2026年4月24日、DeepSeekは V4-Pro と V4-Flash を同時にオープンソース化しました。Flashが「安くて十分使える」というコストパフォーマンス重視のモデルであるのに対し、V4-Pro は全く別次元の製品です。
それは、現在最強のコーディング能力を誇るオープンソースモデルです。
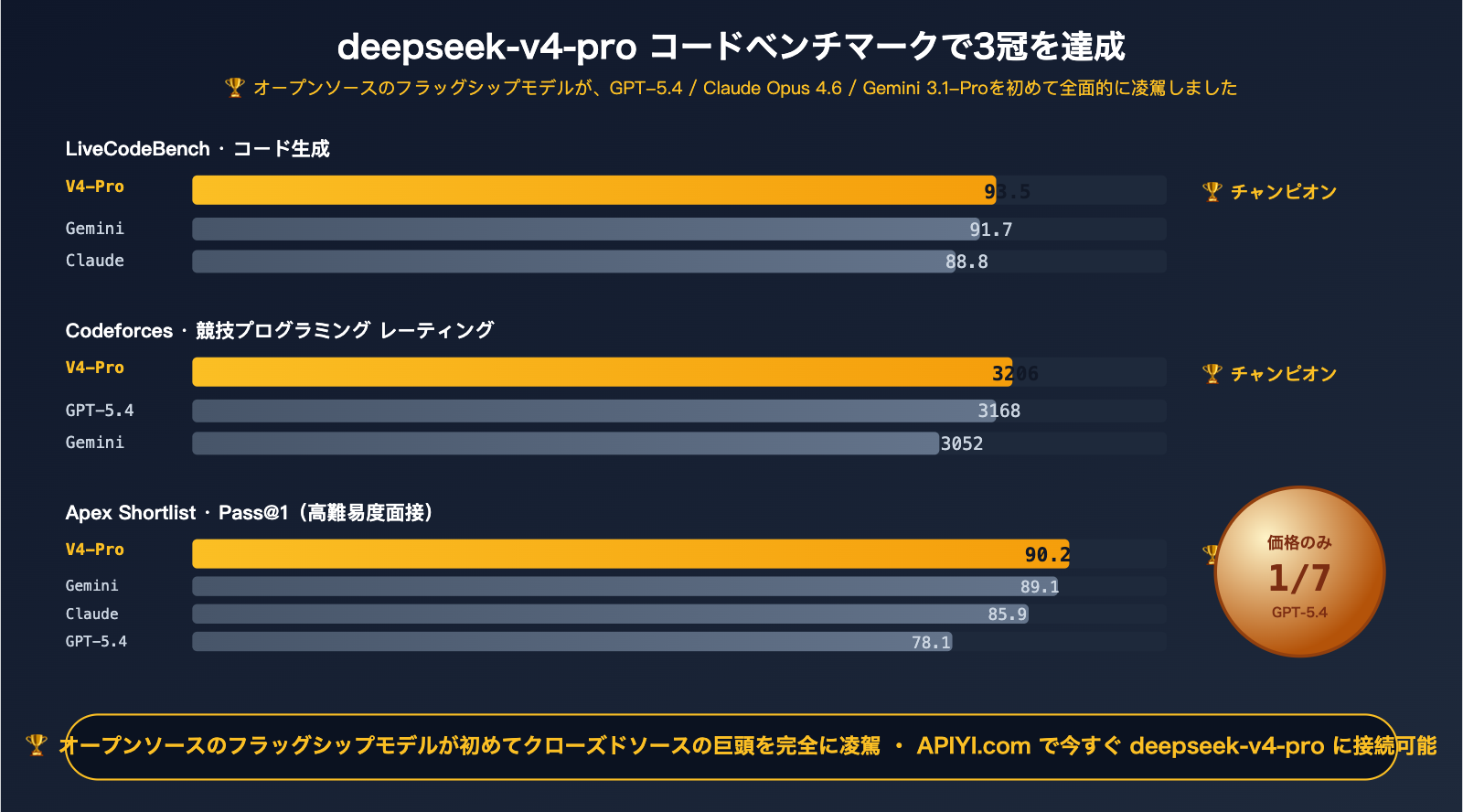
単に「オープンソースの中で最強」という控えめな表現ではなく、GPT-5.4 / Claude Opus 4.6 / Gemini 3.1-Pro を直接凌駕する圧倒的な数値を叩き出したチャンピオンです。
- LiveCodeBench 93.5 — 全体1位。Gemini 3.1-Pro(91.7)や Claude Opus 4.6(88.8)を上回る
- Codeforces Rating 3206 — GPT-5.4(3168)や Gemini 3.1-Pro(3052)を上回る
- Apex Shortlist Pass@1 90.2 — GPT-5.4(78.1)や Claude(85.9)を大きくリード
- IMOAnswerBench 89.8 — 数学オリンピックレベルの難問で Claude Opus 4.6(75.3)に14ポイントもの大差をつける
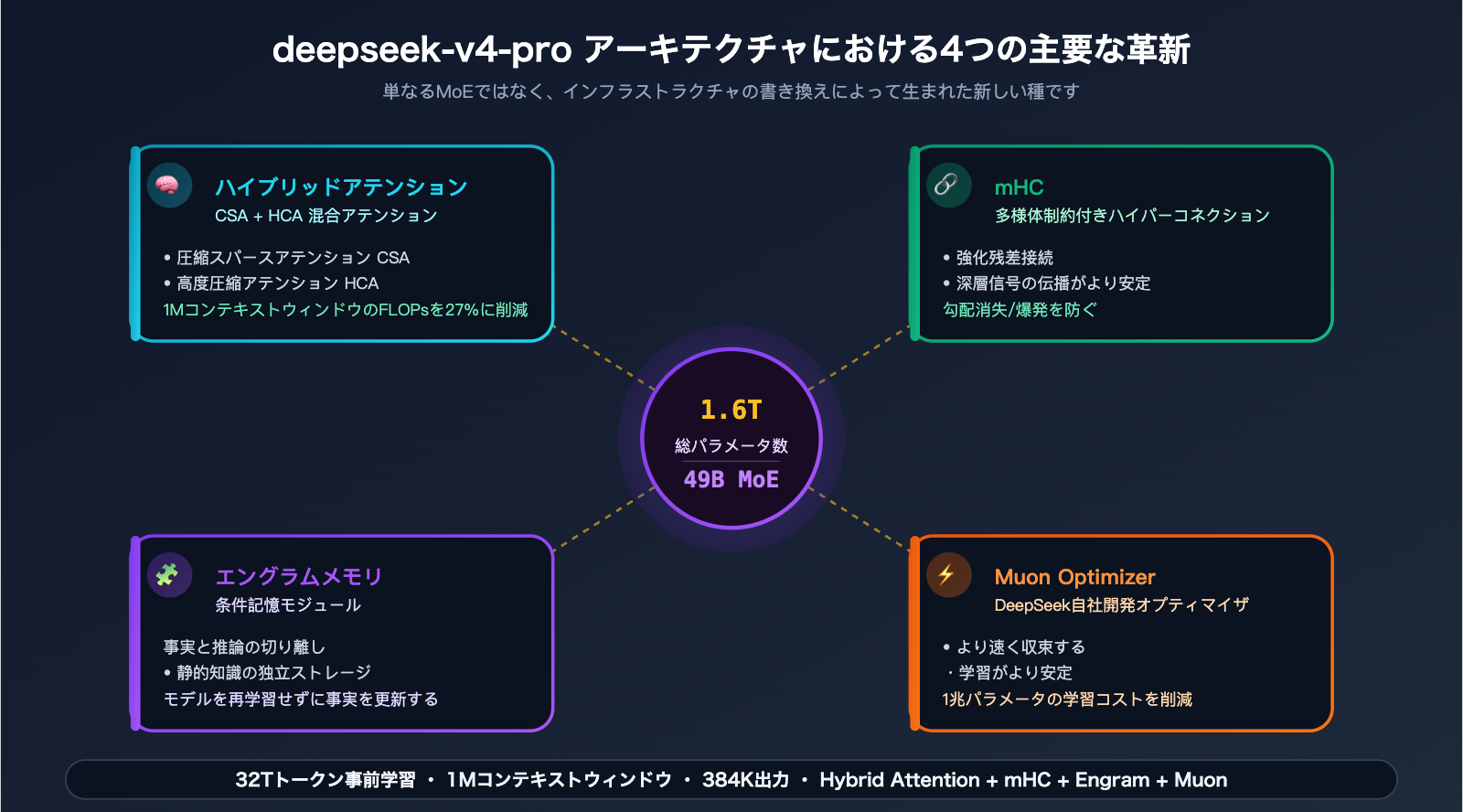
スペックは、総パラメータ数1.6T / アクティブパラメータ49B / 事前学習データ32Tトークン / コンテキストウィンドウ1M / 出力トークン384K。さらに、DeepSeekがV4シリーズのために設計した4つのアーキテクチャ革新(Hybrid Attention、Manifold-Constrained Hyper-Connections (mHC)、Engram Conditional Memory、Muon Optimizer)が搭載されています。
deepseek-v4-pro は APIYI (apiyi.com) で利用可能になりました。OpenAIやAnthropicのプロトコルSDKを使用して、コードを一切変更せずに接続でき、価格はGPT-5.4のわずか7分の1です。
本記事では、「移行方法」や「安価なモデルの選び方」といったFlash編で解説済みの基礎知識は省略します。今回は、deepseek-v4-proという技術の信奉者のために捧げる、フラッグシップモデルの徹底解説です。
- 3分でわかる:Proが「フラッグシップ」と呼ぶにふさわしい理由(アーキテクチャ + データ + スケール)
- 4つのベンチマーク対決表:Proがどの戦場で勝ち、どこで苦戦しているかを可視化
- 5分で接続 + 2つのリアルなコード/数学シナリオでの実戦

一、deepseek-v4-pro の4つのフラッグシップ能力
1.1 コアスペック一覧表
| 項目 | deepseek-v4-pro |
|---|---|
| リリース日 | 2026-04-24(プレビュー版) |
| オープンソースリポジトリ | huggingface.co/deepseek-ai/DeepSeek-V4-Pro |
| 総パラメータ数 | 1.6T(Mixture of Experts) |
| アクティブパラメータ数 | 49B |
| 事前学習データ | > 32T tokens |
| コンテキストウィンドウ | 1M tokens |
| 最大出力 | 384K tokens |
| アーキテクチャの革新 | Hybrid Attention + mHC + Engram Memory + Muon |
| 推論モード | Thinking / Non-Thinking デュアルモード |
| Function Calling | ✅ 対応 |
| JSON モード | ✅ 対応 |
| API プロトコル | OpenAI + Anthropic 両対応 |
| 入力コスト | $1.74 / M tokens |
| 出力コスト | $3.48 / M tokens |
最も重要な4つの数字を覚えておいてください:1.6T / 49B / 32T / 1M。これがフラッグシップモデルの底力です。
1.2 1.6T / 49B MoE:規模における「オープンソースの天井」
DeepSeek-V4-Pro は総パラメータ数 1.6兆 を誇り、Mixture of Experts(MoE)アーキテクチャを採用しています。1トークンあたりのアクティブパラメータ数はわずか 49B です。この数字が意味することは以下の通りです:
| モデル | 総パラメータ数 | アクティブパラメータ数 | タイプ |
|---|---|---|---|
| Llama 3 70B | 70B | 70B | Dense(全アクティブ) |
| Mistral Large 2 | 123B | 123B | Dense |
| DeepSeek-V3.2 | 671B | 37B | MoE |
| DeepSeek-V4-Pro | 1.6T | 49B | MoE ⭐ |
| Claude Opus 4.6 | 非公開 | 非公開 | クローズド |
1.6Tの総パラメータ数により、GPT-5.4 / Claude Opus クラスの広範な知識を持ちつつ、49Bのアクティブパラメータ数によってトークンあたりの推論コストを制御しています。これが、MoEアーキテクチャが最先端の性能を発揮できる本質的な理由です。
1.3 32T tokens の事前学習:データ量を最大化
事前学習データ > 32T tokens
これは驚異的な数字です:
- GPT-4 事前学習データ量:約 13T tokens(業界推測)
- Llama 3:15T tokens
- DeepSeek-V3:14.8T tokens
- DeepSeek-V4-Pro:>32T tokens ⭐
データ量が倍増したことによる直接的なメリットは、ロングテール知識の網羅性向上、コードコーパスの鮮度、数学問題の解法深度です。これが、V4-Pro が LiveCodeBench や IMOAnswerBench でトップを独走している根拠です。
1.4 4つのアーキテクチャ革新:Pro の真の強み
これこそが、V4-Pro が「単なる MoE モデル」と一線を画す鍵です。公式が公開した4つの核心的な革新:
| 革新 | 正式名称 | 解決する課題 |
|---|---|---|
| Hybrid Attention | CSA + HCA 混合アテンション | 長いコンテキスト(1M)推論時のFLOPsとメモリ問題 |
| mHC | Manifold-Constrained Hyper-Connections | 深層残差接続の安定性、勾配消失/爆発の防止 |
| Engram | Engram Conditional Memory | 「静的事実」と「推論能力」の分離、事実更新の低コスト化 |
| Muon | Muon Optimizer | 学習の収束速度と安定性、学習コストの削減 |
それぞれ詳しく解説します:
-
Hybrid Attention(CSA + HCA):従来の Transformer のアテンション計算量は O(n²) であり、1M コンテキストでは破綻します。V4 は**圧縮スパースアテンション(CSA)**で粗いフィルタリングを行い、**高度圧縮アテンション(HCA)**で細部をフォーカスします。これにより、FLOPs を V3.2 の 27% に、KV キャッシュを 10% に削減しました。これが 1M コンテキストを「実用レベルで動かせる」鍵です。
-
mHC(Manifold-Constrained Hyper-Connections):深層 MoE モデルの学習時、数十層を超えると残差接続の信号が歪みます。mHC は多様体(manifold)空間に制約を加え、信号伝達を安定させます。つまり、モデルを崩壊させることなく、より深く、長く学習させることが可能になりました。
-
Engram Conditional Memory:非常にエンジニアリング的な革新です。「モデルが記憶する事実」と「推論能力」を分離し、事実は専用のメモリユニットに、推論チェーンは別の経路を通るようにしました。結果として、世界知識を更新する際にモデル全体を再学習する必要がなくなり、将来的な Pro バージョンのリリースコストが大幅に下がります。
-
Muon Optimizer:DeepSeek 自社開発の最適化手法です。AdamW と比較して収束が速く、安定性が向上しています。兆単位のパラメータ学習において、同じ計算リソースでより深く学習できることを意味します。
🎯 技術的示唆:deepseek-v4-pro は古いアーキテクチャを拡大したものではなく、インフラを根本から書き直したものです。これが、オープンソースでありながら閉源の巨人たちと同等のレベルに達した根本的な理由です。APIYI (apiyi.com) を通じて、業務でよく使うプロンプトを試し、アーキテクチャの進化による違い(特に長文コンテキストや多段階推論)を体感してみてください。
1.5 1M コンテキスト + 384K 出力:長文生成の転換点
Pro と Flash はコンテキストスペックが同じ(1M 入力、384K 出力)ですが、Pro の強みは「どれだけ読めるか」ではなく「1M の文脈でどれだけ深く考えられるか」にあります。
長文シナリオにおける実用的な意義:
| タスク | V3.2 時代 | V4-Pro 時代 |
|---|---|---|
| 50万字の原稿全文修正 | 10以上に分割して結合 | 1M ウィンドウで一括処理 |
| 200ページの技術文書問答 | RAG の構築が必要 | 直接入力可能 |
| 中規模コードリポジトリ監査 | 要約的な分析 | ファイルを跨いだ整合性チェック |
| 小説執筆の整合性 | 記憶を自分で管理 | 384K 出力で一気に完結 |
二、deepseek-v4-pro のベンチマーク王座
2.1 コーディング能力:deepseek-v4-pro が3部門でトップ
まずは最も客観的なデータ、プログラミング能力を見てみましょう:
| ベンチマーク | V4-Pro | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1-Pro | 1位 |
|---|---|---|---|---|---|
| LiveCodeBench | 93.5 | — | 88.8 | 91.7 | V4-Pro 🏆 |
| Codeforces Rating | 3206 | 3168 | — | 3052 | V4-Pro 🏆 |
| Apex Shortlist Pass@1 | 90.2 | 78.1 | 85.9 | 89.1 | V4-Pro 🏆 |
| SWE-bench Verified | 80.6–82.1 | — | 80.8 | 80.6 | 同率 |
| Terminal-Bench 2.0 | 67.9 | 75.1 | 65.4 | 68.5 | GPT-5.4 |
3部門で首位、2部門で「同率1位または僅差」です。オープンソースモデルがコーディング能力で閉源のフラッグシップモデルを全面的に圧倒したのは、2026年における象徴的な出来事です。
詳細な解説:
- LiveCodeBench 93.5:毎月問題が更新されるため、学習データ汚染を防げます。V4-Pro の 93.5 というスコアは、そのコーディング能力が汎用的であり、未知の問題にも対応できることを証明しています。
- Codeforces 3206:競技プログラミングのレーティングで、3206 は IGM(国際特級マスター)レベルです。日常的な業務コードであれば、圧倒的な性能差を見せつけます。
- Apex Shortlist Pass@1 90.2 vs GPT-5.4 78.1:この差は決定的です。Apex Shortlist は高難易度の面接問題集であり、V4-Pro は 12ポイントもの大差をつけています。
- Terminal-Bench 2.0 での僅差:これは多段階のコマンドラインツール操作能力です。GPT-5.4 が依然としてリードしており、「複雑な多段階エージェント」シナリオでは GPT-5.4 に一日の長があることがわかります。
2.2 数学と推論:最前線に迫る deepseek-v4-pro
数学の領域では、Pro は閉源の巨人たちと「抜きつ抜かれつ」の状況であり、全面的にリードしているわけではありません:
| ベンチマーク | V4-Pro | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1-Pro |
|---|---|---|---|---|
| MMLU-Pro | 87.5 | 87.5 | 89.1 | 91.0 |
| IMOAnswerBench | 89.8 | 91.4 | 75.3 | 81.0 |
| HMMT 2026 | 95.2 | 97.7 | 96.2 | — |
| MATH | 92% | — | — | — |
| HumanEval | 90% | — | — | — |
| MMLU | 89% | — | — | — |
IMOAnswerBench での輝き:国際数学オリンピックの問題集において、V4-Pro は 89.8 点を獲得し、Claude Opus 4.6 を 14.5 点、Gemini 3.1-Pro を 8.8 点も引き離しています。数学的推論や形式証明といった高度なタスクにおいて、Pro は現在のオープンソースモデルの天井です。
MMLU-Pro(一般知識)での弱点:Pro の 87.5 は GPT-5.4 と同等ですが、Gemini 3.1-Pro の 91.0 には 3.5 点及んでいません。一般知識の問答シナリオでは、Gemini が依然として優位性を持っています。
2.3 戦場分布図:deepseek-v4-pro の勝ち筋と負け筋
| 戦場 | チャンピオン | V4-Pro の立ち位置 |
|---|---|---|
| コード生成(LiveCodeBench) | V4-Pro 🏆 | チャンピオン |
| 競技プログラミング(Codeforces) | V4-Pro 🏆 | チャンピオン |
| 高難易度面接(Apex) | V4-Pro 🏆 | チャンピオン(大幅リード) |
| ソフトウェアエンジニアリング(SWE-bench) | 同率 | 同率1位 |
| 数学オリンピック(IMO) | GPT-5.4 | 2位(Claude/Geminiを大きく引き離す) |
| 一般知識(MMLU-Pro) | Gemini 3.1-Pro | 3位 |
| 多段階ツールチェーン(Terminal-Bench) | GPT-5.4 | 2位 |
| 整合性推論(HMMT) | GPT-5.4 | 3位 |
結論:もしあなたのワークロードがコード中心であれば、deepseek-v4-pro は現在地球上で最強の選択肢の一つです(オープン・閉源含め)。もし多段階エージェントのツールチェーンがメインであれば GPT-5.4 に微かな優位性があり、一般知識の問答がメインであれば Gemini 3.1-Pro がより強力です。
🎯 選定のアドバイス:まずは APIYI (apiyi.com) にて、業務でよく使う典型的なプロンプトを 20〜50 個ほど用意し、V4-Pro と既存モデルの AB テストを行うことをお勧めします。公開されているベンチマークを鵜呑みにせず、あなた自身のプロンプト分布こそが真のベンチマークであることを忘れないでください。大量の AB テストを行う際は
vip.apiyi.comの高並列回線をご利用ください。
三、5 分钟在 APIYI apiyi.com 调用 deepseek-v4-pro
3.1 Step 1:APIキーの取得と接続先の選択
前提環境:Python 3.8+ または Node.js 18+。公式の OpenAI SDK または Anthropic SDK のいずれかを使用します。
APIキーの取得:
- APIYI
apiyi.comにアクセスし、コンソール → API Keys → 新規キー作成 - Pro 用のキーには、日次制限(業務規模に応じて ¥200–500 など)を設定することを推奨します。
sk-で始まるキーをコピーします。
接続先の選択(3つの接続先で共通のキーを使用可能):
| base_url | 用途 |
|---|---|
https://api.apiyi.com/v1 |
通常の呼び出し、対話型シナリオ |
https://vip.apiyi.com/v1 |
バッチ処理、高並列処理 |
https://b.apiyi.com/v1 |
メインサーバーの不安定時のバックアップ |
3.2 Step 2:Python による最小構成の呼び出し(Non-Thinking)
from openai import OpenAI
client = OpenAI(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com/v1",
)
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "system", "content": "あなたはシニアPythonエンジニアです。"},
{"role": "user", "content": "30行以内で本番環境レベルのLRUキャッシュを書いてください。"},
],
max_tokens=2048,
)
print(resp.choices[0].message.content)
base_url と model の2箇所を変更するだけです。その他の OpenAI SDK コードはそのままで動作します。
3.3 Step 3:Thinking 推論モードの有効化(Pro の真価)
deepseek-v4-pro の真価は Thinking モードで完全に発揮されます。IMOAnswerBench で 89.8、LiveCodeBench で 93.5 というスコアは、すべてこの Thinking モードで測定されたものです。
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "user", "content": """
並行処理で安全なトークンバケットレートリミッターを実装してください。要件:
1. 動的なレート調整をサポート
2. バーストトラフィックの予約をサポート
3. ロックフリー実装(CAS またはアトミック操作)
4. 完全なユニットテストを含む
"""},
],
extra_body={
"reasoning": {"enabled": True, "effort": "high"},
},
max_tokens=16384,
)
print("--- 推論プロセス ---")
print(resp.choices[0].message.reasoning_content)
print("\n--- 最終回答 ---")
print(resp.choices[0].message.content)
effort=high に設定すると、Pro は非常に深い計画を立てます。要件の分析、APIの設計、実装案の検討を経て、最後にコードを出力します。これこそが、Flash と比較して deepseek-v4-pro に追加料金を払う価値がある点です。
3.4 Step 4:コード修正の実践
実際の業務シナリオ:Pro にバグを修正させます。
buggy_code = """
def find_kth_largest(nums, k):
nums.sort()
return nums[k] # ここにバグ
"""
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "system", "content": "あなたはシニアコードレビュアーです。バグを特定し、根本原因を説明し、修正後のコードを提示してください。"},
{"role": "user", "content": f"このコードをレビューしてください:\n```python\n{buggy_code}\n```"},
],
extra_body={"reasoning": {"enabled": True}},
max_tokens=4096,
)
print(resp.choices[0].message.content)
Pro は「ソート後の第 k 位は後ろから k 番目であるため、インデックスは -k であるべき」と指摘し、修正コードと境界条件(k <= 0、k > len(nums))の処理、テストケースを提示します。
SWE-bench 80%+ というデータは、このようなシナリオでの実体験として実感できるはずです。
3.5 Step 5:Function Calling / Tool Use
Pro は単一のツール呼び出しにおいて非常に安定しています。多段階のツールチェーンでは GPT-5.4 に譲る場面もありますが、Claude を上回る性能を見せます。
tools = [
{
"type": "function",
"function": {
"name": "run_sql",
"description": "分析用DBに対して読み取り専用のSQLクエリを実行する。",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "SELECTのみのSQL"},
},
"required": ["query"],
},
},
},
]
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "user", "content": "過去30日間でDAUトップ5の都市は?"},
],
tools=tools,
tool_choice="auto",
)
print(resp.choices[0].message.tool_calls)
3.6 Step 6:Anthropic プロトコル(Claude Code で Pro を利用)
この経路は deepseek-v4-pro の価値が最も過小評価されている部分です。既存の Claude SDK や Claude Code プロジェクトの基盤モデルを、業務コードを一切変更せずに V4-Pro に置き換えることができます。
from anthropic import Anthropic
client = Anthropic(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com", # /v1 は不要
)
resp = client.messages.create(
model="deepseek-v4-pro",
max_tokens=4096,
messages=[
{"role": "user", "content": "このPythonコードをasync/awaitスタイルにリファクタリングして..."},
],
)
print(resp.content[0].text)
Claude Code ターミナル:設定で ANTHROPIC_BASE_URL=https://api.apiyi.com、ANTHROPIC_API_KEY=sk-... を指定し、モデルを deepseek-v4-pro に変更するだけで、強力なコーディング能力を持つターミナル Agent が即座に利用可能になります。
3.7 Step 7:Cursor への deepseek-v4-pro 導入
Cursor の Settings → Models → Custom OpenAI-Compatible にて:
- Base URL:
https://api.apiyi.com/v1 - API Key:
sk-... - Model Name:
deepseek-v4-pro
設定完了後、Cursor の Chat / Cmd+K / Composer のすべてで V4-Pro が利用され、コード補完やリファクタリングの品質が劇的に向上します。
🎯 IDE 導入のアドバイス:Cursor、Windsurf、Cline、Continue など、主要な AI プログラミングツールはすべて OpenAI プロトコルと互換性があります。
base_urlを APIYI のapi.apiyi.com/v1に向け、モデルをdeepseek-v4-proに変更するだけでシームレスに移行できます。詳細な IDE 設定例は、APIYI 公式ドキュメントdocs.apiyi.comの DeepSeek V4 セクションで確認してください。
四、deepseek-v4-pro を選ぶべき時、選ぶべきではない時
4.1 Pro を選ぶべき判断基準
✅ 以下のシナリオでは迷わず deepseek-v4-pro を選択してください:
| シナリオ | 理由 |
|---|---|
| コード生成、リファクタリング、レビュー | LiveCodeBench 93.5 で全場トップ |
| 競技プログラミング、アルゴリズム問題 | Codeforces 3206、IGM レベルの性能 |
| 面接問題のバッチ回答 | Apex Shortlist 90.2 で大幅リード |
| 数学推論、形式証明 | IMOAnswerBench 89.8、Claude を 14 ポイントリード |
| 大規模リポジトリの全体理解 | 1M コンテキスト + 49B アクティブパラメータ |
| 長文の執筆と編集 | 384K の出力を一発で生成 |
| ローカルデプロイ / 二次学習 | オープンソースの重み + Engram モジュールで微調整が容易 |
| Cursor / Claude Code の基盤モデル代替 | Anthropic プロトコルで改造不要 |
4.2 Pro を選ぶべきではない場合
❌ 以下のシナリオでは Pro の計算リソースを浪費しないでください:
| シナリオ | 推奨 |
|---|---|
| 日常的な会話、FAQ | Flash を使用(コストを 12 分の 1 に削減) |
| 短文の分類、抽出 | Flash またはより軽量なモデルを使用 |
| 多段階の複雑な Agent ツールチェーン | GPT-5.4 を優先(Terminal-Bench でリード) |
| 一般的な知識の問答がメイン | Gemini 3.1-Pro がより強力 |
| 遅延に敏感なオンライン対話 | Flash(Non-Thinking モード)またはキャッシュを利用 |
4.3 混合ルーティングの提案
本番環境での最適解は、通常階層型ルーティングです:
def pick_model(request_type: str, complexity: str) -> str:
# コード関連の重い作業 → Pro
if request_type in ("code_gen", "code_review", "refactor") and complexity == "hard":
return "deepseek-v4-pro"
# 数学推論 → Pro
if request_type in ("math_proof", "competitive_programming"):
return "deepseek-v4-pro"
# 長文ドキュメントの深い理解 → Pro
if request_type == "long_doc_analysis":
return "deepseek-v4-pro"
# その他日常的なタスク → Flash
return "deepseek-v4-flash"
APIYI apiyi.com では、これら2つのモデルは共通のキーを使用します。切り替えは model フィールドを変更するだけで、他の設定は不要です。
五、deepseek-v4-pro よくある質問(FAQ)
Q1:なぜ Pro のコーディング能力はこれほど高いのですか?
3つの要因が重なっているためです。
- 32T トークンの事前学習:高品質なコードコーパスを大量に含んでいます。
- 1.6T MoE / 49B アクティブパラメータ:コードに関する知識を保持し、必要に応じて引き出せる設計です。
- Thinking モード + Engram Memory:「コードのパターン記憶」と「新しいコードの推論」を切り離して処理しています。
これら3つの要素が組み合わさることで、LiveCodeBench で 93.5 というスコアを達成しました。
Q2:1.6T パラメータだと応答が遅くなりませんか?
単一の応答速度は総パラメータ数ではなく、アクティブパラメータ数によって決まります。Pro は 1 トークンあたり 49B しかアクティブ化せず、さらに Hybrid Attention による FLOPs 最適化が施されているため、最初のトークンの遅延は Flash と同等です。Thinking モードは(推論過程を出力するため)少し遅くなりますが、これは設計上のトレードオフであり、推論の質のために時間を投資しているとお考えください。
Q3:Thinking モードは必ずオンにする必要がありますか?
必須ではありません。通常の会話、単純なコード作成、日常的な質問であればオフでも問題ありません。しかし、Pro の料金の大部分は Thinking モードの価値にあるため、複雑なコード、数学の問題、多段階の論理推論を行う際は、必ず reasoning.enabled=true + effort=high を設定してください。
Q4:Cursor や Claude Code でどう使いますか?
- Cursor:Settings → Models → Custom OpenAI-Compatible を選択し、Base URL に
https://api.apiyi.com/v1、Model にdeepseek-v4-proを入力します。 - Claude Code:環境変数
ANTHROPIC_BASE_URL=https://api.apiyi.comとANTHROPIC_API_KEY=sk-...を設定し、起動時にモデルとしてdeepseek-v4-proを指定します。
具体的なスクリーンショット付きの手順は、docs.apiyi.com の IDE 接続セクションで確認できます。
Q5:GPT-5.4 と比べてどちらがお得ですか?
どちらかを選ぶなら:
- 日常的なコーディング / 競技プログラミング / 数学 / コスト重視 → deepseek-v4-pro(コード性能トップ、価格は 1/7)
- 多段階ツールチェーン Agent / 一般知識の質問 → GPT-5.4
- 併用 が最適解です(APIYI apiyi.com の同じ API キーで両方のモデルを切り替えて利用可能)
Q6:ローカル環境にデプロイできますか?
可能です。V4-Pro は Hugging Face にて完全な重みデータが公開されています(deepseek-ai/DeepSeek-V4-Pro)。ただし、自前でデプロイするには以下の環境が必要です。
- 単体マシンで ≥ 8×H200 または同等の GPU
- 1M コンテキストには追加の KV キャッシュが必要(Pro はキャッシュを V3.2 の 10% まで圧縮済みですが)
- 推論サービスを維持するためのエンジニアリングコスト
コスト試算:月間の呼び出し量が 500 億トークンを超えない限り、APIYI apiyi.com のホスティングサービスを利用する方が自前でデプロイするよりも経済的です。
Q7:同時実行数の上限はどれくらいですか?
本番環境での推奨設定は以下の通りです。
- メインサイト
api.apiyi.com:50 並列まで安全 - 高並列ライン
vip.apiyi.com:200+ 並列 - バックアップ
b.apiyi.com:メインラインの揺らぎ時に自動でフォールバック
Pro は複雑な Thinking タスクで遅延が発生しやすいため、並列数を増やせば良いというわけではありません。QPS × 平均応答時間 を計算して、必要な並列ウィンドウを見積もるのが適切です。
Q8:Pro の正式版はすぐに出ますか?
2026年4月24日にリリースされたのはプレビュー版です。DeepSeek の過去のリリースサイクルから見ると、正式版は通常プレビュー版の 1〜2 ヶ月後にリリースされ、ベンチマークスコアがわずかに向上する可能性があります。現在 APIYI apiyi.com でプレビュー版を利用しても問題ありません。モデル ID は正式版でも deepseek-v4-pro が維持され、後方互換性が保たれる可能性が高いです。
六、deepseek-v4-pro リリースまとめ
要点だけをまとめると以下の通りです。
- ✅ deepseek-v4-pro は現在、最強のコーディング能力を持つオープンモデルです。LiveCodeBench / Codeforces / Apex の3つのハードなベンチマークで GPT-5.4 / Claude Opus 4.6 / Gemini 3.1-Pro を上回りました。
- ✅ 4つのアーキテクチャ革新(Hybrid Attention / mHC / Engram Memory / Muon)により、単なる「また新しい大規模言語モデル」ではなく、インフラを書き換えた「新しい種」と言えます。
- ✅ 1.6T / 49B MoE + 32T トークンの事前学習 + 1M コンテキスト という規模で、オープンモデルの限界を突破しました。
- ✅ APIYI apiyi.com にて提供中。OpenAI と Anthropic の両プロトコルに対応しており、Cursor / Claude Code / Cline など主要ツールで改造なしに利用可能です。
- ✅ 価格は GPT-5.4 のわずか 1/7。Thinking モードこそが、このモデルの真骨頂です。
コーディングを主とする開発チームにとって、deepseek-v4-pro は今すぐ試す価値があります。単なる「安価な代替品」ではなく、新しい標準(デフォルト)になり得るフラッグシップモデルです。
🎯 アクションプラン:今日中に APIYI
apiyi.comで API キーを取得し(Pro 専用、日額上限を ¥200–500 に設定)、業務を代表するコード、数学、長文のプロンプトを 20 件ほど実行して、V4-Pro(Thinking モード)と現在の主力モデルを AB テストしてみてください。コーディングの品質が明らかに向上するなら、Cursor や Claude Code のデフォルトモデルを切り替えましょう。日常的な安価なモデルが必要なら、V4-Flash(前回の移行ガイドを参照)を併用してください。バッチテスト時はvip.apiyi.comを使用し、メインサイトの揺らぎ時にはb.apiyi.comが自動でフォールバックします。完全な接続サンプル、IDE 設定、ベンチマーク再現スクリプトはdocs.apiyi.comで確認できます。
deepseek-v4-pro の意義は「また安い SOTA モデルが出た」というレベルを超えています。これは、オープンモデルが初めてコアとなるコーディング能力において、クローズドなフラッグシップモデルを完全に圧倒したことを意味しており、AI エンジニアリングに真剣に取り組むすべてのチームが検証すべき出来事です。
著者: APIYI 技術チーム
関連リソース:
- DeepSeek 公式発表: api-docs.deepseek.com/news/news260424
- Hugging Face オープンリポジトリ: huggingface.co/deepseek-ai/DeepSeek-V4-Pro
- APIYI 公式サイト: apiyi.com
- APIYI ドキュメント: docs.apiyi.com
- APIYI メインサイト: api.apiyi.com(バックアップ: vip.apiyi.com / b.apiyi.com)