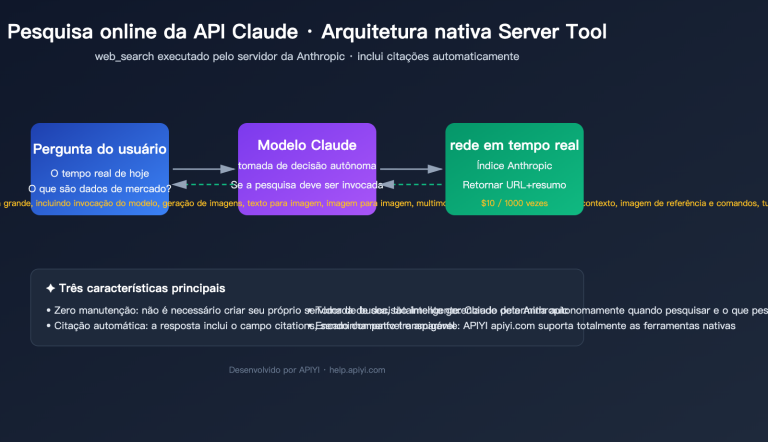
Ao carregar dezenas de milhares de linhas de Excel para uma ferramenta de IA, a API retorna 'saldo insuficiente' — mas a conta claramente tem dinheiro? Este é o cenário mais comum de problema ao usar IA para processar grandes volumes de dados Excel, por trás disso estão as restrições duplas do mecanismo de pré-dedução de tokens e do limite da janela de contexto.
Valor Principal: Ao terminar de ler este artigo, você entenderá completamente por que arquivos Excel grandes causam erros, como usar a IA corretamente para analisar dezenas de milhares de linhas de dados, e qual solução é a mais econômica e eficiente.
<!-- Error response bubble -->
<rect x="0" y="58" width="256" height="84" rx="9" fill="#2d0808" stroke="#ef4444" stroke-width="1.5"/>
<text x="128" y="80" font-family="'PingFang SC',sans-serif" font-size="13" font-weight="bold" fill="#ef4444" text-anchor="middle">❌ Erro 402</text>
<text x="128" y="100" font-family="monospace" font-size="10" fill="#fca5a5" text-anchor="middle">Saldo Insuficiente</text>
<text x="128" y="116" font-family="'PingFang SC',sans-serif" font-size="10" fill="#fca5a5" text-anchor="middle">Saldo insuficiente, recarregue e tente novamente.</text>
<text x="128" y="132" font-family="'PingFang SC',sans-serif" font-size="9" fill="#94a3b8" text-anchor="middle">(Retido $9,00 · Saldo $5,20)</text>
<!-- AI avatar -->
<circle cx="268" cy="100" r="10" fill="#991b1b"/>
<text x="268" y="105" font-family="sans-serif" font-size="11" fill="#fecaca" text-anchor="middle">🤖</text>
<!-- Confused user thought -->
<rect x="40" y="158" width="218" height="50" rx="9" fill="#0f2028"/>
<text x="149" y="178" font-family="'PingFang SC',sans-serif" font-size="10" fill="#7dd3fc" text-anchor="middle">😕 Mas eu tenho saldo na minha conta!</text>
<text x="149" y="196" font-family="'PingFang SC',sans-serif" font-size="10" fill="#7dd3fc" text-anchor="middle">Por que diz saldo insuficiente??</text>
<circle cx="28" cy="183" r="10" fill="#1d4ed8"/>
<text x="28" y="188" font-family="sans-serif" font-size="11" fill="#ffffff" text-anchor="middle">👤</text>
Um. Por que carregar um Excel grande resulta em "saldo insuficiente"?
Muitos usuários ficam confusos quando encontram esse problema pela primeira vez: o saldo da conta é claramente suficiente, então por que a API ainda retorna um erro de saldo insuficiente?
Aqui, é preciso entender um mecanismo chave das APIs de IA: o mecanismo de pré-dedução de tokens.
Detalhes do Mecanismo de Pré-dedução de Tokens
Quando você carrega um arquivo e envia uma solicitação em um cliente de IA como Cherry Studio ou Chatbox, a API não espera que a resposta seja gerada para deduzir o valor. No momento em que a solicitação é enviada, ela estima previamente a quantidade máxima de tokens que a solicitação pode consumir e "congela" temporariamente (pré-deduz) o custo correspondente do saldo da sua conta.
Este processo de pré-dedução funciona aproximadamente assim:
- O usuário carrega o arquivo Excel → o cliente converte o conteúdo do arquivo em texto puro
- O texto puro é inserido completamente no comando (janela de contexto da conversa)
- A API calcula o número de tokens de entrada + estima o número máximo de tokens de saída
- O sistema verifica: total pré-deduzido > saldo da conta → retorna erro de "saldo insuficiente"
Então, essencialmente, não é que você "não tenha dinheiro", mas sim que o valor pré-deduzido para esta solicitação é muito alto, excedendo o saldo atual da sua conta.
Diferenças Fundamentais entre Clientes de IA e ChatGPT
Muitas pessoas têm um equívoco: acham que carregar um Excel no Cherry Studio é o mesmo que carregar um arquivo no ChatGPT.
Na verdade, é completamente diferente:
| Dimensão de Comparação | Cherry Studio / Chatbox | ChatGPT (Code Interpreter) |
|---|---|---|
| Método de processamento de arquivo | Converte para texto e insere totalmente no contexto | Executa código em ambiente sandbox para processar |
| Consumo de tokens | O tamanho do arquivo é diretamente igual ao consumo de tokens | Não ocupa tokens do contexto da conversa |
| Tamanho de arquivo adequado | Sugerido até 100 linhas | Suporta arquivos maiores (limite oficial de aprox. 512MB) |
| Capacidade de análise de dados | Apenas compreensão de texto, não pode executar código | Pode executar Python diretamente para estatísticas |
| Método de acesso à API | Invocação do modelo via chave API, cobrado por token | Assinatura ChatGPT Plus |
🎯 Conhecimento chave: Ao usar um serviço proxy de API (como APIYI apiyi.com) para invocar a IA, o upload de arquivos é feito por meio de um cliente de terceiros, e todo o conteúdo do arquivo é convertido em tokens de texto e transmitido para o modelo. Isso é completamente diferente do mecanismo de sandbox de processamento de arquivos oficial do ChatGPT.
Dois. Quantos Tokens um Excel Grande Realmente Consome?
Antes de discutir as soluções, vamos ter uma ideia intuitiva do consumo de tokens.
Conhecimento Básico de Conversão de Tokens
| Tipo de Conteúdo | Estimativa de Tokens |
|---|---|
| 1 palavra em inglês | Aprox. 1-2 tokens |
| 1 caractere em inglês | Aprox. 0.25 tokens (4 caracteres = 1 token) |
| 1 caractere chinês | Aprox. 1-2 tokens |
| 1 data (ex: 2024-01-15) | Aprox. 5 tokens |
| 1 número (ex: 12345.67) | Aprox. 3-4 tokens |
| 1 linha de dados Excel (10 colunas) | Aprox. 30-80 tokens |
Cálculo de Casos Reais
Tomemos como exemplo um cenário real encontrado por um usuário:
Arquivo A: 60.000 linhas × 10 colunas de dados de eficiência de processo
Estimativa: 60.000 linhas × 10 colunas × média de 5 tokens/célula
= 60.000 × 50
= 3.000.000 tokens (cerca de 3 milhões de tokens!)
Arquivo B: 40.000 linhas × 8 colunas de dados de negócios
Estimativa: 40.000 linhas × 8 colunas × média de 5 tokens/célula
= 40.000 × 40
= 1.600.000 tokens (cerca de 1,6 milhão de tokens)
Comparação da Janela de Contexto e Custos de Vários Modelos
| Modelo | Janela de Contexto | Preço de Entrada (USD/1M tokens) | Custo para processar 3 milhões de tokens |
|---|---|---|---|
| GPT-4o | 128K tokens | $2.50 | Não consegue processar (excede o limite) |
| Claude 3.5 Sonnet | 200K tokens | $3.00 | Não consegue processar (excede o limite) |
| Gemini 1.5 Pro | 1M tokens | $1.25 | Não consegue processar (excede o limite) |
| Gemini 1.5 Pro 2.0 | 2M tokens | $1.25 | Aprox. $3.75/vez |
💡 Como pode ser visto, a maioria dos modelos de linguagem grande simplesmente não consegue acomodar um Excel de 60.000 linhas em sua janela de contexto. Mesmo usando o modelo Gemini 2M de janela de contexto, cada solicitação custaria cerca de US$ 3,75.
Três: 4 Soluções Corretas para AI Processar Grandes Volumes de Dados Excel
Agora que entendemos a causa raiz, vamos apresentar 4 soluções testadas e comprovadas, classificadas por nível de recomendação.
<line x1="0" y1="56" x2="194" y2="56" stroke="#059669" stroke-width="1" opacity="0.5"/>
<text x="0" y="74" font-size="11" font-weight="bold" fill="#34d399">Etapas</text>
<rect x="0" y="80" width="194" height="18" rx="4" fill="#022c22"/>
<text x="8" y="93" font-size="9.5" fill="#6ee7b7">① Extrair 10 linhas de dados de amostra para IA</text>
<rect x="0" y="102" width="194" height="18" rx="4" fill="#022c22"/>
<text x="8" y="115" font-size="9.5" fill="#6ee7b7">② AI compreende a estrutura, gera script de análise</text>
<rect x="0" y="124" width="194" height="18" rx="4" fill="#022c22"/>
<text x="8" y="137" font-size="9.5" fill="#6ee7b7">③ Executar o script localmente para processar todos os dados</text>
<line x1="0" y1="152" x2="194" y2="152" stroke="#059669" stroke-width="1" opacity="0.5"/>
<text x="0" y="170" font-size="11" font-weight="bold" fill="#34d399">Cenários de aplicação</text>
<text x="0" y="186" font-size="10" fill="#a7f3d0">Volume de dados > 10.000 linhas</text>
<text x="0" y="200" font-size="10" fill="#a7f3d0">Análise estatística / Geração de relatórios</text>
<rect x="0" y="214" width="194" height="26" rx="6" fill="#065f46" stroke="#10b981" stroke-width="1.5"/>
<text x="97" y="231" font-size="11" font-weight="bold" fill="#34d399" text-anchor="middle">Consumo de Token: < 2,000</text>
<line x1="0" y1="56" x2="194" y2="56" stroke="#3b82f6" stroke-width="1" opacity="0.5"/>
<text x="0" y="74" font-size="11" font-weight="bold" fill="#93c5fd">Passos de operação</text>
<rect x="0" y="80" width="194" height="18" rx="4" fill="#1e3a5f"/>
<text x="8" y="93" font-size="9.5" fill="#93c5fd">1. Dividir por linha em vários subarquivos</text>
<rect x="0" y="102" width="194" height="18" rx="4" fill="#1e3a5f"/>
<text x="8" y="115" font-size="9.5" fill="#93c5fd">② Chamar em loop a API para processar cada lote</text>
<rect x="0" y="124" width="194" height="18" rx="4" fill="#1e3a5f"/>
<text x="8" y="137" font-size="9.5" fill="#93c5fd">③ Compilar os resultados de cada lote</text>
<line x1="0" y1="152" x2="194" y2="152" stroke="#3b82f6" stroke-width="1" opacity="0.5"/>
<text x="0" y="170" font-size="11" font-weight="bold" fill="#93c5fd">Cenários de aplicação</text>
<text x="0" y="186" font-size="10" fill="#bfdbfe">5000-20000 linhas de dados</text>
<text x="0" y="200" font-size="10" fill="#bfdbfe">Classificação por linha / Análise de sentimento</text>
<rect x="0" y="214" width="194" height="26" rx="6" fill="#1e3a5f" stroke="#3b82f6" stroke-width="1.5"/>
<text x="97" y="231" font-size="11" font-weight="bold" fill="#93c5fd" text-anchor="middle">Custo total cerca de $0.5-1.5</text>
<line x1="0" y1="56" x2="194" y2="56" stroke="#a855f7" stroke-width="1" opacity="0.5"/>
<text x="0" y="74" font-size="11" font-weight="bold" fill="#d8b4fe">Passos de operação</text>
<rect x="0" y="80" width="194" height="18" rx="4" fill="#3b0764"/>
<text x="8" y="93" font-size="9.5" fill="#d8b4fe">① Tabela dinâmica do Excel para estatísticas agregadas</text>
<rect x="0" y="102" width="194" height="18" rx="4" fill="#3b0764"/>
<text x="8" y="115" font-size="9.5" fill="#d8b4fe">② Dados de resumo (dezenas de linhas) para IA</text>
<rect x="0" y="124" width="194" height="18" rx="4" fill="#3b0764"/>
<text x="8" y="137" font-size="9.5" fill="#d8b4fe">③ AI cria relatórios de análise e insights</text>
<line x1="0" y1="152" x2="194" y2="152" stroke="#a855f7" stroke-width="1" opacity="0.5"/>
<text x="0" y="170" font-size="11" font-weight="bold" fill="#d8b4fe">Cenários aplicáveis</text>
<text x="0" y="186" font-size="10" fill="#e9d5ff">Precisa de um relatório de análise de tendência geral.</text>
<text x="0" y="200" font-size="10" fill="#e9d5ff">Não é necessário compreender os dados brutos linha por linha.</text>
<rect x="0" y="214" width="194" height="26" rx="6" fill="#3b0764" stroke="#a855f7" stroke-width="1.5"/>
<text x="97" y="231" font-size="11" font-weight="bold" fill="#d8b4fe" text-anchor="middle">Consumo de Token: mínimo</text>
<line x1="0" y1="56" x2="194" y2="56" stroke="#f97316" stroke-width="1" opacity="0.5"/>
<text x="0" y="74" font-size="11" font-weight="bold" fill="#fdba74">Modelo recomendado</text>
<rect x="0" y="80" width="194" height="18" rx="4" fill="#431407"/>
<text x="8" y="93" font-size="9.5" fill="#fdba74">Gemini 2.0 Flash(1M ctx)</text>
<rect x="0" y="102" width="194" height="18" rx="4" fill="#431407"/>
<text x="8" y="115" font-size="9.5" fill="#fdba74">Gemini 1.5 Pro(1M janela de contexto)</text>
<rect x="0" y="124" width="194" height="18" rx="4" fill="#431407"/>
<text x="8" y="137" font-size="9.5" fill="#fdba74">Claude 3.5 Sonnet(200K)</text>
<line x1="0" y1="152" x2="194" y2="152" stroke="#f97316" stroke-width="1" opacity="0.5"/>
<text x="0" y="170" font-size="11" font-weight="bold" fill="#fdba74">Cenários de aplicação</text>
<text x="0" y="186" font-size="10" fill="#fed7aa">Volume de dados < 5000 linhas</text>
<text x="0" y="200" font-size="10" fill="#fed7aa">Capaz de arcar com custos de API mais altos</text>
<rect x="0" y="214" width="194" height="26" rx="6" fill="#431407" stroke="#f97316" stroke-width="1.5"/>
<text x="97" y="231" font-size="11" font-weight="bold" fill="#fdba74" text-anchor="middle">Custo: $1-5 / vez</text>
Solução A (Altamente Recomendado): Dados de Amostra + Deixar a AI Escrever o Script
Ideia Central: Em vez de deixar a AI processar todos os dados diretamente, a ideia é que a AI entenda a estrutura dos dados e, em seguida, gere um script de processamento para ser executado localmente.
Passos:
Primeiro Passo: Extrair dados de amostra (10 linhas são suficientes)
import pandas as pd
# Lê as primeiras 10 linhas como amostra (incluindo o cabeçalho)
df_sample = pd.read_excel("your_data.xlsx", nrows=10)
# Imprime em formato de texto para facilitar a cópia para a AI
print(df_sample.to_string())
print("\n--- Dados Gerais ---")
print(f"Número total de linhas: {len(pd.read_excel('your_data.xlsx'))}")
print(f"Nomes das colunas: {list(df_sample.columns)}")
print(f"Tipos de dados:\n{df_sample.dtypes}")
Segundo Passo: Enviar os dados de amostra e os requisitos para a AI
Exemplo de comando:
Abaixo estão as 10 primeiras linhas de amostra e a descrição da estrutura dos meus dados Excel:
[Colar o conteúdo da saída do passo anterior]
O total de dados tem 60 mil linhas. Preciso analisar o seguinte:
1. Estatísticas da taxa de conclusão do processo por departamento
2. Identificar nós de processo com tempo médio de processamento superior a 2 horas
3. Gerar relatório de tendências semanais
Por favor, escreva um script Python para mim que leia os dados completos e produza os resultados da análise.
Terceiro Passo: Executar o script gerado pela AI localmente
A AI, com base nas suas 10 linhas de dados de amostra, entenderá o significado dos campos e gerará um script de análise completo. Você executa este script localmente para processar todas as 60 mil linhas de dados. Todo o processo não exigirá mais a invocação da API da AI, resultando em consumo zero de tokens.
Vantagens da Solução:
- Consumo de tokens extremamente baixo (apenas 10 linhas de amostra ≈ algumas centenas de tokens)
- O script local pode ser executado repetidamente; basta rodar novamente após a atualização dos dados
- Adequado para cenários onde dados semelhantes precisam ser processados regularmente
🎯 Ferramenta Recomendada: Use a APIYI apiyi.com para invocar Claude 3.5 Sonnet ou GPT-4o para gerar scripts de processamento de dados. Modelos para tarefas de geração de código como esses têm um desempenho excelente, e uma única requisição geralmente consome menos de 2000 tokens, com um custo muito baixo.
Solução B: Processamento de Dados em Lotes
Cenários de Aplicação: O número de linhas de dados está entre 5.000 e 20.000, e a AI precisa entender o conteúdo de cada linha (como análise de sentimento, classificação de texto).
Passos:
import pandas as pd
def process_in_batches(file_path, batch_size=500):
"""Processa grandes arquivos Excel em lotes"""
df = pd.read_excel(file_path)
total_rows = len(df)
results = []
for start in range(0, total_rows, batch_size):
end = min(start + batch_size, total_rows)
batch = df.iloc[start:end]
# Converte este lote de dados para texto CSV e o envia para a AI processar
batch_text = batch.to_csv(index=False)
print(f"Processando linhas {start+1}-{end} (de um total de {total_rows} linhas)")
# Aqui, invocar a API da AI para processar batch_text
# result = call_ai_api(batch_text)
# results.append(result)
return results
Cada lote de 500 linhas consome aproximadamente 25.000-40.000 tokens. O custo total para processar 60.000 linhas de dados completos usando GPT-4o mini é de aproximadamente $0.5-1.5 USD.
Observações:
- Após cada lote ser processado, os resultados precisam ser consolidados; atente-se à precisão estatística entre os lotes
- O processamento em lotes pode perder relações entre linhas; é adequado para tarefas onde as linhas são independentes
Solução C: Pré-processar Dados Antes de Carregar
Cenários de Aplicação: A AI precisa analisar tendências gerais e escrever relatórios de análise, mas não precisa ver cada linha de dados brutos.
Passos:
Passo 1: Gerar um resumo dos dados usando tabelas dinâmicas do Excel ou Python
import pandas as pd
df = pd.read_excel("data.xlsx")
# Gerar estatísticas de resumo
summary = {
"Número total de linhas": len(df),
"Intervalo de tempo": f"{df['日期'].min()} até {df['日期'].max()}",
"Estatísticas por departamento": df.groupby('部门')['完成率'].mean().to_dict(),
"Tendência mensal": df.groupby(df['日期'].dt.month)['处理时长'].mean().to_dict(),
"Quantidade de dados anormais": len(df[df['处理时长'] > 120])
}
# Converte o resumo para texto estruturado e o envia para a AI escrever o relatório de análise
import json
print(json.dumps(summary, ensure_ascii=False, indent=2))
Passo 2: Enviar os dados de resumo para a AI escrever o relatório de análise
Os dados de resumo geralmente têm apenas algumas centenas de linhas, e enviá-los para a AI consome muito poucos tokens, mas permite que a AI gere uma análise de tendências completa e relatórios de insights de negócios.
Solução D: Escolher Modelo de Linguagem Grande com Janela de Contexto Grande
Cenários de Aplicação: Realmente é necessário que a AI entenda o conteúdo semântico de todos os dados, e você está disposto a arcar com custos mais altos.
| Modelo | Janela de Contexto Máxima | Volume de Dados Adequado | Custo Estimado |
|---|---|---|---|
| Gemini 1.5 Pro | 1 milhão de tokens | Aprox. 20-30 mil linhas | Faturamento por uso via APIYI |
| Gemini 2.0 Flash | 1 milhão de tokens | Aprox. 20-30 mil linhas | Melhor custo-benefício |
| Claude 3.5 Sonnet | 200 mil tokens | Aprox. 3000-5000 linhas | Qualidade de geração de código excelente |
💡 Mesmo usando um Modelo de Linguagem Grande com janela de contexto grande, é altamente recomendável limpar os dados primeiro (excluir linhas vazias, mesclar colunas duplicadas, remover campos irrelevantes) para reduzir o consumo de tokens e evitar atingir limites de pré-pagamento.
🎯 Vantagem da Interface Unificada: Através da plataforma APIYI apiyi.com, você pode usar uma interface de API unificada para invocar vários modelos de linguagem grande com janela de contexto grande, como Gemini, Claude e GPT, sem a necessidade de registrar uma conta separada para cada modelo, facilitando a troca rápida e a comparação de custos.
4. Como evitar cair na mesma armadilha novamente
Depois de dominar as soluções acima, aqui estão algumas das melhores práticas para usar IA no processamento de dados no dia a dia.
<!-- Arrow -->
<line x1="182" y1="38" x2="182" y2="52" stroke="#ef4444" stroke-width="1.5" stroke-dasharray="4,3"/>
<polygon points="176,50 188,50 182,56" fill="#ef4444"/>
<!-- Step 2 -->
<rect x="0" y="56" width="364" height="38" rx="7" fill="#2d1414" stroke="#ef4444" stroke-width="1"/>
<text x="22" y="70" font-size="11" font-weight="bold" fill="#fca5a5">📊 Aumento massivo de tokens: ≈ 3 milhões de tokens2. Análise de dados pela IA</text>
<text x="22" y="86" font-size="10" fill="#ef4444">60.000 linhas × 10 colunas × 5 tokens ≈ 3.000.000 tokens(Consome muitos tokens)</text>
<!-- Arrow -->
<line x1="182" y1="94" x2="182" y2="108" stroke="#ef4444" stroke-width="1.5" stroke-dasharray="4,3"/>
<polygon points="176,106 188,106 182,112" fill="#ef4444"/>
<!-- Step 3 -->
<rect x="0" y="112" width="364" height="38" rx="7" fill="#3d0808" stroke="#dc2626" stroke-width="2"/>
<text x="22" y="126" font-size="12" font-weight="bold" fill="#ff6b6b">💥 Erro de API 402: Saldo insuficiente3. Resultado insatisfatório, reajustar o comando</text>
<text x="22" y="142" font-size="10" fill="#fca5a5">Retenção $9.00 > Saldo da conta $5.20 → Solicitação falhou(Consumo repetitivo de tokens, custo disparado)</text>
<!-- Problem stats -->
<rect x="0" y="162" width="174" height="54" rx="7" fill="#1a0505" stroke="#ef4444" stroke-width="1"/>
<text x="87" y="180" font-size="10" fill="#fca5a5" text-anchor="middle">Consumo de tokensTaxa de Sucesso</text>
<text x="87" y="202" font-size="22" font-weight="bold" fill="#ef4444" text-anchor="middle">3 milhõesBaixa</text>
<rect x="186" y="162" width="178" height="54" rx="7" fill="#1a0505" stroke="#ef4444" stroke-width="1"/>
<text x="275" y="180" font-size="10" fill="#fca5a5" text-anchor="middle">Resultado da análiseEficiência</text>
<text x="275" y="202" font-size="18" font-weight="bold" fill="#ef4444" text-anchor="middle">❌ Não foi possível concluirLenta</text>
<!-- Cost label -->
<rect x="0" y="228" width="364" height="28" rx="6" fill="#2d0808" stroke="#dc2626" stroke-width="1.5"/>
<text x="182" y="246" font-size="12" font-weight="bold" fill="#ff6b6b" text-anchor="middle">Custo estimado: $7.5+ · e excedeu o limite da janela de contextoCusto Total: Alto e Incontrolável</text>
<!-- Arrow -->
<line x1="182" y1="38" x2="182" y2="52" stroke="#10b981" stroke-width="1.5" stroke-dasharray="4,3"/>
<polygon points="176,50 188,50 182,56" fill="#10b981"/>
<!-- Step 2 -->
<rect x="0" y="56" width="364" height="38" rx="7" fill="#022c22" stroke="#10b981" stroke-width="1"/>
<text x="22" y="70" font-size="11" font-weight="bold" fill="#6ee7b7">🤖 AI entende a estrutura, gera scripts Python de análise2. IA gera script de processamento</text>
<text x="22" y="86" font-size="10" fill="#34d399">Consome cerca de 1.500-2.000 tokens para gerar o script.(Consome poucos tokens)</text>
<!-- Arrow -->
<line x1="182" y1="94" x2="182" y2="108" stroke="#10b981" stroke-width="1.5" stroke-dasharray="4,3"/>
<polygon points="176,106 188,106 182,112" fill="#10b981"/>
<!-- Step 3 -->
<rect x="0" y="112" width="364" height="38" rx="7" fill="#064e3b" stroke="#059669" stroke-width="2"/>
<text x="22" y="126" font-size="12" font-weight="bold" fill="#34d399">🚀 Execute o script localmente para processar 60 mil linhas de dados completas3. Executar script localmente para processar todos os dados</text>
<text x="22" y="142" font-size="10" fill="#a7f3d0">O script é executado localmente, e os resultados são salvos em analysis.xlsx.(Não consome tokens, reutilizável)</text>
<!-- Success stats -->
<rect x="0" y="162" width="174" height="54" rx="7" fill="#021a0d" stroke="#10b981" stroke-width="1"/>
<text x="87" y="180" font-size="10" fill="#6ee7b7" text-anchor="middle">Consumo de TokenTaxa de Sucesso</text>
<text x="87" y="202" font-size="22" font-weight="bold" fill="#34d399" text-anchor="middle">~2000Alta</text>
<rect x="186" y="162" width="178" height="54" rx="7" fill="#021a0d" stroke="#10b981" stroke-width="1"/>
<text x="275" y="180" font-size="10" fill="#6ee7b7" text-anchor="middle">Resultado da análiseEficiência</text>
<text x="275" y="202" font-size="18" font-weight="bold" fill="#34d399" text-anchor="middle">✅ Completo e precisoRápida</text>
<!-- Cost label -->
<rect x="0" y="228" width="364" height="28" rx="6" fill="#064e3b" stroke="#059669" stroke-width="1.5"/>
<text x="182" y="246" font-size="12" font-weight="bold" fill="#34d399" text-anchor="middle">Custo real: < $0.01 · O script pode ser reutilizado repetidamenteCusto Total: Baixo e Controlável</text>
Método de Estimativa de Tokens Antes do Uso
Antes de fazer o upload de um arquivo, você pode usar o método a seguir para estimar rapidamente a quantidade de tokens:
import pandas as pd
def estimate_tokens(file_path):
"""Estima aproximadamente o número de tokens de um arquivo Excel após conversão para texto"""
df = pd.read_excel(file_path)
# Converte os dados para texto CSV
csv_text = df.to_csv(index=False)
# Estimativa aproximada: inglês ~4 caracteres/token, chinês ~1.5 caracteres/token
char_count = len(csv_text)
estimated_tokens = char_count / 3.5 # Média para mistura de chinês e inglês
print(f"Número de linhas do arquivo: {len(df)}")
print(f"Número de colunas do arquivo: {len(df.columns)}")
print(f"Número de caracteres CSV: {char_count:,}")
print(f"Número de Tokens estimado: {estimated_tokens:,.0f}")
print(f"Custo estimado (calculado com GPT-4o, $2.5/1M): ${estimated_tokens/1_000_000*2.5:.4f}")
if estimated_tokens > 100_000:
print("⚠️ Aviso: Quantidade de tokens excede 100 mil, sugere-se usar a Abordagem A (amostra + script)")
estimate_tokens("your_data.xlsx")
Tabela de Erros Comuns e Soluções
| Fenômeno do Erro | Causa Raiz | Solução |
|---|---|---|
| "Saldo insuficiente" é reportado, mas há saldo | Pré-dedução de tokens excede o saldo da conta | Recarregar saldo OU usar a Abordagem A/C |
| Resposta muito lenta ou timeout | Muitos tokens de entrada, tempo de inferência longo | Reduzir a quantidade de dados de entrada |
| Resultados da análise da IA imprecisos | Grande volume de dados, efeito "lost-in-the-middle" | Simplificar dados, usar processamento em lotes |
| A API reporta "context length exceeded" | Excedeu a janela de contexto máxima do modelo | Usar um Modelo de Linguagem Grande com janela de contexto maior OU processamento em lotes |
| Custo muito alto a cada vez | Grande volume de dados sendo carregado repetidamente | Usar a Abordagem A para gerar um script local reutilizável |
Cinco: Exercício Prático: Análise de 60 mil linhas de dados de processo
Abaixo, um caso de negócio completo para demonstrar todo o processo, desde os desafios até a solução.
Contexto: A equipe de operações possui um arquivo com 60 mil linhas de dados de eficiência de processos, contendo campos como: departamento, nome do processo, hora de início, hora de término, responsável e status de conclusão. O objetivo é que a IA analise quais nós de processo têm a menor eficiência.
Passo 1: Extrair Amostra
import pandas as pd
# Ler as primeiras 10 linhas
df = pd.read_excel("process_data.xlsx", nrows=10)
print("=== Amostra de Dados (primeiras 10 linhas) ===")
print(df.to_string())
print("\n=== Descrição dos Campos ===")
for col in df.columns:
print(f"- {col}: {df[col].dtype}, Valor de exemplo: {df[col].iloc[0]}")
Passo 2: Enviar para a IA e Obter o Script de Análise
Envie o conteúdo da saída acima para a IA, juntamente com a descrição dos requisitos:
Abaixo está a estrutura e 10 linhas de amostra dos meus dados de processo do Excel:
[Colar conteúdo da saída]
Requisitos:
1. Calcular o tempo médio de processamento para cada "nome do processo" (hora de término - hora de início)
2. Estatísticas da taxa de conclusão do processo por departamento (proporção de "status de conclusão" = "Concluído")
3. Encontrar os 10 processos com o maior tempo médio de processamento e gerar uma tabela
4. Salvar os resultados em analysis_result.xlsx
Por favor, escreva um script Python completo e executável.
Passo 3: Executar o Script Localmente
A IA gerará um script de análise semelhante ao seguinte (versão simplificada de exemplo):
import pandas as pd
# Ler os dados completos
df = pd.read_excel("process_data.xlsx")
# Calcular o tempo de processamento (minutos)
df['处理时长_分钟'] = (
pd.to_datetime(df['结束时间']) - pd.to_datetime(df['开始时间'])
).dt.total_seconds() / 60
# Estatísticas do tempo médio por processo
process_avg = (
df.groupby('流程名称')['处理时长_分钟']
.agg(['mean', 'count'])
.rename(columns={'mean': '平均时长', 'count': '总次数'})
.sort_values('平均时长', ascending=False)
)
# Estatísticas da taxa de conclusão por departamento
dept_completion = (
df.groupby('部门')['完成状态']
.apply(lambda x: (x == '完成').mean() * 100)
.round(2)
.rename('完成率%')
)
# Imprimir os 10 processos mais lentos
print("=== Os 10 nós de processo mais demorados ===")
print(process_avg.head(10).to_string())
# Salvar resultados
with pd.ExcelWriter("analysis_result.xlsx") as writer:
process_avg.to_excel(writer, sheet_name="流程效率分析")
dept_completion.to_excel(writer, sheet_name="部门完成率")
print("\n✅ Resultados da análise salvos em analysis_result.xlsx")
Comparativo de Consumo de Tokens para o Processo Completo:
| Método | Consumo de Tokens | Custo Estimado (GPT-4o) | Qualidade da Análise |
|---|---|---|---|
| Upload direto de 60 mil linhas | ~3 milhões de tokens | $7.5+ e excede a janela de contexto | Não é possível concluir |
| Plano A (amostra + script) | ~2000 tokens | < $0.01 | Completo e preciso |
🎯 Comparativo de custos: O consumo do Plano A é menos de 0,1% do método de upload direto, e os resultados da análise são mais precisos e reutilizáveis. Recomendamos usar APIYI apiyi.com para invocar GPT-4o ou Claude 3.5 Sonnet para gerar scripts de processamento de dados, com excelentes resultados e custos extremamente baixos.
Seis: Perguntas Frequentes (FAQ)
P1: Não tenho conhecimento básico de Python, posso usar esta solução?
Com certeza. O cerne do Plano A é "deixar a IA escrever o script, e você o executa". Você só precisa:
- Instalar Python (site oficial: python.org, basta seguir os passos)
- Instalar pandas: No terminal, digite
pip install pandas openpyxl - Extrair dados de amostra para a IA → A IA gera o script → Salvar como arquivo
.py→ Clicar duas vezes para executar
Para usuários menos familiarizados com a linha de comando, também é possível usar o Jupyter Notebook (incluído no pacote de instalação do Anaconda), que é mais intuitivo.
💡 No APIYI apiyi.com, você também pode usar o recurso de interpretador de código integrado, permitindo que a IA gere e valide a lógica do script diretamente, reduzindo o tempo de depuração.
P2: Além do Python, existem outras maneiras de processar grandes volumes de dados?
Sim, as seguintes opções são listadas por ordem de facilidade de uso:
- Recursos Integrados do Excel: Tabela dinâmica + Power Query, sem necessidade de programação, ideal para estatísticas agregadas.
- Python pandas: Mais flexível, alta eficiência de processamento, recomendado para usuários intermediários a avançados.
- Microsoft Copilot (plugin do Excel): Analisa diretamente com a IA dentro do Excel, mas ainda possui limites de linhas.
- Ferramentas Profissionais de Análise de Dados: Tableau, Power BI conectam-se a fontes de dados, com forte capacidade de processamento de grandes volumes de dados.
P3: Qual o saldo de conta adequado para evitar erros de pré-autorização?
Isso depende do seu cenário de uso diário. Geralmente, sugere-se:
- Usuários de conversação comuns: Manter saldo de $5-20
- Usuários de processamento de dados (upload ocasional de arquivos): Manter saldo de $20-50
- Invocação de API de alta frequência: Recomenda-se configurar recarga automática ou manter saldo de $100+
🎯 Gestão de Saldo: No console do APIYI apiyi.com, você pode visualizar os detalhes de consumo de tokens, configurar alertas de uso para evitar que a falta de saldo afete as operações. A plataforma suporta recargas sob demanda, sem requisitos de consumo mínimo.
P4: Meus dados envolvem privacidade, posso enviar dados de amostra para a IA?
As práticas recomendadas são:
- Anonimizar antes de enviar para a IA: Substituir campos sensíveis como nome, número de telefone, RG por valores de exemplo (como "João Silva" → "Usuário A").
- Fornecer apenas nomes de campos e tipos de dados: Não fornecer valores específicos, apenas informar à IA a estrutura e os tipos de dados dos campos.
- Solução de Modelo Local: Usar Ollama para executar modelos locais (como Qwen2.5), garantindo que os dados nunca saiam da sua máquina.
Resumo
O erro mais comum ao processar grandes volumes de dados Excel com IA é fazer o upload do arquivo completo, o que leva a uma explosão de tokens, erros de API e custos descontrolados. A ideia central para resolver isso é simples:
Deixe a IA "ver uma amostra, escrever um script", em vez de "ver o todo, fazer o cálculo".
Visão geral dos cenários de aplicação para as quatro soluções:
| Cenário | Solução Recomendada | Dificuldade |
|---|---|---|
| Volume de dados > 10 mil linhas, requer análise estatística | Solução A: Amostra + Script | ⭐⭐ (requer execução de Python) |
| Volume de dados 5 mil a 20 mil linhas, requer compreensão linha a linha | Solução B: Processamento em lotes | ⭐⭐⭐ (requer chamada de API) |
| Apenas relatório de tendências, não requer análise linha a linha | Solução C: Resumo pré-processado | ⭐ (apenas com Excel) |
| Volume de dados < 5 mil linhas, custos mais altos são aceitáveis | Solução D: Modelo com janela de contexto ampla | ⭐ (upload direto) |
Experimente a Solução A agora: Extraia as 10 primeiras linhas do seu Excel, selecione GPT-4o ou Claude 3.5 Sonnet em APIYI apiyi.com, diga à IA suas necessidades de análise e deixe-a gerar o script de processamento — a maioria das tarefas de análise de dados pode ser resolvida por menos de $0.01.
🎯 Comece rapidamente: Acesse APIYI apiyi.com, registre-se e experimente diversos modelos populares. Suporta chamadas unificadas de API para OpenAI, Claude, Gemini, entre outros. A cobrança é feita pelo consumo real, sem mensalidades ou consumo mínimo. Ideal para equipes de negócios e usuários individuais que precisam lidar com diversas tarefas de análise de dados.
Este artigo foi compilado pela equipe técnica da APIYI, com base em feedback real de usuários e experiência prática. Se tiver dúvidas ou sugestões, entre em contato conosco via apiyi.com.