2026年4月初,一个名为 HappyHorse 的神秘AI视频模型悄无声息地出现在Artificial Analysis Video Arena的盲测榜单上。V1与V2两个版本几乎同时刷新了文本到视频(Text-to-Video)与图像到视频(Image-to-Video)双榜的Elo分数,将Seedance 2.0、Kling 3.0、PixVerse V6等一线选手全部甩在身后。然而仅仅几天之后,HappyHorse 1.0 又突然从榜单上消失,只留下少量截图和一份语焉不详的官方页面。
围绕 HappyHorse模型 的猜测瞬间在英文AI圈炸开:它是Wan 2.7的伪装马甲?是ByteDance Seedance团队的下一代实验?还是某家未公开的亚洲实验室突然亮剑?本文基于公开可验证的资料,对 HappyHorse 1.0 的架构、性能、开源状态和潜在出身做一次完整梳理,帮助你判断这匹黑马值不值得纳入你的视频生成工具栈。

HappyHorse模型核心信息一览
在拆解技术细节之前,我们先用一张表把已知信息浓缩到一屏之内,方便快速建立认知。
| 维度 | HappyHorse 1.0 已知信息 |
|---|---|
| 模型类型 | 文本+图像到视频生成模型(联合生成画面与音频) |
| 架构 | 40层单流Self-Attention Transformer,无Cross-Attention |
| 推理步数 | 仅需8步去噪,无需CFG(Classifier-Free Guidance) |
| 多语言支持 | 中文、英文、日文、韩文、德文、法文 |
| 发布物 | 基础模型 / 蒸馏模型 / 超分模型 / 推理代码(官方声称全部开源) |
| 出现位置 | Artificial Analysis Video Arena(部分资料也提到LMArena视频赛道) |
| 当前状态 | V1/V2已从公开榜单消失,官网仍在线但GitHub/Model Hub标注为"Coming Soon" |
| 疑似出身 | 来自亚洲团队,社区猜测与Wan 2.7 / Seedance体系有关,但未被官方确认 |
🎯 快速测试建议:由于 HappyHorse模型 的官方权重尚未在主流推理平台开放,如果你想第一时间在生产环境对比同档位的视频模型(如Seedance 2.0、Kling 3.0、Veo 3.1),我们建议先通过APIYI(apiyi.com)这样的统一API中转平台并行调用多家视频模型,等待HappyHorse正式发布后再无缝切换,避免重复改造工程。
HappyHorse モデル登場のタイムライン
この「幸せな馬(HappyHorse)」が、なぜ海外のAIコミュニティにこれほどの衝撃を与えたのか。その理由を探るために、まずは時系列を整理してみましょう。
Year of the Horse(午年)と命名の偶然
2026年は中国の干支で「午年(Year of the Horse)」にあたります。2月の春節(旧正月)以降、海外メディアやUX Tigersなどの専門コラムでは、中国のAI界が「馬」をテーマにした一連のリリースを準備しているという噂が繰り返し報じられていました。「HappyHorse」という命名は、干支に呼応しているだけでなく、同時期に登場した「The Horse」と略される別のモデルとも関連付けられ、コミュニティが「アジアのチームによるものだ」と確信する重要な手がかりとなりました。
Arenaでの爆発的な登場と消失
X(旧Twitter)でBrent Lynch氏らAI動画評価者が4月初旬に公開したスクリーンショットやその後の報道によると、HappyHorse 1.0 の登場から消失までの流れは以下の通りです。
- 初登場: V1バージョンが匿名エントリとして「Artificial Analysis Video Arena」に登録され、わずか数時間でテキストから動画生成のブラインドテストでトップ3にランクイン。
- V2バージョンの公開: ほぼ同時にV2バリエーションが登場し、一時は画像から動画生成ランキングの1位と2位を独占。
- 首位獲得: 音声なしの部門において、HappyHorse 1.0 はSeedance 2.0 720p、Kling 3.0、PixVerse V6といったトップクラスのモデルをすべて追い抜きました。
- 消失: 数日以内にV1/V2は公開ランキングから同時に削除され、スクリーンショットと第三者の記録だけが残されました。その後、公式サイトに「ベースモデルを近日中にオープンソース化する」との告知が掲載されました。
このような「突然のランクイン→独占→静かな撤退」という流れは、通常2つの可能性を示唆します。ある研究所が匿名でA/Bテストを行っていたか、あるいはモデルの背後にいる企業が正式発表を準備中であり、トラフィックによる露出を避けるために一時的に取り下げたかです。どちらの解釈も、HappyHorse モデル の神秘性をさらに高める結果となりました。

HappyHorse モデルアーキテクチャ解析: 40層シングルストリームTransformerの強さ
公式論文はまだ公開されていませんが、happyhorse-ai.com やミラーサイト happy-horse.net の記述から、HappyHorse 1.0 のアーキテクチャにおける重要な設計思想が見えてきました。
マルチストリームからシングルストリームSelf-Attentionへ
従来の動画生成モデル(特に音声、テキスト、映像を同時に扱うマルチモーダルモデル)は、通常マルチストリーム(multi-stream)アーキテクチャを採用しています。テキスト、動画、音声それぞれが独自のエンコーダーを持ち、Cross-Attentionを通じて相互にやり取りする仕組みです。この構造は柔軟ですが、パラメータの無駄が多く、推論時には複数のブランチ間でテンソルを移動させる必要があります。
HappyHorse 1.0 は、これを一つのパイプラインに簡略化しました。40層のSelf-Attention Transformerがテキスト、動画、音声のトークンを同時に処理し、その間にCross-Attentionや特定のモダリティ専用のサブネットワークは存在しません。 すべてのモダリティが統一されたトークンシーケンスとしてエンコードされ、同じアテンション空間内で相互にモデリングされます。この設計には、理論的にいくつかのメリットがあります。
- パラメータ利用効率が高い: モダリティを分離するための冗長なパラメータが不要。
- 推論パスが短い: クロスモーダルな追加の転送がなく、カーネルがより連続的。
- 学習目標の統一: テキスト、映像、音声が同じ損失関数を共有し、エンドツーエンドの最適化が容易。
- 音と映像の統合が自然: 音声と映像が同じシーケンス内のトークンであるため、同期制約が自動的に適用される。
8ステップのノイズ除去 + CFGなしの究極の推論
Stable Video Diffusion、Sora、Klingなどのモデルに慣れ親しんだ開発者にとって、「数十ステップのノイズ除去 + Classifier-Free Guidance(CFG)」は筋肉反射のようなものです。しかし、HappyHorse 1.0 の公式説明は非常に過激です。わずか8ステップのノイズ除去で、CFGを使用せずに、現在のArenaランキング1位の画質を生み出せるとされています。
これは通常、学習段階で「Consistency Distillation(一貫性蒸留)」、「Rectified Flow」、「Progressive Distillation」のような手法を用い、多ステップのサンプリングを数ステップの直接予測に圧縮していることを意味します。同時にリリースされた「蒸留モデル」や「超解像モデル」と組み合わせることで、推論スタック全体が「エッジデバイス対応 + サーバー側の高スループット」という両方の目標に最適化されています。
想定されるパラメータ規模とVRAM要件
ウェイトが公開されていないため、HappyHorse モデル の正確なパラメータ数は検証できません。しかし、40層、シングルストリーム、6言語対応という記述とArenaでのパフォーマンスを考慮すると、Wan 2.x、Seedance 1.x、Hunyuan Videoといった公開モデルと同等クラス、おそらく 10B〜30Bパラメータの範囲 に収まると推測されます。つまり、ローカル環境で本格的にデプロイするには、少なくとも1枚の高性能なプロ用GPUが必要であり、一般的なコンシューマー向けGPUで動かすには、INT8/FP8量子化バージョンの登場を待つ必要があります。
🎯 アーキテクチャ選定のアドバイス: もしチームで「次世代の動画生成インフラ」を評価しているなら、HappyHorse 1.0 のような「シングルストリームTransformer + 極少ステップ推論」というパラダイムを重点的に観察することをお勧めします。完全なオープンソース化を待つ間は、APIYI(apiyi.com)で提供されているSeedance、Kling、Veoなどのモデルを使用してエンジニアリングの調整を行い、プロンプト、カメラワークのスクリプト、後処理のパイプラインを磨き上げておき、HappyHorseのウェイトが準備でき次第、切り替えるのが賢明です。
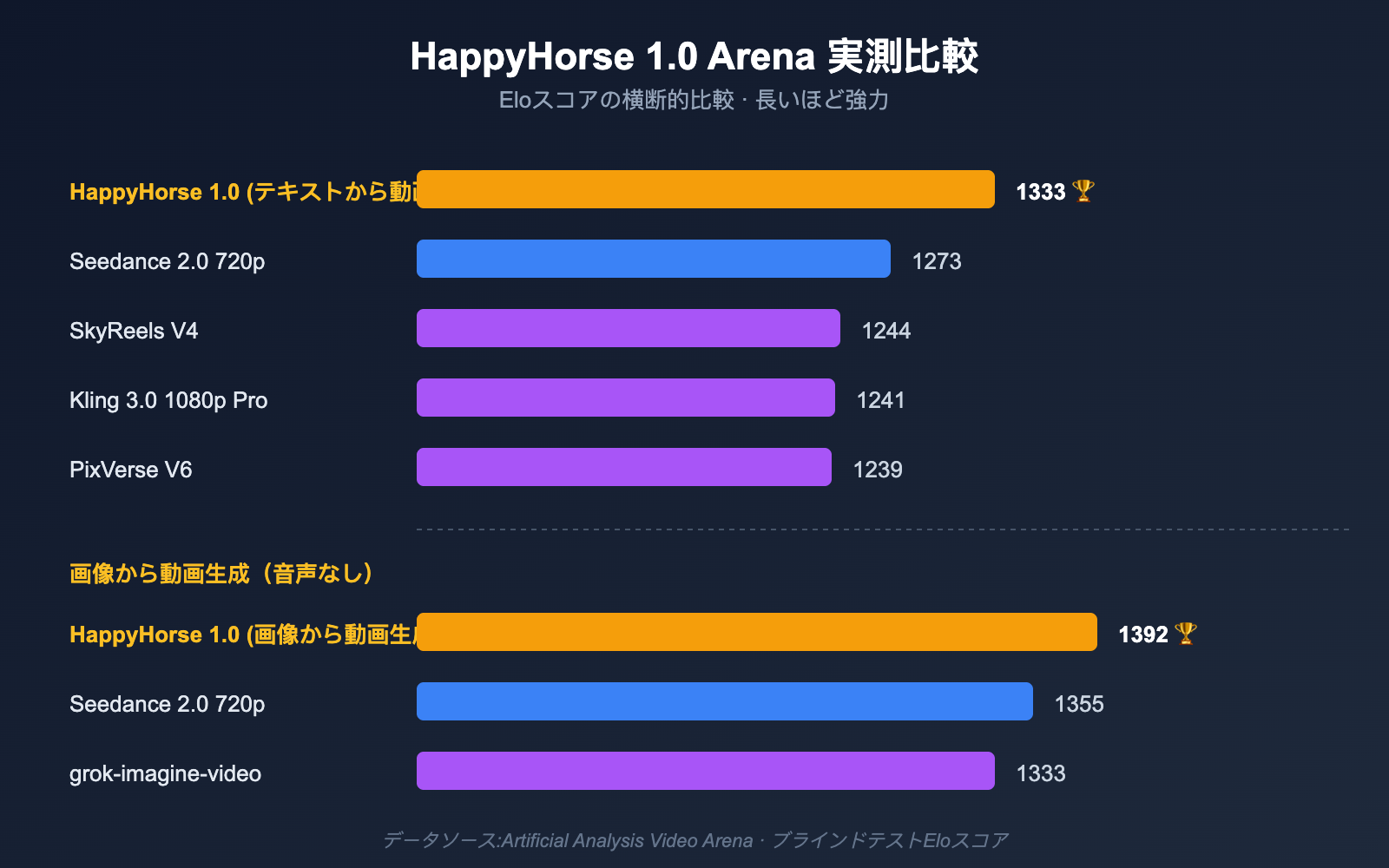
HappyHorse モデルの実測データ:Arenaの2つのランキングをどう制したか
アーキテクチャの解説を終えたところで、現場のチームを真に納得させるのはやはり数字です。以下の表は、サードパーティの公開記録に基づき、HappyHorse 1.0 が Artificial Analysis Video Arena で獲得したブラインドテストのEloスコアと、主要な競合モデルの順位をまとめたものです。
テキストから動画生成 / 画像から動画生成のElo比較
| カテゴリ | 順位 | モデル | Eloスコア |
|---|---|---|---|
| テキストから動画生成(音声なし) | 1 | HappyHorse-1.0 | 1333 |
| テキストから動画生成(音声なし) | 2 | Dreamina Seedance 2.0 720p | 1273 |
| テキストから動画生成(音声なし) | 3 | SkyReels V4 | 1244 |
| テキストから動画生成(音声なし) | 4 | Kling 3.0 1080p (Pro) | 1241 |
| テキストから動画生成(音声なし) | 5 | PixVerse V6 | 1239 |
| テキストから動画生成(音声あり) | 1 | Dreamina Seedance 2.0 720p | 1219 |
| テキストから動画生成(音声あり) | 2 | HappyHorse-1.0 | 1205 |
| 画像から動画生成(音声なし) | 1 | HappyHorse-1.0 | 1392 |
| 画像から動画生成(音声なし) | 2 | Dreamina Seedance 2.0 720p | 1355 |
| 画像から動画生成(音声なし) | 3 | PixVerse V6 | 1338 |
| 画像から動画生成(音声なし) | 4 | grok-imagine-video | 1333 |
| 画像から動画生成(音声なし) | 5 | Kling 3.0 Omni 1080p (Pro) | 1297 |
いくつかの重要なポイント:
- 画像から動画生成カテゴリで最大のリード: 1392対1355と、Eloスコアで約40ポイントの差をつけています。これはブラインドテストにおいて「ユーザーが安定して違いを実感できる」レベルの差です。
- 純粋なテキストから動画生成でも1位: 1333対1273と60ポイントのリード。これは参照画像がない場合でも、HappyHorse モデル が構図や人物の動きといった基礎能力において Seedance 2.0 を上回っていることを意味します。
- 音声カテゴリは暫定2位: 音声と映像の同期においては依然として Seedance 2.0 がリードしています。これは同モデルが「AIディレクター」による長尺の物語制作に向けて行ってきたエンジニアリングの磨き込みによるものです。
- V2のバリエーション: V2は一部のスクリーンショットで一時的にトップに立ったこともありますが、公式には現在1.0のみが公開されており、V2が後に「消えた」バージョンなのかどうかは未確認です。
多言語対応と人間中心のシナリオ
公式発表では、HappyHorse 1.0 が 中国語、英語、日本語、韓国語、ドイツ語、フランス語 の6言語をネイティブサポートしていることが明記されています。また、以下のような「人間中心(human-centric)」のシナリオにおいて、モデルが特に優れたパフォーマンスを発揮することが強調されています。
- 繊細な表情演技(facial performance)
- 自然な音声調整(speech coordination)
- リアルな身体動作(body motion)
- 正確なリップシンク(lip sync)
この説明から、HappyHorse モデル が単なる「風景のプロモーションビデオ」生成ではなく、「バーチャルヒューマン / デジタルコンテンツ / 短編ドラマ」の領域をターゲットにしていることが明確にわかります。これが、画像から動画生成(人物写真に動きを与える)カテゴリで最大のリードを誇る理由でもあります。これはデジタルヒューマン制作における核心的なニーズだからです。
HappyHorse モデルの出自を推測する:WAN 2.7?Seedance?それともダークホースの新星か?
HappyHorse 1.0 のスクリーンショットが英語圏のAIコミュニティで拡散され始めると、「一体どこのモデルなのか」という議論が最も盛り上がりました。コミュニティの情報を総合し、推測を以下の表にまとめました。
3つの主要な推測の比較
| 推測の出所 | 核心的な根拠 | 反論の根拠 |
|---|---|---|
| Alibaba Wan 2.7 の別名 | Wan 2.7 と同時期のリリース。Alibaba Tongyi Lab は動画分野で一貫して積極的。名前に「Horse」が含まれるのは午年を意識? | Wan 2.7 の公式説明は画像/思考モード寄りであり、HappyHorse が強調するシングルストリーム40層アーキテクチャと一致しない |
| ByteDance Seedance チームの実験版 | Seedance 2.0 は現在Arenaの上位に君臨する中国勢。ByteDanceには匿名テストを行う十分な動機がある | Seedance 2.0 公式は音声カテゴリで依然としてHappyHorseをリードしており、ByteDanceが「より強力なバージョン」を別名でアップロードする理由がない |
| 未公開ラボ / 学術連合体 | 「完全オープンソース + 蒸留モデル + 超解像モデル」というパッケージングが研究スタイルに近い。名前が奇抜で公式サイトも極めてシンプル | モデル品質がすでに商用レベルに達しており、純粋な学術チームがこれほどの規模を独自にトレーニングするのは困難 |
個人的には、3番目の仮説の可能性が高まっていると考えています。HappyHorse 1.0 は、オープンソース戦略を通じて一気に知名度を上げたいと考えている新しいチームによるもので、匿名でArenaに投稿したのは、まずブラインドテストのデータで信頼を築き、その後に正式発表するためではないでしょうか。 この「ランキングで実績を作り、オープンソース化し、製品をリリースする」という手法は、過去18ヶ月間で複数のアジアのラボによって有効性が証明されています。
しかし、これらはあくまで推測です。GitHubリポジトリとModel Hubが正式に公開されるまでは、「これがXだ」という主張を事実として受け取るべきではありません。開発者にとってより現実的な態度は、**「その出自よりも、まずはその能力曲線に注目すること」**です。
🎯 慎重なアドバイス: HappyHorse モデル の重みが公開されておらず、ソースが公式に確認されていない現状では、本番環境の業務を直接これに依存させることは推奨しません。まずは APIYI (apiyi.com) などの成熟したプラットフォームを通じて、Seedance 2.0、Kling 3.0、Veo 3.1 といった商用化済みの動画モデルでプロジェクトを完遂させつつ、内部で HappyHorse のオープンソース化の進捗を並行して評価することをお勧めします。
HappyHorse モデルが業界に与える3つの影響
たとえ HappyHorse 1.0 が最終的に入念に計画されたプロモーション活動に過ぎなかったとしても、このモデルはAI動画生成業界全体に記録しておくべき3つの影響を残しました。
第1層:アーキテクチャパラダイムへのシグナル
過去2年間、主要な動画モデルは「マルチストリーム Diffusion + Cross-Attention」という手法の洗練に注力してきました。しかし、HappyHorse モデル は Arena での1位獲得を通じて、「シングルストリーム Self-Attention + 極めて少ないステップでの推論」というアプローチでも SOTA(最高水準)に到達可能であり、かつエンジニアリング的にもよりクリーンであることを証明しました。これは多くのチームに、「Cross-Attention という『複雑性の税金』を省くべきではないか?」という再考を促すでしょう。
第2層:オープンソース戦略の進化
HappyHorse は、「匿名でランクイン → オープンソース化を予告 → 重みデータを公開」というリズムを選択しました。これは従来の「論文を先に出し、その後に重みデータを公開する」という手法とは異なり、コンシューマー向け製品のリリースに近い戦略です。論文よりも「ユーザーが実際に体験したデータ」を優先させたのです。もし予定通りにオープンソース化されれば、HappyHorse 1.0 は Wan、Hunyuan Video、Open-Sora に続く、大量の二次開発が行われる動画基盤モデルになる可能性があります。
第3層:ブラインドテストランキングの信頼性
別の視点から見れば、HappyHorse の「突然の登頂と消失」は、Artificial Analysis や LMArena といったブラインドテストプラットフォームに警鐘を鳴らしました。匿名エントリーが増える中で、「真の新しいモデル」と「既存モデルの特定のチェックポイント」をどう見分けるかは、ランキング運営者が直面せざるを得ない難題となります。 開発者にとっては、Elo レーティングを見る際に、単なる数字だけでなく「モデルカード + 推論サンプル + 実際の業務データ」を組み合わせて判断する必要があることを意味しています。

開発者は HappyHorse モデルのような「突発的な事象」にどう対応すべきか
現場のエンジニアチームやコンテンツクリエイターにとって、「それが何者で、いつオープンソース化されるのか」という推測に時間を費やすよりも、こうした突発的な事象に対する標準的な対応フローを構築しておく方が賢明です。
推奨される4ステップの対応プロセス
| ステップ | アクション | 目的 |
|---|---|---|
| 1 | 統一インターフェースで既存の動画生成業務を円滑化 | 新モデル登場時にシームレスな切り替えを可能にする |
| 2 | 典型的な業務プロンプトと参照素材を収集 | 公開 Arena とは独立した社内「ベンチマークセット」を形成 |
| 3 | 新モデルが利用可能になり次第、社内ベンチマークを実行 | 自社データで Arena のスコアが再現可能か検証 |
| 4 | 総コスト(API価格 / 推論遅延 / コンプライアンス)を評価 | 主力モデルを置き換えるか判断 |
このプロセスの核心は、特定のモデルのリリースリズムに振り回されるのではなく、「新しいモデルを迅速に組み込む」こと自体を基本的な能力にすることです。HappyHorse 1.0 はあくまでその先駆けに過ぎず、2026年後半には同様の匿名モデルが様々な動画 Arena に登場することが予想されます。
🎯 エンジニアリングのヒント: HappyHorse モデル や Seedance、Kling、Veo などの競合モデルを長期的に追跡したいチームには、APIYI (apiyi.com) のような、マルチモデルの並列呼び出しに対応した API 中継サービスの利用をおすすめします。これにより、今後誰がランキング上位に入ろうとも、業務側では
modelパラメータを切り替えるだけで、比較や段階的なリリース(カナリアリリース)を完了させることができます。
HappyHorse モデルに関するよくある質問(FAQ)
Q1: HappyHorse 1.0 はすでにダウンロードして使用できますか?
現時点(2026年4月初旬)では、HappyHorse 1.0 の公式サイトにおいて、GitHubリポジトリおよびModel Hubへのリンクは依然として「Coming Soon(近日公開)」と表示されています。つまり、重みデータや推論コードはまだ一般公開されていません。「すでにダウンロードやデプロイが可能」と謳うチャネルには十分注意してください。公式発表を注視しつつ、重みが正式にリリースされるまでは、APIYI(apiyi.com)などのプラットフォームを通じて、すでに商用化されている Seedance 2.0 や Kling 3.0 などのモデルでプロジェクトを進めることをお勧めします。
Q2: HappyHorse モデルはなぜ Arena ランキングから消えたのですか?
公開情報において、消失の理由に関する明確な説明はありません。コミュニティでの議論に基づくと、主な説は2つあります。1つは、モデル作成者が結果を再整理するために一時的に取り下げたという説。もう1つは、プラットフォーム側が匿名エントリーの身元が不明であるとして一時的に非表示にしたという説です。いずれにせよ、これを単純に「モデルがダメだった」と解釈すべきではありません。消失前に記録されたEloレーティングは、実際のブラインドテストに基づいたデータだからです。
Q3: HappyHorse 1.0 と Wan 2.7 は同じモデルですか?
これを確認する公式情報はありません。Wan 2.7 は、2026年4月にアリババ通義実験室(Tongyi Lab)が正式にリリースした画像/動画生成モデルで、「思考モード」と長文レンダリングを売りにしています。一方、HappyHorse モデル は「40層のシングルストリームTransformer」と「8ステップのデノイズ推論」を強調しており、技術的な説明が一致しません。コミュニティでは同源であるとの推測もありますが、現時点では「同じ時期に同じ市場で競合する2つの製品」と見るのが妥当でしょう。
Q4: HappyHorse モデルは音声と動画を同時に生成できますか?
はい、可能です。公式発表によると、HappyHorse 1.0 は同一の40層Transformer内でテキスト、動画、音声トークンを統合的に処理するため、自然に「テキスト入力 → 音声付きショート動画出力」をサポートしています。Arenaの音声対応部門では、現在Seedance 2.0に次ぐ2位にランクインしており、第一線で活躍するモデルと言えます。
Q5: 開発者として、今どう準備すべきですか?
最も賢明な方法は、ツールチェーンの中立性を保つことです。動画生成業務を、APIYI(apiyi.com)のように複数のモデルを並行して呼び出せる統合プラットフォームに接続し、プロンプト、カメラワークのスクリプト、審査フローをあらかじめ構築しておきましょう。HappyHorse モデル が正式にオープンソース化されるか、APIが公開された際に、コードを書き直すことなくモデルパラメータを切り替えるだけで、この新しい有力モデルを即座に導入できます。
Q6: HappyHorse 1.0 はどのような業務シナリオに適していますか?
「人間中心のシーン、表情の演技、リップシンク、多言語対応」を公式が強調していることから、HappyHorse モデル は、バーチャルライバー / デジタルヒューマンのショート動画、AIショートドラマ、多言語プロモーション動画、広告内の人物カットなどに最適です。もし風景や製品の撮影がメインの業務であれば、Seedance 2.0、Veo 3.1、Kling 3.0 などの方が、現時点ではより安定した選択肢となります。
まとめ:HappyHorse モデルが私たちに示唆するもの
すべての情報を統合すると、HappyHorse 1.0 が詳細な解析に値するのは、単にArtificial Analysis Video ArenaでのEloスコアが高いからだけではありません。それは、2026年の動画生成モデルのリリースにおける新たなパラダイムを象徴しているからです。すなわち、「マルチストリームの複雑な構造からシングルストリームTransformerへ」、「数十ステップのデノイズから極少ステップ推論へ」、「論文先行から匿名ランキング先行へ」、「閉鎖的なAPIからオープンソースの約束へ」という変化です。これら4つの変化は、単独では革新的とは言えませんが、組み合わさることで動画生成モデルの進化スピードが新たな段階に入ったことを意味しています。
現場のチームへのアドバイスはシンプルです。「それが何者か」という謎解きに時間を費やすのではなく、エンジニアリングの負荷テストとして活用してください。新しいモデルが登場したその日に、あなたの動画生成パイプラインは接続と評価を完了できるでしょうか?もし答えがイエスなら、HappyHorse モデルが今後オープンソース化されようと、特定のメーカーの別名義であることが判明しようと、あるいは静かに消えていこうと、あなたはそこから確実に利益を得ることができるはずです。
🎯 最終的なアドバイス: HappyHorse 1.0 以外の主要なAI動画モデル(Seedance 2.0 / Kling 3.0 / Veo 3.1 / PixVerse V6 など)をすぐに体験したい場合や、将来的にHappyHorseへワンクリックで切り替えられる環境を維持したい場合は、APIYI(apiyi.com)のような統合中継プラットフォームを通じた接続をお勧めします。各メーカーのSDKを個別に実装する手間を省き、新しいモデルが登場した際の移行コストを最小限に抑えることができます。
著者: APIYI Team | 大規模言語モデルの社会実装とエンジニアリング実践に注目。動画およびマルチモーダルモデルの評価については、APIYI(apiyi.com)をご覧ください。