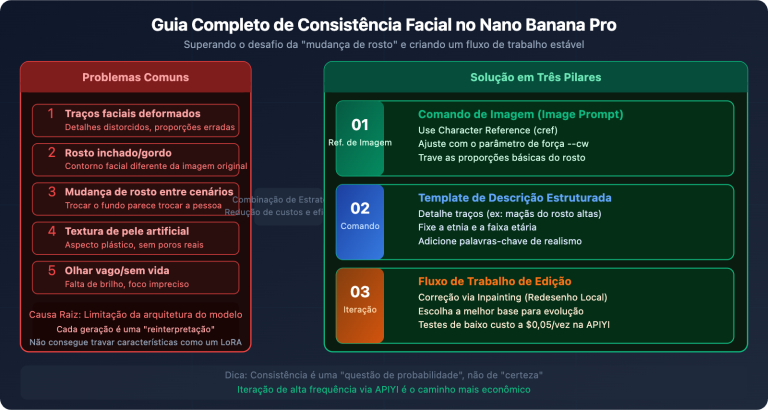
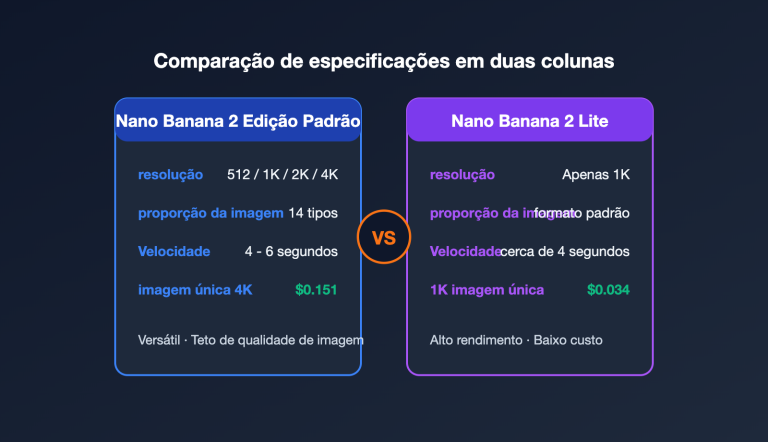
Nota do autor: Explicação detalhada sobre por que os Tokens de Saída do Gemini 3.1 Pro Preview excedem em muito o texto visível: Mecanismo da Cadeia de Raciocínio (Thinking Tokens), Regras de Cobrança e Técnicas de Ajuste do Parâmetro thinking_level para Economizar
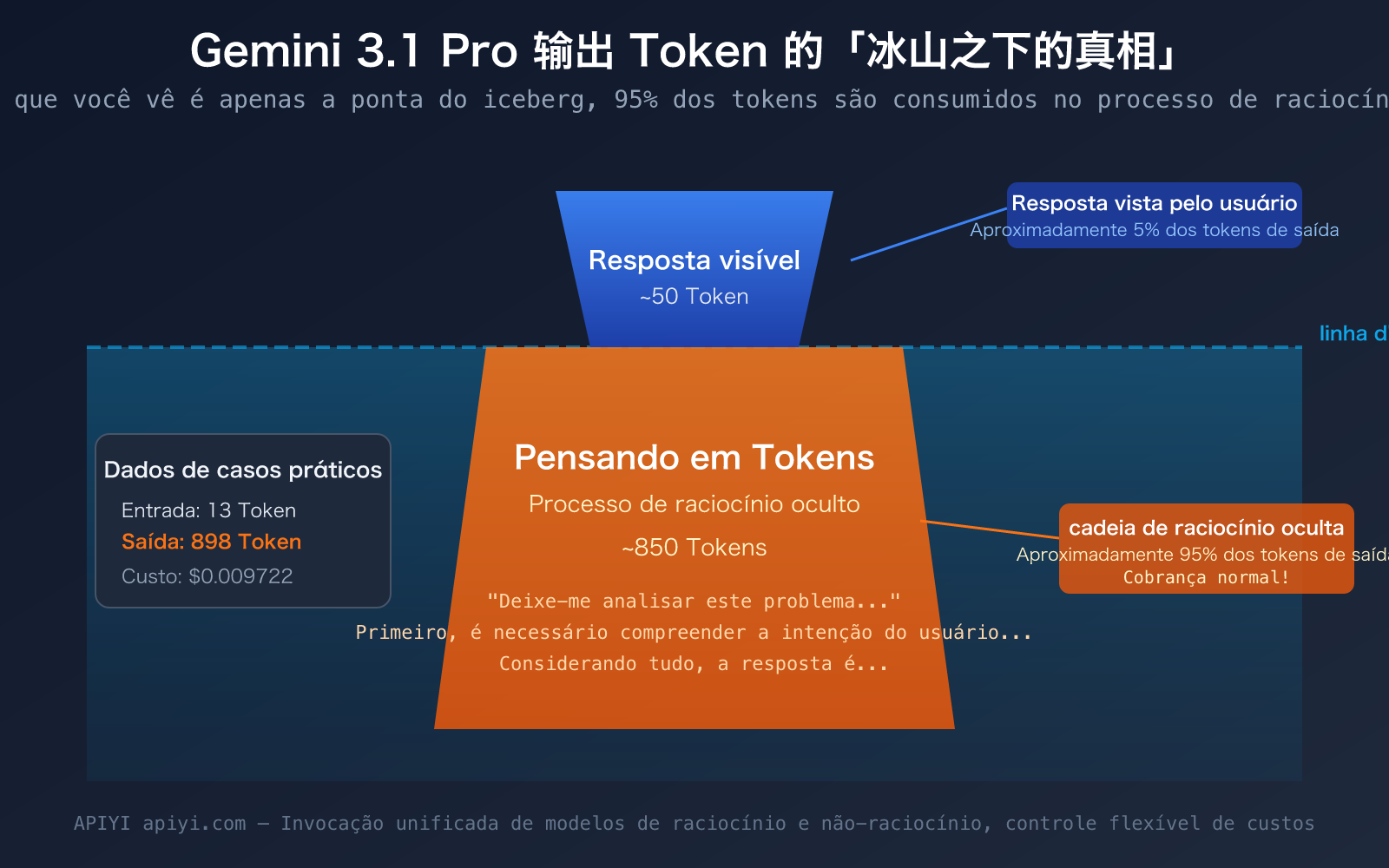
"Eu só enviei uma frase, o modelo só respondeu com uma dúzia de palavras, por que os Tokens de Saída mostram quase 900? Para onde foi o dinheiro?" — Essa é a dúvida real de muitos desenvolvedores ao usar o Gemini 3.1 Pro Preview pela primeira vez. Os dados na captura de tela também mostram claramente esse fenômeno: 13 Tokens de entrada, mas a saída chegou a 898 Tokens.
A resposta são os Thinking Tokens (Tokens de Raciocínio). O Gemini 3.1 Pro é um modelo de raciocínio. Antes de te dar uma resposta, ele faz uma longa cadeia de pensamento e raciocínio "em sua mente". Esse conteúdo de raciocínio não é mostrado para você por padrão, mas é contabilizado nos Tokens de Saída e cobrado normalmente.
Valor Principal: Ao ler este artigo, você entenderá completamente o mecanismo dos Thinking Tokens em modelos de raciocínio, aprenderá a usar o parâmetro thinking_level para controlar a profundidade do raciocínio e, sob a premissa de garantir a qualidade, economizará de 50% a 80% nos custos de Tokens de Saída.
Pontos Principais dos Thinking Tokens do Gemini 3.1 Pro
A maior diferença entre um modelo de raciocínio e um modelo de diálogo comum está na composição completamente diferente dos Tokens de Saída. Aqui estão os conceitos-chave que você precisa entender:
| Ponto | Explicação | Impacto Prático |
|---|---|---|
| Token de Saída = Pensamento + Resposta | Os Tokens de Saída do Gemini 3.1 Pro incluem Thinking Tokens (cadeia de raciocínio) e a resposta real | Você vê poucas palavras, mas o total de Tokens é alto |
| Thinking Tokens são cobrados normalmente | O processo de raciocínio, embora invisível, é cobrado pelo preço dos Tokens de Saída ($12/milhão de Tokens) | Uma pergunta simples pode custar 5 a 10 vezes mais que em um modelo comum |
thinking_level é ajustável |
Suporta três níveis de controle de profundidade de raciocínio: LOW/MEDIUM/HIGH | O nível LOW pode economizar mais de 80% dos Tokens de Saída |
| Modelos não-racionais não têm esse problema | Modelos como GPT-4o, Claude Sonnet 4.6 (com Extended Thinking desativado) são "o que você vê é o que você paga" | Para tarefas simples, usar modelos não-racionais é mais econômico |
Caso Real de Consumo de Thinking Tokens no Gemini 3.1 Pro
Voltando ao exemplo da captura de tela. O usuário fez uma pergunta simples, o modelo respondeu com cerca de uma dúzia de palavras, mas os Tokens de Saída mostraram 891-898. A composição desses Tokens é aproximadamente a seguinte:
- Resposta visível: Cerca de 30-50 Tokens (a dúzia de palavras que você vê)
- Thinking Tokens: Cerca de 840-860 Tokens (o processo de raciocínio interno do modelo)
Ou seja, mais de 95% dos Tokens de Saída você não vê. Eles foram consumidos na cadeia de raciocínio do modelo. É como se você perguntasse a um professor de matemática "quanto é 1+1", o professor só diz "é igual a 2", mas na sua cabeça ele pensou: "Esta é uma questão aritmética básica, precisa usar a operação de adição…" — e você paga por todo o processo de pensamento do professor.
Esse mecanismo não é um bug, mas uma característica de design dos modelos de raciocínio. A razão pela qual o Gemini 3.1 Pro tem um desempenho melhor em problemas complexos (95,1% no benchmark MATH, 77,1% no ARC-AGI-2) é justamente porque ele faz um raciocínio profundo antes de responder.

Mecanismo de funcionamento dos Thinking Tokens do modelo de raciocínio Gemini 3.1 Pro
Diferença fundamental entre modelos de raciocínio e modelos comuns
Um modelo comum (como o GPT-4o) gera uma resposta diretamente após receber sua pergunta. Você vê quantas palavras, consome quantos Tokens de saída. Isso é "o que você vê é o que você obtém".
Um modelo de raciocínio (como o Gemini 3.1 Pro Preview) gera primeiro uma cadeia de raciocínio interna (Chain of Thought) após receber a pergunta e, em seguida, gera a resposta final com base no resultado do raciocínio. Você vê apenas a resposta final, mas a cobrança é pelo número total de Tokens da "cadeia de raciocínio + resposta".
| Tipo de Modelo | Modelos Representativos | Composição dos Tokens de Saída | Custo para Perguntas Simples | Vantagem em Problemas Complexos |
|---|---|---|---|---|
| Modelo Comum | GPT-4o, Claude Sonnet 4.6 | 100% resposta visível | Baixo (o que você vê é o que você obtém) | Capacidade de raciocínio geral |
| Modelo de Raciocínio | Gemini 3.1 Pro, GPT-5.4 Thinking | Cadeia de raciocínio + resposta visível | Alto (5-10 vezes ou mais) | Forte capacidade de raciocínio complexo |
| Modelo Comutável | Claude Sonnet 4.6 (Extended Thinking) | Opção de ativar ou não o raciocínio | Comutação flexível | Ativar raciocínio conforme necessário |
3 detalhes cruciais sobre os Thinking Tokens do Gemini 3.1 Pro
Detalhe 1: Forma de cobrança dos Thinking Tokens. De acordo com a documentação oficial do Google, os Thinking Tokens são cobrados pelo preço padrão dos Tokens de saída. O preço do Token de saída do Gemini 3.1 Pro é de $12 por milhão de Tokens. Quando o modelo gasta 4000 Tokens para raciocinar e 500 Tokens para responder, você paga por 4500 Tokens de saída – e não por 500.
Detalhe 2: Como diferenciar na resposta da API. Na resposta da API Gemini, o campo usage_metadata retornará separadamente thoughts_token_count (número de Tokens de raciocínio) e candidates_token_count (número total de Tokens de saída). Mas atenção: o candidatesTokenCount da API Gemini já inclui os Thinking Tokens, enquanto o candidatesTokenCount do Vertex AI não inclui.
Detalhe 3: O conteúdo da cadeia de raciocínio não é visível por padrão. Você pode obter um resumo do processo de raciocínio (não a cadeia completa) definindo includeThoughts: true, ou pode ativar a funcionalidade de exibição da cadeia de raciocínio em ferramentas como o Cherry Studio para ver o processo de pensamento do modelo.
🎯 Sugestão para economizar: Se você está apenas em conversas simples ou tarefas de tradução, sem necessidade de raciocínio profundo, recomenda-se mudar para um modelo comum (como GPT-4o-mini ou Claude Sonnet 4.6). A APIYI apiyi.com suporta a troca de modelo alterando apenas um parâmetro
model, sem necessidade de modificar outro código.
Otimização dos Thinking Tokens do Gemini 3.1 Pro: 3 estratégias para economizar
Estratégia 1: Usar o parâmetro thinking_level para controlar a profundidade do raciocínio
O Gemini 3.1 Pro oferece o parâmetro thinking_level, que suporta três níveis: LOW, MEDIUM, HIGH. A diferença no consumo de Tokens entre os níveis é enorme:
| thinking_level | Profundidade do Raciocínio | Consumo de Tokens | Cenário de Aplicação | Comparação com HIGH |
|---|---|---|---|---|
| LOW | Raciocínio superficial | Mínimo | Tradução, classificação, perguntas e respostas simples | Economia de ~80%+ |
| MEDIUM | Raciocínio equilibrado | Moderado | Programação diária, geração de documentos, análise geral | Economia de ~50% |
| HIGH | Raciocínio profundo | Máximo | Dedução matemática, problemas científicos, lógica complexa | Linha de base |
Aqui está um exemplo de código para definir thinking_level:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Tarefas simples usam LOW, reduzindo drasticamente os Thinking Tokens
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "把这句话翻译成英文:今天天气真好"}],
extra_body={"thinking_level": "LOW"} # LOW / MEDIUM / HIGH
)
print(response.choices[0].message.content)
print(f"总输出 Token: {response.usage.completion_tokens}")
Ver o código completo de roteamento inteligente (seleciona automaticamente a profundidade do raciocínio com base na complexidade do problema)
import openai
import json
def smart_gemini_call(
prompt: str,
complexity: str = "auto",
api_key: str = "YOUR_API_KEY"
) -> dict:
"""
Chamada inteligente ao Gemini 3.1 Pro, seleciona automaticamente a profundidade do raciocínio com base na complexidade da tarefa
Args:
prompt: Entrada do usuário
complexity: "low" / "medium" / "high" / "auto"
api_key: Chave API
Returns:
Dicionário contendo a resposta e estatísticas de uso de Tokens
"""
client = openai.OpenAI(
api_key=api_key,
base_url="https://vip.apiyi.com/v1"
)
# Julgamento automático da complexidade
if complexity == "auto":
simple_keywords = ["翻译", "translate", "分类", "classify", "总结", "summarize"]
complex_keywords = ["推导", "证明", "计算", "分析", "比较", "为什么"]
prompt_lower = prompt.lower()
if any(kw in prompt_lower for kw in simple_keywords):
thinking_level = "LOW"
elif any(kw in prompt_lower for kw in complex_keywords):
thinking_level = "HIGH"
else:
thinking_level = "MEDIUM"
else:
thinking_level = complexity.upper()
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": prompt}],
extra_body={"thinking_level": thinking_level}
)
return {
"answer": response.choices[0].message.content,
"thinking_level": thinking_level,
"input_tokens": response.usage.prompt_tokens,
"output_tokens": response.usage.completion_tokens,
"total_tokens": response.usage.total_tokens
}
# Exemplo de uso
# Tarefa simples → seleção automática LOW
result = smart_gemini_call("翻译:今天天气真好")
print(f"推理深度: {result['thinking_level']}, 输出Token: {result['output_tokens']}")
# Tarefa complexa → seleção automática HIGH
result = smart_gemini_call("证明勾股定理的至少两种方法")
print(f"推理深度: {result['thinking_level']}, 输出Token: {result['output_tokens']}")
Sugestão: Ao chamar o Gemini 3.1 Pro através da APIYI apiyi.com, é suportado passar o parâmetro
thinking_level. Recomenda-se definir como MEDIUM para uso diário, usando HIGH apenas em cenários de raciocínio complexo como matemática/ciência.
Estratégia 2: Usar diretamente modelos não-racionais para tarefas simples
Nem todos os cenários exigem um modelo de raciocínio. Para tarefas como tradução, conversão de formato, perguntas e respostas simples, usar modelos não-racionais pode economizar 5 a 10 vezes o custo de Tokens:
- GPT-4o-mini: Excelente custo-benefício, primeira escolha para conversas diárias
- Claude Sonnet 4.6 (com Extended Thinking desativado): Alta qualidade de saída, Tokens são o que você vê é o que você obtém
- Gemini 3.1 Flash: Modelo leve do Google, rápido e de baixo custo
Estratégia 3: Definir max_tokens para limitar o limite de saída
Adicionar o parâmetro max_tokens à chamada da API pode impedir que o modelo de raciocínio "pense demais". Mas atenção: max_tokens limita a saída total (raciocínio + resposta). Se definido muito baixo, pode causar truncamento da resposta. Recomenda-se defini-lo como 2-3 vezes o comprimento esperado da resposta.
🎯 Sugestão abrangente: Na plataforma APIYI apiyi.com, você pode usar uma interface unificada para acessar simultaneamente modelos racionais e não-racionais, alternando dinamicamente com base no tipo de tarefa. Uma única chave API pode chamar toda a série de modelos Gemini, Claude e GPT.

Perguntas Frequentes
Q1: Por que os Thinking Tokens do Gemini 3.1 Pro não mostram o processo de raciocínio por padrão?
Esta é uma escolha de design de produto do Google. A cadeia de raciocínio completa pode conter milhares de tokens de derivações intermediárias, e exibi-la diretamente afetaria severamente a experiência do usuário. Você pode obter um resumo do raciocínio configurando includeThoughts: true, ou ativar a função de exibição da cadeia de raciocínio em clientes como o Cherry Studio para ver o processo de pensamento.
Q2: Como posso ver exatamente quantos Thinking Tokens foram consumidos na resposta da API?
Verifique o campo thoughts_token_count no usage_metadata retornado pela API Gemini. Se você estiver fazendo a chamada através do APIYI (apiyi.com), pode visualizar a decomposição detalhada de tokens (entrada/saída/raciocínio) para cada chamada na página de estatísticas de uso da plataforma, facilitando o monitoramento e otimização de custos.
Q3: Além do Gemini 3.1 Pro, quais outros modelos têm um mecanismo similar de Thinking Tokens?
Os principais modelos de raciocínio têm mecanismos similares:
- GPT-5.4 Thinking: Modelo de raciocínio da OpenAI, onde os tokens de raciocínio também são contabilizados e faturados como tokens de saída.
- Claude Sonnet 4.6 Extended Thinking: Modo de raciocínio da Anthropic, que pode ser ativado seletivamente.
- DeepSeek-R1: Modelo de raciocínio de código aberto, onde a cadeia de raciocínio é totalmente visível.
A diferença crucial é que alguns modelos (como o Claude) permitem ligar/desligar o modo de raciocínio de forma flexível, enquanto outros (como o Gemini 3.1 Pro) têm o raciocínio ativado por padrão. Através do APIYI (apiyi.com), você pode usar uma interface unificada para testar e comparar o consumo real de tokens desses modelos.
Resumo
Os pontos principais sobre os Thinking Tokens do Gemini 3.1 Pro são:
- Os Tokens de Saída incluem uma cadeia de raciocínio oculta: O que você vê é apenas a parte da resposta; mais de 95% do consumo de tokens de saída está nos Thinking Tokens invisíveis.
- Thinking Tokens são faturados normalmente: Cobrados ao preço padrão dos tokens de saída, o custo para perguntas simples pode ser 5 a 10 vezes maior do que em modelos não-racionais.
- Use o parâmetro
thinking_levelpara economizar: O nívelLOWpode economizar mais de 80% dos tokens,MEDIUMé adequado para uso diário, e useHIGHapenas para tarefas complexas. - Para tarefas simples, escolha modelos não-racionais: Em cenários como tradução, classificação ou perguntas e respostas simples, é mais econômico usar diretamente o GPT-4o-mini ou o Claude Sonnet 4.6.
Entender o mecanismo dos Thinking Tokens permite que você aloque seu orçamento de raciocínio de forma racional. Recomendamos gerenciar chamadas para múltiplos modelos através da interface unificada do APIYI (apiyi.com), selecionando dinamicamente entre modelos de raciocínio ou modelos não-racionais com base na complexidade da tarefa, para alcançar o melhor equilíbrio entre qualidade e custo.
📚 Referências
-
Documentação do Google Cloud – Modo Thinking (Raciocínio): Documentação técnica oficial do modelo de raciocínio Gemini
- Link:
docs.cloud.google.com/vertex-ai/generative-ai/docs/thinking - Descrição: Fonte autoritativa sobre regras de cobrança de Thinking Tokens e configuração do parâmetro
thinking_level
- Link:
-
Documentação do Google AI para Desenvolvedores – Contagem de Tokens: Explicação oficial sobre contagem de tokens e campo
usage_metadata- Link:
ai.google.dev/gemini-api/docs/tokens - Descrição: Como diferenciar
thoughts_token_countecandidates_token_countna resposta da API
- Link:
-
Google DeepMind – Model Card do Gemini 3.1 Pro: Detalhes sobre capacidades do modelo e benchmarks de raciocínio
- Link:
deepmind.google/models/model-cards/gemini-3-1-pro/ - Descrição: Fonte oficial dos dados de desempenho como MATH 95.1%, ARC-AGI-2 77.1%
- Link:
-
OpenRouter – Melhores Práticas para Tokens de Raciocínio: Melhores práticas da comunidade para gerenciamento de tokens em modelos de raciocínio
- Link:
openrouter.ai/docs/guides/best-practices/reasoning-tokens - Descrição: Comparação de regras de cobrança de tokens de raciocínio entre modelos e recomendações de otimização
- Link:
Autor: Equipe Técnica da APIYI
Discussão Técnica: Convidamos você a compartilhar suas experiências de otimização de tokens em modelos de raciocínio nos comentários. Para mais tutoriais sobre invocação de modelos, visite o centro de documentação da APIYI em docs.apiyi.com