange-gelbe Akzentfarbe,
crisp typography, clear hierarchy, no watermark
Vorlage 4: Datenvisualisierungskarte
Xiaohongshu-Datenkarte, 3:4 Hochformat, dunkelblauer Verlaufs-Hintergrund,
Oberer Titel „【Datenthema】Neueste Daten 2026“ weiß 52pt,
Mitte: 1 zentrale große Zahl „【Schlüsselzahl】“, nimmt 40% der Bildhöhe ein,
Unter der Zahl: Datenquellenangabe 12pt hellblau,
Mitte-Unten: 3 Zeilen mit ergänzenden kleinen Daten, jede Zeile enthält Symbol + Daten + kurze Erklärung,
Unten: Heller CTA „An Kollegen weiterleiten“,
Farbschema: Dunkelblau #0F172A bis #1E40AF Verlauf, weißer Text mit hohem Kontrast,
high-fidelity typography, crisp small text, no extra words
Vorlage 5: Checklisten-Grafik
Xiaohongshu-Checklisten-Cover, 3:4 Hochformat,
Oben: Neongrüner Balken, schwarzer fetter Text „【Zahl】x 【Thema】“ 60pt,
Untertitel „Vom Blogger geheim gehalten, direkt kopieren und anwenden“ 24pt,
Mitte: 【Zahl】 Checklistenpunkte, jeder Punkt enthält ✓ Symbol + Punktname,
Kompaktes Layout mit angemessenem Weißraum, klare Schriftgrößenabstufung,
Unten: Pinker Rahmen + Text „Vollständige Liste auf dem nächsten Bild“,
Stil: Schlicht und modern, Notion-Stil Layout,
high-fidelity Chinese text, crisp icons, no decorative noise
Vorlage 6: Spezialszenario für webbasierte Bilderzeugung (speziell für gpt-image-2-all)
Xiaohongshu-Produktempfehlungskarte, 3:4 Hochformat,
Thema: Vorstellung von „【Neuestes Produkt, z.B. iPhone 17 Pro Max】“,
Bitte recherchiere online die neuesten offiziellen Farben, Schlüsselparameter und das Veröffentlichungsdatum dieses Produkts,
Oben: Rendering des tatsächlichen Produktaussehens,
Mitte: Produktname + 3 Kernverkaufsargumente (Farbe/Kapazität/Preis),
Unten: Werbetext „Lohnt sich der Kauf? Erst lesen, dann entscheiden“,
Stil: Apple-Stil, schlicht, weißer Hintergrund,
high-fidelity, accurate product details from web search, no fictional specs
💡 Tipps zur Verwendung der Vorlagen: Alle oben genannten Vorlagen wurden für die chinesische Textdarstellung optimiert. Es wird empfohlen, beim ersten Mal
quality="medium"zu verwenden, um das Layout zu testen. Sobald die Anordnung stimmt, kannst du für das finale Ergebnis aufquality="high"wechseln, um 30-40 % der Kosten zu sparen. Für die Massenproduktion empfiehlt sich die Anbindung über APIYI (apiyi.com), da diese stabiler und schneller ist als eine Direktverbindung.
gpt-image-2 vs. traditionelle Grafiktools: Ein Leistungsvergleich
Viele Kreative fragen sich: Warum sollte ich zu gpt-image-2 wechseln, wenn ich Canva, Figma oder Photoshop habe? Die folgende Tabelle vergleicht die Effizienz dieser vier Werkzeuge für die wichtigsten Xiaohongshu-Szenarien.
| Vergleichsdimension | gpt-image-2 | Canva | Figma | Photoshop |
|---|---|---|---|---|
| Zeit pro Bild | 30 Sek. – 1 Min. | 15-30 Min. | 30-60 Min. | 1-2 Std. |
| Zeit für 9-Bilder-Carousel | 5 Min. (n=9) | 3-4 Std. | 4-6 Std. | 8+ Std. |
| Chinesische Textdarstellung | 95%+ genau | 100% (manuell) | 100% (manuell) | 100% (manuell) |
| Kreative Entfaltung | Hoch (KI-generiert) | Mittel (Vorlagen) | Niedrig (leeres Blatt) | Niedrig (leeres Blatt) |
| Online-Wissen | ✅ Integriert | ❌ | ❌ | ❌ |
| Lernkurve | Niedrig (Chinesisch schreiben) | Niedrig | Mittel | Hoch |
| Monatliche Kosten | $5-30 (nutzungsbasiert) | $12.99 Abo | $15 Abo | $22.99 Abo |
| Geeignet für | Massenproduktion, Infografiken | Vorlagennutzung | Teamarbeit | Kommerzielle Retusche |
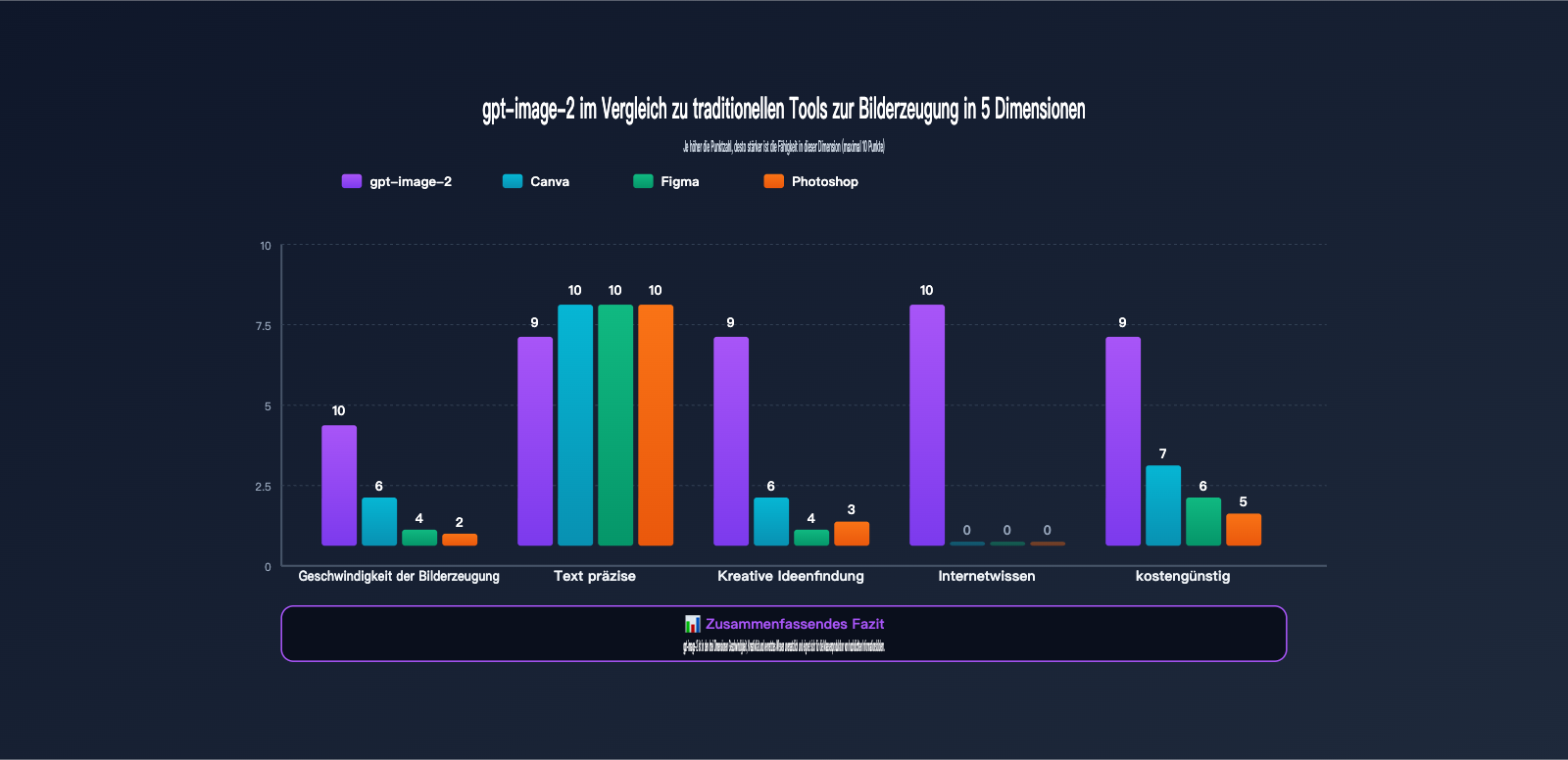
Wie die Vergleichstabelle zeigt, ist gpt-image-2 nicht dazu gedacht, Canva oder Figma zu ersetzen, sondern deckt ein völlig neues Szenario ab: die Kombination aus "kreativer Entfaltung + Massenproduktion + Online-Wissen". Wenn dein Xiaohongshu-Kanal wöchentlich 3-5 Beiträge benötigt, kann gpt-image-2 die Zeit für die Bilderstellung von 8-10 Stunden auf unter eine Stunde verkürzen.
gpt-image-2 FAQ: Häufige Fragen zum Xiaohongshu-Betrieb
Q1: Funktionieren chinesische Texte in mit gpt-image-2 erstellten Xiaohongshu-Bildern wirklich fehlerfrei?
Die Genauigkeit liegt in der Praxis bei über 95 %. OpenAI hat gpt-image-2 im offiziellen Blog explizit als „polyglottes“ Modell gekennzeichnet, das bei nicht-lateinischen Schriftzeichen wie Chinesisch, Japanisch und Koreanisch deutlich verbessert wurde. Beachten Sie jedoch zwei Punkte: Erstens: Setzen Sie den chinesischen Text in der Eingabeaufforderung in Anführungszeichen (z. B. „Text hier“), da das Modell ihn sonst eher „versteht“ statt ihn „kopiert“. Zweitens: Bei seltenen Schriftzeichen oder traditionellem Chinesisch können noch Fehler auftreten. Wir empfehlen daher, wichtige Texte vor der Veröffentlichung stichprobenartig zu prüfen.
Q2: Was kostet ein 3:4-Bild für Xiaohongshu mit gpt-image-2 ungefähr?
Gemäß der offiziellen Preisgestaltung kostet ein hochwertiges Bild in 1024×1536 (3:4) etwa $0,20–$0,25. Für eine Bildergalerie mit 9 Bildern liegen die Kosten bei ca. $1,80–$2,30 (entspricht etwa 13–17 RMB). Über den API-Proxy-Dienst von APIYI (apiyi.com) ist die Anbindung oft günstiger, zudem werden Zahlungen in RMB und Rechnungsstellung unterstützt, was für inländische Kreative bei der Massenproduktion ideal ist.
Q3: Wie nutze ich die „Online-Bilderzeugung“ von gpt-image-2?
Die Online-Funktion ist in der ChatGPT-Weboberfläche standardmäßig aktiviert (Thinking-Modus). Über die API müssen Sie ein Modell-Variante wählen, die Online-Zugriff unterstützt. Wenn Sie das Modell gpt-image-2-all über APIYI (apiyi.com) aufrufen, ist die Websuche standardmäßig aktiv – Sie müssen lediglich in der Eingabeaufforderung Informationen erwähnen, die eine Recherche erfordern (z. B. „neueste Veröffentlichungen“, „offizielle Farbschemata“ oder „echte Parameter“). Das Modell führt dann automatisch eine Websuche durch und integriert die Ergebnisse in die Bilderzeugung.
Q4: Ich kann nicht programmieren, kann ich gpt-image-2 trotzdem für Xiaohongshu nutzen?
Absolut. Wir empfehlen das Web-Tool imagen.apiyi.com. Sie benötigen weder API-Konfiguration noch eine Python-Umgebung. Wählen Sie einfach das Modell (gpt-image-2 oder gpt-image-2-all) im Webformular, geben Sie die Eingabeaufforderung ein, wählen Sie das Format (3:4) und die Anzahl, und klicken Sie auf „Generieren“. Das Tool bietet eine chinesische Benutzeroberfläche, Batch-Downloads und eine Historienverwaltung – ideal für reine Content-Ersteller.
Q5: Werden mit gpt-image-2 erstellte Xiaohongshu-Bilder als „KI-generiert“ gedrosselt?
Bisher gibt es von Xiaohongshu keine öffentliche Regelung, die „KI-generierte Bilder“ pauschal drosselt. Der Algorithmus bewertet primär die Interaktionsrate (Likes, Favoriten, Kommentare, Shares, Follows). Solange Ihre Bilder eine hohe Informationsdichte aufweisen und für die Leser wertvoll sind, erhalten Sie natürliches, positives Feedback. Wir empfehlen, die Bildquelle im Text kurz anzugeben (z. B. „KI-unterstützt erstellt“), um die Transparenz zu erhöhen.
Q6: Wie viele Bilder kann gpt-image-2 maximal auf einmal generieren?
Über die API sind pro Anfrage bis zu 10 Bilder (n=10) möglich, in der ChatGPT-Weboberfläche bis zu 8. Für eine 9-Bilder-Galerie auf Xiaohongshu kann die API dies in einem einzigen Durchgang erledigen, was deutlich effizienter ist als bei anderen Modellen. Beachten Sie jedoch: Je höher n, desto länger die Warte- und Verarbeitungszeit. Bei Massenproduktionen empfehlen wir die Einrichtung asynchroner Aufgaben.
Q7: Welches Modell eignet sich besser für Xiaohongshu: gpt-image-2, Nano Banana Pro oder Seedream?
Kurz gesagt: gpt-image-2 eignet sich für Inhalte mit hoher Informationsdichte und viel Text (Infografiken, Testberichte, Datengrafiken). Nano Banana Pro ist ideal für kreative Szenarien und Gesichtskonsistenz (Seriengeschichten, narratives Storytelling). Seedream punktet bei östlicher Ästhetik und chinesischen Stilen (Hanfu, traditionelle Kunst, Tuschemalerei). Alle drei Modelle können auf imagen.apiyi.com getestet werden – wir empfehlen A/B-Tests, bevor Sie sich auf ein Hauptmodell festlegen.
Q8: Wie erziele ich bei mehreren mit gpt-image-2 generierten Bildern einen einheitlichen Stil?
Drei Kernstrategien: Erstens: Generieren Sie alle 9 Bilder gleichzeitig (n=9), damit das Modell den Stil automatisch beibehält. Zweitens: Legen Sie das Farbschema in der Eingabeaufforderung fest (z. B. „Verwende einheitlich #2D1B69 Violett + #FF6B9D Pink“). Third: Fixieren Sie das Layout (z. B. „Alle Bilder folgen dem Aufbau: Titel oben, Inhalt mittig, CTA unten“). Für eine noch stärkere Konsistenz von Charakteren oder Szenen können Sie die Bild-zu-Bild-Funktion von gpt-image-2 nutzen, die auf einem Referenzbild basiert.
Fazit: Die 3 Grundlogiken für Xiaohongshu mit gpt-image-2
Zusammenfassend lassen sich 3 Grundlogiken für die Erstellung von Xiaohongshu-Inhalten mit gpt-image-2 ableiten:
Erstens: Betrachten Sie die Bilderzeugung als „Produktdesign“ und nicht als „Malen“. Durch das Agentic Reasoning von gpt-image-2 agiert es wie ein „mitdenkender Designer“. Je mehr Ihre Eingabeaufforderung einem Design-Briefing ähnelt (klare Ziele, Informationshierarchie, visuelle Vorgaben), desto präziser ist das Ergebnis.
Zweitens: Nutzen Sie „Informationsdichte“ als Differenzierungsmerkmal. Der Xiaohongshu-Algorithmus belohnt Inhalte mit hoher Speicherrate, und der Kern einer hohen Speicherrate ist der „praktische Nutzen“. Die Fortschritte von gpt-image-2 bei der Textdarstellung und dem Layout ermöglichen Ihnen „hochdichte Infografiken“, die mit Canva-Vorlagen nicht möglich wären – der beste Weg für neue Accounts, um schnell zu wachsen.
Drittens: Nutzen Sie „Online-Wissen“ für die Aktualität Ihrer Inhalte. Bei Themen wie neuen Produkten, aktuellen Ereignissen oder offiziellen Daten sollten Sie unbedingt Modelle wie gpt-image-2-all verwenden, die eine Websuche unterstützen, um Fehler durch KI-Halluzinationen zu vermeiden.
🚀 Handlungsempfehlung: Wenn Sie gpt-image-2 in Ihren Xiaohongshu-Workflow integrieren möchten, empfehlen wir zwei Einstiegspunkte: Reine Content-Ersteller starten mit dem Web-Tool imagen.apiyi.com (erstes Bild in 3 Minuten); technisch versierte Studios binden das Modell gpt-image-2-all über die API von APIYI (api.apiyi.com) an, um eine automatisierte Produktionspipeline aufzubauen. Beide Zugänge unterstützen die Online-Bilderzeugung zu fairen Preisen, ideal für die skalierte Nutzung in inländischen Kreativteams.
Die Beherrschung von gpt-image-2 macht Ihren Xiaohongshu-Account nicht über Nacht zum Hit, aber es reduziert den Zeitaufwand für die Bilderstellung um 90 %. So können Sie mehr Energie in Themenplanung, Textoptimierung und Community-Management stecken – das ist der wahre Mehrwert von KI-Tools für Content-Ersteller.
Autor dieses Artikels: APIYI Technical Team – Spezialisiert auf die API-Anbindung großer Sprachmodelle und die Entwicklung von Tools für die Content-Erstellung. Besuchen Sie apiyi.com für weitere Modellbewertungen, Prompt-Vorlagen und Entwickler-Guides.