「You've reached your rate limit. Please try again later.」 というエラーに困惑していませんか?ついさっきまで問題なく使えていたし、トークン制限も超えていないのに、なぜ急に使えなくなったのでしょうか?
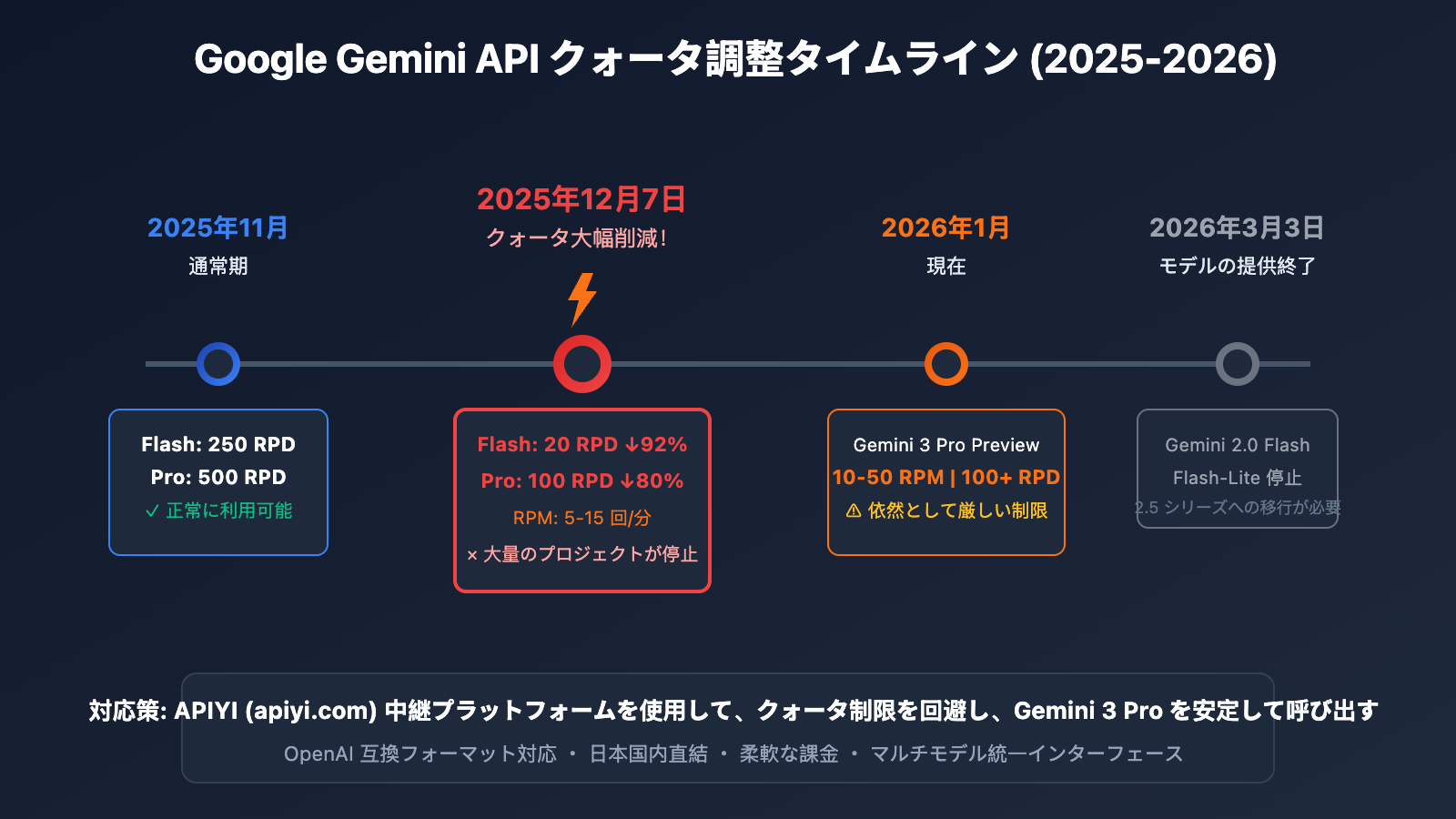
もしあなたが個人学習ユーザーで、AI Studio で Gemini 3 Pro を使ってテキスト生成を行っている際にこの問題に直面したなら、それはあなただけではありません。2025年12月7日、Google は Gemini API の無料枠を 50%〜92% も密かに削減しました。この変更により、世界中の数万人の開発者のプロジェクトが一夜にして停止する事態となっています。
この記事のメリット: 本記事を読むことで、クォータ(割当)削減の真の理由を理解し、レート制限を回避する5つの方法をマスターできます。また、API中継プラットフォームを通じて Gemini 3 Pro を安定して利用する方法についても学ぶことができます。

Gemini 3 Pro レート制限の要点
問題を解決する前に、Google がどのような調整を行ったのかを知る必要があります。
| 調整項目 | 調整前 (2025年11月) | 調整後 (2025年12月7日) | 減少幅 |
|---|---|---|---|
| Flash モデル RPD | 250 リクエスト/日 | 20 リクエスト/日 | -92% |
| Pro モデル RPD | 500 リクエスト/日 | 100 リクエスト/日 | -80% |
| Pro モデル RPM | 15 リクエスト/分 | 5 リクエスト/分 | -67% |
| Gemini 3 Pro Preview | 制限なし | 10-50 RPM, 100+ RPD | 新規制限 |
Gemini 3 Pro レート制限の4つの指標
Google のレート制限システムは、以下の4つの指標で使用量を制御しています。
| 制限の指標 | 正式名称 | 説明 | 無料枠の現在の値 |
|---|---|---|---|
| RPM | Requests Per Minute | 1分あたりのリクエスト数 | 5-15 回 |
| TPM | Tokens Per Minute | 1分あたりのトークン数 | 250,000 |
| RPD | Requests Per Day | 1日あたりのリクエスト数 | 20-100 回 |
| IPM | Images Per Minute | 1分あたりの画像数 | マルチモーダルに適用 |
🔑 重要: Gemini 3 Pro はプレビュー版として、現在無料枠では 10-50 RPM および 100+ RPD 程度に制限されていますが、実際にはドキュメントに記載されているよりも厳しい制限がかかっているという報告が多く寄せられています。
なぜ Google はクォータを大幅に削減したのか?
Google の公式発表によると、クォータの調整には以下の理由があります。
- 需要の爆発的な増加: 2025年はAIアプリが爆発的に普及し、API呼び出し量が予想を大幅に上回りました。
- インフラへの負荷: Gemini 2.0/3.0 モデルは計算リソースの要求が非常に高いです。
- 有料ユーザーの体験保護: 有料枠ユーザーへのサービス品質を優先的に確保するためです。
- ビジネス戦略の調整: 開発者を有料プランへ誘導するためです。
Gemini 3 Pro のレート制限を解決する 5 つの方法
AI Studio のレート制限(Rate Limit)問題に対して、検証済みの 5 つの解決策を紹介します。
解決策 1:他の Gemini モデルに切り替える
これは最も簡単な一時的な解決策です。モデルによってクォータ(割り当て)制限が異なります。
| モデル | RPM | RPD | 推奨シナリオ |
|---|---|---|---|
| Gemini 2.5 Flash-Lite | 15 | 1,000 | 軽量なタスクに最適 |
| Gemini 2.5 Flash | 10 | 500 | パフォーマンスのバランス |
| Gemini 2.5 Pro | 5 | 100 | 複雑な推論 |
| Gemini 3 Pro Preview | 10-50 | 100+ | 最強の能力、制限は厳しめ |
💡 役立つヒント: Gemini 3 Pro の全能力を必要としないタスクであれば、Gemini 2.5 Flash-Lite に切り替えることで最大 1,000 RPD のクォータを利用でき、日常的な学習には十分です。
解決策 2:クォータの解除を待つ
Gemini API の RPD(1日あたりのリクエスト数)制限は、太平洋標準時の午前 0 時にリセットされます。
クォータのリセット時間対照表:
- 日本時間:午後 4:00 (夏時間) / 午後 5:00 (冬時間)
- 北京時間:午後 4:00 (夏時間) / 午後 5:00 (冬時間)
解決策 3:有料プランにアップグレードする
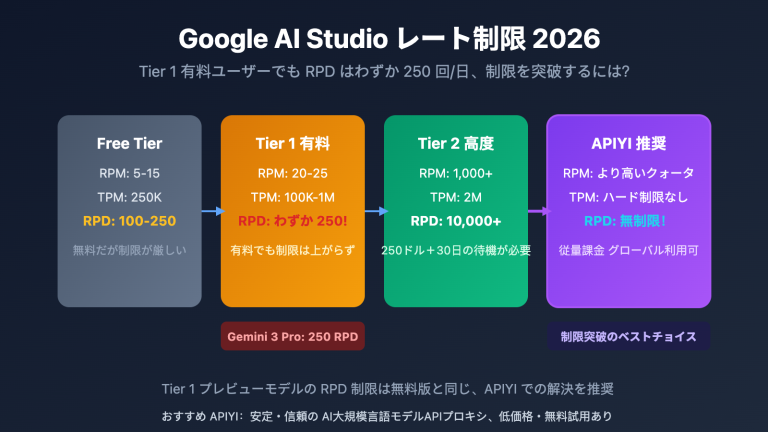
Gemini 3 Pro を安定して使用する必要がある場合、有料プランへのアップグレードが公式の推奨プランです。
| ティア | 要件 | RPM | RPD | 平均月額コスト |
|---|---|---|---|---|
| Free Tier | なし | 5-15 | 20-100 | $0 |
| Tier 1 | クレジットカード登録 | 150-300 | 無制限 | 従量課金 |
| Tier 2 | 累計消費 $250 + 30日間利用 | 1,000+ | 無制限 | 従量課金 |
Gemini 3 Pro の価格設定:
- 入力:$2.00 / 100万トークン(≤200K コンテキスト)
- 出力:$12.00 / 100万トークン(≤200K コンテキスト)
- 超長文コンテキスト(>200K):価格は 2 倍
解決策 4:API 中継プラットフォームを使用する(推奨)
個人の学習ユーザーや中小規模のチームにとって、API 中継プラットフォームの使用は最もコストパフォーマンスの高い選択肢です。
# APIYI を介して Gemini 3 Pro を呼び出す - シンプルな例
import openai
client = openai.OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1" # APIYI 統合インターフェース
)
response = client.chat.completions.create(
model="gemini-3-pro-preview",
messages=[
{"role": "user", "content": "Transformer アーキテクチャについて説明してください"}
],
max_tokens=2000
)
print(response.choices[0].message.content)
🚀 クイックスタート: APIYI (apiyi.com) プラットフォームを使用して、Gemini 3 Pro に素早くアクセスすることをお勧めします。このプラットフォームは統合された OpenAI 形式のインターフェースを提供しており、クォータ制限を気にすることなく、5 分で統合を完了できます。
完全なコード例を表示する(エラー処理を含む)
# Gemini 3 Pro の完全な呼び出し例 - APIYI 経由
import openai
from openai import OpenAI
import time
def call_gemini_3_pro(prompt: str, max_retries: int = 3) -> str:
"""
Gemini 3 Pro モデルを呼び出す
Args:
prompt: ユーザー入力
max_retries: 最大再試行回数
Returns:
モデルの応答内容
"""
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1" # APIYI 統合インターフェース
)
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model="gemini-3-pro-preview",
messages=[
{
"role": "system",
"content": "あなたは専門的な AI アシスタントです。日本語で回答してください。"
},
{
"role": "user",
"content": prompt
}
],
max_tokens=4000,
temperature=0.7
)
return response.choices[0].message.content
except openai.RateLimitError as e:
print(f"リクエストが頻繁すぎます。待機してから再試行します... ({attempt + 1}/{max_retries})")
time.sleep(2 ** attempt) # 指数バックオフ
except openai.APIError as e:
print(f"API エラー: {e}")
raise
raise Exception("再試行回数の上限に達しました")
# 使用例
if __name__ == "__main__":
result = call_gemini_3_pro("大規模言語モデルの仕組みを 100 文字程度で説明してください")
print(result)
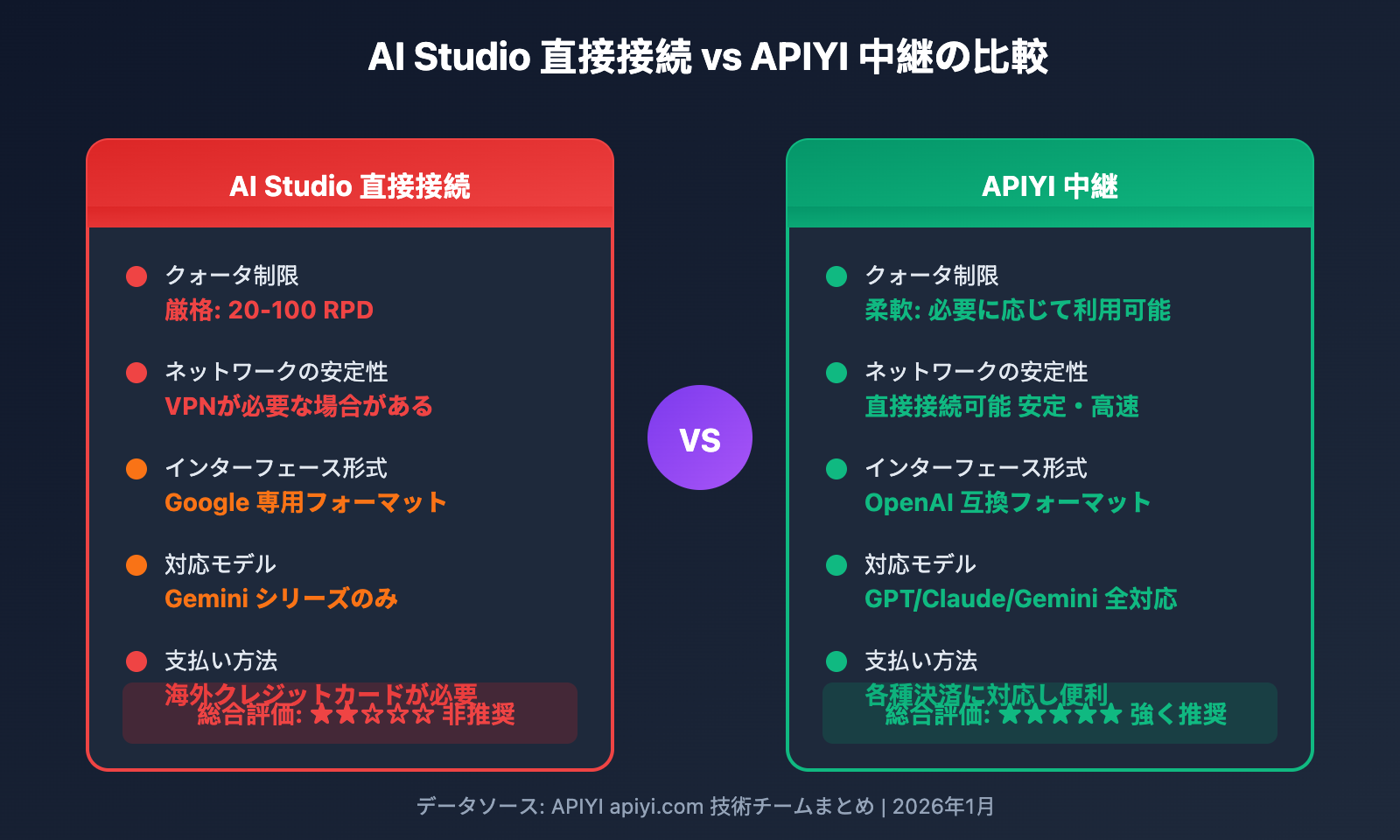
API 中継プラットフォームを使用するメリット:
| 比較項目 | AI Studio 直接接続 | APIYI 中継 |
|---|---|---|
| クォータ制限 | 厳格 (20-100 RPD) | 柔軟、オンデマンド |
| ネットワークの安定性 | VPN が必要な場合がある | 国内から直接接続可能 |
| インターフェース形式 | Google 専用フォーマット | OpenAI 互換フォーマット |
| マルチモデル切り替え | Gemini シリーズのみ | GPT/Claude/Gemini などに対応 |
| 支払い方法 | 海外クレジットカードが必要 | 主要な決済方法を幅広くサポート |
解決策 5:リクエスト戦略を適切に計画する
無料枠を使用し続ける必要がある場合、以下の戦略によってクォータの利用効率を最大化できます。
1. リクエストのバッチ処理
# 複数の小さな質問を 1 つのリクエストにまとめる
combined_prompt = """
以下の質問に順番に答えてください:
1. Python における list と tuple の違いは何ですか?
2. デコレータとは何ですか?
3. シングルトンパターンをどのように実装しますか?
"""
2. キャッシュメカニズムの使用
import hashlib
import json
# シンプルなローカルキャッシュ
cache = {}
def cached_query(prompt: str) -> str:
cache_key = hashlib.md5(prompt.encode()).hexdigest()
if cache_key in cache:
return cache[cache_key]
result = call_gemini_3_pro(prompt) # 実際の API 呼び出し
cache[cache_key] = result
return result
3. オフピーク時間の利用
- ピーク時間帯(米国の勤務時間など)を避ける
- 太平洋標準時の午前 0 時以降のクォータリセット直後に利用する
Gemini 3 Pro レート制限に関するよくある質問
Q1: わずか数件のメッセージを送信しただけでレート制限がかかるのはなぜですか?
これは、2025年12月のクォータ(割り当て)調整後によく見られる問題です。現在、Gemini 3 Pro Preview の無料枠の制限は非常に厳しく、公式ドキュメントに記載されている数値よりも低く設定されている可能性があります。一部のユーザーからは、実際の RPM(1分あたりのリクエスト数)がドキュメントの半分程度しかないという報告も寄せられています。
解決策: 継続的な利用が必要な場合は、APIYI(apiyi.com)などの中継プラットフォームを経由して呼び出すことをお勧めします。これにより、Google の無料枠による制限を直接受けることを回避できます。
Q2: 有料プランにアップグレードすれば、制限の問題は完全に解決しますか?
有料ティア(Tier 1)にアップグレードすると、RPM は 150〜300 に向上し、RPD(1日あたりのリクエスト数)の制限は実質的に解除されます。ただし、以下の点に注意が必要です:
- 外貨建て決済可能なクレジットカードの登録が必要
- トークン使用量に応じた従量課金制
- Gemini 3 Pro の価格設定は比較的高め(100万トークンあたり 2〜12ドル)
個人の学習ユーザーにとっては、APIYI(apiyi.com)などのプラットフォームを利用する方が経済的であり、かつ現地の決済方法も利用しやすいため、より実用的かもしれません。
Q3: API中継サービスの使用は安全ですか?
正規の API 中継プラットフォームを選択すれば安全です。APIYI を例にとると、以下の対策が講じられています:
- ユーザーの対話内容を保存しない
- HTTPS 暗号化通信をサポート
- 完全な API 呼び出しログの提供
定評があり、運営実績の長いプラットフォームを選択することをお勧めします。
Q4: Gemini 3 Pro と Gemini 2.5 Pro の違いは何ですか?
| 比較項目 | Gemini 3 Pro | Gemini 2.5 Pro |
|---|---|---|
| 推論能力 | 最強 | 強 |
| コンテキスト長 | 200K+ | 1M |
| マルチモーダル能力 | 強化 | 標準 |
| 無料枠クォータ | 厳格 | 100 RPD |
| 料金 | $2-12/1Mトークン | $1.25-5/1Mトークン |
最新の機能を必要としないタスクであれば、Gemini 2.5 Pro の方がコストパフォーマンスに優れています。
Q5: 2026年以降もクォータの調整は続きますか?
Google の発表によると、2026年3月3日に Gemini 2.0 Flash および Flash-Lite モデルの提供が終了します。以下の対応を推奨します:
- 早めに Gemini 2.5 シリーズへ移行する
- Google AI 開発者フォーラムの最新動向をチェックする
- 迅速なモデル切り替えが可能な APIYI(apiyi.com)などのマルチモデル対応プラットフォームの利用を検討する
Gemini 3 Pro レート制限解決策の比較
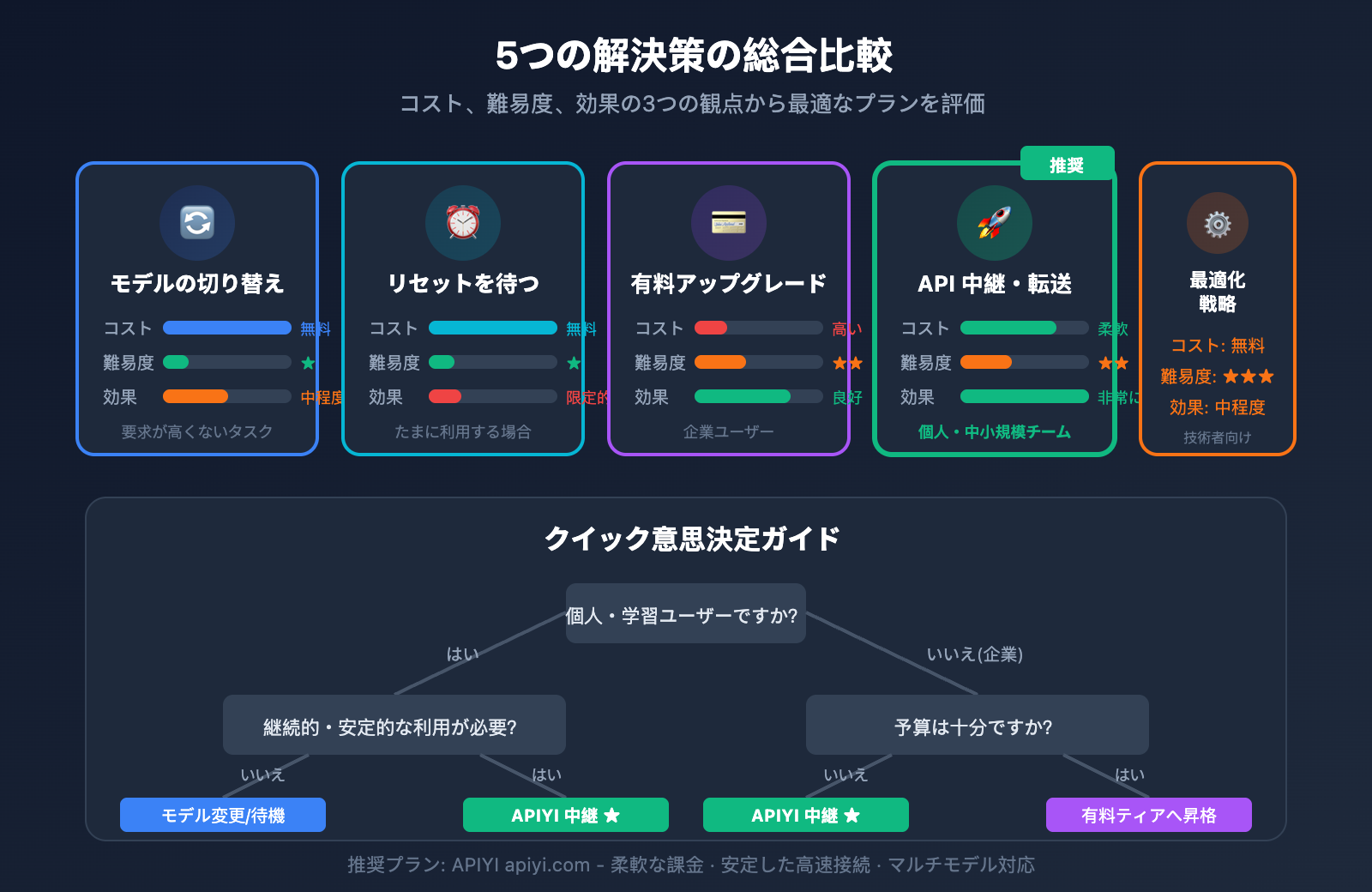
| 解決策 | コスト | 実施難易度 | 効果 | 推奨シーン |
|---|---|---|---|---|
| モデルの切り替え | 無料 | ⭐ | 中程度 | 要求が高くないタスク |
| リセットを待つ | 無料 | ⭐ | 限定的 | たまに利用する場合 |
| 有料ティアへのアップグレード | 高い | ⭐⭐ | 良好 | 企業ユーザー |
| API 中継プラットフォーム | 柔軟 | ⭐⭐ | 非常に良い | 個人・中小規模チーム |
| リクエスト戦略の最適化 | 無料 | ⭐⭐⭐ | 中程度 | 技術者向け |
💡 選択のアドバイス: 個人の学習ユーザーの方は、まずモデルの切り替えを試すか、API 中継プラットフォームの利用を検討することをお勧めします。APIYI(apiyi.com)は柔軟な従量課金制を採用しており、必要な分だけ支払うことができるため、クォータ制限を気にせず効率的にレート制限を解決できる有力な選択肢です。
まとめ
AI Studioの「You've reached your rate limit」エラーは、2025年12月にGoogleが無料枠のクォータ(割当量)を大幅に削減したことに起因しています。本記事で紹介した5つの解決策には、それぞれメリットとデメリットがあります。
- モデルを切り替える – 最も簡単で、一時的なニーズに適しています。
- リセットを待つ – コストはかかりませんが、効率は低いです。
- 有料プランにアップグレードする – 効果は高いですが、コストもかかります。
- API転送サービスを利用する – コスパが良く、個人ユーザーにおすすめです。
- 戦略を最適化する – 技術的なスキルが必要です。
多くの個人学習ユーザーには、**APIYI(apiyi.com)**を通じてレート制限の問題を素早く解決することをお勧めします。このプラットフォームは、Gemini 3 Pro、GPT-4、Claude 3.5などの主要な大規模言語モデルの統合呼び出しをサポートしており、安定したアクセスと柔軟な支払い方法を提供しています。
参考文献
-
Google AI – Rate Limits 公式ドキュメント
- リンク:
ai.google.dev/gemini-api/docs/rate-limits - 説明: Gemini API レート制限に関する公式説明
- リンク:
-
Google AI Developers Forum – Rate Limit に関する議論
- リンク:
discuss.ai.google.dev/t/youve-reached-your-rate-limit/35201 - 説明: レート制限に関するコミュニティユーザーの議論
- リンク:
-
Gemini API Pricing 公式料金プラン
- リンク:
ai.google.dev/gemini-api/docs/pricing - 説明: 各モデルの料金体系とクォータ情報
- リンク:
📝 著者: APIYI Team
🔗 テクニカルサポート: APIYI (apiyi.com) – ワンストップ AI 大規模言語モデル API 転送プラットフォーム
📅 更新日: 2026年1月24日