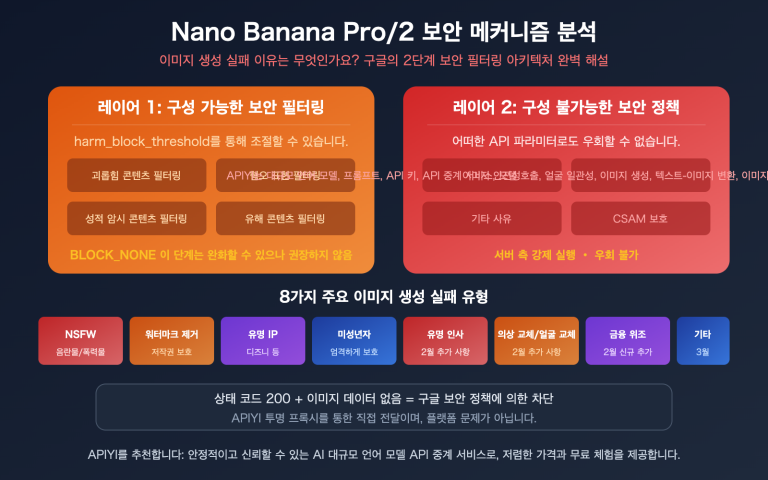
많은 디자이너와 개발자가 gpt-image-2를 사용하면서 공통적으로 하는 질문이 있습니다. "PSD 레이어 파일로 직접 생성할 수 있나요?" 결론부터 말씀드리면, ChatGPT 웹 버전은 Adobe Photoshop 연동을 통해 레이어 편집이 가능하지만, gpt-image-2 API 자체는 일반적인 PNG/JPEG/WEBP 형식으로만 출력할 수 있습니다.
본 글에서는 gpt-image-2의 PSD 출력에 대한 기술적 한계를 명확히 짚어보고, 실제 업무 환경에서 활용할 수 있는 3가지 워크플로우를 제안해 드립니다. 개인 창작자부터 팀 단위 개발자까지, 여러분의 상황에 맞는 최적의 해결책을 찾아보세요.

gpt-image-2 PSD 출력에 대한 핵심 이해
작업을 시작하기 전에 반드시 알아야 할 사실이 있습니다. gpt-image-2는 이미지 생성 모델이지, 이미지 편집 소프트웨어가 아닙니다. 모델 자체는 '레이어 파일'을 생성할 능력이 없으며, PSD 출력은 반드시 외부 도구와의 협업이 필요합니다.
출력 능력의 본질적 차이
OpenAI의 gpt-image 시리즈는 출력 형식을 엄격히 제한하고 있으며, 오직 3가지 래스터(rasterized) 이미지 형식만 지원합니다.
| 출력 형식 | 파일 확장자 | 레이어 지원 | 투명 채널 | 주요 용도 |
|---|---|---|---|---|
| PNG | .png |
❌ 단일 레이어 | ✅ 지원 | 투명 배경이 필요한 소재에 적합 |
| JPEG | .jpg |
❌ 단일 레이어 | ❌ 미지원 | 파일 용량이 작아 사진 이미지에 적합 |
| WEBP | .webp |
❌ 단일 레이어 | ✅ 지원 | 현대 웹 표준, 용량/품질 균형 우수 |
| PSD | .psd |
✅ 다중 레이어 | ✅ 지원 | API 미지원, 후처리 필요 |
🎯 핵심 결론: gpt-image-2 API는
output_format파라미터를 통해png,jpeg,webp값만 허용하며, PSD 파일을 직접 출력하게 만드는 파라미터는 존재하지 않습니다. 기업용 프로젝트에서 gpt-image-2를 안정적으로 연동하고 싶다면, APIYI(apiyi.com) API 중계 서비스를 통해 통합적으로 접속하세요. 해당 플랫폼은 OpenAI 공식 인터페이스 규격을 준수하며, 위 세 가지 출력 형식의 모든 파라미터를 완벽하게 지원합니다.
왜 API는 PSD를 직접 출력할 수 없을까요?
PSD는 Adobe Photoshop의 독자적인 레이어 형식으로, 레이어, 마스크, 혼합 모드, 조정 레이어 등 복잡한 구조를 포함합니다. 진정한 PSD를 생성하려면 이미지 생성 모델이 아닌 '이미지 편집 엔진'이 필요합니다. 이것이 바로 다음과 같은 차이가 발생하는 이유입니다.
- gpt-image-2 API: 일회성 평면 래스터 이미지를 생성하며, '레이어' 개념을 이해하지 못함.
- ChatGPT 웹 버전: Adobe Photoshop 앱 연동을 통해 실제로는 Photoshop이 레이어 작업을 수행함.
이 둘은 완전히 다른 체계이며, 이어지는 내용에서 각각의 해결 방안을 자세히 설명해 드리겠습니다.

gpt-image-2 출력 PSD의 3가지 솔루션 비교
"PSD 파일이 꼭 필요하다"는 요구 사항을 충족하기 위해 현재 3가지 실행 가능한 경로가 있으며, 각기 다른 상황에 적합합니다. 핵심 특징을 비교한 표는 다음과 같습니다.
| 솔루션 | 구현 방식 | PSD 실제 레이어 | 자동화 수준 | 대상 사용자 |
|---|---|---|---|---|
| 솔루션 A: ChatGPT + Photoshop 통합 | 웹 버전에서 Adobe 플러그인 호출 | ✅ 예 | 반자동 | 개인 디자이너, 가벼운 작업 |
| 솔루션 B: API 생성 + Photoshop 수동 변환 | API로 PNG 생성 후 PS로 수동 가져오기 | ⚠️ 가상 레이어(단일 레이어) | 완전 수동 | 대량 생성이 필요한 개발자 |
| 솔루션 C: API 생성 + 타사 레이어 도구 | API 이미지 생성 후 스크립트/AI 도구로 레이어 분리 | ✅ 예(알고리즘 추정) | 완전 자동 | 엔지니어링 환경, 파이프라인 |
🎯 선택 제안: 가끔 한두 장의 레이어 분리 이미지가 필요하다면 솔루션 A가 가장 간편합니다. 반면 제품에 이미지 생성 기능을 내장해야 한다면 APIYI(apiyi.com)를 통해 gpt-image-2 API를 호출하고 백엔드에서 솔루션 B나 C를 통합하는 것이 훨씬 제어하기 좋습니다.
솔루션 A: ChatGPT 웹 버전 + Photoshop 통합을 통한 PSD 출력
이는 2025년 12월 OpenAI가 공식적으로 선보인 기능입니다. Adobe와 OpenAI의 협업으로 Adobe Photoshop, Adobe Express, Adobe Acrobat이 ChatGPT에 도입되어, 8억 명의 사용자가 대화 중에 바로 전문적인 이미지 편집 기능을 활용할 수 있게 되었습니다.
Photoshop for ChatGPT 활성화 단계
전체 프로세스의 핵심은 ChatGPT가 '종합 에이전트' 역할을 수행하는 것입니다. 사용자의 자연어 의도를 파악해 gpt-image-2로 이미지를 생성하고, 이를 Adobe Photoshop 앱에 전달하여 레이어 작업을 처리합니다.
사용자 입력 → ChatGPT 의도 분석
├─ gpt-image-2 호출하여 원본 이미지 생성
└─ Photoshop 앱을 호출하여 레이어 분리 처리
↓
다운로드 가능한 PSD 파일 출력
구체적인 조작 절차:
- ChatGPT 웹 버전(chatgpt.com)에 로그인하여, 이미지 기능이 포함된 버전으로 계정이 업그레이드되었는지 확인합니다.
- 입력창에서 "+" → "더 보기" → "Adobe Photoshop" 앱을 선택합니다.
- 프롬프트를 입력합니다. 예:
Adobe Photoshop을 사용하여 야경 도시 일러스트를 생성해 줘. 전경의 인물, 중경의 건물, 원경의 하늘을 각각 다른 레이어로 분리해 줘. - ChatGPT가 자동으로 gpt-image-2를 호출하여 기초 이미지를 생성합니다.
- 이어서 Photoshop 앱을 호출하여 레이어 분리, 조정, 혼합 작업을 수행합니다.
- 완료 후 대화창 내의 다운로드 버튼을 클릭하면 레이어가 포함된 PSD 파일을 받을 수 있습니다.
Photoshop for ChatGPT의 기능 범위
Adobe 공식 helpx 문서에 나열된 통합 버전 지원 핵심 작업은 다음과 같습니다.
| 작업 유형 | 지원 여부 | 설명 |
|---|---|---|
| 부분 영역 조정 | ✅ | 이미지 특정 부분의 밝기, 대비 조정 가능 |
| 크리에이티브 효과 | ✅ | Glitch, Glow 등 내장 필터 |
| 배경 흐림/교체 | ✅ | Adobe Firefly 활용 |
| 레이어 분리 | ✅ | 피사체, 전경, 배경 레이어 분리 |
| 마스크 및 선택 영역 | ⚠️ 일부 | 복잡한 선택 영역은 데스크톱 버전 권장 |
| 스마트 오브젝트 | ❌ | 편집 가능한 스마트 오브젝트 생성 불가 |
| 고급 혼합 모드 | ❌ | 기본 혼합만 지원 |
🎯 기능 팁: ChatGPT 내의 Photoshop은 가벼운 편집에 적합하며, 전체 기능은 여전히 Photoshop 데스크톱 버전에 있습니다. PSD를 빈번하게 대량 생성해야 한다면 APIYI(apiyi.com)를 통해 gpt-image-2 API로 PNG를 출력한 뒤 데스크톱 Photoshop으로 넘기는 워크플로우가 훨씬 효율적입니다.
솔루션 A의 한계
ChatGPT + Photoshop 통합은 경험이 매끄럽지만, 반드시 알아두어야 할 몇 가지 엄격한 제한이 있습니다.
- API 호출 불가: 웹 버전 전용 기능으로, 본인의 프로그램에서 이 워크플로우를 재현할 수 있는 공개 API 인터페이스가 없습니다.
- 생성 속도 저하: 1회 생성 및 레이어 처리 시 보통 60~120초가 소요됩니다.
- 낮은 제어력: 레이어 개수, 이름, 순서는 ChatGPT가 자체적으로 결정하며, 프롬프트로 강제 제어할 수 없습니다.
- 할당량 제한: 무료 사용자는 일일 호출 횟수가 제한되며, Plus 사용자도 상한선이 존재합니다.
이러한 제한으로 인해 솔루션 A는 '영감 탐색'이나 '일회성 창작'에는 적합하지만, 안정적인 생산 환경에는 적합하지 않습니다.

옵션 B: gpt-image-2 API + Photoshop 수동 PSD 변환
"프로그램으로 이미지를 대량 생성한 뒤, 사람이 직접 선별하여 PSD로 변환"하는 것이 목적이라면 옵션 B가 가장 직관적인 선택입니다. 이 방식은 AI 이미지 생성과 레이어 작업을 완전히 분리합니다.
gpt-image-2 API 호출 초간단 예제
OpenAI 호환 인터페이스를 사용하여 이미지를 생성하는 최소한의 실행 코드입니다.
import requests
import base64
response = requests.post(
"https://api.apiyi.com/v1/images/generations",
headers={"Authorization": "Bearer YOUR_API_KEY"},
json={
"model": "gpt-image-2",
"prompt": "밤의 사이버펑크 도시, 네온사인, 비 오는 거리",
"size": "1024x1024",
"quality": "high",
"output_format": "png"
}
)
data = response.json()["data"][0]
image_bytes = base64.b64decode(data["b64_json"])
with open("output.png", "wb") as f:
f.write(image_bytes)
📦 전체 Python 예제 (오류 처리 및 매개변수 설명 포함)
import os
import base64
import requests
from typing import Optional
def generate_image(
prompt: str,
output_path: str,
size: str = "1024x1024",
quality: str = "high",
output_format: str = "png",
background: Optional[str] = None
) -> dict:
"""
gpt-image-2를 호출하여 이미지 생성
Args:
prompt: 이미지 설명
output_path: 출력 파일 경로
size: 1024x1024 / 1024x1536 / 1536x1024
quality: low / medium / high
output_format: png / jpeg / webp
background: transparent / opaque (png/webp만 지원)
"""
api_key = os.getenv("APIYI_API_KEY")
if not api_key:
raise ValueError("APIYI_API_KEY 환경 변수를 설정하세요")
payload = {
"model": "gpt-image-2",
"prompt": prompt,
"size": size,
"quality": quality,
"output_format": output_format,
}
if background:
payload["background"] = background
response = requests.post(
"https://api.apiyi.com/v1/images/generations",
headers={
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
},
json=payload,
timeout=180
)
response.raise_for_status()
result = response.json()
image_data = result["data"][0]["b64_json"]
with open(output_path, "wb") as f:
f.write(base64.b64decode(image_data))
return {
"path": output_path,
"usage": result.get("usage", {}),
"size": size
}
if __name__ == "__main__":
info = generate_image(
prompt="제품 홍보 포스터용 미래지향적 도시 일러스트",
output_path="hero.png",
size="1536x1024",
quality="high",
background="transparent"
)
print(f"생성 성공: {info}")
🎯 연동 팁: APIYI(apiyi.com)를 통해 gpt-image-2를 호출할 때, 인터페이스 URL의
api.openai.com을api.apiyi.com으로 교체하기만 하면 됩니다. 다른 매개변수는 완벽하게 호환되며output_format을 통해 png/jpeg/webp 출력을 지원합니다.
PNG를 Photoshop으로 가져와 PSD로 변환하기
API에서 반환된 PNG를 받은 후, Photoshop에서 PSD로 변환하는 표준 절차입니다.
- Photoshop 데스크톱 버전에서 PNG 파일 열기 (
File → Open) - 이미지가 단일 레이어(보통 '배경' 레이어)로 표시됨
- 레이어를 더블 클릭하여 잠금을 해제하고 편집 가능한 레이어로 전환
- 필요에 따라 피사체 분리:
- 개체 선택 도구로 피사체 자동 인식
- 생성형 확장으로 배경 다시 그리기
- 알파 채널을 사용하여 투명 영역 추출
- PSD로 저장:
File → Save As → Photoshop (.PSD)
옵션 B의 실제 레이어 분리 능력
주의할 점은 PNG에서 PSD로 바로 변환하면 기본적으로 레이어가 1개뿐이라는 것입니다. 진정한 다중 레이어 PSD를 얻으려면 추가적인 분리 작업이 필요합니다. 일반적인 방법은 다음과 같습니다.
| 분리 방식 | 작업 복잡도 | 분리 품질 |
|---|---|---|
| 수동 선택 영역 + 레이어 복사 | 높음 | 매우 높음 |
| AI 누끼 도구(Remove.bg) | 낮음 | 보통 |
| Photoshop 개체 선택 + 생성형 채우기 | 중간 | 높음 |
| Photoshop 신경망 필터 깊이 추정 | 낮음 | 보통(가상 3D 분리) |
gpt-image-2로 PSD 출력 시 프롬프트 엔지니어링 팁
옵션 B의 분리 효율을 극대화하려면 프롬프트 단계에서 후속 레이어 분리 가능성을 고려해야 합니다. 실무에서 검증된 프롬프트 템플릿입니다.
[주제]: 제품 홍보 포스터, 피사체는 미래지향적 운동화
[구도 요구사항]:
- 피사체 중앙 배치, 화면의 60% 차지
- 배경은 단색 또는 단순한 그라데이션으로 처리하여 누끼 작업 용이하게 함
- 피사체와 배경의 색상 차이 및 심도 분리 확실하게
- 배경에 피사체와 유사한 요소 포함 금지
[출력 매개변수]:
- 해상도: 1536x1024
- 배경: transparent (지원 시)
- 스타일: 상업 사진 질감
이런 프롬프트 방식을 사용하면 생성된 PNG가 후속 레이어 분리 작업에 훨씬 '친화적'이 되어, 누끼 도구의 인식 정확도가 크게 향상됩니다.
| 프롬프트 키워드 | 레이어 분리에 미치는 영향 |
|---|---|
pure background / solid color background |
누끼 경계가 더 깔끔함 |
clear subject separation |
피사체와 배경 경계가 명확함 |
centered composition |
피사체 위치 자동 감지 용이 |
studio lighting |
그림자 투영 감소, 오판율 저하 |
no overlapping elements |
레이어 간 겹침 방지 |
🎯 효율성 향상: APIYI(apiyi.com)의 gpt-image-2를 연동할 때, 시스템 수준의 프롬프트 템플릿을 활용하여 이러한 제약 조건을 미리 설정하면 팀 전체가 생성하는 이미지가 후속 PSD 워크플로우에 최적화되도록 할 수 있습니다.
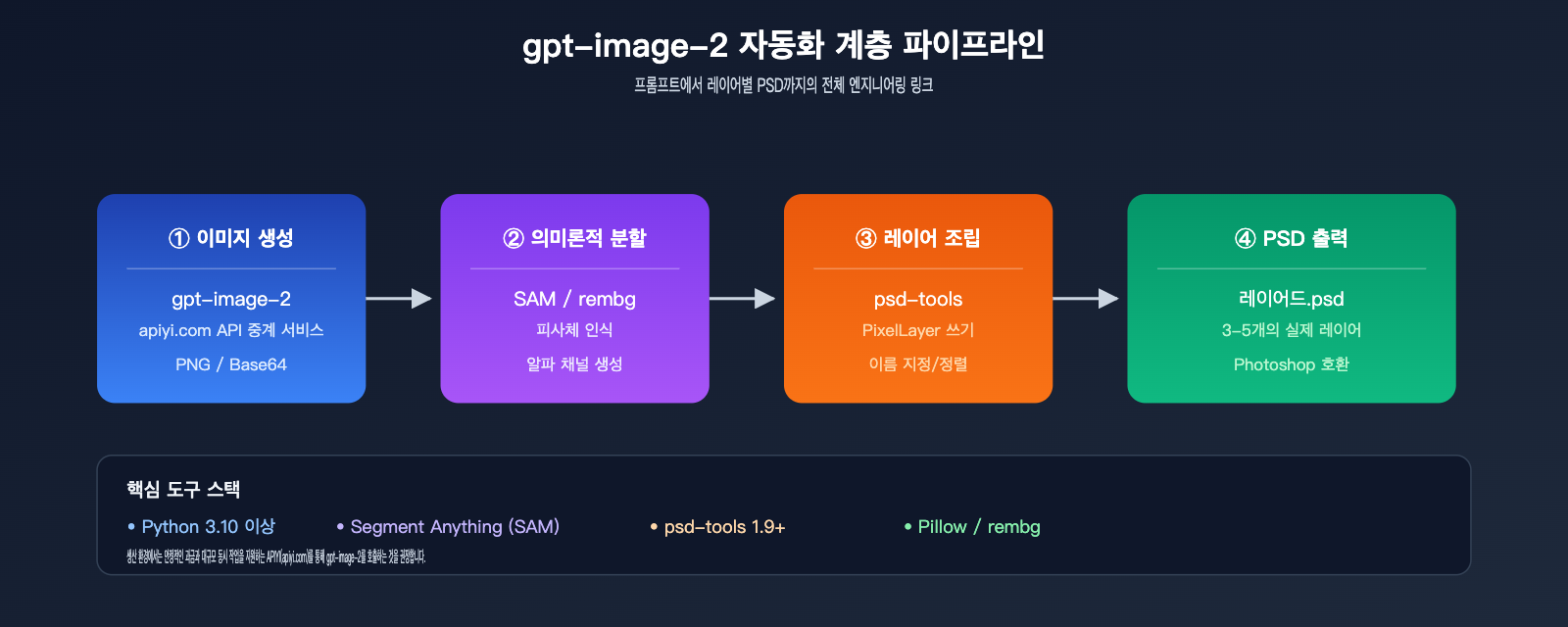
옵션 C: API + 타사 분리 도구를 통한 자동 PSD 출력
제품화 환경(예: 이커머스 소재 자동 생성, 광고 파이프라인)에서는 Photoshop을 수동으로 조작하는 것이 비현실적입니다. 이때는 자동화된 레이어 분리 도구를 도입해야 합니다.
자동화 워크플로우 아키텍처
[사용자 프롬프트 입력]
↓
[gpt-image-2 API 원본 이미지 생성]
↓
[의미론적 분할 모델 영역 인식] (예: SAM, Florence)
↓
[각 레이어별 알파 채널 생성]
↓
[psd-tools / photoshop-python-api를 통한 PSD 작성]
↓
[다중 레이어 PSD 파일 출력]
전체 파이프라인을 코드로 구현할 수 있어 Photoshop 클라이언트를 열 필요가 없습니다.
주요 도구 조합
| 도구 | 역할 | 추천도 |
|---|---|---|
| psd-tools (Python) | PSD 파일 구조 읽기/쓰기 | ⭐⭐⭐⭐⭐ |
| Pillow | 기본 이미지 처리 | ⭐⭐⭐⭐⭐ |
| SAM (Segment Anything) | Meta의 의미론적 분할 | ⭐⭐⭐⭐⭐ |
| rembg | 원클릭 누끼, 배경 제거 | ⭐⭐⭐⭐ |
| MiDaS | 깊이 추정, 전경/배경 분리 | ⭐⭐⭐⭐ |
| Photopea API | 온라인 PSD 편집 | ⭐⭐⭐ |
자동 레이어 분리 예제 코드
from psd_tools import PSDImage
from psd_tools.api.layers import PixelLayer
from PIL import Image
from rembg import remove
original = Image.open("gpt_image_2_output.png")
foreground = remove(original)
background = Image.new("RGBA", original.size, (255, 255, 255, 0))
psd = PSDImage.new(mode="RGBA", size=original.size)
psd.append(PixelLayer.frompil(background, psd, "Background"))
psd.append(PixelLayer.frompil(foreground, psd, "Foreground"))
psd.save("layered_output.psd")
🎯 엔지니어링 제안: 프로덕션 환경에서는 "gpt-image-2 호출 → 누끼 작업 → PSD 작성" 과정을 마이크로서비스로 캡슐화하는 것을 권장합니다. APIYI(apiyi.com)를 통해 gpt-image-2 API를 호출하면 고성능 동시 처리와 안정적인 과금이 가능하여 이미지 파이프라인의 상위 능력으로 적합합니다.
옵션 C 주의사항
- 레이어 품질은 분할 모델에 따라 결정됨: SAM이 rembg보다 정확하지만 추론 비용이 높음
- PSD 호환성: psd-tools로 생성된 PSD는 주요 Photoshop 버전에서 잘 작동하지만, 극히 일부 구버전에서는 메타데이터가 유실될 수 있음
- 대량 작업 시 연산 비용: 모든 이미지에 분할 모델을 적용하면 GPU 비용이 크게 상승함
- 혼합 방식이 현실적: API 이미지 생성 + 단순 배경 분리 + 소량의 수동 정밀 보정 방식을 권장
심화: 다중 객체 레이어 분리 실무 코드
인물, 상품, 텍스트 등 여러 의미론적 객체를 각각 독립된 레이어로 배치해야 할 때는 SAM(Segment Anything Model)을 결합하여 더 정밀하게 분리할 수 있습니다.
📦 SAM + psd-tools 다중 객체 레이어 분리 전체 예제
import torch
import numpy as np
from PIL import Image
from segment_anything import SamPredictor, sam_model_registry
from psd_tools import PSDImage
from psd_tools.api.layers import PixelLayer
def gpt_image_to_layered_psd(image_path: str, output_psd: str, points: list):
"""
gpt-image-2 출력 PNG를 여러 객체 레이어로 분리한 PSD로 변환
Args:
image_path: gpt-image-2 생성 PNG 경로
output_psd: 출력할 PSD 파일 경로
points: 분리할 객체 중심점 리스트 [(x, y, label), ...]
"""
image = Image.open(image_path).convert("RGBA")
image_np = np.array(image)
sam = sam_model_registry["vit_h"](checkpoint="sam_vit_h.pth")
sam.to("cuda" if torch.cuda.is_available() else "cpu")
predictor = SamPredictor(sam)
predictor.set_image(image_np[:, :, :3])
psd = PSDImage.new(mode="RGBA", size=image.size)
for idx, (x, y, label) in enumerate(points):
masks, scores, _ = predictor.predict(
point_coords=np.array([[x, y]]),
point_labels=np.array([1]),
multimask_output=False
)
mask = masks[0]
layer_array = image_np.copy()
layer_array[~mask] = [0, 0, 0, 0]
layer_image = Image.fromarray(layer_array, "RGBA")
psd.append(PixelLayer.frompil(layer_image, psd, label))
background_array = image_np.copy()
background_image = Image.fromarray(background_array, "RGBA")
background_layer = PixelLayer.frompil(background_image, psd, "Background")
psd.insert(0, background_layer)
psd.save(output_psd)
print(f"✅ 다중 레이어 PSD 생성 완료: {output_psd}")
if __name__ == "__main__":
gpt_image_to_layered_psd(
image_path="gpt_image_2_poster.png",
output_psd="layered_poster.psd",
points=[
(512, 400, "Subject"),
(200, 600, "ProductLeft"),
(800, 600, "ProductRight"),
]
)
이 과정을 통해 gpt-image-2로 생성한 포스터를 3~5개의 실제 레이어로 분리된 PSD로 만들 수 있으며, 각 레이어는 Photoshop에서 독립적으로 편집 가능합니다.
오류 처리 및 문제 해결
엔지니어링 환경에서 gpt-image-2 호출 및 후속 분리 과정 중 발생할 수 있는 주요 문제와 대응 방법입니다.
| 현상 | 근본 원인 | 해결 방법 |
|---|---|---|
API 응답 invalid output_format |
지원하지 않는 psd 등의 값 전달 |
png/jpeg/webp만 사용 |
b64_json 필드 비어 있음 |
콘텐츠 필터링 차단 | 프롬프트 최적화, 민감한 묘사 회피 |
| 누끼 후 가장자리 거침 | 분할 모델 정밀도 부족 | SAM + 가장자리 feather 후처리 적용 |
| Photoshop에서 PSD가 열리지 않음 | psd-tools 메타데이터 작성 불완전 | psd-tools를 1.9+ 버전으로 업데이트 |
| 분리 후 레이어 어긋남 | RGBA 채널 정렬 불일치 | 캔버스 크기를 통일한 후 작성 |
| 호출 속도 저하 | 고동시성 제한 | APIYI(apiyi.com)의 다중 경로 라우팅으로 분산 |
🎯 안정성 팁: 프로덕션 환경에서는 API 호출 계층에 재시도 및 폴백(fallback) 로직을 추가하는 것을 권장합니다. APIYI(apiyi.com)를 통해 중계되는 요청은 OpenAI의 속도 제한 응답을 자동으로 인식하여 지능적으로 전환하므로 대량 작업의 실패율을 낮출 수 있습니다.
gpt-image-2 출력 PSD 관련 FAQ
실무에서 자주 묻는 질문들을 모아 정리해 드립니다.
Q1: gpt-image-2 API는 정말 PSD로 직접 출력할 수 없나요?
네, 불가능합니다. OpenAI 공식 문서에 따르면 output_format 매개변수는 png, jpeg, webp 세 가지만 지원합니다. "API가 PSD를 직접 출력한다"고 광고하는 서비스들은 내부 서버에서 별도의 레이어 분리 과정을 거친 뒤 PSD로 변환해 전달하는 것일 뿐, 이는 gpt-image-2 모델 자체의 기능이 아닙니다.
🎯 참고: 공식 gpt-image-2를 안정적으로 연동하려면 APIYI(apiyi.com)와 같이 OpenAI 공식 인터페이스와 호환되는 API 중계 서비스를 사용하세요. 매개변수 동작이 OpenAI와 동일하게 유지되어 예기치 않은 오류를 방지할 수 있습니다.
Q2: ChatGPT 웹 버전에서 출력되는 PSD는 진짜 레이어가 나뉘어 있나요?
네, 그렇습니다. 웹 버전은 내부적으로 Adobe Photoshop을 사용하여 편집 작업을 수행하므로, 생성된 PSD에는 실제 레이어, 마스크, 효과가 포함되어 있습니다. 다만 레이어 개수나 이름을 사용자가 정밀하게 제어할 수는 없으며, 보통 3~5개 정도의 레이어(배경, 피사체, 전경, 조정 레이어 등)로 구성됩니다.
Q3: gpt-image-2와 gpt-image-2-all은 출력 형식에 차이가 있나요?
미세한 차이가 있습니다. gpt-image-2-all은 ChatGPT 웹 버전과 동일한 역방향 채널을 사용하며, 반환되는 b64_json 필드에 data:image/png;base64, 접두사가 포함됩니다. 반면 gpt-image-2는 OpenAI Images API에 직접 연결되어 접두사가 없는 순수 base64 문자열을 반환합니다. 둘 다 PSD 출력을 지원하지 않으므로, 문자열 처리 코드 작성 시 주의가 필요합니다.
Q4: 투명 배경의 PNG만 필요하다면 PSD가 없어도 될까요?
많은 경우 그렇습니다. gpt-image-2 API는 background: "transparent" 매개변수를 지원하여 투명 배경의 PNG를 바로 생성할 수 있습니다. 이는 다음과 같은 경우에 유용합니다.
- 이커머스 상품 누끼 작업
- 로고, 아이콘, 스티커 제작
- UI 요소 생성
피사체 외의 부분까지 레이어로 분리하여 수정해야 할 때만 PSD 워크플로우가 필요합니다.
Q5: PSD 대량 생성 시 비용은 어떻게 관리하나요?
비용은 크게 세 부분으로 나뉩니다.
| 비용 항목 | gpt-image-2 API | 후처리 과정 |
|---|---|---|
| 단가 | 약 $0.03 – $0.20/장 | 누끼 GPU 연산 ~$0.001 |
| 시간 | 60-120 초 | 5-30 초 |
| 안정성 | OpenAI 제한 영향 | 자체 연산 자원 활용 가능 |
🎯 비용 절감 전략: 대량 생성 시에는 우수한 후보 이미지에 대해서만 레이어 분리 작업을 수행하는 것을 추천합니다. 먼저
quality=low매개변수로 미리보기 이미지를 빠르게 생성하고, APIYI(apiyi.com)의 통합 결제 내역을 통해 비용을 확인한 뒤, 만족스러운 결과물만high품질로 다시 생성하여 후처리 파이프라인에 태우세요.
Q6: gpt-image-2로 기존 PSD 파일을 직접 편집할 수 있나요?
불가능합니다. gpt-image-2의 이미지 편집 인터페이스는 PNG/JPEG/WEBP 입력만 지원하며, PSD 내부의 레이어 구조를 인식하지 못합니다. "PSD의 특정 레이어만 AI로 다시 그리고 싶다면" 다음 절차를 따르세요.
- Photoshop에서 해당 레이어를 PNG(알파 채널 포함)로 내보냅니다.
- gpt-image-2의 편집 인터페이스와 마스크를 사용하여 다시 그립니다.
- 결과물을 새 레이어로 다시 PSD에 가져옵니다.
gpt-image-2 PSD 출력 실무 사례
산업군마다 PSD 출력에 대한 요구사항이 다르므로, 비즈니스 상황에 맞는 전략이 필요합니다. 3가지 대표 사례를 소개합니다.
사례 1: 이커머스 상품 포스터 대량 제작
매일 300개 이상의 상품 포스터를 제작해야 하는 팀의 경우, 상품 레이어, 배경 레이어, 텍스트 레이어를 분리하여 운영자가 문구만 빠르게 교체할 수 있도록 구성합니다.
워크플로우:
- 상품 업로드 후 운영자가 키워드 입력
- gpt-image-2 API로 메인 이미지 생성(
output_format=png,background=transparent) - rembg로 누끼 경계선 정밀 조정
- psd-tools를 사용하여 3개 레이어 구조 생성:
- Layer 1: 상품(투명 배경)
- Layer 2: AI 생성 배경
- Layer 3: 텍스트 자리 표시자
- 디자이너는 PSD에서 텍스트만 수정하여 배포
효율성: 포스터 제작 시간이 장당 30분에서 2분으로 단축되었습니다.
🎯 선택 가이드: 반복 작업이 많은 경우, APIYI(apiyi.com)의 gpt-image-2 인터페이스와 기업용 결제 솔루션을 결합하면 비용 예측이 가능하고 생산성을 탄력적으로 확장할 수 있습니다.
사례 2: 게임 UI 에셋 프로토타이핑
게임 아트 팀이 프로토타입 단계에서 버튼, 아이콘, 배너 등 '임시' UI 에셋을 대량으로 만들 때 PSD 형식을 활용합니다.
워크플로우:
gpt-image-2로 기본 비주얼 생성
↓
SAM으로 피사체 자동 분할
↓
여러 개의 PNG(프레임, 아이콘, 광택 등)로 내보내기
↓
psd-tools로 레이어별 PSD 통합
↓
아티스트가 PS에서 최종 수정
| 에셋 유형 | gpt-image-2 출력 | 후처리 작업 | 최종 레이어 수 |
|---|---|---|---|
| 버튼 | 투명 PNG | 상태별 슬라이스(기본/호버/클릭) | 3 |
| 아이콘 | 투명 PNG | 하이라이트/그림자 분리 | 2-4 |
| 배너 | RGB PNG | 피사체/배경/광효과 분리 | 3-5 |
| 카드 | RGB PNG | 테두리/배경/라벨 분리 | 3-4 |
사례 3: 마케팅 콘텐츠 다국어 버전 제작
광고 팀이 하나의 메인 비주얼을 10개 언어 버전으로 제작해야 할 때, 텍스트 레이어만 독립적으로 관리합니다.
핵심 작업:
- gpt-image-2로 "텍스트 없는" 메인 비주얼 생성(프롬프트에
no text,no letters명시) - psd-tools로 텍스트 레이어 자리 표시자 생성
- 이후 텍스트 레이어만 수정하여 10개 언어 버전 출력
이 방식은 메인 비주얼을 한 번만 생성하고 텍스트 레이어를 완벽하게 제어할 수 있어, AI가 다국어 텍스트를 생성할 때 발생하는 오타 문제를 방지합니다.
🎯 다국어 팁: gpt-image-2는 영어 생성은 비교적 정확하지만, 중국어, 일본어, 한국어는 오타가 잦습니다. APIYI(apiyi.com)를 통해 호출할 때 프롬프트에서 텍스트를 제외하고, PSD 내에서 텍스트 레이어로 관리하는 것을 강력히 추천합니다.
사례 4: 만화 및 일러스트 콘티 보조
일러스트레이터가 gpt-image-2로 초안 아이디어를 얻고 Photoshop에서 정밀 수정하는 방식입니다.
레이어 구성 예시:
- 스케치 레이어: gpt-image-2 출력 원본(참조용)
- 선화 레이어: 스케치 기반 라인 작업
- 밑색 레이어: 면 채우기
- 그림자 레이어: 명암 묘사
- 하이라이트 레이어: 빛 표현
- 효과 레이어: 장식 요소
작업 포인트:
1. gpt-image-2로 1024x1536 세로형 구도 생성
2. Photoshop에서 해당 이미지를 Layer 0(잠금)으로 설정
3. 그 위에 5~6개의 빈 레이어를 생성하여 작업
4. 완료 후 PSD로 저장
이 프로세스를 통해 AI 초안을 일회성 이미지가 아닌, 지속적으로 수정 가능한 자산으로 활용할 수 있습니다.
gpt-image-2와 다른 이미지 형식 비교
PSD가 워크플로우에서 어떤 위치를 차지하는지 더 명확히 이해하기 위해, 다른 일반적인 출력 형식들과 비교해 보겠습니다.
| 형식 | 파일 크기 | 편집 편의성 | 소프트웨어 호환성 | gpt-image-2 후처리 적합도 |
|---|---|---|---|---|
| PNG | 중간 | 낮음(평면) | ✅ 매우 좋음 | ⭐⭐⭐⭐⭐ 기본 권장 |
| JPEG | 작음 | 매우 낮음 | ✅ 매우 좋음 | ⭐⭐⭐ 미리보기용 |
| WEBP | 작음 | 낮음 | ⚠️ 웹 중심 | ⭐⭐⭐ 웹 환경용 |
| PSD | 큼 | ✅ 매우 높음 | ⚠️ Adobe 생태계 | ⭐⭐⭐⭐ 후처리 필요 |
| TIFF | 매우 큼 | 중간 | ✅ 인쇄 중심 | ⭐⭐ 인쇄용 |
| SVG | 작음 | ✅ 매우 높음(벡터) | ✅ 웹/인쇄 | ❌ gpt-image-2 미지원 |
표에서 볼 수 있듯이 **PSD의 핵심 가치는 '편집 편의성'**에 있으며, 이는 다른 형식이 대체하기 어려운 부분입니다. 별도의 후반 작업이 필요 없다면 PNG가 훨씬 적합합니다.
gpt-image-2 PSD 출력 베스트 프랙티스 요약
처음 질문으로 돌아가서, gpt-image-2는 어떻게 PSD 파일로 출력할까요? 핵심 결론을 세 가지로 정리해 드립니다.
- API 경로로는 PSD 직접 출력 불가: gpt-image-2 API는 모델 자체의 한계로 인해 PNG, JPEG, WEBP 세 가지 래스터 형식만 지원합니다.
- ChatGPT 웹 버전은 Photoshop을 통해 레이어가 살아있는 PSD 출력 가능: Adobe Photoshop 앱이 레이어 처리를 담당하므로 개인 디자이너의 가벼운 작업에 적합합니다.
- 엔지니어링 환경은 "API 생성 + 후처리" 조합 필요: SAM/rembg 같은 도구로 자동으로 레이어를 분리하고, psd-tools를 사용하여 파일을 작성하는 방식이 대량 자동화에 유리합니다.
| 사용자 유형 | 권장 솔루션 | 도구 조합 |
|---|---|---|
| 개인 디자이너 | 솔루션 A | ChatGPT + Photoshop 연동 |
| 중소 규모 팀 | 솔루션 B | gpt-image-2 API + 데스크톱 Photoshop 수동 레이어링 |
| 기업 개발자 | 솔루션 C | gpt-image-2 API + 자동화 레이어링 파이프라인 |
🎯 최종 제안: 먼저 ChatGPT 웹 버전에서 Photoshop 연동을 경험해 보며 레이어 분리 과정을 이해한 뒤, API 파이프라인 구축 여부를 결정하세요. 엔지니어링 통합이 필요하다면 APIYI(apiyi.com)를 통해 gpt-image-2를 통합하세요. 이 플랫폼은 국내에서 안정적으로 접근 가능한 OpenAI 호환 인터페이스를 제공하며, 기업급 안정성과 투명한 비용 정산을 지원합니다.
이번 gpt-image-2 PSD 출력 가이드가 여러분의 시행착오를 줄이는 데 도움이 되길 바랍니다. gpt-image-2의 PSD 파일 출력에서 진짜 어려운 점은 API 자체가 아니라 적절한 워크플로우를 선택하는 것입니다. 자신의 규모, 예산, 자동화 요구 사항에 맞춰 A/B/C 솔루션을 선택한다면 보통 일주일 내에 전체 프로세스를 구축할 수 있습니다.
작성자: APIYI 기술팀 | apiyi.com — 기업용 대규모 언어 모델 API 중계 서비스 플랫폼