作者注:Claude Opus 4.6とGPT-5.4を、12のベンチマーク、価格設定、コンテキストウィンドウ、エージェント能力、適用シナリオについて客観的に比較し、開発者が正しい選択を行えるよう支援します。
2026年2月と3月、AI分野は2つの重要なフラッグシップモデルを迎えました:AnthropicのClaude Opus 4.6(2月5日)とOpenAIのGPT-5.4(3月5日)です。どちらも各社史上最強の汎用モデルですが、設計哲学と得意分野は大きく異なります。
ベンチマークテストは示しています:GPT-5.4が5つのカテゴリーで勝利し、Claude Opus 4.6が3つのカテゴリーで勝利——しかし、プログラミング、推論、コード品質といった中核的な次元では、Claudeのリードがより実用的な価値を持ちます。
中核的価値:この記事を読めば、プログラミング、推論、自動化、視覚など、さまざまなシナリオでどちらのモデルを選択すべきかが明確になります。

Claude Opus 4.6 vs GPT-5.4 コアデータ比較
| 比較項目 | Claude Opus 4.6 | GPT-5.4 | 説明 |
|---|---|---|---|
| リリース日 | 2026-02-05 | 2026-03-05 | 1ヶ月の間隔 |
| モデル ID | claude-opus-4-6 | gpt-5.4 | — |
| コンテキストウィンドウ | 200K (1M Beta) | 1,000K | GPTは正式に1Mをサポート |
| 最大出力 | 128K | 128K | 同じ |
| 入力料金 | $5.00/M | $2.50/M | GPTは50%安い |
| 出力料金 | $25.00/M | $15.00/M | GPTは40%安い |
| キャッシュ入力 | $0.50/M | $0.25/M | GPTは50%安い |
| 推論モード | 適応的思考 (Adaptive) | 5段階推論 (none→xhigh) | それぞれ特色あり |
| コンピュータ操作 | ✅ (72.7%) | ✅ (75.0%) | GPTが人間を超える |
| エージェントチーム | ✅ Agent Teams | ❌ | Claude独自機能 |
| ツール検索 | ❌ | ✅ Token 47%削減 | GPT独自機能 |
| 金融プラグイン | ❌ | ✅ Excel/Sheets | GPT独自機能 |
Claude Opus 4.6 と GPT-5.4 の設計哲学の違い
両モデルの設計哲学は大きく異なります:
Claude Opus 4.6 は「深層知能」路線を進んでいます。適応的思考(Adaptive Thinking)により、モデルは問題の複雑さに応じて推論の深さを自動的に決定し、手動での予算設定は不要です。Agent Teams機能では、1つのメインClaudeインスタンスが複数の独立したサブエージェントを派生させて並行作業を行い、共有タスクリストとメッセージシステムを通じて調整します。このアーキテクチャ設計は、深い理解と長い連鎖推論を必要とする複雑なプログラミングタスクにより適しています。
GPT-5.4 は「万能ツールマン」路線を進んでいます。プログラミング(GPT-5.3 Codexを継承)、コンピュータ操作、フル解像度視覚、ツール検索を初めて1つの汎用モデルに統合しました。ツール検索メカニズムにより、モデルは必要に応じてツール定義を検索し、Token使用量を47%削減します。金融プラグイン(Moody's、MSCIなど)とChatGPT for Excelは、企業レベルの専門業務を狙っています。
🎯 モデル選択のヒント: 両者の強みはほぼ補完的です。APIYI apiyi.com を通じて1つのAPIキーでClaude Opus 4.6とGPT-5.4の両方を呼び出し、シナリオに応じて柔軟に切り替えることができます。
Claude Opus 4.6 vs GPT-5.4 ベンチマーク詳細分析
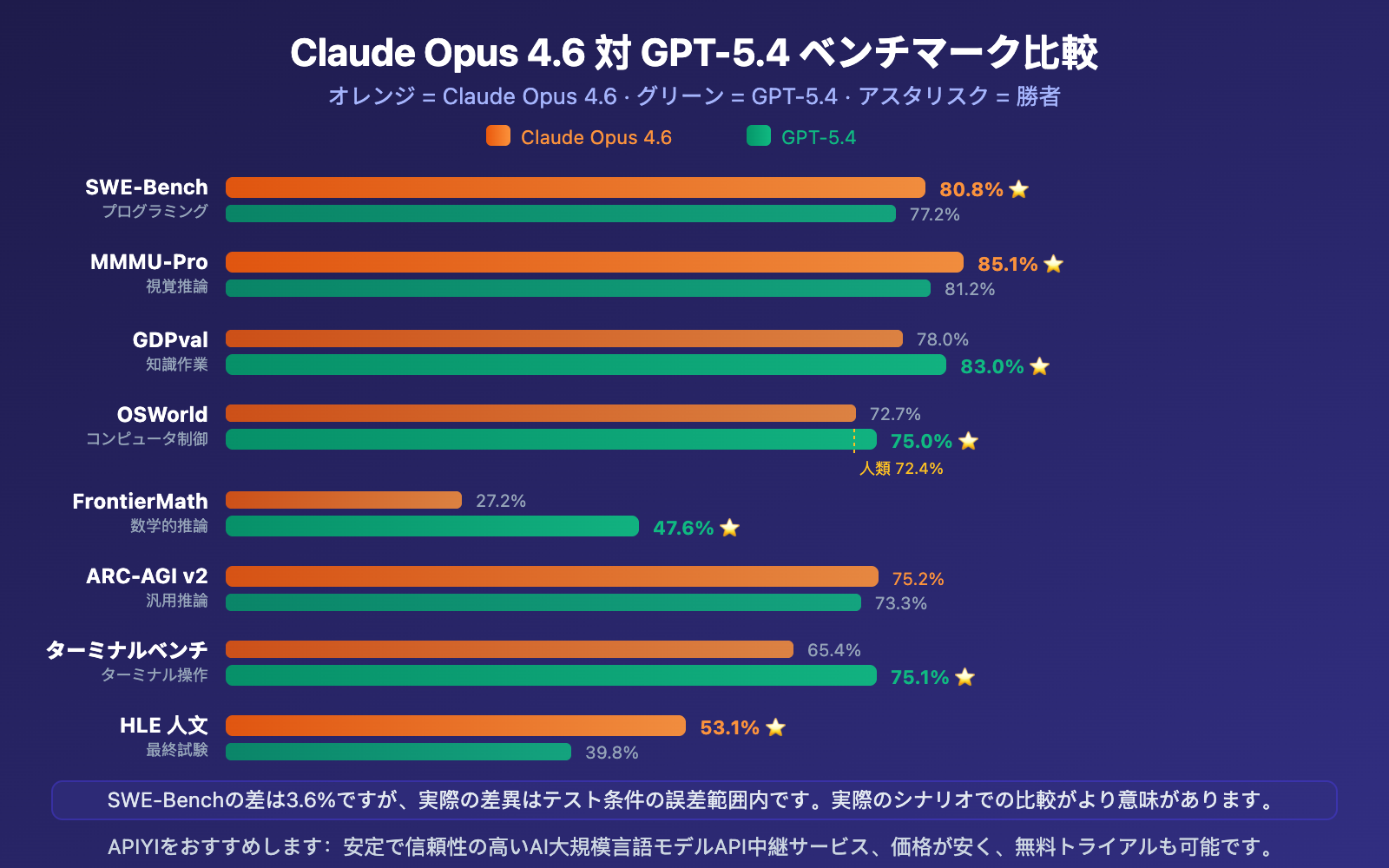
Claude Opus 4.6 vs GPT-5.4 完全ベンチマーク表
| ベンチマーク | Claude Opus 4.6 | GPT-5.4 | 差 | 勝者 |
|---|---|---|---|---|
| SWE-Bench Verified | 80.8% | 77.2% | +3.6% | Claude |
| SWE-Bench Pro (高難易度) | ~45.9% | 57.7% | +11.8% | GPT |
| MMMU-Pro 視覚推論 | 85.1% | 81.2% | +3.9% | Claude |
| GDPval 知識作業 | 78.0% | 83.0% | +5.0% | GPT |
| OSWorld コンピュータ操作 | 72.7% | 75.0% | +2.3% | GPT |
| FrontierMath 数学 | 27.2% | 47.6% | +20.4% | GPT |
| ARC-AGI v2 汎用推論 | 75.2% | 73.3% | +1.9% | Claude |
| Terminal-Bench ターミナル | 65.4% | 75.1% | +9.7% | GPT |
| Humanity's Last Exam | 53.1% | 39.8% | +13.3% | Claude |
| Tau2 Telecom | 99.3% | 98.9% | +0.4% | Claude |
| GPQA 大学院生推論 | 91.3% | 92.8% | +1.5% | GPT |
| BrowseComp ウェブ閲覧 | 84.0% | 82.7% | +1.3% | Claude |
特に指摘すべき点は:80.0%、80.6%、80.8%というSWE-Benchの差異は、実際にはテスト条件の誤差範囲内にあります。言い換えれば、標準化されたプログラミングベンチマークでは、両者は収束しつつあります。真の違いは、コード品質、アーキテクチャ理解、実際の開発体験に現れます。
🎯 実測アドバイス: ベンチマークはあくまで参考の出発点です。APIYI apiyi.com を通じて無料枠を取得し、ご自身のプロジェクトで両モデルの実際のパフォーマンスを比較することをお勧めします。これはどんなベンチマークよりも価値があります。
Claude Opus 4.6 vs GPT-5.4 独自能力比較
Claude Opus 4.6 独自の優位性
1. Agent Teams(エージェントチーム)
Claude Opus 4.6 が導入した Agent Teams は、現在の AI 分野で唯一無二の機能です。1つのメイン Claude インスタンス(Lead)が、複数の独立したサブエージェント(Teammates)を派生させることができ、各サブエージェントは完全に独立したコンテキストウィンドウを持ち、共有タスクリストとメッセージシステムを通じて並列で協業します。
深い研究タスクにおいて、このマルチエージェント技術は性能を約 15 パーセントポイント 向上させました。このアーキテクチャは、大規模なコードベースの並列リファクタリングに特に適しています。メインエージェントが計画を担当し、サブエージェントが異なるモジュールをそれぞれ処理します。
2. 適応的思考(Adaptive Thinking)
GPT-5.4 の手動5段階推論レベルとは異なり、Claude の適応的思考は、モデルが問題の複雑さを自動的に判断し、推論の深さを動的に割り当てることを可能にします。デフォルトの high レベルでは、Claude はほぼ常に思考連鎖(Chain of Thought)を有効化します。一方、単純な問題では自動的にスキップし、トークン使用量と遅延を節約します。
適応的思考は、インターリーブ思考(Interleaved Thinking)もサポートしています。これは、ツール呼び出しの間に思考を挟み込むもので、エージェント型のワークフローに特に効果的です。
GPT-5.4 独自の優位性
1. ネイティブなコンピュータ操作
GPT-5.4 は、OpenAI 初のネイティブなコンピュータ操作能力を内蔵した汎用モデルです。OSWorld ベンチマークで 75.0% を達成し、人間のベースライン 72.4% を直接上回りました。Playwright コードと直接的なキーボード・マウス命令の2つの方法で、ブラウザやデスクトップアプリケーションを操作できます。
2. ツール検索(Tool Search)
多数のツールを持つシステムでは、従来の方法ではすべてのツール定義を一度にモデルに送信する必要がありました。GPT-5.4 のツール検索機能により、モデルは必要に応じてツール定義を検索できるようになり、トークン使用量が 47% 削減され、精度は変わりません。
3. 金融業界への深い統合
ChatGPT for Excel/Google Sheets と Moody's/MSCI/FactSet データとの統合により、GPT-5.4 は金融分析分野で、Claude が現在匹敵できない生態系の優位性を形成しています。内部の投資銀行ベンチマークは 43.7% から 87.3% に向上しました。
🎯 API アクセス: Claude Opus 4.6 と GPT-5.4 はどちらも、APIYI apiyi.com の統一インターフェースを通じて呼び出すことができます。GPT-5.4 の価格設定は公式サイトと同期($2.50/$15.00)しており、100ドル以上チャージすると10%分が付与されます。
Claude Opus 4.6 vs GPT-5.4 シナリオ別選定ガイド

Claude Opus 4.6 vs GPT-5.4 API アクセス例
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# 複雑なコードリファクタリング → Claude Opus 4.6
refactor = client.chat.completions.create(
model="claude-opus-4-6",
messages=[{"role": "user", "content": "このモジュールの依存性注入をリファクタリングしてください"}]
)
# 超大規模プロジェクトのグローバル分析 → GPT-5.4
analysis = client.chat.completions.create(
model="gpt-5.4",
messages=[{"role": "user", "content": "プロジェクト全体のセキュリティ脆弱性を分析してください"}]
)
推奨: APIYI apiyi.com でアカウントを登録すれば、両方のフラッグシップモデルを同時に呼び出すことができます。GPT-5.4 の価格設定は公式サイトと同期しており、100ドル以上チャージすると10%分が付与されます。モデルの切り替えは、たった1つのパラメータを変更するだけです。
よくある質問
Q1: Claude Opus 4.6 と GPT-5.4、どちらがプログラミングに強いですか?
次元によります。標準的なプログラミングベンチマークである SWE-Bench では、Claude が 80.8% 対 77.2% でリードしており、コード品質やマルチファイルリファクタリング能力も優れています。しかし、GPT-5.4 は高難度の SWE-Bench Pro では 57.7% 対 ~45.9% で逆転し、ターミナル操作タスクでも大幅にリードしています(75.1% 対 65.4%)。ほとんどの開発者にとって、両者のプログラミング能力は収束しつつあります。
Q2: 価格差は大きいですか?どう選べばいいですか?
GPT-5.4 が全面的に安価です:入力 $2.50 vs $5.00/M(50%安)、出力 $15.00 vs $25.00/M(40%安)。コストが主な考慮事項であれば、GPT-5.4 が適しています。プロジェクトがコード品質やアーキテクチャ理解に対して極めて高い要求がある場合は、Claude のプレミアム価値は価値があります。シナリオに応じて APIYI apiyi.com を通じて両者を混合使用し、コストを最適化することをお勧めします。
Q3: 一つのプラットフォームで両方のモデルを同時に使うには?
APIYI apiyi.com でアカウント登録:
- 統一 APIキーを取得
base_urlをhttps://vip.apiyi.com/v1に設定- リファクタリングタスク:
model="claude-opus-4-6" - 大規模プロジェクト分析:
model="gpt-5.4" - 日常タスク:
model="gpt-5.3-chat-latest"(最もコスト効率が良い)
100米ドル以上のチャージで10%ボーナス、一つのアカウントで主要モデルをすべて呼び出せます。
まとめ
Claude Opus 4.6 vs GPT-5.4 の核心的な結論:
- プログラミングと視覚推論なら Claude: SWE-Bench 80.8%、MMMU-Pro 85.1% で業界最高、コード品質がよりクリーン、Agent Teams によるマルチエージェント協調は独自の強み
- 知識作業と自動化なら GPT: GDPval 83.0%、OSWorld 75.0% で人間を超越、1M コンテキストウィンドウが正式利用可能、API価格が40-50%安い
- 最も賢い戦略は組み合わせて使用: 両者の強み領域はほぼ補完的——リファクタリングは Claude、大規模プロジェクト分析と自動化は GPT、日常タスクは GPT-5.3 Instant で節約
SWE-Bench での 80.8% 対 77.2% の差は大きく見えないかもしれませんが、実際の開発では、Claude のアーキテクチャ理解力とコードの整然さの優位性は依然として明らかです。GPT-5.4 は 1M コンテキストウィンドウ、コンピュータ操作、そしてより低価格という別の次元で優位性を築いています。
APIYI apiyi.com を通じて両フラッグシップモデルに統一アクセスし、一つの APIキーですべてを呼び出し、100米ドル以上のチャージで10%ボーナスを得ることをお勧めします。
📚 参考資料
-
GPT-5.4 vs Claude Opus 4.6 プログラミング比較: 開発者視点での SWE-Bench、コード品質、Agent 能力分析
- リンク:
blog.getbind.co/gpt-5-4-vs-claude-opus-4-6-which-one-is-better-for-coding/ - 説明: プログラミング分野における最も詳細な比較分析。SWE-Bench Pro と Terminal-Bench のデータを含む。
- リンク:
-
GPT-5.4 vs Opus 4.6 vs Gemini 3.1 Pro 三強比較: 12項目のベンチマークによる全体的な分析
- リンク:
digitalapplied.com/blog/gpt-5-4-vs-opus-4-6-vs-gemini-3-1-pro-best-frontier-model - 説明: 価格設定、コンテキストウィンドウ、ベンチマークテスト、長所と短所を網羅。
- リンク:
-
Claude Opus 4.6 公式リリース発表: Agent Teams、適応的思考などの新機能詳細
- リンク:
anthropic.com/news/claude-opus-4-6 - 説明: Claude 独自の機能を理解するための第一級の情報源。
- リンク:
-
Claude Opus 4.6 適応的思考 API ドキュメント: 開発者向け統合ガイド
- リンク:
platform.claude.com/docs/en/build-with-claude/adaptive-thinking - 説明: 適応的思考の具体的な使用方法とパラメータ設定について。
- リンク:
著者: APIYI 技術チーム
技術交流: コメント欄での議論をお待ちしています。詳細な資料は APIYI のドキュメントセンター docs.apiyi.com をご覧ください。