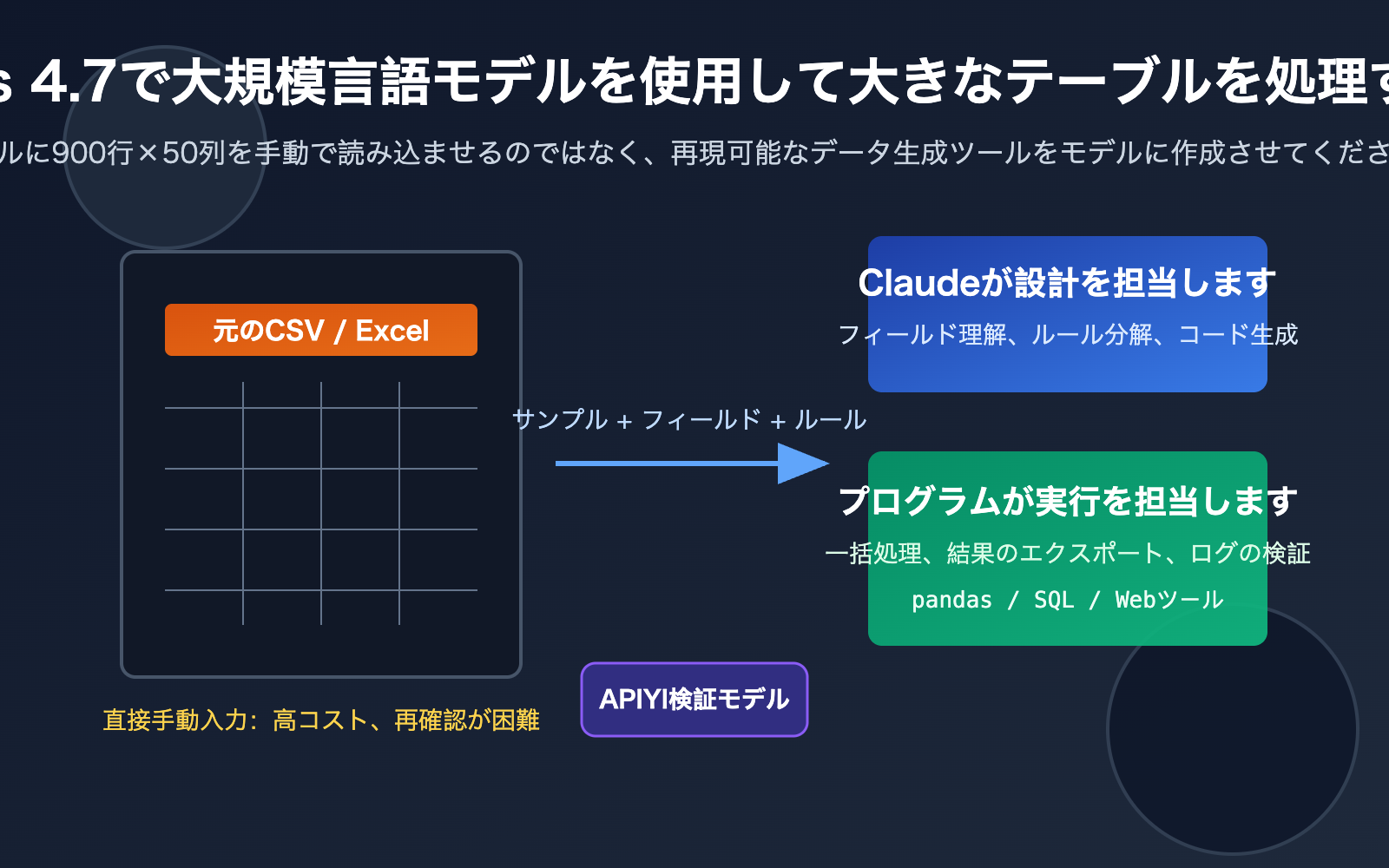
著者注:Claude Opus 4.7 を活用した CSV および Excel ファイル処理の実践的な経験を共有します。なぜ巨大なテーブルをそのまま AI に丸投げしてはいけないのか、代わりに AI にスクリプトを書かせ、ツールを構築し、検証を行わせるべき理由を解説します。
900行以上、50列もあるような CSV や Excel ファイルを手に、「この表を処理して」と Claude Opus 4.7 に直接投げても、一見賢そうに見えて再現性のない回答が返ってくるのが関の山です。問題は Claude Opus 4.7 の能力不足ではなく、あなたがそれを「データ処理プロセスの設計者」ではなく「手作業のデータ入力員」として扱っている点にあります。
より良い方法は、Claude Opus 4.7 に少量のサンプルデータ、完全なフィールド説明、そして目標とする結果を提示し、Python スクリプトの作成やウェブツールの生成、あるいは再現可能なデータパイプラインの設計をさせることです。そうすれば、モデルの推論能力とコーディング能力を活かしつつ、計算、フィルタリング、集計、検証といった作業を確実性の高いプログラムに任せることができます。
Claude Opus 4.7 で CSV を処理する際の核心ポイント
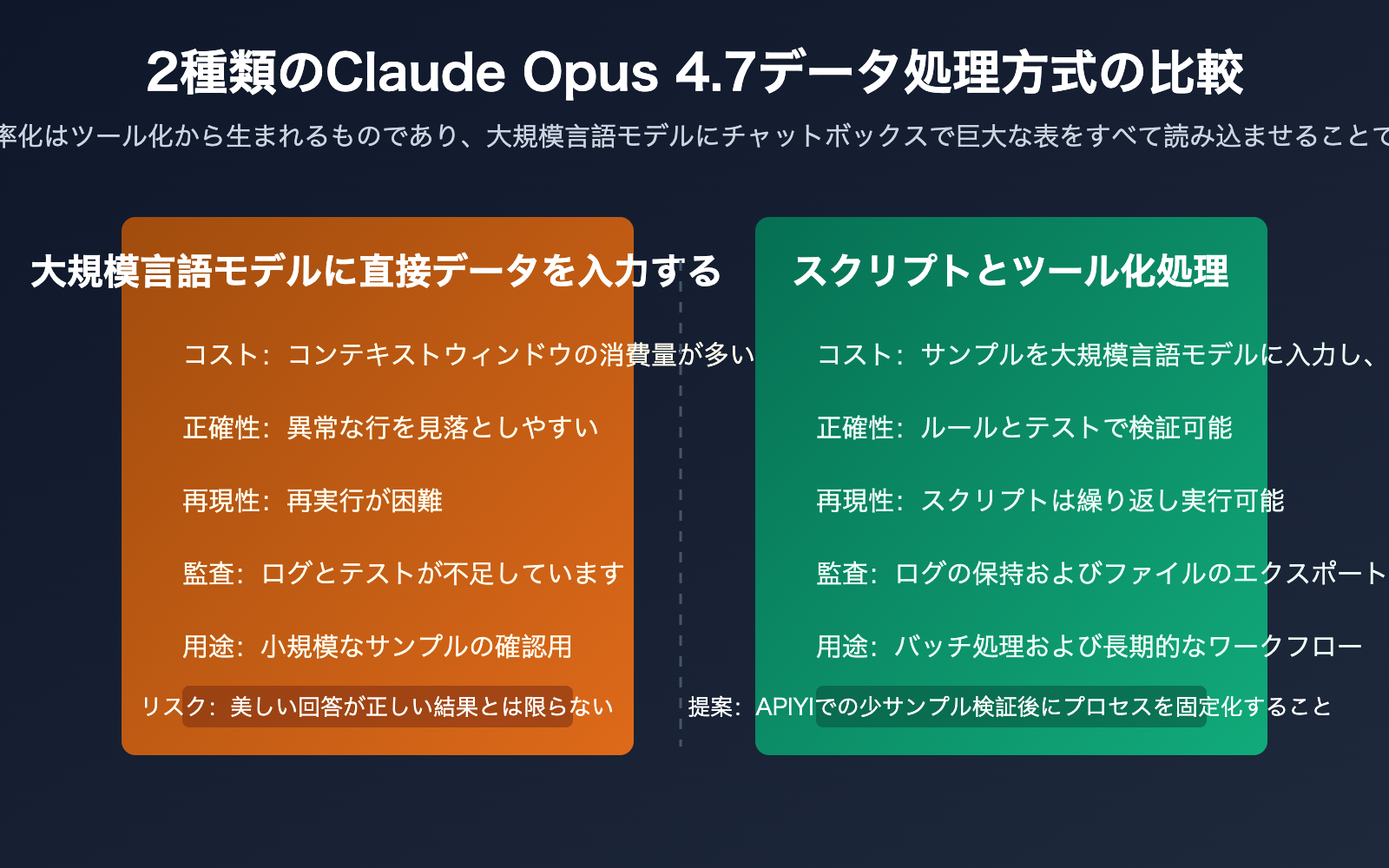
Claude Opus 4.7 はすでに強力なコーディングおよびエージェント型ワークフローモデルであり、公式も複雑なコード、企業ワークフロー、スプレッドシートのシナリオに適していると強調しています。しかし、「コンテキストウィンドウがより大きい」ことは「テーブル全体を対話に詰め込むべき」という意味ではありません。特に、データに大量の重複行、異常値、非表示列、混乱したフォーマット、複雑なビジネスルールが含まれている場合、生のデータをそのまま手入力するのは非効率的であり、結果の監査も困難になります。
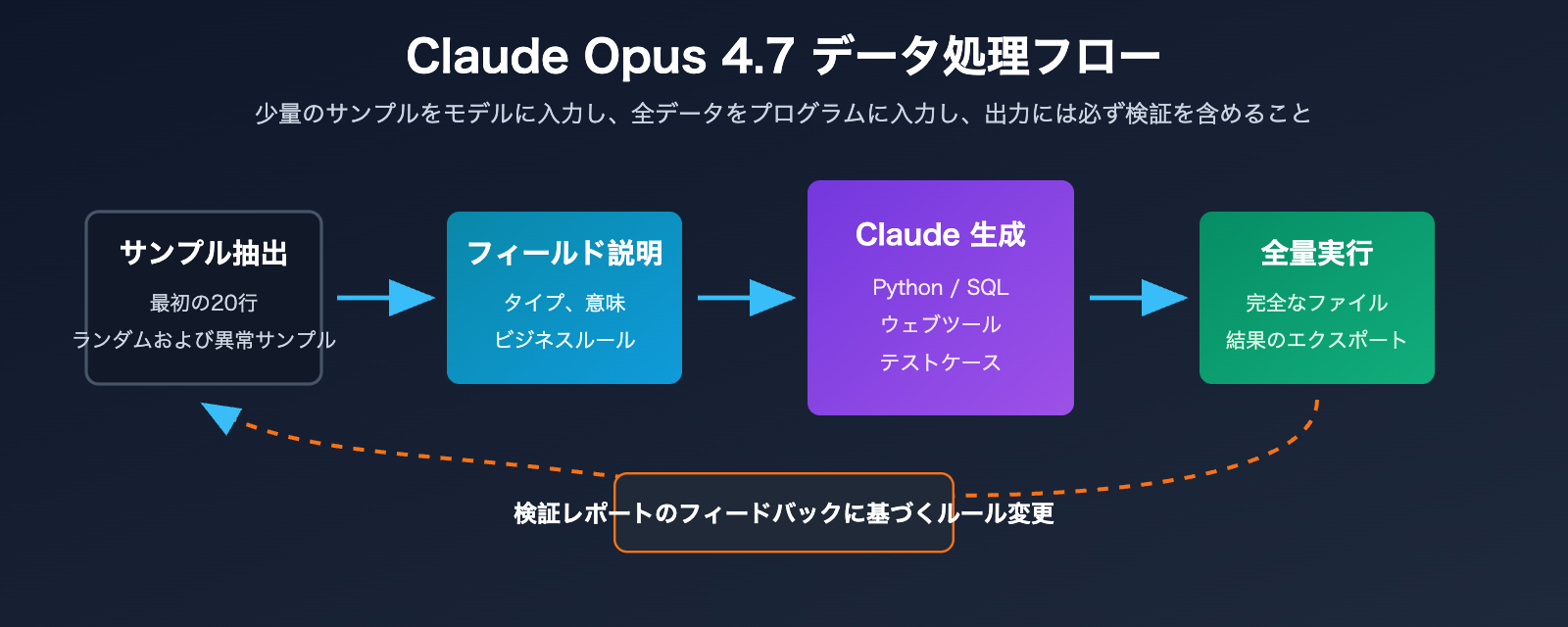
Claude Opus 4.7 を用いた真に効率的な CSV 処理方法は、モデルを「ビジネス目標の理解」「処理プログラムの生成」「出力結果の解釈」という3つのフェーズに配置することです。行ごとの読み取り、型変換、重複排除、集計、ソート、ファイルエクスポートといった作業は、Python、SQL、ブラウザベースのツール、あるいは Claude 自体のデータ分析ツールチェーンに任せるべきです。
| シナリオ | AI に直接表を読み込ませる問題点 | 推奨される Claude Opus 4.7 の活用法 | 結果の利点 |
|---|---|---|---|
| 900行×50列の CSV | コンテキスト消費が激しく、列や行の漏れが発生しやすい | 最初の20行のサンプルとフィールド説明を渡し、pandas スクリプトを書かせる | 再現性が高く、一括実行可能 |
| Excel の複数シート | 非表示の数式、結合セル、フォーマットが理解を妨げる | まず構造探索スクリプトを書かせ、ワークブックの概要を出力させる | 構造を理解してから処理できる |
| ビジネスルールのフィルタリング | 自然言語では境界条件を見落としやすい | ルールを関数とテストケースに変換させる | ルールが明確で検証可能 |
| レポート生成 | 一回限りの回答は再確認が困難 | エクスポートスクリプトと検証用サマリーを生成させる | 出力が安定し、納品しやすい |
ここで重要な判断基準があります。Claude Opus 4.7 は「データ分析に参加」することはできますが、「データそのものの唯一の実行環境」になるべきではありません。もし API を通じてデータ処理のプロンプトやモデルの選択を繰り返し検証する必要がある場合は、APIYI (apiyi.com) の統合インターフェースを使用して小規模なサンプルテストを行い、安定したプロンプトをスクリプトに落とし込むことをお勧めします。これにより、毎回巨大なテーブルをコピーし直す手間を省けます。
Claude Opus 4.7 による CSV 処理の分担原則
Claude Opus 4.7 は、フィールドの意味推論、クレンジング戦略の設計、異常事態の検知、コード生成、結果の解釈といった高レベルな判断に最も適しています。チャットウィンドウ内のテーブルテキストは構造情報の一部が失われやすく、繰り返し実行やバージョン管理にも適していないため、確定的な計算をチャットボックスに担わせるべきではありません。
より堅実な原則は「モデルには小規模なサンプルを、プログラムにはビッグデータを」です。まず最初の20行、ランダムな20行、異常値を含む20行を提供し、さらにフィールド辞書と目標とする出力を補足します。Claude Opus 4.7 がこれらの情報に基づいてスクリプトを生成した後、そのスクリプトで完全な CSV や Excel ファイルを実行する。このように、モデルが設計を担い、プログラムが実行を担うのが理想的です。
Claude Opus 4.7 で Excel を扱う際、巨大なテーブルをそのまま読み込ませてはいけない理由
Excel と CSV はどちらも表形式ですが、その複雑さは全く異なります。CSV は純粋なテキストの行と列で構成されていますが、Excel には複数のシート、数式、書式設定、フィルター状態、非表示列、結合セル、日付シリアル値、ローカライズされた数値形式などが含まれる可能性があります。Excel をそのままテキストとしてコピーして AI に渡すと、これらの重要な情報が平坦化されてしまい、モデルは元のワークブックではなく、破壊された平面的なテキストとして認識することになります。
公式の英語資料によると、Claude 関連製品はすでに分析ツール、コード実行、Data プラグイン、および Excel シナリオ機能をサポートしています。これらの方向性は、「表の処理はチャットウィンドウ内でのモデルによる『脳内計算』に頼るのではなく、ツール環境に依存すべきである」という事実を示しています。たとえ Claude Opus 4.7 がより大きなコンテキストウィンドウをサポートしていても、そのコンテキストは業務ルール、フィールドの説明、サンプル例、検証要件のために使うべきであり、テーブルの全行・全列のデータで浪費すべきではありません。
| データの特徴 | 直接アップロード/貼り付けのリスク | Claude Opus 4.7 への推奨入力 | 推奨ツール |
|---|---|---|---|
| 列が多い | 各列の意味をモデルが安定して記憶できない | フィールド辞書、列の型、主要列の説明 | pandas、SQL |
| 行が多い | トークンコスト増、結果の再現性が低い | ヘッダーサンプル、ランダムサンプル、異常値サンプル | Pythonによる分割処理 |
| 複数シート | シート間の関係が失われやすい | ワークブック構造の要約、シートの用途説明 | openpyxl、Excelプラグイン |
| データが汚い | 異常値が推論に悪影響を与える | 欠損値統計、重複行統計、書式サンプル | データ品質チェック用スクリプト |
| 複雑なルール | 自然言語による説明が逸脱しやすい | 明確なルール、反例、期待される出力サンプル | ユニットテスト、検証スクリプト |
技術的アドバイス: Claude Opus 4.7 を既存のデータ処理システムに統合する場合、まずは APIYI (apiyi.com) を通じてインターフェースレベルの検証を行うことをお勧めします。まずは小規模なサンプルでプロンプト、モデルパラメータ、エラー処理を最適化してから、完全なファイル処理パイプラインに組み込んでください。
Claude Opus 4.7 で Excel を扱う際の重要な誤解
第一の誤解は、「モデルが表を理解できる」ことを「モデルが巨大な表を直接処理すべきだ」と解釈することです。小規模なファイルや一時的な分析、探索的な質疑応答では CSV や Excel をアップロードするのは便利ですが、バッチ処理、顧客リストのスコアリング、注文照合、財務分類といったタスクでは、一度きりの自然言語による回答ではなく、繰り返し実行可能なルールが必要です。
第二の誤解は、最初の20行のサンプルだけを与えることです。最初の20行は通常、正常な構造しか示しておらず、異常なケースをカバーできません。より良いサンプルの組み合わせは「最初の20行 + ランダムな20行 + 異常値を含む20行 + フィールド辞書 + ターゲットとなる出力の3行」です。これにより、Claude Opus 4.7 は実際の業務に近い処理ロジックを記述できるようになります。
Claude Opus 4.7 で CSV を扱うための5ステップワークフロー
以下のフローは、ほとんどの CSV および Excel 自動化タスクに適しています。特に500行以上、20列以上のフィールドがあり、ルールを繰り返し調整する必要があるシナリオに最適です。最初からファイルをすべてモデルに渡す必要はありません。サンプル、構造、目標を明確にし、スクリプト、テスト、出力の説明を生成させるだけで十分です。
| ステップ | Claude Opus 4.7 への提供材料 | Claude に生成させる内容 | 人間が確認すべき点 |
|---|---|---|---|
| 1. 構造の調査 | ファイル形式、フィールド名、サンプル行 | フィールド型の仮説とクレンジング計画 | フィールドの意味が正しいか |
| 2. ルールの定義 | 業務目標、フィルタ条件、反例 | 処理ルール表と境界条件 | 業務上の例外をカバーしているか |
| 3. スクリプト生成 | サンプルデータ、目標出力形式 | Python または SQL 処理スクリプト | ローカルで実行可能か |
| 4. 小規模検証 | 20〜60行のサンプル | 期待される出力とテストアサーション | 出力が直感と合致しているか |
| 5. 全量実行 | 完全なファイルパス | 結果ファイル、ログ、検証レポート | 合計、金額、グループ分けが正しいか |
このフローの核心的な価値は、「一度きりの質問」を「実行可能な資産」に変えることです。業務ルールが変更された場合、Claude Opus 4.7 にスクリプトとテストを修正させるだけで済みます。データを再アップロードしたり、コンテキストを再説明したり、モデルがすべての詳細を記憶しているか賭けに出たりする必要はありません。
Claude Opus 4.7 で CSV を扱うためのプロンプトテンプレート
以下のプロンプト構造をそのまま再利用できます。CSV の内容を貼り付けるだけでなく、フィールドの意味、処理目標、異常サンプル、受け入れ基準を明確にしてください。モデルが「何が正解か」を理解すればするほど、生成されるスクリプトは安定します。
CSV/Excel のデータ処理タスクがあります。結論だけを出すのではなく、以下の手順で進めてください。
目標:
顧客リストを業界、役職、会社規模に基づいてスコアリングし、トップリードを出力する。
データサンプル:
1. 最初の20行:...
2. ランダムな20行:...
3. 異常値を含む20行:...
フィールド説明:
- company_name:会社名
- title:連絡先の役職
- employee_count:従業員数(空の可能性あり)
- industry:業界(同義語が存在する可能性あり)
以下のタスクを完了してください:
1. フィールドの意味と潜在的なデータ品質の問題を説明する
2. input.csv を読み込む Python スクリプトを作成する
3. cleaned.csv と scored.csv を出力する
4. 基本的な検証(行数、空値、重複値、スコア分布)を追加する
5. 未知のフィールドの意味を勝手に推測せず、不確実なルールは TODO としてマークする
このフローを API サービスとして構築する場合、プロンプトテンプレート、フィールド辞書、サンプルデータを固定入力として、APIYI (apiyi.com) を経由して Claude Opus 4.7 や他の利用可能なモデルを呼び出し、比較テストを行うことができます。これにより、コード生成、ルール解釈、異常処理におけるモデル間の違いを素早く判断できます。
Claude Opus 4.7 で CSV を扱う Python サンプル
以下は、正しいアプローチを体現した最小限のバージョンです。Claude Opus 4.7 がスクリプトを書き、そのスクリプトが完全なファイルを読み込み、結果と検証サマリーを出力します。実際のプロジェクトでは、ログ、例外処理、ユニットテスト、設定ファイルなどを追加していくことができます。
import pandas as pd
INPUT = "input.csv"
OUTPUT = "scored.csv"
df = pd.read_csv(INPUT)
required = ["company_name", "title", "employee_count", "industry"]
missing = [col for col in required if col not in df.columns]
if missing:
raise ValueError(f"不足している列: {missing}")
df["employee_count"] = pd.to_numeric(df["employee_count"], errors="coerce").fillna(0)
df["score"] = 0
# 役職に基づくスコアリング
df.loc[df["title"].str.contains("cto|chief|founder", case=False, na=False), "score"] += 40
# 従業員数に基づくスコアリング
df.loc[df["employee_count"].between(50, 500), "score"] += 30
# 業界に基づくスコアリング
df.loc[df["industry"].str.contains("ai|software|saas", case=False, na=False), "score"] += 30
print({"rows": len(df), "duplicates": int(df.duplicated().sum())})
df.sort_values("score", ascending=False).to_csv(OUTPUT, index=False)
モデルに出力結果を解釈させたい場合は、スクリプトで summary.json を生成した後、その要約を Claude Opus 4.7 に渡すと良いでしょう。マルチステップの自動化タスクでは、APIYI (apiyi.com) を通じてモデル呼び出し、失敗時の再試行、ログ保存を一元管理することをお勧めします。これにより、データ処理パイプラインの保守性が大幅に向上します。
Claude Opus 4.7 によるExcel処理のツール選択
タスクに応じて最適なツールを選択することが重要です。一時的なデータ探索であればClaudeの分析機能やDataプラグインが適していますが、業務フローに組み込む場合はPythonスクリプト、SQLパイプライン、またはWebツールの方が適しています。チーム内に技術に詳しくないメンバーがいる場合は、Claude Opus 4.7にローカルで動作するWebツールを作成させ、ファイルのアップロード、ルール選択、結果のダウンロードを視覚的なインターフェースで行えるようにすると非常に便利です。
| ツール構成 | 適したタスク | 不向きなタスク | 推奨される使い方 |
|---|---|---|---|
| Pythonスクリプト | 一括クレンジング、スコアリング、照合、エクスポート | コマンドラインが全く分からないチーム | ClaudeにスクリプトとREADMEを書かせる |
| ローカルWebツール | 非技術者による同種ファイルの繰り返し処理 | 複雑なバックエンド権限や複数人での共同作業 | ClaudeにHTML/JSまたは軽量サービスを作成させる |
| SQLパイプライン | データウェアハウス、注文データ、ログ分析 | 一時的な小規模Excel表 | Claudeにクエリと検証用SQLを書かせる |
| Claudeデータツール | 探索的分析、グラフ作成、一時的なレポート | 厳格なコンプライアンスや長期的な自動化タスク | まず探索し、その後スクリプトとして定着させる |
| APIワークフロー | 複数モデルの比較、自動化システムの統合 | 一回限りの手作業 | 統一インターフェースを通じてデバッグする |
Claude Opus 4.7 でExcel処理用のWebツールを作る考え方
ユーザーがPythonに詳しくない場合、「ClaudeにWebツールを書かせる」ことは「ClaudeにCSVを直接読み込ませる」よりも実用的です。Webツールであれば、アップロードボタン、フィールドマッピング、ルール設定、結果プレビュー、ダウンロードボタンを実装でき、ユーザーは毎回AIと対話することなく、ファイルを選択するだけで処理を完結できます。
Claude Opus 4.7に対しては、「Papa Parseを使用してCSVを読み込み、フロントエンドでフィールドマッピングとスコアリングを行い、最終的に新しいCSVをエクスポートする単一ファイルのHTMLツールを作成して」といった指示を出すと良いでしょう。データ量が少なく、機密性の高いルールを含まず、ローカルブラウザで動作させるだけであれば、この方法は非常に経済的です。より複雑な権限管理や監査、大規模ファイルが必要な場合は、バックエンドサービスへの移行を検討してください。
導入のアドバイス: Webツールにモデルの解釈機能やフィールドマッピングの提案、異常診断などを組み込みたい場合は、APIYI (apiyi.com) を通じてモデルインターフェースを呼び出すことができます。フロントエンドはインタラクションのみを担当し、バックエンドでモデルへのリクエストやログ記録を行う構成がおすすめです。
Claude Opus 4.7 によるCSV検証チェックリスト
データ処理において最も恐ろしいのは、コードがエラーを出さずに、誤った結果を静かに出力することです。そのため、Claude Opus 4.7にPython、SQL、Webツールのいずれを作成させる場合でも、必ず検証チェックリストを同時に生成するよう要求してください。このリストは複雑である必要はありませんが、行数、フィールド、空値、重複値、主要指標、サンプリングによる再確認を網羅する必要があります。
| 検証項目 | 重要性 | 推奨される確認方法 | 異常時の処理案 |
|---|---|---|---|
| 入出力行数 | 誤削除や重複生成の防止 | len(input) と len(output) の比較 |
差異の理由を説明 |
| 必須フィールド | フィールド名変更による計算ミス防止 | 列セットのチェック | 欠損時は即座にエラー |
| 空値の割合 | スコアリングや分類の偏り防止 | 列ごとの空値統計 | 閾値超過時に警告を書き込み |
| 重複レコード | 重複課金や重複アプローチの防止 | 主キーまたは複合キーによる重複排除 | 重複レポートを作成 |
| 金額・数量合計 | 集計ロジックの誤り防止 | 集計前後の合計値比較 | 不一致時は処理を中断 |
| サンプリング確認 | ルール解釈のズレ発見 | ランダムに20行抽出し目視確認 | 問題をClaudeにフィードバックして修正 |
実際に使用する際は、この表をプロンプトの一部として組み込み、Claude Opus 4.7がスクリプトを生成する際に自動的に対応するチェック機能を追加させるのが効果的です。APIYI (apiyi.com) でモデル呼び出しテストを行う際も、検証結果を固定の戻り値として要求することをお勧めします。これにより、単に回答が綺麗かどうかだけでなく、モデルの安定性を比較しやすくなります。
Claude Opus 4.7 でCSVを処理する際のNGプロンプト
「この表をクレンジングして」とだけ伝えるのは避けましょう。より良い方法は、「まず必要なフィールド情報を指摘してからスクリプトを書いてください。最終的な結論をいきなり出さないでください。ステップごとにログを出力し、判断できないルールにはTODOを付けてください。5つのユニットテスト用サンプルを生成してください」といった指示です。このような制約を設けることで、モデルは暗黙の推論を明示化せざるを得なくなり、業務の誤解をより早く発見できるようになります。
同様に、最初の20行のサンプルを完全な事実として扱わないでください。最初の20行は構造を理解するのには適していますが、汚いデータ(ダーティデータ)を網羅するには不十分です。空値、重複、日付形式の混在、負の金額、列挙値のスペルミス、日本語と英語の混在など、異常なサンプルを別途提供するようにしましょう。
Claude Opus 4.7 による CSV 処理 FAQ
Claude Opus 4.7 で CSV を処理する際、最初の20行のサンプルで十分ですか?
十分ではありませんが、良い出発点にはなります。最初の20行はフィールド構造や正常なレコードを確認するには適していますが、異常値まではカバーできません。「最初の20行 + ランダムな20行 + 異常値を含む20行」という組み合わせがより推奨されます。サンプルを Claude Opus 4.7 に渡した後は、サンプルに基づいた結論だけを求めるのではなく、フルデータに対して実行するためのスクリプトを作成するよう依頼すべきです。
Claude Opus 4.7 で Excel を処理する場合、ファイル全体をアップロードすべきですか?
一時的な調査であれば、ファイルをアップロードしてツールで分析させることも可能です。しかし、長期的に再利用する業務フローであれば、まず Claude Opus 4.7 に構造解析スクリプトを書かせ、その後に処理用スクリプトを生成させるべきです。API 自動化のシナリオでは、APIYI (apiyi.com) を通じて小さなサンプルでテストし、モデルがフィールドやルールを安定して理解できることを確認してから、全量処理のフローに接続するのが賢明です。
Claude Opus 4.7 は 1M のコンテキストウィンドウがあるため、スクリプトは不要になりますか?
いいえ、不要にはなりません。コンテキストが大きければ、より多くのフィールド説明やサンプル、業務背景を詰め込むことはできますが、それは再現可能な計算プログラムの代わりにはなりません。特に金額計算、ランキング、グループ化、重複排除、統計基準などが絡む場合、スクリプトと検証こそが結果の信頼性を担保する基盤となります。
Claude Opus 4.7 による Excel 処理と従来の BI にはどのような違いがありますか?
Claude Opus 4.7 は曖昧な要件をルールやコード、解説に変換するのに適しており、従来の BI は安定したレポート作成、権限管理、データモデリング、複数人での共同作業に適しています。両者は対立するものではなく、Claude でデータクレンジングのスクリプトや分析ロジックを生成し、その安定した結果を BI やデータウェアハウスに統合するという使い方が可能です。
プログラミングの知識がなくても、Claude Opus 4.7 での CSV 処理は使う価値がありますか?
あります。ただし、チャット画面で直接最終結果を出力させるのではなく、ローカルで動作するウェブツールや詳細な操作手順を作成させることをお勧めします。処理ロジックをボタンやフォーム、ダウンロード機能として実装させ、自分はファイルのアップロードと結果の確認に専念するようにしましょう。モデルの API が必要な場合は、APIYI (apiyi.com) を使って、様々なモデルのコード生成効果を素早くテストできます。
Claude Opus 4.7 で機密性の高い Excel ファイルを処理する際の注意点は?
機密データは、事前に匿名化するか、管理された環境で処理する必要があります。身分証番号、電話番号、顧客契約書、財務明細などをそのまま不確実な環境に送信してはいけません。より安全な方法は、匿名化したサンプルとフィールド構造を提供して Claude にスクリプトを書かせ、そのスクリプトをローカル環境や企業内の安全な環境で実行することです。
Claude Opus 4.7 による CSV 処理の重要なポイント(Key Takeaways)
- Claude Opus 4.7 で CSV を処理する際のベストプラクティスは、巨大なファイルを直接読み込ませることではなく、サンプルとルールに基づいて実行可能なスクリプトを生成させることです。
- 最初の20行のサンプルは構造を理解する助けにはなりますが、実際のタスクにはランダムサンプル、異常値サンプル、およびフィールド定義書が必要です。
- Excel は CSV よりも複雑であり、複数のシート、数式、非表示列、書式設定などが処理結果に影響を与える可能性があるため、まずは構造解析から行うべきです。
- バッチ処理タスクにおいては、チャットウィンドウでの一度きりの回答よりも、Python、SQL、またはローカルのウェブツールの方が再現性が高くなります。
- 検証リストは処理スクリプトと同時に生成し、行数、フィールド、空値、重複値、および主要な合計値のチェックを重点的に行う必要があります。
- API 自動化のシナリオでは、まず小規模なサンプルでモデルのテストを行い、安定したソリューションを本番環境のパイプラインに組み込むことを推奨します。
Claude Opus 4.7 による Excel データ処理の推奨アプローチ
Claude Opus 4.7 はデータ処理タスクにおいて非常に強力ですが、その真価を発揮させるコツは「表データをそのまま AI に丸投げする」ことではなく、「AI にデータ処理用のツールを設計させる」ことにあります。データ規模が数百行・数十列に及ぶ場合や、業務ルールを繰り返し適用する必要がある場合は、スクリプト、Web ツール、SQL パイプライン、あるいは検証レポートを作成させる方が、はるかに効率的で経済的です。
Claude Opus 4.7 を「データエンジニアリングのアシスタント」として活用してみましょう。少量のサンプルを見せ、ルールを明確にし、処理用スクリプトの作成やテストの生成、結果の解説を依頼するのです。こうすることで、大規模言語モデルが持つ「ビジネス上の文脈を理解する」という強みを活かしつつ、生のデータを直接入力する際に発生しがちな非効率性や、監査の難しさを回避できます。
Claude Opus 4.7 を活用した CSV、Excel、データ自動化関連の開発を行っているなら、まずは APIYI (apiyi.com) を利用してモデル呼び出しやプロンプトの検証を行うことをお勧めします。安定したワークフローを構築してから、それをスクリプトやツールとして定着させることで、コストをより適切に管理でき、チームでの再確認や長期的な保守も容易になります。
参考資料:
- Anthropic Claude Opus 4.7: anthropic.com/claude/opus
- Claude Opus 4.7 使用ガイド: claude.com/resources/tutorials/working-with-claude-opus-4-7
- Claude コード実行ツール: platform.claude.com/docs/en/agents-and-tools/tool-use/code-execution-tool
- Claude データプラグイン: claude.com/plugins/data