“gemini-3.1-flash-lite-image到底支不支持推理模式?”是最近在 API 调用群里被问得最多的问题之一。答案是肯定的,而且这不是猜测——我们结合 Google 官方文档,通过 APIYI 网关做了三组对照实验,拿到了真实的 token 消耗和延迟数据。本文将从参数结构、实测数据、计费规则三个角度,把 thinkingLevel 这个开关讲透。
核心价值: 读完本文,你会明确 gemini-3.1-flash-lite-image 的推理模式怎么开、开了之后多花多少 token、以及什么场景值得为这份延迟买单。

gemini-3.1-flash-lite-image 推理模式核心结论
先给结论,再讲细节。Google official documentation dengan jelas menyebutkan bahwa melalui gemini-3.1-flash-image dan gemini-3.1-flash-lite-image, developer bisa mengontrol seberapa besar porsi “pemikiran” yang dipakai model. Artinya, flash-lite di level ini juga punya kemampuan inferensi bawaan, bukan cuma model flagship yang memilikinya. Tapi tidak semua model gambar mendukung parameter ini; tabel di bawah menunjukkan perbandingan dukungan pada tiga model Gemini image yang umum dipakai.
| Model | Apakah mendukung thinkingLevel | Level yang bisa diatur | Default | Catatan |
|---|---|---|---|---|
| gemini-3.1-flash-image | ✅ Didukung | minimal / high | minimal | Dicantumkan jelas di dokumentasi resmi |
| gemini-3.1-flash-lite-image | ✅ Didukung | minimal / high | minimal | Memakai thinkingConfig yang sama dengan flash-image |
| gemini-3-pro-image | ⚠️ Parameter tidak efektif | Tetap, tidak bisa diatur | Dikunci internal | Saat high dikirim tidak error, tapi hasilnya tidak berubah |
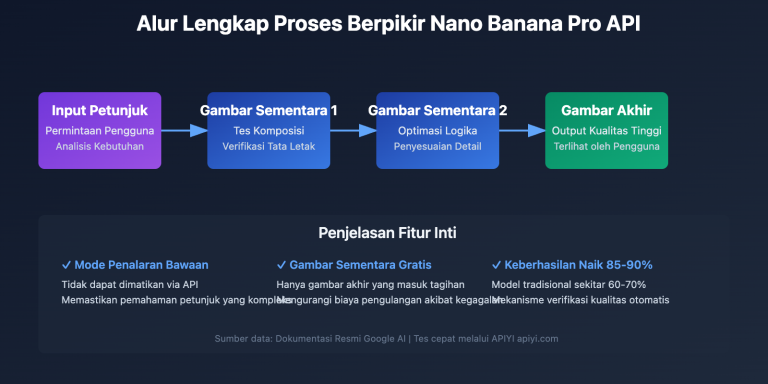
Perlu dicatat, thinkingLevel hanya punya dua pilihan, bukan budget berpikir yang bisa diatur secara kontinu seperti pada model teks. Di dokumen resmi disebutkan bahwa “minimal” tidak berarti model sama sekali tidak berpikir; jadi meskipun memakai default, model tetap melakukan inferensi dasar, hanya saja tidak sampai melakukan verifikasi komposisi berulang seperti pada level high.
Ini juga jadi sinyal penting di industri. Pada generasi model pembuatan gambar sebelumnya, entah itu nano banana maupun flash-image versi awal, API resmi belum pernah membuka parameter seperti tingkat pemikiran. Modelnya entah menghasilkan gambar dengan strategi tetap, atau sepenuhnya mengandalkan prompt engineering untuk menutup kekurangan komposisi. Di generasi 3.1 ini, Google membuka mekanisme inferensi “rencanakan dulu, baru hasilkan” ke keluarga flash. Intinya, pendekatan berpikir yang sebelumnya sudah teruji di model teks, kini dipindahkan ke skenario pembuatan gambar. Memahami konteks ini membantu kita menilai apakah vendor lain nantinya akan menempuh arah yang sama.
🎯 Saran teknis: Kalau kamu sedang memanggil model Gemini image series lewat APIYI apiyi.com, sebaiknya mulai dulu dari level minimal bawaan untuk memastikan alur bisnis berjalan, lalu baru pindah ke high kalau kualitas gambar memang perlu ditingkatkan. Platform ini menyediakan antarmuka seragam, jadi gemini-3.1-flash-image, flash-lite-image, dan pro-image bisa dipanggil dengan kode yang sama, sehingga enak untuk A/B test.
Penjelasan detail parameter thinkingLevel dan cara pemanggilannya
thinkingLevel bukan parameter mandiri, melainkan objek thinkingConfig yang berada di bawah generationConfig, dan digunakan bersama includeThoughts. includeThoughts menentukan apakah ringkasan pemikiran model dikembalikan ke pemanggil, sedangkan thinkingLevel menentukan “intensitas” berpikirnya. Keduanya adalah dua toggle yang terpisah, jadi jangan dicampuradukkan.
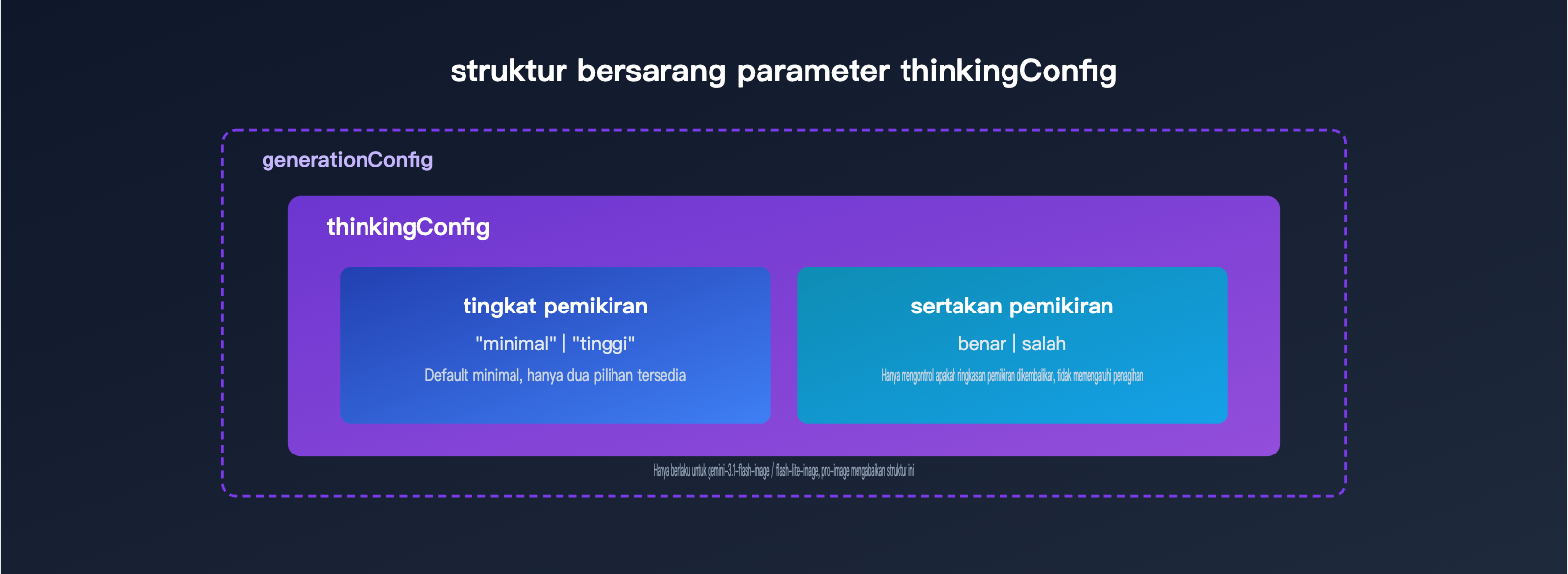
Tabel berikut merangkum tipe dan rentang nilai dua field penting di dalam objek thinkingConfig.
| Field | Tipe | Nilai yang bisa dipilih | Default | Fungsi |
|---|---|---|---|---|
| thinkingLevel | string enum | minimal / high |
minimal |
Mengontrol intensitas penalaran model, hanya berlaku untuk model gambar seri flash |
| includeThoughts | boolean | true / false |
false |
Apakah ringkasan proses berpikir dikembalikan di respons, tidak memengaruhi biaya |
Saat pemanggilan nyata, struktur penulisan di tiga bahasa utama sebenarnya sama saja: semuanya menaruh objek thinkingConfig ke dalam config. Contoh dengan Python:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # lewat gateway terpadu APIYI
)
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-image",
messages=[{"role": "user", "content": "画一只在雪山下喝咖啡的猫"}],
extra_body={
"thinkingConfig": {
"thinkingLevel": "high",
"includeThoughts": True
}
}
)
print(response.choices[0].message.content)
Lihat contoh lengkap pemanggilan REST native
{
"contents": [{"parts": [{"text": "画一只在雪山下喝咖啡的猫"}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"thinkingConfig": {
"thinkingLevel": "high",
"includeThoughts": true
}
}
}
Struktur penulisan JavaScript SDK juga sama, hanya saja format snake dari REST diubah ke camelCase pada objek thinkingConfig, sementara nama field lainnya tetap sama. Logika pemanggilan di tiga bahasa ini tidak berbeda secara mendasar, jadi cukup ingat satu aturan: “thinkingConfig hanya ditempel di bawah generationConfig”.
Ada satu detail yang mudah jadi jebakan: nilai thinkingLevel adalah enum string yang sensitif terhadap huruf besar/kecil. Di contoh resmi pernah muncul dua penulisan, "High" dan "high", yang tercampur. Dari pengujian, keduanya sama-sama dikenali dan bekerja lewat gateway, tetapi supaya tidak bergantung pada perilaku kompatibilitas yang belum didokumentasikan, sebaiknya di kode bisnis selalu pakai huruf kecil "high" dan "minimal". Dengan begitu, kalau nanti upstream memperketat validasi huruf besar/kecil, call di produksi tetap aman.
Saran: lewat APIYI apiyi.com, Anda bisa dapat kuota uji gratis dan langsung memverifikasi apakah parameter thinkingConfig diteruskan dengan benar di sisi gateway, jauh lebih praktis daripada harus minta official key dulu.
Data pengujian APIYI: dampak nyata thinkingLevel terhadap token dan latensi
Dokumentasi parameter, sejelas apa pun, tetap kalah jelas dibanding hasil pengujian langsung. Kami memakai prompt yang sama, untuk pembuatan gambar resolusi 1K, lalu menguji lewat gateway APIYI pada tiga skenario: gemini-3.1-flash-image di mode minimal, gemini-3.1-flash-image di mode high, dan gemini-3-pro-image yang dipaksa menerima parameter high.
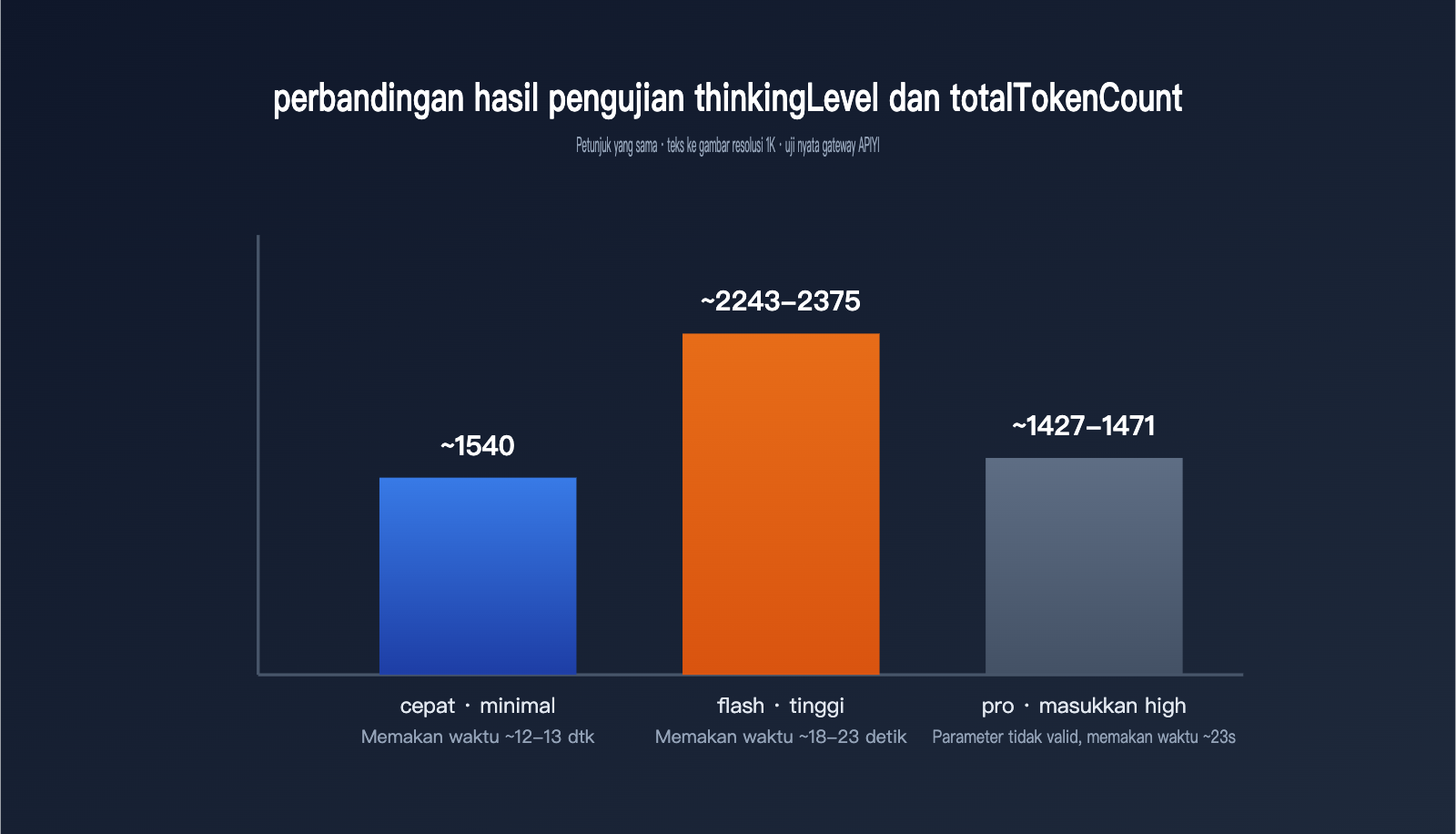
| Model / Setelan | thoughtsTokenCount | token gambar | totalTokenCount | waktu |
|---|---|---|---|---|
| gemini-3.1-flash-image · minimal (default) | tidak ada field ini | 1120 | sekitar 1540 | sekitar 12–13 detik |
| gemini-3.1-flash-image · high | 700–792 | 1120 | sekitar 2243–2375 | sekitar 18–23 detik |
| gemini-3-pro-image · dipaksa high | 181–214 (tidak berbeda dari default) | 1120 | sekitar 1427–1471 | sekitar 23 detik |
Dari data ini ada tiga pola penting. Pertama, begitu thinkingLevel diubah ke high, thoughtsTokenCount naik dari default 0—bahkan di respons field ini kadang tidak muncul sama sekali—ke kisaran 700–800, total token naik hampir 50%, dan latensi respons juga melambat dari 12–13 detik menjadi 18–23 detik. Artinya, proses berpikir memang butuh biaya dan waktu nyata.
Kedua, baik minimal maupun high, token output gambar tetap 1120. Ini menunjukkan bahwa thinkingLevel hanya memengaruhi “cara model berpikir”, bukan resolusi output atau biaya gambar itu sendiri.
Ketiga, saat parameter high dikirim ke gemini-3-pro-image, tidak ada error, tetapi token berpikirnya 181–214 dan praktis sama seperti default. Ini menguatkan penjelasan di dokumentasi resmi bahwa pro-image punya perilaku berpikir yang tetap dan tidak mendukung pengaturan dari luar.
Jadi, kalau logika bisnis Anda memakai thinkingConfig yang sama dan mengirimkannya sekaligus ke model flash, flash-lite, dan pro, model pro-image akan diam-diam mengabaikan parameter itu. Tidak akan error, tetapi juga tidak akan benar-benar menyesuaikan intensitas berpikir seperti yang Anda harapkan.
Perlu dicatat juga, data di atas bukan hasil satu kali pengukuran, melainkan rentang yang diambil dari beberapa permintaan berulang dengan prompt yang sama pada tiap setelan. Itu sebabnya nilai thoughtsTokenCount di mode high muncul sebagai 700–792, bukan angka tunggal. Tugas yang melibatkan pemikiran memang punya sedikit randomisasi; jalur inferensi menengah yang dihasilkan model tidak selalu sama di setiap percobaan, sehingga konsumsi token juga bisa sedikit naik-turun. Tapi secara umum skala dan tren latensinya stabil dan bisa direproduksi, jadi tidak akan muncul kasus aneh seperti mode high malah lebih cepat dari minimal, atau token berpikir membengkak sampai ribuan.
Token pemikiran dan aturan penagihan pada model gambar
Banyak developer saat pertama kali melihat field thoughtsTokenCount akan refleks membandingkannya dengan biaya berpikir pada model teks. Padahal, mekanisme berpikir pada model gambar sebenarnya dibagi jadi dua bagian penagihan, dan memahami ini penting banget untuk kontrol biaya.
| Dimensi | Pemikiran model teks | Pemikiran model gambar |
|---|---|---|
| Bentuk hasil pemikiran | Rantai penalaran dalam teks murni | Ringkasan teks + maksimal dua sketsa komposisi sementara |
| Skala token teks pemikiran | Bisa mencapai ribuan | Paket Pro maksimal 400, paket Flash high sekitar 700-800 |
| Field utama penanggung biaya | thoughtsTokenCount | Sketsa dihitung ke candidatesTokenCount, ditagih sebagai part gambar biasa |
| Standar biaya per sketsa | Tidak berlaku | Resolusi 1K sekitar 1120 token, setara sekitar 0.0336 dolar per gambar |
| Pengaruh includeThoughts ke penagihan | Tidak berpengaruh, tagihan tetap | Tidak berpengaruh, tagihan tetap |
Dokumentasi resmi menegaskan bahwa, baik includeThoughts diset true maupun false, token yang dihasilkan dari proses berpikir tetap akan ditagihkan seperti biasa. Ini juga terkonfirmasi dari hasil uji coba kami — saat includeThoughts diaktifkan, struktur respons dan total tagihan tidak berubah apa pun, hanya ada tambahan potongan ringkasan pemikiran yang bisa dipakai untuk debugging. Dengan kata lain, includeThoughts itu cuma sakelar “mau lihat atau tidak”, bukan “mau bayar atau tidak”. Detail ini sering banget disalahpahami.
Yang lebih perlu diperhatikan, porsi biaya terbesar pada model gambar bukan ada di field thoughtsTokenCount, melainkan pada gambar komposisi sementara yang dibuat selama proses inferensi. Dokumentasi resmi menyebutkan bahwa model bisa menghasilkan maksimal dua gambar sementara saat tahap berpikir untuk menguji komposisi dan kewajaran logika. Sketsa ini akan dikembalikan sebagai part gambar biasa dan dihitung ke candidatesTokenCount, lalu ditagihkan dengan harga standar output gambar. Artinya, satu kali inferensi gambar dengan paket high sebenarnya bisa diam-diam menambah satu sampai dua biaya sketsa “tak terlihat”, dan ini mudah terlewat saat menghitung anggaran.
Kalau dihitung kasar, angkanya jadi lebih jelas. Misalnya satu request pembuatan gambar 1K berjalan di paket high, token teks pemikiran sekitar 750 token. Jika model memang menghasilkan dua sketsa sementara, lalu ditambah gambar final, secara teori akan ada tiga part gambar. Dengan asumsi tiap gambar 1120 token, sekitar 0.0336 dolar, biaya output untuk tiga gambar saja sudah mendekati 0.1 dolar. Ditambah biaya token teks pemikiran, totalnya bisa jadi 2-3 kali paket minimal. Apakah benar-benar akan muncul dua sketsa atau tidak, itu tergantung penilaian model terhadap petunjuk yang diberikan, jadi tidak semua pemanggilan high otomatis menghasilkan dua sketsa penuh. Itu juga sebabnya total token dari pengujian nyata sering muncul di rentang 2243-2375, bukan naik tepat dua kali lipat.
💰 Optimasi biaya: Untuk tim yang sensitif terhadap biaya token, sebaiknya cek dulu
totalTokenCountaktual lewat log pemanggilan di platform APIYI apiyi.com, baru putuskan apakah paket high perlu diaktifkan terus-menerus. Ini membantu menghindari pembengkakan anggaran karena sketsa yang tidak dihitung sebelumnya.
Kapan sebaiknya pakai high, kapan cukup minimal default
Berdasarkan data uji coba, berikut referensi keputusan yang sederhana.

| Skenario bisnis | Paket yang disarankan | Alasan |
|---|---|---|
| Pembuatan massal gambar promosi, tidak terlalu menuntut presisi komposisi | minimal (default) | Latensi lebih rendah, biaya token lebih terkontrol, cukup untuk kebutuhan output harian |
| Komposisi dengan banyak objek, perlu mengikuti tata letak teks atau hubungan spasial secara presisi | high | Pemikiran tambahan memberi akurasi komposisi yang lebih tinggi, layak dibayar demi kualitas |
| Detail halaman produk e-commerce, poster, atau skenario dengan toleransi kesalahan rendah | high | Mengurangi frekuensi revisi dan gambar ulang, sehingga biaya total justru bisa lebih rendah |
| Skenario interaksi real-time yang sangat sensitif terhadap kecepatan respons | minimal | Latensi paket high bisa bertambah 5-10 detik, kurang cocok untuk pengalaman interaktif yang ketat |
Memanggil gemini-3-pro-image |
Tidak perlu diset | Perilaku berpikir model ini bersifat tetap, jadi pengaturan parameter tidak akan berpengaruh |
Simpelnya, paket high paling cocok untuk skenario di mana “sekali jadi” lebih penting daripada “cepat keluar gambar”. Kalau aplikasi kamu sering butuh retry dan bolak-balik ubah petunjuk demi dapat komposisi yang pas, justru lebih masuk akal langsung pakai high. Biaya per request memang sedikit lebih mahal, tapi tingkat keberhasilan sekali jalan lebih tinggi, jadi secara total sering kali lebih hemat.
Dalam implementasi engineering sehari-hari, pendekatan yang paling aman adalah menjadikan thinkingLevel sebagai opsi konfigurasi, bukan ditulis hardcode di kode. Misalnya, routing otomatis berdasarkan jenis bisnis yang dikirim pemanggil API: tugas batch default ke minimal, sedangkan request yang butuh tata letak presisi atau hubungan ruang antar banyak objek otomatis dialihkan ke high. Dengan begitu, rata-rata biaya tetap terkendali tanpa mengorbankan kualitas di skenario penting. Kalau tim kamu juga mengelola logika pemanggilan untuk model flash, flash-lite, dan pro sekaligus, sebaiknya parameter ini disatukan di layer pembungkusan parameter, dan hanya kirim thinkingLevel ke model yang memang mendukungnya. Ini mencegah parameter tak valid ikut diteruskan ke pro-image dan bikin proses investigasi jadi rumit.
🚀 Mulai cepat: Disarankan memakai platform APIYI apiyi.com untuk membangun prototipe dengan cepat. Satu set
base_urlsaja sudah cukup untuk berganti antara pengaturan minimal dan high guna membandingkan hasil, tanpa perlu konfigurasi autentikasi terpisah untuk tiap paket.
FAQ
Q1: Apakah performa penalaran gemini-3.1-flash-lite-image dan gemini-3.1-flash-image sama?
Keduanya memakai struktur parameter thinkingConfig yang sama, dan level yang didukung juga sama-sama minimal dan high. Tapi, flash-lite diposisikan sebagai versi ringan, jadi kedalaman berpikir sebenarnya dan detail hasil gambar biasanya lebih lemah dibanding flash-image. Ini juga terlihat dari pola penamaannya: seri flash-lite di model teks memang selalu diposisikan sebagai “lebih cepat, lebih hemat, akurasi sedikit turun”, dan seri gambar melanjutkan logika kompromi yang sama. Saat high diaktifkan, kekurangan model ringan pada komposisi yang kompleks bisa sedikit tertutupi, tapi tetap sulit menyamai performa flash-image sepenuhnya. Kalau ingin perbandingan kuantitatif, kamu bisa memanggil kedua model lewat platform APIYI apiyi.com dengan set petunjuk yang sama, lalu bandingkan thoughtsTokenCount dan hasil gambarnya secara langsung.
Q2: Kalau mengirim parameter thinkingLevel ke gemini-3-pro-image, apakah akan error?
Tidak error. Hasil pengujian kami menunjukkan bahwa setelah parameter high dikirim, request tetap berhasil dan respons normal, tetapi thoughtsTokenCount tetap berada di rentang 181–214, hampir sama seperti saat parameter tidak dikirim. Ini menunjukkan bahwa perilaku berpikir model tersebut bersifat tetap dan tidak menerima penyesuaian dari luar. Saat melakukan pemanggilan model secara batch ke banyak model, sebaiknya di kode bisnis cek nama model secara terpisah, supaya tidak salah mengira parameternya sudah bekerja.
Q3: Setelah mengaktifkan level high, apakah resolusi gambar atau parameter kualitas perlu ikut diubah?
Tidak perlu. Data pengujian menunjukkan bahwa token gambar pada dua level minimal dan high sama-sama stabil di 1120, yang berarti thinkingLevel hanya memengaruhi proses penalaran internal model, bukan mengubah pengaturan resolusi gambar keluaran. Resolusi tetap dikendalikan secara terpisah oleh parameter ukuran di imageConfig, dan tidak ada hubungannya dengan level berpikir. Singkatnya, thinkingLevel dan parameter resolusi adalah dua sumbu pengaturan yang saling independen: satu mengatur apakah model “berpikir cukup matang”, satunya lagi mengatur “gambar dibuat sebesar dan sedetail apa”. Keduanya bisa dikombinasikan bebas, tanpa hubungan saling mengunci atau saling memengaruhi.
Kesimpulan
gemini-3.1-flash-lite-image memang mendukung mode penalaran, dan ini sudah terverifikasi baik lewat dokumentasi resmi maupun data pengujian APIYI. thinkingLevel hanya punya dua pilihan, yaitu minimal dan high. Saat high diaktifkan, token berpikir bisa naik ke atas 700 dan waktu total bertambah sekitar 5–10 detik, tetapi konsumsi token gambar akhir tidak berubah. Sementara itu, gemini-3-pro-image memang menerima parameter ini tanpa error, tetapi dalam praktiknya tidak berpengaruh. Memahami logika biaya dua jalur ini—“teks berpikir masuk ke thoughtsTokenCount, sedangkan sketsa komposisi masuk ke candidatesTokenCount”—adalah kunci penting untuk mengontrol biaya pembuatan gambar. Kalau kamu perlu berpindah cepat antar berbagai model gambar Gemini untuk pengujian, lebih praktis memakai gateway terpadu APIYI apiyi.com, supaya tidak perlu membuat kunci API terpisah dan mengelola kode pemanggilan untuk tiap model.
Data dalam artikel ini berasal dari pengujian langsung tim teknis APIYI. Kalau kamu ingin berdiskusi lebih lanjut soal detail pemanggilan model gambar Gemini, silakan hubungi dukungan teknis lewat APIYI apiyi.com.
Referensi
- Dokumentasi Resmi Gemini API – Pembuatan Gambar: Penjelasan parameter tingkat berpikir (thinking levels)
- Tautan:
ai.google.dev/gemini-api/docs/generate-content/image-generation
- Tautan: