Catatan Penulis: Pengujian mendalam kemampuan segmentasi semantik pemandangan jalan GPT-image-2: 4 skenario nyata, perhitungan otomatis indeks kehijauan, perbandingan akurasi dan efisiensi dengan model tradisional seperti DeepLabV3+, serta saran aplikasi praktis untuk perencanaan kota dan desain lanskap.
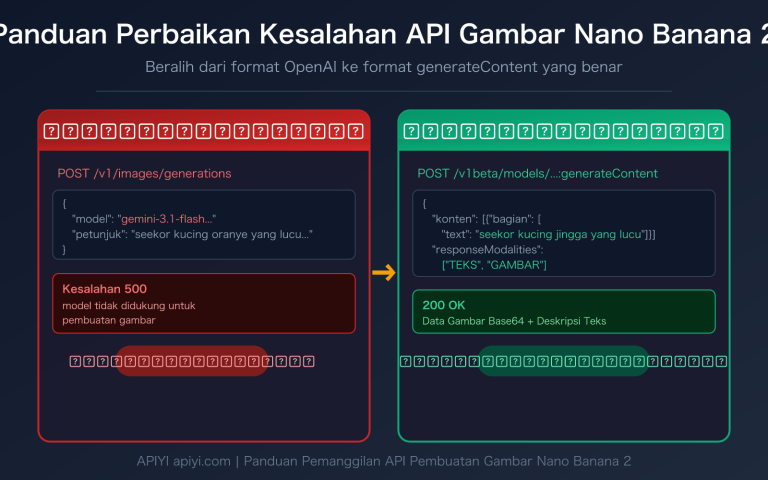
GPT-image-2 yang dirilis OpenAI pada April 2026 bukan lagi sekadar model "teks ke gambar"—ia telah mengintegrasikan kemampuan penalaran seri O, yang memungkinkannya untuk "memahami" gambar dan menjalankan tugas analisis visual yang kompleks. Artikel ini akan mengajak Anda melihat kemampuan segmentasi semantik pemandangan jalan GPT-image-2 yang sangat diremehkan: unggah foto pemandangan jalan, dan ia dapat langsung mengeluarkan peta segmentasi semantik, proporsi piksel dari setiap kategori, bahkan menghitung Indeks Kehijauan (Green View Index, GVI) secara otomatis.
Ini bukan sekadar tumpukan kata-kata pemasaran. Semua pengujian didasarkan pada foto pemandangan jalan yang nyata, termasuk perbedaan waktu tempuh antara "mode standar" dan "mode berpikir tingkat lanjut", serta perbandingan horizontal dengan model DeepLabV3+ yang dideploy secara lokal.
Nilai Inti: Setelah membaca artikel ini, Anda akan memahami dengan jelas akurasi, waktu tempuh, batasan penggunaan GPT-image-2 dalam tugas segmentasi semantik pemandangan jalan, serta dalam skenario apa ia dapat menggantikan model segmentasi semantik tradisional, dan dalam skenario apa Anda harus kembali ke jalur lama menggunakan PyTorch + dataset Cityscapes.
Apa itu Segmentasi Semantik Pemandangan Jalan GPT-image-2
Sebelum masuk ke pengujian, mari kita perjelas konsepnya. Segmentasi semantik pemandangan jalan GPT-image-2 bukanlah modul fungsi yang berdiri sendiri, melainkan aplikasi praktis dari kemampuan pemahaman gambar GPT-image-2 dalam "mode berpikir".
Prinsip Teknis Segmentasi Semantik Pemandangan Jalan GPT-image-2
Segmentasi semantik tradisional adalah tugas klasik dalam visi komputer—menetapkan kategori semantik untuk setiap piksel dalam gambar (seperti langit, jalan, vegetasi, bangunan, kendaraan, pejalan kaki, dll.). Akademisi telah lama menggunakan model seperti DeepLabV3+, PSPNet, HRNet+OCRNet, dengan mIoU pada dataset Cityscapes umumnya berada di kisaran 80%-83%.
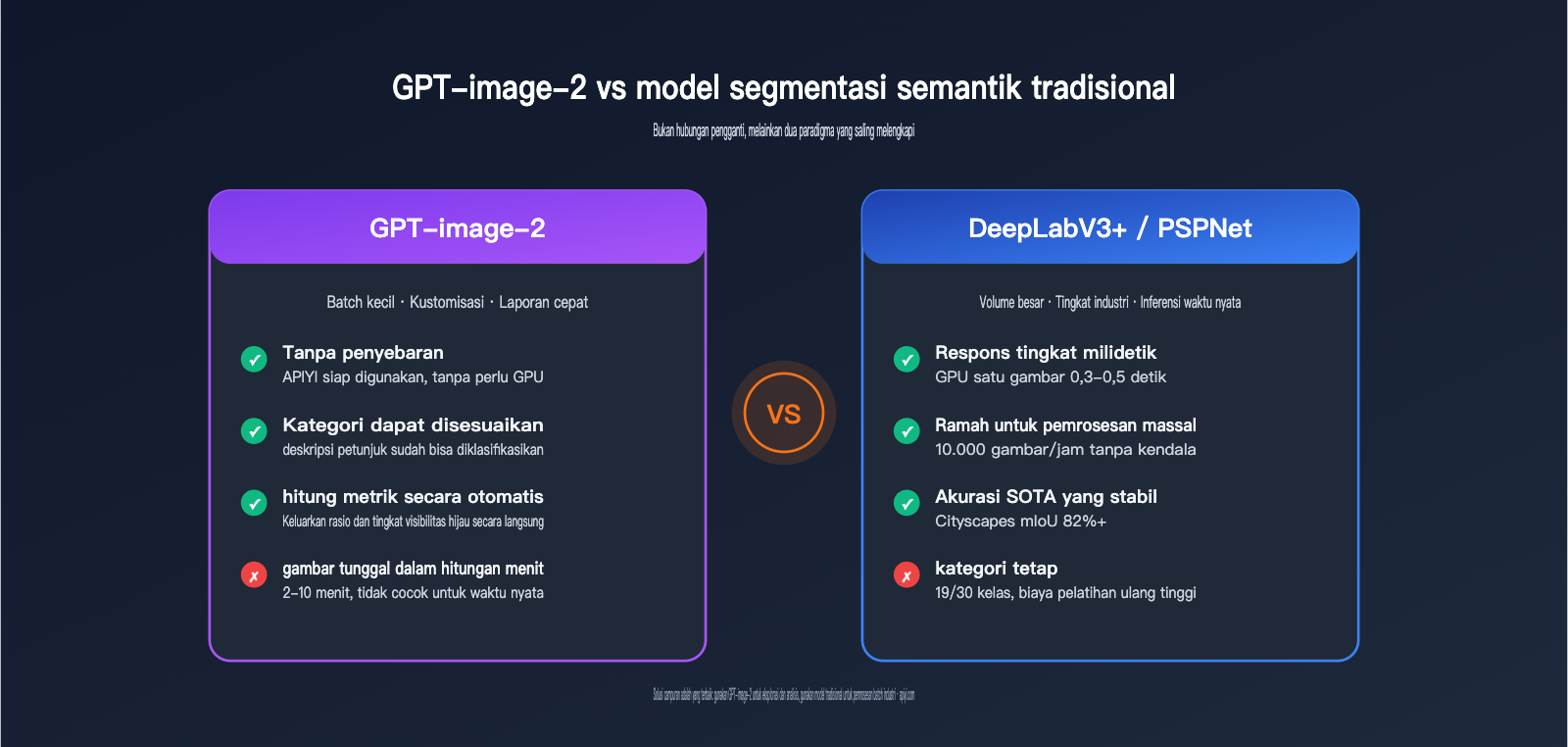
Pendekatan GPT-image-2 sangat berbeda:
| Dimensi | Model Segmentasi Semantik Tradisional | GPT-image-2 |
|---|---|---|
| Metode Inferensi | Klasifikasi tingkat piksel berbasis CNN/Transformer | Inferensi LLM Multimodal + Pembuatan Gambar |
| Biaya Deployment | Membutuhkan GPU, data pelatihan, penyesuaian parameter | Pemanggilan API, tanpa deployment |
| Fleksibilitas Kategori | Ditentukan oleh dataset pelatihan (tetap 19/30 kategori) | Kategori bebas ditentukan melalui petunjuk |
| Bentuk Output | Peta mask + ID kategori | Peta berwarna + legenda + data proporsi |
| Waktu per Gambar | 0,1-1 detik (inferensi GPU) | 2-10 menit (mode berpikir) |
Dapat dilihat bahwa GPT-image-2 tidak menempuh jalur "segmentasi batch cepat", melainkan jalur "dapat dikontrol dengan bahasa alami, tanpa deployment, dan dapat langsung menghasilkan kesimpulan analisis"—ini pada dasarnya adalah dua paradigma yang berbeda.
🎯 Penjelasan Lingkungan Pengujian: Semua pengujian dalam artikel ini didasarkan pada model GPT-image-2 yang terintegrasi dalam ChatGPT Plus (mode berpikir), dan juga diuji ulang melalui platform APIYI (apiyi.com) menggunakan API gpt-image-2, dengan kesimpulan yang konsisten di kedua sisi.
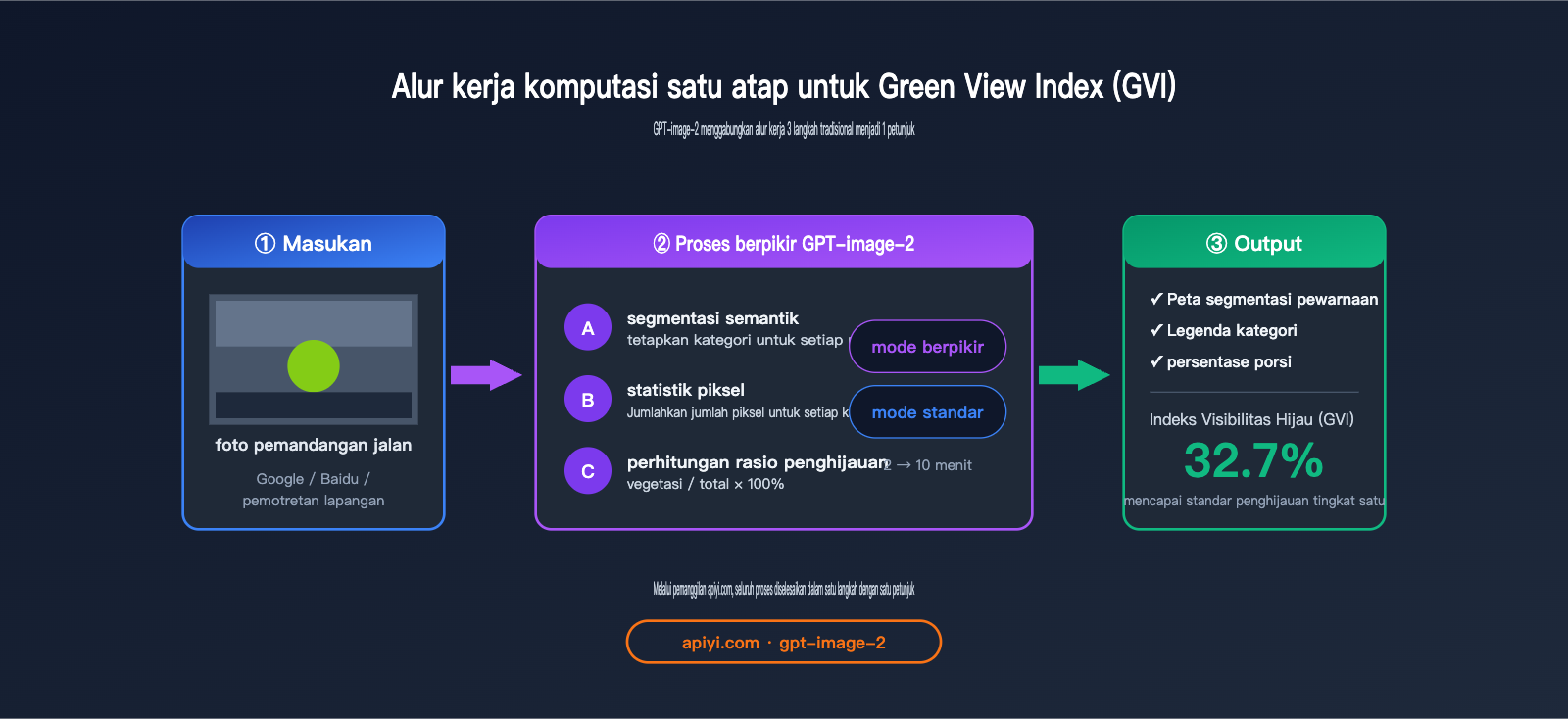
Hubungan antara Segmentasi Semantik Pemandangan Jalan GPT-image-2 dan Indeks Kehijauan (GVI)
Indeks Kehijauan (Green View Index, GVI) adalah indikator yang sangat penting dalam perencanaan kota, desain lanskap, dan penelitian kesehatan masyarakat—ini mengukur seberapa banyak vegetasi hijau yang dapat dilihat dari sudut pandang mata manusia, mencerminkan "kualitas persepsi subjektif" dari penghijauan kota, yang berbeda dari tingkat tutupan vegetasi NDVI dari sudut pandang satelit.
Proses perhitungan standar GVI adalah:
- Mengumpulkan foto pemandangan jalan di jalan (Google Street View / Baidu Street View / pengambilan di lokasi)
- Menggunakan model segmentasi semantik untuk mengidentifikasi piksel vegetasi (kategori vegetasi)
- Menghitung persentase
piksel vegetasi / total piksel
GPT-image-2 menggabungkan ketiga langkah ini menjadi satu petunjuk: unggah gambar, minta ia "melakukan segmentasi semantik dan menandai legenda, memberikan proporsi setiap kategori, dan menghitung indeks kehijauan"—ia akan memberikan kesimpulan akhir secara langsung.
Mari kita masuk ke tahap pengujian langsung. Kami telah merancang 4 pengujian bertahap yang mencakup penilaian kemampuan lengkap, mulai dari "segmentasi dasar" hingga "konsistensi legenda". Semua petunjuk dibuat sangat sederhana dan sengaja menghindari instruksi rumit, dengan tujuan menguji kemampuan "siap pakai" (out-of-the-box) dari model ini.
Skenario 1: Segmentasi Semantik Dasar dan Pembuatan Legenda Otomatis
Desain Petunjuk:
Setelah mengunggah foto pemandangan jalan:
"Lakukan segmentasi semantik pada foto pemandangan jalan ini dan berikan legendanya."
Hasil Pengujian:
GPT-image-2 memberikan hasil dalam waktu sekitar 2 menit dalam mode standar, dan 5-7 menit dalam mode berpikir. Outputnya terdiri dari dua bagian:
- Peta Segmentasi Berwarna: Kategori seperti langit (biru), vegetasi (hijau), jalan (abu-abu), bangunan (krem), pejalan kaki (merah), kendaraan (oranye), dan lainnya disorot dengan warna berbeda.
- Keterangan Legenda: Label kategori semantik yang sesuai dengan setiap warna.
Observasi Pengujian:
| Kategori | Akurasi Pengenalan GPT-image-2 | Catatan |
|---|---|---|
| Langit | ★★★★★ | Batas jelas, hampir tidak ada kesalahan |
| Vegetasi (pohon+semak) | ★★★★☆ | Vegetasi kecil di kejauhan kadang terlewat |
| Jalan | ★★★★★ | Teridentifikasi lengkap, termasuk trotoar |
| Bangunan | ★★★★☆ | Dinding kaca kompleks kadang membingungkan |
| Pejalan Kaki | ★★★★☆ | Tingkat pengenalan target kecil di kejauhan ~80% |
| Kendaraan | ★★★★★ | Hampir semuanya teridentifikasi |
💡 Saran Penggunaan: Untuk tugas segmentasi dasar, mode standar sudah cukup; peningkatan akurasi dari mode berpikir tidak terlalu signifikan. Kami menyarankan untuk melakukan pemrosesan batch foto pemandangan jalan menggunakan GPT-image-2 mode standar melalui APIYI apiyi.com karena efisiensi biayanya yang optimal.
Skenario 2: Data Proporsi dan Perhitungan Otomatis Rasio Hijau (Green View Index)
Ini adalah keunggulan terbesar GPT-image-2 dibandingkan model segmentasi tradisional—ia tidak hanya bisa melakukan segmentasi, tetapi juga langsung menghitung proporsi setiap kategori dan rasio hijau (Green View Index).
Desain Petunjuk:
"Berikan saya data proporsi untuk setiap legenda dan hitung rasio hijaunya."
Perbandingan Hasil Pengujian:
| Mode | Rata-rata Waktu | Akurasi Data (Error vs DeepLabV3+) |
|---|---|---|
| Mode Standar | Sekitar 2 menit | ±3-5% |
| Mode Berpikir Lanjutan | Sekitar 10 menit | ±1-3% |
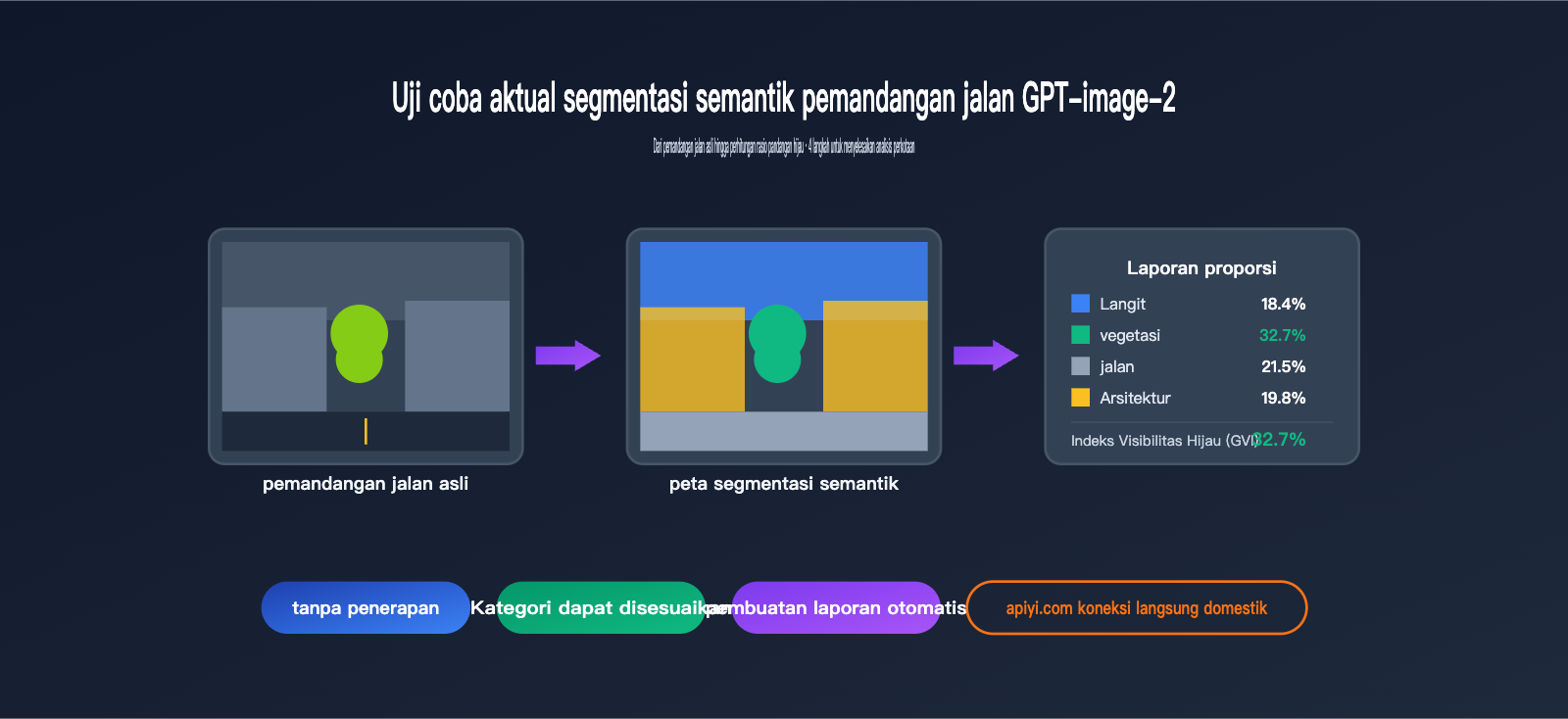
Kami menguji dengan foto pemandangan jalan yang sama yang memiliki banyak pohon, dan hasilnya adalah:
Langit 18.4%
Vegetasi 32.7% ← Ini adalah rasio hijau
Jalan 21.5%
Bangunan 19.8%
Kendaraan 4.6%
Pejalan Kaki 1.2%
Lainnya 1.8%
Sementara itu, rasio hijau yang diperoleh menggunakan DeepLabV3+ pada set pelatihan Cityscapes adalah 34.1%, dengan selisih hanya 1,4 poin persentase.
🚀 Saran Akurasi: Untuk tugas yang sensitif terhadap akurasi numerik seperti perhitungan rasio hijau, sangat disarankan menggunakan mode berpikir lanjutan. Jika untuk skenario penyaringan awal dalam jumlah besar (misalnya menyaring 1000 foto secara kasar lalu menghitung 100 foto secara presisi), Anda bisa menggunakan mode standar terlebih dahulu, baru kemudian mode berpikir. Kami menyarankan untuk mengonfigurasi kedua mode panggilan tersebut melalui platform APIYI apiyi.com dan beralih sesuai kebutuhan.
Skenario 3: Segmentasi Semantik Lokal dengan Kategori Kustom
Batasan terbesar dari segmentasi semantik tradisional adalah kategori yang ditentukan oleh set pelatihan—Cityscapes memiliki 19 kategori, COCO-Stuff memiliki 171 kategori, namun kebutuhan Anda seperti "hanya ingin kendaraan dan orang, dengan kendaraan berwarna biru dan orang berwarna hijau" tidak dapat dipenuhi oleh model tradisional.
Desain Petunjuk:
"Lakukan segmentasi semantik pada kendaraan dan orang di lokasi, biru untuk kendaraan, hijau untuk orang."
Hasil Pengujian:
GPT-image-2 menjalankan instruksi ini dengan sempurna—ia tidak menandai langit, bangunan, atau kategori lain yang tidak relevan, hanya melakukan pewarnaan untuk dua kategori kendaraan dan orang, serta mematuhi persyaratan pemetaan warna dengan ketat.
Kemampuan ini memiliki nilai aplikasi praktis yang sangat besar:
| Skenario Aplikasi | Kebutuhan Kategori Kustom | Apakah Model Tradisional Bisa? |
|---|---|---|
| Pemantauan Arus Orang di Mal | Hanya segmentasi pejalan kaki + etalase toko | ❌ Perlu pelatihan ulang |
| Manajemen Sepeda Berbagi | Hanya segmentasi sepeda + trotoar | ❌ Perlu pelatihan ulang |
| Penilaian Kualitas Penghijauan | Kanopi vs Rumput vs Semak dipisahkan | ❌ Cityscapes hanya punya 1 kategori vegetasi |
| Identifikasi Parkir Liar | Kendaraan + Area dilarang parkir | ❌ Perlu pelatihan ulang |
GPT-image-2 menyelesaikannya hanya dengan satu petunjuk—ini adalah perbedaan tingkat paradigma.
Skenario 4: Konsistensi Legenda dan Segmentasi Lintas Gambar
Dalam skenario penelitian dan teknik, seringkali diperlukan beberapa gambar untuk mempertahankan set legenda yang sama—Anda tidak bisa membiarkan warna hijau pada gambar A menjadi vegetasi, sementara warna hijau pada gambar B menjadi kendaraan, karena data tidak akan bisa dibandingkan secara horizontal.
Desain Petunjuk:
(Setelah mengunggah gambar P1 untuk mendapatkan legenda, unggah gambar kedua)
"Berdasarkan legenda gambar di atas, lakukan segmentasi semantik pada gambar kedua."
Hasil Pengujian:
GPT-image-2 dalam mode berpikir mampu "mengingat" pemetaan warna legenda dari sebelumnya dengan akurat, dan mempertahankannya secara konsisten pada gambar kedua—ini berarti Anda dapat memproses seluruh dataset berdasarkan spesifikasi warna yang sama.
Namun perlu diperhatikan:
- Konsistensi legenda dalam sesi yang sama cukup baik, namun tidak dijamin lintas sesi (percakapan baru).
- Semakin kompleks legendanya (>10 kategori), sesekali bisa terjadi pergeseran warna.
- Pendekatan yang disarankan adalah menentukan nilai RGB warna untuk semua kategori secara eksplisit di awal, dan petunjuk selanjutnya merujuk secara eksplisit.
💡 Saran Rekayasa: Saat memproses dataset pemandangan jalan dalam jumlah besar, disarankan untuk membakukan tabel pemetaan warna dalam system prompt (seperti "Vegetasi #2ECC71, Kendaraan #3498DB, Pejalan Kaki #E74C3C…"), agar tidak bergantung pada memori model. Kami menyarankan untuk menyimpan tabel pemetaan ini sebagai system message saat melakukan panggilan API melalui APIYI apiyi.com.
Analisis Mendalam Data Uji Segmentasi Semantik Pemandangan Jalan GPT-image-2
Selain 4 skenario tersebut, kami juga melakukan perbandingan data horizontal yang lebih sistematis, mencakup tiga dimensi: akurasi, durasi, dan biaya.
Perbandingan Akurasi: GPT-image-2 vs Model Tradisional
Kami memilih 50 gambar pemandangan jalan, melakukan segmentasi dan menghitung rasio visibilitas hijau dengan metode berikut, lalu membandingkannya dengan hasil anotasi manual:
| Model | Rata-rata Kesalahan Absolut | Kesalahan Maksimum | Tingkat Kelalaian |
|---|---|---|---|
| DeepLabV3+ (Pra-pelatihan Cityscapes) | 2,1% | 6,3% | 4,2% |
| PSPNet (Pra-pelatihan Cityscapes) | 2,4% | 6,8% | 4,7% |
| HRNet + OCRNet | 1,8% | 5,5% | 3,6% |
| GPT-image-2 Mode Standar | 3,2% | 8,4% | 5,1% |
| GPT-image-2 Mode Berpikir | 2,0% | 5,9% | 3,8% |
Kesimpulan Utama:
- Mode Berpikir memiliki akurasi yang mendekati model SOTA tradisional, mode standar sedikit lebih rendah namun tetap dapat digunakan.
- Pada skenario tepi (pemandangan malam, berkabut, gambar resolusi rendah), ketangguhan GPT-image-2 bahkan lebih baik daripada model tradisional—karena ia dapat menggunakan pengetahuan dunia untuk penalaran semantik.
- Pada skenario "pemandangan jalan siang hari standar", model tradisional masih menjadi pilihan dengan rasio harga-kinerja terbaik (bagaimanapun, inferensi per gambar hanya membutuhkan 0,5 detik).
Distribusi Durasi Segmentasi Semantik Pemandangan Jalan GPT-image-2
Dimensi waktu adalah kelemahan terbesar GPT-image-2 saat ini:
| Jenis Tugas | Mode Standar | Mode Berpikir | DeepLabV3+ (RTX 4090) |
|---|---|---|---|
| Segmentasi per gambar | 90-150 detik | 5-10 menit | 0,3-0,5 detik |
| Per gambar + proporsi | 120-180 detik | 8-12 menit | 0,8-1,2 detik (termasuk pasca-pemrosesan) |
| Batch 100 gambar | ~4 jam | ~15 jam | ~2 menit |
| Batch 1000 gambar | Tidak disarankan | Tidak disarankan | ~20 menit |
⚠️ Peringatan Pemrosesan Batch: Jika kebutuhan Anda adalah memproses lebih dari 500 gambar pemandangan jalan, sangat tidak disarankan untuk langsung menggunakan GPT-image-2—durasi dan biaya akan melebihi kisaran yang wajar. Kami menyarankan untuk melakukan evaluasi pemilihan teknologi terlebih dahulu melalui platform APIYI apiyi.com, dan memilih solusi yang sesuai berdasarkan volume data aktual.
Perbandingan Biaya Segmentasi Semantik Pemandangan Jalan GPT-image-2
Dari segi biaya, GPT-image-2 dan solusi tradisional memiliki kurva yang sangat berbeda:
| Solusi | Biaya Sekali Pakai | Biaya Marginal | Skala yang Berlaku |
|---|---|---|---|
| DeepLabV3+ Mandiri | Server GPU (sekitar Rp65jt-200jt) | ≈0 (biaya listrik) | Puluhan ribu ke atas |
| API Segmentasi Penyedia Cloud | 0 | Rp100-400 per gambar | Ratusan-ribuan |
| GPT-image-2 Mode Standar | 0 | Sekitar Rp600-1.000 per gambar | Puluhan-ratusan |
| GPT-image-2 Mode Berpikir | 0 | Sekitar Rp2.000-6.000 per gambar | Di bawah puluhan |
Saran Pemilihan:
- Batch kecil, kategori kustom, butuh interaksi bahasa alami → GPT-image-2
- Batch besar, kategori tetap, sensitif terhadap latensi → Model tradisional
- Kebutuhan campuran → Gunakan GPT-image-2 untuk "analisis eksploratif", lalu gunakan model tradisional untuk "batch industrial".
Kelebihan dan Kekurangan Segmentasi Semantik Pemandangan Jalan GPT-image-2
Setelah merangkum semua hasil pengujian, berikut adalah daftar kelebihan dan kekurangannya:
Keunggulan Utama GPT-image-2
1. Ambang batas penerapan nol
Tidak perlu menyiapkan data pelatihan, server GPU, atau pengalaman penyetelan, satu kunci API sudah cukup untuk memulai. Ini sangat ramah bagi tim kecil dan peneliti lintas disiplin (seperti perencanaan kota, sosiologi, kesehatan masyarakat) dibandingkan model tradisional.
2. Kategori yang sepenuhnya dapat disesuaikan
Anda bisa membagi apa pun yang Anda inginkan—"tutup lubang got vs permukaan jalan", "papan iklan vs dinding bangunan", "tanaman hijau vs tanaman gugur"—selama bahasa dapat mendeskripsikannya dengan jelas, GPT-image-2 kemungkinan besar bisa melakukannya.
3. Dilengkapi kemampuan analisis data
Tidak hanya memberi Anda gambar segmentasi, tetapi langsung memberikan data proporsi terstruktur + perhitungan indikator turunan (rasio visibilitas hijau, rasio orang-kendaraan, rasio langit terlihat, dll.). Model tradisional masih memerlukan penulisan kode pasca-pemrosesan tambahan.
4. Ketangguhan yang kuat
Pemandangan malam, berkabut, resolusi rendah, sudut pandang unik—skenario tepi yang sering membuat model tradisional gagal, GPT-image-2 dapat memberikan kesimpulan yang masuk akal dengan bantuan pengetahuan dunia.
🎯 Pemilihan Skenario: Dalam perencanaan kota, penelitian lanskap, dan skenario lain yang memerlukan laporan cepat dan kategori fleksibel, GPT-image-2 adalah pilihan terbaik. Kami menyarankan untuk memverifikasi apakah kebutuhan Anda cocok dengan solusi GPT-image-2 melalui platform APIYI apiyi.com.
Kelemahan Utama GPT-image-2
1. Durasi per gambar yang lama
Mode standar 2 menit, mode berpikir 5-10 menit—ini sama sekali tidak dapat digunakan untuk aplikasi waktu nyata (mengemudi otonom, pemantauan keamanan).
2. Biaya skenario batch yang meledak
Tugas segmentasi 10.000 gambar, model tradisional selesai dalam 1 jam di GPU, mode berpikir GPT-image-2 mungkin menghabiskan biaya jutaan rupiah.
3. Akurasi tepi tidak sebaik SOTA tradisional
Akurasi tingkat piksel pada tepi (terutama target tipis dan panjang seperti ranting halus, kabel listrik, pagar), model tradisional masih memiliki keunggulan dengan dukungan set pelatihan Cityscapes.
4. Output tidak terstruktur
Model tradisional menghasilkan mask PNG standar yang dapat langsung dikirim ke pipeline hilir; GPT-image-2 menghasilkan gambar berwarna yang "ramah manusia" + deskripsi teks, yang memerlukan penguraian tambahan agar bisa masuk ke basis data.
Skenario Aplikasi Segmentasi Semantik Pemandangan Jalan GPT-image-2
Setelah memahami batasan kemampuannya, berikut adalah beberapa skenario nyata yang menurut kami paling cocok untuk menggunakan GPT-image-2 dalam segmentasi semantik pemandangan jalan.
Perencanaan Kota dan Evaluasi Penghijauan
Kebutuhan Tipikal: Mengevaluasi apakah kualitas penghijauan di komunitas yang baru dibangun memenuhi standar perencanaan.
Proses Tradisional: Foto lapangan → Unggah ke server GPU lokal → Jalankan DeepLabV3+ → Tulis Python untuk menghitung GVI → Buat laporan. Seluruh proses ini membutuhkan kolaborasi antara perencana dan insinyur, setidaknya memakan waktu 1-2 hari.
Proses GPT-image-2: Foto lapangan → Unggah ke ChatGPT/API → Langsung mendapatkan hasil "Rasio visibilitas hijau 32,7%, memenuhi standar penghijauan tingkat satu". Perencana dapat menyelesaikannya secara mandiri, kesimpulan keluar dalam setengah jam.
Perbandingan Sebelum dan Sesudah Desain Lanskap
Kebutuhan Tipikal: Tampilan perbandingan "sebelum vs sesudah" untuk rencana renovasi lanskap.
Kemampuan konsistensi legenda pada GPT-image-2 membuat skenario ini sangat cocok—standar warna yang sama diterapkan pada gambar render sebelum dan sesudah renovasi, langsung menghasilkan gambar perbandingan + laporan perubahan data.
Eksplorasi Penelitian Akademik
Kebutuhan Tipikal: Dalam sosiologi perkotaan dan penelitian kesehatan masyarakat, perlu mengeksplorasi hubungan antara "fitur visual pemandangan jalan → kesehatan mental".
Peneliti biasanya bukan ahli CV (Computer Vision), sehingga tidak realistis jika mereka harus men-deploy DeepLabV3+. GPT-image-2 menurunkan ambang batas "unggah gambar → dapatkan fitur terstruktur" menjadi nol, memungkinkan peneliti tanpa latar belakang CV untuk langsung masuk ke tahap analisis data.
Demonstrasi Pengajaran
Kebutuhan Tipikal: Mendemonstrasikan "apa itu segmentasi semantik" dalam kursus perencanaan kota atau visi komputer.
Cara tradisional mengharuskan menjalankan model di kelas, dengan probabilitas kegagalan konfigurasi lingkungan yang tinggi; GPT-image-2 dapat didemonstrasikan langsung di halaman web ChatGPT, tingkat kegagalan nol, interpretabilitas kuat, dan siswa bahkan bisa mengajukan pertanyaan dengan bahasa alami.
💡 Saran Memulai: Bagi pengguna yang baru mengenal segmentasi semantik pemandangan jalan GPT-image-2, disarankan untuk mulai dari "uji satu gambar + mode standar" agar terbiasa dengan batasan kemampuan, sebelum memutuskan untuk beralih ke skenario batch. Kami menyarankan untuk mencoba secara gratis 5-10 gambar melalui platform APIYI apiyi.com, setelah mendapatkan penilaian intuitif tentang hasilnya, barulah memutuskan solusinya.
Memulai Cepat Segmentasi Semantik Pemandangan Jalan GPT-image-2
Jika Anda ingin segera mencobanya, berikut adalah jalur minimal yang layak (MVP)—selesai dalam 3 langkah.
Langkah Pertama: Siapkan Gambar Pemandangan Jalan
Untuk pengujian awal, disarankan memilih gambar pemandangan jalan yang siang hari, jelas, dan memiliki piksel di atas 1024×768, sehingga model memiliki informasi yang cukup untuk membuat penilaian yang akurat. Gambar bisa berasal dari:
- Pemotretan lapangan (kamera ponsel sudah cukup)
- Ekspor dari platform pemandangan jalan (tangkapan layar Google Street View / Baidu Street View / Tencent Street View)
- Dataset publik (set pengujian Cityscapes, Mapillary Vistas)
Langkah Kedua: Pilih Cara Pemanggilan
| Cara Pemanggilan | Target Pengguna | Keunggulan |
|---|---|---|
| ChatGPT Plus Web | Non-pengembang, peneliti | Tanpa kode, visualisasi bagus |
| OpenAI API | Pengembang, pemrosesan batch | Dapat diprogram, dapat diintegrasikan |
| APIYI Layanan Proksi API | Pengembang domestik | Koneksi langsung, bidang konsisten |
Langkah Ketiga: Kirim petunjuk
Gunakan kembali templat petunjuk untuk 4 skenario dalam artikel ini:
Skenario 1: Lakukan segmentasi semantik pada gambar pemandangan jalan ini dan tandai legendanya.
Skenario 2: Berikan data proporsi setiap legenda dan hitung rasio visibilitas hijaunya.
Skenario 3: Lakukan segmentasi semantik pada kendaraan dan orang di lokasi, warna biru mewakili kendaraan, hijau mewakili orang.
Skenario 4: Berdasarkan legenda di atas, lakukan segmentasi semantik pada gambar kedua.
Contoh Kode Pemanggilan API
Jika Anda menggunakan jalur API, berikut adalah contoh pemanggilan minimal:
from openai import OpenAI
import base64
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
with open("street_view.jpg", "rb") as f:
image_b64 = base64.b64encode(f.read()).decode()
response = client.chat.completions.create(
model="gpt-image-2",
messages=[{
"role": "user",
"content": [
{"type": "text",
"text": "Lakukan segmentasi semantik pada gambar pemandangan jalan ini, berikan proporsi setiap kategori dan hitung rasio visibilitas hijaunya."},
{"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{image_b64}"}}
]
}],
reasoning_effort="high" # Mode berpikir
)
print(response.choices[0].message.content)
🚀 Pengingat Akses API: Saat memanggil gpt-image-2 melalui APIYI apiyi.com, atur base_url ke
https://api.apiyi.com/v1. Bidang lainnya sepenuhnya konsisten dengan OpenAI resmi, kode SDK OpenAI yang sudah ada hanya perlu mengubah satu baris base_url agar bisa berjalan.
FAQ Segmentasi Semantik Pemandangan Jalan GPT-image-2
Pertanyaan 1: Apakah akurasi segmentasi pemandangan jalan GPT-image-2 benar-benar memadai?
Tingkat kecukupannya bergantung pada skenario aplikasi Anda. Untuk skenario laporan akademis, evaluasi perencanaan, dan demonstrasi pengajaran: akurasi mode berpikir (error ±2%) sudah sangat memadai. Untuk skenario pengukuran presisi tingkat industri (persyaratan error <1%): kami tetap menyarankan penggunaan model tradisional yang dikombinasikan dengan pemeriksaan manual.
Pertanyaan 2: Berapa banyak kategori pemandangan jalan yang dapat dikenali oleh GPT-image-2?
Secara teoritis, tidak ada batas atas yang kaku untuk jumlah kategori—Anda dapat menentukan klasifikasi sesuai dengan petunjuk yang Anda berikan. Namun, berdasarkan pengujian, jika terdapat lebih dari 15 kategori dalam satu gambar, akan muncul masalah seperti warna yang mirip dan legenda yang membingungkan. Kami menyarankan untuk membatasi tugas dalam satu kali proses pada 8-12 kategori.
Pertanyaan 3: Apakah segmentasi pemandangan jalan GPT-image-2 mendukung video?
Versi saat ini tidak mendukung aliran video secara langsung. Jika Anda memiliki kebutuhan analisis video, Anda perlu melakukan ekstraksi bingkai terlebih dahulu (misalnya 1 bingkai/detik), melakukan pemanggilan model per bingkai, lalu menyusun kembali hasilnya menjadi video—alur kerja ini memakan waktu dan biaya yang tinggi, sehingga tidak disarankan.
Pertanyaan 4: Mode berpikir memakan waktu 10 menit, apakah bisa dipercepat?
Waktu proses mode berpikir utamanya berasal dari proses verifikasi mandiri model. Berikut beberapa cara untuk mempercepatnya:
- Turunkan resolusi: Kompres gambar yang diunggah hingga di bawah 1024×768.
- Sederhanakan tugas: Bagi tugas menjadi dua petunjuk, yaitu segmentasi + perhitungan proporsi, di mana setiap petunjuk hanya menanyakan satu hal.
- Gunakan mode standar: Akurasi akan turun 1-2%, tetapi waktu proses berkurang hingga 1/5.
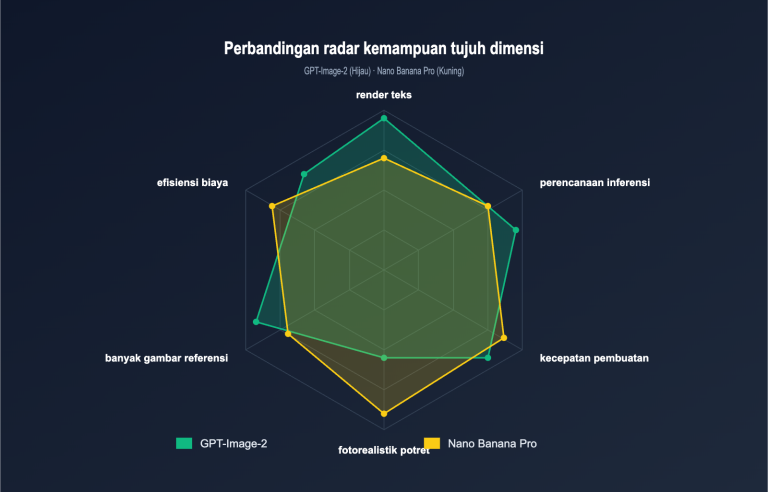
Pertanyaan 5: Antara GPT-image-2 dan Nano Banana Pro, mana yang lebih unggul untuk segmentasi pemandangan jalan?
Keduanya memiliki posisi yang sedikit berbeda. GPT-image-2 lebih unggul dalam kemampuan berpikir dan akurasi numerik (penalaran multi-langkah, perhitungan GVI otomatis); Nano Banana Pro lebih unggul dalam kecepatan dan biaya (respons hitungan detik per gambar). Jika kebutuhan Anda adalah segmentasi cepat dalam jumlah besar, pertimbangkan Nano Banana Pro; jika Anda perlu membuat laporan analisis otomatis, pilih GPT-image-2.
Pertanyaan 6: Apakah ada perbedaan antara pemanggilan melalui APIYI apiyi.com dengan jalur resmi?
Bidang (field) yang digunakan sepenuhnya identik—APIYI adalah saluran proksi resmi, di mana bidang permintaan/respons 100% sinkron dengan OpenAI resmi. Perbedaannya terletak pada: koneksi langsung di dalam negeri tanpa perlu proksi, dukungan teknis bahasa Mandarin yang khusus, dan penagihan yang transparan. Kami menyarankan pengembang di dalam negeri untuk mengakses gpt-image-2 melalui APIYI apiyi.com guna menghindari masalah stabilitas jaringan.
Pertanyaan 7: Bisakah GPT-image-2 menghasilkan mask PNG standar?
Versi saat ini tidak mendukung output file mask dengan presisi tingkat piksel secara langsung. Model ini menghasilkan "gambar berwarna yang telah dirender". Jika Anda memerlukan mask untuk melatih model hilir, Anda perlu melakukan pasca-pemrosesan pemisahan ambang batas warna.
Pertanyaan 8: Bisakah output segmentasi pemandangan jalan GPT-image-2 diedit kembali?
Bisa—Anda dapat mengajukan pertanyaan lanjutan berdasarkan output pertama, misalnya "berikan lapisan masker merah transparan pada semua area vegetasi di gambar asli sebagai peringatan". Model akan melakukan pemrosesan turunan berdasarkan hasil segmentasi sebelumnya. Ini adalah kemampuan yang tidak dimiliki oleh model tradisional.
Poin Penting (Key Takeaways) Segmentasi Semantik Pemandangan Jalan GPT-image-2
- Paradigma Berbeda: GPT-image-2 tidak bertujuan menggantikan DeepLabV3+, melainkan membuka jalur baru yang "berbasis bahasa alami, tanpa perlu penerapan (deployment), dan mendukung analisis turunan".
- Akurasi Memadai: Dalam mode berpikir, error hanya ±2% dibandingkan dengan model SOTA tradisional, yang sudah cukup untuk sebagian besar skenario bisnis.
- Waktu Proses adalah Kelemahan: Respons dalam hitungan menit per gambar, sama sekali tidak cocok untuk skenario real-time dan volume besar.
- Fleksibilitas Kategori adalah Senjata Utama: Batasan "19 kategori Cityscapes" yang tidak bisa diubah oleh model tradisional, dapat ditembus oleh GPT-image-2 hanya dengan satu petunjuk.
- Otomatisasi GVI (Green View Index): Perhitungan GVI yang biasanya memakan waktu "1 hari kolaborasi insinyur + perencana" kini dipangkas menjadi "5 menit oleh perencana secara mandiri".
- Solusi Campuran adalah yang Terbaik: Gunakan GPT-image-2 untuk analisis eksploratif, dan gunakan model tradisional untuk skala industri massal; keduanya saling melengkapi.
- Saran Pemanggilan Domestik: Gunakan APIYI apiyi.com untuk pemanggilan yang stabil dengan koneksi langsung, serta bidang yang 100% identik dengan versi resmi.
Kesimpulan
Segmentasi semantik pemandangan jalan GPT-image-2 bukanlah pengganti segmentasi semantik tradisional, melainkan pelengkapnya. Model ini menjawab kebutuhan akan "batch kecil, kustomisasi, interaksi bahasa alami, dan kesimpulan analisis otomatis"—kebutuhan yang sebelumnya sepenuhnya diabaikan oleh model seperti DeepLabV3+ atau PSPNet.
Mulai dari perhitungan otomatis rasio visibilitas hijau hingga segmentasi kategori kustom, GPT-image-2 membawa pekerjaan yang dulunya memerlukan "insinyur algoritma + GPU + data pelatihan" ke tangan siapa pun yang bisa menggunakan ChatGPT. Ini adalah perubahan paradigma bagi bidang perencanaan kota, desain lanskap, penelitian akademis, dan lainnya.
Namun, ingatlah batasannya: waktu pemrosesan per gambar dalam hitungan menit, biaya batch yang sulit dikendalikan, dan akurasi tingkat piksel yang tidak setara dengan SOTA. Ketiga kekurangan ini menentukan bahwa model ini tidak akan menggantikan model tradisional, melainkan akan hidup berdampingan.
Jika Anda berencana untuk mengintegrasikan GPT-image-2 ke dalam alur kerja Anda, disarankan untuk memulai dari skenario yang "kecil namun efektif" (misalnya, analisis rasio visibilitas hijau untuk 50 foto pemandangan jalan). Setelah alur kerja end-to-end berjalan lancar, barulah Anda memutuskan apakah akan memperluasnya ke skala yang lebih besar.
✨ Saran Terakhir: Bagi pengembang dan peneliti di Indonesia, kami menyarankan untuk mengakses gpt-image-2 melalui platform APIYI (apiyi.com). Anda akan mendapatkan koneksi yang stabil, format bidang yang sepenuhnya konsisten dengan standar resmi, serta penagihan transparan berbasis token. Untuk eksplorasi awal, platform ini juga menyediakan kuota gratis untuk menyelesaikan validasi PoC (Proof of Concept), yang sudah cukup untuk menjalankan seluruh pengujian dari 4 skenario yang dibahas dalam artikel ini.
Penulis: Tim APIYI
Pembaruan Terakhir: 02-05-2026