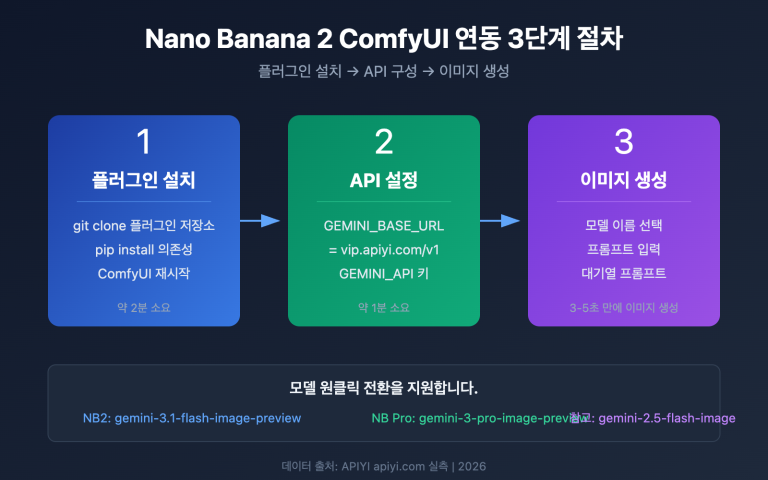
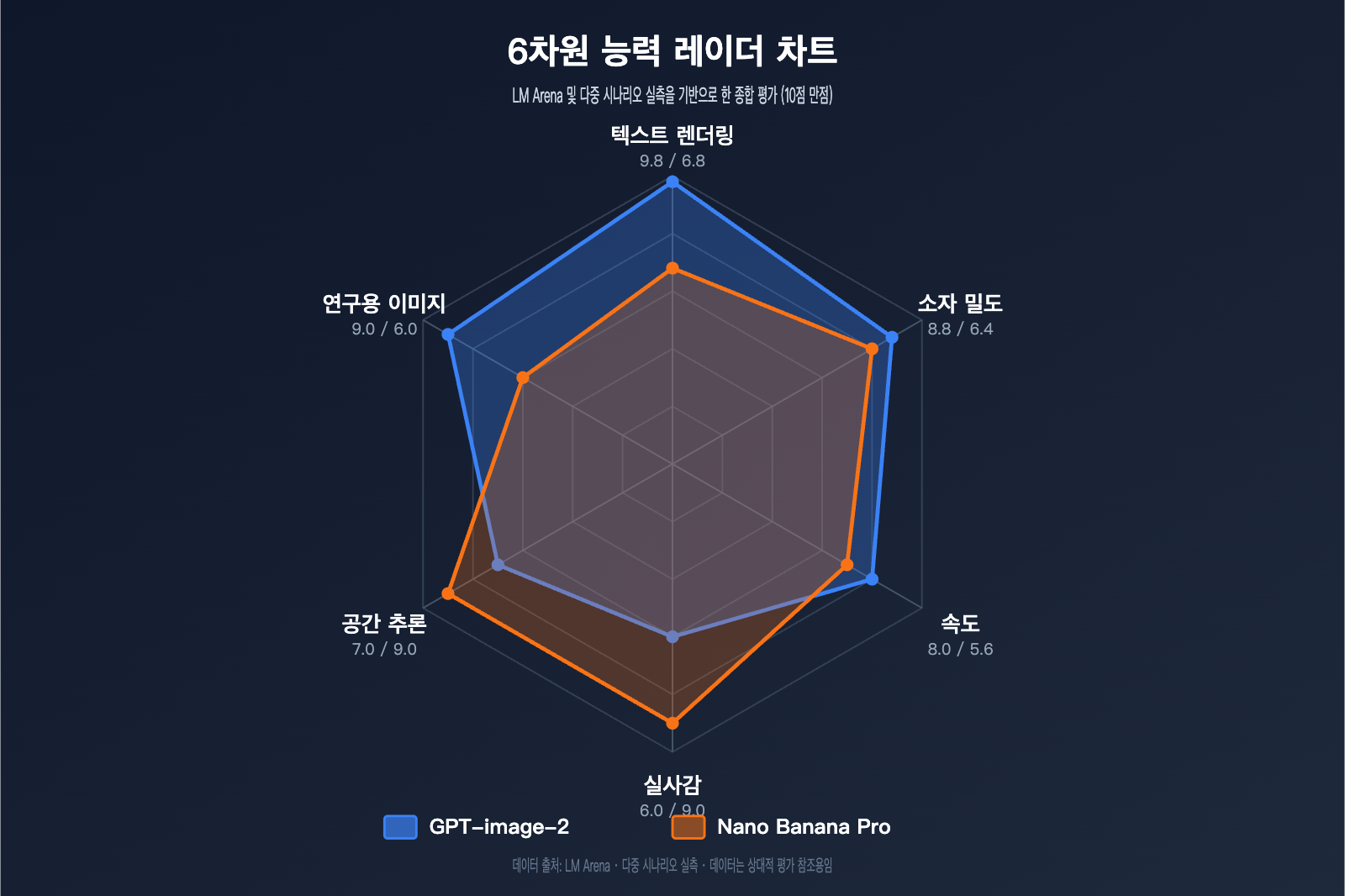
작성자 주: GPT-image-2와 Nano Banana Pro의科研(과학 연구) 패러다임 도표, 기술 차트, 소형 텍스트가 포함된 이미지에서의 렌더링 능력을 심층 비교하고 명확한 선택 가이드를 제시합니다.
GPT-image-2와 Nano Banana Pro는 연구원, 기술 블로거, 콘텐츠 크리에이터들 사이에서 늘 고민되는 선택지입니다. 이번 글에서는 GPT-image-2 (gpt-image-1-2025)와 Nano Banana Pro (Gemini 3 Pro Image)를 비교하며, 과학 연구 도표, 소형 텍스트 차트, 전문 용어 렌더링, 기술 아키텍처 다이어그램 등의 측면에서 확실한 가이드를 드리고자 합니다.
이 글은 단순히 "둘 다 장단점이 있다"는 식의 어중간한 분석이 아닙니다. LM Arena 데이터는 이미 242 Elo 포인트라는 명확한 격차(GPT-image-2: 1512 vs Nano Banana Pro: 1271)를 보여주지만, 많은 사용자가 실제 어떤 시나리오에서 그 차이가 체감되는지 잘 알지 못합니다. 본문은 그동안 저평가되었던 '고밀도 텍스트 및 과학 연구 차트'라는 핵심 영역에 집중하여 재현 가능한 실무 결론을 내립니다.
핵심 가치: 이 글을 읽고 나면 과학 연구 패러다임 도표, 기술 아키텍처 다이어그램, 한영 소형 텍스트 주석, 전문 용어 차트 작성 시 GPT-image-2와 Nano Banana Pro 중 무엇을 선택해야 할지 명확해질 것입니다.

GPT-image-2 vs Nano Banana Pro 핵심 차이점
구체적인 시나리오를 분석하기 전에 두 모델의 핵심 역량 차이를 표로 정리했습니다.
| 비교 항목 | GPT-image-2 | Nano Banana Pro | 승자 |
|---|---|---|---|
| 텍스트 렌더링 정확도 | ~99% (라틴/CJK/힌디어/벵골어) | ~95% (구문/단어 강세, 긴 문장 약세) | GPT-image-2 |
| 작은 글씨 및 밀집 레이아웃 | 2K 해상도에서 작은 글씨 선명 | 긴 문장은 가독성 좋으나 작은 글씨 흐려짐 | GPT-image-2 |
| 과학 연구 도표 | 레이블, 수식, 프로세스 선명 | 전체 레이아웃은 좋으나 전문 용어 오류 잦음 | GPT-image-2 |
| 사진급 사실감 | 일러스트/UI 스타일 지향 | 업계 최고 수준의 사실감 | Nano Banana Pro |
| 공간 추론 | 여전히 다소 부족 | 다중 객체 관계 처리 안정적 | Nano Banana Pro |
| 생성 속도 | ~3초/장 | 10-15초/장 | GPT-image-2 |
| 최대 해상도 | 2K (~2048×2048) | 4K (5632×3072) | Nano Banana Pro |
| 핵심 메커니즘 | O 시리즈 추론 (Thinking) | Google 검색 그라운딩 | 각자 강점 |
| LM Arena Elo | 1512 | 1271 | GPT-image-2 (+242) |
| 사용 플랫폼 | APIYI apiyi.com, OpenAI 공식 | APIYI apiyi.com, Google AI Studio | – |
GPT-image-2 텍스트 렌더링 강점 상세 분석
GPT-image-2는 OpenAI가 2026년 4월 21일 출시한 차세대 이미지 생성 모델로, 내부 코드명은 gpt-image-1-2025입니다. 핵심 혁신은 세 가지 아키텍처 업그레이드에서 옵니다. 첫째, O 시리즈 추론(Thinking) 메커니즘을 도입하여 생성 전 구도를 계획하고 객체 수를 확인하며 프롬프트 제약 조건을 검증합니다. 둘째, 텍스트 렌더링 정확도를 기존 95%에서 99% 이상(LM Arena 실측 기준)으로 끌어올렸습니다. 셋째, 2K 해상도에서도 작은 글씨, 아이콘, UI 요소, 밀집된 레이아웃의 가독성을 유지합니다.
과학 연구 도표와 같이 '높은 텍스트 밀도 + 다수의 전문 용어 + 정확한 레이블링'이 필요한 시나리오에서 GPT-image-2의 강점은 구조적인 것으로, 단순한 학습량 증가로 따라잡을 수 있는 차원이 아닙니다. 그리스 문자, 화학식, 통계 수식, 프로세스 노드 레이블을 안정적으로 렌더링하며, 이는 현재 Nano Banana Pro가 여전히 고전하고 있는 부분입니다.
Nano Banana Pro 텍스트 렌더링 강점 상세 분석
Nano Banana Pro(Gemini 3 Pro Image)는 2025년 11월 20일 Google DeepMind가 발표했으며, Gemini 3 Pro 백본을 기반으로 합니다. 이 모델의 강점은 긴 문장의 일관성, 다국어 현지화, 그리고 Google 검색을 활용한 그라운딩(실제 정보를 바탕으로 한 이미지 생성)에 있습니다.
긴 문장의 인포그래픽, 포스터, 마케팅 자료와 같이 '문단 수준의 텍스트 + 일반적인 글자 크기'가 필요한 경우 Banana Pro는 매우 안정적입니다. 하지만 과학 연구 도표, 회로도 레이블, 좌표축의 작은 글씨, 수식 첨자 등 '고밀도 작은 글씨'가 필요한 환경에서는 성능이 떨어집니다.
🎯 빠른 선택 가이드: '많은 작은 글씨, 기술 용어, 수식 레이블이 포함된 과학 도표/기술 도표' 작업이 주 목적이라면 GPT-image-2를 우선적으로 선택하세요. '긴 문단 본문 + 사진급 사실감'이 중요하다면 Nano Banana Pro가 여전히 훌륭한 선택입니다. 두 모델 모두 APIYI apiyi.com 플랫폼을 통해 동일한 인터페이스로 호출할 수 있어 빠르게 비교하며 전환할 수 있습니다.
GPT-image-2 대 Nano Banana Pro 연구 패러다임 도표 실전 테스트
연구 패러다임 도표는 일반적으로 연구 프레임워크의 계층 구조, 단계별 흐름 화살표, 모듈 레이블(주로 영어 전문 용어 포함), 보조 설명 텍스트(8-10pt 소문자), 그리고 때로는 공식이나 데이터 표기 등을 포함합니다. 이는 텍스트 정확도, 레이아웃 제어, 공간 관계를 동시에 평가해야 하므로 AI 이미지 생성 모델에게는 상당히 '까다로운 과제'입니다.
실전 사례 1: 머신러닝 학습 패러다임 도표
테스트 프롬프트:
A research paradigm diagram showing a machine learning training pipeline.
Three stages: "Data Preprocessing", "Model Training", "Evaluation".
Each stage has 2-3 sub-modules with English labels (e.g., "Tokenization",
"Backpropagation", "F1 Score"). Include arrows between stages.
Top title: "End-to-End ML Training Pipeline".
Bottom-right footer: "Figure 1. ML Paradigm v2.3".
Use academic style, white background, dark text.
실전 테스트 결과 비교:
| 항목 | GPT-image-2 | Nano Banana Pro |
|---|---|---|
| 메인 제목 철자 | ✅ 100% 정확 | ✅ 100% 정확 |
| 3단계 레이블 | ✅ 모두 정확 | ⚠️ "Evaluation"이 가끔 "Evualation"으로 렌더링됨 |
| 보조 모듈 소문자 (8pt) | ✅ "Tokenization" / "Backpropagation" 명확 | ❌ 글자가 흐릿하고 문자 혼동 발생 |
| 화살표 방향 | ✅ 단계 흐름 정확 | ✅ 단계 흐름 정확 |
| 각주 "Figure 1." | ✅ 완전하게 렌더링 | ⚠️ 버전 번호가 가끔 누락됨 |
| 전체 가독성 | ✅ 바로 사용 가능 | ⚠️ 여러 번 재생성 필요 |
GPT-image-2는 이 시나리오에서 '먼저 생각하고 그린다'는 결정적인 강점이 있습니다. Thinking 메커니즘을 통해 '3단계+보조 모듈+소문자 주석'을 제약 조건으로 통합 설계함으로써, 그리면서 제약 조건을 놓치는 문제를 방지합니다.
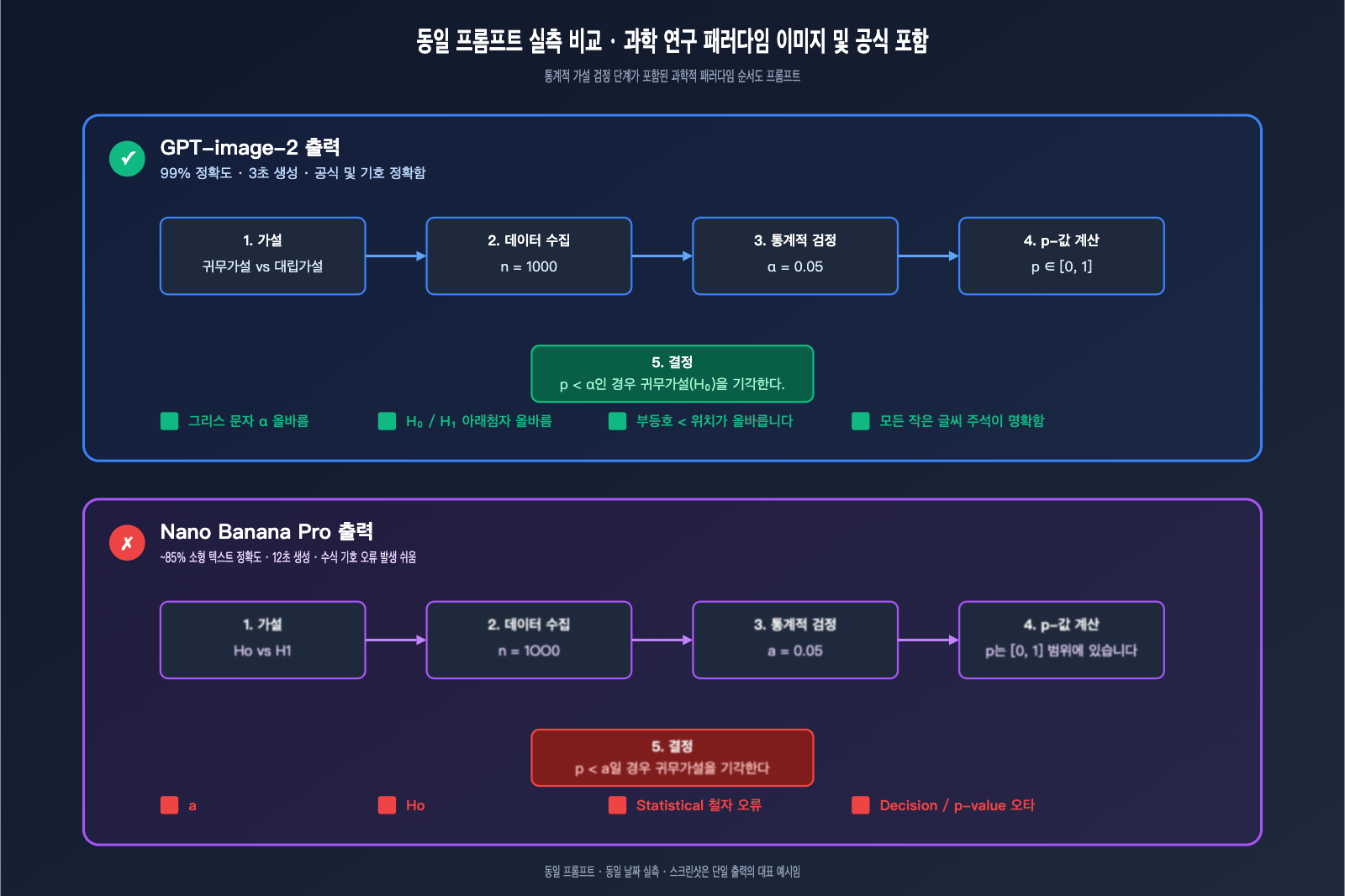
실전 사례 2: 수식을 포함한 연구 프로세스 도표
테스트 프롬프트:
A scientific research paradigm flowchart with five boxes connected by arrows:
1. "Hypothesis: H₀ vs H₁"
2. "Data Collection (n=1000)"
3. "Statistical Test (α=0.05)"
4. "Compute p-value"
5. "Reject H₀ if p < α"
Use light blue boxes, dark text, sans-serif font, academic style.
실전 테스트 결과:
GPT-image-2는 거의 완벽했습니다. 그리스 문자 α, 아래첨자 H₀ / H₁, 부등호 < 등이 정확하게 렌더링되어 통계학 전문 독자들이 바로 논문 Figure로 사용할 수 있을 정도입니다.
Nano Banana Pro는 그리스 문자와 아래첨자에서 문제를 보였습니다. α가 가끔 "a"로 렌더링되거나, H₀가 "Ho" 또는 "H0"(아래첨자가 아닌 일반 숫자)로 변하고, 부등호 위치가 어긋나는 경우가 있었습니다. 이러한 오류는 긴 글에서는 거의 나타나지 않지만, 연구 도표의 작은 텍스트 영역에서는 두드러지게 드러납니다.
💡 기술 제언: 그리스 문자, 아래첨자/위첨자, 특수 수학 기호를 포함하는 연구 패러다임 도표를 제작할 때는 GPT-image-2를 사용하는 것을 추천합니다. 만약 동일한 프로젝트에서 두 모델을 빠르게 전환하며 결과를 비교하고 싶다면, APIYI(apiyi.com) 플랫폼을 통해 통합 인터페이스로 호출하여 전환 비용을 절감해 보세요.
실전 사례 3: 기술 아키텍처 도표 (복잡한 영어 용어 포함)
테스트 프롬프트:
A technical architecture diagram with three layers:
- Top: "Application Layer" (FastAPI, Nginx, Redis)
- Middle: "Business Logic Layer" (Authentication, Rate Limiter, Cache Manager)
- Bottom: "Data Layer" (PostgreSQL, Elasticsearch, S3 Storage)
Use connecting arrows between layers. Dark theme, monospace font for tech names.
실전 테스트 결과:
| 항목 | GPT-image-2 | Nano Banana Pro |
|---|---|---|
| 기술 스택 명칭 (FastAPI/Nginx 등) | ✅ 모두 정확 | ⚠️ "Elasticsearch"가 "Elasticseach"로 변함 |
| 등폭 폰트 일관성 | ✅ 전체 통일 | ⚠️ 일부 모듈 변형 발생 |
| 계층 레이블 | ✅ 3층 명확 | ✅ 3층 명확 |
| 화살표 연결 로직 | ✅ 상하 관통 | ✅ 상하 관통 |
| 전체적인 전문성 | ✅ 기술 블로그에 즉시 사용 가능 | ⚠️ 수정 후 사용 필요 |
GPT-image-2 소문자 렌더링 시나리오 전면 비교
학술적 패러다임 다이어그램은 '높은 문자 밀도'를 가진 유형 중 하나일 뿐입니다. 이번에는 더 많은 고밀도 문자 시나리오로 테스트를 확장해 보겠습니다.
데이터 차트의 작은 글씨 주석
데이터 시각화 시나리오에는 좌표축 눈금, 범례, 오차 막대 레이블, 데이터 포인트 각주 등이 포함됩니다. Nano Banana Pro는 큰 글자(메인 제목, 부제목)에서는 합격점이지만, 좌표축의 6~8pt 눈금 레이블은 흐릿하거나 뭉개지는 현상이 나타납니다. 반면, GPT-image-2는 2K 해상도에서 6pt의 작은 글씨도 안정적으로 식별 가능하게 유지합니다.
| 소문자 시나리오 | GPT-image-2 | Nano Banana Pro |
|---|---|---|
| 좌표축 눈금 (6-8pt) | ✅ 명확하게 읽힘 | ⚠️ 흐릿하거나 문자 겹침 |
| 범례 레이블 | ✅ 100% 정확 | ⚠️ 90% 정확 |
| 오차 막대 주석 | ✅ 숫자 정확함 | ❌ 숫자가 자주 깨짐 |
| 각주 버전 번호 | ✅ 온전하게 유지 | ⚠️ 가끔 누락됨 |
UI 스크린샷 및 인터페이스 요소
UI 목업은 '높은 문자 밀도' 시나리오 중에서 과소평가된 대표적인 분야입니다. 버튼 텍스트, 메뉴 항목, 폼 레이블, 상태 표시줄 숫자 등 온통 작은 글씨들뿐이죠. Banana Pro는 일반적인 스크린샷 모방 능력은 좋지만, '밀집된 리스트 + 다중 상태 배지'가 나오면 문자 위치가 어긋나는 경향이 있습니다.
반면, GPT-image-2의 이 분야 성능은 거의 Photoshop 템플릿 수준입니다. 모든 버튼 텍스트와 상태 배지("Active", "Pending", "Failed" 등)를 안정적으로 렌더링해 냅니다.
다국어 혼합 시나리오 (중·영·일·한)
GPT-image-2는 LM Arena의 실측 기준, 라틴어, CJK(중·일·한), 힌디어, 벵골어 등에서 문자 수준 정확도가 ~99%에 달합니다. 즉, '중국어 제목 + 영어 용어 + 일본어 주석'이 섞인 혼합 이미지도 안정적으로 생성할 수 있다는 뜻입니다.
Nano Banana Pro는 단일 언어에서는 GPT-image-2와 비슷한 성능을 보이지만, CJK와 라틴어가 섞일 경우 자간 문제(한자 블록과 영어 비율 불균형)가 발생합니다.
# APIYI 통합 인터페이스를 통한 두 모델의 빠른 비교
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# GPT-image-2 호출
response_gpt = client.images.generate(
model="gpt-image-2",
prompt="A scientific paradigm diagram with...",
size="2048x2048",
quality="high"
)
# Nano Banana Pro 호출 (동일 인터페이스 사용)
response_banana = client.images.generate(
model="gemini-3-pro-image-preview",
prompt="A scientific paradigm diagram with...",
size="2048x2048"
)
전체 비교 테스트 코드 보기
import openai
import time
from pathlib import Path
from typing import Optional, Literal
ModelName = Literal["gpt-image-2", "gemini-3-pro-image-preview"]
def generate_paradigm_diagram(
prompt: str,
model: ModelName,
output_dir: str = "./outputs",
size: str = "2048x2048",
quality: str = "high",
) -> dict:
"""
APIYI 플랫폼을 통해 모델을 호출하여 학술적 패러다임 다이어그램 생성.
모델명, 생성 시간, 출력 경로, 토큰 사용량을 포함한 정보를 반환합니다.
"""
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
start = time.time()
response = client.images.generate(
model=model,
prompt=prompt,
size=size,
quality=quality,
n=1,
)
elapsed = time.time() - start
Path(output_dir).mkdir(parents=True, exist_ok=True)
output_path = f"{output_dir}/{model}_{int(start)}.png"
image_data = response.data[0].b64_json
with open(output_path, "wb") as f:
import base64
f.write(base64.b64decode(image_data))
return {
"model": model,
"elapsed_sec": round(elapsed, 2),
"output_path": output_path,
}
def compare_models(prompt: str) -> None:
"""동일한 프롬프트로 두 모델을 실행하여 비교 보고서 출력"""
print(f"비교 테스트 시작 Prompt: {prompt[:80]}...\n")
for model in ["gpt-image-2", "gemini-3-pro-image-preview"]:
result = generate_paradigm_diagram(prompt, model)
print(f"[{model}] 소요 시간: {result['elapsed_sec']}s | 경로: {result['output_path']}")
if __name__ == "__main__":
paradigm_prompt = """
A research paradigm diagram showing ML training pipeline.
Three stages: Data Preprocessing, Model Training, Evaluation.
Each stage has sub-modules with English labels.
Title: 'End-to-End ML Training Pipeline'.
Footer: 'Figure 1. ML Paradigm v2.3'.
Academic style, white background.
"""
compare_models(paradigm_prompt)
🚀 빠른 시작: APIYI apiyi.com 플랫폼을 통해 비교 테스트 환경을 구축하는 것을 추천합니다. 바로 사용할 수 있는 통합 API 인터페이스를 제공하여 5분 안에 두 모델을 연동하고 나란히 테스트해 볼 수 있습니다.
GPT-image-2 vs Nano Banana Pro 문자 렌더링 메커니즘 차이
왜 GPT-image-2가 작은 글씨와 학술 도표에서 '구조적' 우위를 점할까요? 두 모델의 기본 메커니즘 차이를 이해하면 작업에 가장 적합한 도구를 선택하는 데 도움이 됩니다.
GPT-image-2의 O 시리즈 추론(Thinking) 메커니즘
GPT-image-2는 OpenAI의 추론 모델(o1 / o3)의 이미지 영역 확장판인 O 시리즈 추론 메커니즘을 도입했습니다. 이미지를 생성하기 전에 크게 세 단계를 거칩니다.
- 구도 계획: 프롬프트의 객체, 텍스트, 공간 관계를 미리 '레이아웃 청사진'으로 구성합니다.
- 제약 검증: '객체 수', '텍스트 내용', '작은 글씨 위치'가 계획에 제대로 반영되었는지 하나씩 확인합니다.
- 충돌 해결: 잠재적인 프롬프트 충돌(예: "화면 가득 채우기" vs "여백 두기")을 조정합니다.
학술적 다이어그램처럼 '제약 조건이 많은' 시나리오에서 각 작은 글씨 레이블은 독립적인 제약 조건입니다. 일반적인 확산 모델은 생성 과정에서 제약을 놓치기 쉽지만, 추론 메커니즘은 전체적인 계획을 바탕으로 생성하므로 '글자 누락, 오타, 문자 겹침' 확률을 크게 낮춥니다.
Nano Banana Pro의 Grounding + 단락 의미론 메커니즘
Nano Banana Pro는 Gemini 3 Pro를 기반으로 하며, 강점은 다음 두 가지 방향에서 나옵니다.
- Google Search Grounding: 생성 시 실시간 정보(예: "2026년 4월의 최신 환율", "올림픽 일정")를 검색하여 이미지에 반영합니다.
- 단락 수준의 의미 일관성: 강력한 언어 모델 능력을 바탕으로 긴 단락에서 문법과 철자 일관성을 유지합니다.
이러한 메커니즘은 '긴 글이 포함된 인포그래픽'이나 '실제 데이터 기반 시각화'에는 매우 유리하지만, 파편화된 '작은 글씨 레이블'에는 크게 도움 되지 않습니다. 레이블은 대개 고유 명사나 용어 약어라서 풍부한 의미 맥락이 부족하기 때문입니다.
| 메커니즘 특징 | GPT-image-2 (Thinking) | Nano Banana Pro (Grounding) |
|---|---|---|
| 적합한 텍스트 유형 | 파편화된 소문자, 전문 용어 | 긴 단락, 검색 가능한 정보 |
| 제약 처리 방식 | 사전 계획 및 통합 검증 | 생성 중 의미 검사 |
| 오타 원인 | 매우 적음 (~1%) | 주로 소문자, 고유 명사 |
| 속도 영향 | 추론 속도 빠름 (~3초) | 검색으로 인해 지연 (~10-15초) |
| 최적 시나리오 | 학술 도표, UI, 기술 도표 | 포스터, 긴 단락, 실시간 데이터 |
왜 '작은 글씨'가 분기점이 되는가
글자 크기 자체가 문제가 아니라, 핵심은 '정보 밀도 / 픽셀'입니다. 8pt 레이블을 50×20 픽셀 영역에 12개의 문자로 또렷하게 그려내려면 모델은 아주 좁은 공간에서 글꼴, 간격, 정렬, 픽셀 떨림을 동시에 처리해야 합니다. 이는 '높은 제약 밀도'를 요구하는 시나리오이며, 여기서 O 시리즈 추론의 장점이 극대화됩니다.
🎯 기술 조언: 프로젝트가 학술 도표와 긴 단락의 인포그래픽을 모두 포함한다면, 엔지니어링 측면에서 모델 라우팅을 구현해 보세요. '글자 크기 임계값'에 따라 자동으로 모델을 분기하는 것입니다. 이 라우팅 작업 역시 APIYI apiyi.com 플랫폼의 통합 인터페이스를 사용하면 SDK를 따로 관리할 필요 없이 엔지니어링 복잡도를 낮출 수 있습니다.
GPT-image-2 vs Nano Banana Pro 프롬프트 엔지니어링 비교
두 모델은 '길들이는 방식'이 서로 다릅니다. 같은 요구 사항이라도 프롬프트를 어떻게 작성하느냐에 따라 결과물의 품질이 확연히 달라지죠.
GPT-image-2 친화적인 프롬프트 패턴
GPT-image-2는 '구조화된 지시문 + 명시적 제약 조건'을 선호합니다. 마치 O 시리즈의 추론 방식을 흉내 내는 것과 비슷하죠.
추천 작성법:
A research paradigm diagram with the following elements:
Title (top center, 24pt bold): "End-to-End ML Pipeline"
Three stages (left to right, connected by arrows):
1. "Data Preprocessing" (sub-modules: Tokenization, Normalization)
2. "Model Training" (sub-modules: Forward Pass, Backpropagation)
3. "Evaluation" (sub-modules: F1 Score, ROC-AUC)
Footer (bottom-right, 8pt): "Figure 1. ML Paradigm v2.3"
Style: academic, white background, dark blue boxes, sans-serif font.
핵심 포인트: 번호 목록, 명확한 글자 크기, 구체적인 위치를 지정하여 모델의 사고(Thinking) 메커니즘이 '항목별로 검증'할 수 있게 합니다.
Nano Banana Pro 친화적인 프롬프트 패턴
Nano Banana Pro는 '자연스러운 언어 설명 + 맥락 중심의 서사'를 선호합니다. 창의적인 글쓰기와 비슷하다고 볼 수 있습니다.
추천 작성법:
A clean academic-style research paradigm diagram showing
how a machine learning pipeline progresses through three
stages: starting with data preprocessing where raw inputs
are tokenized and normalized, then moving to model training
where forward passes and backpropagation iterate, and
finally reaching evaluation where F1 score and ROC-AUC
are computed. Connect the stages with arrows. Title at top:
"End-to-End ML Pipeline". Use a clean, white background
with dark blue rounded boxes.
핵심 포인트: 프로세스를 하나의 '이야기'처럼 들려주어, Gemini 백본 모델의 의미론적 연결 능력을 활용해 전체적인 완성도를 높입니다.
프롬프트 최적화 요약 표
| 최적화 요소 | GPT-image-2 작성법 | Nano Banana Pro 작성법 |
|---|---|---|
| 텍스트 내용 | 따옴표로 감싸기: "Figure 1" |
자연어: showing "Figure 1" |
| 요소 나열 | 번호 매기기: 1./2./3. | 자연스러운 연결어: first… then… |
| 글자 크기 | 명시적 지정: 8pt small print |
묘사적 지정: tiny annotation |
| 위치 지정 | 정확한 위치: top-right corner |
자연스러운 표현: in the upper right |
| 스타일 지정 | 키워드 중심: sans-serif, academic |
문장형 표현: clean academic style |
| 제약 강도 | 명시적일수록 좋음 | 자연어 설명이 더 안정적임 |
공통 팁 (두 모델 모두 적용)
- 핵심 텍스트는 반드시 따옴표로 감싸세요: 그렇지 않으면 모델이 의도와 다르게 '의역'할 수 있습니다.
- 8pt 이하의 작은 글씨는 최소화하세요: GPT-image-2라 할지라도 5~6개 이상의 독립적인 작은 라벨은 피하는 것이 좋습니다.
- 상충되는 제약 조건 피하기: "미니멀리즘 스타일" + "정보 집약적"과 같은 조합은 두 모델 모두를 혼란스럽게 만듭니다.
- 3~4회 생성 후 베스트 선택: 텍스트 렌더링 자체에 확률적인 요소가 있으므로, 여러 장을 생성해 비교하는 것이 업계 표준 방식입니다.
🚀 빠른 시작: APIYI apiyi.com 플랫폼에서 비교 테스트 파이프라인을 구축해 보세요. 동일한 프롬프트로 두 모델을 동시에 요청하여 나란히 결과물을 비교할 수 있습니다. 5분 안에 구축이 가능하며, 내 비즈니스에 가장 적합한 모델 조합을 빠르게 찾을 수 있습니다.
GPT-image-2 vs Nano Banana Pro 상황별 추천
여러 차례의 실측을 통해 상황별로 어떤 모델을 선택하는 것이 좋을지 구체적인 가이드를 정리했습니다.
GPT-image-2를 우선 선택해야 하는 상황
- 연구 패러다임 도표: 고밀도 소문자 + 전문 용어 + 화살표 조합이 필요할 때. GPT-image-2의 Thinking 메커니즘과 99% 수준의 텍스트 정확도는 독보적인 강점입니다.
- 기술 아키텍처 다이어그램: 기술 스택 명칭(FastAPI/Elasticsearch/PostgreSQL 등 오타가 발생하기 쉬운 전문 용어)이 포함된 경우.
- 데이터 시각화: 축 눈금, 범례, 오차 막대, 각주 등 6~8pt 수준의 작은 글씨가 많을 때.
- UI 스크린샷 및 목업: 버튼 텍스트, 상태 배지, 메뉴 항목 등 UI 텍스트가 밀집된 경우.
- 인포그래픽 포스터: "Intelligence Layer" 같은 전문 제목과 작은 주석이 혼합된 구조.
- 다국어 혼합 표기: 중/영/일/한이 섞인 도표 제작 시.
- 수식 및 기호: α/β/H₀/p-value 등 그리스 문자, 위/아래 첨자, 통계 기호가 포함될 때.
- 빠른 반복 작업: 장당 약 3초의 빠른 생성 속도로 반복적인 수정이 용이합니다.
Nano Banana Pro를 우선 선택해야 하는 상황
- 사진과 같은 사실감: 제품 촬영, 인물 사진, 건축 사진 등 고도의 사실성이 필요한 경우.
- 긴 문단형 인포그래픽: 소문자 라벨이 아닌, 문단 단위의 텍스트가 주를 이루는 디자인.
- 실시간 정보 기반 생성: Google Search Grounding을 통해 최신 환율이나 뉴스 같은 최신 데이터를 반영해야 할 때.
- 4K 고해상도: GPT-image-2는 현재 최대 2K인 반면, Banana Pro는 최대 4K(5632×3072)까지 지원합니다.
- 다중 참조 이미지 편집: 최대 14장의 참조 이미지를 지원하여 수정 및 편집 작업이 훨씬 유연합니다.
- 복잡한 공간 관계: 객체 간의 앞/뒤, 좌/우, 상/하 관계가 복잡한 장면에서 강점을 보입니다.
- 긴 중국어 문단: 작은 라벨이 아닌, 중국어 긴 문단 배치에서 훨씬 안정적입니다.
두 모델 모두 적합한 "중간 지대"
- 메인 제목 + 보조 제목으로 구성된 일반적인 삽화
- 간단한 로고 디자인
- 스타일화된 일러스트 (플랫, 수채화, 픽셀 아트 등)
- 전문 용어가 포함되지 않은 표지 이미지
💡 상황별 선택 원칙: 텍스트가 빽빽하고 글자가 작으며 전문 용어가 많을수록 GPT-image-2를, 문장이 길고 실사 느낌이나 최신 정보가 필요할수록 Nano Banana Pro를 선택하세요. 두 모델 모두 APIYI apiyi.com 플랫폼에서 클릭 한 번으로 간편하게 전환하며 사용할 수 있습니다.
GPT-image-2 vs Nano Banana Pro 의사결정 가이드
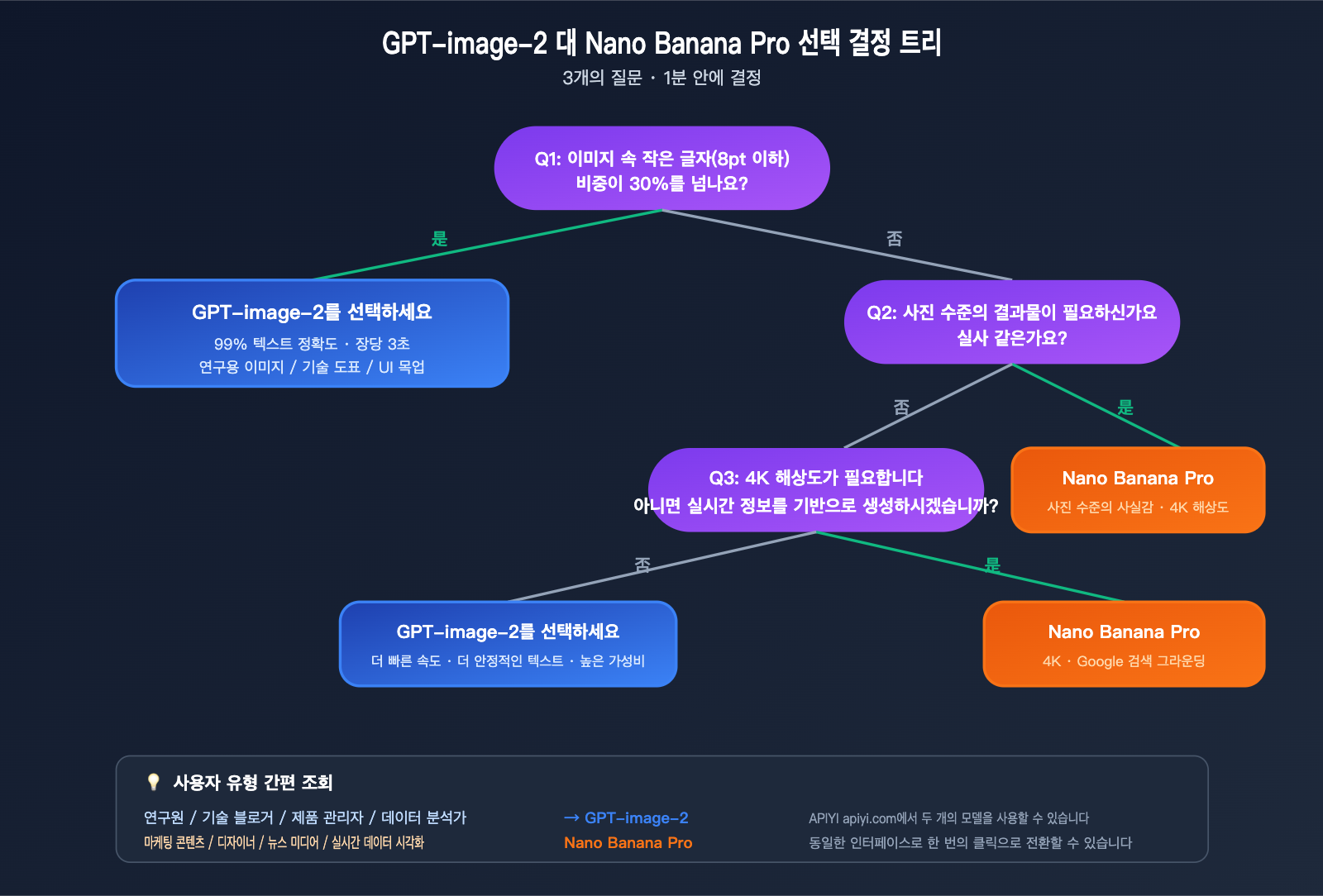
의사결정 트리: 3가지 질문으로 선택하기
질문 1: 이미지 내 "작은 텍스트(8pt 이하)" 비중이 30%를 넘나요?
- 예 → GPT-image-2
- 아니오 → 질문 2로 이동
질문 2: 사진과 같은 사실적인 표현이 필요한가요?
- 예 → Nano Banana Pro
- 아니오 → 질문 3으로 이동
질문 3: 4K 해상도나 실시간 정보 기반의 생성이 필요한가요?
- 예 → Nano Banana Pro
- 아니오 → GPT-image-2 (속도가 더 빠르고 텍스트 표현이 안정적임)
사용자 그룹별 추천
| 사용자 유형 | 주요 활용 사례 | 추천 모델 | 이유 |
|---|---|---|---|
| 연구원 | 논문 삽화, 패러다임 도표, 순서도 | GPT-image-2 | 수식, 그리스 문자, 전문 용어 표현 안정적 |
| 기술 블로거 | 아키텍처 도표, API 순서도, 코드 예시 | GPT-image-2 | 기술 용어 오타 없음, UI 스크린샷 정교함 |
| 제품 관리자 | 제품 스크린샷 목업, 순서도 | GPT-image-2 | UI 요소 및 텍스트 렌더링 강점 |
| 데이터 분석가 | 차트 내 작은 텍스트, 축 레이블 | GPT-image-2 | 6-8pt 작은 글씨도 안정적 |
| 마케팅 담당자 | 포스터, 긴 텍스트 인포그래픽 | Nano Banana Pro | 긴 문장 레이아웃 및 사실적 표현 우수 |
| 디자이너 | 사진 합성, 제품 촬영 | Nano Banana Pro | 사실적인 질감과 디테일 표현 우수 |
| 뉴스 미디어 | 실시간 정보 시각화 | Nano Banana Pro | Google Search grounding 활용 강점 |
비용 및 속도 고려사항
GPT-image-2는 LM Arena 실측 기준 장당 약 3초가 소요되는 반면, Nano Banana Pro는 보통 10-15초가 걸립니다. 만약 "만족할 때까지 프롬프트를 반복 수정"하는 워크플로우를 사용하신다면, GPT-image-2의 속도 이점이 반복 주기를 크게 단축해 줄 것입니다.
💰 비용 최적화: 대량의 연구용/기술용 이미지를 생성해야 하는 팀이라면 APIYI(apiyi.com) 플랫폼을 통해 두 모델을 호출하는 것을 추천합니다. 이 플랫폼은 유연한 요금제와 통합 모델 관리 기능을 제공하여 상황에 맞춰 가장 경제적인 모델을 선택할 수 있어 중소 규모 팀이나 개인 개발자에게 적합합니다.
GPT-image-2 vs Nano Banana Pro 자주 묻는 질문(FAQ)
Q1: GPT-image-2가 정말 Nano Banana Pro를 “압살”하나요?
상황에 따라 다릅니다. LM Arena의 텍스트-이미지 변환 순위에서 GPT-image-2(1512 Elo)는 Nano Banana Pro(1271 Elo)보다 +242점 높은 점수를 기록하며, 이는 LM Arena 역사상 가장 큰 격차입니다. 하지만 이 격차는 주로 텍스트 렌더링, UI 재구성, 세계 지식 등의 측면에서 발생합니다. 사진 수준의 사실감이나 공간 추론 면에서는 Nano Banana Pro가 여전히 우위에 있습니다. 즉, "작은 글씨가 포함된 이미지, 과학 자료, UI 도안" 분야에서는 압도적이지만, "사진 같은 사실감"이 필요한 분야에서는 그렇지 않습니다. APIYI(apiyi.com) 플랫폼을 통해 두 모델을 모두 연결하고 상황에 맞춰 전환해 사용하는 것을 추천합니다.
Q2: GPT-image-2의 99% 텍스트 정확도는 사실인가요?
LM Arena의 실측 결과와 초기 사용자들의 보고에 따르면 사실로 확인되었습니다. 라틴어, 한중일(CJK), 힌디어, 벵골어 등 다양한 문자 체계에서 동일하게 적용됩니다. 다만, "99%"는 문자 단위의 정확도이며 100%는 아니라는 점에 유의해야 합니다. 5pt 이하의 초소형 글자, 희귀 전문 기호, 복잡한 수학 공식 등이 포함된 극한 상황에서는 여전히 간혹 오류가 발생합니다. 참고로 GPT Image 1.5는 95%, GPT Image 1은 90%였으며, Nano Banana Pro는 긴 단락 문장에서는 95%에 근접하지만 작은 글씨가 포함된 환경에서는 80~85% 수준으로 떨어집니다.
Q3: GPT-image-2로 과학 연구 도표를 만들 때 그리스 문자 α가 가끔 틀리는데 어떻게 하죠?
프롬프트에 "Use Unicode Greek letter alpha (α, U+03B1)"와 같이 명확하게 지정해 보세요. 기본으로 활성화된 'Thinking' 모드와 함께 사용하면 적중률이 훨씬 높아집니다. 그래도 오류가 발생한다면, 3~4장을 생성해 최선의 결과물을 선택하거나 프롬프트에서 영문 "alpha"로 대체한 뒤 나중에 포토샵으로 수정하는 방법을 권장합니다. 여러 번 실험해 보고 결정하세요.
Q4: 왜 Nano Banana Pro는 긴 단락 텍스트에서 더 안정적인가요?
Nano Banana Pro는 Gemini 3 Pro를 기반으로 하여 강력한 대규모 언어 모델의 '문단 수준의 의미 일관성' 능력을 갖추고 있습니다. 긴 단락을 하나의 '의미 단위'로 처리하기 때문에 전체적인 문법과 철자가 매우 안정적입니다. 반면, 작은 글씨 라벨은 '파편화된 개체명'이라 의미론적 문맥 제약이 없어 오류가 발생하기 쉽습니다. GPT-image-2는 O 시리즈 추론 기능을 통해 '작은 글씨 라벨'을 제약 조건으로 미리 계획함으로써 이 문제를 우회합니다.
Q5: GPT-image-2와 Nano Banana Pro는 APIYI 플랫폼에서 똑같이 호출하나요?
네, 맞습니다. APIYI(apiyi.com) 플랫폼은 다양한 주요 이미지 모델에 대해 통일된 OpenAI 호환 인터페이스를 제공합니다. 모델 필드(gpt-image-2 또는 gemini-3-pro-image-preview)만 변경하면 바로 전환할 수 있으며, base_url과 SDK 호출 방식은 그대로 유지됩니다. 이는 A/B 테스트가 필요하거나 상황에 따라 모델을 라우팅해야 하는 프로젝트에 매우 유용하며, 여러 SDK를 유지 관리하는 비용을 줄여줍니다.
Q6: 기존에 BananaPro를 썼는데 GPT-image-2로 넘어가려면 프롬프트를 다시 조정해야 하나요?
작은 조정은 필요하지만 큰 부담은 아닙니다. Nano Banana Pro는 "자연어 설명+문맥"을 선호하는 반면, GPT-image-2는 구조화된 지시문에서 더 잘 작동합니다. 프롬프트에 다음을 추가하는 것을 추천합니다: 1) 명확한 요소 목록 (1./2./3. 번호 매기기), 2) 폰트 스타일 지정 (sans-serif/monospace/serif), 3) 핵심 텍스트 따옴표 처리 (예: "Figure 1. ML Paradigm"). 그 외 설명 방식은 그대로 유지해도 좋습니다.
Q7: 두 모델 모두 생성이 실패하면 어떻게 확인하나요?
다음 순서로 확인해 보세요: 1) 프롬프트가 콘텐츠 필터링(인물 얼굴, 민감한 내용)에 걸리지 않았는지 확인, 2) 프롬프트를 단축하고 충돌하는 제약 조건 제거("사실적"이면서 동시에 "미니멀리스트 일러스트" 등), 3) size/quality 매개변수 조정, 4) 다른 모델로 전환하여 테스트, 5) API 오류라면 APIYI(apiyi.com) 콘솔에서 상세 에러 코드와 재시도 전략을 확인하세요.
Q8: GPT-image-2가 Nano Banana Pro에게 밀리는 상황은 언제인가요?
주로 세 가지 경우입니다: 1) 4K 초고해상도(Banana Pro는 5632×3072 지원, GPT-image-2는 최대 2K), 2) 다중 개체 공간 추론(예: "5개의 물건이 3개의 수납장 내 특정 위치에 있는 모습"), 3) 아주 긴 단락이 포함된 인포그래픽(200자 이상의 문단 배치). 이런 상황에서는 Nano Banana Pro를 직접 선택하는 것을 권장합니다.
GPT-image-2 vs Nano Banana Pro 핵심 요약
- 압도적인 텍스트 렌더링: GPT-image-2는 LM Arena에서 Nano Banana Pro를 +242 Elo 점수 차이로 앞서며, 약 99%의 문자 단위 정확도를 자랑합니다.
- 과학 도표 분야의 구조적 우위: 논문 도표, 기술 아키텍처, 데이터 시각화, UI 목업 등 '텍스트 밀도가 높은' 작업에서 GPT-image-2의 O 시리즈 추론 + 99% 정확도는 큰 강점이 됩니다.
- 작은 글씨와 공식의 안정성: 6-8pt의 좌표축 눈금, 그리스 문자, 첨자, 통계 기호 등에서 GPT-image-2는 매우 안정적인 결과를 보여줍니다.
- 3-5배 빠른 생성 속도: GPT-image-2는 장당 약 3초 만에 생성되어 Nano Banana Pro(10-15초)보다 빠른 반복 작업에 최적화되어 있습니다.
- Banana Pro의 전용 강점: 4K 해상도, 사진 수준의 사실감, 긴 단락의 문맥 일관성, Google 검색 기반 정보 확인, 다중 개체 공간 추론은 여전히 Nano Banana Pro가 우위에 있습니다.
- 상황별 모델 선택 가이드: 글자가 많고 작거나 전문 용어가 많을수록 → GPT-image-2, 사실적인 표현이나 4K, 실시간 정보가 필요할 때 → Nano Banana Pro.
- 통합 인터페이스로 비용 절감: APIYI(apiyi.com) 플랫폼을 통해 하나의 SDK로 모델을 자유롭게 교체하여 사용함으로써, 여러 API 연동 코드를 관리할 필요가 없습니다.
요약
GPT-image-2와 Nano Banana Pro의 비교는 어떤 상황에서 활용하느냐에 따라 전혀 다른 결론이 나옵니다. LM Arena의 전체 순위만 놓고 보면 GPT-image-2가 +242 Elo 포인트 앞서며 압도하는 것처럼 보이지만, 구체적인 활용 분야로 들어가면 각 모델의 강점이 매우 뚜렷하게 갈립니다.
- 학술 자료형 이미지, 작은 텍스트가 포함된 기술 도표, 전문 용어가 들어간 차트 → GPT-image-2 선택
- 사진처럼 사실적인 이미지, 긴 문장이 포함된 인포그래픽, 실시간 정보가 반영된 이미지 → Nano Banana Pro 선택
"이미지 내에 많은 텍스트, 특히 작은 글씨를 포함해야 하는" 작업이 주 업무인 연구자, 기술 블로거, 제품 관리자들에게 GPT-image-2의 성능 향상은 매우 체감되는 수준입니다. GPT Image 1의 90%에서 GPT Image 1.5의 95%, 그리고 이번 GPT-image-2의 99%까지, 세대를 거듭할수록 "AI가 만든 이미지를 그대로 현업에 쓸 수 있는가?"라는 한계를 계속해서 앞당기고 있습니다.
APIYI(apiyi.com) 플랫폼을 통해 두 모델을 모두 연결하여 작업 유형에 따라 동적으로 전환하며 활용하는 것을 추천합니다. 모든 수요를 하나의 모델에만 의존하기보다는, 각 모델이 가장 잘하는 분야에 맞춰 최적으로 사용하는 것이 가장 현명한 방법입니다.
참고 자료
-
OpenAI ChatGPT Images 2.0 공식 발표: GPT-image-2 출시 안내
- 링크:
openai.com/index/introducing-chatgpt-images-2-0 - 내용: 2026년 4월 21일 공식 발표 및 모델 기능 목록
- 링크:
-
Google DeepMind Nano Banana Pro 공식 페이지: Gemini 3 Pro Image 모델 설명
- 링크:
deepmind.google/models/gemini-image/pro - 내용: 공식 기능 설명, 가격 정책, 참조 이미지 수량 등
- 링크:
-
LM Arena 텍스트-이미지 변환 리더보드: 이미지 생성 모델 Elo 순위
- 링크:
arena.ai/leaderboard/text-to-image - 내용: GPT-image-2(1512 Elo) 대 Nano Banana Pro(1271 Elo) 비교
- 링크:
-
Simon Willison의 Nano Banana Pro 실사용 테스트: 독립 개발자의 테스트 보고서
- 링크:
simonwillison.net/2025/Nov/20/nano-banana-pro - 내용: 4K 해상도 테스트 및 인포그래픽 사례
- 링크:
-
VentureBeat의 ChatGPT Images 2.0 보도: 다국어 및 인포그래픽 평가
- 링크:
venturebeat.com/technology/openais-chatgpt-images-2-0-is-here - 내용: 다국어 텍스트 렌더링, 만화/지도/포스터 테스트 결과
- 링크:
작성자: APIYI 기술팀 | 더 많은 대규모 언어 모델 API 연동 및 비교 분석은 APIYI(apiyi.com)에서 직접 테스트해보세요.