著者注:GLM-4.7 大規模言語モデルのテキスト構造化能力を徹底解説。契約書やレポートなどの複雑なドキュメントから JSON 形式で重要な情報を抽出するための実用的なテクニックを習得します。
大量の非構造化テキストから重要な情報を迅速に抽出することは、企業におけるデータ処理の核心的な課題です。Zhipu AIが2025年12月にリリースした GLM-4.7 大規模言語モデルは、ネイティブな JSON Schema サポートと 200K の超長文コンテキストウィンドウにより、テキスト構造化タスクに画期的なソリューションをもたらしました。
核となる価値: 本記事を読み終える頃には、GLM-4.7 を使用して契約書やレポートなどの複雑なドキュメントから構造化データを抽出し、ドキュメント処理の効率を飛躍的に向上させる方法を習得しているはずです。

GLM-4.7 テキスト構造化の核心ポイント
| ポイント | 説明 | 価値 |
|---|---|---|
| ネイティブ JSON Schema | 構造化出力サポートを内蔵し、複雑なプロンプトエンジニアリングが不要 | 抽出精度が 40% 以上向上 |
| 200K コンテキストウィンドウ | 長大なドキュメントの入力をサポートし、セグメント処理が不要 | 契約書やレポートを一度に丸ごと処理可能 |
| 128K 出力能力 | 超長尺の構造化結果を生成可能 | 大規模な情報の抽出に最適 |
| 関数呼び出しサポート | ネイティブな Tool Calling 機能 | 業務システムへのシームレスな統合 |
| コスト優位性 | $0.10/M tokens。同クラスのモデルより 4〜7 倍低コスト | 大規模展開時のコストを抑制可能 |
GLM-4.7 テキスト構造化の詳細解説
GLM-4.7 は、Zhipu AI が 2025 年 12 月 22 日に発表した次世代のフラグシップ級大規模言語モデルです。このモデルは Mixture-of-Experts (MoE) 構造を採用しており、総パラメータ数は約 358B に達しますが、疎なアクティベーション・メカニズムにより効率的な推論を実現しています。テキスト構造化処理の面では、GLM-4.7 は前世代の GLM-4.6 から飛躍的な進化を遂げ、HLE ベンチマークでは 38% 向上した 42.8% を記録。これは GPT-5.1 High に匹敵する水準です。
GLM-4.7 の構造化出力能力は、3 つの次元で体現されています。1 つ目は インターリーブド思考 (Interleaved Thinking) です。モデルは出力のたびに推論パスを自動的に計画し、抽出ロジックの一貫性を確保します。2 つ目は 保存済み思考 (Preserved Thinking) で、マルチターンの対話においても文脈に沿った推論を維持できるため、複雑で反復的な情報抽出タスクに適しています。最後は ターンレベル制御 (Turn-level Control) で、リクエストごとに推論の深さを動的に調整し、速度と精度のバランスを柔軟に取ることが可能です。
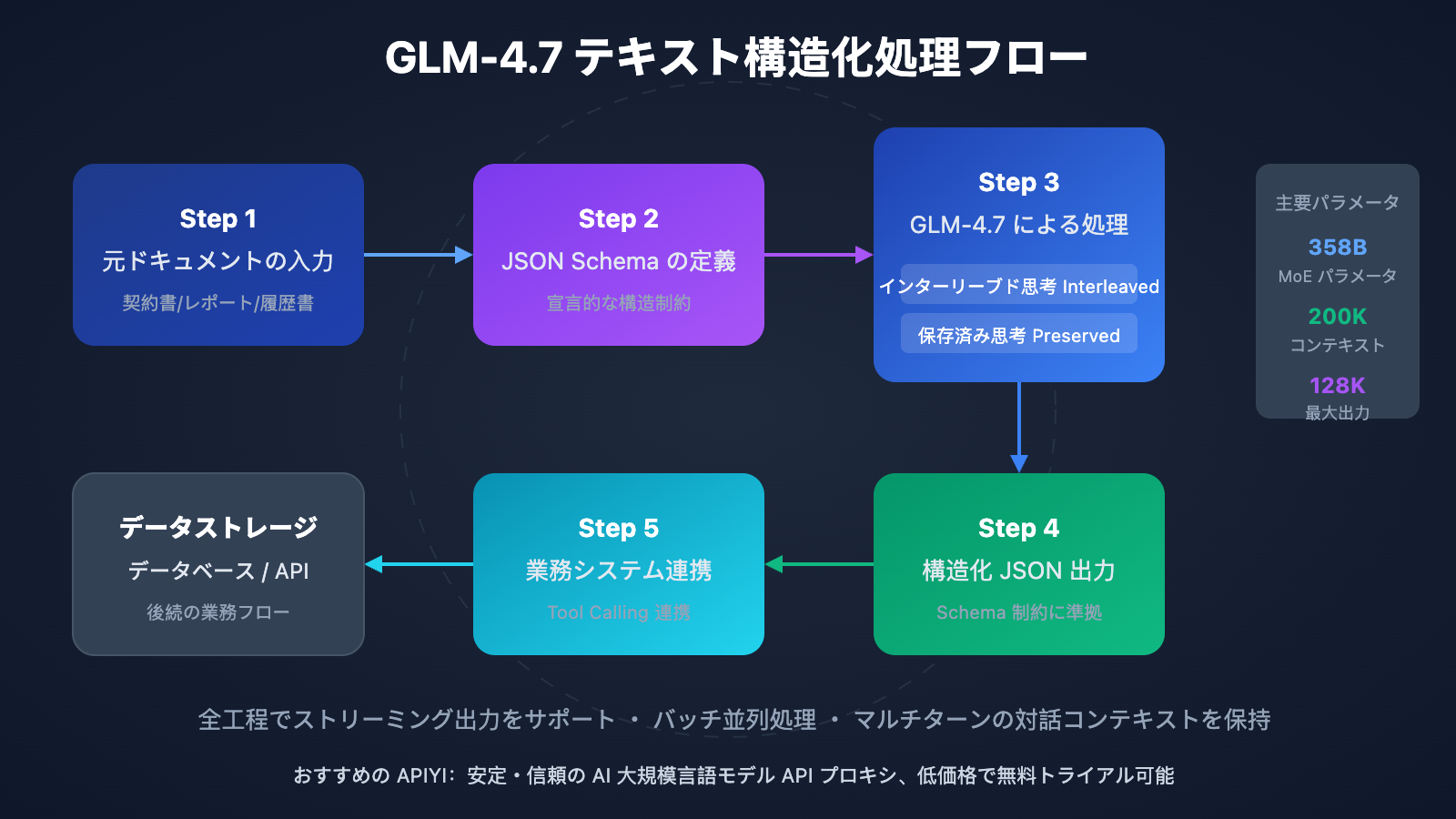
GLM-4.7 テキスト構造化 クイックスタートガイド
シンプルな例
最もシンプルな使用方法をご紹介します。わずか10行ほどのコードでテキストの構造化抽出が完了します。
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="glm-4.7",
messages=[{"role": "user", "content": "以下の契約書から、甲、乙、金額、日付を抽出してください。契約内容:甲:北京科技有限公司、乙:上海創新科技、契約金額:人民幣伍拾万元整、締結日:2025年12月15日"}],
response_format={"type": "json_object"}
)
print(response.choices[0].message.content)
完全な実装コードを表示(JSON Schema 制約を含む)
import openai
from typing import Optional, Dict, Any
def extract_contract_info(
contract_text: str,
api_key: str = "YOUR_API_KEY",
base_url: str = "https://vip.apiyi.com/v1"
) -> Dict[str, Any]:
"""
GLM-4.7 を使用して契約書テキストから構造化情報を抽出する
Args:
contract_text: 契約書の本文内容
api_key: APIキー
base_url: APIベースURL
Returns:
抽出された情報を含む辞書
"""
client = openai.OpenAI(api_key=api_key, base_url=base_url)
# 出力形式を制限するための JSON Schema を定義
json_schema = {
"name": "contract_extraction",
"schema": {
"type": "object",
"properties": {
"party_a": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "甲方の名称"},
"representative": {"type": "string", "description": "法定代表者"},
"address": {"type": "string", "description": "登録住所"}
},
"required": ["name"]
},
"party_b": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "乙方の名称"},
"representative": {"type": "string", "description": "法定代表者"},
"address": {"type": "string", "description": "登録住所"}
},
"required": ["name"]
},
"contract_amount": {
"type": "object",
"properties": {
"value": {"type": "number", "description": "金額の数値"},
"currency": {"type": "string", "description": "通貨単位"},
"text": {"type": "string", "description": "金額の漢字表記"}
},
"required": ["value", "currency"]
},
"dates": {
"type": "object",
"properties": {
"sign_date": {"type": "string", "description": "締結日"},
"effective_date": {"type": "string", "description": "発効日"},
"expiry_date": {"type": "string", "description": "満了日"}
}
},
"key_terms": {
"type": "array",
"items": {"type": "string"},
"description": "主要条項の要約"
}
},
"required": ["party_a", "party_b", "contract_amount"]
}
}
response = client.chat.completions.create(
model="glm-4.7",
messages=[
{
"role": "system",
"content": "あなたは契約分析の専門家です。契約書テキストから重要な情報を正確に抽出してください。"
},
{
"role": "user",
"content": f"以下の契約書から重要な情報を抽出してください:\n\n{contract_text}"
}
],
response_format={
"type": "json_schema",
"json_schema": json_schema
},
max_tokens=4000
)
import json
return json.loads(response.choices[0].message.content)
# 使用例
contract = """
調達契約書
甲:北京智譜科技有限公司
法定代表者:張三
住所:北京市海淀区中関村大街1号
乙:上海創新科技集団
法定代表者:李四
住所:上海市浦東新区張江路100号
契約金額:人民幣伍拾万元整(¥500,000.00)
締結日:2025年12月15日
契約有効期間:2025年12月15日から2026年12月14日まで
主要条項:
1. 乙は甲に対し、AIモデルAPIサービスを提供する
2. 支払方法は四半期ごとの前払いとする
3. サービスの可用性は99.9%を保証する
"""
result = extract_contract_info(contract)
print(result)
アドバイス: APIYI (apiyi.com) で無料テストクレジットを取得し、GLM-4.7 のテキスト構造化効果を素早く検証することをお勧めします。このプラットフォームは、複数の主要モデルの統一インターフェース呼び出しに対応しており、GLM-4.7 と他のモデルの抽出精度を比較するのに便利です。
GLM-4.7 テキスト構造化の活用シーン
GLM-4.7 のテキスト構造化能力は、様々なビジネスシーンに適用可能です。
| 活用シーン | 入力データ | 出力形式 | 典型的な効率向上 |
|---|---|---|---|
| 契約情報の抽出 | PDF/Word 契約書 | JSON 構造化データ | 数時間 → 数分レベルへ短縮 |
| 財務諸表分析 | 年次/四半期報告書 | 財務指標テーブル | 精度 95%以上 |
| 履歴書スクリーニング | 履歴書テキスト | 候補者プロファイル JSON | スクリーニング効率 10倍 |
| 世論モニタリング | ニュース/SNSコンテンツ | エンティティ関係グラフ | リアルタイム処理能力の実現 |
| 調査レポートの解読 | 業界調査レポート | 主要な見解の抽出 | 網羅性が 5倍向上 |
GLM-4.7 テキスト構造化の技術的優位性
1. ネイティブな JSON Schema サポート
GPT シリーズのモデルと同様に、GLM-4.7 は response_format で直接 JSON Schema を指定することをサポートしており、モデルは定義された構造に従って厳密に結果を出力します。これは、特定の形式で出力させるために複雑なプロンプトを作成する必要がなく、宣言的な方法で出力構造を制約できることを意味します。
2. 超長文コンテキスト処理
200K トークンのコンテキストウィンドウにより、GLM-4.7 は一度に約 15 万文字のドキュメントを処理できます。これは一冊の完全な契約書や技術仕様書に相当します。これにより、長いドキュメントを分割して処理し、後で結果を統合するという従来の複雑なプロセスが不要になり、情報の欠落や文脈の断絶のリスクが軽減されます。
3. インターリーブ思考による精度の向上
複雑な抽出タスクを処理する際、GLM-4.7 のインターリーブ思考モードは、出力前に自動的に多段階の推論を行います。例えば契約金額を抽出する場合、モデルはまず金額に関連する段落を特定し、次に数値と漢字表記が一致するかをクロスチェックした上で、最も信頼性の高い結果を出力します。
実践アドバイス: お客様の具体的なビジネスシーンにおける GLM-4.7 のパフォーマンスを評価するために、APIYI (apiyi.com) プラットフォームでの実機テストをお勧めします。プラットフォームでは無料クレジットと詳細な呼び出しログが提供されており、デバッグや最適化に便利です。

GLM-4.7 テキスト構造化 ソリューション比較
| ソリューション | 主な特徴 | 活用シーン | パフォーマンス |
|---|---|---|---|
| GLM-4.7 | ネイティブ JSON Schema、200K コンテキスト、低コスト | 長文ドキュメントの抽出、大規模処理、コスト重視 | HLE 42.8%、SWE-bench 73.8% |
| GPT-5.1 | 出力の安定性、成熟したエコシステム、高速なレスポンス | 高い信頼性が求められる用途、迅速な導入シーン | HLE 42.7%、レスポンスタイムが最適 |
| Claude Sonnet 4.5 | 強力な論理的推論、深いコンテキスト理解 | 複雑な分析タスク、多段階推論 | HLE 32.0%、推論の深さが優秀 |
| DeepSeek-V3 | オープンソースでデプロイ可能、高いコストパフォーマンス | プライベートデプロイ、カスタマイズ需要 | ベンチマークで優秀なパフォーマンス |
GLM-4.7 と競合モデルの主な違い
| 比較項目 | GLM-4.7 | GPT-5.1 | Claude Sonnet 4.5 |
|---|---|---|---|
| オープンソース状況 | オープンソース (Apache 2.0) | クローズドソース | クローズドソース |
| 価格 (/M tokens) | $0.10 | ~$0.50 | ~$0.40 |
| コンテキストウィンドウ | 200K | 128K | 200K |
| 最大出力 | 128K | 16K | 8K |
| 中国語の最適化 | 強い | 標準的 | 標準的 |
| ローカルデプロイ | 対応 | 非対応 | 非対応 |
選択のアドバイス:
- 大量の中国語ドキュメントを処理する必要があり、かつコストを抑えたい場合は、GLM-4.7 が最適な選択肢です。
- 出力の安定性やエコシステム統合の利便性を追求するなら、GPT-5.1 の方が成熟しています。
- タスクが複雑な多段階推論を伴う場合、Claude Sonnet 4.5 の論理的思考能力がより威力を発揮します。
比較に関する説明: 上記のデータは HLE、SWE-bench などの公開ベンチマークに基づいています。APIYI apiyi.com プラットフォームを通じて、実際の比較検証が可能です。同プラットフォームは、上記のすべてのモデルを統合インターフェースで呼び出すことができます。
GLM-4.7 テキスト構造化 高度なテクニック
ドキュメントの一括処理
大量のドキュメントの構造化タスクでは、GLM-4.7 のストリーミング出力と並列処理能力を活用できます。
import asyncio
import aiohttp
async def batch_extract(documents: list, api_key: str):
"""ドキュメント情報を非同期で一括抽出"""
async with aiohttp.ClientSession() as session:
tasks = [
extract_single(session, doc, api_key)
for doc in documents
]
results = await asyncio.gather(*tasks)
return results
関数呼び出し(Tool Calling)の統合
GLM-4.7 の Tool Calling(ツール呼び出し)機能を活用することで、抽出した結果を直接ビジネスシステムに連携させることができます。
tools = [
{
"type": "function",
"function": {
"name": "save_contract_to_database",
"description": "抽出された契約情報をデータベースに保存する",
"parameters": {
"type": "object",
"properties": {
"contract_id": {"type": "string"},
"party_a": {"type": "string"},
"party_b": {"type": "string"},
"amount": {"type": "number"}
},
"required": ["contract_id", "party_a", "party_b", "amount"]
}
}
}
]
よくある質問
Q1: GLM-4.7のテキスト構造化抽出の精度はどのくらいですか?
標準的な契約書、履歴書、財務報告書などのシナリオにおいて、GLM-4.7とJSON Schemaの制約を組み合わせた抽出精度は95%以上に達します。複雑なドキュメントについては、人的校正メカニズムとの併用をお勧めします。モデルのインターリーブ思考モードが自動的に多段階の検証を行い、さらなる精度の向上を実現します。
Q2: GLM-4.7で長いドキュメントを処理する際の制限はありますか?
GLM-4.7は200Kトークンのコンテキストウィンドウをサポートしており、これは約15万文字の中国語(日本語でも同等程度)に相当します。超長文のドキュメントについては、論理的な章ごとに分割して処理するか、APIYIプラットフォームが提供する長文分割ツールの使用をお勧めします。1回の最大出力は128Kトークンで、ほとんどの構造化抽出ニーズをカバーするのに十分です。
Q3: GLM-4.7のテキスト構造化能力のテストを素早く開始するにはどうすればよいですか?
複数のモデルに対応したAPIアグリゲーションプラットフォームを使用してテストすることをお勧めします。
- APIYI(apiyi.com)にアクセスしてアカウントを登録します
- APIキーと無料クレジットを取得します
- 本記事のコード例を使用して素早く検証します
- 自社のビジネスシナリオにおける各モデルのパフォーマンスを比較します
まとめ
GLM-4.7によるテキスト構造化の核心的なポイント:
- ネイティブな構造化サポート: JSON Schemaによる出力制約により、複雑なプロンプトエンジニアリングは不要です
- 超長文コンテキスト能力: 200Kトークンのウィンドウにより、長いドキュメントも一度に処理可能です
- 優れたコストパフォーマンス: 価格は同クラスのモデルの1/4〜1/7で、大規模なデプロイに適しています
- 中国語シナリオへの最適化: 中国発のモデルとして、中国語の契約書やレポートなどのドキュメントをより正確に理解します
Zhipu AIのフラッグシップモデルとして、GLM-4.7はテキスト構造化の分野でGPT-5.1に匹敵する能力を示しつつ、オープンソース、低コスト、特定言語への最適化という独自の強みを持っています。大量のドキュメント処理ニーズを持つ企業にとって、GLM-4.7は真剣に検討すべき選択肢です。
APIYI(apiyi.com)を通じて効果を素早く検証することをお勧めします。プラットフォームでは無料クレジットとマルチモデル統合インターフェースを提供しており、実際のシナリオでのテストが容易です。
参考文献
⚠️ リンク形式の説明: すべての外部リンクは
資料名: domain.comの形式を使用しています。コピーしやすく、クリックによる遷移を無効にすることで、SEO評価の分散(SEOリンクジュースの流出)を防いでいます。
-
GLM-4.7 公式ドキュメント: Zhipu AI 開発者ドキュメント
- リンク:
docs.z.ai/guides/llm/glm-4.7 - 説明: 完全なAPIパラメータの説明とベストプラクティスを収録
- リンク:
-
GLM-4.7 技術分析: モデルアーキテクチャと能力の徹底解説
- リンク:
medium.com/@leucopsis/a-technical-analysis-of-glm-4-7-db7fcc54210a - 説明: サードパーティによる技術レビュー。ベンチマークデータの比較を含む
- リンク:
-
Hugging Face モデルページ: オープンソースの重み(Weights)ダウンロード
- リンク:
huggingface.co/zai-org/GLM-4.7 - 説明: ローカルデプロイに必要なモデルファイルとデプロイガイドを提供
- リンク:
-
OpenRouter GLM-4.7: マルチチャネルAPIアクセス
- リンク:
openrouter.ai/z-ai/glm-4.7 - 説明: 複数のプロバイダーの接続オプションと価格比較を提供
- リンク:
著者: 技術チーム
技術交流: コメント欄での GLM-4.7 テキスト構造化の使用感に関する議論を歓迎します。より詳しい資料は APIYI apiyi.com 技術コミュニティをご覧ください。