智譜AIは2026年2月11日、現在最もパラメータ規模の大きいオープンソース大規模言語モデルの一つであるGLM-5を正式に発表しました。GLM-5は744BのMoE(混合エキスパート)アーキテクチャを採用しており、推論ごとに40Bのパラメータを有効化し、推論、コーディング、およびAgentタスクにおいてオープンソースモデルとして最高レベルに達しています。
コアバリュー: この記事を読むことで、GLM-5の技術アーキテクチャの原理、API呼び出し方法、Thinking推論モードの設定、そしてこの744Bオープンソース・フラッグシップモデルの価値を実際のプロジェクトで最大限に引き出す方法を習得できます。

GLM-5 主要パラメータ一覧
技術的な詳細に入る前に、GLM-5の主要なパラメータを確認しておきましょう。
| パラメータ | 数値 | 説明 |
|---|---|---|
| 総パラメータ数 | 744B (7440億) | 現在最大級のオープンソースモデルの一つ |
| 有効パラメータ数 | 40B (400億) | 推論時に実際に使用されるパラメータ |
| アーキテクチャ | MoE (混合エキスパート) | 256エキスパート、1トークンあたり8つを有効化 |
| コンテキストウィンドウ | 200,000 トークン | 超長文ドキュメントの処理に対応 |
| 最大出力 | 128,000 トークン | 長文生成のニーズに対応 |
| 事前学習データ | 28.5T トークン | 前世代から24%増加 |
| ライセンス | Apache-2.0 | 完全オープンソース、商用利用可能 |
| 学習ハードウェア | Huawei Ascendチップ | 完全国産の計算リソース、海外製に依存しない |
GLM-5の顕著な特徴の一つは、Huawei Ascend(華為昇騰)チップとMindSporeフレームワークに完全に基づき学習されている点であり、国産コンピューティングスタックの完全な検証を実現しています。これは国内の開発者にとって、技術スタックの自主制御における強力な選択肢がまた一つ増えたことを意味します。
GLMシリーズの進化
GLM-5は、智譜AIのGLMシリーズにおける第5世代製品であり、各世代で能力が飛躍的に向上しています。
| バージョン | 発表時期 | パラメータ規模 | 主な進展 |
|---|---|---|---|
| GLM-4 | 2024-01 | 非公開 | マルチモーダル基礎能力 |
| GLM-4.5 | 2025-03 | 355B (32B 有効) | MoEアーキテクチャの初導入 |
| GLM-4.5-X | 2025-06 | 同上 | 推論の強化、フラッグシップの位置付け |
| GLM-4.7 | 2025-10 | 非公開 | Thinking推論モード |
| GLM-4.7-FlashX | 2025-12 | 非公開 | 超低コスト・高速推論 |
| GLM-5 | 2026-02 | 744B (40B 有効) | Agent能力の飛躍、ハルシネーション率56%低減 |
GLM-4.5の355BからGLM-5の744Bへと、総パラメータ数は2倍以上に増加しました。有効パラメータ数も32Bから40Bへと25%向上し、事前学習データは23Tから28.5Tトークンへと増加しています。これらの数字の背景には、智譜AIによる計算リソース、データ、アルゴリズムの3つの次元における全面的な投資があります。
🚀 クイック体験: GLM-5はすでに APIYI(apiyi.com)で利用可能です。価格は公式サイトと同じですが、チャージ特典キャンペーンを利用すれば実質約20%オフで、この744Bフラッグシップモデルをいち早く体験したい開発者に最適です。
GLM-5 MoE アーキテクチャ技術解析
GLM-5 が MoE アーキテクチャを選択した理由
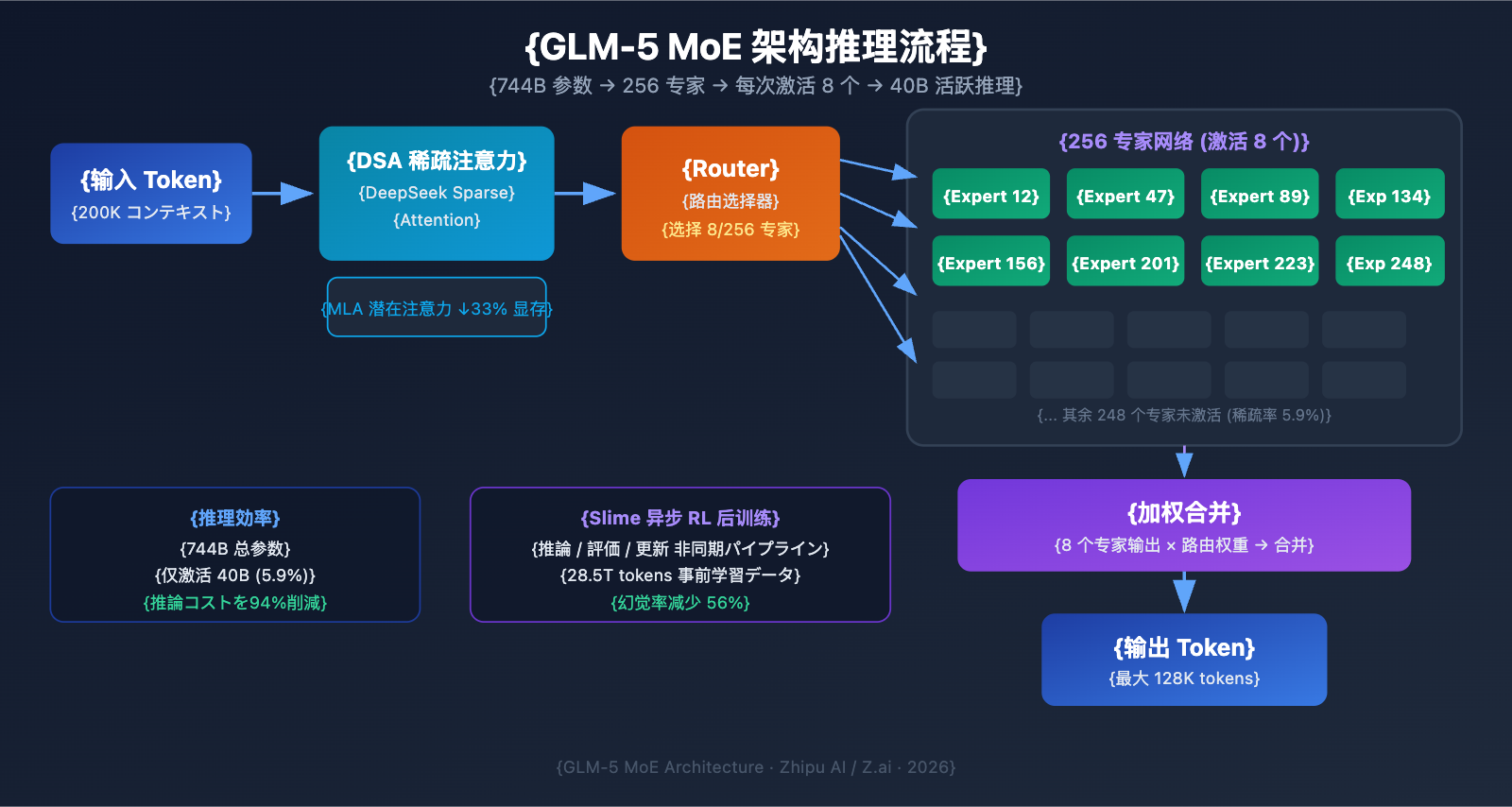
MoE(Mixture of Experts:混合エキスパート)は、現在の大規模言語モデルを拡張するための主流な技術ルートです。すべてのパラメータが推論ごとに参加する Dense アーキテクチャとは異なり、MoE アーキテクチャは各トークンを処理するためにエキスパートネットワークのごく一部のみをアクティブ化します。これにより、大規模言語モデルの知識容量を維持しながら、推論コストを大幅に削減できます。
GLM-5 の MoE アーキテクチャ設計には、以下の主要な特性があります。
| アーキテクチャ特性 | GLM-5 の実装 | 技術的価値 |
|---|---|---|
| エキスパート総数 | 256 個 | 知識容量が極めて大きい |
| トークンごとの起動数 | 8 個のエキスパート | 推論効率が高い |
| 疎性(スパース率) | 5.9% | パラメータのごく一部のみを使用 |
| アテンション機構 | DSA + MLA | デプロイコストの削減 |
| メモリ最適化 | MLA により 33% 削減 | ビデオメモリ使用量がさらに低い |
簡単に言えば、GLM-5 は 744B のパラメータを持っていますが、推論ごとにアクティブ化されるのは 40B(約 5.9%)のみです。これは、同規模の Dense モデルよりも推論コストがはるかに低く、同時に 744B パラメータに蓄えられた豊富な知識を活用できることを意味します。
GLM-5 の DeepSeek Sparse Attention (DSA)
GLM-5 は DeepSeek Sparse Attention(DSA)メカニズムを統合しています。この技術は、長いコンテキスト能力を維持しながら、デプロイコストを大幅に削減します。Multi-head Latent Attention(MLA)と組み合わせることで、GLM-5 は 200K トークンという超長文コンテキストウィンドウの下でも効率的に動作します。
具体的には以下の通りです:
- DSA (DeepSeek Sparse Attention): 疎なアテンションパターンを通じて、アテンション計算の複雑さを軽減します。従来のフルアテンション機構では 200K トークンを処理する際の計算量が膨大になりますが、DSA は重要なトークン位置を選択的に注目することで、情報の完全性を保ちつつ計算コストを抑えます。
- MLA (Multi-head Latent Attention): アテンションヘッドの KV キャッシュを潜在空間に圧縮し、メモリ使用量を約 33% 削減します。長いコンテキストのシナリオでは、KV キャッシュが通常ビデオメモリの主な消費源となりますが、MLA はこのボトルネックを効果的に緩和します。
これら 2 つの技術の組み合わせにより、744B 規模のモデルであっても、FP8 量子化を施せば 8 枚の GPU で実行可能となり、デプロイのハードルが大幅に下がりました。
GLM-5 の後学習:Slime 非同期 RL システム
GLM-5 は、「slime」と呼ばれる新しい非同期強化学習(RL)インフラストラクチャを後学習に採用しています。従来の RL トレーニングには、生成、評価、更新のステップ間に大量の待機時間が発生するという効率のボトルネックがありました。Slime はこれらのステップを非同期化することで、よりきめ細かな後学習の反復を実現し、トレーニングのスループットを大幅に向上させました。
従来の RL トレーニングフローでは、モデルが一連の推論を完了し、評価結果を待ち、その後にパラメータを更新するという 3 つのステップが直列に実行されていました。Slime はこれら 3 つのステップを独立した非同期パイプラインとして切り離し、推論、評価、更新を並列に行えるようにしたことで、トレーニング効率を劇的に高めました。
この技術改善は、GLM-5 のハルシネーション(幻覚)率に直接反映されており、前世代と比較して 56% 減少しました。より十分な後学習の反復により、モデルの事実の正確性が明らかに改善されています。
GLM-5 と Dense アーキテクチャの比較
MoE アーキテクチャの利点をよりよく理解するために、GLM-5 と、仮に同規模の Dense モデルが存在した場合を比較してみましょう。
| 比較項目 | GLM-5 (744B MoE) | 仮想 744B Dense | 実際の差異 |
|---|---|---|---|
| 推論ごとのパラメータ数 | 40B (5.9%) | 744B (100%) | MoE は 94% 削減 |
| 推論時のビデオメモリ要件 | 8x GPU (FP8) | 約 96x GPU | MoE が圧倒的に低い |
| 推論速度 | 比較的高速 | 極めて低速 | MoE は実用的なデプロイに最適 |
| 知識容量 | 744B の全知識 | 744B の全知識 | 同等 |
| 専門化能力 | 異なるエキスパートが特定タスクに特化 | 統一的に処理 | MoE の方がより精緻 |
| 学習コスト | 高いが制御可能 | 極めて高い | MoE の方がコストパフォーマンスに優れる |
MoE アーキテクチャの核心的な利点は、744B パラメータが持つ膨大な知識容量を維持しながら、わずか 40B パラメータ分の推論コストという高い効率性を手に入れたことにあります。これが、GLM-5 が最先端の性能を維持しつつ、同クラスのクローズドソースモデルをはるかに下回る価格設定を提供できる理由です。
GLM-5 API 呼び出しクイックスタート
GLM-5 API リクエストパラメータ詳細
コードを書く前に、GLM-5 の API パラメータ設定を確認しておきましょう。
| パラメータ | 型 | 必須 | デフォルト値 | 説明 |
|---|---|---|---|---|
model |
string | ✅ | – | "glm-5" に固定 |
messages |
array | ✅ | – | 標準的なチャット形式のメッセージ |
max_tokens |
int | ❌ | 4096 | 最大出力トークン数(上限 128K) |
temperature |
float | ❌ | 1.0 | サンプリング温度。低いほど確定的になります |
top_p |
float | ❌ | 1.0 | 核サンプリング(Nucleus Sampling)パラメータ |
stream |
bool | ❌ | false | ストリーミング出力を行うかどうか |
thinking |
object | ❌ | disabled | {"type": "enabled"} で推論モードを有効化 |
tools |
array | ❌ | – | Function Calling のツール定義 |
tool_choice |
string | ❌ | auto | ツールの選択戦略 |
GLM-5 のシンプルな呼び出し例
GLM-5 は OpenAI SDK のインターフェース形式と互換性があります。base_url と model パラメータを変更するだけで、すぐに導入可能です。
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 統合インターフェース
)
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "あなたは経験豊富な AI 技術エキスパートです"},
{"role": "user", "content": "MoE(混合エキスパート)アーキテクチャの仕組みと利点を説明してください"}
],
temperature=0.7,
max_tokens=4096
)
print(response.choices[0].message.content)
上記のコードが GLM-5 の最も基本的な呼び出し方法です。モデル ID に glm-5 を使用し、インターフェースは OpenAI の chat.completions 形式と完全に互換性があるため、既存プロジェクトからの移行は 2 つのパラメータを修正するだけで済みます。
GLM-5 Thinking 推論モード
GLM-5 は、DeepSeek R1 や Claude の拡張思考能力に似た「Thinking 推論モード」をサポートしています。これを有効にすると、モデルは回答前に内部的な連鎖思考(Chain-of-Thought)を行い、複雑な数学、論理、プログラミングの問題におけるパフォーマンスが大幅に向上します。
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 統合インターフェース
)
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "user", "content": "証明してください:すべての正の整数 n について、n^3 - n は 6 で割り切れる"}
],
extra_body={
"thinking": {"type": "enabled"}
},
temperature=1.0 # Thinking モードでは 1.0 を推奨
)
print(response.choices[0].message.content)
GLM-5 Thinking モードの利用推奨事項:
| 利用シーン | Thinking 有効化 | 推奨 temperature | 説明 |
|---|---|---|---|
| 数学的証明 / 競技問題 | ✅ 有効 | 1.0 | 深い推論が必要 |
| コードのデバッグ / アーキテクチャ設計 | ✅ 有効 | 1.0 | システム的な分析が必要 |
| 論理的推論 / 分析 | ✅ 有効 | 1.0 | 連鎖的な思考が必要 |
| 日常会話 / ライティング | ❌ 無効 | 0.5-0.7 | 複雑な推論は不要 |
| 情報抽出 / 要約 | ❌ 無効 | 0.3-0.5 | 安定した出力を重視 |
| クリエイティブな生成 | ❌ 無効 | 0.8-1.0 | 多様性が必要 |
GLM-5 ストリーミング出力
リアルタイムな対話が必要なシーンでは、GLM-5 のストリーミング出力を利用することで、ユーザーはモデルが生成を行う過程で結果を段階的に確認できます。
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
stream = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "user", "content": "Python でキャッシュ機能付きの HTTP クライアントを実装してください"}
],
stream=True,
temperature=0.6
)
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
GLM-5 Function Calling と Agent 構築
GLM-5 はネイティブで Function Calling をサポートしており、これは Agent システムを構築するための核となる能力です。GLM-5 は HLE w/ Tools において 50.4% という成績を収め、Claude Opus (43.4%) を上回りました。これは、ツール呼び出しやタスクオーケストレーションにおいて非常に優れたパフォーマンスを発揮することを示しています。
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
tools = [
{
"type": "function",
"function": {
"name": "search_documents",
"description": "ナレッジベース内の関連ドキュメントを検索する",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "検索キーワード"},
"top_k": {"type": "integer", "description": "返却する結果の数", "default": 5}
},
"required": ["query"]
}
}
},
{
"type": "function",
"function": {
"name": "execute_code",
"description": "サンドボックス環境で Python コードを実行する",
"parameters": {
"type": "object",
"properties": {
"code": {"type": "string", "description": "実行する Python コード"},
"timeout": {"type": "integer", "description": "タイムアウト時間(秒)", "default": 30}
},
"required": ["code"]
}
}
}
]
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "あなたはドキュメント検索とコード実行ができる AI アシスタントです"},
{"role": "user", "content": "GLM-5 の技術パラメータを調べてから、コードを使って性能比較図を描いてください"}
],
tools=tools,
tool_choice="auto"
)
# ツール呼び出しの処理
message = response.choices[0].message
if message.tool_calls:
for tool_call in message.tool_calls:
print(f"ツール呼び出し: {tool_call.function.name}")
print(f"パラメータ: {tool_call.function.arguments}")
cURL 呼び出し例を表示
curl https://api.apiyi.com/v1/chat/completions \
-H "Authorization: Bearer $API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "glm-5",
"messages": [
{"role": "system", "content": "あなたはシニアソフトウェアエンジニアです"},
{"role": "user", "content": "分散タスクスケジューリングシステムのアーキテクチャを設計してください"}
],
"max_tokens": 8192,
"temperature": 0.7,
"stream": true
}'
🎯 技術アドバイス: GLM-5 は OpenAI SDK 形式と互換性があるため、既存プロジェクトは
base_urlとmodelの 2 つのパラメータを変更するだけで移行できます。APIYI(apiyi.com)プラットフォーム経由で呼び出すことで、統合されたインターフェース管理やチャージ特典を利用できます。
GLM-5 Benchmark 性能実測
GLM-5 主要ベンチマークデータ
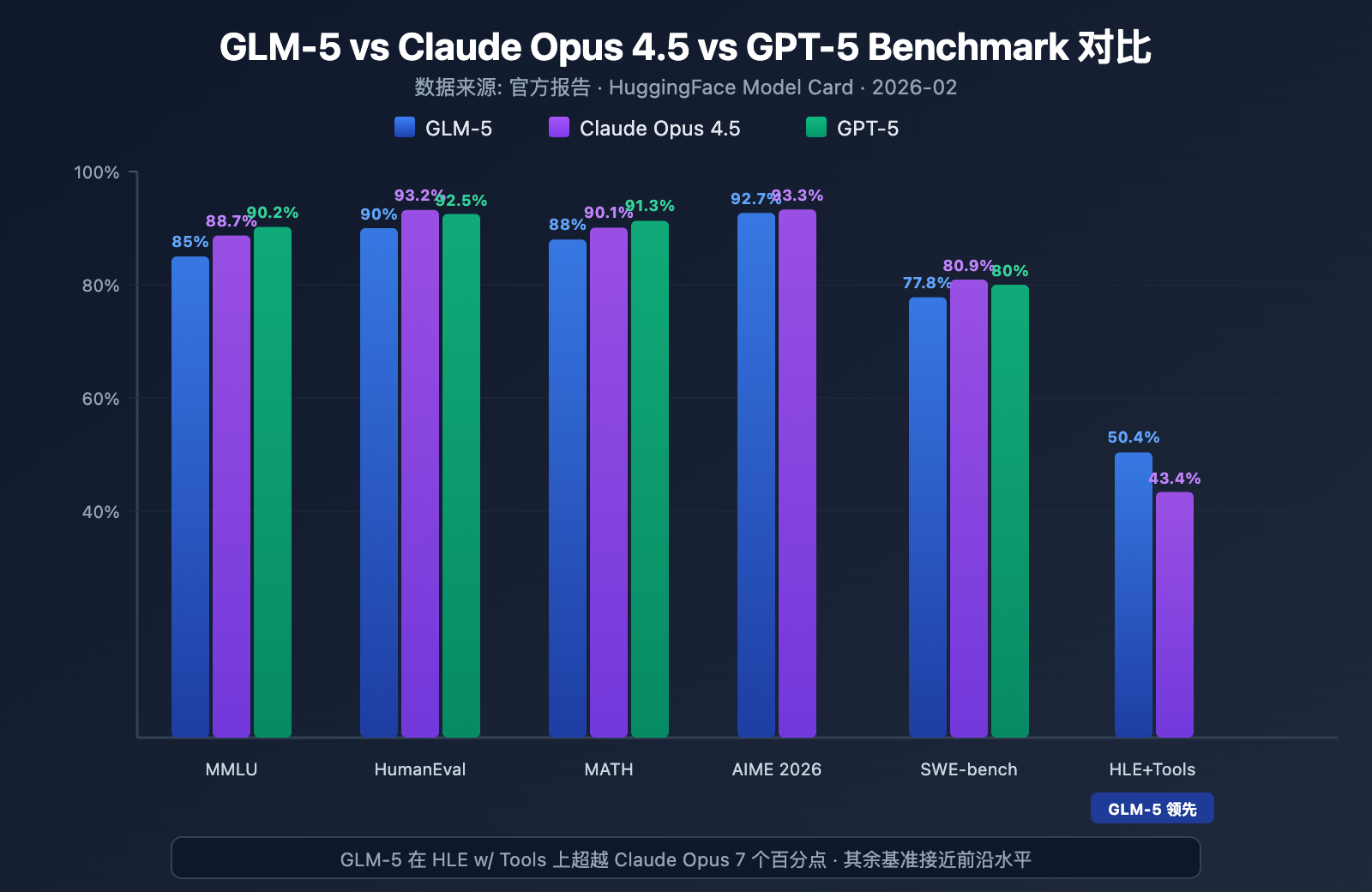
GLM-5 は、複数の主要なベンチマークにおいてオープンソースモデルとして最高水準のレベルを示しています。
| ベンチマーク | GLM-5 | Claude Opus 4.5 | GPT-5 | テスト内容 |
|---|---|---|---|---|
| MMLU | 85.0% | 88.7% | 90.2% | 57 分野の知識 |
| MMLU Pro | 70.4% | – | – | 強化版マルチドメイン |
| GPQA | 68.2% | 71.4% | 73.1% | 大学院レベルの科学 |
| HumanEval | 90.0% | 93.2% | 92.5% | Python プログラミング |
| MATH | 88.0% | 90.1% | 91.3% | 数学的推論 |
| GSM8k | 97.0% | 98.2% | 98.5% | 数学の文章題 |
| AIME 2026 I | 92.7% | 93.3% | – | 数学競技 |
| SWE-bench | 77.8% | 80.9% | 80.0% | 実際のソフトウェアエンジニアリング |
| HLE w/ Tools | 50.4% | 43.4% | – | ツール利用を伴う推論 |
| IFEval | 88.0% | – | – | 指示への追従性 |
| Terminal-Bench | 56.2% | 57.9% | – | ターミナル操作 |
GLM-5 性能分析:4 つの主な強み
ベンチマークデータから、いくつかの注目すべきポイントが見えてきます。
1. GLM-5 の Agent 能力:HLE w/ Tools でクローズドソースモデルを凌駕
GLM-5 は Humanity's Last Exam(ツール利用あり)において 50.4% の成績を収め、Claude Opus の 43.4% を上回り、Kimi K2.5 の 51.8% に次ぐ成績となりました。これは、プランニング、ツール呼び出し、反復的な解法が求められる複雑なタスクにおいて、GLM-5 が最先端モデルのレベルに達していることを示しています。
この結果は、GLM-5 の設計理念と一致しています。アーキテクチャからポストトレーニングに至るまで、Agent ワークフローに特化した最適化が行われています。AI Agent システムを構築したい開発者にとって、GLM-5 はオープンソースかつコストパフォーマンスの高い選択肢となります。
2. GLM-5 のコーディング能力:トップティアに到達
HumanEval 90%、SWE-bench Verified 77.8% という数値は、GLM-5 がコード生成や実際のソフトウェアエンジニアリングタスクにおいて、Claude Opus (80.9%) や GPT-5 (80.0%) のレベルに非常に近づいていることを示しています。オープンソースモデルとして SWE-bench 77.8% を達成したことは重要な突破口であり、GLM-5 が実際の GitHub の Issue を理解し、コードの問題を特定して、有効な修正を提案できるようになったことを意味します。
3. GLM-5 の数学的推論:最高水準(天井)に迫る
AIME 2026 I において、GLM-5 は 92.7% を記録し、Claude Opus にわずか 0.6 ポイント差まで迫りました。GSM8k の 97% も、中難易度の数学問題において GLM-5 が非常に信頼できることを示しています。MATH 88% という成績も同様にトップクラスです。
4. GLM-5 のハルシネーション抑制:大幅な低減
公式データによると、GLM-5 は前世代のバージョンと比較してハルシネーション(幻覚)率が 56% 減少しました。これは、Slime 非同期 RL システムによる、より十分なポストトレーニングの反復によって実現されました。高い正確性が求められる情報抽出、ドキュメント要約、ナレッジベースの Q&A シーンにおいて、ハルシネーション率の低下は出力品質の向上に直結します。
GLM-5 と同クラスのオープンソースモデルのポジショニング
現在のオープンソース大規模言語モデルの競争環境において、GLM-5 の立ち位置は明確です。
| モデル | パラメータ数 | アーキテクチャ | 主な強み | ライセンス |
|---|---|---|---|---|
| GLM-5 | 744B (40B アクティブ) | MoE | Agent + 低ハルシネーション | Apache-2.0 |
| DeepSeek V3 | 671B (37B アクティブ) | MoE | コスパ + 推論 | MIT |
| Llama 4 Maverick | 400B (17B アクティブ) | MoE | マルチモーダル + エコシステム | Llama License |
| Qwen 3 | 235B | Dense | 多言語 + ツール | Apache-2.0 |
GLM-5 の差別化要因は、主に 3 つの点に集約されます。Agent ワークフローの専門的な最適化(HLE w/ Tools でのリード)、極めて低いハルシネーション率(56% 削減)、そして中国国産の計算リソースによるトレーニングがもたらすサプライチェーンの安全性です。最先端のオープンソースモデルを国内でデプロイする必要がある企業にとって、GLM-5 は重点的に検討すべき選択肢です。
GLM-5 定価とコスト分析
GLM-5 公式価格
| 課金タイプ | Z.ai 公式価格 | OpenRouter 価格 | 説明 |
|---|---|---|---|
| 入力トークン | $1.00/M | $0.80/M | 100万入力トークンあたり |
| 出力トークン | $3.20/M | $2.56/M | 100万出力トークンあたり |
| キャッシュ入力 | $0.20/M | $0.16/M | キャッシュヒット時の入力価格 |
| キャッシュストレージ | 当面無料 | – | キャッシュデータのストレージ費用 |
GLM-5 と競合モデルの価格比較
GLM-5 の価格戦略は、特にクローズドソースの最先端モデルと比較して非常に競争力があります:
| モデル | 入力 ($/M) | 出力 ($/M) | GLM-5 に対する相対コスト | モデルのポジショニング |
|---|---|---|---|---|
| GLM-5 | $1.00 | $3.20 | 基準 | オープンソース・フラッグシップ |
| Claude Opus 4.6 | $5.00 | $25.00 | 約 5-8倍 | クローズドソース・フラッグシップ |
| GPT-5 | $1.25 | $10.00 | 約 1.3-3倍 | クローズドソース・フラッグシップ |
| DeepSeek V3 | $0.27 | $1.10 | 約 0.3倍 | オープンソース・高コスパ |
| GLM-4.7 | $0.60 | $2.20 | 約 0.6-0.7倍 | 前世代フラッグシップ |
| GLM-4.7-FlashX | $0.07 | $0.40 | 約 0.07-0.13倍 | 超低コスト |
価格面で見ると、GLM-5 は GPT-5 と DeepSeek V3 の中間に位置しています。大半のクローズドソース最先端モデルよりも大幅に安価ですが、軽量なオープンソースモデルよりは若干高価です。744B というパラメータ規模とオープンソース最強クラスのパフォーマンスを考慮すれば、この価格設定は妥当と言えるでしょう。
GLM 全シリーズの製品ラインナップと価格
GLM-5 が特定のユースケースに完全に合致しない場合、智譜(Zhipu AI)は選択可能な完全な製品ラインナップを提供しています:
| モデル | 入力 ($/M) | 出力 ($/M) | 適用シーン |
|---|---|---|---|
| GLM-5 | $1.00 | $3.20 | 複雑な推論、エージェント、長文読解 |
| GLM-5-Code | $1.20 | $5.00 | コード開発専用 |
| GLM-4.7 | $0.60 | $2.20 | 中程度の複雑さの汎用タスク |
| GLM-4.7-FlashX | $0.07 | $0.40 | 高頻度・低コストな呼び出し |
| GLM-4.5-Air | $0.20 | $1.10 | 軽量・バランス型 |
| GLM-4.7/4.5-Flash | 無料 | 無料 | 入門・体験および単純なタスク |
💰 コスト最適化: GLM-5 はすでに APIYI(apiyi.com)で利用可能になっており、価格は Z.ai 公式と同等です。プラットフォームのチャージ特典キャンペーンを利用することで、実際の使用コストを公式価格の約 20% オフまで抑えることができ、継続的な呼び出しニーズがあるチームや開発者に適しています。
GLM-5 適用シーンと選定アドバイス
GLM-5 はどのようなシーンに適しているか
GLM-5 の技術的特徴とベンチマーク結果に基づき、具体的な推奨シーンを以下に挙げます:
強く推奨されるシーン:
- エージェント・ワークフロー: GLM-5 は長期サイクルのエージェントタスク向けに設計されており、HLE w/ Tools で 50.4% と Claude Opus を上回っています。自律的な計画策定やツール呼び出しを行うエージェントシステムの構築に最適です。
- コードエンジニアリング・タスク: HumanEval 90%、SWE-bench 77.8% を記録しており、コード生成、バグ修正、コードレビュー、アーキテクチャ設計に長けています。
- 数学・科学的推論: AIME 92.7%、MATH 88% と、数学的証明、公式の導出、科学計算に適しています。
- 超長文ドキュメント分析: 200K のコンテキストウィンドウにより、完全なコードベース、技術文書、法的契約書などの超長文テキストを処理できます。
- 低ハルシネーションな Q&A: ハルシネーション率が 56% 減少しており、ナレッジベースの Q&A やドキュメント要約など、高い正確性が求められるシーンに適しています。
他のソリューションを検討すべきシーン:
- マルチモーダル・タスク: GLM-5 本体はテキストのみをサポートしています。画像理解が必要な場合は、GLM-4.6V などのビジョンモデルを選択してください。
- 極めて低いレイテンシ: 744B MoE モデルの推論速度は小型モデルには及びません。高頻度かつ低レイテンシが求められるシーンでは、GLM-4.7-FlashX の使用をお勧めします。
- 超低コストなバッチ処理: 大量のテキスト処理で品質への要求がそれほど高くない場合、DeepSeek V3 や GLM-4.7-FlashX の方がコストを抑えられます。
GLM-5 と GLM-4.7 の選定比較
| 比較項目 | GLM-5 | GLM-4.7 | 選定アドバイス |
|---|---|---|---|
| パラメータ規模 | 744B (アクティブ 40B) | 非公開 | GLM-5 の方が大規模 |
| 推論能力 | AIME 92.7% | ~85% | 複雑な推論なら GLM-5 |
| エージェント能力 | HLE w/ Tools 50.4% | ~38% | エージェントタスクなら GLM-5 |
| コーディング能力 | HumanEval 90% | ~85% | コード開発なら GLM-5 |
| ハルシネーション制御 | 56% 減少 | 基準 | 高い正確性なら GLM-5 |
| 入力価格 | $1.00/M | $0.60/M | コスト重視なら GLM-4.7 |
| 出力価格 | $3.20/M | $2.20/M | コスト重視なら GLM-4.7 |
| コンテキスト長 | 200K | 128K+ | 長文ドキュメントなら GLM-5 |
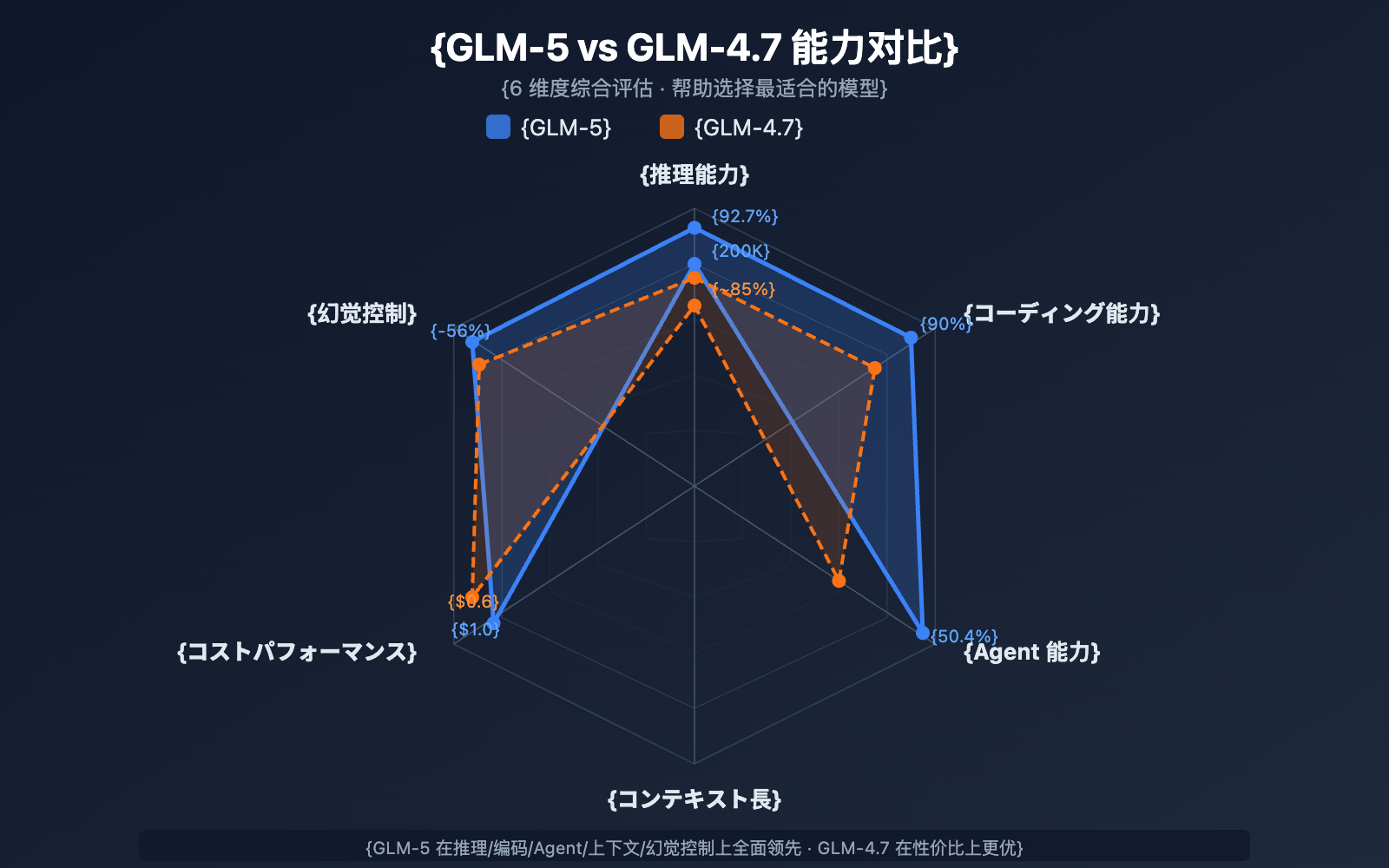
💡 選定アドバイス: プロジェクトでトップクラスの推論能力、エージェント・ワークフロー、または超長文コンテキスト処理が必要な場合は、GLM-5 が最適な選択です。予算が限られており、タスクの複雑さが中程度であれば、GLM-4.7 も優れたコストパフォーマンスを発揮します。どちらのモデルも APIYI(apiyi.com)プラットフォームを通じて呼び出すことができ、いつでも簡単に切り替えてテストすることが可能です。
GLM-5 API 利用に関するよくある質問
Q1: GLM-5 と GLM-5-Code の違いは何ですか?
GLM-5 は汎用フラッグシップモデル(入力 $1.00/M、出力 $3.20/M)で、あらゆるテキストタスクに適しています。一方、GLM-5-Code はコード特化の強化版(入力 $1.20/M、出力 $5.00/M)で、コード生成、デバッグ、エンジニアリングタスク向けにさらなる最適化が施されています。主な利用シーンがコード開発であれば、GLM-5-Code を試す価値があります。どちらのモデルも、統一された OpenAI 互換インターフェースを通じて呼び出すことが可能です。
Q2: GLM-5 の Thinking モードは出力速度に影響しますか?
はい、影響します。Thinking モードでは、GLM-5 は最終的な回答を出力する前に内部的な推論チェーンを生成するため、最初のトークンまでの遅延(TTFT)が増加します。単純な質問の場合は、より速いレスポンスを得るために Thinking モードをオフにすることをお勧めします。複雑な数学、プログラミング、論理問題については、速度は少し落ちますが、正解率が大幅に向上するため、オンにすることをお勧めします。
Q3: GPT-4 や Claude から GLM-5 に移行する場合、どのコードを修正する必要がありますか?
移行は非常に簡単で、以下の 2 つのパラメータを変更するだけです:
base_urlを APIYI のインターフェースアドレスhttps://api.apiyi.com/v1に変更するmodelパラメータを"glm-5"に変更する
GLM-5 は、system/user/assistant ロール、ストリーミング出力、Function Calling 機能などを含め、OpenAI SDK の chat.completions インターフェース形式と完全に互換性があります。統一された API 転送プラットフォームを経由することで、同じ API Key のまま異なるベンダーのモデルを切り替えて呼び出すことができるため、A/B テストを行う際にも非常に便利です。
Q4: GLM-5 は画像入力に対応していますか?
対応していません。GLM-5 本体は純粋なテキストモデルであり、画像、音声、動画の入力には対応していません。画像理解能力が必要な場合は、智譜(Zhipu AI)の GLM-4.6V や GLM-4.5V などのビジョン系モデルをご利用ください。
Q5: GLM-5 のコンテキストキャッシュ機能はどのように使いますか?
GLM-5 はコンテキストキャッシュ(Context Caching)をサポートしています。キャッシュされた入力の価格はわずか $0.20/M で、通常の入力の 5 分の 1 です。長い対話や、同じプレフィックス(接頭辞)を繰り返し処理する必要があるシーンでは、キャッシュ機能によってコストを大幅に削減できます。キャッシュストレージは現在、一時的に無料で提供されています。マルチターンの対話では、システムが重複するコンテキストプレフィックスを自動的に識別してキャッシュします。
Q6: GLM-5 の最大出力長はどのくらいですか?
GLM-5 は最大 128,000 トークンの出力長をサポートしています。ほとんどのシーンでは、デフォルトの 4096 トークンで十分です。長いテキスト(完全な技術ドキュメントや大規模なコードブロックなど)を生成する必要がある場合は、max_tokens パラメータで調整可能です。ただし、出力が長くなるほど、トークンの消費量と待ち時間が増加することに注意してください。
GLM-5 API 利用のベストプラクティス
実際に GLM-5 を使用する際、以下の実践的な経験を取り入れることで、より良い効果を得ることができます。
GLM-5 システムプロンプトの最適化
GLM-5 はシステムプロンプト(system prompt)に対する応答品質が非常に高いため、適切に設計することで出力の質を大幅に向上させることができます。
# 推奨:明確な役割定義 + 出力形式の要求
messages = [
{
"role": "system",
"content": """あなたは経験豊富な分散システムアーキテクトです。
以下のルールに従ってください:
1. 回答は構造化し、Markdown形式を使用すること
2. 抽象的な話ではなく、具体的な技術案を提示すること
3. コードが含まれる場合は、実行可能なサンプルを提供すること
4. 適宜、潜在的なリスクや注意事項を明記すること"""
},
{
"role": "user",
"content": "百万級の同時実行をサポートするメッセージキューシステムを設計してください"
}
]
GLM-5 temperature 調整ガイド
タスクによって temperature への感度は異なります。以下は実測に基づく推奨値です:
- temperature 0.1-0.3: コード生成、データ抽出、フォーマット変換など、正確な出力が求められるタスク
- temperature 0.5-0.7: 技術ドキュメント、Q&A、要約など、安定しつつもある程度の表現の柔軟性が必要なタスク
- temperature 0.8-1.0: クリエイティブライティング、ブレインストーミングなど、多様性が求められるタスク
- temperature 1.0 (Thinking モード): 数学的な推論、複雑なプログラミングなどの深い推論タスク
GLM-5 長文コンテキスト処理のコツ
GLM-5 は 200K トークンのコンテキストウィンドウをサポートしていますが、実運用では以下の点に注意してください:
- 重要な情報を前方に配置: 最も重要なコンテキストは、プロンプトの末尾ではなく冒頭に配置してください。
- セグメント処理: 100K トークンを超えるドキュメントは、より安定した出力を得るために、セグメントごとに処理してから統合することをお勧めします。
- キャッシュの活用: マルチターンの対話では、同じプレフィックス内容は自動的にキャッシュされます。キャッシュ入力の価格はわずか $0.20/M です。
- 出力長の制御: 長いコンテキストを入力する際は、
max_tokensを適切に設定し、出力が長くなりすぎて不要なコストが発生するのを避けてください。
GLM-5 ローカルデプロイメント・リファレンス
自社のインフラストラクチャに GLM-5 をデプロイする必要がある場合、主なデプロイ方法は以下の通りです。
| デプロイ方法 | 推奨ハードウェア | 精度 | 特徴 |
|---|---|---|---|
| vLLM | 8x A100/H100 | FP8 | 主要な推論フレームワーク、投機的デコードをサポート |
| SGLang | 8x H100/B200 | FP8 | 高性能推論、Blackwell GPU 最適化 |
| xLLM | Huawei Ascend NPU | BF16/FP8 | 中国国産演算リソースへの適応 |
| KTransformers | コンシューマー向け GPU | 量子化 | GPU 加速推論 |
| Ollama | コンシューマー向けハードウェア | 量子化 | 最も簡単なローカル体験 |
GLM-5 は BF16 全精度と FP8 量子化の 2 種類の重み形式を提供しており、HuggingFace (huggingface.co/zai-org/GLM-5) または ModelScope からダウンロード可能です。FP8 量子化バージョンは、大部分の性能を維持しつつ、ビデオメモリ(VRAM)の需要を大幅に削減しています。
GLM-5 のデプロイに必要な主要構成:
- テンソル並列 (Tensor Parallel): 8 並列 (tensor-parallel-size 8)
- ビデオメモリ利用率: 0.85 を推奨
- ツール呼び出しパーサー: glm47
- 推論パーサー: glm45
- 投機的デコード: MTP および EAGLE の 2 方式をサポート
ほとんどの開発者にとって、API 経由での呼び出しが最も効率的です。デプロイや運用のコストを省き、アプリケーション開発に集中できます。プライベートデプロイが必要なケースについては、公式ドキュメント(
github.com/zai-org/GLM-5)をご参照ください。
GLM-5 API 利用のまとめ
GLM-5 コア能力クイックチェック
| 能力次元 | GLM-5 のパフォーマンス | 適用シーン |
|---|---|---|
| 推論 | AIME 92.7%, MATH 88% | 数学的証明、科学的推論、論理分析 |
| コーディング | HumanEval 90%, SWE-bench 77.8% | コード生成、バグ修正、アーキテクチャ設計 |
| Agent | HLE w/ Tools 50.4% | ツール呼び出し、タスクプランニング、自律実行 |
| 知識 | MMLU 85%, GPQA 68.2% | 学術的な質疑応答、技術コンサルティング、知識抽出 |
| 指示遵守 | IFEval 88% | フォーマット出力、構造化生成、ルール遵守 |
| 正確性 | ハルシネーション率 56% 減少 | ドキュメント要約、ファクトチェック、情報抽出 |
GLM-5 オープンソースエコシステムの価値
GLM-5 は Apache-2.0 ライセンスを採用してオープンソース化されています。これは以下のことを意味します:
- 商用利用の自由: 企業はライセンス料を支払うことなく、無料で使用、修正、配布が可能です。
- 微調整(ファインチューニング): GLM-5 をベースに特定ドメインの微調整を行い、業界専用モデルを構築できます。
- プライベートデプロイ: 機密データを社内ネットワークから出さずに運用でき、金融、医療、政府などのコンプライアンス要件を満たせます。
- コミュニティエコシステム: HuggingFace 上にはすでに 11 以上の量子化バリエーションと 7 以上の微調整バージョンが存在し、エコシステムは拡大し続けています。
GLM-5 は Zhipu AI の最新フラッグシップモデルとして、オープンソース大規模言語モデルの分野で新たなベンチマークを確立しました:
- 744B MoE アーキテクチャ: 256 エキスパートシステムを採用し、推論ごとに 40B パラメータをアクティブ化。モデル容量と推論効率の優れたバランスを実現しています。
- オープンソース最強の Agent: HLE w/ Tools で 50.4% を記録し Claude Opus を凌駕。長期サイクルの Agent ワークフロー向けに設計されています。
- 完全国産演算リソースでの訓練: 10 万枚の Huawei Ascend チップを使用して訓練され、中国国産コンピューティングスタックによる最先端モデルの訓練能力を証明しました。
- 高いコストパフォーマンス: 入力 $1/M、出力 $3.2/M と、同クラスのクローズドソースモデルを大きく下回る価格設定。オープンソースコミュニティで自由にデプロイや微調整が可能です。
- 200K の超長文コンテキスト: コードベース全体や大規模な技術文書の一括処理をサポートし、最大出力は 128K トークンに達します。
- 56% の低ハルシネーション: Slime 非同期 RL(強化学習)ポストトレーニングにより、事実の正確性が大幅に向上しました。
APIYI (apiyi.com) を通じて GLM-5 の各機能を素早く体験することをお勧めします。プラットフォームの価格は公式と同一ですが、チャージ特典キャンペーンにより実質約 20% オフでご利用いただけます。
本記事は APIYI Team 技術チームによって執筆されました。AI モデルの利用ガイドに関する詳細は、APIYI (apiyi.com) ヘルプセンターをご覧ください。