Em 24/04/2026, a DeepSeek lançou simultaneamente o V4-Pro e o V4-Flash. Se o Flash é a escolha ideal de custo-benefício para quem busca "preço acessível e eficiência", o V4-Pro é um produto em um patamar completamente diferente:
Ele é, atualmente, o Modelo de Linguagem Grande de código aberto com a maior capacidade de codificação.
Não é apenas uma forma elegante de dizer que é o "melhor entre os open source", mas sim um campeão que supera, em dados brutos, o GPT-5.4, o Claude Opus 4.6 e o Gemini 3.1-Pro:
- LiveCodeBench 93.5 — Primeiro lugar geral, superando o Gemini 3.1-Pro (91.7) e o Claude Opus 4.6 (88.8)
- Codeforces Rating 3206 — Superando o GPT-5.4 (3168) e o Gemini 3.1-Pro (3052)
- Apex Shortlist Pass@1 90.2 — Liderança expressiva sobre o GPT-5.4 (78.1) e o Claude (85.9)
- IMOAnswerBench 89.8 — Uma vantagem de 14 pontos sobre o Claude Opus 4.6 (75.3) em problemas de olimpíadas de matemática
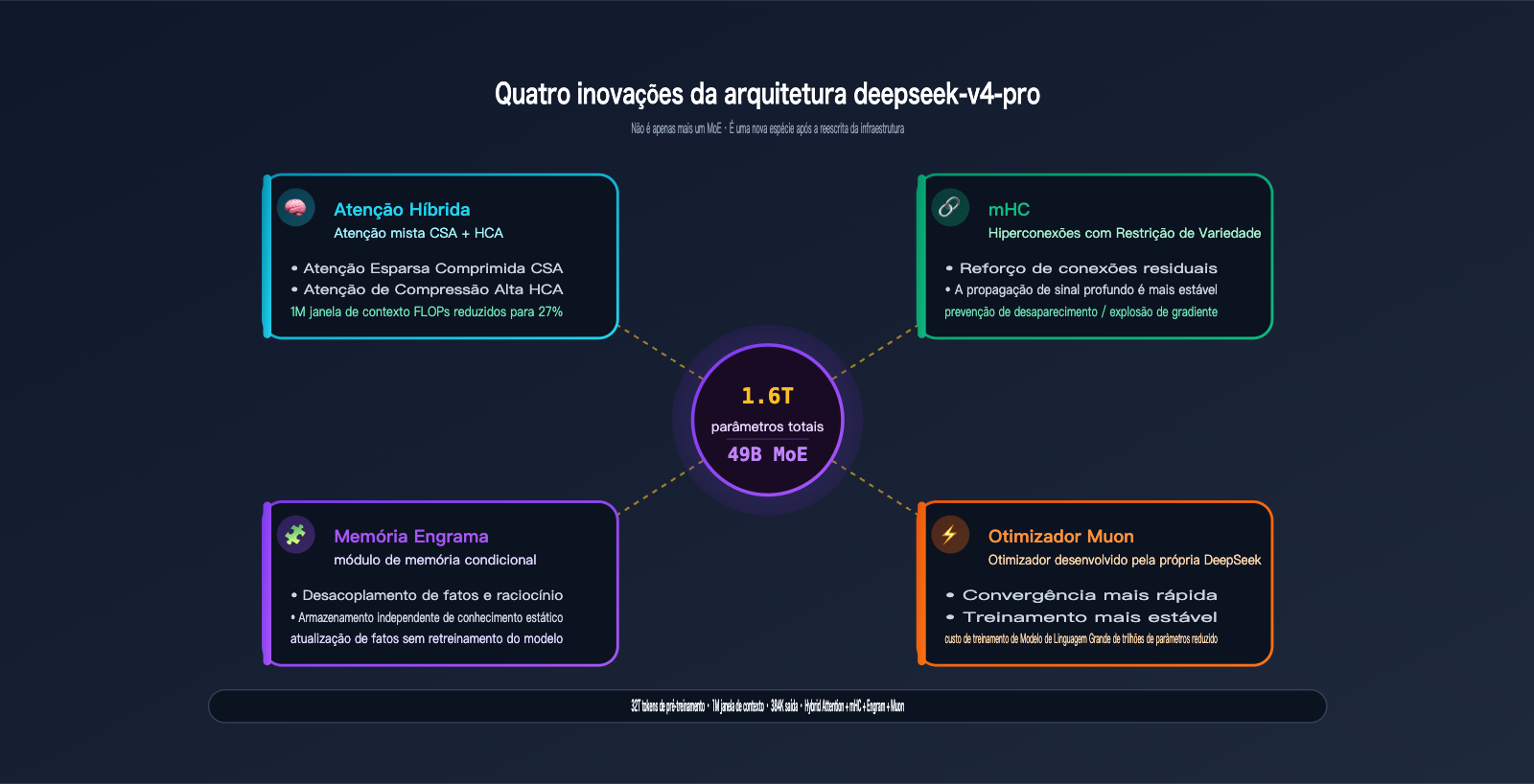
A configuração técnica é impressionante: 1.6T de parâmetros totais / 49B ativos / 32T de tokens de pré-treinamento / 1M de janela de contexto / 384K de saída, somados às quatro inovações arquiteturais que a DeepSeek projetou especificamente para a série V4: Hybrid Attention, Manifold-Constrained Hyper-Connections (mHC), Engram Conditional Memory e Muon Optimizer.
O deepseek-v4-pro já está disponível na APIYI (apiyi.com). Você pode integrá-lo com zero esforço usando o SDK compatível com OpenAI ou Anthropic, pagando apenas 1/7 do preço do GPT-5.4.
Este artigo não vai repetir o básico sobre "como migrar" ou "como escolher modelos baratos", pois isso já cobrimos no post sobre o Flash. Este é um guia dedicado aos entusiastas técnicos do deepseek-v4-pro:
- 3 minutos para entender por que o Pro merece o título de "flagship" (arquitetura + dados + escala)
- 4 tabelas de comparação de benchmarks para ver onde o Pro domina e onde ele compete
- 5 minutos para integração + 2 cenários reais de aplicação em código e matemática

一、As quatro principais capacidades do deepseek-v4-pro
1.1 Visão geral das especificações principais
| Dimensão | deepseek-v4-pro |
|---|---|
| Data de lançamento | 24/04/2026 (versão de visualização) |
| Repositório open source | huggingface.co/deepseek-ai/DeepSeek-V4-Pro |
| Parâmetros totais | 1.6T (Mixture of Experts) |
| Parâmetros ativos | 49B |
| Dados de pré-treinamento | > 32T tokens |
| Janela de contexto | 1M tokens |
| Saída máxima | 384K tokens |
| Inovação de arquitetura | Hybrid Attention + mHC + Engram Memory + Muon |
| Modo de inferência | Modo duplo Thinking / Non-Thinking |
| Function Calling | ✅ Suportado |
| Modo JSON | ✅ Suportado |
| Protocolo de API | Dupla compatibilidade OpenAI + Anthropic |
| Preço de entrada | $1.74 / M tokens |
| Preço de saída | $3.48 / M tokens |
Lembre-se dos 4 números principais: 1.6T / 49B / 32T / 1M — esta é a base da sua performance de elite.
1.2 1.6T / 49B MoE: O "teto open source" em escala
O DeepSeek-V4-Pro possui 1,6 trilhão de parâmetros totais, utilizando a arquitetura Mixture of Experts, com apenas 49B de parâmetros ativados por token. O significado desses números:
| Modelo | Parâmetros totais | Parâmetros ativos | Tipo |
|---|---|---|---|
| Llama 3 70B | 70B | 70B | Denso (totalmente ativado) |
| Mistral Large 2 | 123B | 123B | Denso |
| DeepSeek-V3.2 | 671B | 37B | MoE |
| DeepSeek-V4-Pro | 1.6T | 49B | MoE ⭐ |
| Claude Opus 4.6 | Não divulgado | Não divulgado | Fechado |
Os 1.6T de parâmetros totais conferem ao modelo um nível de conhecimento próximo ao GPT-5.4 / Claude Opus, enquanto os 49B de parâmetros ativos mantêm o custo de inferência por token sob controle — esta é a razão fundamental pela qual a arquitetura MoE consegue atingir um desempenho de ponta.
1.3 32T tokens de pré-treinamento: Volume de dados maximizado
Dados de pré-treinamento > 32T tokens
Este é um número impressionante:
- Dados de pré-treinamento do GPT-4: aprox. 13T tokens (estimativa da indústria)
- Llama 3: 15T tokens
- DeepSeek-V3: 14.8T tokens
- DeepSeek-V4-Pro: >32T tokens ⭐
Os benefícios diretos de dobrar o volume de dados são: cobertura mais completa de conhecimentos de cauda longa, corpus de código mais atualizado e bancos de problemas matemáticos mais profundos — esta é a raiz do domínio do V4-Pro no LiveCodeBench e no IMOAnswerBench.
1.4 Quatro inovações de arquitetura: O verdadeiro diferencial do Pro
Este é o ponto chave que separa o V4-Pro de "apenas mais um modelo MoE". As quatro inovações principais divulgadas oficialmente:
| Inovação | Nome completo | Problema resolvido |
|---|---|---|
| Hybrid Attention | Atenção mista CSA + HCA | Problemas de FLOPs e memória de vídeo em inferência de contexto longo (1M) |
| mHC | Manifold-Constrained Hyper-Connections | Estabilidade de conexões residuais profundas, evitando desaparecimento/explosão de gradiente |
| Engram | Engram Conditional Memory | Desacoplamento de "fatos estáticos" e "capacidade de raciocínio", tornando a atualização de fatos mais barata |
| Muon | Otimizador Muon | Velocidade de convergência e estabilidade do treinamento, reduzindo custos |
Cada item merece uma explicação detalhada:
-
Hybrid Attention (CSA + HCA): A complexidade de atenção do Transformer tradicional é O(n²), o que inviabiliza 1M de contexto. O V4 usa Atenção Esparsa Comprimida (CSA) para filtragem de granulação grossa e Atenção Altamente Comprimida (HCA) para foco de granulação fina, reduzindo os FLOPs para 27% do V3.2 e o cache KV para apenas 10%. Esta é a chave para o deepseek-v4-pro conseguir "rodar" com 1M de contexto.
-
mHC (Manifold-Constrained Hyper-Connections): No treinamento de modelos MoE profundos, o sinal das conexões residuais pode sofrer distorção após dezenas de camadas. O mHC adiciona restrições no espaço de manifold, tornando a propagação do sinal mais estável. Na prática: o modelo pode ser treinado de forma mais profunda e por mais tempo sem colapsar.
-
Engram Conditional Memory: Uma inovação muito prática. Ela desacopla os "fatos na memória do modelo" da "capacidade de raciocínio" — os fatos são armazenados em módulos de memória dedicados, enquanto a cadeia de raciocínio segue outro caminho. O resultado é que, quando o conhecimento mundial precisa ser atualizado, não é necessário treinar novamente todo o modelo, o que reduzirá drasticamente o custo de lançamento de futuras versões Pro.
-
Muon Optimizer: Otimizador desenvolvido pela própria DeepSeek, que converge mais rápido e é mais estável que o AdamW. Em escala de trilhões de parâmetros, isso significa treinar de forma mais completa com o mesmo poder computacional.
🎯 Insight técnico: O deepseek-v4-pro não é apenas uma versão ampliada da arquitetura antiga, mas uma reescrita completa da infraestrutura. Esta é a razão fundamental pela qual ele consegue atingir o nível dos gigantes de código fechado sendo open source. Se você pretende usar o modelo intensivamente, recomendo usar o serviço proxy de API APIYI (apiyi.com) para rodar um conjunto de comandos típicos do seu negócio e sentir a diferença da atualização da arquitetura — especialmente em cenários de contexto longo e raciocínio de várias etapas.
1.5 1M de contexto + 384K de saída: O divisor de águas na geração de textos longos
As especificações de contexto do Pro e do Flash são idênticas: 1M tokens de entrada e 384K tokens de saída. Mas a vantagem do Pro não está em "quanto ele consegue ler", mas em "quão profundamente ele consegue pensar com 1M de tokens".
Significado prático para cenários de textos longos:
| Tarefa | Era V3.2 | Era V4-Pro |
|---|---|---|
| Revisão completa de um livro de 500 mil palavras | Precisava dividir em 10+ partes | Processamento de uma só vez com janela de 1M |
| Perguntas e respostas sobre documentos técnicos de 200 páginas | Precisava construir RAG | Alimentação direta |
| Auditoria de repositório de código médio | Análise baseada em resumo | Verificação de consistência entre arquivos |
| Coerência na escrita de romances | Precisava gerenciar a memória manualmente | 384K de saída de uma só vez |
二、O trono de Benchmark do deepseek-v4-pro
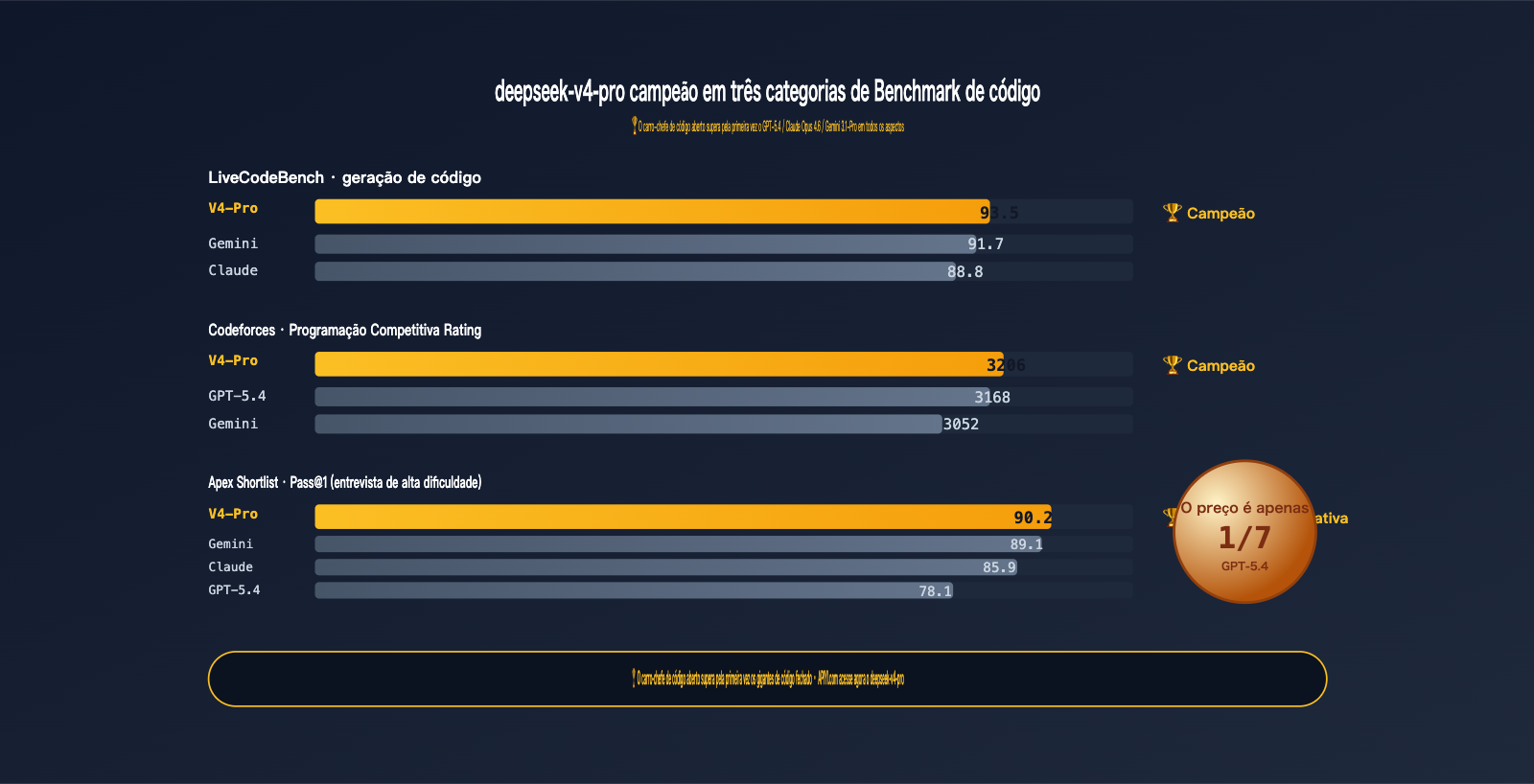
2.1 Capacidade de código: deepseek-v4-pro lidera em três rankings
Primeiro, vejamos os dados mais concretos — capacidade de programação:
| Benchmark | V4-Pro | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1-Pro | Primeiro lugar |
|---|---|---|---|---|---|
| LiveCodeBench | 93.5 | — | 88.8 | 91.7 | V4-Pro 🏆 |
| Codeforces Rating | 3206 | 3168 | — | 3052 | V4-Pro 🏆 |
| Apex Shortlist Pass@1 | 90.2 | 78.1 | 85.9 | 89.1 | V4-Pro 🏆 |
| SWE-bench Verified | 80.6–82.1 | — | 80.8 | 80.6 | Empate |
| Terminal-Bench 2.0 | 67.9 | 75.1 | 65.4 | 68.5 | GPT-5.4 |
Liderando em três categorias e "empatado ou ligeiramente atrás" em duas. Pela primeira vez, um modelo open source supera completamente os modelos fechados de elite em capacidade de código — este é um evento marcante de 2026.
Análise detalhada:
- LiveCodeBench 93.5: O LiveCodeBench atualiza as questões mensalmente para evitar contaminação dos dados de treinamento. A pontuação 93.5 do V4-Pro mostra que sua capacidade de código é generalizada e capaz de resolver novos problemas, não apenas memorizar bancos de questões.
- Codeforces 3206: Pontuação em programação competitiva, 3206 pontos equivalem ao nível IGM (International Grandmaster). Essa pontuação para tarefas de código de negócios diárias é um nível acima.
- Apex Shortlist Pass@1 90.2 vs GPT-5.4 78.1: Esta diferença é sistêmica. O Apex Shortlist é um conjunto de questões de entrevista de alta dificuldade, e o V4-Pro superou o GPT-5.4 por 12 pontos percentuais.
- Terminal-Bench 2.0 ligeiramente inferior: Este benchmark avalia a capacidade de uso de ferramentas de linha de comando em várias etapas. O GPT-5.4 ainda lidera aqui, o que indica que o GPT-5.4 possui uma vantagem em cenários de "Agentes complexos de várias etapas".
2.2 Matemática e raciocínio: deepseek-v4-pro se aproxima da fronteira
Na dimensão matemática, o Pro e os gigantes de código fechado estão em uma "corrida acirrada", sem uma liderança absoluta:
| Benchmark | V4-Pro | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1-Pro |
|---|---|---|---|---|
| MMLU-Pro | 87.5 | 87.5 | 89.1 | 91.0 |
| IMOAnswerBench | 89.8 | 91.4 | 75.3 | 81.0 |
| HMMT 2026 | 95.2 | 97.7 | 96.2 | — |
| MATH | 92% | — | — | — |
| HumanEval | 90% | — | — | — |
| MMLU | 89% | — | — | — |
O destaque é o IMOAnswerBench: Conjunto de questões da Olimpíada Internacional de Matemática, onde o V4-Pro obteve 89.8 pontos, superando o Claude Opus 4.6 em 14.5 pontos e o Gemini 3.1-Pro em 8.8 pontos. Para tarefas de alto nível como raciocínio matemático e provas formais, o Pro é atualmente o teto dos modelos open source.
Ponto fraco no conhecimento geral MMLU-Pro: Os 87.5 do Pro estão empatados com o GPT-5.4, mas 3.5 pontos abaixo dos 91.0 do Gemini 3.1-Pro. Em cenários de perguntas e respostas de conhecimento geral, o Gemini ainda mantém uma certa vantagem.
2.3 Mapa de distribuição de campo: Onde o deepseek-v4-pro ganha e onde perde
| Campo | Campeão | Posição do V4-Pro |
|---|---|---|
| Geração de código (LiveCodeBench) | V4-Pro 🏆 | Campeão |
| Programação competitiva (Codeforces) | V4-Pro 🏆 | Campeão |
| Entrevistas de alta dificuldade (Apex) | V4-Pro 🏆 | Campeão (liderança ampla) |
| Engenharia de software (SWE-bench) | Empate | Empatado em primeiro |
| Olimpíada de matemática (IMO) | GPT-5.4 | Segundo (muito acima de Claude/Gemini) |
| Conhecimento geral (MMLU-Pro) | Gemini 3.1-Pro | Terceiro |
| Cadeia de ferramentas de várias etapas (Terminal-Bench) | GPT-5.4 | Segundo |
| Raciocínio de consistência (HMMT) | GPT-5.4 | Terceiro |
Conclusão: Se a sua carga de trabalho é focada principalmente em código, o deepseek-v4-pro é atualmente uma das escolhas mais fortes do planeta (incluindo modelos open e fechados). Se o foco for em cadeias de ferramentas de Agentes de várias etapas, o GPT-5.4 ainda tem uma pequena vantagem; se for em perguntas e respostas de conhecimento geral, o Gemini 3.1-Pro é mais forte.
🎯 Sugestão de seleção: Recomendamos que você rode um conjunto de comparações AB (20–50 exemplos são suficientes) do V4-Pro vs modelos existentes usando seus comandos típicos no APIYI (apiyi.com). Não confie apenas em Benchmarks públicos para decidir — a distribuição dos seus próprios comandos é o verdadeiro Benchmark. Para testes AB em lote, sugerimos usar a linha de alta concorrência
vip.apiyi.com.
三、5 minutos para invocar o deepseek-v4-pro na APIYI apiyi.com
3.1 Passo 1: Obter a chave e escolher a rota
Ambiente prévio: Python 3.8+ ou Node.js 18+, usando o SDK oficial da OpenAI ou da Anthropic.
Obter a chave:
- Acesse a APIYI
apiyi.com, vá em Painel → API Keys → Criar nova chave. - Recomendamos definir um limite diário separado para a chave Pro (¥200–500, dependendo da escala do seu negócio).
- Copie a chave que começa com
sk-.
Escolher a rota (as três rotas compartilham a mesma chave):
| base_url | Uso |
|---|---|
https://api.apiyi.com/v1 |
Chamadas diárias, cenários interativos |
https://vip.apiyi.com/v1 |
Tarefas em lote, alta concorrência |
https://b.apiyi.com/v1 |
Backup em caso de instabilidade no site principal |
3.2 Passo 2: Invocação mínima em Python (Sem Thinking)
from openai import OpenAI
client = OpenAI(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com/v1",
)
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "system", "content": "You are a senior Python engineer."},
{"role": "user", "content": "Write a production-ready LRU cache in 30 lines."},
],
max_tokens=2048,
)
print(resp.choices[0].message.content)
Altere apenas dois pontos: base_url e model — o restante do código do SDK da OpenAI permanece inalterado.
3.3 Passo 3: Ativar o modo de raciocínio Thinking (O destaque do Pro)
O verdadeiro valor do deepseek-v4-pro só é totalmente liberado no modo Thinking. Benchmarks como IMOAnswerBench 89.8 e LiveCodeBench 93.5 foram medidos neste modo.
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "user", "content": """
Por favor, implemente um limitador de taxa (rate limiter) de balde de tokens (token bucket) seguro para concorrência, exigindo:
1. Suporte a ajuste dinâmico de taxa
2. Suporte a reserva de tráfego de pico
3. Implementação sem bloqueio (CAS ou operações atômicas)
4. Inclusão de testes unitários completos
"""},
],
extra_body={
"reasoning": {"enabled": True, "effort": "high"},
},
max_tokens=16384,
)
print("--- Processo de raciocínio ---")
print(resp.choices[0].message.reasoning_content)
print("\n--- Resposta final ---")
print(resp.choices[0].message.content)
Com effort=high, o Pro realiza um planejamento profundo — você verá que ele primeiro analisa os requisitos, depois projeta a API, discute diferentes abordagens de implementação e, finalmente, fornece o código. Este é o diferencial que justifica o preço do deepseek-v4-pro em relação ao Flash.
3.4 Passo 4: Prática de correção de código
Cenário de negócio real: pedir ao Pro para corrigir um bug.
buggy_code = """
def find_kth_largest(nums, k):
nums.sort()
return nums[k] # BUG aqui
"""
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "system", "content": "You are a senior code reviewer. Identify bugs, explain root cause, and give fixed code."},
{"role": "user", "content": f"Review this code:\n```python\n{buggy_code}\n```"},
],
extra_body={"reasoning": {"enabled": True}},
max_tokens=4096,
)
print(resp.choices[0].message.content)
O Pro apontará que o índice deveria ser -k (após a ordenação, o k-ésimo maior elemento está na posição k a partir do final), e fornecerá a correção + tratamento de condições de contorno (k <= 0, k > len(nums)) + casos de teste.
Os dados de 80%+ no SWE-bench refletem exatamente essa experiência real.
3.5 Passo 5: Function Calling / Uso de Ferramentas
O Pro é muito estável em chamadas de ferramentas únicas. Embora cadeias de ferramentas de várias etapas sejam ligeiramente inferiores ao GPT-5.4, ele supera o Claude:
tools = [
{
"type": "function",
"function": {
"name": "run_sql",
"description": "Execute a read-only SQL query on the analytics DB.",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "SELECT-only SQL"},
},
"required": ["query"],
},
},
},
]
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "user", "content": "Quais foram as 5 cidades com maior DAU nos últimos 30 dias?"},
],
tools=tools,
tool_choice="auto",
)
print(resp.choices[0].message.tool_calls)
3.6 Passo 6: Protocolo Anthropic (Conectando o Claude Code ao Pro)
Este caminho é o valor mais subestimado do deepseek-v4-pro: você pode substituir o modelo base de todos os seus projetos existentes com SDK Claude / Claude Code pelo V4-Pro sem alterar nenhuma linha de código de negócio.
from anthropic import Anthropic
client = Anthropic(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com", # Note que não há /v1
)
resp = client.messages.create(
model="deepseek-v4-pro",
max_tokens=4096,
messages=[
{"role": "user", "content": "Refatore este código Python para o estilo async/await..."},
],
)
print(resp.content[0].text)
Terminal Claude Code: Nas configurações, defina ANTHROPIC_BASE_URL=https://api.apiyi.com + ANTHROPIC_API_KEY=sk-... e altere o modelo para deepseek-v4-pro. Você terá instantaneamente um Agent de terminal com capacidades de código superiores.
3.7 Passo 7: Conectando o deepseek-v4-pro no Cursor
No Cursor, vá em Settings → Models → Custom OpenAI-Compatible:
- Base URL:
https://api.apiyi.com/v1 - API Key:
sk-... - Model Name:
deepseek-v4-pro
Após concluir, as entradas Chat / Cmd+K / Composer do Cursor usarão o V4-Pro, e a qualidade da conclusão e refatoração de código será visivelmente superior.
🎯 Dica de integração em IDE: Ferramentas de programação com IA como Cursor, Windsurf, Cline e Continue são compatíveis com o protocolo OpenAI. Basta apontar o
base_urlparaapi.apiyi.com/v1da APIYI e trocar o modelo paradeepseek-v4-propara uma migração perfeita. Exemplos detalhados de configuração de IDE podem ser consultados na coluna DeepSeek V4 da documentação oficial da APIYI emdocs.apiyi.com.
Quatro: Quando escolher (ou não) o deepseek-v4-pro
4.1 Condições de decisão para escolher o Pro
✅ Escolha o deepseek-v4-pro diretamente nestes cenários:
| Cenário | Por que |
|---|---|
| Geração, refatoração e revisão de código | Campeão absoluto com 93.5 no LiveCodeBench |
| Programação competitiva, treinamento em algoritmos | Nível IGM equivalente (3206 no Codeforces) |
| Respostas em lote para questões de entrevista | Liderança ampla com 90.2 no Apex Shortlist |
| Raciocínio matemático, provas formais | Liderança de 14 pontos sobre o Claude no IMOAnswerBench |
| Compreensão de repositórios inteiros | 1M de janela de contexto + 49B de ativação |
| Escrita e edição de textos longos | 384K de saída de uma só vez |
| Implantação local / treinamento secundário | Pesos open source + módulo Engram facilitam o ajuste fino |
| Substituição do modelo base do Cursor / Claude Code | Integração com protocolo Anthropic sem modificações |
4.2 Quando não escolher o Pro
❌ Não desperdice o poder computacional do Pro nestes casos:
| Cenário | Sugestão |
|---|---|
| Conversas diárias, FAQ | Use o Flash (economize 12x) |
| Classificação e extração de textos curtos | Use o Flash ou um modelo menor |
| Cadeias de ferramentas de Agent complexas e multietapas | Priorize o GPT-5.4 (liderança no Terminal-Bench) |
| Perguntas e respostas de conhecimento geral | O Gemini 3.1-Pro é mais forte |
| Interações online sensíveis à latência | Use o Flash (modo Non-Thinking) ou adicione cache |
4.3 Sugestão de roteamento híbrido
A melhor solução em ambientes de produção geralmente é o roteamento em camadas:
def pick_model(request_type: str, complexity: str) -> str:
# Trabalho pesado de código → Pro
if request_type in ("code_gen", "code_review", "refactor") and complexity == "hard":
return "deepseek-v4-pro"
# Raciocínio matemático → Pro
if request_type in ("math_proof", "competitive_programming"):
return "deepseek-v4-pro"
# Compreensão profunda de documentos longos → Pro
if request_type == "long_doc_analysis":
return "deepseek-v4-pro"
# Outros usos diários → Flash
return "deepseek-v4-flash"
Na APIYI apiyi.com, esses dois modelos compartilham a mesma chave. Para alternar, basta alterar o campo model, sem precisar mexer em outras configurações.
V. FAQ sobre o deepseek-v4-pro
Q1: Por que a capacidade de código do Pro é tão forte?
Três fatores combinados:
- Pré-treinamento com 32T tokens: Inclui uma vasta quantidade de corpora de código de alta qualidade.
- MoE de 1.6T / 49B ativos: Permite que o conhecimento de código seja armazenado e recuperado com eficiência.
- Modo Thinking + Engram Memory: Desacopla a "memorização de paradigmas de código" da "inferência de novos códigos".
Nenhum desses pontos sozinho alcançaria essa pontuação; juntos, eles atingiram 93.5 no LiveCodeBench.
Q2: Os 1.6T de parâmetros não deixam a resposta muito lenta?
A velocidade de resposta única é determinada pelos parâmetros ativos, não pelo total. O Pro ativa apenas 49B por token e, com a otimização de FLOPs do Hybrid Attention, a latência do primeiro token é próxima à do Flash. O modo Thinking é um pouco mais lento (por precisar exibir o processo de raciocínio), mas é uma escolha de design — você está pagando com tempo pela qualidade da inferência.
Q3: O modo Thinking é obrigatório?
Não. Para conversas comuns, códigos simples e perguntas do dia a dia, você pode desativá-lo. No entanto, a maior parte do valor que você paga pelo Pro está no modo Thinking — para códigos complexos, problemas matemáticos e raciocínio lógico de várias etapas, certifique-se de ativar reasoning.enabled=true + effort=high.
Q4: Como usar no Cursor / Claude Code?
- Cursor: Settings → Models → Custom OpenAI-Compatible, no Base URL coloque
https://api.apiyi.com/v1, e em Model coloquedeepseek-v4-pro. - Claude Code: Defina as variáveis de ambiente
ANTHROPIC_BASE_URL=https://api.apiyi.com+ANTHROPIC_API_KEY=sk-..., e ao iniciar, especifique o modelodeepseek-v4-pro.
Capturas de tela com o passo a passo podem ser encontradas na seção de integração de IDE em docs.apiyi.com.
Q5: Comparado ao GPT-5.4, qual vale mais a pena?
Se tiver que escolher um:
- Código diário / Competições / Matemática / Sensível a custo → deepseek-v4-pro (campeão em código, preço 1/7).
- Agentes de fluxo de trabalho de várias etapas / Perguntas de conhecimento geral → GPT-5.4.
- O uso misto é a solução ideal (usando a mesma chave API da APIYI apiyi.com para alternar entre os dois modelos).
Q6: É possível fazer o deploy local?
Sim, o V4-Pro teve os pesos completos disponibilizados no Hugging Face (deepseek-ai/DeepSeek-V4-Pro). Porém, o auto-deploy exige:
- Máquina única com ≥ 8×H200 ou GPU equivalente.
- 1M de janela de contexto requer cache KV adicional (embora o Pro tenha reduzido o cache para 10% do V3.2).
- Custo de engenharia para manter o serviço de inferência.
Cálculo de custo: A menos que seu volume mensal de chamadas exceda 50 bilhões de tokens, o uso via serviço proxy de API da APIYI apiyi.com é mais econômico do que o auto-deploy.
Q7: Qual o limite de concorrência?
Recomendações para ambiente de produção:
- Site principal
api.apiyi.com: 50 conexões simultâneas seguras. - Rota de alta concorrência
vip.apiyi.com: 200+ conexões simultâneas. - Backup
b.apiyi.com: fallback automático em caso de instabilidade na rota principal.
Como o Pro tem latência maior em tarefas complexas de Thinking, a concorrência não deve ser maximizada sem critério — é melhor estimar a janela necessária baseada em QPS × tempo médio de resposta.
Q8: O Pro terá uma versão oficial em breve?
O lançamento de 24/04/2026 é uma versão de visualização (Preview). Seguindo o ritmo da DeepSeek, a versão oficial costuma sair 1 a 2 meses após a preview, podendo trazer pequenas melhorias nos benchmarks. Usar a versão preview na APIYI apiyi.com é totalmente seguro — o ID do modelo provavelmente permanecerá deepseek-v4-pro na versão oficial, mantendo a compatibilidade retroativa.
VI. Resumo do lançamento do deepseek-v4-pro
Se você pulou direto para a conclusão, aqui está:
- ✅ O deepseek-v4-pro é o modelo open-source com a maior capacidade de código atualmente — superou o GPT-5.4 / Claude Opus 4.6 / Gemini 3.1-Pro em três benchmarks rigorosos: LiveCodeBench, Codeforces e Apex.
- ✅ Quatro inovações de arquitetura (Hybrid Attention / mHC / Engram Memory / Muon) fazem dele não apenas "mais um Modelo de Linguagem Grande", mas uma nova espécie após uma reescrita da infraestrutura.
- ✅ Escala de 1.6T / 49B MoE + 32T tokens de pré-treinamento + 1M de janela de contexto atingindo o teto do open-source.
- ✅ Já disponível na APIYI apiyi.com, compatível com os protocolos OpenAI + Anthropic, com integração sem modificações em todas as ferramentas principais como Cursor, Claude Code e Cline.
- ✅ Preço de apenas 1/7 do GPT-5.4, sendo o modo Thinking o seu verdadeiro destaque.
Para equipes de desenvolvimento focadas em código, o deepseek-v4-pro merece testes imediatos — ele não é apenas um "substituto mais barato", mas um modelo carro-chefe que pode se tornar o novo padrão.
🎯 Sugestão de ação: Recomendo solicitar hoje mesmo uma chave na APIYI
apiyi.com(dedicada ao Pro, com limite diário de R$ 200–500), rodar 20 comandos de código/matemática/textos longos que representem seu negócio e fazer um teste A/B entre o V4-Pro (modo Thinking) e seu modelo principal atual. Se a qualidade das tarefas de código melhorar significativamente, mude o modelo padrão do Cursor / Claude Code; se precisar de um modelo barato para o dia a dia, instale também o V4-Flash (veja o guia de migração anterior). Ao rodar testes em lote, usevip.apiyi.com, e em caso de instabilidade, ob.apiyi.comfará o fallback automático. Exemplos completos de integração, configuração de IDE e scripts de reprodução de benchmark podem ser encontrados emdocs.apiyi.com.
O significado do deepseek-v4-pro vai além de ser "apenas mais um modelo SOTA barato". Ele marca a primeira vez que um modelo open-source supera completamente os modelos proprietários líderes em capacidade de código — algo que merece ser testado seriamente por qualquer equipe que leve a engenharia de IA a sério.
Autor: Equipe técnica da APIYI
Recursos relacionados:
- Comunicado oficial da DeepSeek: api-docs.deepseek.com/news/news260424
- Repositório open-source no Hugging Face: huggingface.co/deepseek-ai/DeepSeek-V4-Pro
- Site oficial da APIYI: apiyi.com
- Documentação da APIYI: docs.apiyi.com
- Site principal da APIYI: api.apiyi.com (alternativos: vip.apiyi.com / b.apiyi.com)