2026年のコード生成用大規模言語モデル市場は、全く異なる2つの製品形態によって二分されています。一方はMistral Codestral 2(最新版 Codestral 25.08)に代表される「IDE優先・高頻度補完型」で、Fill-in-the-Middle (FIM)、高い補完成功率、80以上のプログラミング言語に対する即時応答に特化しています。もう一方はZhipu GLM-5.1に代表される「長距離エージェント型」で、744BパラメータのMoEアーキテクチャと200Kのコンテキストウィンドウを武器に、「8時間の自律的なエンジニアリングタスク」をこなすSWE-Bench Pro級の複雑なコード生成能力を強みとしています。
これら2つの路線は、ターゲットユーザーや課金戦略においてほとんど重なりがありませんが、「どちらがコードを書くのに適しているか」という問いにおいて頻繁に比較されます。本記事では、Mistral AIの公式発表(2025-07-30 Codestral 25.08)やZ.aiの開発者ドキュメント(GLM-5.1、2026-03-27公開)などの英語一次資料に基づき、アーキテクチャ、ベンチマーク、コンテキスト、長距離タスク、デプロイと価格の6つの観点から、再現可能な選定意思決定表を作成しました。また、2つのモデルのAPI接続用サンプルコードも併記していますので、10分で判断を下す助けとなるはずです。

Codestral 2 と GLM-5.1 のコアとなるポジショニングの違い
詳細なベンチマーク結果に入る前に、一つ明確にしておくべきことがあります。それは、この2つのモデルは製品カテゴリが全く異なるということです。これらを同じ土俵で比較すると、非常に誤解を招く結論に至ります。
一言で言うと
- Codestral 2 (25.08):コード補完と編集タスクに特化した専用コード生成モデル。22Bの稠密アーキテクチャ、ネイティブなFIM学習目標を持ち、「秒単位の応答+高い受け入れ率」を重視する、IDE Copilot系製品の事実上の標準の一つです。
- GLM-5.1:汎用エージェントと長距離プログラミングタスク向けの汎用フラッグシップモデル。744B MoE(1トークンあたりのアクティブパラメータは約40B)、200Kのコンテキストウィンドウを備え、SWE-Bench Proにおいて58.4ポイントを記録し、GPT-5.4、Claude Opus 4.6、Gemini 3.1 Proを上回っています。
選定前に答えるべき3つの質問
| 質問 | Codestral 2 向き | GLM-5.1 向き |
|---|---|---|
| 主な利用シーンはIDE内補完か、自律的なPR作成か? | IDE補完 | 多ステップ自律タスク |
| 1回のリクエストのトークン量は数十か、数万か? | 数十~数千 | 数千~十数万 |
| 応答待ち時間に数十秒を許容できるか? | できない | できる |
🎯 選定のアドバイス:呼び出しの80%が「コードを1行書く際の次の補完」であるなら、Codestral 2を選んでください。逆に呼び出しの80%が「リポジトリ内のバグ修正」であるなら、GLM-5.1が最適です。どちらもAPIYI (apiyi.com) の統一インターフェースを通じて並行テストが可能であり、MistralとZ.aiを個別に契約する必要はありません。
Codestral 2 と GLM-5.1 のアーキテクチャとパラメータの比較
アーキテクチャの違いは、その後のすべてのパフォーマンス表現の根源となります。
主要スペック一覧
| 項目 | Codestral 2 (25.08) | GLM-5.1 |
|---|---|---|
| ベンダー | Mistral AI | Zhipu AI (Z.ai) |
| アーキテクチャ | Dense Transformer | Mixture-of-Experts |
| 総パラメータ数 | 22B | 744B |
| アクティブパラメータ数 | 22B | 約 40B(256 experts、1トークンあたり8つがアクティブ) |
| コンテキストウィンドウ | 256K | 200K |
| 最大出力 | 標準 | 128K tokens |
| 注意力機構 | 標準 + FIM 最適化 | DeepSeek Sparse Attention |
| ライセンス | Mistral 商用ライセンス / MNPL | MIT(オープンソースウェイト) |
| リリース日 | 2025-07-30(最新イテレーション) | 2026-03-27 |
| 対応プログラミング言語 | 80以上の主要言語 | 汎用多言語 |
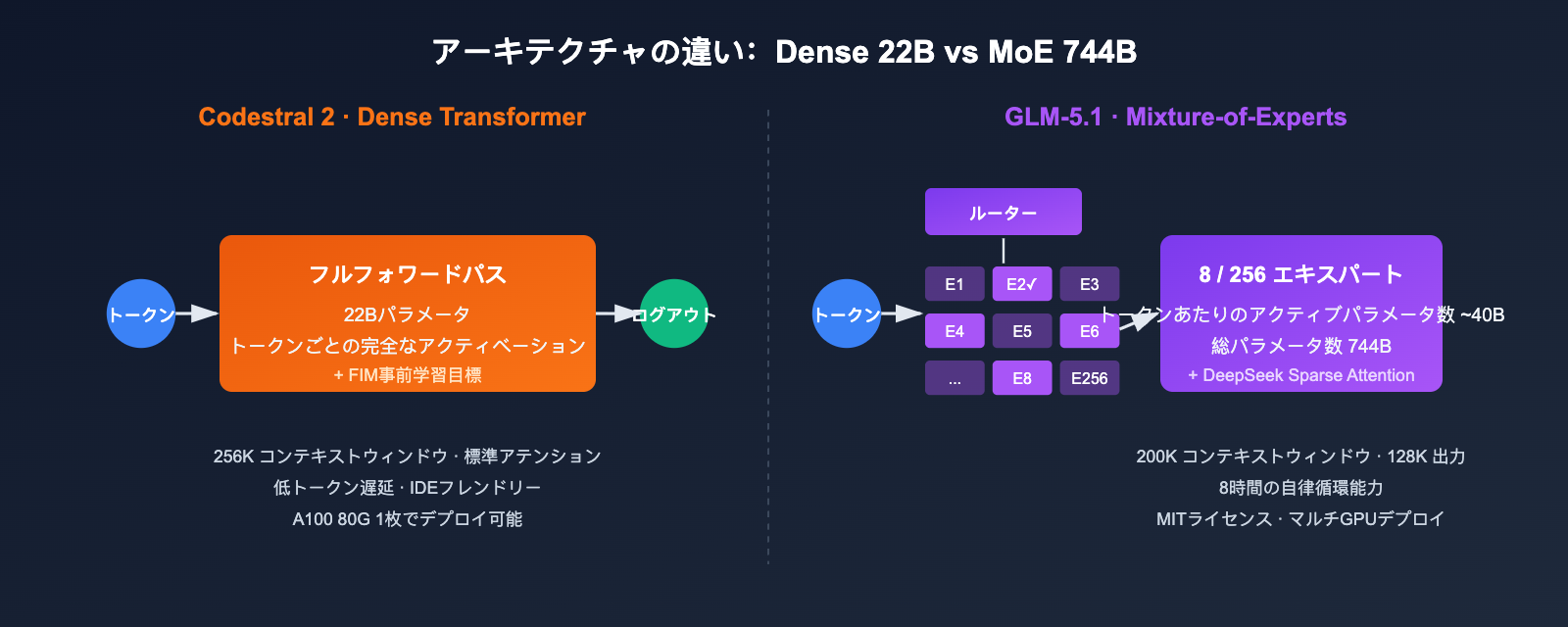
アーキテクチャの違いによる直接的な影響
- VRAMとデプロイコスト:Codestral 2は22Bのため、単一マシン(A100 80G)で推論可能です。一方、GLM-5.1はマルチGPU並列処理やホスト型推論サービスが必要です。
- シングルトークン遅延:Codestral 2のDenseアーキテクチャは、短い入力に対してより安定した遅延を実現します。GLM-5.1はルーターの選択や疎な注意機構の影響を受けるため、最初のトークン生成はわずかに遅れますが、長いシーケンスでは優位性があります。
- オープンソース戦略:GLM-5.1はMITライセンスでウェイトが公開されており、プライベートデプロイや追加学習に適しています。Codestral 2はローカル実行可能ですが、商用利用にはライセンスが必要です。
🎯 デプロイの推奨:完全にプライベートな環境でデプロイする必要があるチームは、GLM-5.1のMITライセンス版を優先してください。自社ホスティングを検討せず、迅速に導入したいチームは、APIYI (apiyi.com) を通じて両モデルのAPIを直接呼び出すことで、調達やライセンス交渉の手間を省くことができます。
Codestral 2 vs GLM-5.1 コアコードベンチマーク比較
両モデルのスコアはメーカーによる自己評価であり、評価セットは完全には一致していません。ここでは直接比較可能な指標のみを記載します。
Codestral 2 の強み:補完品質とIDE指標
| 指標 | 数値 | 説明 |
|---|---|---|
| Accepted Completions(受け入れ率) | +30%(25.01比) | 本番環境IDEでの採用率 |
| Retained Code(保持率) | +10% | 提案コードがコミット時に削除されなかった割合 |
| Runaway Generations(暴走生成) | -50% | 無意味な長文生成の減少 |
| IFEval v8(指示追従) | +5% | 指示の正確性 |
| MultiPL-E 平均スコア | +5% | 多言語コード生成能力 |
| HumanEval(前世代 25.01 データ) | 86.6% | 参考データ |
| MBPP(前世代 25.01 データ) | 91.2% | 参考データ |
GLM-5.1 の強み:複雑なエンジニアリングタスク
| 指標 | 数値 | 説明 |
|---|---|---|
| SWE-Bench Pro | 58.4 | GPT-5.4 / Claude Opus 4.6 / Gemini 3.1 Pro を上回る |
| Claude Code 比較 | 45.3(Opus 4.6 は 47.9) | Opus 4.6 の 94.6% に到達 |
| vs GLM-5 ベースライン | +28% | ポストトレーニング最適化による向上 |
| KernelBench Level 3 | 3.6倍の高速化 | MLカーネル最適化シナリオ |
| 単一タスクの継続時間 | 最大8時間 | 自律的な「実験-分析-最適化」サイクル |
両者の能力重複度評価
| 能力 | Codestral 2 | GLM-5.1 |
|---|---|---|
| 単一ファイル補完 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| 複数ファイルのリファクタリング | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| バグ特定 + PR修正 | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| クロス言語翻訳 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| エージェント / ツール使用 | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| 初回トークン遅延 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |

🎯 ベンチマークの読み方:公式データは通常、最も有利な設定で測定されているため、実際の業務環境では10%〜20%程度の変動がある可能性があります。APIYI (apiyi.com) で自社のコードベースを使用してA/Bテストを行い、最終的な判断を下すことをお勧めします。
description: Codestral 2とGLM-5.1のコンテキストウィンドウと長距離タスク能力を比較。コード補完から自律型エージェントまで、最適なモデルの選び方とAPIYIでの活用方法を解説します。
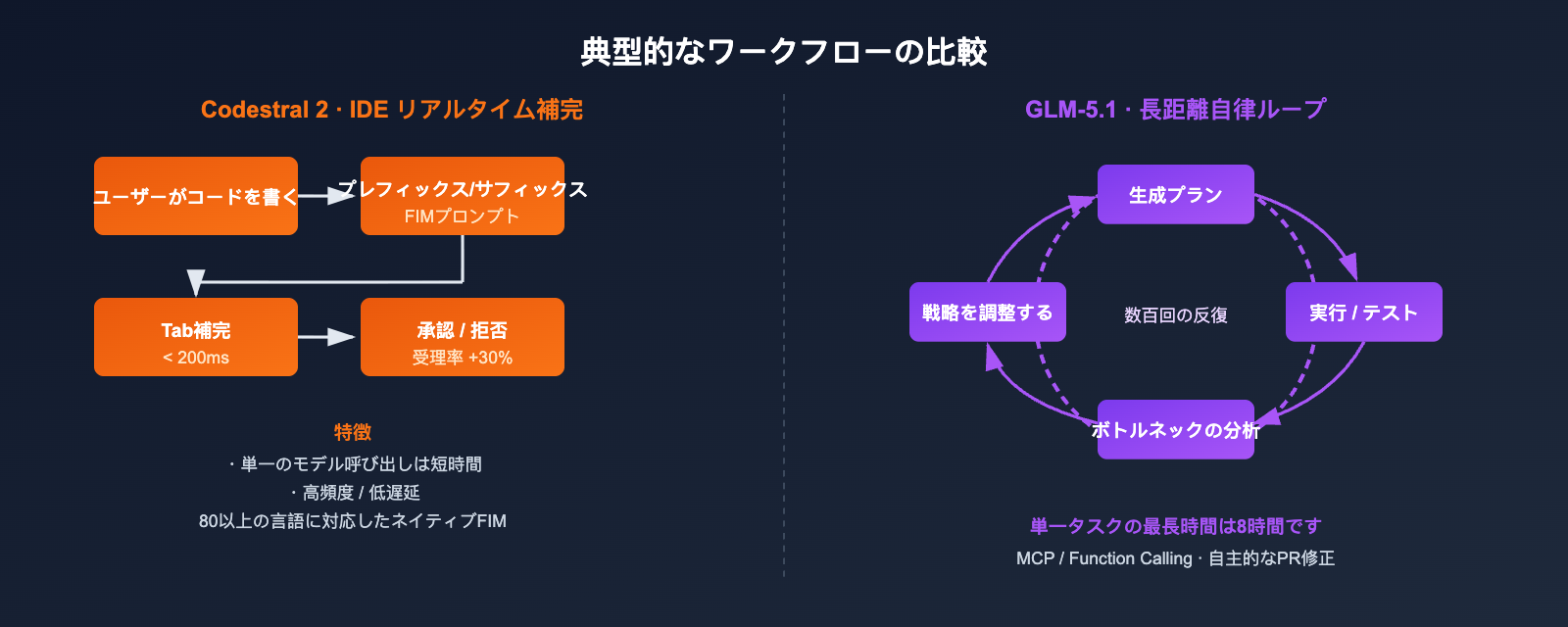
Codestral 2 と GLM-5.1 のコンテキストと長距離タスク能力
256K と 200K というコンテキストウィンドウの数値は非常に近いですが、それぞれが担うタスクの性質は全く異なります。
Codestral 2 の 256K コンテキスト:全リポジトリ補完
Codestral 2 は、256K のコンテキストを主に**「コードベース全体をプロンプトに詰め込む」**ために使用し、補完時にファイル間の依存関係を認識できるように設計されています。
- 適しているタスク:モノレポ内の大規模な関数補完、プロジェクト全体の Lint Fix、モジュールを跨いだリネーム。
- 適していないタスク:多段階の推論、ツール呼び出し、結果の書き戻しが必要なエージェントプロセス。
GLM-5.1 の 200K コンテキスト + 8 時間の自律ループ
GLM-5.1 のブレイクスルーは「どれだけ多くのコンテキストを詰め込めるか」ではなく、「どれだけ長く自律的に作業し続けられるか」にあります。
- 公式デモでは、モデルが単一タスク内で数百回もの反復を行えます:ベンチマーク実行 → ボトルネックの特定 → 戦略の調整 → 再度ベンチマーク実行。
- DeepSeek Sparse Attention により、200K の長シーケンス推論コストを実用的な範囲に抑えています。
- Function Calling / MCP と組み合わせることで、外部ツールチェーンと直接連携可能です。
長距離タスクの比較
| タスク | Codestral 2 | GLM-5.1 |
|---|---|---|
| 200行の関数を補完する | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| GitHub Issue から PR を生成する | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| リポジトリ全体からバグを探して修正する | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| MLカーネルの多段階自動チューニング | ⭐ | ⭐⭐⭐⭐⭐ |
| IDEでTabキーによる補完を行う | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
🎯 シナリオ移行のアドバイス:これまで Codestral を使用して全リポジトリ補完を行っていたチームが、「補完はできたがテストが通らない」という課題に直面した場合、GLM-5.1 に「生成-実行-修正」のサイクルを任せてみるのがおすすめです。APIYI (apiyi.com) で
base_urlを切り替えるだけで、既存の OpenAI 互換コードをそのまま再利用できます。
クイックスタート:Codestral 2 と GLM-5.1 の API 接続比較
両モデルとも OpenAI 互換のインターフェースを提供しており、主な違いはモデル名とパラメータです。以下の例では、APIYI (apiyi.com) の統一された base_url を使用した最小限のコードを紹介します。
Codestral 2 の呼び出し(コード補完)
from openai import OpenAI
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="YOUR_API_KEY",
)
resp = client.chat.completions.create(
model="codestral-latest", # Codestral 25.08 を指定
messages=[
{"role": "system", "content": "あなたはシニアPythonエンジニアです。"},
{"role": "user", "content": "高性能なLRUキャッシュの実装を補完してください。"},
],
temperature=0.2,
max_tokens=512,
)
print(resp.choices[0].message.content)
GLM-5.1 の呼び出し(長距離タスク)
from openai import OpenAI
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="YOUR_API_KEY",
)
resp = client.chat.completions.create(
model="glm-5.1",
messages=[
{"role": "system", "content": "あなたはSWEエージェントです。リポジトリを分析し、テストを実行し、反復してください。"},
{"role": "user", "content": "リポジトリ内の tests/test_api.py の失敗しているテストケースをすべて修正してください。"},
],
temperature=0.3,
max_tokens=8192,
# GLM-5.1 は Function Calling + 構造化出力をサポート
)
print(resp.choices[0].message.content)
📎 FIM 専用呼び出しを表示(Codestral 2 独自機能)
# Codestral のネイティブ FIM は prefix / suffix でプロンプトを組み立てます
prefix = "def binary_search(arr, target):\n "
suffix = "\n return -1"
prompt = f"[PREFIX]{prefix}[SUFFIX]{suffix}[MIDDLE]"
# このプロンプトを user コンテンツとして codestral-latest に送信すると、高精度な補完が得られます
🎯 接続のアドバイス:両モデルとも OpenAI スキーマに準拠しているため、モデル名を切り替えるだけで同じビジネスロジックを再利用できます。APIYI (apiyi.com) を通じて一括管理することで、Mistral Console や Z.ai のアカウント管理、残高確認、レート制限対策などの運用コストを削減できます。
title: Codestral 2 と GLM-5.1 の価格とデプロイ戦略
description: Codestral 2 と GLM-5.1 の価格体系、デプロイオプション、およびユースケース別の選定ガイドを解説します。APIYI を活用したコスト最適化のヒントも紹介。
Codestral 2 と GLM-5.1 の価格とデプロイ戦略
価格とデプロイの柔軟性は、意思決定における最後の重要なピースです。
公開価格の目安
| モデル | 入力単価 | 出力単価 | 備考 |
|---|---|---|---|
| Codestral 2(25.08) | $0.20 / 1M | $0.60 / 1M | Codestral シリーズの価格体系を継承 |
| GLM-5.1 | 約 $3〜の Coding Plan プラン | プラン制 | トークン課金オプションも別途提供 |
注:上記の価格はメーカー公式サイトおよび公開情報に基づくものです。実際のレートやキャンペーンは当日の状況をご確認ください。
デプロイオプションの比較
| デプロイ方式 | Codestral 2 | GLM-5.1 |
|---|---|---|
| 公式 Cloud API | ✅ Mistral Console | ✅ Z.ai プラットフォーム |
| サードパーティ互換ゲートウェイ | ✅(APIYI apiyi.com 等) | ✅(APIYI apiyi.com 等) |
| VPC / プライベートクラウド | ✅ ライセンスが必要 | ✅ MIT ライセンスで自由なデプロイが可能 |
| ローカル単体推論 | ✅ A100 1枚/コンシューマーGPUで制限あり | ❌ 複数カードが必要 |
| Function Calling | 対応(chat completions 経由) | ✅ ネイティブ対応 + MCP |
🎯 コスト最適化のアドバイス:補完頻度が高く、1回あたりのトークン数が少ない IDE シナリオでは、Codestral 2 + キャッシュの組み合わせを優先しましょう。一方、頻度は低いが1回あたりのトークン数が多いエージェントシナリオでは、GLM-5.1 のプラン制の方が経済的です。これら2つの戦略は、APIYI apiyi.com 上でモデルごとにグループ設定を行うことで、アカウント全体の予算が特定のモデルに偏って消費されるのを防ぐことができます。
Codestral 2 と GLM-5.1 のユースケース別推奨と注意点
4つの典型的なシナリオにおける意思決定
| シナリオ | 推奨モデル | 主な理由 |
|---|---|---|
| VSCode / JetBrains 補完プラグイン | Codestral 2 | FIM(Fill-In-the-Middle)ネイティブ対応 + 低遅延 |
| 自動バグ修正 / PR ボット | GLM-5.1 | 長期的な自律ループ性能 |
| コードレビュー支援(単一ファイル) | Codestral 2 | 高速レスポンス、低コスト |
| エンドツーエンドエージェント(テスト/デプロイ連携) | GLM-5.1 | MCP + Function Calling |
| ボイラープレート(プロジェクト雛形)生成 | 並列 | どちらのモデルでも可 |
| ML カーネルのパフォーマンスチューニング | GLM-5.1 | KernelBench による 3.6倍の高速化 |
よくある落とし穴リスト
- ❌ Codestral 2 にエージェントを任せない:制御不能な生成率は 50% 低減されましたが、マルチステップの意思決定に最適化されているわけではありません。
- ❌ GLM-5.1 にミリ秒単位の補完をさせない:最初のトークンまでの遅延(TTFT)が、IDE の Tab キーによる補完体験を損なう可能性があります。
- ❌ 一つのランキングだけを信じない:SWE-Bench Pro では GLM-5.1 が優勢ですが、HumanEval では Codestral シリーズも決して劣っていません。
- ✅ 小規模な A/B テストを実施する:自社の業務で最も典型的な 100 件のプロンプトを用意し、APIYI apiyi.com でモデルパラメータを切り替えて比較テストを行ってください。
よくある質問(FAQ)
Q1:公式サイトで Codestral 2 ではなく Codestral 25.08 と呼ばれているのはなぜですか?
Mistral の命名規則は <シリーズ名>-<年>.<月> となっています。Codestral 25.08 は Codestral の第2世代にあたります(第1世代は24.05にリリースされ、第2世代は25.01から25.08へと進化しました)。業界やコミュニティでは、25.01以降を総称して「Codestral 2」と呼ぶのが一般的です。モデル呼び出し時には codestral-latest を指定すれば、常に第2世代の最新バージョンを利用できます。
Q2:GLM-5.1 は 744B というパラメータ数ですが、推論は遅くないですか?
MoE(混合エキスパート)アーキテクチャを採用しているため、1トークンあたりにアクティブ化されるのは 40B パラメータのみです。さらに DeepSeek Sparse Attention を組み合わせることで、実際の推論速度は 40B クラスの密なモデルに近いレベルを実現しています。APIYI(apiyi.com)の長接続およびキャッシュ戦略と組み合わせれば、長いコンテキストを扱う場面でも体感的な遅延は許容範囲内に収まります。
Q3:どちらのモデルの方がコンテキストを最大限活用できますか?
Codestral 2 の 256K は「容量」としての側面が強く、GLM-5.1 の 200K は稀少注意機構(Sparse Attention)のおかげで「実質的な利用効率」の面で優れています。コードベース全体を扱うタスクを行う際は、tiktoken や公式のトークナイザーを使用して実際のトークン数を事前に見積もり、無駄な切り捨てを防ぐことを推奨します。
Q4:オープンソースの重み(ウェイト)は企業にとってどのような実利がありますか?
GLM-5.1 は MIT ライセンスで重みが公開されており、社内ネットワークへのデプロイや追加学習が可能です。一方、Codestral 2 の商用利用にはライセンス契約が必要です。コンプライアンス要件が厳しい金融機関や政府・企業にとって、この違いは非常に大きいです。単に地域的なアクセス制限を回避したいだけであれば、APIYI(apiyi.com)が提供する安定した国内向けアクセスポイントを利用することも可能です。
Q5:2つのモデルを併用することはできますか?
はい、併用を推奨します。典型的な手法として、IDEの補完には Codestral 2、バックエンドの Agent には GLM-5.1 を使用する方法があります。それぞれ異なるモデルキーを使用し、APIYI(apiyi.com)で一元的に課金管理を行うのが効率的です。
Q6:ベンチマークスコアはメーカーの自社測定ですが、信頼性はどの程度ですか?
Codestral と GLM のスコアはいずれもメーカーによる自己申告であり、Z.ai による SWE-Bench Pro の 58.4 というスコアも独立した検証はまだ行われていません。公開されているスコアは「能力の上限の目安」として捉え、導入前には必ず実際の業務シナリオで回帰テストを行うことをお勧めします。
まとめ:Codestral 2 と GLM-5.1 の最終選定アドバイス
冒頭の3つの問いに戻りましょう。
- Copilot、Tab 補完、コードスニペット生成といった製品であれば、Codestral 2 を選択してください。FIM(Fill-In-the-Middle)、遅延、コスト、そして 80 以上の言語対応という点で、この種のシナリオにおける最適なバランスを備えています。
- PR ロボット、バグ修正エージェント、8時間稼働するバックエンドの Agent といった製品であれば、GLM-5.1 を選択してください。744B MoE + SWE-Bench Pro 58.4 + 長期自律ループという構成は、現在オープンソース陣営の中で Claude Opus 4.6 に最も近い選択肢です。
- 両方のシナリオを併せ持つ製品であれば、2026年時点での最も経済的な解決策は両モデルの併用です。
🎯 導入アドバイス:選定を「どちらか一つ」にするのではなく、「デュアルモデル編成」へとアップグレードしましょう。APIYI(apiyi.com)の OpenAI 互換インターフェースを利用すれば、業務コード内で「短い補完 / 長いタスク」をフィールドで区別するだけで、Codestral 2 と GLM-5.1 の間で自動ルーティングを行い、それぞれのタスクに最適なモデルへリクエストを振り分けることができます。
— APIYI Team(APIYI テクニカルチーム)