阿里云 Qwen3.5 API 호출 속도가 느리다는 점은 최근 개발자 커뮤니티에서 가장 많이 논의되는 주제 중 하나입니다. 알리바바 자체 개발 모델인 Qwen3.5-Plus와 Qwen3.5-Flash는 이론적으로 자체 컴퓨팅 파워에서 뛰어난 성능을 보여야 하지만, 실제 경험은 많은 개발자들에게 혼란을 주고 있습니다. 자체 모델이 자체 플랫폼에서 느리게 실행될 뿐만 아니라, 알리바바 클라우드를 통해 GLM-5, Kimi-K2.5, MiniMax-M2.5와 같은 타사 모델을 호출할 때도 눈에 띄게 지연이 발생합니다.
핵심 가치: 이 글에서는 컴퓨팅 파워 공급, 아키텍처 설계, 스케줄링 전략의 세 가지 차원에서 알리바바 클라우드 API 응답 지연의 근본적인 원인을 심층적으로 분석하고, 실제 프로젝트에서 더 빠른 추론 경험을 얻는 데 도움이 될 검증된 세 가지 대체 솔루션을 제시합니다.

阿里云 Qwen3.5 API 속도 저하의 5가지 주요 원인 분석
원인 1: 전 세계 GPU 컴퓨팅 파워 공급의 심각한 부족
이 문제는 비단 阿里云만의 문제가 아니라, 산업 전반의 구조적인 모순입니다. 2026년 데이터센터급 GPU의 납기일이 36-52주까지 늘어났으며, 阿里云 고위 관계자는 반도체 제조업체, 스토리지 칩, 메모리 부품 전반에 걸쳐 공급 부족이 심각하며, 공급망이 향후 2-3년간 '주요 병목 현상'이 될 것이라고 공개적으로 인정했습니다.
| 컴퓨팅 파워 공급 지표 | 2025년 | 2026년 | 변화 추세 |
|---|---|---|---|
| GPU 납기일 | 12-24주 | 36-52주 | ↑ 대폭 연장 |
| 阿里云 AI 매출 성장 | — | 34% | 수요 폭발 |
| 阿里云 컴퓨팅 파워 가격 조정 | 기준가 | 최고 34% 인상 | ↑ 2026년 4월 18일부터 |
| 전 세계 AI 추론 지출 비중 | 42% | 55% | 최초로 훈련 초과 |
阿里云은 2026년 4월 18일부터 AI 컴퓨팅 파워 가격을 최고 34%까지 인상한다고 공식 발표했습니다. 그 직접적인 이유는 '전 세계 AI 수요 폭발과 공급망 가격 상승'입니다. 阿里云의 매출은 34% 증가했지만, 수요를 충족시키기에는 여전히 부족하다고 공개적으로 밝혔습니다. 이것이 바로 Qwen3.5 API 속도 저하의 거시적인 배경입니다.
원인 2: Qwen3.5 모델 아키텍처의 컴퓨팅 파워 소모
Qwen3.5 제품군은 MoE(Mixture of Experts) 아키텍처를 채택했습니다. 플래그십 버전인 Qwen3.5-397B-A17B는 총 파라미터 수가 3970억 개에 달하며, 각 추론 시 170억 개의 파라미터가 활성화됩니다. 경량 모델인 Qwen3.5-Flash(35B-A3B 기반)조차도 100만 토큰 컨텍스트와 멀티모달 입력(텍스트+이미지+비디오)을 기본 지원합니다.
| 모델 버전 | 총 파라미터 수 | 활성화 파라미터 수 | 기본 컨텍스트 | 멀티모달 지원 |
|---|---|---|---|---|
| Qwen3.5-397B-A17B (플래그십) | 3970억 개 | 170억 개 | 262K→1M | 텍스트+이미지+비디오 |
| Qwen3.5-Plus (API 버전) | 미공개 | 미공개 | 1M | 텍스트+이미지+비디오 |
| Qwen3.5-Flash (API 버전) | 350억 개 | 30억 개 | 1M | 텍스트+이미지+비디오 |
| Qwen3.5-122B-A10B | 1220억 개 | 100억 개 | 262K | 텍스트+이미지+비디오 |
이 모델들은 훈련 단계부터 조기 융합(early-fusion) 멀티모달 아키텍처를 사용하여 텍스트, 이미지, 비디오를 통합 처리하는 것을 기본으로 합니다. 강력한 기능의 대가는 각 요청의 계산 오버헤드가 순수 텍스트 모델보다 훨씬 높다는 것입니다. 여기에 백만 토큰급 컨텍스트 창이 더해지면, 단일 추론 시 GPU 메모리와 컴퓨팅 파워 점유율이 크게 증가합니다.
원인 3: 阿里云의 제3자 모델 재판매로 인한 추가 지연
阿里云 DashScope 플랫폼을 통해 GLM-5(Zhipu AI), Kimi-K2.5(Moonshot AI), MiniMax-M2.5와 같은 제3자 모델을 호출할 때, 요청 경로는 다음과 같이 구성됩니다.
사용자 애플리케이션 → 阿里云 API 게이트웨이 → DashScope 스케줄링 계층 → 제3자 모델 서비스
전달 계층이 하나 추가될 때마다 지연 시간이 늘어납니다. 더 중요한 것은, 阿里云이 이 모델들을 재판매할 때 GPU 자원 할당 우선순위가 자체 모델보다 낮을 수 있다는 점입니다. 컴퓨팅 파워 자체가 부족하기 때문이죠. 업계 개발자들의 일반적인 피드백은 다음과 같습니다. GLM-5, Kimi-K2.5, MiniMax-M2.5를 阿里云을 통해 호출하는 것이 공식 API보다 명백히 느립니다.
원인 4: 추론 스케줄링 전략의 최적화 부족
SiliconFlow, Fireworks AI, Together AI와 같은 전문 제3자 추론 플랫폼은 맞춤형 CUDA 커널, 어텐션 메커니즘 융합, 세분화된 스케줄링 등의 기술을 통해 추론 효율성에서 상당한 이점을 가집니다. 실제 테스트 데이터에 따르면:
- SiliconFlow: 추론 속도가 범용 클라우드 플랫폼보다 최대 2.3배 빠르고, 지연 시간은 32% 감소했습니다.
- Fireworks AI: FireAttention v2 기술은 최대 8배의 속도 향상을 주장하며, 실제 테스트 결과 약 747 TPS를 기록했습니다.
- Together AI: 투기적 디코딩과 FP4 양자화를 통해 오픈소스 모델의 추론 속도를 최대 2배 향상시켰습니다.
阿里云은 범용 클라우드 플랫폼으로서, 추론 스케줄링이 극단적인 추론 속도 최적화보다는 범용성과 안정성에 더 중점을 둡니다. 이는 컴퓨팅 파워가 충분할 때는 큰 영향을 미치지 않지만, GPU 자원이 부족한 시기에는 격차가 확대됩니다.
원인 5: 멀티 테넌트 자원 경쟁
중국 최대 클라우드 서비스 제공업체인 阿里云은 AI 추론 클러스터를 통해 수많은 사용자를 동시에 지원합니다. 피크 타임에는 GPU 자원 경쟁으로 인해 대기 시간이 증가합니다. 阿里云이 개발한 Aegaeon 리소스 풀링 시스템이 GPU 활용률을 82% 향상시켰다고 주장하지만, 이는 본질적으로 '제한된 케이크를 더 잘게 자르는 것'일 뿐, 컴퓨팅 파워 총량 부족 문제를 근본적으로 해결하지는 못합니다.
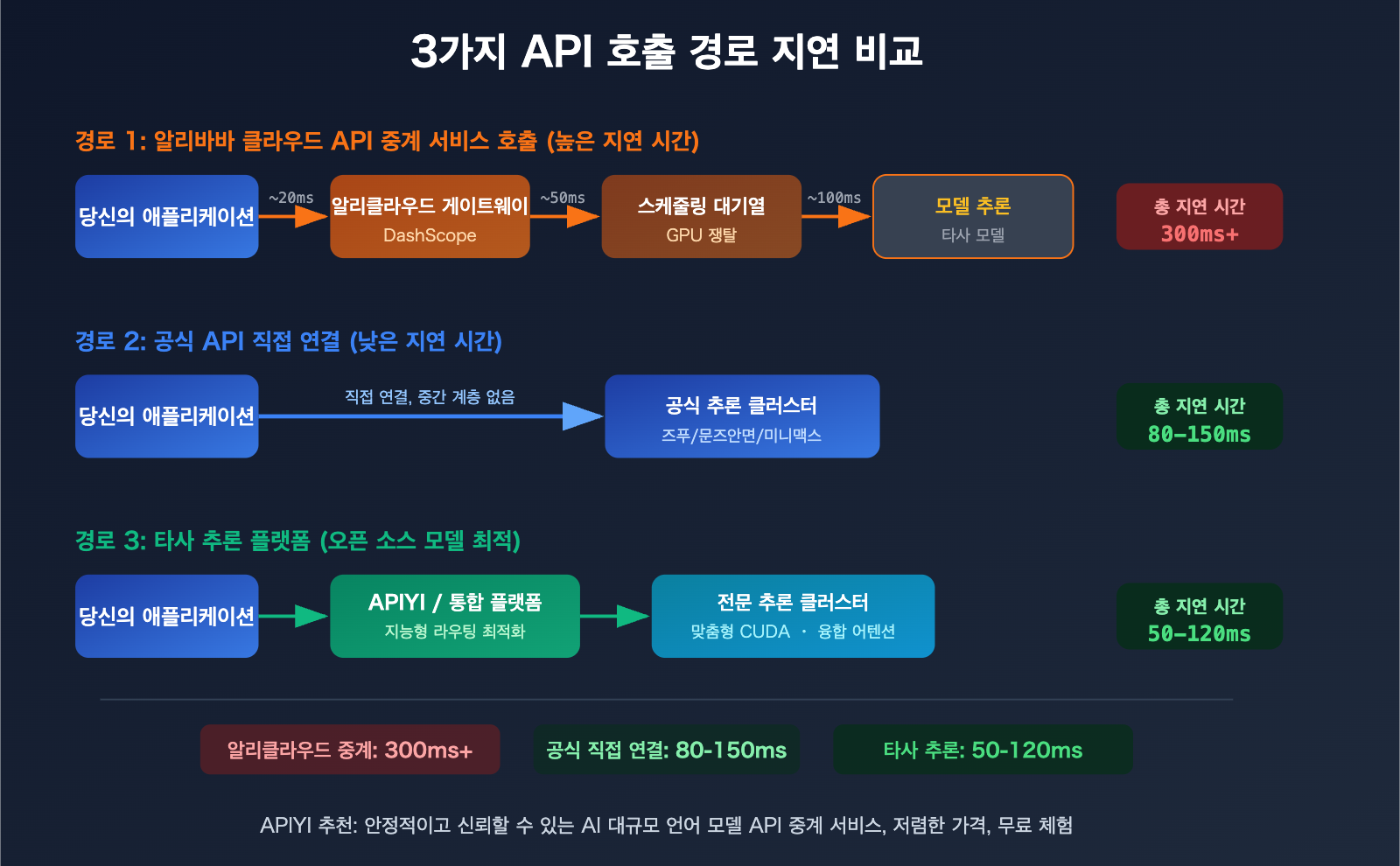
GLM-5, Kimi-K2.5, MiniMax-M2.5: 알리바바 클라우드 vs 공식 API 호출 지연 시간 비교
원인을 파악했으니, 이제 실제 모델 호출 시나리오를 살펴보겠습니다. 다음은 세 가지 인기 모델이 다양한 플랫폼에서 경험하는 차이점을 분석한 내용입니다.
GLM-5 (Zhipu AI) API 호출 지연 시간 분석
GLM-5은 Zhipu AI가 2026년 2월에 출시한 플래그십 모델로, 총 7440억 개, 활성 파라미터 400억 개를 가진 MoE(Mixture of Experts) 아키텍처를 사용합니다. 화웨이 Ascend 칩에서 훈련되었으며, 20만 토큰의 컨텍스트를 지원하고 MIT 라이선스로 오픈 소스화되었습니다.
주요 특징: GLM-5은 Agent 모드를 네이티브로 지원하여 작업을 하위 작업으로 분해하고 직접 전문 오피스 문서(.docx, .pdf, .xlsx)를 생성할 수 있습니다. 가격은 입력 1M 토큰당 $1.00, 출력 1M 토큰당 $3.20입니다.
알리바바 클라우드를 통해 GLM-5을 호출할 때, 요청은 추가적인 게이트웨이와 스케줄링 계층을 거쳐 전달되므로 지연 시간이 상당히 증가합니다. 반면, Zhipu AI 공식 API(bigmodel.cn)에 직접 연결하면 요청이 Zhipu 자체 추론 클러스터에 직접 도달하여 응답이 더 빠릅니다.
Kimi-K2.5 (Moonshot AI) API 호출 지연 시간 분석
Kimi-K2.5은 2026년 1월에 출시된 1조 개 파라미터의 MoE 모델로, 각 요청 시 320억 개의 파라미터만 활성화됩니다. 15조 개의 혼합 시각 및 텍스트 토큰으로 사전 훈련되었으며 네이티브 멀티모달 기능을 지원합니다.
최대 강점: Agent Swarm 기능으로, 최대 100개의 전문 AI Agent를 동시에 조율하여 협업할 수 있으며, 작업 시간을 4.5배 단축합니다. SWE-Bench Verified에서 Gemini 3 Pro를 능가했으며, Cursor AI는 Kimi 기술 기반으로 Composer 2 기능을 구축했음을 확인했습니다.
알리바바 클라우드의 API 중계 서비스를 통해 Kimi-K2.5을 호출하면, 추가적인 전달 경로 때문에 이미 많은 컴퓨팅 파워를 요구하는 1조 개 파라미터 모델의 경험이 더욱 저하됩니다. Moonshot AI 공식 API(platform.moonshot.ai)를 직접 사용하는 것을 권장합니다.
MiniMax-M2.5 API 호출 지연 시간 분석
MiniMax-M2.5은 2026년 2월에 출시되었으며, 총 2300억 개, 활성 파라미터 100억 개를 가지고 있습니다. SWE-Bench Verified에서 80.2%의 점수를 기록했으며, M2.1보다 37% 빠른 완료 속도를 보여 Claude Opus 4.6과 동등한 수준입니다.
뛰어난 비용 효율성: "사용자가 비용을 걱정할 필요 없는" 최초의 최첨단 모델을 표방하며, 초당 100 토큰 속도로 1시간 동안 지속 실행해도 약 1달러만 소요됩니다. Hugging Face에 오픈 소스화되었으며, vLLM 또는 SGLang 배포를 권장합니다.
| 모델 | 출시 시간 | 총 파라미터 | 활성 파라미터 | 권장 호출 방식 | 오픈 소스 상태 |
|---|---|---|---|---|---|
| GLM-5 | 2026.02.11 | 7440억 | 400억 | Zhipu 공식 API | MIT 오픈 소스 |
| Kimi-K2.5 | 2026.01.27 | 1조 | 320억 | Moonshot AI 공식 API | 오픈 소스 |
| MiniMax-M2.5 | 2026.02.12 | 2300억 | 100억 | MiniMax 공식 / 서드파티 | MIT 수정 버전 |
🎯 실측 권장 사항: GLM-5, Kimi-K2.5, MiniMax-M2.5와 같은 비공개 또는 반오픈 소스 서드파티 모델의 경우, 최적의 경험을 위해 각 공식 API에 직접 연결하는 것을 권장합니다. 여러 모델의 API 인터페이스를 통합 관리해야 한다면, APIYI apiyi.com 플랫폼을 통해 하나의 API 키로 여러 모델을 호출하고 더 나은 가격 혜택을 누릴 수 있습니다.
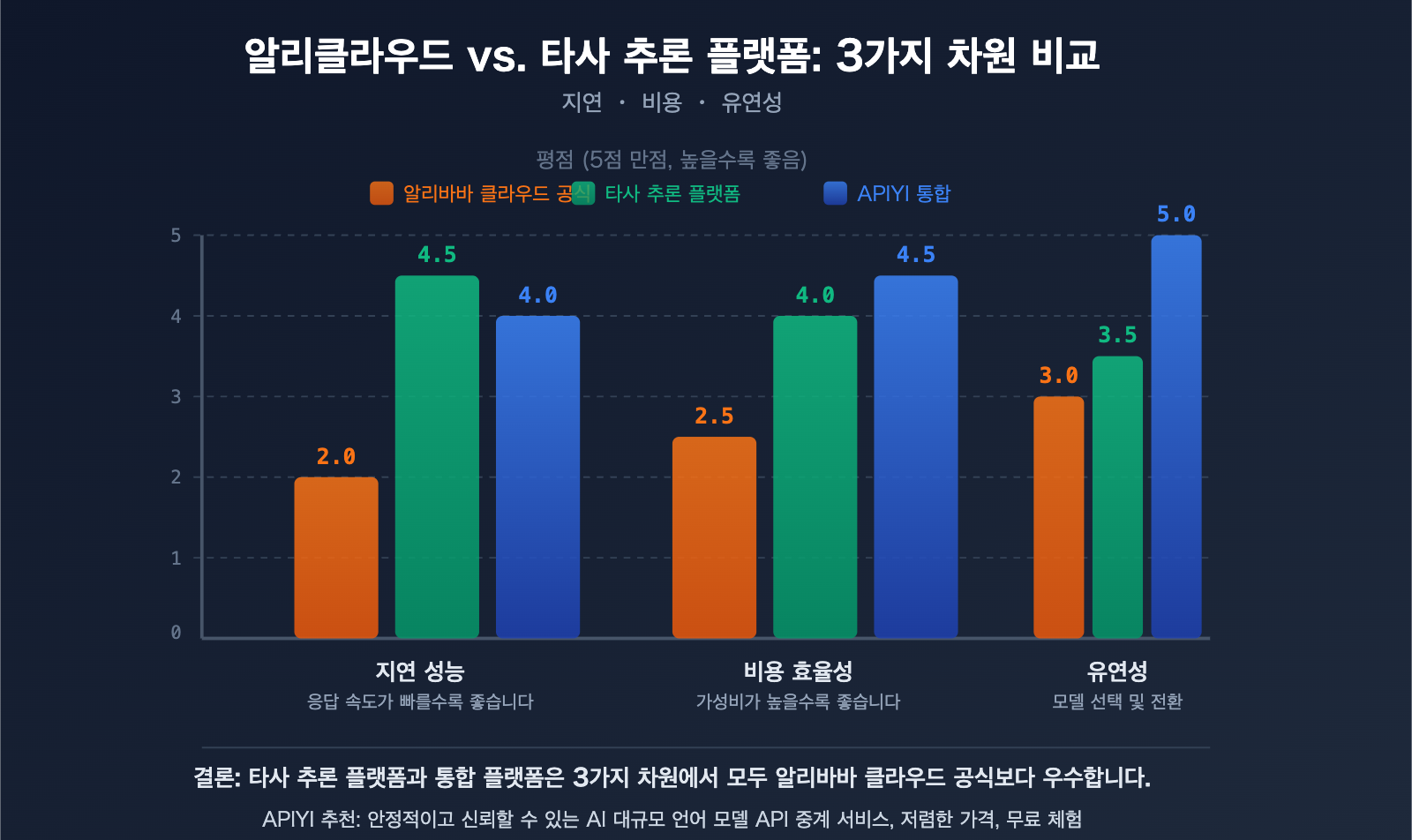
서드파티 추론 플랫폼 vs 알리바바 클라우드: 오픈 소스 모델 배포의 3가지 주요 이점
Qwen3.5와 같은 오픈 소스 모델의 경우, 알리바바 클라우드 공식 API 외에도 더 많은 선택지가 있습니다. 전문 서드파티 추론 플랫폼은 오픈 소스 모델 배포에서 원 제조사 못지않거나 그 이상의 성능을 보여주는 경우가 많습니다.
이점 1: 더 빠른 추론 속도
전문 추론 플랫폼의 핵심 경쟁력은 속도입니다. 이들은 맞춤형 추론 엔진 최적화를 통해 동일한 모델에서 더 낮은 지연 시간을 달성합니다.
| 플랫폼 유형 | 일반적인 지연 시간 | 처리량 | 속도 이점 |
|---|---|---|---|
| 범용 클라우드 플랫폼 (알리바바 클라우드 등) | 100-300ms | 기준 | — |
| SiliconFlow | 32% 감소 | 2.3배 증가 | 맞춤형 CUDA 커널 |
| Fireworks AI | ~0.17초 | ~747 TPS | FireAttention v2 |
| Together AI | — | 2배 증가 | 투기적 디코딩 + FP4 양자화 |
| APIYI apiyi.com | 다중 채널 최적화 | 지능형 라우팅 | 가장 빠른 채널 자동 선택 |
이점 2: 더 낮은 비용
2026년 AI 추론 지출이 처음으로 훈련 지출을 초과하여 AI 클라우드 인프라 총 지출의 55%를 차지했습니다. 이러한 배경에서 추론 비용 최적화는 매우 중요합니다.
- 오픈 소스 모델을 서드파티 API로 호출하면 일반적으로 1M 토큰당 $1 미만으로, 비공개 모델 대비 70-90% 절약됩니다.
- 전문 추론 플랫폼은 NVIDIA Blackwell과 같은 차세대 하드웨어를 활용하여 AI 추론 비용을 최대 10배까지 절감합니다.
- 자체 GPU 클러스터를 구축할 필요 없이 사용한 만큼만 지불하므로 중소 규모 팀 및 개인 개발자에게 적합합니다.
이점 3: 더 유연한 모델 선택
서드파티 플랫폼은 일반적으로 오픈 소스 및 비공개 모델을 모두 지원하며, 통합된 API 인터페이스와 투명한 가격 정책을 제공합니다. 이는 다음을 의미합니다.
- 벤더 종속성 없음: 특정 클라우드 서비스 제공업체에 얽매이지 않습니다.
- 빠른 전환: 하나의 인터페이스로 여러 모델을 호출하고, 효과를 비교한 후 최적의 모델을 선택할 수 있습니다.
- 맞춤형 최적화: 오픈 소스 모델은 양자화, 미세 조정, 병합 등 맞춤형 작업을 지원합니다.
💡 선택 권장 사항: Qwen3.5와 같은 오픈 소스 모델의 경우, 서드파티 추론 플랫폼의 배포 효과가 알리바바 클라우드 공식 API보다 더 좋을 수 있습니다. APIYI apiyi.com 플랫폼을 통해 실제 테스트를 비교해 보시는 것을 권장합니다. 이 플랫폼은 여러 추론 채널을 통합하여 자동으로 가장 지연 시간이 짧은 경로를 선택해 줍니다.
오픈소스 모델 API 호출 빠른 시작: 5분 연동 가이드
Qwen3.5-Flash를 예시로, 서드파티 플랫폼을 통해 오픈소스 모델 API를 빠르게 호출하는 방법을 보여드릴게요.
초간단 코드 예시
import openai
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1" # APIYI 통합 인터페이스
)
response = client.chat.completions.create(
model="qwen3.5-flash",
messages=[
{"role": "user", "content": "Qwen3.5의 MoE 아키텍처 장점 분석"}
]
)
print(response.choices[0].message.content)
전체 코드 보기 (다중 모델 전환 및 오류 처리 포함)
import openai
import time
# 클라이언트 초기화 - APIYI를 통해 여러 모델 통합 호출
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1"
)
# 지원되는 모델 목록
models = [
"qwen3.5-flash", # 알리바바 Qwen3.5-Flash
"qwen3.5-plus", # 알리바바 Qwen3.5-Plus
"glm-5", # Zhipu AI GLM-5
"kimi-k2.5", # Moonshot AI Kimi-K2.5
"minimax-m2.5", # MiniMax-M2.5
]
prompt = "MoE 아키텍처가 대규모 언어 모델 추론에서 가지는 장점을 3문장으로 설명해줘"
for model_name in models:
try:
start = time.time()
response = client.chat.completions.create(
model=model_name,
messages=[{"role": "user", "content": prompt}],
max_tokens=500,
temperature=0.7
)
elapsed = time.time() - start
content = response.choices[0].message.content
print(f"\n[{model_name}] 소요 시간: {elapsed:.2f}초")
print(f"응답: {content[:200]}...")
except Exception as e:
print(f"\n[{model_name}] 호출 실패: {e}")
🚀 빠른 시작: APIYI apiyi.com 플랫폼을 사용하여 위 모델들을 빠르게 테스트해 보세요. 회원가입 시 무료 사용량이 제공되며, 하나의 API 키로 Qwen3.5, GLM-5, Kimi-K2.5, MiniMax-M2.5 등 주요 모델을 별도로 여러 플랫폼에 가입할 필요 없이 호출할 수 있습니다.
다양한 시나리오별 모델 호출 솔루션 추천
실제 요구사항에 맞춰 가장 적합한 호출 방식을 선택하세요:
시나리오 1: 클로즈드 소스/반클로즈드 소스 모델 호출 필요
GLM-5, Kimi-K2.5 등의 모델 클로즈드 소스 버전(자체 배포가 아닌 경우)을 주로 사용하신다면:
- 최우선: 각 공식 API에 직접 연결 (지연 시간 최소화)
- 차선책: APIYI apiyi.com과 같은 통합 플랫폼을 통해 통일된 호출 (약간의 지연 시간 증가와 관리 편의성 확보)
시나리오 2: 오픈소스 모델 배포 필요
Qwen3.5, GLM-5 오픈소스 버전, MiniMax-M2.5 오픈소스 버전 등의 모델을 사용하신다면:
- 예산 충분: SiliconFlow, Together AI 등 전문 추론 플랫폼 선택 (최적의 지연 시간)
- 가성비 우선: APIYI apiyi.com 통합 호출을 통해 최적의 경로로 자동 라우팅
- 완전한 제어: vLLM 또는 SGLang을 사용하여 자체 추론 서비스 구축 (자체 GPU 리소스 필요)
시나리오 3: 다중 모델 비교 테스트 필요
개발 초기 단계에서 여러 모델의 성능을 빠르게 비교해야 할 때:
- 추천: 통일된 API 인터페이스 (예: APIYI apiyi.com) 사용. 한 번의 등록으로 여러 모델을 전환하며 테스트 가능
- 각 모델별로 별도의 계정 등록 및 다중 API 키 관리는 피하세요.
💰 비용 최적화 팁: 예산이 민감한 프로젝트의 경우, APIYI apiyi.com 플랫폼을 통해 오픈소스 모델 API를 호출하는 것이 가장 가성비 높은 솔루션입니다. 플랫폼은 유연한 과금 방식을 제공하며, 오픈소스 모델 호출 비용은 클로즈드 소스 모델의 공식 가격보다 훨씬 저렴합니다.
자주 묻는 질문
Q1: Qwen3.5-Flash는 경량 모델이라고 하는데, 왜 API 응답이 느린가요?
Qwen3.5-Flash는 추론 시 30억 개의 파라미터만 활성화하지만, 기본적으로 100만 토큰의 컨텍스트 윈도우를 지원하며 텍스트, 이미지, 비디오를 포함한 멀티모달 처리 능력과 내장 도구 호출 기능이 통합되어 있습니다. 이러한 "숨겨진 비용" 때문에 실제 연산량은 동일 파라미터 수의 순수 텍스트 모델보다 훨씬 높습니다. 여기에 알리바바 클라우드의 GPU 자원 부족이라는 배경이 더해져 대기 시간이 길어지면서 체감 지연 시간이 늘어나는 것입니다.
Q2: 오픈소스 모델을 서드파티 플랫폼에 배포하면 성능이 저하되나요?
아닙니다. SiliconFlow, Together AI와 같은 전문 서드파티 추론 플랫폼은 원본 오픈소스 가중치를 사용하며, 최적화된 추론 엔진과 함께 사용하여 원본과 동일한 성능을 내고, 오히려 추론 속도가 더 빠릅니다. APIYI apiyi.com 플랫폼을 통해 다양한 채널의 추론 품질과 속도를 빠르게 비교하고 최적의 솔루션을 선택할 수 있습니다.
Q3: 알리바바 클라우드의 연산 능력 문제는 언제쯤 완화될까요?
알리바바 클라우드 고위 관계자의 공개 발언에 따르면, GPU 공급 부족 현상은 앞으로 2~3년 동안 지속될 것으로 예상됩니다. 단기적으로 알리바바 클라우드는 대규모 증설보다는 Aegaeon과 같은 리소스 풀링 기술을 통해 기존 GPU 활용률을 높이는 데 집중할 것으로 보입니다. 따라서 개발자들은 플랫폼 최적화를 기다리기보다, 공식 API 직접 연결 또는 서드파티 추론 플랫폼과 같이 더 적합한 호출 방안을 능동적으로 선택하는 것이 좋습니다. APIYI apiyi.com을 통해 다양한 모델의 호출 속도를 무료로 테스트해 볼 수 있습니다.
요약: 알리바바 클라우드 Qwen3.5 API 응답 지연에 대한 대응 전략
알리바바 클라우드 Qwen3.5 API의 응답 지연 근본 원인은 전 세계적인 GPU 연산 능력 공급 부족이며, 여기에 모델 아키텍처의 높은 연산량 소모, 멀티 테넌트 환경에서의 자원 경쟁 등의 요인이 더해집니다. 알리바바 클라우드를 통해 GLM-5, Kimi-K2.5, MiniMax-M2.5 등 서드파티 모델을 호출할 때 발생하는 끊김 현상 역시 본질적으로 같은 이유입니다. 즉, 알리바바 클라우드는 자체 모델에 연산 능력을 우선적으로 할당하며, 서드파티 모델은 부차적인 자원 배분을 받게 됩니다.
3가지 핵심 제안:
- 폐쇄형 모델은 공식 API 직접 연결: GLM-5는 Zhipu AI API, Kimi-K2.5는 Moonshot AI API, MiniMax-M2.5는 MiniMax API를 사용하여 중간 전달 지연을 피하세요.
- 오픈소스 모델은 서드파티 플랫폼 선택: Qwen3.5와 같은 오픈소스 모델은 전문 추론 플랫폼에서 알리바바 클라우드 공식 API보다 더 나은 성능을 보일 수 있습니다.
- 통합 관리는聚合平台 활용: 여러 모델을 동시에 사용해야 한다면, APIYI apiyi.com을 통해 단일 인터페이스로 모든 모델을 호출하여 효율성과 관리 편의성을 모두 잡는 것을 추천합니다.
연산 능력 부족은 향후 2~3년간 업계 전반의 상수가 될 것입니다. 클라우드 플랫폼의 증설을 수동적으로 기다리기보다는, 최적의 플랫폼과 모델 조합을 선택하는 능동적인 호출 전략을 통해 AI 애플리케이션 경험을 향상시키는 것이 최선의 경로입니다.
작성자: APIYI Team | 더 많은 AI 모델 API 호출 팁과 최신 튜토리얼, 무료 테스트 기회는 APIYI apiyi.com을 방문하세요.
📚 참고 자료
-
Qwen3.5 모델 시리즈 공식 문서: 알리바바 클라우드 통의천문(Qwen) 모델 기술 사양
- 링크:
github.com/QwenLM/Qwen3.5 - 설명: 전체 모델 파라미터, 벤치마크 테스트 및 사용 가이드 포함
- 링크:
-
알리바바 클라우드 컴퓨팅 파워 가격 조정 공지: 2026년 4월부터 AI 컴퓨팅 파워 가격 인상
- 링크:
www.alibabacloud.com - 설명: 컴퓨팅 파워 수요-공급 불균형에 대한 공식 설명
- 링크:
-
GLM-5 기술 보고서: Zhipu AI 플래그십 모델 기술 세부 정보
- 링크:
github.com/THUDM/GLM-5 - 설명: 7440억 개 파라미터 MoE 아키텍처 및 Agent 모드 설명
- 링크:
-
Kimi-K2.5 공식 문서: Moonshot AI의 조 단위 파라미터 모델
- 링크:
platform.moonshot.ai/docs/guide/kimi-k2-5-quickstart - 설명: Agent Swarm 기능 및 API 연동 가이드
- 링크:
-
MiniMax-M2.5 기술 블로그: 최신 오픈소스 모델 상세 설명
- 링크:
www.minimax.io/news/minimax-m25 - 설명: 성능 벤치마크, 배포 권장 사항 및 비용 분석
- 링크: