Nota do autor: Analisamos o desempenho do Claude Opus 4.6 e da versão Thinking, que conquistaram simultaneamente o topo dos rankings de Texto e Código no Arena.ai, e mostramos como acessar a API do Claude Opus 4.6 via APIYI com 20% de desconto e alta concorrência sem limites de velocidade.
Os dados mais recentes do ranking Arena.ai foram divulgados — a série Claude Opus 4.6 ocupou as duas primeiras posições nos rankings de Texto e Código. No ranking de Texto, o claude-opus-4-6-thinking alcançou o topo com 1502 pontos, seguido de perto pelo claude-opus-4-6 com 1501 pontos; no ranking de Código, o claude-opus-4-6 garantiu o primeiro lugar com 1548 pontos, com a Anthropic ocupando quatro das cinco primeiras posições. Esta é uma dominação dupla raramente vista em competições de Modelos de Linguagem Grande. Este artigo analisa esses dados e apresenta como acessar este modelo de ponta com 20% de desconto através da APIYI.
Valor central: Entenda a posição dominante do Claude Opus 4.6 nos rankings autoritários do setor e a forma mais econômica de realizar a invocação do modelo via API.
![]()
title: "Análise dos dados do ranking Arena do Claude Opus 4.6"
Análise dos dados do ranking Arena do Claude Opus 4.6
A Arena.ai (antiga LMSYS Chatbot Arena) é uma das plataformas terceirizadas mais respeitadas para avaliação de modelos de IA. Ela utiliza um mecanismo de votação cega por humanos, onde os usuários testam dois modelos anônimos lado a lado e votam no melhor, culminando em um ranking baseado no sistema de pontuação Elo.
Dados do ranking de texto do Claude Opus 4.6
| Posição | Modelo | Pontuação | Votos | Fabricante |
|---|---|---|---|---|
| 1 | claude-opus-4-6-thinking | 1502 | 11.801 | Anthropic |
| 2 | claude-opus-4-6 | 1501 | 12.546 | Anthropic |
| 3 | gemini-3.1-pro-preview | 1493 | 14.677 | |
| 4 | grok-4.20-beta1 | 1492 | 7.396 | xAI |
| 5 | gemini-3-pro | 1486 | 41.762 | |
| 6 | gpt-5.4-high | 1485 | 4.965 | OpenAI |
As duas versões do Claude Opus 4.6 (padrão e Thinking) ocupam o topo com 1502 e 1501 pontos, superando o terceiro colocado, Gemini 3.1 Pro, por 9 pontos. No sistema Elo, essa diferença representa uma vantagem de vitória de cerca de 55-57% — uma liderança sólida e confiável.
Dados do ranking de código do Claude Opus 4.6
| Posição | Modelo | Pontuação | Votos | Fabricante |
|---|---|---|---|---|
| 1 | claude-opus-4-6 | 1548 | 4.059 | Anthropic |
| 2 | claude-opus-4-6-thinking | 1546 | 3.317 | Anthropic |
| 3 | claude-sonnet-4-6 | 1521 | 5.876 | Anthropic |
| 4 | claude-opus-4-5-20251101 | 1489 | 13.259 | Anthropic |
| 5 | claude-opus-4-5-20251101 | 1465 | 13.313 | Anthropic |
| 6 | gpt-5.4-high (codex-harne…) | 1457 | 1.486 | OpenAI |
Os dados do ranking de código são ainda mais impressionantes: os cinco primeiros lugares são todos modelos Claude da Anthropic. O Claude Opus 4.6 lidera com 1548 pontos, superando o GPT-5.4 High em 91 pontos — o que, no sistema Elo, significa uma vantagem de vitória próxima de 63%, uma liderança avassaladora.
🎯 Análise do ranking: A vantagem do Claude Opus 4.6 em capacidade de codificação é muito maior do que em tarefas de texto. Isso explica por que o Claude Code domina o mercado de agentes de programação — a capacidade de código do modelo base é, sem dúvida, a número um.
Através da APIYI (apiyi.com), você pode acessar este modelo poderoso com 12% de desconto.
Por que o Claude Opus 4.6 lidera ambos os rankings
Vantagens técnicas centrais do Claude Opus 4.6
O sucesso do Claude Opus 4.6 nos dois rankings deve-se à estratégia de foco computacional da Anthropic: 100% das GPUs são dedicadas à inferência de modelos, sem dispersão para geração de imagens ou vídeos.
| Dimensão de capacidade | Claude Opus 4.6 | Comparação com concorrentes |
|---|---|---|
| SWE-bench | 80,8% (correção de código) | GPT-5.4 aprox. 75% |
| ARC-AGI-2 | 68,8% (raciocínio) | Lidera modelos do mesmo período |
| MRCR v2 (1M) | 76% (recuperação de contexto longo) | Sonnet 4.5 apenas 18,5% |
| BigLaw Bench | 90,2% (raciocínio jurídico) | O mais alto da série Claude |
| Terminal-Bench 2.0 | 65,4% (operação de terminal) | Líder do setor |
| Janela de contexto | 1M tokens (sem custo extra) | Uma das maiores do setor |
| Saída máxima | 128K tokens | A mais alta do setor |
Claude Opus 4.6: Versão Padrão vs. Versão Thinking
Podemos observar um fenômeno interessante no ranking da Arena:
- Ranking de texto: A versão Thinking leva uma leve vantagem (1502 vs 1501) — o raciocínio profundo traz um pequeno benefício em tarefas textuais.
- Ranking de código: A versão padrão leva uma leve vantagem (1548 vs 1546) — em tarefas de codificação, a resposta direta pode ser mais precisa.
A diferença é mínima (1-2 pontos), o que mostra que a capacidade básica do Claude Opus 4.6 já é robusta o suficiente. O modo Thinking traz ganhos limitados, pois o modelo já "pensa" nativamente, não necessitando sempre de um modo de raciocínio explícito.
![]()
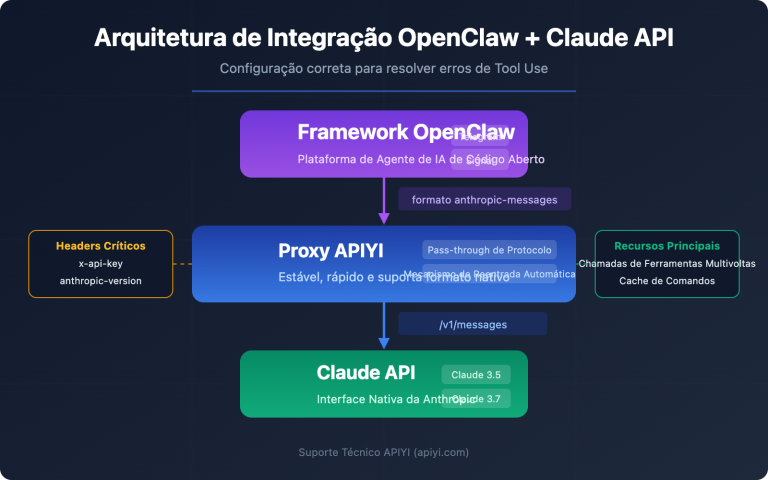
Guia de início rápido: Integrando o Claude Opus 4.6 via APIYI
Exemplo minimalista: Integre o modelo líder do ranking com apenas 3 linhas de código
import openai
client = openai.OpenAI(
api_key="SUA_CHAVE_API", # Obtenha em apiyi.com
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-6", # Código #1 no ranking Arena
messages=[
{"role": "user", "content": "Analise os gargalos de desempenho deste código e sugira otimizações"}
],
max_tokens=16000
)
print(response.choices[0].message.content)
Ver código de invocação para a versão Thinking
import openai
client = openai.OpenAI(
api_key="SUA_CHAVE_API",
base_url="https://vip.apiyi.com/v1"
)
# Usando a versão Thinking (Texto #1 no ranking Arena)
response = client.chat.completions.create(
model="claude-opus-4-6-thinking",
messages=[
{"role": "user", "content": "Projete uma arquitetura de sistema de fila de mensagens de alta concorrência"}
],
max_tokens=32000
)
print(response.choices[0].message.content)
A versão Thinking realiza um raciocínio mais profundo internamente, sendo ideal para design de arquiteturas complexas, deduções matemáticas e tarefas de análise profunda.
Recomendação de uso: Use
claude-opus-4-6(Código #1) para tarefas gerais de programação eclaude-opus-4-6-thinking(Texto #1) para tarefas de raciocínio complexo. A APIYI (apiyi.com) suporta ambos os modelos com um desconto unificado de 12% (0,88).
Cálculo de preços do Claude Opus 4.6 na APIYI
Detalhes das vantagens de preço do Claude Opus 4.6 na APIYI
| Item de cobrança | Preço oficial Anthropic | Preço APIYI (12% de desc.) | Após bônus de recarga |
|---|---|---|---|
| Token de entrada | $5.00/M | $4.40/M | ~$4.00/M |
| Token de saída | $25.00/M | $22.00/M | ~$20.00/M |
| Escrita em cache | $6.25/M | $5.50/M | ~$5.00/M |
| Hit de cache | $0.50/M | $0.44/M | ~$0.40/M |
Cálculo de bônus de recarga:
- Recarregue $100, ganhe $10, saldo real de $110.
- Desconto de grupo de 0,88 + bônus de recarga de 10% → Desconto total de aproximadamente 0,80 (20% de desconto sobre o oficial).
- O mesmo volume de chamadas custa 20% menos do que a chamada direta oficial.
Por que a APIYI consegue oferecer o Claude Opus 4.6 a um preço menor?
A APIYI colabora com o AWS Claude, acessando os modelos via AWS Bedrock. O desconto de volume da AWS somado à eficiência operacional da APIYI resulta na vantagem de preço para o usuário. A versão e a qualidade do modelo são exatamente as mesmas da oficial; não se trata de uma versão reduzida ou canal alternativo.
🎯 Dica de custo: Se o seu gasto mensal com a API do Claude ultrapassa $100, integrar via APIYI (apiyi.com) pode economizar mais de $20 por mês. Quanto maior o projeto, maior a economia. Registre-se e ganhe créditos gratuitos para testar antes de decidir.
Perguntas Frequentes
Q1: Existe diferença entre o Claude Opus 4.6 da APIYI e a chamada oficial direta?
O modelo é exatamente o mesmo — a APIYI conecta-se ao Claude através do canal oficial da AWS Bedrock, não se tratando de canais de terceiros, engenharia reversa ou versões reduzidas. A versão do modelo, a capacidade de raciocínio e a qualidade da saída são idênticas às do site oficial da Anthropic. A única diferença é o método de acesso: a APIYI fornece um formato compatível com OpenAI; basta alterar uma linha no base_url para conectar, sem a necessidade de registrar uma conta na Anthropic ou configurar credenciais da AWS.
Q2: Como o desconto de 0,88 é calculado? Ele pode ser acumulado com bônus de recarga?
Sim, pode ser acumulado. O preço de grupo de 0,88 é o desconto base, aplicado a todas as solicitações do Claude Opus 4.6. A recarga de $100 com bônus de $10 é uma oferta adicional; quando combinados, o desconto total é de aproximadamente 80% em relação ao site oficial. Exemplo: um volume de uso que custaria $100 no site oficial, na APIYI custará efetivamente cerca de $80.
Q3: O que significa exatamente “alta concorrência sem limite de velocidade”?
A API oficial da Anthropic possui limites de taxa rigorosos (RPM e TPM), que variam conforme o nível (Tier) e exigem solicitação de aumento. A APIYI não possui essas restrições — você pode enviar qualquer número de solicitações simultâneas conforme sua necessidade, sendo ideal para processamento de dados em lote, testes automatizados e cenários de aplicações corporativas.
Q4: O mecanismo de pontuação do ranking Arena é confiável?
O Arena.ai (anteriormente LMSYS Chatbot Arena) é atualmente uma das plataformas de avaliação de terceiros mais reconhecidas na comunidade de IA. Ele utiliza votação cega por humanos — os usuários utilizam dois modelos anônimos simultaneamente e votam no que consideram melhor, evitando o viés de marca. O sistema de pontuação Elo acumulou dezenas de milhares de votos, garantindo alta confiabilidade estatística. O número de votos do Claude Opus 4.6 (12.546 votos no ranking de Texto e 4.059 votos no de Código) também fornece um tamanho de amostra suficiente.
Resumo
Informações principais sobre a liderança do Claude Opus 4.6 no ranking Arena:
- Primeiro lugar nos rankings de Texto e Código: O
claude-opus-4-6-thinkingconquistou o primeiro lugar no ranking de Texto (1502 pontos), e oclaude-opus-4-6conquistou o primeiro lugar no ranking de Código (1548 pontos); os cinco primeiros colocados no ranking de Código são todos modelos da Anthropic. - Vantagem expressiva em capacidade de código: No ranking de Código, o Claude Opus 4.6 supera o GPT-5.4 por uma margem de 91 pontos (Elo), consolidando sua dominância indiscutível na área de programação.
- APIYI oferece a melhor forma de acesso: Desconto de 0,88 + 10% de bônus na recarga = desconto total de 20%. Qualidade garantida pela parceria com a AWS, alta concorrência sem limites e formato compatível com OpenAI para integração com apenas uma linha de código.
Recomendamos acessar o Claude Opus 4.6, líder do ranking, através da APIYI em apiyi.com — registre-se para ganhar créditos gratuitos e aproveite o bônus de $10 a cada $100 recarregados, obtendo facilmente um desconto de 20% em relação ao site oficial.
📚 Referências
-
Ranking Arena.ai: Classificação independente e cega de modelos de IA
- Link:
arena.ai/leaderboard - Descrição: Ranking em tempo real com múltiplas dimensões, como texto e código.
- Link:
-
Apresentação oficial do Claude Opus 4.6: Comunicado de lançamento da Anthropic
- Link:
anthropic.com/news/claude-opus-4-6 - Descrição: Inclui dados de testes de referência e detalhes técnicos.
- Link:
-
Análise de desempenho do Claude Opus 4.6: Análise profunda de agência de avaliação independente
- Link:
artificialanalysis.ai/models/claude-opus-4-6-adaptive - Descrição: Contém dados de latência, throughput e comparação de preços.
- Link:
-
Central de Documentação APIYI: Guia de integração da API do Claude Opus 4.6
- Link:
docs.apiyi.com - Descrição: Inclui tutoriais de integração, informações de preços e exemplos de código.
- Link:
Autor: Equipe técnica da APIYI
Troca técnica: Sinta-se à vontade para discutir na seção de comentários. Para mais materiais, visite a central de documentação da APIYI em docs.apiyi.com.
![]()