저자 주: GPT-5.4일까요, 아니면 Claude Opus 4.6일까요? 2026년 가장 주목해야 할 두 플래그십 AI 모델이 정면 대결을 펼칩니다. 본문에서는 Chatbot Arena, SWE-bench, ARC-AGI-2, 그리고 OpenClaw PinchBench의 최신 실측 데이터를 바탕으로 코딩, 추론, 에이전트 작업, 가성비라는 네 가지 핵심 차원에서 명확한 선택 가이드를 제시합니다.
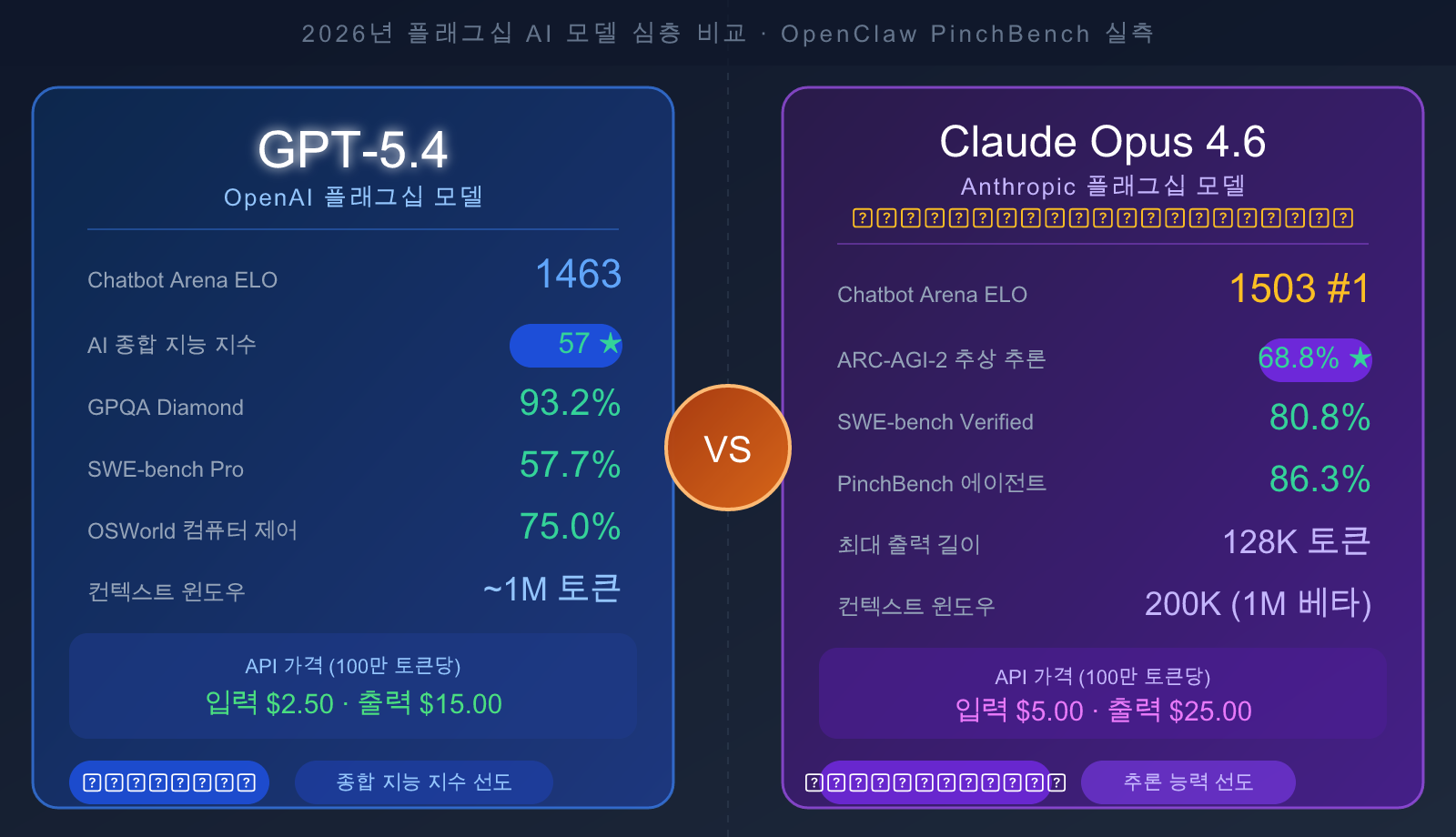
GPT-5.4 vs Claude Opus 4.6: 핵심 차이점 한눈에 보기
플래그십 AI 모델을 선택할 때 가장 중요한 몇 가지 핵심 지표를 정리했습니다.
| 비교 항목 | GPT-5.4 | Claude Opus 4.6 |
|---|---|---|
| 출시일 | 2025년 말 | 2026년 2월 |
| Chatbot Arena ELO | 1463 | 1503 (#1) |
| AI 종합 지능 지수 | 57 | 53 |
| API 입력 가격 | $2.50/M tokens | $5.00/M tokens |
| API 출력 가격 | $15.00/M tokens | $25.00/M tokens |
| 컨텍스트 윈도우 | ~1M tokens | 200K (1M Beta) |
| 최대 출력 길이 | — | 128K tokens |
| 상태 | 서비스 중 | 서비스 중 |
핵심 결론: GPT-5.4는 종합 지능 지수가 더 높고 가격이 약 50% 저렴합니다. 반면 Claude Opus 4.6은 Chatbot Arena 사용자 만족도에서 세계 1위를 기록하고 있으며, 복잡한 코딩 및 에이전트 작업에서 더 강력한 성능을 보여줍니다.
🎯 빠른 제안: 가격에 민감한 개발자라면 GPT-5.4의 가성비가 더 뛰어납니다. 만약 복잡한 코드 생성이나 긴 문서 처리가 필요한 프로젝트라면 Opus 4.6에 투자할 가치가 충분합니다. APIYI(apiyi.com)를 통해 두 모델을 동시에 연결하여 직접 비교 테스트해 보시는 것을 추천드려요. 이 플랫폼은 통합 API 인터페이스로 빠른 모델 전환을 지원합니다.
권위 있는 벤치마크 테스트: GPT-5.4 vs Claude Opus 4.6 전방위 비교
추론 및 지식 능력 비교
| 벤치마크 | GPT-5.4 | Claude Opus 4.6 | 설명 |
|---|---|---|---|
| GPQA Diamond (대학원 수준 과학 문제) | 93.2% | 91.3% | GPT-5.4 승 |
| MMLU (백과사전 지식) | 89.6% | 91.1% | Opus 4.6 승 |
| ARC-AGI-2 (추상적 추론) | 52.9% | 68.8% | Opus 4.6 큰 폭으로 앞섬 |
| BigLaw Bench (법률 전문) | — | 90.2% | Opus 4.6 특화된 강점 |
| MRCR v2 (1M 롱 컨텍스트) | — | 76% | Opus 4.6 초장문 문서 처리 우위 |
| GDPval-AA ELO (전문 작업) | 1462 | 1606 | Opus 4.6 확연히 우세 |
해석: GPT-5.4는 과학적 추론(GPQA Diamond)에서 미세한 우위를 점하고 있지만, 추상적 추론(ARC-AGI-2에서 16퍼센트 포인트 리드), 전문 지식 작업 및 롱 컨텍스트 처리 능력에서는 Claude Opus 4.6이 더 강력한 성능을 보여줍니다.
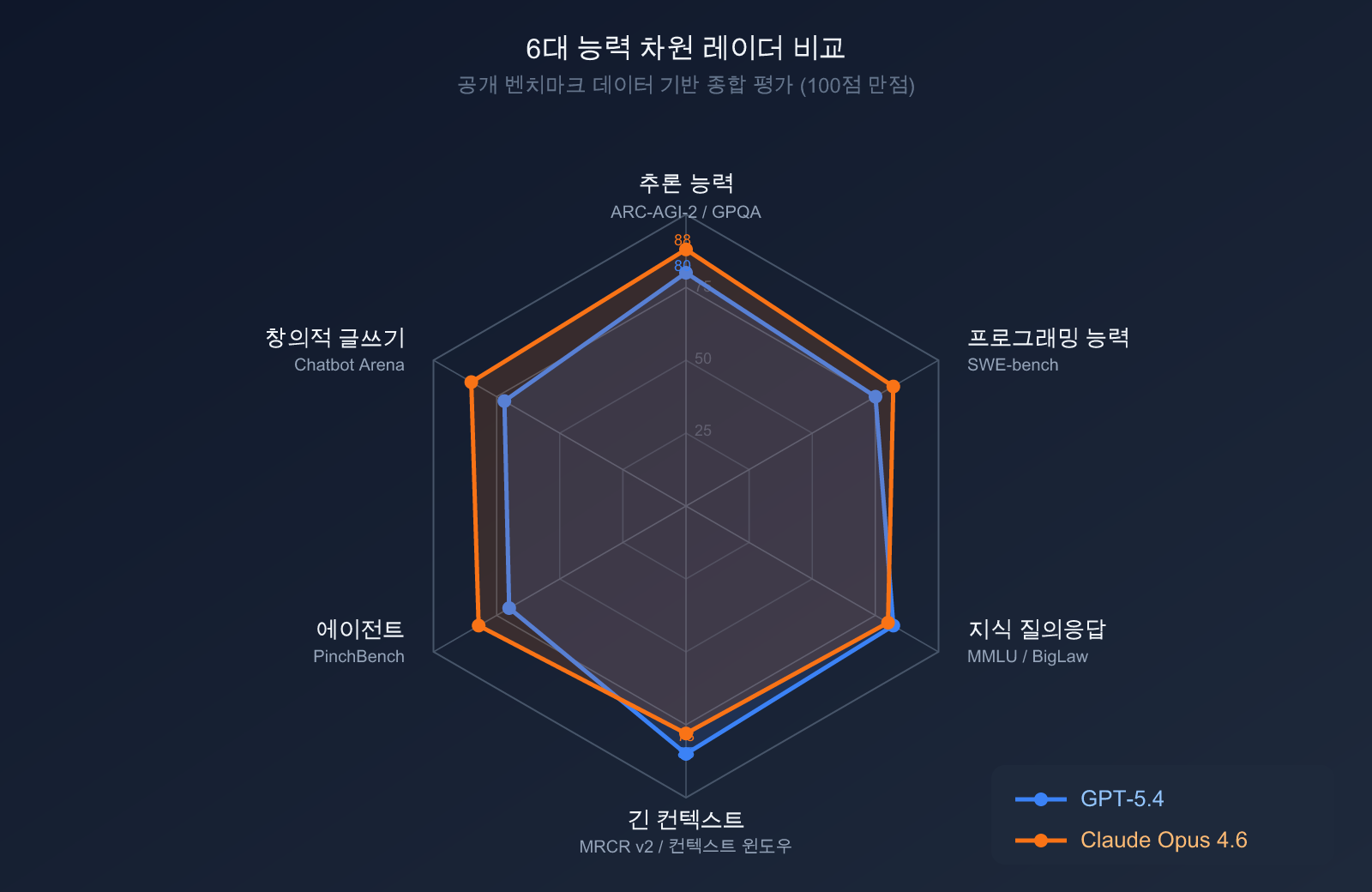
코딩 및 에이전트 능력 비교
| 벤치마크 | GPT-5.4 | Claude Opus 4.6 | 설명 |
|---|---|---|---|
| SWE-bench Verified (실제 코드 수정) | ~77.2% | 80.8% | Opus 4.6 승 |
| SWE-bench Pro (전문가급 코드) | 57.7% | ~45% | GPT-5.4 승 |
| Terminal-Bench 2.0 (터미널 조작) | 64.7% | 65.4% | Opus 4.6 미세하게 승 |
| OSWorld (컴퓨터 제어) | 75.0% | 72.7% | GPT-5.4 미세하게 승 |
| BrowseComp (웹 검색 연구) | 77.9% | 84.0% | Opus 4.6 승 |
| OpenRCA (근본 원인 분석) | — | 34.9% | Opus 4.6 특화된 강점 |
해석: 두 대규모 언어 모델은 코딩 분야에서 각각의 강점이 다릅니다. 일상적인 코드 수정(SWE-bench Verified)은 Opus 4.6이 더 강하고, 기업용 복잡한 코드(SWE-bench Pro)는 GPT-5.4가 앞서고 있습니다. 컴퓨터 제어는 GPT-5.4가 근소하게 앞섰지만, Opus 4.6은 웹 연구와 근본 원인 분석에서 뛰어난 성과를 냈습니다.
💡 개발자를 위한 팁: 제품 출시를 위한 코드 생성 작업이라면, 먼저 APIYI(apiyi.com)의 통합 인터페이스를 통해 두 모델을 각각 테스트해 보시길 권장해요. 여러분의 구체적인 코드베이스 특징에 맞춰 결정하는 것이 좋으며, 비용은 Anthropic이나 OpenAI 공식 API를 직접 호출하는 것보다 20~40% 정도 저렴합니다.
OpenClaw 에이전트 실전: PinchBench 최신 테스트 데이터
OpenClaw와 PinchBench란 무엇인가요?
OpenClaw는 오픈소스이며 직접 호스팅 가능한 AI 에이전트 플랫폼입니다(Claude Code와 유사). 터미널 접속, 다중 파일 편집을 지원하며 WhatsApp, Telegram, Slack 등 50개 이상의 도구와 통합할 수 있습니다. 오스트리아의 개발자 Peter Steinberger가 2025년 11월에 제작했으며, 현재 GitHub에서 빠르게 성장하고 있습니다.
PinchBench는 Kilo.ai에서 개발한 OpenClaw 에이전트 전용 평가 벤치마크입니다. 기존의 벤치마크가 단일 문답을 측정하는 것과 달리, 실제 환경에서의 다단계 작업 수행 능력을 테스트합니다:
- 회의 일정 예약 및 캘린더 관리
- 다중 파일 코드 프로젝트 작성
- 이메일 분류 처리 및 파일 관리
- 웹 리서치 및 정보 통합
이는 현재 실제 AI 에이전트 사용 시나리오에 가장 가까운 테스트 중 하나로 평가받습니다.
PinchBench 리더보드 (2026년 3월 13일 기준, 47개 모델, 277회 실행)
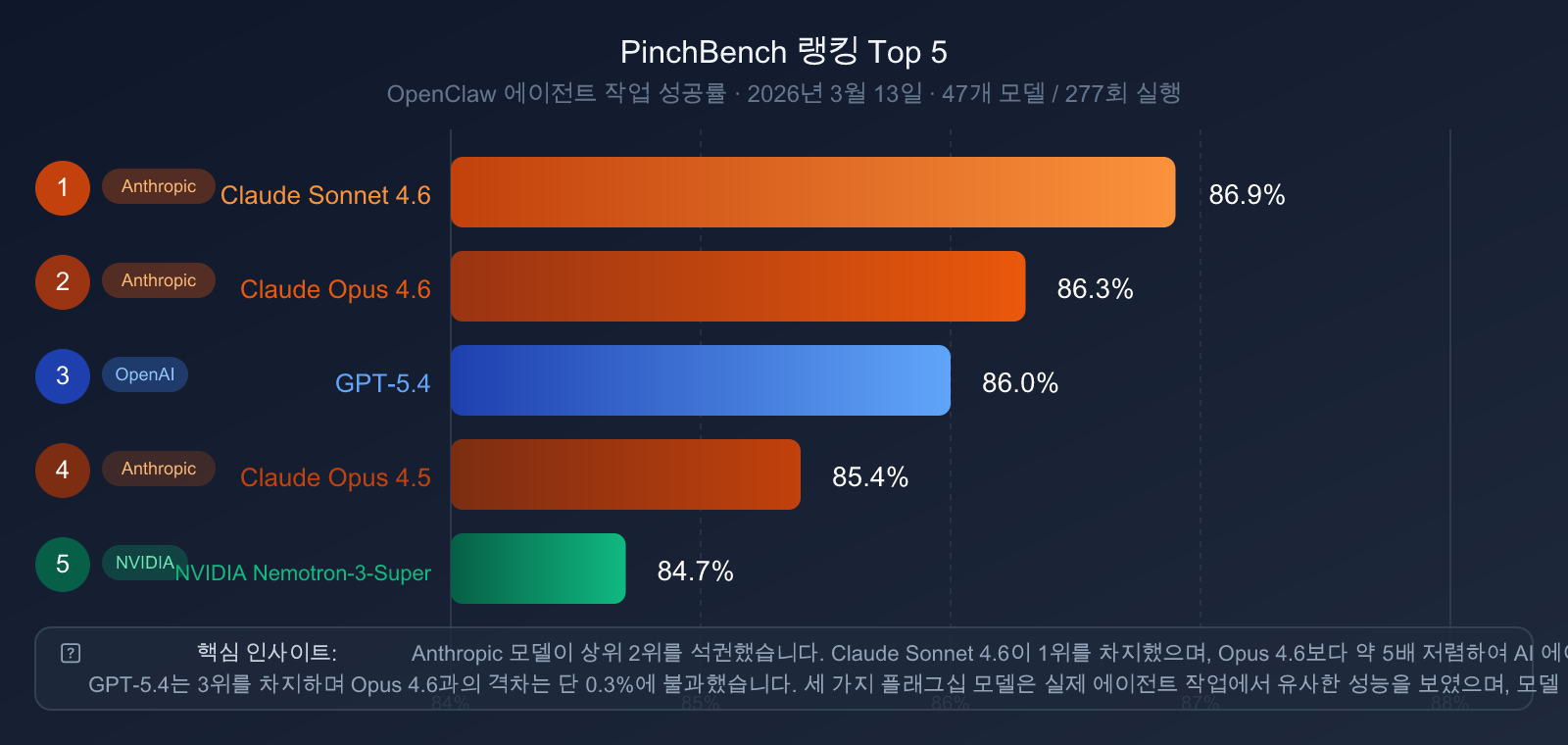
| 순위 | 모델 | PinchBench 성공률 |
|---|---|---|
| 🥇 1 | Claude Sonnet 4.6 | 86.9% |
| 🥈 2 | Claude Opus 4.6 | 86.3% |
| 🥉 3 | GPT-5.4 | 86.0% |
| 4 | Claude Opus 4.5 | 85.4% |
| 5 | NVIDIA Nemotron-3-Super | 84.7% |
주요 발견:
- Claude 시리즈의 상위권 독점: Sonnet 4.6과 Opus 4.6이 각각 1, 2위를 차지하며 Anthropic이 에이전트 엔지니어링 분야에서 체계적인 우위를 점하고 있음을 보여주었습니다.
- GPT-5.4의 3위 기록: Opus 4.6과의 차이가 단 0.3% 포인트에 불과할 정도로 격차가 매우 좁습니다.
- 가성비의 정점: Opus 4.6보다 약 5배 저렴한 Claude Sonnet 4.6이 PinchBench에서 오히려 더 높은 순위를 기록했습니다. 무조건 비싼 모델이 좋은 것은 아니라는 점을 시사합니다.
- Claude Sonnet 4.6의 재발견: OpenClaw와 같은 에이전트 작업에서 Sonnet 4.6은 최고의 가성비를 제공하는 선택지입니다.
🔍 에이전트 프로젝트 추천: OpenClaw 기반의 AI 에이전트를 구축 중이라면 상위 3개 모델(Sonnet 4.6, Opus 4.6, GPT-5.4)의 성능 차이가 1% 미만이므로, **APIYI(apiyi.com)**를 통해 필요에 따라 모델을 선택해 보세요. 작업 유형에 맞춰 모델을 동적으로 선택하면 비용을 절감하면서도 높은 성공률을 유지할 수 있습니다.
Chatbot Arena ELO: 사용자가 직접 뽑은 최강의 모델
Chatbot Arena(구 LMSYS)는 현재 가장 권위 있는 AI 모델 사용자 선호도 순위로, 수백만 건의 실제 대화 블라인드 테스트 투표를 통해 ELO 점수를 산출합니다.
2026년 2월 최신 순위 (Top 5):
| 순위 | 모델 | ELO 점수 |
|---|---|---|
| 🥇 1 | Claude Opus 4.6 | 1503 |
| 2 | Grok-4.1-Thinking | 1482 |
| 🥉 3 | GPT-5.4 | 1463 |
| 4 | Gemini 3 Pro | ~1445 |
| 5 | Claude Sonnet 4.6 | ~1438 |
Claude Opus 4.6는 GPT-5.4보다 ELO 점수에서 40점 앞서며 선두를 달리고 있습니다. 특히 멀티턴 대화, 스타일 제어, 창의적 글쓰기 등의 영역에서 두각을 나타내고 있죠. Chatbot Arena의 평가 체계에서 이 정도의 격차는 상당히 유의미한 우위라고 볼 수 있습니다.
GPT-4.5 (과거 참고용): OpenAI가 2025년 2월에 출시했던 GPT-4.5(코드명 "Orion")는 감성 지능과 대화 품질에 집중하며 출시 초기 잠시 Chatbot Arena 1위를 차지하기도 했습니다. 하지만 이 모델은 2025년 7월 14일부로 API 서비스가 종료되었고, ChatGPT 내에서도 2025년 8월에 완전히 퇴장했습니다. 현재는 GPT-5.4가 그 자리를 이어받아 모든 능력치에서 전작을 압도하고 있습니다.
API 가격 및 가성비: 비용에 민감한 프로젝트를 위한 선택 가이드
| 비용 항목 | GPT-5.4 | Claude Opus 4.6 | 차이 |
|---|---|---|---|
| 입력 가격 (100만 토큰당) | $2.50 | $5.00 | Opus 4.6이 2배 비쌈 |
| 출력 가격 (100만 토큰당) | $15.00 | $25.00 | Opus 4.6이 1.67배 비쌈 |
| 컨텍스트 윈도우 | ~1M tokens | 200K (1M Beta) | GPT-5.4 승 |
| 최대 출력 길이 | — | 128K tokens | Opus 4.6 승 |
| 멀티모달 지원 | ✅ 이미지 입력 | ✅ 이미지 입력 | 대등함 |
비용 추산 (일일 입력 100만 토큰 + 출력 20만 토큰 처리 기준):
- GPT-5.4: 약 $5.50/일 (월 평균 $165)
- Claude Opus 4.6: 약 $10.00/일 (월 평균 $300)
💰 비용 최적화 방안: 트래픽이 많거나 예산이 한정된 프로젝트라면, APIYI(apiyi.com)에서 일상적인 작업은 Claude Sonnet 4.6을 사용하고, 가장 강력한 추론 능력이 필요한 경우에만 Opus 4.6을 호출하는 방식을 추천합니다. 이렇게 하면 API 비용을 60~75%까지 절감할 수 있어요. APIYI는 하나의 계정으로 여러 모델의 통합 결제를 지원하여 세밀한 비용 관리가 가능합니다.
추천 시나리오: GPT-5.4 vs Claude Opus 4.6, 무엇을 선택해야 할까요?
GPT-5.4를 추천하는 상황
✅ 가성비 높은 범용 작업
- 예산은 한정적이지만 플래그십급 성능이 필요한 경우
- 일상적인 콘텐츠 제작, 고객 응대(CS) 답변, 정보 추출
- 월 모델 호출 비용이 $500를 초과할 때 비용 절감 효과가 뚜렷함
✅ 과학 연구 및 기술 질의응답
- GPQA Diamond 지표에서 앞서며, 박사 수준의 과학적 추론 능력이 더 강력함
- 화학, 물리, 생물 등 학술 분야의 전문적인 질의응답
✅ 기업용 복잡한 코드 (SWE-bench Pro 선두)
- 초대형 코드베이스의 아키텍처 수준 수정 작업
- 복잡한 의존 관계를 깊이 있게 이해해야 하는 리팩토링 작업
✅ 초장문 컨텍스트 시나리오
- 1M 토큰에 가까운 초장문 문서나 코드베이스를 처리해야 할 때
- Opus 4.6의 1M 컨텍스트는 아직 베타 단계임
Claude Opus 4.6을 추천하는 상황
✅ 프로덕션 수준의 코드 생성 및 수정
- SWE-bench Verified 80.8% 달성, 일상적인 버그 수정과 기능 개발에서 더 높은 신뢰도 제공
- BrowseComp 84%의 웹 리서치 능력으로 RAG(검색 증강 생성) 강화 애플리케이션에 적합
✅ OpenClaw와 같은 에이전트 프로젝트
- PinchBench 순위 상위권 차지, Anthropic 모델이 실제 에이전트 작업에서 시스템적으로 더 우수함
✅ 대화 품질이 중요한 서비스
- 챗봇 아레나(Chatbot Arena) ELO 1503점으로 사용자 만족도 세계 1위
- 다회차 대화의 일관성과 스타일 적응 능력이 더 뛰어남
✅ 전문 지식 업무
- ARC-AGI-2에서 16%p 앞서며 추상적 추론 능력이 더 강력함
- BigLaw Bench 90.2% 기록, 법률, 컴플라이언스, 문서 분석에서 더 높은 신뢰도 제공
✅ 긴 문서 출력
- 최대 128K 출력을 지원하여 전체 보고서나 장편 문서 생성에 적합
🎯 의사결정 제안: 두 모델은 각기 다른 강점을 가지고 있으며, 차이는 주로 특정 작업에서 나타납니다. 정식 도입 전 APIYI apiyi.com 플랫폼을 통해 A/B 테스트를 진행해 보시는 것을 추천합니다. 플랫폼에서 제공하는 통합 인터페이스를 사용하면 모델을 빠르게 전환하며 비즈니스 시나리오에 가장 적합한 선택지를 찾을 수 있습니다.
빠른 연동: 통합 API로 두 모델 동시에 사용하기
OpenAI와 Anthropic 계정을 각각 만들 필요 없이, APIYI의 통합 인터페이스를 통해 모든 주요 모델에 접속할 수 있습니다.
from openai import OpenAI
# APIYI 통합 인터페이스를 통해 GPT-5.4와 Claude Opus 4.6 지원
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1" # APIYI 통합 접속 주소
)
# Claude Opus 4.6 호출
# (참고: 실제 모델명은 플랫폼 제공 기준에 따름)
response_opus = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "user", "content": "다음 코드에서 잠재적인 버그를 분석해 주세요..."}
],
max_tokens=4096
)
# GPT-5.4 호출 (동일한 인터페이스에서 모델 이름만 변경)
response_gpt = client.chat.completions.create(
model="gpt-5-4",
messages=[
{"role": "user", "content": "다음 코드에서 잠재적인 버그를 분석해 주세요..."}
],
max_tokens=4096
)
print("Opus 4.6 결과:", response_opus.choices[0].message.content)
print("GPT-5.4 결과:", response_gpt.choices[0].message.content)
💡 연동 안내:
base_url을https://vip.apiyi.com/v1로 설정하고,api_key를 APIYI apiyi.com에서 신청한 키로 바꾸기만 하면 즉시 전환이 가능합니다. 첫 충전 시 증정 포인트가 제공되므로, 정식 서비스 적용 전에 두 모델의 실제 차이를 테스트해 보기에 좋습니다.
모델 명칭 대조표:
| 모델 | API 호출 이름 | 월평균 비용 (1억 토큰 기준) |
|---|---|---|
| Claude Opus 4.6 | claude-opus-4-6 |
약 $500+ |
| Claude Sonnet 4.6 | claude-sonnet-4-6 |
약 $100+ |
| GPT-5.4 | gpt-5-4 |
약 $250+ |
자주 묻는 질문(FAQ)
Q: GPT-4.5와 GPT-5.4는 같은 모델인가요?
아니요, 다릅니다. GPT-4.5(코드명 "Orion")는 OpenAI가 2025년 2월에 출시했던 과도기적 모델로, 감성 지능과 대화 품질에 집중했으나 가격이 매우 높았습니다(1M 토큰당 $75/$150). 이 모델은 2025년 7월 14일부로 API 서비스가 공식 종료되었습니다. 반면 GPT-5.4는 현재 OpenAI에서 판매 중인 최신 플래그십 모델로, 모든 면에서 GPT-4.5를 능가하며 가격 또한 1M 토큰당 $2.50/$15로 대폭 낮아졌습니다. 가장 강력한 OpenAI 모델을 사용하고 싶다면 GPT-5.4를 선택해야 하며, **APIYI(apiyi.com)**를 통해 간편하게 연결할 수 있습니다.
Q: OpenClaw란 무엇인가요? Cursor나 Claude Code와는 어떻게 다른가요?
OpenClaw는 오픈 소스 기반의 자가 호스팅(Self-hosted)이 가능한 AI 에이전트 플랫폼입니다. 터미널 접속, 다중 파일 코드 편집, WhatsApp/Telegram/Slack 등 50개 이상의 도구 연동을 지원하며, 스스로 새로운 기술을 생성하는 '자기 진화' 능력도 갖추고 있습니다. Cursor(상용 IDE 플러그인)나 Claude Code(Anthropic 공식 CLI)와 비교했을 때, OpenClaw의 핵심 장점은 완전한 오픈 소스이며 프라이빗 배포가 가능하다는 점입니다. 따라서 데이터 보안이 중요한 기업 환경에 적합합니다. 참고로 PinchBench는 OpenClaw 에이전트 작업에서 AI 모델의 성능을 전문적으로 측정하는 벤치마크입니다.
Q: AI 글쓰기 작업에는 어떤 모델이 더 좋나요?
Chatbot Arena ELO 점수에 따르면, Claude Opus 4.6이 사용자 선호도 테스트에서 1503점을 기록하며 세계 1위를 차지했습니다. 특히 창의적 글쓰기, 다회차 대화, 문체 적응력 면에서 매우 뛰어난 성능을 보입니다. GPT-5.4 역시 글쓰기 실력이 훌륭하지만 사용자 만족도 순위는 조금 더 낮습니다. **APIYI(apiyi.com)**를 통해 실제 작성하려는 콘텐츠로 직접 테스트해 보시는 것을 추천드려요. 글의 스타일이나 유형에 따라 결과가 달라질 수 있기 때문입니다.
Q: Claude Sonnet 4.6과 Claude Opus 4.6의 차이는 얼마나 큰가요?
PinchBench 에이전트 테스트 결과를 보면, Sonnet 4.6(86.9%)이 오히려 Opus 4.6(86.3%)보다 근소하게 높게 나타납니다. Chatbot Arena ELO 점수에서는 Opus 4.6이 약 1503점, Sonnet 4.6이 약 1438점으로 65점 정도 차이가 납니다. 대부분의 프로그래밍이나 분석 작업에서는 가성비가 뛰어난 Sonnet 4.6(Opus 4.6 가격의 약 20%)이 더 나은 선택일 수 있습니다. 복잡한 추론, 방대한 문서 처리, 극도의 정밀도가 요구되는 상황에서만 Opus 4.6으로 업그레이드하는 것을 권장합니다.
요약: 2026년 플래그십 모델, 어떻게 선택해야 할까요?
| 요구 상황 | 추천 모델 | 핵심 이유 |
|---|---|---|
| 일상적인 개발 + 비용 절감 | GPT-5.4 | 50% 더 저렴하며, 종합적인 능력이 뛰어남 |
| 복잡한 코드 수정(SWE-bench) | Claude Opus 4.6 | 80.8%의 성능으로 GPT-5.4(77.2%)에 앞섬 |
| AI 에이전트 작업(OpenClaw) | Claude Sonnet 4.6 | PinchBench 1위, Opus보다 훨씬 저렴함 |
| 대화형 서비스 / 사용자 만족도 | Claude Opus 4.6 | Chatbot Arena ELO 1위 (1503점) |
| 과학 연구 / 학술 질의응답 | GPT-5.4 | GPQA Diamond 93.2%로 소폭 앞섬 |
| 초장문 문서 분석 | Claude Opus 4.6 | 128K 출력 지원 + MRCR v2 76% 달성 |
| 추상적 추론 / AGI 작업 | Claude Opus 4.6 | ARC-AGI-2 68.8% vs GPT-5.4 52.9% |
핵심 요약:
- GPT-5.4는 종합 가성비가 가장 높은 선택입니다. AI 종합 지능 지수(57 vs 53)가 약간 더 높으면서도 가격은 Opus 4.6의 절반 수준입니다.
- Claude Opus 4.6은 전 세계 사용자 만족도 1위(ELO 1503) 모델로, 복잡한 코드, 에이전트 활용, 추상적 추론 분야에서 확실한 우위를 점하고 있습니다.
- 대부분의 실제 프로젝트에서 가장 합리적인 해답은 Claude Sonnet 4.6입니다. PinchBench 순위 1위이면서 가격은 Opus 4.6보다 훨씬 저렴하기 때문입니다.
"영원히 최고인 모델"은 없습니다. 여러분의 상황에 가장 잘 맞는 모델이 최고의 모델입니다.
🚀 지금 바로 테스트해보세요: APIYI(apiyi.com) 플랫폼에서는 하나의 API 키로 GPT-5.4, Claude Opus 4.6, Claude Sonnet 4.6을 모두 사용할 수 있습니다. 실제 비즈니스 데이터로 세 모델의 성능과 비용을 직접 비교해 보세요. 신규 가입 시 제공되는 테스트 크레딧으로 최적의 결정을 내릴 수 있도록 도와드립니다.
본문의 데이터 출처: Anthropic 공식 문서, OpenAI API 문서, Chatbot Arena 랭킹(2026년 2월), PinchBench 랭킹(2026년 3월 13일), Artificial Analysis 모델 비교, DigitalApplied 기술 평가. 데이터는 모델 업데이트에 따라 변동될 수 있으므로 공식 최신 문서를 참고하시기 바랍니다.
작성자: APIYI Team | 게시: AI123.dev