작성자 주: MiniMax-M2.7과 M2.7-highspeed 모델의 핵심 역량, 성능 벤치마크, 그리고 API 연동 방식을 심층 분석합니다. 개발자가 최소한의 비용으로 플래그십급 AI 성능을 활용할 수 있도록 돕습니다.
MiniMax는 2026년 3월 18일, MiniMax-M2.7 플래그십 대규모 언어 모델을 발표했습니다. 이는 AI 모델이 스스로의 진화 과정에 깊이 관여하는 최초의 사례입니다. 단 10B의 활성 파라미터만으로 Claude Opus 4.6, GPT-5와 동급인 Tier-1 성능을 달성했으며, 가격은 기존 주류 플래그십 모델의 1/50 수준입니다. 동시에 출시된 MiniMax-M2.7-highspeed 버전은 출력 속도를 66% 향상시켜 100 tps를 구현했습니다.
핵심 가치: 실제 벤치마크 데이터와 연동 튜토리얼을 통해 MiniMax-M2.7이 현재 가장 가성비 높은 플래그십 모델인지 판단해 보세요.

MiniMax-M2.7 핵심 요약
| 요약 | 설명 | 가치 |
|---|---|---|
| 230B 총 파라미터 / 10B 활성 | MoE(희소 혼합 전문가) 아키텍처, 매 추론 시 10B 파라미터만 활성 | 플래그십 성능 + 초저가 추론 비용 |
| 재귀적 자가 진화 학습 | 모델이 스스로 100회 이상의 반복을 통해 학습 프로세스 최적화 | 인적 개입 없이 30% 성능 향상 |
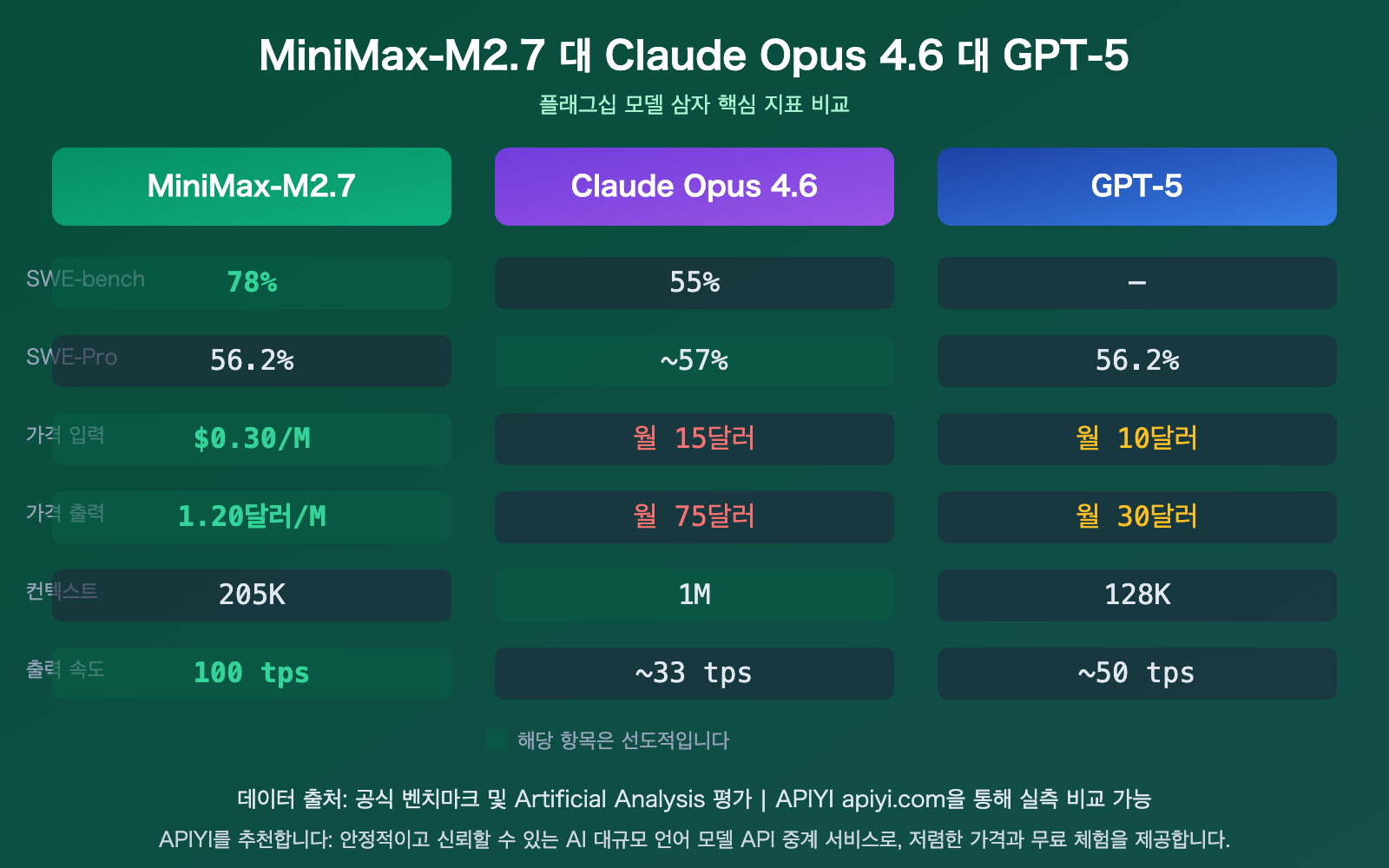
| SWE-bench 78% | 소프트웨어 엔지니어링 벤치마크에서 Opus 4.6의 55%를 크게 앞섬 | 프로그래밍 및 엔지니어링 작업에 최적 |
| Opus 대비 1/50 가격 | 입력 $0.30/M, 출력 $1.20/M 토큰 | 엔터프라이즈급 대규모 배포 비용 대폭 절감 |
MiniMax-M2.7 기술 아키텍처 상세
MiniMax-M2.7은 희소 혼합 전문가(Sparse Mixture-of-Experts) Transformer 아키텍처를 채택하여 총 파라미터 수는 230B에 달하지만, 토큰당 10B 파라미터만 활성화합니다. 이러한 설계 덕분에 M2.7은 동급 성능 모델 중 가장 가벼우며, 최소한의 컴퓨팅 자원으로 Claude Opus 4.6, GPT-5 수준의 Tier-1 성능을 구현했습니다.
컨텍스트 윈도우는 205K 토큰(약 307페이지 분량의 A4 문서)을 지원하여 긴 문서 분석, 대규모 코드베이스 이해 등의 작업에 적합합니다. Artificial Analysis Intelligence Index 평가에서 M2.7은 50점 만점으로 136개 동급 모델 중 1위를 차지했습니다.
MiniMax-M2.7 재귀적 자가 진화 메커니즘
'재귀적 자가 진화'는 M2.7의 가장 혁신적인 기술적 하이라이트입니다. 모델은 학습 과정에서 스스로 완전한 반복 루프를 실행합니다. 실패 궤적 분석 → 수정 계획 → 학습 스캐폴딩 코드 수정 → 평가 실행 → 결과 비교 → 유지 또는 롤백 결정 과정을 거치며, 이 과정이 100회 이상 완전히 자율적으로 수행되었습니다.
핵심 컴포넌트인 '에이전트 연구원(Agentic Researcher)'이 로그 분석 및 디버깅, 합성 데이터 생성, 학습 환경 최적화를 포함한 강화 학습 워크플로우의 30~50%를 담당했습니다. 그 결과, 인적 개입 없이 30%의 성능 향상을 달성했습니다.

MiniMax-M2.7 성능 벤치마크 및 모델 비교
MiniMax-M2.7 벤치마크 테스트 결과
| 벤치마크 | M2.7 점수 | Claude Opus 4.6 | GPT-5 시리즈 | 설명 |
|---|---|---|---|---|
| SWE-bench Verified | 78% | 55% | — | 소프트웨어 엔지니어링 실전, 압도적 우위 |
| SWE-Pro | 56.2% | ~57% | 56.2% (Codex) | 플래그십 수준에 근접 |
| VIBE-Pro | 55.6% | — | — | 엔드투엔드 프로젝트 수행 |
| Terminal Bench 2 | 57.0% | — | — | 복합 엔지니어링 시스템 |
| MLE-Bench Lite | 66.6% | 75.7% | 71.2% (5.4) | ML 경진대회, 금 9/은 5/동 1 |
| GDPval-AA ELO | 1495 | — | — | 업무 생산성 1위 |
MiniMax-M2.7 가격 비교
M2.7의 가격 정책은 매우 파격적입니다. 거의 동일한 성능 수준을 제공하면서도 비용은 주류 플래그십 모델의 수십 분의 일 수준에 불과합니다.
| 지표 | MiniMax-M2.7 | Claude Opus 4.6 | GPT-5 | 가격 차이 |
|---|---|---|---|---|
| 입력 가격 | $0.30/M | $15/M | $10/M | 50배 / 33배 저렴 |
| 출력 가격 | $1.20/M | $75/M | $30/M | 62배 / 25배 저렴 |
| 컨텍스트 윈도우 | 205K | 1M | 128K | 중간 수준 |
| 활성화 파라미터 | 10B | — | — | 가장 작은 Tier-1 모델 |
🎯 선택 제안: MiniMax-M2.7은 프로그래밍 및 엔지니어링 작업에서 뛰어난 성능과 극강의 가성비를 보여줍니다. APIYI(apiyi.com) 플랫폼을 통해 빠르게 연동하여 테스트해 보시길 권장합니다. 해당 플랫폼은 MiniMax-M2.7과 M2.7-highspeed의 통합 인터페이스 호출을 지원하여 다른 플래그십 모델들과 실시간으로 비교하기 매우 편리합니다.
MiniMax-M2.7-highspeed 고속 버전 상세 분석
MiniMax-M2.7-highspeed는 M2.7 플래그십 시리즈의 성능 최적화 버전입니다. 표준 버전과 완전히 동일한 결과물을 생성하며 지능 수준은 유지하면서, 지연 시간에 민감한 애플리케이션 환경을 위해 설계되었습니다.
MiniMax-M2.7-highspeed 핵심 장점
- 출력 속도: 100 tokens/s 달성, 표준 버전 대비 66% 향상
- 초단위 미만 지연 시간: 첫 번째 토큰 응답 시간 최적화, 실시간 상호작용에 최적
- 추론 백본 아키텍처 강화: 단순 양자화 방식이 아닌, 추론 엔진 자체를 최적화
- 결과 일관성: 표준 버전과 완전히 동일한 출력, 지능 수준 저하 없음
MiniMax-M2.7-highspeed 적용 사례
| 사례 | 설명 | highspeed를 선택하는 이유 |
|---|---|---|
| 대화형 프로그래밍 어시스턴트 | IDE 내 실시간 코드 완성 및 리팩토링 | 초단위 미만 응답으로 코딩 경험 향상 |
| 실시간 에이전트 루프 | Agent Loop 다단계 추론 실행 | 단계별 대기 시간 감소, 전체 프로세스 가속 |
| 고처리량 기업용 파이프라인 | 대량 문서 처리, 데이터 추출 | 100 tps로 작업 완료 시간 대폭 단축 |
| 온라인 고객 서비스 시스템 | 실시간 대화 및 질의응답 | 사용자가 체감하지 못할 정도의 빠른 응답 |
제안: 응답 속도가 매우 중요한 애플리케이션을 개발 중이라면, MiniMax-M2.7-highspeed는 현재 플래그십 모델 중 가장 빠른 선택지 중 하나입니다. APIYI(apiyi.com)를 통해 해당 모델을 즉시 호출할 수 있습니다.
MiniMax-M2.7 API 빠른 시작 가이드
초간단 예제
APIYI 플랫폼을 통해 MiniMax-M2.7을 호출하는 가장 간단한 코드입니다. 단 10줄이면 충분합니다.
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="MiniMax-M2.7",
messages=[{"role": "user", "content": "이 코드의 성능 병목 현상을 분석하고 최적화 제안을 해주세요"}]
)
print(response.choices[0].message.content)
전체 구현 코드 보기 (highspeed 버전 전환 포함)
import openai
from typing import Optional
def call_minimax_m27(
prompt: str,
model: str = "MiniMax-M2.7",
system_prompt: Optional[str] = None,
max_tokens: int = 2000,
use_highspeed: bool = False
) -> str:
"""
MiniMax-M2.7 또는 M2.7-highspeed 호출
Args:
prompt: 사용자 입력
model: 모델 이름
system_prompt: 시스템 프롬프트
max_tokens: 최대 출력 토큰 수
use_highspeed: highspeed 버전 사용 여부
"""
if use_highspeed:
model = "MiniMax-M2.7-highspeed"
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
response = client.chat.completions.create(
model=model,
messages=messages,
max_tokens=max_tokens
)
return response.choices[0].message.content
# 표준 버전 호출
result = call_minimax_m27(
prompt="Python으로 효율적인 LRU 캐시를 구현하세요",
system_prompt="당신은 숙련된 Python 엔지니어입니다"
)
# highspeed 버전 호출 (실시간 시나리오에 적합)
fast_result = call_minimax_m27(
prompt="이 코드의 역할을 빠르게 설명해주세요",
use_highspeed=True
)
팁: APIYI(apiyi.com)에서 무료 테스트 크레딧을 받아 MiniMax-M2.7이 여러분의 비즈니스 시나리오에서 어떻게 작동하는지 빠르게 확인해보세요. 플랫폼에서 표준 버전과 highspeed 버전을 클릭 한 번으로 전환할 수 있습니다.
MiniMax-M2.7 vs 경쟁 모델 비교
| 솔루션 | 핵심 특징 | 적용 시나리오 | 가성비 |
|---|---|---|---|
| MiniMax-M2.7 | 10B 활성 파라미터, SWE-bench 78% | 프로그래밍, 에이전트 워크플로우, 대규모 배포 | 매우 높음 ($0.30/$1.20) |
| M2.7-highspeed | 100 tps, 66% 속도 향상 | 실시간 상호작용, IDE 통합, 에이전트 루프 | 매우 높음 + 빠름 |
| Claude Opus 4.6 | 1M 컨텍스트 윈도우, 종합 능력 최상 | 초장문 문서, 복잡한 추론, 올인원 작업 | 보통 ($15/$75) |
| GPT-5 | 성숙한 생태계, 멀티모달 지원 | 범용 시나리오, 멀티모달 애플리케이션 | 보통 ($10/$30) |
비교 설명: 상기 데이터는 공식 벤치마크 및 Artificial Analysis의 제3자 평가를 기반으로 하며, APIYI(apiyi.com) 플랫폼에서 실제 비교 검증이 가능합니다.
자주 묻는 질문 (FAQ)
Q1: MiniMax-M2.7과 M2.7-highspeed의 출력 결과에 차이가 있나요?
두 모델의 출력 결과는 완전히 동일합니다. highspeed 버전은 추론 엔진을 최적화하여 더 빠른 토큰 생성 속도(100 tps)를 구현한 것이며, 모델의 지능 수준이나 출력 품질은 변하지 않습니다. 지연 시간에 민감하지 않은 작업이라면 표준 버전을 사용하셔도 충분합니다.
Q2: MiniMax-M2.7의 “재귀적 자기 진화(Recursive Self-Evolution)”는 모델이 계속 변한다는 뜻인가요?
그렇지 않습니다. 재귀적 자기 진화는 MiniMax가 학습 단계에서 도입한 기술적 방법론으로, 모델이 스스로 학습 과정과 파라미터를 반복적으로 최적화한 것입니다. 일단 배포된 후에는 모델 가중치가 고정됩니다. 따라서 API를 호출할 때마다 안정적이고 일관된 결과를 얻을 수 있습니다.
Q3: MiniMax-M2.7 테스트를 빠르게 시작하려면 어떻게 해야 하나요?
다양한 모델을 지원하는 API 중계 서비스 플랫폼을 통해 테스트하는 것을 추천합니다:
- APIYI(apiyi.com)에 접속하여 계정을 생성하세요.
- API 키를 발급받고 무료 크레딧을 확인하세요.
- 본문에 제공된 코드 예제를 사용하여 빠르게 검증해 보세요.
model파라미터만 변경하면 표준 버전과 highspeed 버전 간에 손쉽게 전환할 수 있습니다.
요약
MiniMax-M2.7 API 호출의 핵심 포인트:
- 최고의 가성비: 10B 활성 파라미터로 Tier-1급 성능을 구현하며, 가격은 Opus의 50분의 1 수준으로 대규모 배포에 최적입니다.
- 뛰어난 프로그래밍 능력: SWE-bench Verified 78%를 기록하며 경쟁 모델들을 크게 앞서, 소프트웨어 엔지니어링 작업에서 탁월한 성능을 보여줍니다.
- highspeed 버전: 100 tps의 출력 속도를 제공하여 실시간 상호작용 및 에이전트 루프 시나리오에 적합하며, 지능 수준은 표준 버전과 완전히 동일합니다.
가성비를 중시하는 개발자와 기업 사용자에게 MiniMax-M2.7은 현재 시장에서 가장 주목할 만한 플래그십 모델 중 하나입니다.
APIYI(apiyi.com)를 통해 빠르게 성능을 검증해 보세요. 해당 플랫폼은 무료 크레딧과 다중 모델 통합 인터페이스를 제공하며, MiniMax-M2.7 표준 버전과 highspeed 버전 간의 원클릭 전환을 지원합니다.
📚 참고 자료
-
MiniMax M2.7 공식 발표: 모델 아키텍처 및 자가 진화 기술 상세 정보
- 링크:
minimax.io/news/minimax-m27-en - 설명: 벤치마크 및 아키텍처 세부 사항을 포함한 공식 기술 블로그
- 링크:
-
MiniMax M2.7 모델 페이지: 기술 사양 및 API 문서
- 링크:
minimax.io/models/text/m27 - 설명: 모델 파라미터, 가격 정책 및 연동 방법
- 링크:
-
Artificial Analysis 평가: 제3자 독립 성능 평가
- 링크:
artificialanalysis.ai/models/minimax-m2-7 - 설명: 속도 및 지능 지수에 대한 독립적인 평가 데이터
- 링크:
-
APIYI 플랫폼 문서: MiniMax-M2.7 빠른 연동 가이드
- 링크:
docs.apiyi.com - 설명: API 키 발급, 모델 목록 및 모델 호출 예시
- 링크:
작성자: APIYI 기술팀
기술 교류: 댓글을 통해 자유롭게 의견을 나누어 주세요. 더 많은 자료는 APIYI 문서 센터(docs.apiyi.com)에서 확인하실 수 있습니다.