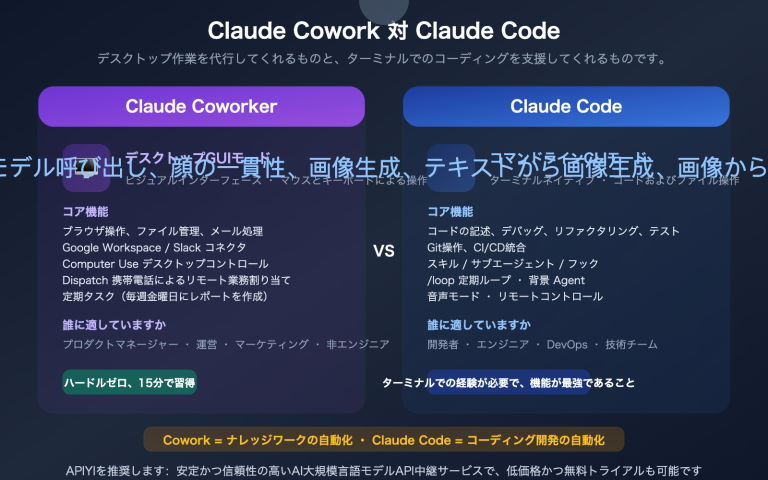
作者注:手取り足取り、Chatbox でカスタムエンドポイントを使用して gpt-image-2 を接続する方法を解説します。また、なぜ Chatbox が ChatGPT のウェブ版のように画像生成後の連続的な対話や修正ができないのか、その背景にある images/generations、chat/completions、Responses API という 3 つの異なるエンドポイントのアーキテクチャの違いを深掘りします。
多くのユーザーが Chatbox クライアントに OpenAI API Key を設定し、gpt-image-2 を入力して直接画像生成を試みた結果、エラーが返されたり、文字化けしたりするケースが多発しています。本記事では 2 つの答えを提示します。第一に、Chatbox で gpt-image-2 を正しく接続する方法(カスタムエンドポイント https://api.apiyi.com/v1/images/generations の設定)、第二に、より重要な「なぜ Chatbox は ChatGPT ウェブ版のように『画像を生成してから、対話で修正する』ことができないのか」という点です。
これは Chatbox のバグではありません。 OpenAI 公式が画像生成、対話補完、マルチターン編集をそれぞれ全く異なる API エンドポイントに割り当てているためであり、Chatbox がデフォルトで利用するルート自体が、連続的な画像生成や編集をサポートしていないのです。
核心的価値:この記事を読み終えれば、OpenAI の 3 つの主要エンドポイントの境界と能力の違いを完全に理解できます。どのような状況なら Chatbox で十分か、どのような状況で Responses API に切り替えるべきか、そして APIYI 中継サービスを使って国内からいかに安定して各エンドポイントを呼び出すかが分かります。
Chatbox で gpt-image-2 を接続する正しい方法
まずは最も実用的な内容からお伝えします。Chatbox で今すぐ gpt-image-2 による画像生成を動かしたい場合は、以下の手順で 5 分で完了します。
Chatbox で gpt-image-2 を接続するための核心設定
Chatbox はデフォルトで「チャット対話補完」形式で API を呼び出しますが(つまり /v1/chat/completions エンドポイント)、gpt-image-2 は対話モデルではなく純粋な画像生成モデルであり、呼び出し先は /v1/images/generations です。そのため、Chatbox の「カスタムエンドポイント」機能を使用してデフォルトのアドレスを書き換える必要があります。
設定手順の全容:
| 手順 | 操作 | 重要なパラメータ |
|---|---|---|
| 1 | Chatbox 設定 → モデルプロバイダー → カスタムプロバイダーを追加 | OpenAI API 互換モードを選択 |
| 2 | API Host | https://api.apiyi.com |
| 3 | API Path(重要) | /v1/images/generations |
| 4 | API Key | APIYI コンソールで取得した Bearer Token |
| 5 | Model フィールド | gpt-image-2 |
| 6 | タイムアウト時間 | 360 秒以上に設定 |
Chatbox で gpt-image-2 を呼び出す最小構成例
以下は公式推奨の curl 呼び出し例です。まずはこれを使って、API Key が正しく機能するか確認してください。
curl --request POST \
--url https://api.apiyi.com/v1/images/generations \
--header 'Authorization: Bearer sk-your-apiyi-key' \
--header 'Content-Type: application/json' \
--data '{
"model": "gpt-image-2",
"prompt": "横長 16:9 の映画のような画角、夕暮れ時の海辺にある古い灯台"
}'
この curl コマンドが成功したら、Chatbox のエンドポイントを /v1/images/generations に書き換えれば利用可能になります。
🎯 設定のヒント:Chatbox のカスタムエンドポイントを初めて設定する際は、まず curl で API Key とエンドポイントのパスが正常か確認することをお勧めします。APIYI (apiyi.com) プラットフォームでテスト用クレジットを取得すれば、無料で全設定の検証が可能です。
Chatbox で gpt-image-2 を接続する際によくある設定ミス
ユーザーが最も陥りやすい 5 つの落とし穴をまとめました。
| エラー現象 | 原因 | 解決策 |
|---|---|---|
model not found が返る |
エンドポイントが /v1/chat/completions になっている |
/v1/images/generations に変更 |
invalid prompt format が返る |
チャットの messages 形式を使用している | prompt フィールド(文字列)を使用する |
| 60 秒後にリクエストがタイムアウト | デフォルトのタイムアウトが短すぎる | 360 秒以上に設定(高画質生成には時間が必要) |
| 画像が表示されない | Chatbox が b64_json を解析できていない | レスポンスを url 形式で返すようにする |
| 日本語のプロンプトでエラー | エンコーディングの問題 | Content-Type: application/json; charset=utf-8 を確認 |
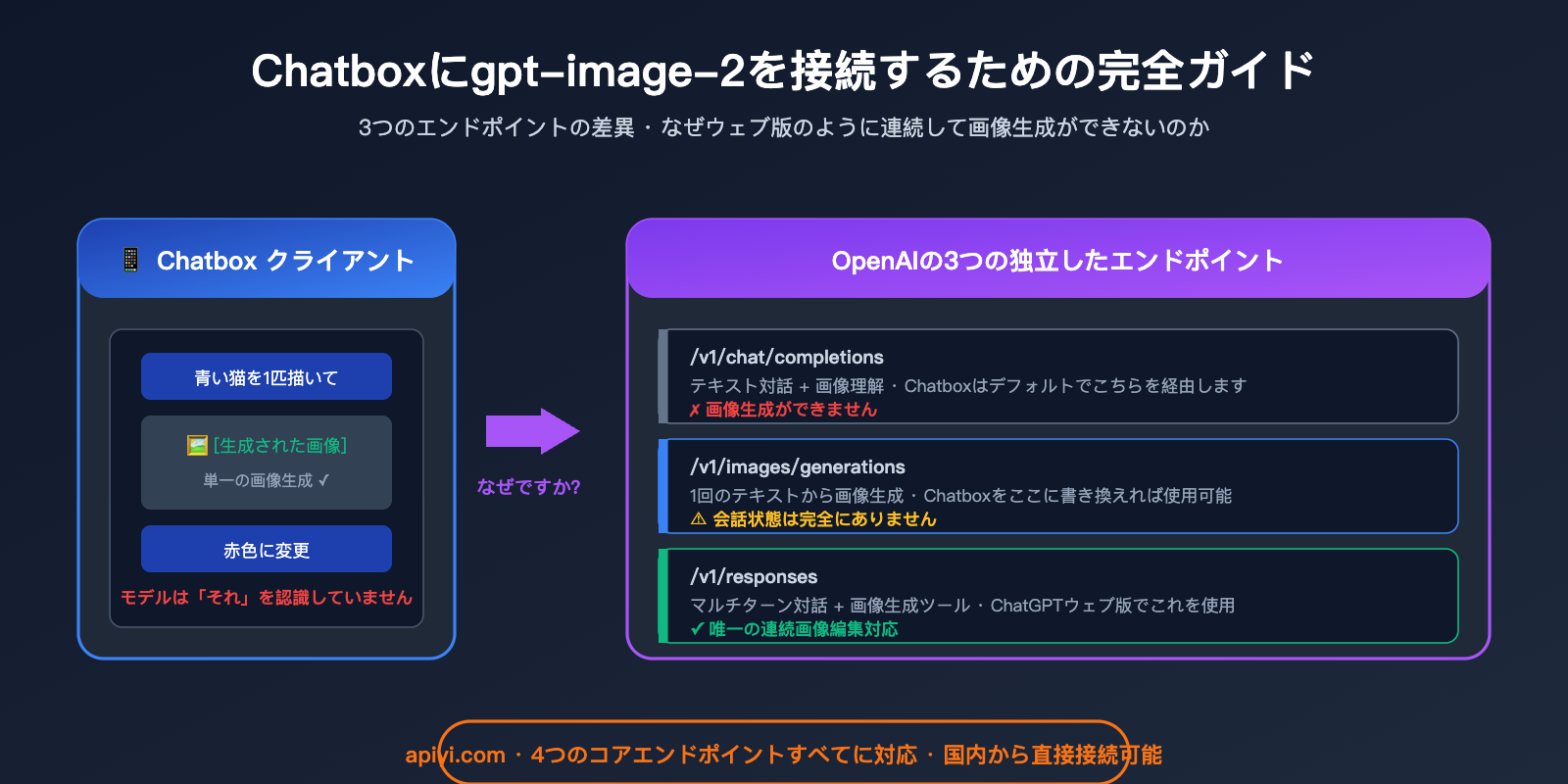
Chatbox で gpt-image-2 を使用した際に画像を連続で修正できない理由
これは本記事の最も重要な技術的ポイントです。多くのユーザーが設定を終えた後にこう尋ねます。「Chatbox で画像を生成して、『空を青くして』と指示しても、モデルが全く理解してくれないのはなぜ?ChatGPT のウェブ版なら無限に連続修正できるのに!」
その答えは Chatbox のバグではなく、エンドポイント自体が対応していないからです。
Chatbox に gpt-image-2 を接続する際のエンドポイントのアーキテクチャ制限
この問題を明確に理解するために、OpenAI が現在提供している3つの完全に独立したエンドポイントについて知る必要があります。
| エンドポイント | パス | 設計目的 | 画像生成のサポート | 会話状態の保持 |
|---|---|---|---|---|
| Chat Completions | /v1/chat/completions |
テキスト対話補完 | ❌ 画像入力のみ | ❌ クライアント管理 |
| Image Generations | /v1/images/generations |
単発の画像生成 | ✅ 生成のみ | ❌ ステートレス |
| Image Edits | /v1/images/edits |
単発の画像編集 | ✅ 編集のみ | ❌ ステートレス |
| Responses API | /v1/responses |
マルチターン対話+ツール呼び出し | ✅ ツール呼び出し | ✅ サーバー管理 |
重要な事実:
- Chatbox はデフォルトで
/v1/chat/completionsを使用しますが、このエンドポイントは画像生成をサポートしていません。 /v1/images/generationsに書き換えると画像生成は可能になりますが、このエンドポイントは**完全にステートレス(状態を持たない)**であり、リクエストのたびに独立して処理されます。- ChatGPT のウェブ版は裏で
/v1/responsesを使用しており、image_generationツール呼び出しとサーバー側の会話状態管理が組み込まれています。

なぜ ChatGPT ウェブ版では画像を連続修正できるのか
ChatGPT ウェブ版の背後にあるワークフローは以下の通りです:
- 「青い猫を描いて」と入力。
- ChatGPT が
/v1/responsesエンドポイントを呼び出し、モデルがimage_generationツールの使用を決定。 - ツールが画像 ID(例:
ig_abc123)を返し、同時に現在のセッションのサーバー側状態に記録。 - 続けて「それを赤くして」と入力。
- ChatGPT が再度
/v1/responsesを呼び出し、previous_response_idを渡す。 - モデルがコンテキストに基づいて「それ」が直前の画像を指していると認識し、
image_generationツールのeditアクションを呼び出す。 - ツールが直前の画像に基づいて編集を行い、新しい画像を返す。
このプロセス全体における鍵は、previous_response_id + サーバー側の会話状態 + 組み込みの image_generation ツールです。これら3つの能力は、/v1/images/generations エンドポイントには一切備わっていません。
Chatbox の現在のアーキテクチャの限界
Chatbox は Chat Completions スタイルのクライアントであり、そのコアデータモデルは「messages 配列」(system / user / assistant のマルチターンメッセージ)です。その動作メカニズムは以下の通りです:
- ユーザーの各メッセージを messages 配列に追加する。
- チャットスタイルのエンドポイント(デフォルトは
/v1/chat/completions)を呼び出す。 - レスポンスを messages 配列に追加する。
- これを繰り返す。
エンドポイントを /v1/images/generations に書き換えた場合、Chatbox はリクエストパスを切り替えただけの状態になります。しかし、messages 配列は依然としてチャット形式で送信され、エンドポイント側も単発のプロンプトしか受け付けないため、会話状態を全く引き継ぐことができません。
💡 技術的アドバイス:Chatbox のコア設計は「エンドポイントがチャットスタイルであること」を前提としていますが、OpenAI は画像生成と編集を独立した RESTful リソースエンドポイントとして設計しており、これがアーキテクチャレベルでの不一致を生んでいます。まずは APIYI (apiyi.com) プラットフォームを通じて
/v1/images/generationsでの単発画像生成をテストし、動作を確認してから Responses API への切り替えを検討することをお勧めします。
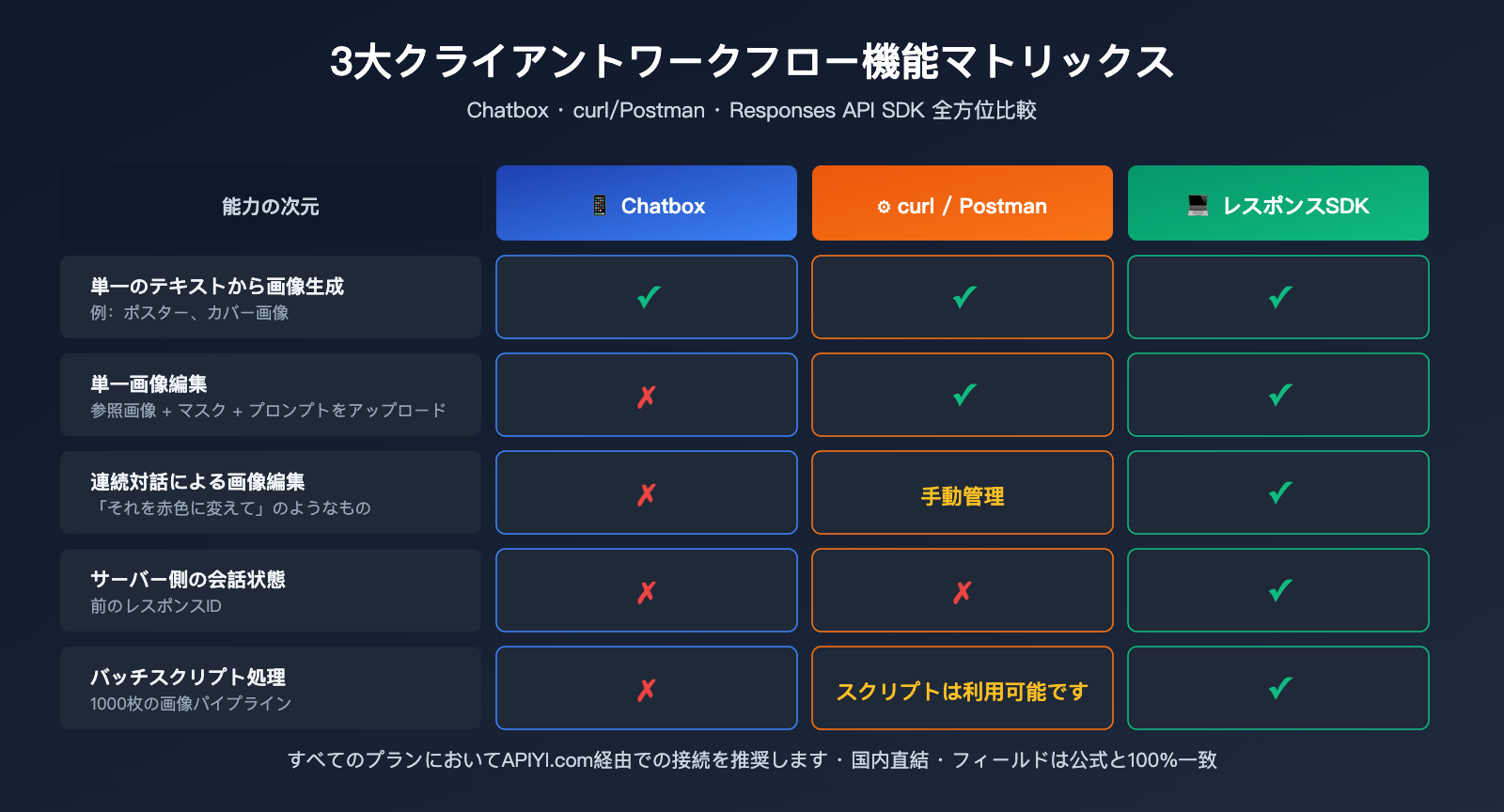
Chatbox への gpt-image-2 接続:機能の境界線と代替案
制限事項を把握した上で、「できること」と「できないこと」を明確にしたリストを作成しました。
Chatbox + gpt-image-2 でできること
| シナリオ | 対応状況 | 説明 |
|---|---|---|
| プロンプト1つで画像を1枚生成 | ✅ | 標準的な使い方 |
| 日本語・英語プロンプト | ✅ | gpt-image-2 がネイティブ対応 |
| サイズ/比率の指定 | ✅ | size パラメータで指定 |
| 画質の指定(standard/high) | ✅ | quality パラメータで指定 |
| URL または base64 出力 | ✅ | response_format パラメータで指定 |
Chatbox + gpt-image-2 でできないこと
| シナリオ | 対応状況 | 代替案 |
|---|---|---|
| 生成後に「赤色に変更して」と指示 | ❌ | Responses API へ切り替え |
| 多段階の反復による細部の調整 | ❌ | Responses API へ切り替え |
| 画像アップロード + プロンプトで部分編集 | ❌ Chatbox 非対応 | /v1/images/edits または Responses API へ切り替え |
| 複数の参照画像を融合して生成 | ❌ Chatbox 非対応 | Responses API へ切り替え |
| サーバー側での会話履歴の記録 | ❌ | Responses API へ切り替え |
Responses API を使用した連続画像生成の最小コード
「対話形式での画像修正」が必要な場合は、Chatbox クライアントの使用を諦め、/v1/responses エンドポイントを呼び出すコードを自分で記述する必要があります。
from openai import OpenAI
client = OpenAI(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com/v1",
timeout=600.0
)
# 第1ラウンド:初期画像を生成
resp1 = client.responses.create(
model="gpt-5", # Responses API は gpt-5 シリーズが必要です
input="月明かりの下を散歩する青い猫、写実的なスタイルで描いて",
tools=[{"type": "image_generation"}]
)
response_id_1 = resp1.id
print("1枚目の画像:", resp1.output[-1])
# 第2ラウンド:前回の結果に基づいて修正(previous_response_id が重要)
resp2 = client.responses.create(
model="gpt-5",
previous_response_id=response_id_1, # 会話状態を連結
input="色をオレンジに変更して、背景を日の出に変えて",
tools=[{"type": "image_generation"}]
)
print("修正後:", resp2.output[-1])
いくつかの重要なポイント:
gpt-5以上のモデルを使用する必要があります(gpt-image-2 は直接対話モデルとして呼び出せません)。tools=[{"type": "image_generation"}]を渡してツールを有効にする必要があります。previous_response_idを使用して会話履歴を連結する必要があります。そうしないと、モデルは「それ」が何を指しているのか理解できません。
🚀 接続のアドバイス:Responses API で連続画像生成を行う際は、
base_urlをhttps://api.apiyi.com/v1に設定してください。OpenAI 公式のフィールドと完全に一致しているため、既存の OpenAI SDK コードのbase_urlを1行書き換えるだけで切り替え可能です。国内から安定して接続できる APIYI (apiyi.com) を通じた接続を推奨します。
Chatbox で gpt-image-2 を利用するための実践設定ガイド
理論的な説明はここまでにして、実際に「ゼロから」設定を行うための完全ガイドをお届けします。
ステップ 1:APIYI プラットフォームで APIキーを取得する
- APIYI コントロールパネル
api.apiyi.comにアクセスします。 - アカウント登録後、「API トークン」ページに移動します。
- 新しいトークンを作成します(プロジェクトごとに個別のトークンを作成することをお勧めします)。
- 発行された Bearer トークン(
sk-で始まるもの)をコピーします。
ステップ 2:Chatbox でカスタムプロバイダーを設定する
Chatbox で以下の操作を行います。
- 「設定」→「モデルプロバイダー」を開きます。
- 「追加」をクリックし、「カスタム OpenAI 互換プロバイダー」を選択します。
- 以下のフィールドを入力します。
名称: APIYI - 画像生成
API Host: https://api.apiyi.com
API Path: /v1/images/generations # 重要!必ず書き換えてください
API Key: sk-your-apiyi-key
デフォルトモデル: gpt-image-2
- 高度な設定:
- リクエストタイムアウト: 600 秒
- リトライ回数: 2
- 文字コード: UTF-8
ステップ 3:テスト用プロンプトを送信する
Chatbox のチャット欄に以下を入力してみてください。
横長 16:9 映画風の構図、夕暮れ時の海辺にある古い灯台、
柔らかな暖色系のトーン、海面には薄い霧、2K 解像度
設定が正しければ、1〜3 分以内に画像が返信されます。
ステップ 4:よくあるトラブルシューティング
| 問題 | 確認項目 |
|---|---|
| 何も返ってこない | APIキーが完全か、画像生成の権限があるか確認してください |
| エラーコード 401 | APIキーが間違っているか期限切れです。再取得してください |
| エラーコード 404 | APIパスの綴りミスです。/v1/images/generations を確認してください |
| エラーコード 429 | レート制限に達しました。数分待ってから再試行してください |
| タイムアウトが発生 | タイムアウト設定が短すぎます。600秒に調整してください |
💡 上級者向けアドバイス:gpt-image-2 をデスクトップクライアントではなく独自のアプリケーションに統合したい場合は、OpenAI 公式 SDK を使用して
/v1/images/generationsを直接呼び出すことをお勧めします。Chatbox よりもはるかに柔軟です。APIYI (apiyi.com) を経由し、base_urlをhttps://api.apiyi.com/v1に置き換えるだけで利用可能です。
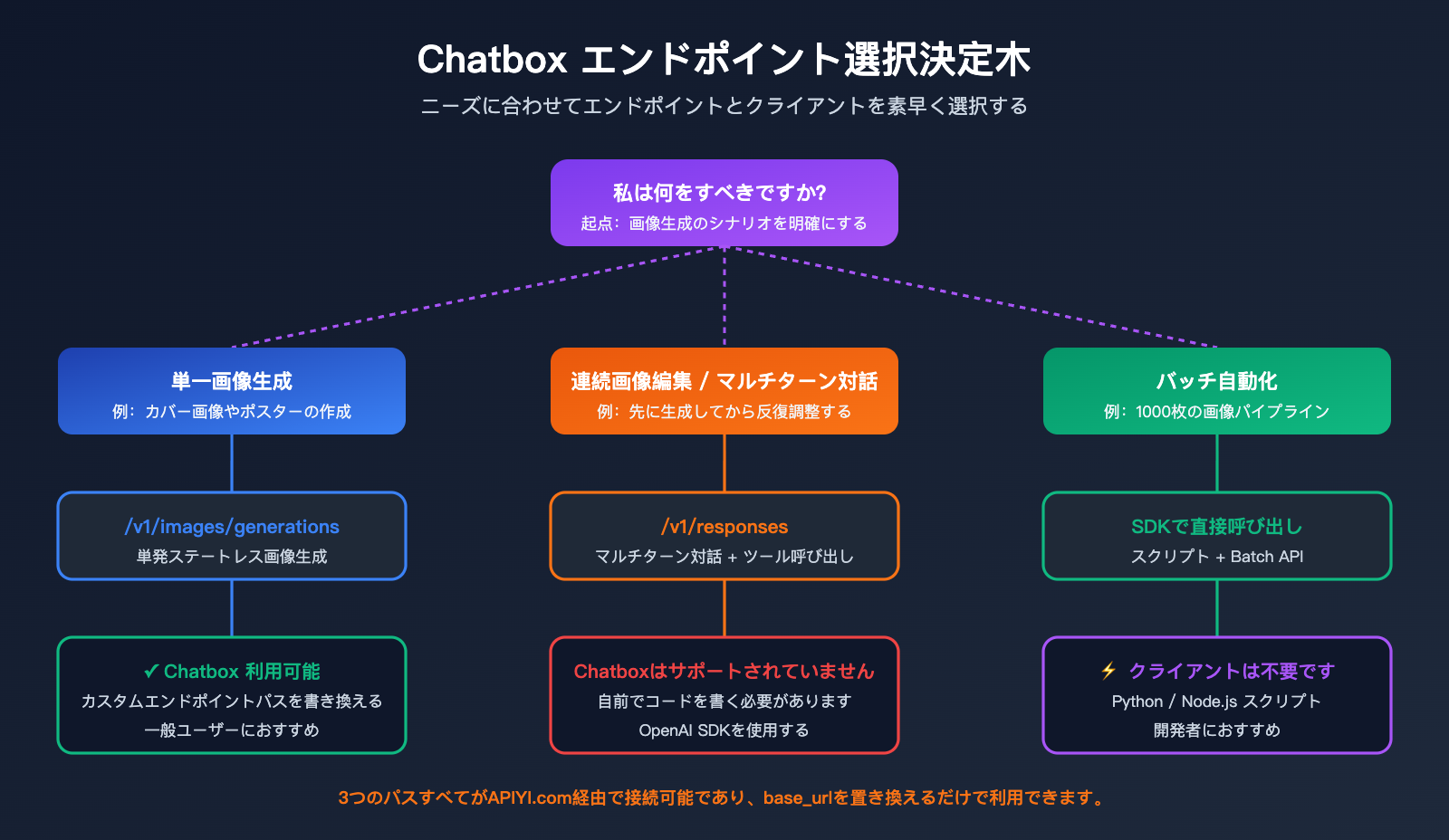
3 つの主要エンドポイント選定ガイド
以下の決定表を参考に、どのシナリオでどのエンドポイントを使うべきか判断してください。
| ニーズ | 推奨エンドポイント | 適したクライアント |
|---|---|---|
| 単発の画像生成(カバー画像など) | /v1/images/generations |
Chatbox / curl / SDK |
| 単発の画像編集(マスク使用) | /v1/images/edits |
curl / SDK(Chatbox は非対応) |
| 連続対話による画像修正 | /v1/responses |
自作コード(Chatbox は非対応) |
| テキストのみの対話 | /v1/chat/completions |
Chatbox / 各種チャットクライアント |
| テキスト対話 + 画像理解(画像認識) | /v1/chat/completions |
Chatbox 対応 |
Chatbox 接続 gpt-image-2 に関するFAQ
質問 1:なぜ Chatbox 公式は gpt-image-2 の連続画像生成を直接サポートしていないのですか?
これは Chatbox の設計上の欠陥ではなく、クライアント全般における技術的な制約です。Chatbox のデータモデルは messages 配列(チャット形式)をベースにしていますが、Responses API のデータモデルは previous_response_id + サーバー側の対話状態という形式であり、これら2つは根本的に互換性のないパラダイムだからです。Chatbox でこの機能をサポートするには、対話エンジン全体を書き直す必要があります。
質問 2:Chatbox でカスタムエンドポイントを設定すれば、画像をアップロードして gpt-image-2 で編集できますか?
理論上は可能ですが、実際には非常に困難です。/v1/images/edits エンドポイントは multipart/form-data 形式での画像アップロードを要求しますが、Chatbox のチャット画面はテキスト入力しかサポートしていません。無理に設定すると 415 エラーが発生します。推奨される代替案:curl や Postman、あるいは自作スクリプトを使用して /v1/images/edits を呼び出すことをお勧めします。
質問 3:APIYI の中継サービスは Responses API をサポートしていますか?
完全対応しています。APIYI は公式転送チャネルであり、リクエストおよびレスポンスフィールドは OpenAI 公式と 100% 同期しています。/v1/responses、/v1/images/generations、/v1/images/edits、/v1/chat/completions という4つのコアエンドポイントすべてに対応済みです。国内から直接接続でき、プロキシ不要で安定している APIYI (apiyi.com) を通じて Responses API を呼び出し、連続画像生成を実現することを推奨します。
質問 4:Chatbox で gpt-image-2 を呼び出す際、プロンプトは最大でどれくらいの長さまで可能ですか?
OpenAI 公式ではプロンプトの最大長を 32,000 文字と制限していますが、実際には 1,000 文字以内に収めることを推奨します。長すぎるプロンプトはモデルの集中力を分散させ、逆に生成品質を低下させる原因となります。
質問 5:Chatbox でチャットモデルと画像生成モデルを同時に設定できますか?
可能です。Chatbox は複数の「カスタムプロバイダー」を設定できるため、以下のように2つ作成することをお勧めします。
APIYI - 対話→ エンドポイント/v1/chat/completions→ モデルgpt-5/claude-sonnet-4-6などAPIYI - 画像生成→ エンドポイント/v1/images/generations→ モデルgpt-image-2
プロバイダーを切り替えるだけで、両方のモードを自由に行き来できます。
質問 6:Chatbox で gpt-image-2 の呼び出しに失敗した場合、Chatbox と API のどちらに問題があるか確認する方法は?
最も手っ取り早い方法は、まず curl で直接 API を叩いてみることです。もし curl で成功するなら Chatbox の設定ミス、curl でも失敗するなら APIキー またはネットワークの問題です。記事冒頭の curl 例をそのままコピーして試してみてください。
質問 7:APIYI 経由での利用と OpenAI 公式の利用に違いはありますか?
フィールドは完全に同一で、APIYI は公式転送チャネルです。主な違いは、国内からの直接接続でプロキシが不要な点、日本語による専門的なテクニカルサポートがある点、そして課金が透明で確認しやすい点です。ネットワークの安定性を確保するため、国内の開発者には APIYI (apiyi.com) を通じた gpt-image-2 への接続をお勧めします。
質問 8:Chatbox を諦めて、Responses API を使って自作コードを書くべきなのはどのような時ですか?
以下の3つの明確なサインがあれば移行の時期です。
- 「対話型画像編集」が必要な場合(一度生成した後、何度も微調整したい時)
- 画像とテキストの混合出力が必要な場合(解説をしてから画像を生成し、その後にまた解説をするようなフロー)
- 個人の利用ではなくプロダクトとして開発しており、サーバー側で対話状態を管理する必要がある場合
いずれかの条件に当てはまる場合は、Responses API への移行を検討してください。
Chatbox での gpt-image-2 活用:重要ポイント
- Chatbox はデフォルトで
/v1/chat/completionsを使用します。このエンドポイントは画像生成をサポートしていないため、/v1/images/generationsへ書き換える必要があります。 /v1/images/generationsはステートレスなエンドポイントです。各リクエストは独立しており、「連続修正」を行うことはできません。- ChatGPT Web版の連続画像生成機能は Responses API によるものです。組み込みの
image_generationツール +previous_response_idによる対話状態管理が使用されています。 - Chatbox で連続画像生成ができないのはバグではありません。チャット形式クライアントと Responses API の根本的なパラダイムの違いによるものです。
- 代替案:連続画像生成が必要な場合は、OpenAI SDK を使用して自作コードから
/v1/responsesを呼び出してください(gpt-5 シリーズのモデルが必須です)。 - 国内からの接続推奨:APIYI (apiyi.com) を経由して接続してください。4つのコアエンドポイントすべてに対応しており、
base_urlを書き換えるだけで利用可能です。 - 迅速なトラブルシューティング:設定がうまくいかない場合は、まず curl で検証してください。curl で実行できれば、問題は API ではなくクライアント側にあります。
まとめ
Chatbox で gpt-image-2 を利用する際の「設定」に関する問題はあくまで表面的なものに過ぎません。開発者が真に理解すべきは、OpenAI が提供する3つの独立したエンドポイントアーキテクチャです。これらはそれぞれ異なるユースケース向けに設計されており、能力の境界線が明確に分かれています。
- Chat Completions: 「テキスト対話 + 画像理解」のためのエンドポイントであり、画像生成はできません。
- Images Generations / Edits: 「単発の画像生成/編集」のためのステートレスなエンドポイントです。シンプルで直接的ですが、対話を通じた反復的な編集には対応していません。
- Responses API: 「マルチターン対話 + ツール呼び出し」のためのエンドポイントであり、「対話形式での画像編集」を実現できる唯一の手段です。
Chatbox はチャット形式のクライアントであるため、前述の2つのモードのいずれか一方にしか完璧には適合しません。カスタムエンドポイントの設定を書き換えることで単発の画像生成をサポートすることは可能ですが、ChatGPT の Web 版のような「無限の対話型編集」を実現するには、既存のクライアントツールを離れ、自らコードを書いて Responses API を呼び出す必要があります。
この点を理解すれば、ワークフローの選択肢が明確になります。
- 小規模、単発の画像生成、個人利用 → Chatbox +
/v1/images/generations - 継続的な画像編集が必要、製品レベルの統合 → Responses API + 自作コード
- バッチ処理、自動化パイプライン → SDK を使用して直接
/v1/images/generationsを呼び出し
✨ 最後のアドバイス: 国内の開発者の方には、どのルートを選択する場合でも、APIYI (apiyi.com) プラットフォーム経由での接続をおすすめします。4つの主要エンドポイントをすべてサポートしており、OpenAI 公式のフィールド仕様と100%互換性があるため、国内から直接接続しても安定しており、トークン単位の透明な課金体系となっています。新規ユーザーには無料のテスト枠も用意されているため、Chatbox の設定と Responses API の両方の検証を十分に行うことができます。
著者: APIYI Team
最終更新日: 2026年5月2日