作者注:客观对比 Claude Opus 4.6 和 GPT-5.4 的 12 项基准测试、定价、上下文窗口、代理能力和适用场景,帮开发者做出正确选型
2026 年 2 月和 3 月,AI 领域迎来两款重磅旗舰模型:Anthropic 的 Claude Opus 4.6(2 月 5 日)和 OpenAI 的 GPT-5.4(3 月 5 日)。两者都是各自公司有史以来最强的通用模型,但它们的设计哲学和优势领域截然不同。
基准测试显示:GPT-5.4 赢得 5 个类别,Claude Opus 4.6 赢得 3 个类别——但编程、推理和代码质量这些核心维度上,Claude 的领先更具实际价值。
核心价值: 看完本文,你将明确在编程、推理、自动化、视觉等不同场景下该选择哪个模型。

Claude Opus 4.6 vs GPT-5.4 核心数据对比
| 对比维度 | Claude Opus 4.6 | GPT-5.4 | 说明 |
|---|---|---|---|
| 发布日期 | 2026-02-05 | 2026-03-05 | 相隔 1 个月 |
| 模型 ID | claude-opus-4-6 | gpt-5.4 | — |
| 上下文窗口 | 200K (1M Beta) | 1,000K | GPT 正式支持 1M |
| 最大输出 | 128K | 128K | 相同 |
| 输入价格 | $5.00/M | $2.50/M | GPT 便宜 50% |
| 输出价格 | $25.00/M | $15.00/M | GPT 便宜 40% |
| 缓存输入 | $0.50/M | $0.25/M | GPT 便宜 50% |
| 推理模式 | 自适应思维 (Adaptive) | 5 级推理 (none→xhigh) | 各有特色 |
| 电脑操控 | ✅ (72.7%) | ✅ (75.0%) | GPT 超越人类 |
| 代理团队 | ✅ Agent Teams | ❌ | Claude 独有 |
| 工具搜索 | ❌ | ✅ Token 降 47% | GPT 独有 |
| 金融插件 | ❌ | ✅ Excel/Sheets | GPT 独有 |
Claude Opus 4.6 与 GPT-5.4 的设计哲学差异
两款模型的设计哲学截然不同:
Claude Opus 4.6 走的是"深度智能"路线。自适应思维(Adaptive Thinking)让模型根据问题复杂度自动决定推理深度,无需手动设置预算。Agent Teams 功能允许一个主 Claude 实例派生多个独立的子代理并行工作,通过共享任务列表和消息系统协调。这种架构设计更适合需要深度理解和长链推理的复杂编程任务。
GPT-5.4 走的是"全能工具人"路线。它首次将编程(继承 GPT-5.3 Codex)、电脑操控、全分辨率视觉和工具搜索融合在一个通用模型中。工具搜索机制让模型按需查找工具定义,Token 用量降低 47%。金融插件(Moody's、MSCI 等)和 ChatGPT for Excel 则瞄准企业级专业工作。
🎯 选型提示: 两者的优势领域几乎互补。通过 API易 apiyi.com 可以一个 API Key 同时调用 Claude Opus 4.6 和 GPT-5.4,按场景灵活切换。
Claude Opus 4.6 vs GPT-5.4 基准测试详细分析
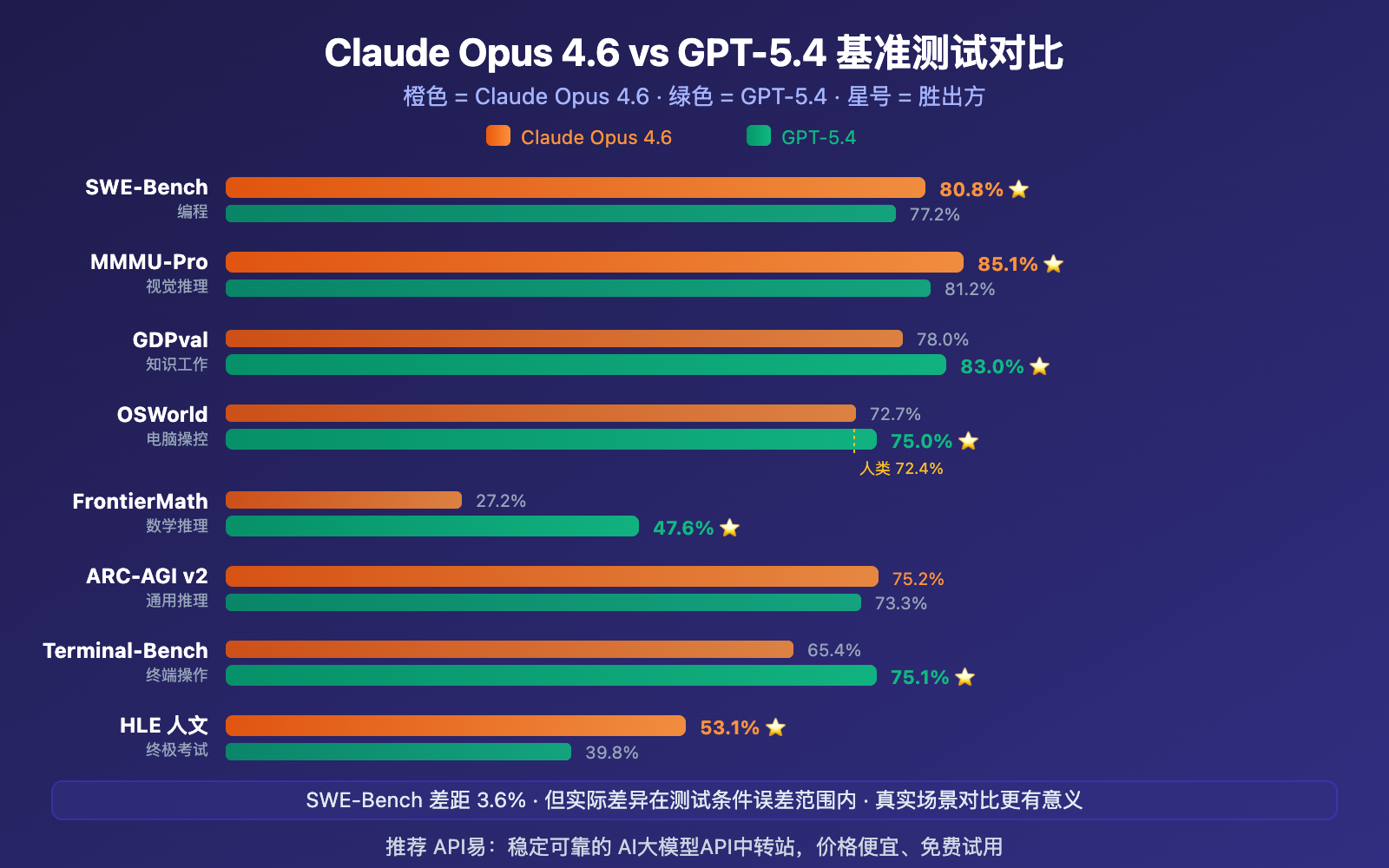
Claude Opus 4.6 vs GPT-5.4 完整基准测试表
| 基准测试 | Claude Opus 4.6 | GPT-5.4 | 差距 | 胜出 |
|---|---|---|---|---|
| SWE-Bench Verified | 80.8% | 77.2% | +3.6% | Claude |
| SWE-Bench Pro (高难度) | ~45.9% | 57.7% | +11.8% | GPT |
| MMMU-Pro 视觉推理 | 85.1% | 81.2% | +3.9% | Claude |
| GDPval 知识工作 | 78.0% | 83.0% | +5.0% | GPT |
| OSWorld 电脑操控 | 72.7% | 75.0% | +2.3% | GPT |
| FrontierMath 数学 | 27.2% | 47.6% | +20.4% | GPT |
| ARC-AGI v2 通用推理 | 75.2% | 73.3% | +1.9% | Claude |
| Terminal-Bench 终端 | 65.4% | 75.1% | +9.7% | GPT |
| Humanity's Last Exam | 53.1% | 39.8% | +13.3% | Claude |
| Tau2 Telecom | 99.3% | 98.9% | +0.4% | Claude |
| GPQA 研究生推理 | 91.3% | 92.8% | +1.5% | GPT |
| BrowseComp 网页浏览 | 84.0% | 82.7% | +1.3% | Claude |
需要特别指出的是:80.0%、80.6% 和 80.8% 之间的 SWE-Bench 差异,实际上已经在测试条件的误差范围内。换句话说,在标准化编程基准上,两者已经趋于收敛。真正的差异体现在代码质量、架构理解和实际开发体验上。
🎯 实测建议: 基准测试只是参考起点。建议通过 API易 apiyi.com 获取免费额度,在你自己的项目中对比两个模型的实际表现,这比任何基准测试都更有价值。
Claude Opus 4.6 vs GPT-5.4 独有能力对比
Claude Opus 4.6 独有优势
1. Agent Teams(代理团队)
Claude Opus 4.6 引入的 Agent Teams 是当前 AI 领域独一无二的功能。一个主 Claude 实例(Lead)可以派生多个独立的子代理(Teammates),每个子代理拥有完整的独立上下文窗口,通过共享任务列表和消息系统并行协作。
在深度研究任务中,多代理技术将性能提升了约 15 个百分点。这种架构特别适合大型代码库的并行重构——主代理负责规划,子代理分别处理不同模块。
2. 自适应思维(Adaptive Thinking)
与 GPT-5.4 的手动 5 级推理等级不同,Claude 的自适应思维让模型自动判断问题复杂度并动态分配推理深度。在默认的 high 级别下,Claude 几乎总会启用思维链;在简单问题上则自动跳过,节省 Token 和延迟。
自适应思维还支持交错思维(Interleaved Thinking)——在工具调用之间穿插思考,这对代理式工作流特别有效。
GPT-5.4 独有优势
1. 原生电脑操控
GPT-5.4 是 OpenAI 首款内置原生电脑操控能力的通用模型。OSWorld 75.0% 直接超越人类基线 72.4%。它能通过 Playwright 代码和直接键鼠指令两种方式操作浏览器和桌面应用。
2. 工具搜索(Tool Search)
在拥有大量工具的系统中,传统方式需要将所有工具定义一次性发送给模型。GPT-5.4 的工具搜索让模型按需查找工具定义,Token 用量降低 47%,准确率不变。
3. 金融行业深度集成
ChatGPT for Excel/Google Sheets + Moody's/MSCI/FactSet 数据集成,让 GPT-5.4 在金融分析领域形成了 Claude 目前无法匹敌的生态优势。内部投行基准从 43.7% 提升到 87.3%。
🎯 API 接入: Claude Opus 4.6 和 GPT-5.4 均可通过 API易 apiyi.com 统一接口调用。GPT-5.4 定价同步官网($2.50/$15.00),充值 100 美金起送 10%。
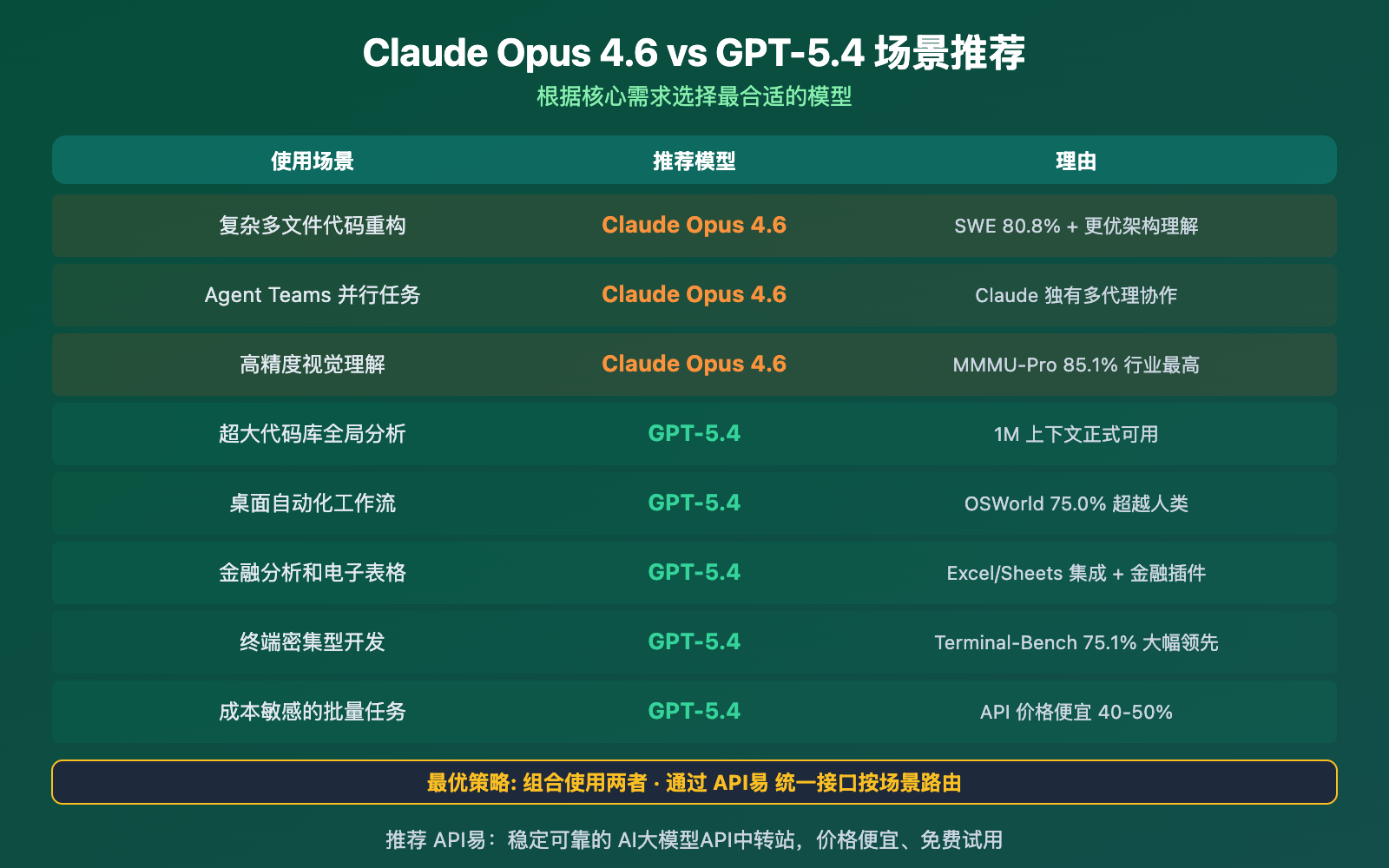
Claude Opus 4.6 vs GPT-5.4 场景选型决策
Claude Opus 4.6 vs GPT-5.4 API 接入示例
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# 复杂代码重构 → Claude Opus 4.6
refactor = client.chat.completions.create(
model="claude-opus-4-6",
messages=[{"role": "user", "content": "重构这个模块的依赖注入"}]
)
# 超大项目全局分析 → GPT-5.4
analysis = client.chat.completions.create(
model="gpt-5.4",
messages=[{"role": "user", "content": "分析整个项目的安全漏洞"}]
)
建议: 通过 API易 apiyi.com 注册一个账号即可同时调用两大旗舰模型。GPT-5.4 定价同步官网,充值 100 美金起送 10%。切换模型只需修改一个参数。
常见问题
Q1: Claude Opus 4.6 和 GPT-5.4 哪个编程更强?
看维度。标准编程基准 SWE-Bench 上 Claude 以 80.8% vs 77.2% 领先,代码质量和多文件重构能力也更优。但 GPT-5.4 在高难度 SWE-Bench Pro 上以 57.7% vs ~45.9% 反超,终端操作任务也大幅领先(75.1% vs 65.4%)。对大多数开发者来说,两者的编程能力已经趋于收敛。
Q2: 价格差距大吗?该怎么选?
GPT-5.4 全面更便宜:输入 $2.50 vs $5.00/M(50%),输出 $15.00 vs $25.00/M(40%)。如果成本是主要考量,GPT-5.4 更合适。如果项目对代码质量和架构理解要求极高,Claude 的溢价值得。建议通过 API易 apiyi.com 按场景混合使用两者,优化成本。
Q3: 如何通过一个平台同时使用两个模型?
通过 API易 apiyi.com 注册账号:
- 获取统一 API Key
- 设置
base_url为https://vip.apiyi.com/v1 - 重构任务:
model="claude-opus-4-6" - 大项目分析:
model="gpt-5.4" - 日常任务:
model="gpt-5.3-chat-latest"(最省钱)
充值 100 美金起送 10%,一个账号调用所有主流模型。
总结
Claude Opus 4.6 vs GPT-5.4 的核心结论:
- 编程和视觉推理选 Claude: SWE-Bench 80.8%、MMMU-Pro 85.1% 行业最高,代码质量更干净,Agent Teams 多代理协作是独有优势
- 知识工作和自动化选 GPT: GDPval 83.0%、OSWorld 75.0% 超越人类,1M 上下文正式可用,API 价格便宜 40-50%
- 最聪明的策略是组合使用: 两者的优势领域几乎互补——重构用 Claude,大项目分析和自动化用 GPT,日常任务用 GPT-5.3 Instant 省钱
SWE-Bench 上 80.8% vs 77.2% 的差距看起来不大,但在实际开发中,Claude 的架构理解力和代码整洁度优势仍然明显。GPT-5.4 则凭借 1M 上下文、电脑操控和更低定价在另一个维度建立了优势。
推荐通过 API易 apiyi.com 统一接入两大旗舰模型,一个 API Key 调用全部,充值 100 美金起送 10%。
📚 参考资料
-
GPT-5.4 vs Claude Opus 4.6 编程对比: 开发者视角的 SWE-Bench、代码质量和 Agent 能力分析
- 链接:
blog.getbind.co/gpt-5-4-vs-claude-opus-4-6-which-one-is-better-for-coding/ - 说明: 最详细的编程维度对比,含 SWE-Bench Pro 和 Terminal-Bench 数据
- 链接:
-
GPT-5.4 vs Opus 4.6 vs Gemini 3.1 Pro 三强对比: 12 项基准测试全维度分析
- 链接:
digitalapplied.com/blog/gpt-5-4-vs-opus-4-6-vs-gemini-3-1-pro-best-frontier-model - 说明: 定价、上下文、基准测试、优劣势全覆盖
- 链接:
-
Claude Opus 4.6 官方发布公告: Agent Teams、自适应思维等新功能详情
- 链接:
anthropic.com/news/claude-opus-4-6 - 说明: 了解 Claude 独有功能的第一手资料
- 链接:
-
Claude Opus 4.6 自适应思维 API 文档: 开发者集成指南
- 链接:
platform.claude.com/docs/en/build-with-claude/adaptive-thinking - 说明: 了解自适应思维的具体使用方法和参数设置
- 链接:
作者: APIYI 技术团队
技术交流: 欢迎在评论区讨论,更多资料可访问 API易 docs.apiyi.com 文档中心